🍂 枫言枫语 :我是予枫,一名行走在 Java 后端与多模态 AI 交叉路口的研二学生。
"予一人以深耕,观万木之成枫。"
在这里,我记录从底层源码到算法前沿的每一次思考。希望能与你一起,在逻辑的丛林中寻找技术的微光。
2023 CVPR Decoupled Multimodal Distilling for Emotion Recognition
引言
人类多模态情感识别(MER)旨在通过语言、视觉和声学模态来感知情感。尽管多模态研究取得了显著进展,但不同模态间的异质性(Heterogeneity)以及各模态对情感表达的贡献差异(如语言通常占主导地位)依然是巨大的挑战。
这篇由南京理工大学发表于 CVPR 2023 的论文,提出了 DMD(Decoupled Multimodal Distillation) 框架。它通过将特征空间解耦并引入动态图蒸馏机制,实现了更具灵活性和自适应性的跨模态知识迁移。
一、 核心痛点:模态贡献的不平等
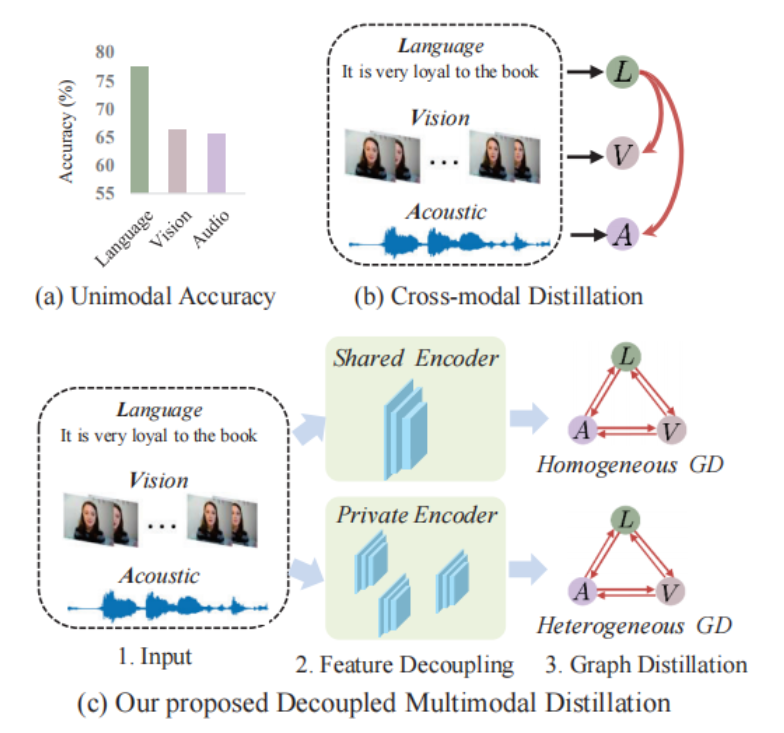
-
性能鸿沟:实验表明,语言模态在情感识别中的准确率通常远高于视觉和音频。
-
传统蒸馏的局限:常规方法通常需要预设蒸馏方向(如从强模态向弱模态),无法根据具体样本动态调整。
-
分布不匹配:直接在异质特征间进行蒸馏往往效果不佳。
二、 DMD 核心架构设计
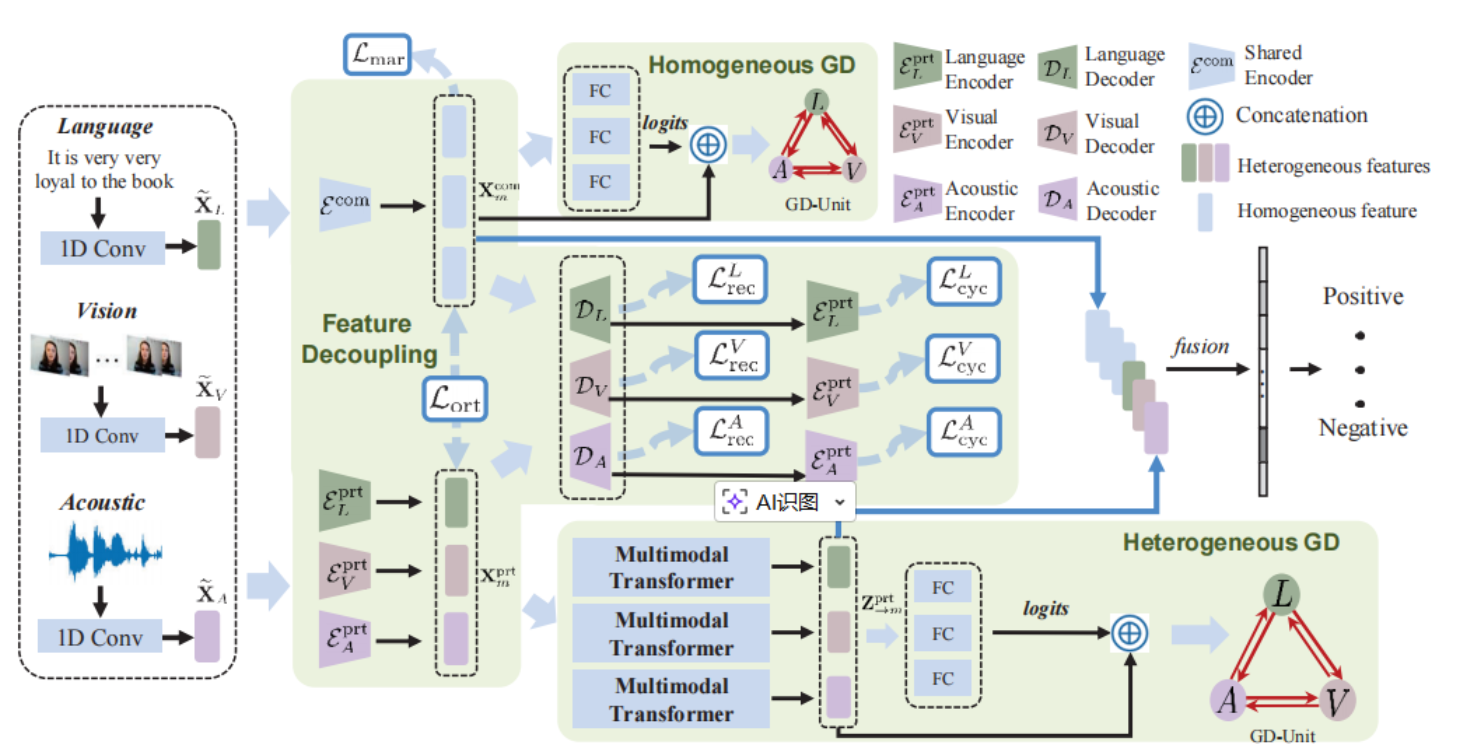
DMD 框架由三个关键阶段组成:特征解耦 、双路径图蒸馏 和自适应融合。
1. 多模态特征解耦 (Feature Decoupling)
模型通过共享编码器(Shared Encoder)和私有编码器(Private Encoder)将特征显式分解为两个子空间:
-
模态无关空间 (Modality-Irrelevant):捕获各模态间的共有情感特征。
-
模态特有空间 (Modality-Exclusive):保留各模态独特的表达细节。
-
自我回归机制:为了确保解耦彻底,DMD 引入了重构损失(Reconstruction Loss)和循环损失(Cycle Loss),通过自我回归的方式预测并验证解耦特征。
2. 双路径图蒸馏单元 (GD-Units)
DMD 针对不同的解耦空间设计了两套图蒸馏方案,其核心是包含动态蒸馏权重的图单元:
-
同质图蒸馏 (HomoGD):在分布差距已显著缩小的共有空间内,利用图结构直接进行跨模态语义关联的迁移。
-
异质图蒸馏 (HeteroGD) :针对分布差异较大的私有空间,引入 Multimodal Transformer 来建立语义对齐并桥接分布鸿沟,随后再进行知识蒸馏。
三、 实验结果:刷新 SOTA 指标
作者在两大主流 benchmark(CMU-MOSI 和 CMU-MOSEI)上进行了广泛测试:

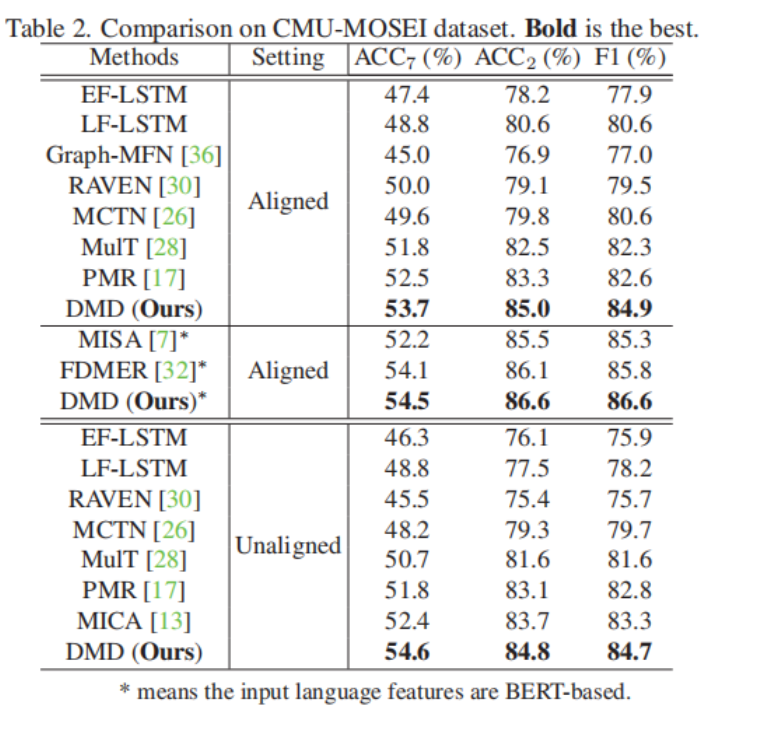
-
卓越性能:DMD 在对齐(Aligned)和非对齐(Unaligned)设置下均取得了优于 MISA、MulT 和 FDMER 等 SOTA 方法的准确率。
-
缩小模态差距:消融实验显示,特征解耦(FD)能显著提升单模态的性能,并缩小各模态间识别能力的标准差。
-
蒸馏权重的物理意义 :可视化发现,在 HomoGD 中,蒸馏主要由
语言 → 音频和语言 → 视觉主导,这符合语言模态包含最关键情感信息的直觉 。
四、 予枫的总结与思考
DMD 论文给我们的启发在于:
-
分而治之:与其直接融合复杂的异质特征,不如先通过解耦将"共性"与"个性"分开处理。
-
动态权重的必要性:利用图结构学习蒸馏强度,比手动设置规则更能捕获多模态间的细微交互。
-
Transformer 的桥梁作用:在异质空间中,利用注意力机制进行预对齐是实现高质量知识迁移的前提。
项目代码(开源) :https://github.com/mdswyz/DMD
博主结语:
如果您对论文中的"自我回归机制"或具体的"损失函数加权"有疑问,欢迎在评论区与我交流!
关于作者 : 💡 予枫 ,某高校在读研究生,专注于 Java 后端开发与多模态情感计算。💬 欢迎点赞、收藏、评论,你的反馈是我持续输出的最大动力!
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=9wrxwtlju1l
当前加入还有惊喜相送!