tfidf算法是一种文本特征提取方法。
tf:词频,单词在当前文档中的频率,局部重要性

idf:逆文档频率,单词在所有文档中的稀缺程度,全局重要性

tf-idf:以上两者的乘积,衡量单词在当前文档中的重要性和在所有文档中的特殊性
一个词在当前文档中出现次数越多(TF高),且在其它文档中出现越少(IDF高),它的TF-IDF值就越高,说明这个词对该文档越有代表性,也就是每一篇文章中的关键词。
我们平时所用的百度,谷歌等浏览器这些大型的搜索引擎就是这个原理。这些搜索引擎其实是一个巨大的爬虫系统,根据公开的域名爬取网页,提取网页中的关键词,形成一个自己的索引数据库,当我们输入搜索内容的时候,就先会在其数据库中搜索,然后再按照相关性排序呈现给我们。
一、TF-idf简单案列
采用简单且小型的数据内容,每一行当做一篇文章
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
inFile=open(r"D:\人工智能\机器学习算法\机器学习课件\10、TF-IDF\task2_1.txt",'r')
corpus=inFile.readlines()#当做一个语料库
vectorizer=TfidfVectorizer()#定义类对象,TfidfVectorizer是一个类
tfidf=vectorizer.fit_transform(corpus)#计算tfdif值,数据不用做预处理,可以直接被处理
print(tfidf)
wordlist=vectorizer.get_feature_names()#获取语料库所有单词
print(wordlist)
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)#tfidf.T.todense()转置,稀疏矩阵转为稠密矩阵
#转置的意思就是原本数据是六行十四列,转置之后就是十四行六列
print(df)
for j in range(len(corpus)):#对每一篇文章的词按照tfidf值降序排列
featurelist=df.iloc[:,j].to_list()#通过索引号第二列的内容并转换为列表
resdict={}#循环排列每一篇文章中单词的逆文档频率
for i in range(0,len(wordlist)):
resdict[wordlist[i]]=featurelist[i]
resdict=sorted(resdict.items(),key=lambda x:x[1],reverse=True)
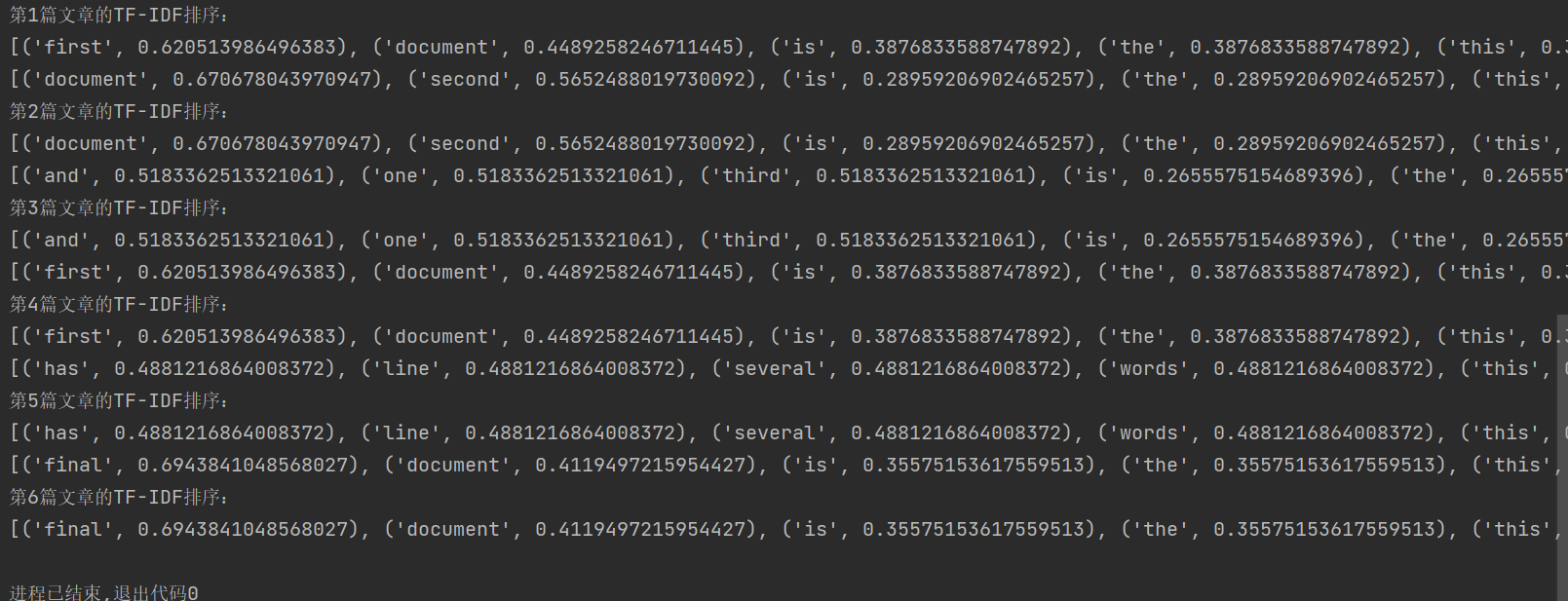
print(resdict)#这里是利用sorted方法进行排序需要注意:
第一个输出,输出的tfidf,括号(0,1)的意思是第0篇文章中的第一个词的tfidf值是0.4489258246711445
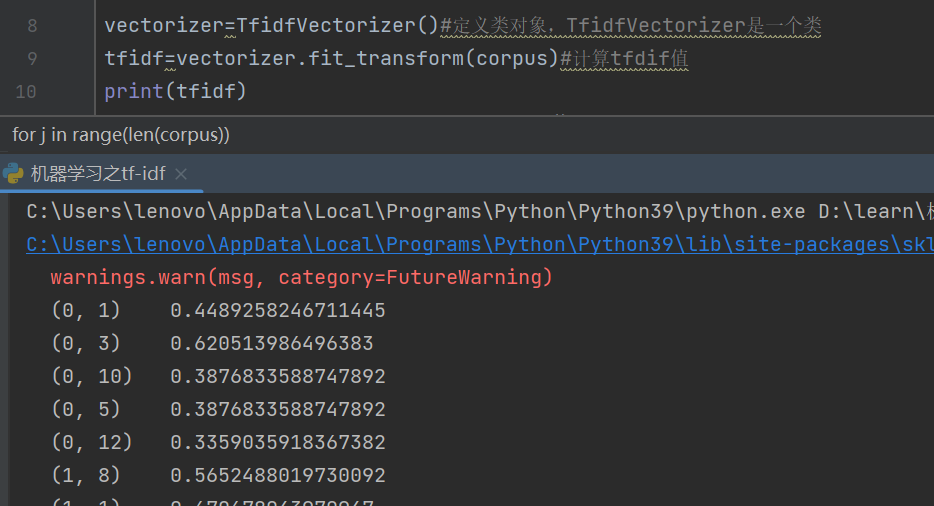
第0篇就是第一篇,但是第一个词并不是该篇文章的第一个词,而是整个语料库的中的第一个值,也就是我们第二个输出,第一个词就是'document',
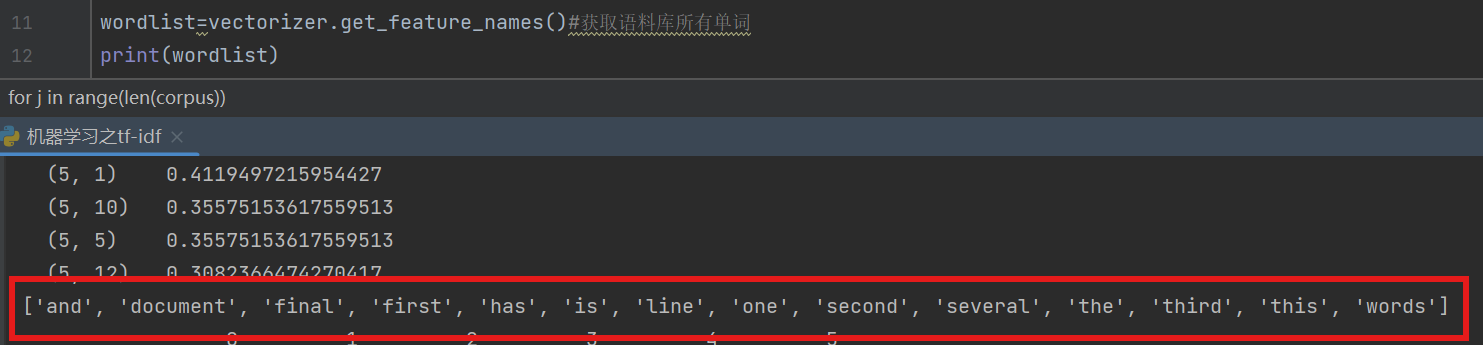
在代码中提到的稀疏矩阵,可以观察第一个输出的内容,只存该篇文章出现的词,tfidf为0的跳过
如果把原本某篇文章中没有但在语料库有的词也添上,他们的tfidf值为0,
例如这里会补上(0,0)tfidf=0 (0,2)tfidf=0......那就是稠密矩阵
第三个输出

最终结果(部分)
二、红楼梦案例
红楼梦txt是120回内容每章前有标题,分为上卷下卷
1.把红楼梦txt每一回分为一章
原文文本文件有一个红楼梦开头,并不是章节内容,所以把他单拿出来作为红楼梦开头txt文件
for循环进行遍历,每篇开头有标题,以'卷 第'作为寻找标题的判断,如果是标题就进行if中代码块,将标题作为章节文件名然后继续读取文件
第一次找到标题会运行flag=0的代码块,创建,之后读取的内容都写入第一个章节里,知道下一个标题被遍历到
但是这里原文件文本标题后有两行没用,一行是该章节的字数时间等信息,一行为空行,为了后续方便操作所以这两行不要写入文件,这里我使用了变量line_count=0记录当前是第几行,从第三行开始写入,当然也要满足每次新找到一个标题时,这个count要重新赋值为0
python
import os #python标准库,不需要安装。关于操作系统的库
if not os.path.exists('红楼梦\\红楼梦章节'):
os.makedirs('红楼梦\\红楼梦章节')
file = open(r"D:\人工智能\机器学习算法\机器学习课件\10、TF-IDF\红楼梦\红楼梦.txt",encoding='utf-8')#
flag = 0#用来标记当前是不是在第一次保存文件
line_count = 0
juan_file = open('.\红楼梦\红楼梦卷开头.txt','w',encoding='utf-8')
for line in file: #开始遍历整个红楼梦
if '卷 第' in line: #找到标题
line_count = 0
juan_name = line.strip() +'.txt'
path = os.path.join('.\\红楼梦\\红楼梦章节' , juan_name)#构建一个完整的路径
print(path)
if flag == 0: #判断是否 是第1次读取到 卷 第
juan_file = open(path,'w',encoding='utf-8') #创建第1个卷文件
flag = 1
else: #判断是否 不是第1次读取到 卷 第
juan_file.close() #关闭第1次及 上一次的文件对象
juan_file = open(path,'w',encoding='utf-8') #创建一个新的 卷文件
continue
if line_count < 2:#是因为原文中标题之后有一行为无用信息一行为空,我们从第三行才开始写入
line_count += 1
continue
else:
juan_file.write(line)#然后写入其他行
juan_file.close()
file.close()
2.开始分词,分成标准形式
1)分词需要用到jieba库,分词前需要有分词的词库
红楼梦词库.txt
2)文本内容比较多,减轻计算量,可以不计算标点、常见词、语气词等词,这些词不会影响结果,叫做停用词词库
stopwordCN.txt,这里stopword是表头
单列列表,获取该列所有值


python
'''导入库'''
import jieba
import os
import pandas as pd
import codecs
#加载自定义词库:让jieba正确识别红楼梦的专有名词
jieba.load_userdict(r"D:\人工智能\机器学习算法\机器学习课件\10、TF-IDF\红楼梦分析\红楼梦词库.txt")
#加载停用词:删除无意义的词和标点符号
stopwords = pd.read_csv(r"D:\人工智能\机器学习算法\机器学习课件\10、TF-IDF\红楼梦分析\StopwordsCN.txt",
encoding='utf8', engine='python',index_col=False)
stopwords_list=stopwords['stopword'].tolist()
'''读取文件内容'''
filepaths=[]#用来存储每个文件的完整路径
filecontents=[]#存储每个文件的内容
for root,dirs,files in os.walk('./红楼梦/红楼梦章节'):#遍历目录下所有文件
#遍历当前目录下的所有文件
for name in files:
filepath=os.path.join(root,name)#拼接完整文件路径
filepaths.append(filepath)#存储文件路径
f=codecs.open(filepath,'r','utf-8')#打开文件
filecontent=f.read()#读取文件全部内容
f.close()
filecontents.append(filecontent)#存储文件内容
#创建DataFrame表格:两列分别为文件路径和文件内容
corpos=pd.DataFrame({'filepath':filepaths,'filecontent':filecontents})
'''中文分词处理'''
segmented_text=[]#存储分词结果
for content in filecontents:
words=jieba.lcut(content)#使用jieba进行分词
#过滤停用词
filtered=[w for w in words
if len(w.strip())>1#过滤条件:长度>1,不在停用表中,至少包含一个中文字符
and w.strip() not in stopwords_list
and any('\u4e00' <=c <= '\u9fff' for c in w)]
segmented_text.append(filtered)#存储过滤后的分词结果
corpos['segmented']=segmented_text#将分词结果添加到dataframe表格,第三列分词结果列表
corpos['word_count']=[len(words) for words in segmented_text]#第四列,计算每篇的词数量
'''保存分词结果'''
output_txt = r"全部分词结果.txt"#定义输出文件路径
# 将分词结果合并:每章用空格连接词语,文章之间用换行分隔
all_segmented='\n'.join([' '.join(seg) for seg in corpos['segmented']])
# 写入文件
with open(output_txt, 'w', encoding='utf-8') as f:
f.write(all_segmented)标准形式:
这种形式就和一开始做的小语料库案例一样的形式,一行是一篇文章,这些文章的词库就组成了一个语料库

3.计算tfidf值,并排序
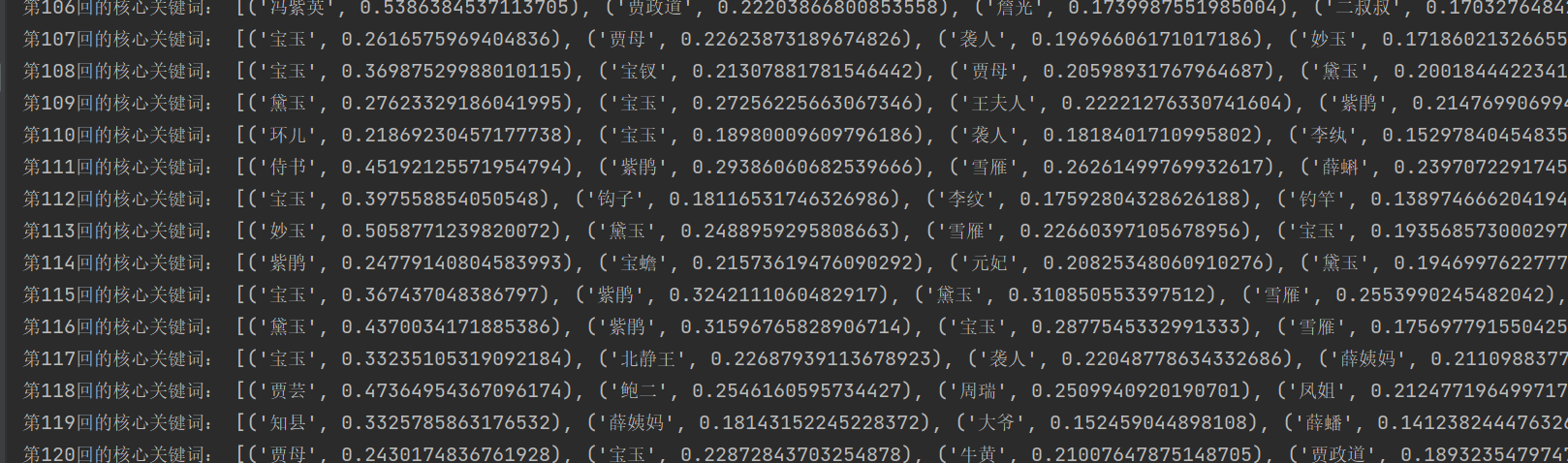
从大到小进行排序,可以根据输出结果得知该篇文章的关键词
python
from sklearn.feature_extraction.text import TfidfVectorizer#tfidf向量化工具
import pandas as pd#数据处理
inFile = open(r'D:\learn\全部分词结果.txt', 'r',encoding='utf-8')
corpus = inFile.readlines()#返回一个列表,列表一个元素就是一行内容,一行是一章
vectorizer = TfidfVectorizer() #类,转为TF-IDF的向量器
tfidf = vectorizer.fit_transform(corpus) #计算tfidf矩阵
wordlist = vectorizer.get_feature_names() #行是章节,列是所有词语
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)#tfidf.T.todense()#转置
for i in range(len(corpus)):#遍历每章
featurelist = df.iloc[:,i].to_list()#获取章的所有词的tfidf值
resdict = {} #创建字典
for j in range(0, len(wordlist)):
resdict[wordlist[j]] = featurelist[j] #[('贾宝玉',0.223),()]
#tfidf降序排列
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
print('第{}回的核心关键词:'.format(i+1),resdict[0:10])#打印前十个结果(部分):