Softsign Function - Derivatives and Gradients {导数和梯度}
- [1. Softsign Function](#1. Softsign Function)
-
- [1.1. Shape](#1.1. Shape)
- [2. Softsign Function - Derivatives and Gradients (导数和梯度)](#2. Softsign Function - Derivatives and Gradients (导数和梯度))
-
- [2.1. PyTorch `torch.abs(input: Tensor, *, out: OptionalTensor) -> Tensor`](#2.1. PyTorch
torch.abs(input: Tensor, *, out: Optional[Tensor]) -> Tensor) - [2.2. PyTorch `torch.abs(input: Tensor, *, out: OptionalTensor) -> Tensor`](#2.2. PyTorch
torch.abs(input: Tensor, *, out: Optional[Tensor]) -> Tensor) - [2.3. Python Softsign Function](#2.3. Python Softsign Function)
- [2.4. Python Softsign Function](#2.4. Python Softsign Function)
- [2.1. PyTorch `torch.abs(input: Tensor, *, out: OptionalTensor) -> Tensor`](#2.1. PyTorch
- References
1. Softsign Function
class torch.nn.Softsign(*args, **kwargs)
https://docs.pytorch.org/docs/stable/generated/torch.nn.Softsign.html
torch.nn.functional.softsign(input) -> Tensor
https://docs.pytorch.org/docs/stable/generated/torch.nn.functional.softsign.html
https://github.com/pytorch/pytorch/blob/v2.9.1/torch/nn/modules/activation.py
class torch.nn.Softsign(*args, **kwargs)
Applies the element-wise Softsign function.
sign [saɪn]
v. 签名;签署;叹息;预示
n. 符号;信号;表示;招牌The definition of the Softsign function:
SoftSign ( x ) = x 1 + ∣ x ∣ \text{SoftSign}(x) = \frac{x}{1 + |x|} SoftSign(x)=1+∣x∣x
Quotient Rule:
( u v ) = u ′ v − u v ′ v 2 \left( \frac{u}{v} \right) = \frac{u'v - uv'}{v^{2}} (vu)=v2u′v−uv′
The derivative of the Softsign function:
d y d x = f ′ ( x ) = d ( x 1 + ∣ x ∣ ) d x = d ( { x 1 + x , x ≥ 0 x 1 + ( − x ) , x < 0 ) d x = d ( { x 1 + x , x ≥ 0 x 1 − x , x < 0 ) d x = { 1 ( 1 + x ) 2 , x ≥ 0 1 ( 1 − x ) 2 , x < 0 = 1 ( 1 + ∣ x ∣ ) 2 \begin{aligned} \frac{dy}{dx} &= f'(x) \\ &= \frac{d ( \frac{x}{1 + |x|} ) }{dx} \\ &= \frac{d \left( \begin{cases} \frac{x}{1 + x}, & x \geq 0 \\ \frac{x}{1 + (-x)}, & x < 0 \\ \end{cases} \right) }{dx} \\ &= \frac{d \left( \begin{cases} \frac{x}{1 + x}, & x \geq 0 \\ \frac{x}{1 - x}, & x < 0 \\ \end{cases} \right) }{dx} \\ &= \begin{cases} \frac{1}{(1 + x)^{2}}, & x \geq 0 \\ \frac{1}{(1 - x)^{2}}, & x < 0 \\ \end{cases} \\ &= \frac{1}{(1 + |x|)^{2}} \\ \end{aligned} dxdy=f′(x)=dxd(1+∣x∣x)=dxd({1+xx,1+(−x)x,x≥0x<0)=dxd({1+xx,1−xx,x≥0x<0)={(1+x)21,(1−x)21,x≥0x<0=(1+∣x∣)21
The derivative f ′ ( x ) f'(x) f′(x) is always positive and stays within the range ( 0 , 1 ] (0,1] (0,1].
The derivative of the Softsign function:
d y d x = f ′ ( x ) = d ( x 1 + ∣ x ∣ ) d x = ( 1 ) ( 1 + ∣ x ∣ ) − ( x ) ( sgn ( x ) ) ( 1 + ∣ x ∣ ) 2 = 1 + ∣ x ∣ − x ∗ sgn ( x ) ( 1 + ∣ x ∣ ) 2 = 1 + ∣ x ∣ − ∣ x ∣ ( 1 + ∣ x ∣ ) 2 = 1 ( 1 + ∣ x ∣ ) 2 \begin{aligned} \frac{dy}{dx} &= f'(x) \\ &= \frac{d ( \frac{x}{1 + |x|} ) }{dx} \\ &= \frac{(1)(1 + |x|) - (x)(\text{sgn}(x))}{(1 + |x|)^{2}} \\ &= \frac{ 1 + |x| - x * \text{sgn}(x)}{(1 + |x|)^{2}} \\ &= \frac{ 1 + |x| - |x|}{(1 + |x|)^{2}} \\ &= \frac{1}{(1 + |x|)^{2}} \\ \end{aligned} dxdy=f′(x)=dxd(1+∣x∣x)=(1+∣x∣)2(1)(1+∣x∣)−(x)(sgn(x))=(1+∣x∣)21+∣x∣−x∗sgn(x)=(1+∣x∣)21+∣x∣−∣x∣=(1+∣x∣)21
- u = x u = x u=x
u ′ = 1 u' = 1 u′=1 - v = 1 + ∣ x ∣ v=1+|x| v=1+∣x∣
v ′ = sgn ( x ) v' = \text{sgn}(x) v′=sgn(x), where sgn ( x ) \text{sgn}(x) sgn(x) is 1 1 1 for x > 0 x>0 x>0, − 1 -1 −1 for x < 0 x<0 x<0, 0 0 0 for x = 0 x=0 x=0.
The following equations show the relationship between these two functions:
∣ x ∣ = x sgn ( x ) , {\displaystyle |x|=x\operatorname {sgn} (x),} ∣x∣=xsgn(x),
or
∣ x ∣ sgn ( x ) = x , {\displaystyle |x|\operatorname {sgn} (x)=x,} ∣x∣sgn(x)=x,
and for x ≠ 0 x \neq 0 x=0,
sgn ( x ) = ∣ x ∣ x = x ∣ x ∣ . {\displaystyle \operatorname {sgn} (x)={\frac {|x|}{x}}={\frac {x}{|x|}}.} sgn(x)=x∣x∣=∣x∣x.
1.1. Shape
- Input :
(*), where*means any number of dimensions. - Output :
(*), same shape as the input.
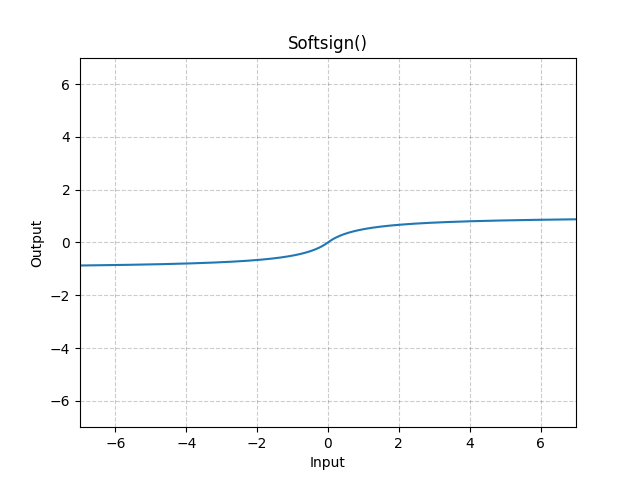
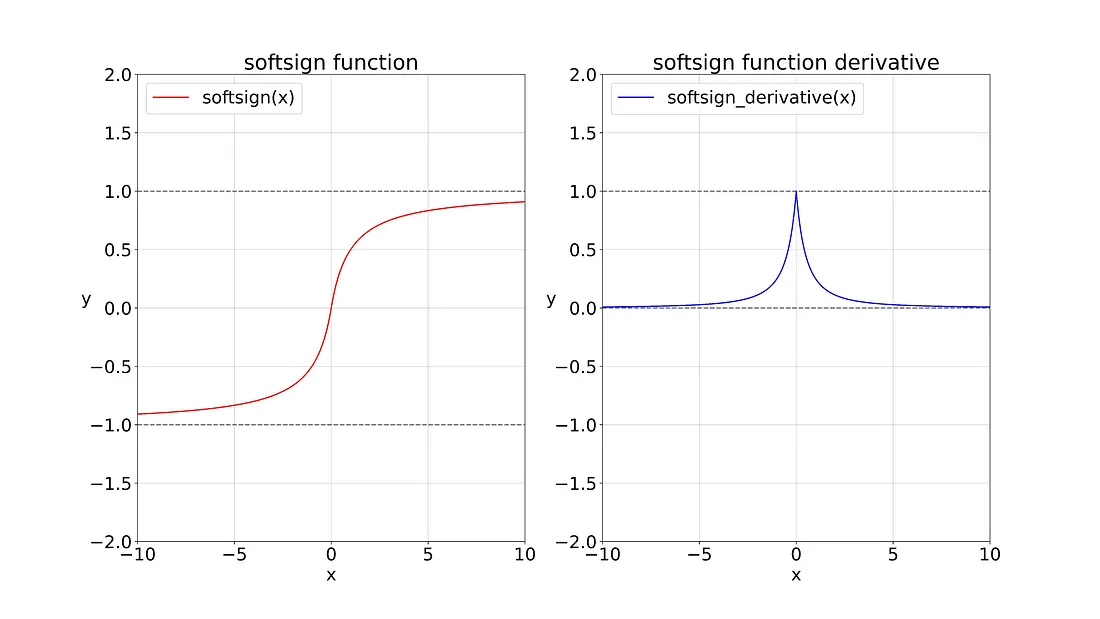
This is the graph for the Softsign function and its derivative.
# !/usr/bin/env python
# coding=utf-8
import torch
from matplotlib import pyplot as plt
def plot(X, Y=None, xlabel=None, ylabel=None, legend=[], xlim=None, ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5), axes=None):
"""
https://github.com/d2l-ai/d2l-en/blob/master/d2l/torch.py
"""
def has_one_axis(X): # True if X (tensor or list) has 1 axis
return ((hasattr(X, "ndim") and (X.ndim == 1)) or (isinstance(X, list) and (not hasattr(X[0], "__len__"))))
if has_one_axis(X): X = [X]
if Y is None:
X, Y = [[]] * len(X), X
elif has_one_axis(Y):
Y = [Y]
if len(X) != len(Y):
X = X * len(Y)
# Set the default width and height of figures globally, in inches.
plt.rcParams['figure.figsize'] = figsize
if axes is None:
axes = plt.gca() # Get the current Axes
# Clear the Axes
axes.cla()
for x, y, fmt in zip(X, Y, fmts):
axes.plot(x, y, fmt) if len(x) else axes.plot(y, fmt)
axes.set_xlabel(xlabel), axes.set_ylabel(ylabel) # Set the label for the x/y-axis
axes.set_xscale(xscale), axes.set_yscale(yscale) # Set the x/y-axis scale
axes.set_xlim(xlim), axes.set_ylim(ylim) # Set the x/y-axis view limits
if legend:
axes.legend(legend) # Place a legend on the Axes
# Configure the grid lines
axes.grid()
plt.show()
plt.savefig("yongqiang.png", transparent=True) # Save the current figure
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.nn.functional.softsign(x)
plot(x.detach(), y.detach(), 'x', 'Softsign(x)', figsize=(5, 2.5))
# Clear out previous gradients
# x.grad.data.zero_()
y.backward(torch.ones_like(x), retain_graph=True)
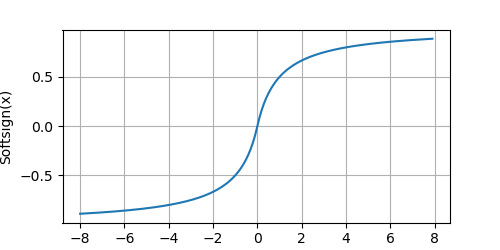
plot(x.detach(), x.grad, 'x', 'gradient of Softsign(x)', figsize=(5, 2.5))The Softsign function:
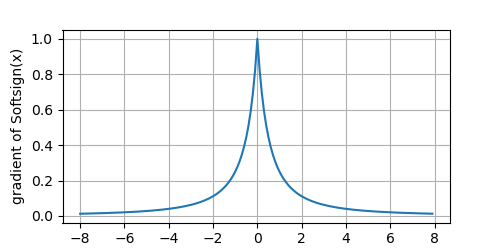
The derivative of the Softsign function:
2. Softsign Function - Derivatives and Gradients (导数和梯度)
Notes
- Element-wise Multiplication (Hadamard Product) (
*operator ornumpy.multiply()): Multiplies corresponding elements of two arrays that must have the same shape (or be broadcastable to a common shape). - Matrix Multiplication (Dot Product) (
@operator ornumpy.matmul()ornumpy.dot()): Performs the standard linear algebra operation that requires specific dimension compatibility rules. (e.g., the number of columns in the first array must match the number of rows in the second).
2.1. PyTorch torch.abs(input: Tensor, *, out: Optional[Tensor]) -> Tensor
# !/usr/bin/env python
# coding=utf-8
import torch
import torch.nn as nn
torch.set_printoptions(precision=6)
input = torch.tensor([-1.5, 0.0, 1.5, 0.5, -2.0, 3.0], dtype=torch.float, requires_grad=True)
print(f"input.requires_grad: {input.requires_grad}, input.shape: {input.shape}")
forward_output = torch.nn.functional.softsign(input)
print(f"\nforward_output.shape: {forward_output.shape}")
print(f"Forward Pass Output:\n{forward_output}")
forward_output.backward(torch.ones_like(input), retain_graph=True)
print(f"\nbackward_output.shape: {input.grad.shape}")
print(f"Backward Pass Output:\n{input.grad}")
/home/yongqiang/miniconda3/bin/python /home/yongqiang/quantitative_analysis/softsign.py
input.requires_grad: True, input.shape: torch.Size([6])
forward_output.shape: torch.Size([6])
Forward Pass Output:
tensor([-0.600000, 0.000000, 0.600000, 0.333333, -0.666667, 0.750000],
grad_fn=<DivBackward0>)
backward_output.shape: torch.Size([6])
Backward Pass Output:
tensor([0.160000, 1.000000, 0.160000, 0.444444, 0.111111, 0.062500])
Process finished with exit code 02.2. PyTorch torch.abs(input: Tensor, *, out: Optional[Tensor]) -> Tensor
# !/usr/bin/env python
# coding=utf-8
import torch
import torch.nn as nn
torch.set_printoptions(precision=6)
input = torch.tensor([[-1.5, 0.0, 1.5], [0.5, -2.0, 3.0]], dtype=torch.float, requires_grad=True)
print(f"input.requires_grad: {input.requires_grad}, input.shape: {input.shape}")
forward_output = torch.nn.functional.softsign(input)
print(f"\nforward_output.shape: {forward_output.shape}")
print(f"Forward Pass Output:\n{forward_output}")
forward_output.backward(torch.ones_like(input), retain_graph=True)
print(f"\nbackward_output.shape: {input.grad.shape}")
print(f"Backward Pass Output:\n{input.grad}")
/home/yongqiang/miniconda3/bin/python /home/yongqiang/quantitative_analysis/softsign.py
input.requires_grad: True, input.shape: torch.Size([2, 3])
forward_output.shape: torch.Size([2, 3])
Forward Pass Output:
tensor([[-0.600000, 0.000000, 0.600000],
[ 0.333333, -0.666667, 0.750000]], grad_fn=<DivBackward0>)
backward_output.shape: torch.Size([2, 3])
Backward Pass Output:
tensor([[0.160000, 1.000000, 0.160000],
[0.444444, 0.111111, 0.062500]])
Process finished with exit code 02.3. Python Softsign Function
# !/usr/bin/env python
# coding=utf-8
import numpy as np
# numpy.multiply:
# Multiply arguments element-wise
# Equivalent to x1 * x2 in terms of array broadcasting
class SoftsignLayer:
"""
A class to represent the Softsign layer for a neural network.
"""
def __init__(self):
# Cache the input for the backward pass
self.input = None
def forward(self, input):
"""
Forward Pass: f(x) = x / (1 + |x|)
Maps input values to the range [-1, 1]
Computes the element-wise absolute value
"""
self.input = input
output = input / (1 + np.abs(input))
return output
def backward(self, upstream_gradient):
"""
Backward Pass (Backpropagation): f'(x) = 1 / (1 + |x|)^2
The total gradient is the element-wise product of the upstream
gradient and the derivative of the Log.
"""
softsign_derivative = 1 / (1 + np.abs(self.input)) ** 2
print(f"abs_derivative.shape: {softsign_derivative.shape}")
print(f"Softsign Derivative:\n{softsign_derivative}")
# upstream_gradient: the gradient of the loss with respect to the output
# Computes the gradient of the loss with respect to the input (dL/dx)
# Apply the chain rule: multiply the derivative by the upstream gradient
# dL/dx = dL/dy * dy/dx = upstream_gradient * f'(x)
downstream_gradient = upstream_gradient * softsign_derivative
return downstream_gradient
layer = SoftsignLayer()
input = np.array([-1.5, 0.0, 1.5, 0.5, -2.0, 3.0], dtype=np.float32)
# Forward pass
forward_output = layer.forward(input)
print(f"\nforward_output.shape: {forward_output.shape}")
print(f"Forward Pass Output:\n{forward_output}")
# Backward pass
upstream_gradient = np.ones(forward_output.shape) * 0.1
backward_output = layer.backward(upstream_gradient)
print(f"\nbackward_output.shape: {backward_output.shape}")
print(f"Backward Pass Output:\n{backward_output}")
/home/yongqiang/miniconda3/bin/python /home/yongqiang/quantitative_analysis/softsign.py
forward_output.shape: (6,)
Forward Pass Output:
[-0.6 0. 0.6 0.33333334 -0.6666667 0.75 ]
abs_derivative.shape: (6,)
Softsign Derivative:
[0.16 1. 0.16 0.44444445 0.11111111 0.0625 ]
backward_output.shape: (6,)
Backward Pass Output:
[0.016 0.1 0.016 0.04444444 0.01111111 0.00625 ]
Process finished with exit code 02.4. Python Softsign Function
# !/usr/bin/env python
# coding=utf-8
import numpy as np
# numpy.multiply:
# Multiply arguments element-wise
# Equivalent to x1 * x2 in terms of array broadcasting
class SoftsignLayer:
"""
A class to represent the Softsign layer for a neural network.
"""
def __init__(self):
# Cache the input for the backward pass
self.input = None
def forward(self, input):
"""
Forward Pass: f(x) = x / (1 + |x|)
Maps input values to the range [-1, 1]
Computes the element-wise absolute value
"""
self.input = input
output = input / (1 + np.abs(input))
return output
def backward(self, upstream_gradient):
"""
Backward Pass (Backpropagation): f'(x) = 1 / (1 + |x|)^2
The total gradient is the element-wise product of the upstream
gradient and the derivative of the Log.
"""
softsign_derivative = 1 / (1 + np.abs(self.input)) ** 2
print(f"abs_derivative.shape: {softsign_derivative.shape}")
print(f"Softsign Derivative:\n{softsign_derivative}")
# upstream_gradient: the gradient of the loss with respect to the output
# Computes the gradient of the loss with respect to the input (dL/dx)
# Apply the chain rule: multiply the derivative by the upstream gradient
# dL/dx = dL/dy * dy/dx = upstream_gradient * f'(x)
downstream_gradient = upstream_gradient * softsign_derivative
return downstream_gradient
layer = SoftsignLayer()
input = np.array([[-1.5, 0.0, 1.5], [0.5, -2.0, 3.0]], dtype=np.float32)
# Forward pass
forward_output = layer.forward(input)
print(f"\nforward_output.shape: {forward_output.shape}")
print(f"Forward Pass Output:\n{forward_output}")
# Backward pass
upstream_gradient = np.ones(forward_output.shape) * 0.1
backward_output = layer.backward(upstream_gradient)
print(f"\nbackward_output.shape: {backward_output.shape}")
print(f"Backward Pass Output:\n{backward_output}")
/home/yongqiang/miniconda3/bin/python /home/yongqiang/quantitative_analysis/softsign.py
forward_output.shape: (2, 3)
Forward Pass Output:
[[-0.6 0. 0.6 ]
[ 0.33333334 -0.6666667 0.75 ]]
abs_derivative.shape: (2, 3)
Softsign Derivative:
[[0.16 1. 0.16 ]
[0.44444445 0.11111111 0.0625 ]]
backward_output.shape: (2, 3)
Backward Pass Output:
[[0.016 0.1 0.016 ]
[0.04444444 0.01111111 0.00625 ]]
Process finished with exit code 0References
1 Yongqiang Cheng (程永强), https://yongqiang.blog.csdn.net/
2 动手学深度学习, https://zh.d2l.ai/index.html
3 Deep Learning Tutorials, https://neuralthreads.medium.com/i-was-not-satisfied-by-any-deep-learning-tutorials-online-37c5e9f4bea1
4 Gradient boosting performs gradient descent, https://explained.ai/gradient-boosting/descent.html
5 Matrix calculus, https://en.wikipedia.org/wiki/Matrix_calculus
6 Artificial Inteligence, https://leonardoaraujosantos.gitbook.io/artificial-inteligence