文章目录
在2010年左右,有一个支持包非常盛行,叫做 selenium,可以可视化看到获取的过程,相较于其他的方法,其自动化程序更高,但是到2020年左右的时候,来了一个更效率的家伙,叫做 playwright,这下直接让数据的获取变得更智能和可视化了,它直接将浏览器的内核打包进程序,也可以像VBA录制宏一直接写数据获取过程的代码,非常方便,话不多说,直接介绍!
一、获取与安装
主要要进行的一个是支持包的安装,另一个就是浏览器的安装,支持包安装直接通过pip语法就行:
shell
pip install playwright安装后的目录在你环境变量的site-packages下,比如我的是anaconda环境,下载后的支持包存放在D:\anaconda\Lib\site-packages\playwright\driver下,除了这一步,我们还需要安装一下浏览器内核,通过以下命令:
shell
playwright install当然上面的这句话会一次性下载3个以上不同的内核,如果你只需要特定的内核,比如最常用的,可以使用如下命令:
shell
playwright install chromium你也可以把最后的这个内核改成 firefox 或者 webkit,也是支持的,唯一要注意的就是确保playwright所在的路径已经在你的环境变量中,如果没有的话,playwright就不能直接写,而是要写上完整的路径
二、基本使用方法
一般playwright都采用同步方式进行获取,我们下面进行简单的演示,sync_playwright 在这里就支持我们进行各种同步的获取,下面这段代码演示了我们进入豆瓣top250的页面,并打印页面标题,最后退出:
python
from playwright.sync_api import sync_playwright
p = sync_playwright().start() # 启动 playwright driver 进程
browser = p.chromium.launch(headless=True) # 启动浏览器,返回 Browser 类型对象
# 创建新页面,返回 Page 类型对象
page = browser.new_page()
page.goto("https://movie.douban.com/top250") # 访问的网址
print(page.title()) # 打印网页标题栏
browser.close() # 关闭浏览器
p.stop() # 关闭 playwright driver 进程p.chromium.launch 这一句就是我们使用的浏览器内核,和我们第一步下载的是哪个有关系,如果你下载的是其他的,那对应做修改,headless=True代表无头模式打开,不显示浏览器,如果你想要使用playwright 之外的浏览器内核,可以通过以下方式进行自定义设置:
python
# 启动浏览器,返回 Browser 类型对象,通过executable_path指定本地自己安装的内核
browser = p.chromium.launch(headless=True,
executable_path="C:\Program Files\Google\Chrome\Application\chrome.exe") 同时由于使用的是同步过程,因此在playwright 的使用中,一般不建议通过time.sleep来设置页面延时,其有自己内置的方法wait_for_timeout,如下方所示:
python
# time.sleep(2) # 不建议这么写,因为底层是通过异步实现的
page.wait_for_timeout(2000) # 建议这么写,内部自己支持的方法三、录制过程转为代码
在开始的时候,我就介绍了playwright具有自己的一套成熟的录制功能,我们只需要在命令行输入以下命令,就可以一边操作页面,右边的代码框会用代码的形式同步记录你的每一步操作,这样就很方便:
shell
playwright codegen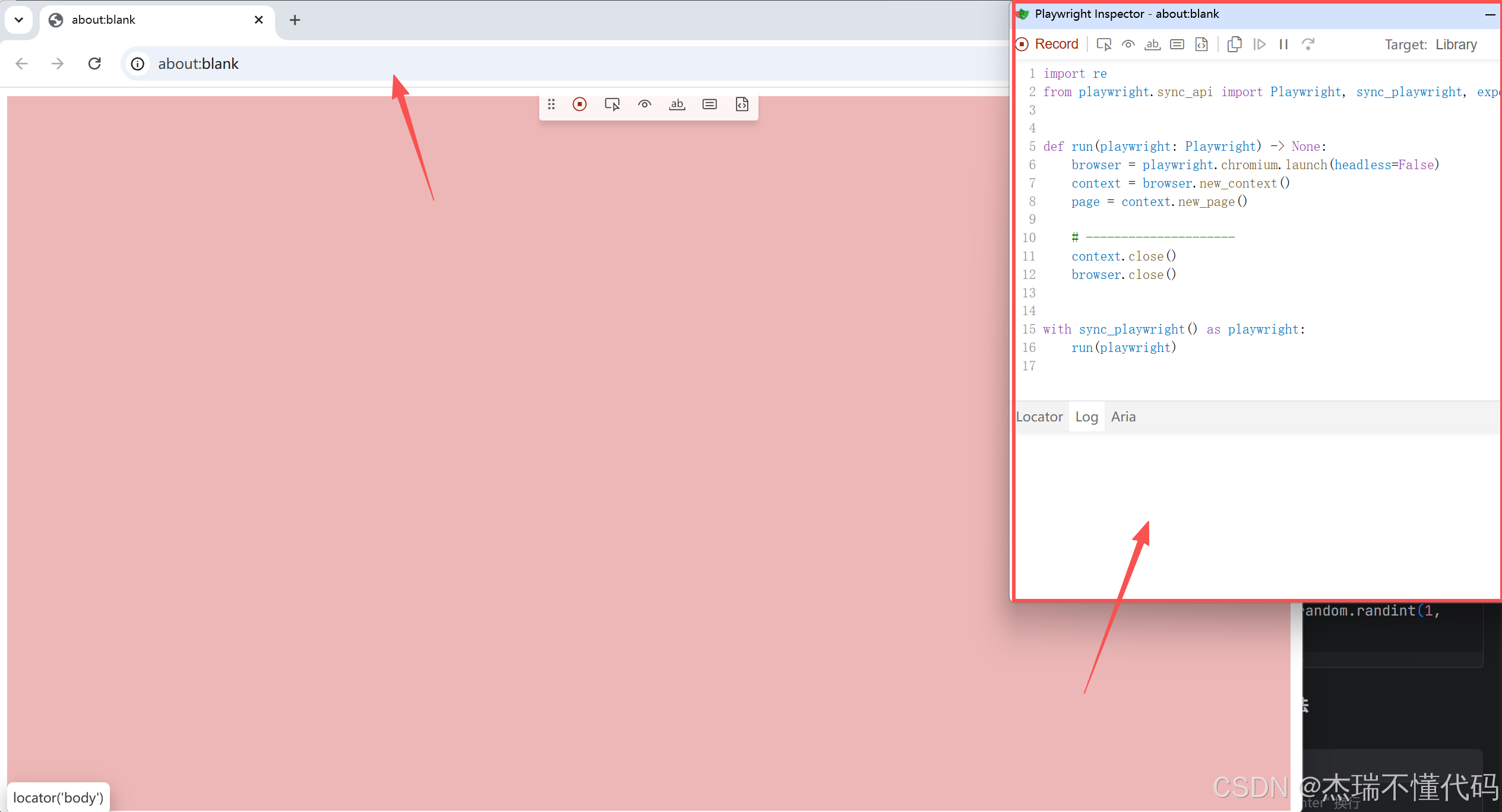
在代码的录制框中,可以记录到你对页面的点击,填充等大部分功能,但是也有一些部分是没法记录的,因此想要通过这个方法完全满足自己的要求,可能不大行,但是其提供了一种更便捷的代码编写方式。
四、代码记录和追踪功能
我们通过以下代码段来演示此追踪功能,注意如果要使用追踪功能,需要在page 创建前多用一个new_context的步骤,同时page 由new_context 创建,context.tracing.start 中主要是三个参数,分别用于记录:
screenshots=True,启用截图记录,在测试执行的每个步骤自动捕获屏幕截图snapshots=True,启用快照记录,记录 DOM 快照,包括页面结构、元素状态等sources=True,启用源代码记录,方便后续动作和代码一一对应
最后的stop中填入保存的路径即可,一般是一个zip文件
python
from playwright.sync_api import sync_playwright
import time
p = sync_playwright().start() # 启动 playwright driver 进程
browser = p.chromium.launch(headless=True) # 启动浏览器,返回 Browser 类型对象
context = browser.new_context()
context.tracing.start(screenshots=True, snapshots=True, sources=True)
page = context.new_page() # 注意:这里是 context.new_page(),不是 browser.new_page()
page.goto("https://movie.douban.com/top250") # 访问的网址
page.get_by_placeholder("搜索电影、电视剧、综艺、影人").fill("星")
page.get_by_role("button", name="搜索").click()
context.tracing.stop(path="trace.zip")
browser.close() # 关闭浏览器
p.stop() # 关闭 playwright driver 进程对于这个zip文件,我们由两种方法来读取,首先是通过pywright的官方网页(点击可跳转),将我们的文件拖入即可,另外一种方法就是通过命令行输入以下命令实现,当然需要保证你的记录文件路径正确(我这是同目录):
shell
playwright show-trace trace.zip拖入之后你就可以发现这里打开了这样一个界面,界面中清晰记录了你每次的动作,和代码的对应关系以及每个动作时候的截图,可以通过截图上方的Action/Before/After切换查看动作 执行时,执行前,执行后 的页面状态。
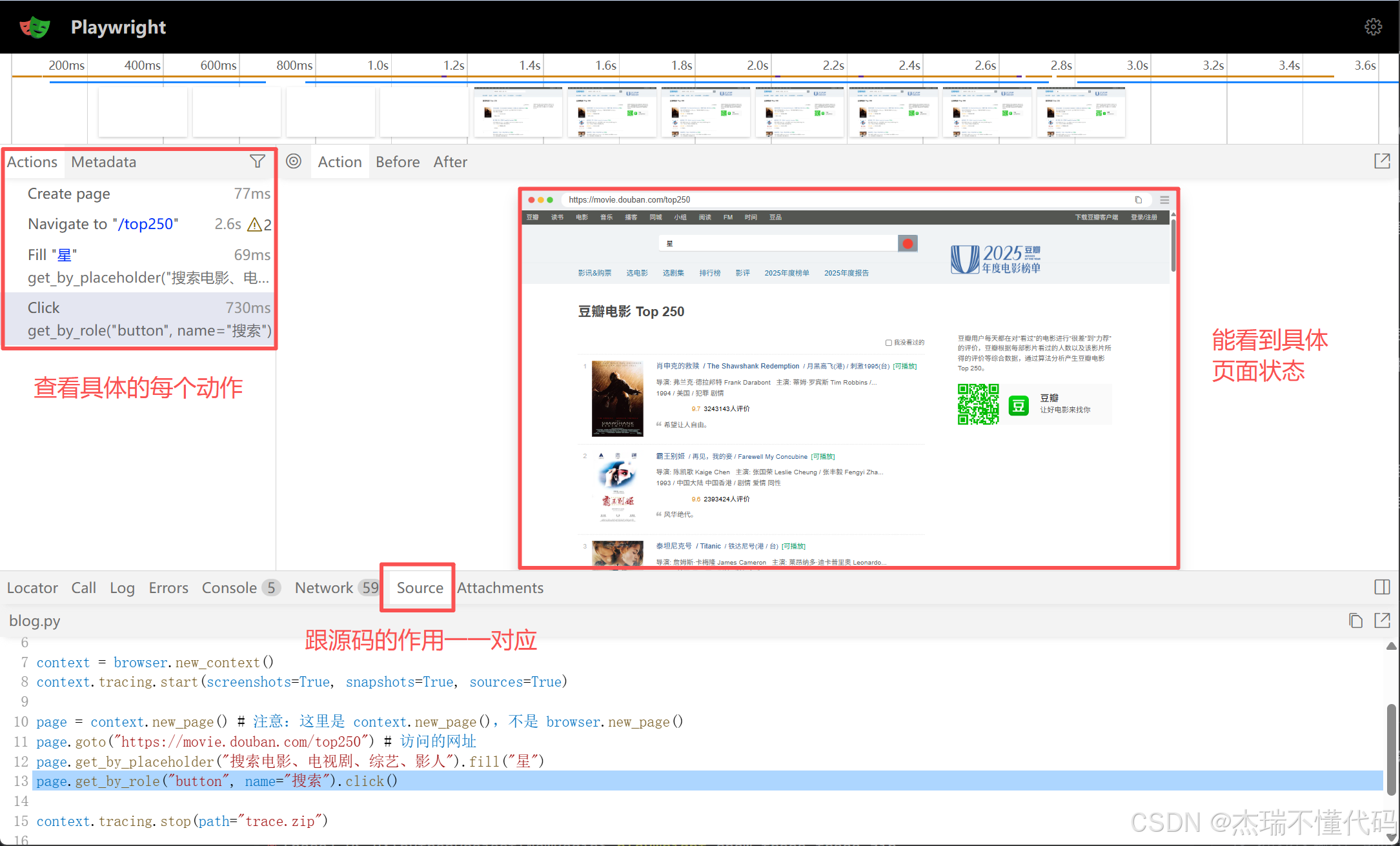
在我们上面写的这一段代码中,就是访问了网站,然后在顶部搜索栏键入了 "星" 这个关键字,然后点击搜索,从上面的过程中清晰可以看见这三步动作的具体情况,可谓非常直观!
上面只是告诉你如何初步入门使用playwright,后面我会分享更多实用的干货,我是不懂代码的杰瑞学长,我们下期再见!
如果觉得文章对你有帮助,欢迎点赞 + 收藏 + 关注,一起进步!