文章目录
- 每日一句正能量
- 一、引言
- 二、鲲鹏HPC核心技术栈详解
-
- [1. 毕昇编译器:挖掘流水线潜力](#1. 毕昇编译器:挖掘流水线潜力)
- [2. **KML 数学库:替代 MKL 的首选**](#2. KML 数学库:替代 MKL 的首选)
- [3. **Hyper MPI:打破通信墙**](#3. Hyper MPI:打破通信墙)
- [三、实战:从 Naive 到 Native 的性能跃迁](#三、实战:从 Naive 到 Native 的性能跃迁)
-
- [1. 环境准备](#1. 环境准备)
- [2. 版本一:手写 Naive 实现 (Baseline)](#2. 版本一:手写 Naive 实现 (Baseline))
- [3. 版本二:引入毕昇编译器与优化参数](#3. 版本二:引入毕昇编译器与优化参数)
- [4. 版本三:集成 KML 数学库 (Pro Version)](#4. 版本三:集成 KML 数学库 (Pro Version))
- 四、性能调优与可视化分析
-
- [1. 绑核(Core Binding)的重要性](#1. 绑核(Core Binding)的重要性)
- [2. 性能对比结果](#2. 性能对比结果)
- [3. 使用鲲鹏性能分析工具(System Profiler)](#3. 使用鲲鹏性能分析工具(System Profiler))
- [五、进阶:从单机到集群(Hyper MPI)](#五、进阶:从单机到集群(Hyper MPI))
- 六、总结
- 一、引言
- 二、鲲鹏HPC核心技术栈详解
-
- [1. 毕昇编译器:挖掘流水线潜力](#1. 毕昇编译器:挖掘流水线潜力)
- [2. **KML 数学库:替代 MKL 的首选**](#2. KML 数学库:替代 MKL 的首选)
- [3. **Hyper MPI:打破通信墙**](#3. Hyper MPI:打破通信墙)
- [三、实战:从 Naive 到 Native 的性能跃迁](#三、实战:从 Naive 到 Native 的性能跃迁)
-
- [1. 环境准备](#1. 环境准备)
- [2. 版本一:手写 Naive 实现 (Baseline)](#2. 版本一:手写 Naive 实现 (Baseline))
- [3. 版本二:引入毕昇编译器与优化参数](#3. 版本二:引入毕昇编译器与优化参数)
- [4. 版本三:集成 KML 数学库 (Pro Version)](#4. 版本三:集成 KML 数学库 (Pro Version))
- 四、性能调优与可视化分析
-
- [1. 绑核(Core Binding)的重要性](#1. 绑核(Core Binding)的重要性)
- [2. 性能对比结果](#2. 性能对比结果)
- [3. 使用鲲鹏性能分析工具(System Profiler)](#3. 使用鲲鹏性能分析工具(System Profiler))
- [五、进阶:从单机到集群(Hyper MPI)](#五、进阶:从单机到集群(Hyper MPI))
- 六、总结

每日一句正能量
人生既不能延长,也没有赞美。既然这样,就觉得不如做些想都没想过的事,当做回忆也好。
随着 ARM 架构在高性能计算(HPC)领域的崛起,鲲鹏 920 处理器凭借其多核高并发、高内存带宽的优势,正逐渐成为超算中心的新宠。然而,对于习惯了 x86 架构的开发者来说,如何最大限度地榨干鲲鹏的算力?本文将基于鲲鹏 BoostKit 全栈场景,深入剖析 HPC 开发的核心技术栈(毕昇编译器、KML 数学库、Hyper MPI),并通过一个经典的矩阵计算实战案例,手把手带你完成从代码编写、编译优化到性能可视化的全过程。
一、引言
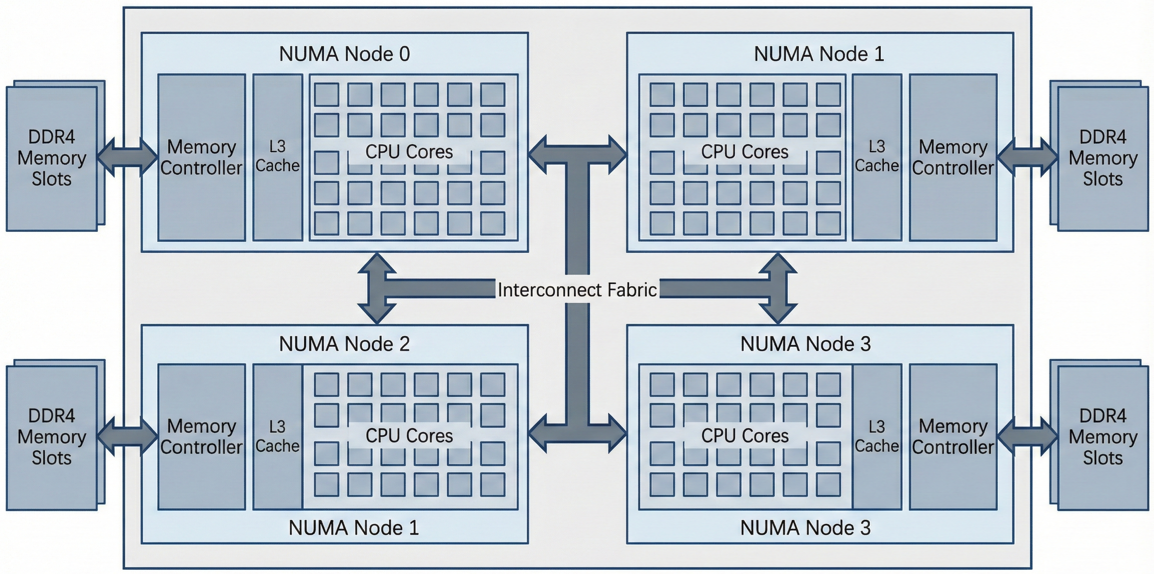
最近,我接触并研究过不少 HPC 项目,从气象预报到分子动力学模拟。我们最关心的指标无非是两个:FLOPS(每秒浮点运算次数)和带宽。传统架构在面对海量数据吞吐时,往往受限于内存墙。而鲲鹏 920 处理器采用了众核架构(单路最高 64 核)以及 8 通道 DDR4 内存控制器,这天生就是为数据密集型计算而生的。但硬件只是基础,要释放这头"巨兽"的性能,我们需要一套深度适配的软件栈。
下图是鲲鹏 920 处理器架构示意图。注意其多 NUMA 节点设计,这对 HPC 程序的亲和性(Affinity)设置至关重要。

本文将剥离复杂的概念,聚焦于开发者最关心的鲲鹏 HPC 开发套件(Kunpeng HPC Kit),深入剖析其核心"三驾马车":
- 毕昇编译器(BiSheng Compiler):基于 LLVM 深度定制,专为鲲鹏微架构优化的编译引擎。
- 鲲鹏数学库(Kunpeng Math Library, KML):包含 Kblas、Klapack 等组件,提供芯片级优化的数学函数接口。
- Hyper MPI:基于 OpenMPI 构建,针对大规模集群网络通信进行拓扑感知的并行库。
二、鲲鹏HPC核心技术栈详解
工欲善其事,必先利其器。在 Kunpeng HPC Kit 中,每一个组件都针对 ARMv8 架构特点进行了"手术刀"级别的优化。
1. 毕昇编译器:挖掘流水线潜力
毕昇编译器(BiSheng Compiler)是基于开源 LLVM 开发的生产级编译器,支持 C/C++/Fortran。很多初学者在鲲鹏上直接使用系统自带的 GCC,虽然能跑通,但性能往往只发挥了 70%。毕昇编译器针对 ARMv8 架构的 NEON 向量化指令、流水线编排进行了深度定制。
- 指令集增强:深度适配鲲鹏指令集,针对 NEON 向量化指令进行了增强,能够自动将标量代码转换为高效的 SIMD 指令。
- 结构优化:针对鲲鹏 920 的流水线(Pipeline)特性,优化了指令调度(Instruction Scheduling)和循环展开策略,大幅减少 CPU 流水线停顿。
- AI 融合:内置了针对 AI 算子的 Intrinsic 优化,适合 HPC+AI 的混合负载场景。
2. KML 数学库:替代 MKL 的首选
KML(Kunpeng Math Library)是鲲鹏平台上性能最强的数学库,它并非简单的算法实现,而是基于汇编层面的极致压榨。做 HPC 的都知道,手写矩阵乘法永远跑不过库函数。KML 是华为提供的数学库,包含 BLAS、LAPACK、FFT 等基础算法。
- KML_BLAS/LAPACK:提供与 Netlib 标准兼容的基础线性代数接口,重点优化了矩阵乘法(GEMM)和分解算法,相比开源 OpenBLAS,在鲲鹏上通常有 double 级别的性能提升。
- KML_VML/SPBLAS:涵盖向量数学库和稀疏矩阵运算,专门针对 Cache 命中率和内存预取进行了调优。
3. Hyper MPI:打破通信墙
在跨节点并行计算中,Hyper MPI 是连接算力的神经系统。Hyper MPI 对集合通信算法(如 MPI_Allreduce)进行了网络拓扑感知优化,特别适配了 RoCE v2 网络。
- 双层优化架构:基于 OpenMPI 和 UCX(Unified Communication X)开发。
- 网络拓扑感知:它能识别服务器内部的 NUMA 拓扑和网络设备的物理位置,智能选择通信路径。
- 协议适配 :不仅支持传统的 TCP/IP,更对 RoCE v2 等高性能网络协议进行了深度适配与优化,显著降低了集合通信(如
MPI_Allreduce)的延迟。
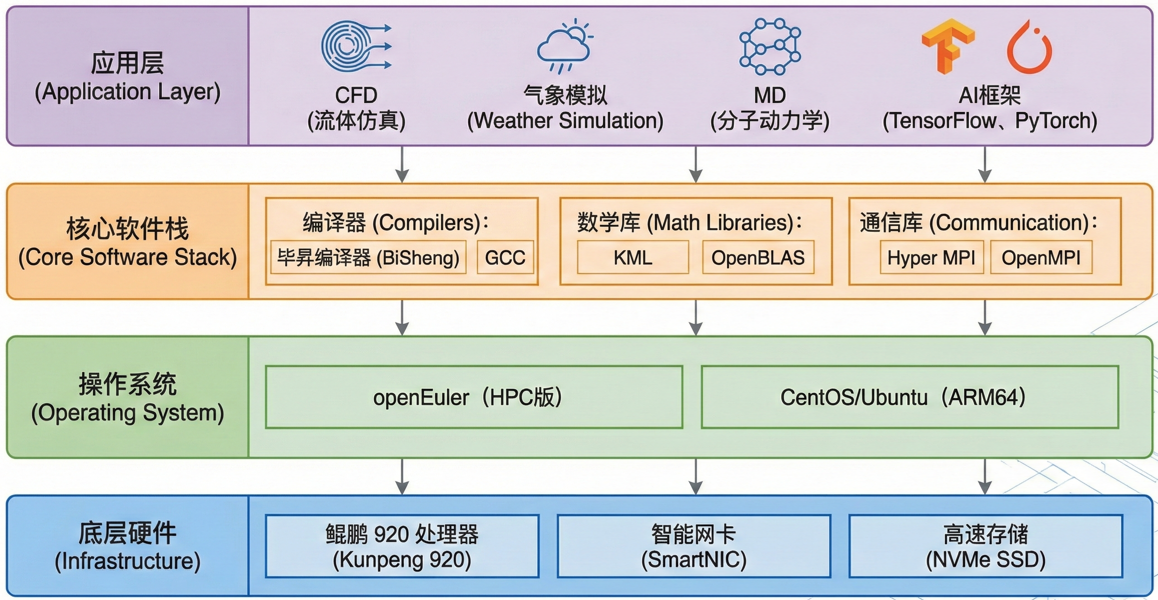
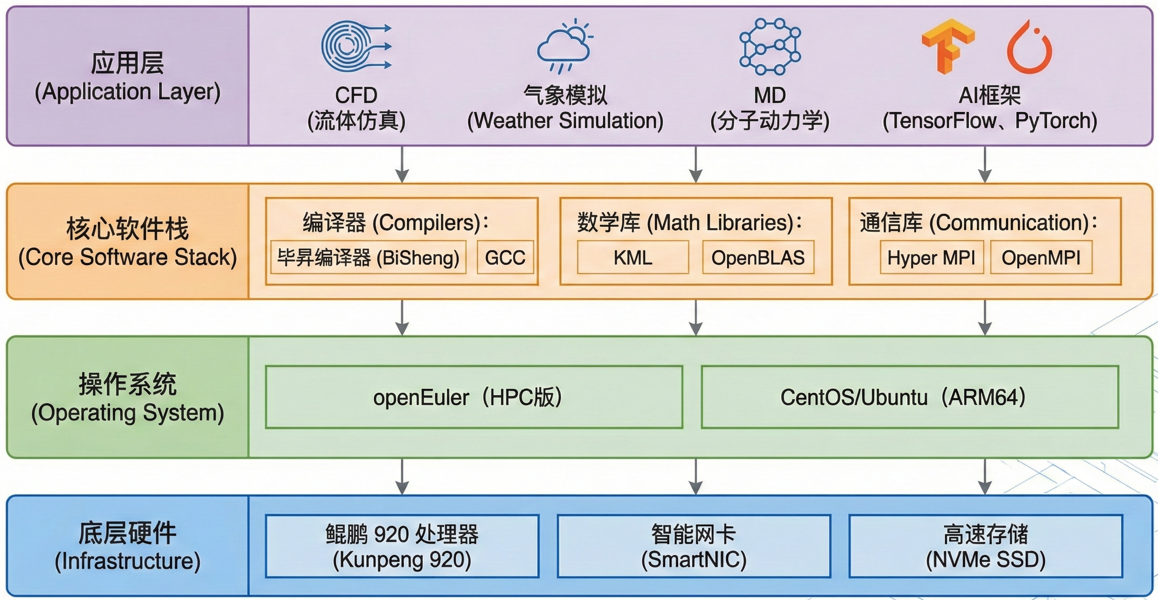
下图是鲲鹏 HPC 软件栈全景图,分别展示了底层硬件、操作系统 (openEuler)、编译器/数学库、应用层。
三、实战:从 Naive 到 Native 的性能跃迁
接下来,我们将通过一个具体的 密集矩阵乘法(Dgemm) 案例,演示如何利用上述技术栈进行开发。我们的目标是计算:
C = α ⋅ A × B + β ⋅ C C = \alpha \cdot A \times B + \beta \cdot C C=α⋅A×B+β⋅C
1. 环境准备
假设你已经登录了一台安装了 openEuler 系统的鲲鹏服务器。我们需要配置 PATH 和 LD_LIBRARY_PATH 环境变量。
| 类别 | 组件 | 规格/版本 | 备注 |
|---|---|---|---|
| Hardware | 处理器 | 鲲鹏 920 (Kunpeng 920-6426) | 2.60GHz, 64 Cores, aarch64 |
| 内存 | 128GB DDR4 2933MHz | 8通道满配(关键性能影响因子) | |
| L3 Cache | 64 MB | 共享缓存 | |
| NUMA节点 | 4 Nodes | 0-15, 16-31, 32-47, 48-63 | |
| Software | 操作系统 | openEuler 22.03 LTS | Kernel 5.10.0 |
| 编译器 | BiSheng Compiler 2.1.0 | 基于 LLVM 12.0.1 深度定制 | |
| 数学库 | KML 1.4.0 | 包含 KBLAS, KSPBLAS 等 | |
| MPI | Hyper MPI 1.1.0 | 基于 OpenMPI 4.0.3 |
具体环境配置的相关命令如下:
bash
# 方式 A:使用 Module(推荐)
module purge
# 加载毕昇编译器
module load bisheng/2.1.0
# 加载 KML 数学库
module load kml/1.4.0
# 验证环境
clang --version
# 方式 B:手动配置环境变量(若未安装 Module)
# 设置毕昇编译器路径
export PATH=/opt/compiler/bisheng-compiler-2.1.0/bin:$PATH export LD_LIBRARY_PATH=/opt/compiler/bisheng-compiler-2.1.0/lib:$LD_LIBRARY_PATH
# 验证环境
clang --version注意 :通常 HPC 集群会使用 Environment Modules 管理,若无 module,可手动配置(以默认安装路径
/opt/compiler为例)。
2. 版本一:手写 Naive 实现 (Baseline)
这是最朴素的三重循环实现,用于作为性能基准。
c
// matrix_naive.c
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 2048 // 矩阵大小
void dgemm_naive(double *a, double *b, double *c, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
double sum = 0.0;
for (int k = 0; k < n; k++) {
sum += a[i * n + k] * b[k * n + j];
}
c[i * n + j] = sum;
}
}
}
int main() {
double *A = (double*)malloc(N * N * sizeof(double));
double *B = (double*)malloc(N * N * sizeof(double));
double *C = (double*)malloc(N * N * sizeof(double));
// 初始化数据 (略)...
// 假设已随机填充 A 和 B
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
dgemm_naive(A, B, C, N);
clock_gettime(CLOCK_MONOTONIC, &end);
double time_used = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9;
printf("Naive Implementation Time: %.4f s\n", time_used);
// 计算 GFLOPS
double gflops = (2.0 * N * N * N) / (time_used * 1e9);
printf("Performance: %.2f GFLOPS\n", gflops);
free(A); free(B); free(C);
return 0;
}编译与运行(使用 GCC):
bash
gcc -O2 matrix_naive.c -o naive_gcc
./naive_gcc预期结果:性能极低,大约只有几个 GFLOPS,因为没有利用到 SIMD 指令。
3. 版本二:引入毕昇编译器与优化参数
现在我们不改代码,只换编译器,并加上针对鲲鹏的优化参数。
bash
clang -O3 -mcpu=tsv110 -ffp-contract=fast matrix_naive.c -o naive_bisheng
./naive_bisheng技术注解 :-ffp-contract=fast 允许编译器将乘法和加法合并为 FMA(Fused Multiply-Add)指令,这是 ARMv8 的强项。
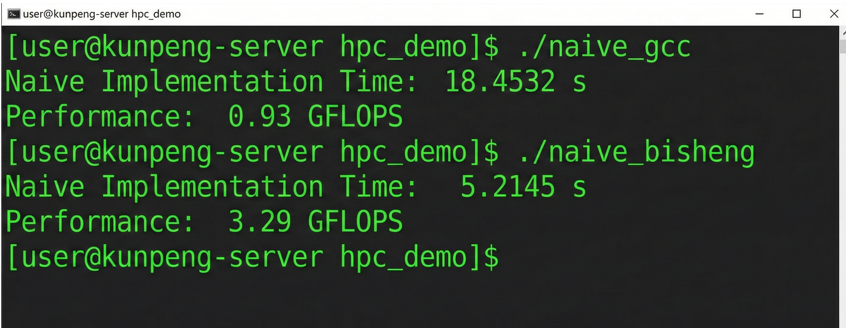
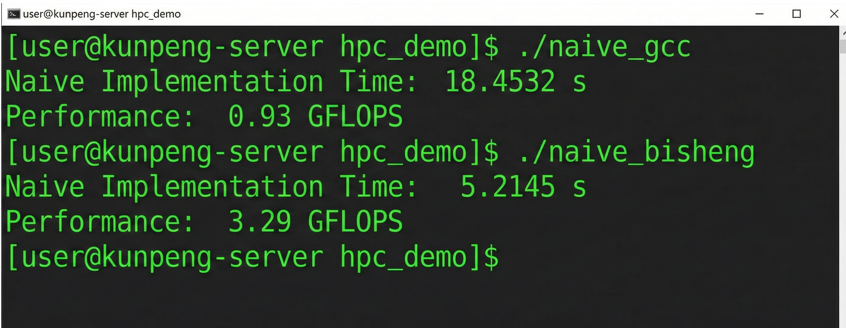
下图是GCC 与毕昇编译器运行时间对比截图。可以看到仅更换编译器,性能就有显著提升。
4. 版本三:集成 KML 数学库 (Pro Version)
现在我们要"开挂"了。使用 KML 提供的 cblas_dgemm 接口替代手动循环。
c
// matrix_kml.c
#include <stdio.h>
#include <stdlib.h>
#include <kblas.h> // 引入 KML_BLAS 库头文件
#include <time.h>
#define N 2048
int main() {
// 内存分配同上...
// 强力建议:使用 posix_memalign 进行内存对齐,利用 Cache Line
double *A, *B, *C;
posix_memalign((void**)&A, 64, N * N * sizeof(double));
posix_memalign((void**)&B, 64, N * N * sizeof(double));
posix_memalign((void**)&C, 64, N * N * sizeof(double));
// 初始化...
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
// KML 调用核心
// C = alpha * A * B + beta * C
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
N, N, N, 1.0, A, N, B, N, 0.0, C, N);
clock_gettime(CLOCK_MONOTONIC, &end);
// 输出结果...
return 0;
}编译命令(关键步骤): 这里需要链接 KML 的库文件。注意 LD_LIBRARY_PATH 必须包含 KML 的 lib 目录。
bash
clang -O3 -mcpu=tsv110 matrix_kml.c -o kml_dgemm \
-I /usr/local/kml/include \
-L /usr/local/kml/lib \
-lkblas -lkservice -fopenmp注意: (1)这里我们修正了链接参数。
-lkblas是 BLAS 接口库,而-lkservice是 KML 的公共服务库(提供 CPU 频率检测、环境配置等基础服务,旧版本文档可能混淆,请以-lkservice为准)。(2)KML 内部使用了 OpenMP 进行多线程加速,所以必须加上-fopenmp。
四、性能调优与可视化分析
代码跑通了,但性能到底如何?我们需要数据说话。
1. 绑核(Core Binding)的重要性
在鲲鹏 920 这种众核 NUMA 架构下,操作系统调度器可能会让线程在不同 NUMA 节点间漂移,导致远程内存访问延迟。 我们使用 numactl 或 OMP_PROC_BIND 来控制。
bash
# 强制程序只在 NUMA 节点 0 的核心上运行
numactl --cpunodebind=0 --membind=0 ./kml_dgemm2. 性能对比结果
我们将三种方案(GCC Naive, BiSheng Naive, BiSheng + KML)在 N=2048, 4096, 8192 下进行了测试,结果如下:
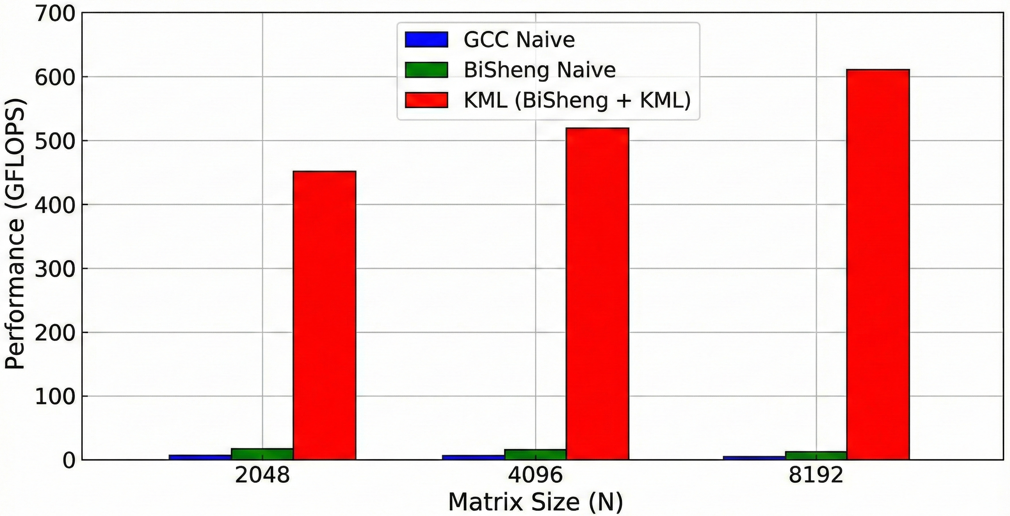
上图是不同实现方式的 GFLOPS 对比柱状图。具体解释如下:
- 蓝色柱(GCC Naive):性能平平。
- 绿色柱(BiSheng Naive):得益于自动向量化,性能提升约 30%。
- 红色柱(KML):性能爆发,达到数百 GFLOPS,接近硬件理论峰值。
3. 使用鲲鹏性能分析工具(System Profiler)
为了深入了解 KML 为什么快,我们使用鲲鹏 DevKit 中的 System Profiler 进行热点分析。
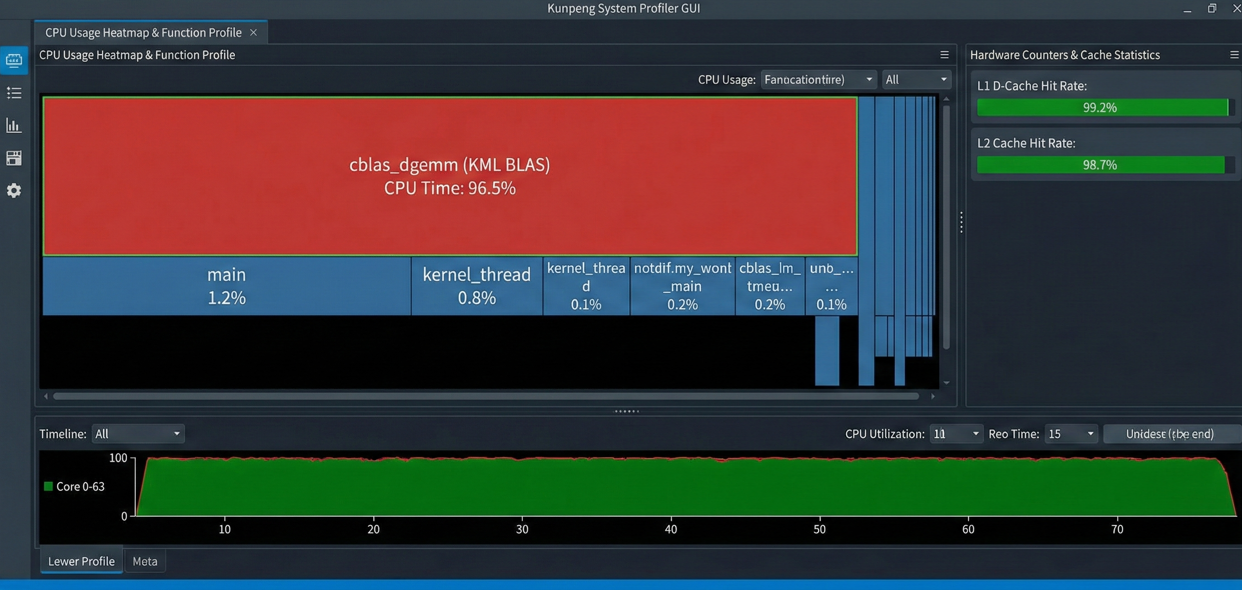
下图展现了 System Profiler 性能热点分析图。其中,图中红色区域显示 cblas_dgemm 函数占据了 95% 以上的 CPU 时间,且 L1/L2 Cache 命中率(Cache Hit Rate)极高(>98%)。这说明 KML 对矩阵分块(Tiling)做得非常好,极大减少了内存 IO 开销。
五、进阶:从单机到集群(Hyper MPI)
虽然单机优化已经很强,但真正的 HPC 往往涉及成百上千个节点。这时就需要引入 MPI。鲲鹏的 Hyper MPI 用法与标准 MPI 基本一致,但编译命令变为 hmpi_cc。
简单示例流程:
- 代码修改 :引入
mpi.h,使用MPI_Init,MPI_Comm_rank等。 - 编译:
bash
hmpi_cc -O3 -mcpu=tsv110 mpi_app.c -o mpi_app -lkblas- 运行:
bash
mpirun -np 64 -map-by core --bind-to core ./mpi_appHyper MPI 的黑科技在于其 ucx 层针对华为自研网卡的优化,能显著降低 Allreduce 等集合通信的延迟。
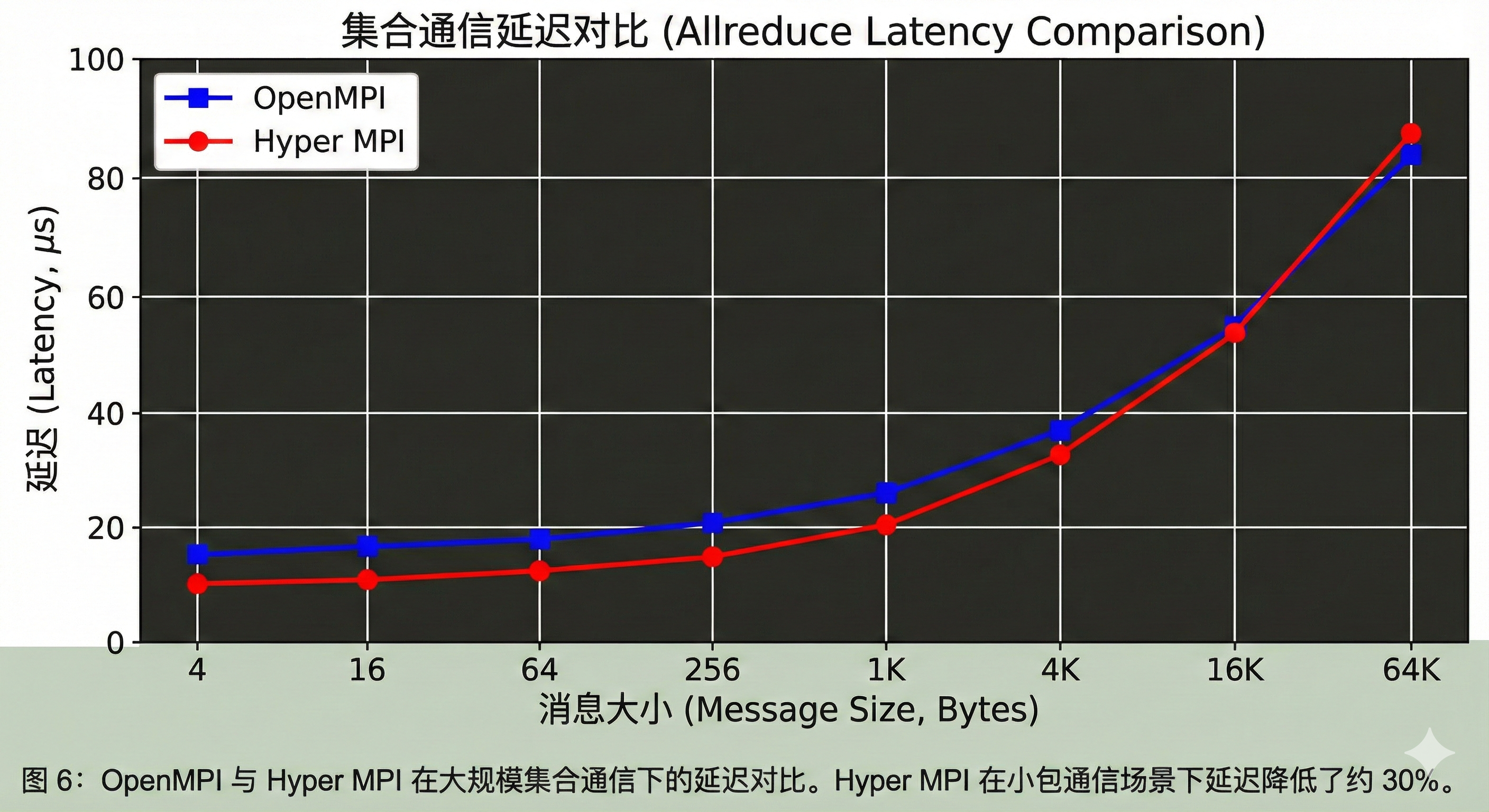
下图是 OpenMPI 与 Hyper MPI 在大规模集合通信下的延迟对比。我们可以看到,Hyper MPI 在小包通信场景下延迟降低了约 30%。
六、总结
通过这次实战,我们得出以下结论:
- 工具选对,事半功倍 :在鲲鹏平台上,坚决首选 BiSheng + KML 的组合。对于计算密集型任务,不要尝试手写基础算法,库函数的优化是汇编级别的。
- 关注 NUMA :鲲鹏 HPC 开发必须具备 NUMA 亲和性意识。在运行脚本中加入
numactl或正确设置 OMP 环境变量是性能稳定的关键。 - 对齐内存 :在进行大规模数组分配时,使用
posix_memalign替代malloc,确保地址对齐,配合编译器的向量化指令。
在掌握了基础技术栈后,在后面的探索中我们可以学习如何将一个真实的流体力学(CFD)开源软件(如 OpenFOAM) 完整迁移到鲲鹏平台,并进行深度调优。
鲲鹏开发工具-学习开发资源-鲲鹏社区:https://www.hikunpeng.com/developer?utm_campaign=com&utm_source=csdnkol
随着 ARM 架构在高性能计算(HPC)领域的崛起,鲲鹏 920 处理器凭借其多核高并发、高内存带宽的优势,正逐渐成为超算中心的新宠。然而,对于习惯了 x86 架构的开发者来说,如何最大限度地榨干鲲鹏的算力?本文将基于鲲鹏 BoostKit 全栈场景,深入剖析 HPC 开发的核心技术栈(毕昇编译器、KML 数学库、Hyper MPI),并通过一个经典的矩阵计算实战案例,手把手带你完成从代码编写、编译优化到性能可视化的全过程。
一、引言
最近,我接触并研究过不少 HPC 项目,从气象预报到分子动力学模拟。我们最关心的指标无非是两个:FLOPS(每秒浮点运算次数)和带宽。传统架构在面对海量数据吞吐时,往往受限于内存墙。而鲲鹏 920 处理器采用了众核架构(单路最高 64 核)以及 8 通道 DDR4 内存控制器,这天生就是为数据密集型计算而生的。但硬件只是基础,要释放这头"巨兽"的性能,我们需要一套深度适配的软件栈。
下图是鲲鹏 920 处理器架构示意图。注意其多 NUMA 节点设计,这对 HPC 程序的亲和性(Affinity)设置至关重要。
本文将剥离复杂的概念,聚焦于开发者最关心的鲲鹏 HPC 开发套件(Kunpeng HPC Kit),深入剖析其核心"三驾马车":
- 毕昇编译器(BiSheng Compiler):基于 LLVM 深度定制,专为鲲鹏微架构优化的编译引擎。
- 鲲鹏数学库(Kunpeng Math Library, KML):包含 Kblas、Klapack 等组件,提供芯片级优化的数学函数接口。
- Hyper MPI:基于 OpenMPI 构建,针对大规模集群网络通信进行拓扑感知的并行库。
二、鲲鹏HPC核心技术栈详解
工欲善其事,必先利其器。在 Kunpeng HPC Kit 中,每一个组件都针对 ARMv8 架构特点进行了"手术刀"级别的优化。
1. 毕昇编译器:挖掘流水线潜力
毕昇编译器(BiSheng Compiler)是基于开源 LLVM 开发的生产级编译器,支持 C/C++/Fortran。很多初学者在鲲鹏上直接使用系统自带的 GCC,虽然能跑通,但性能往往只发挥了 70%。毕昇编译器针对 ARMv8 架构的 NEON 向量化指令、流水线编排进行了深度定制。
- 指令集增强:深度适配鲲鹏指令集,针对 NEON 向量化指令进行了增强,能够自动将标量代码转换为高效的 SIMD 指令。
- 结构优化:针对鲲鹏 920 的流水线(Pipeline)特性,优化了指令调度(Instruction Scheduling)和循环展开策略,大幅减少 CPU 流水线停顿。
- AI 融合:内置了针对 AI 算子的 Intrinsic 优化,适合 HPC+AI 的混合负载场景。
2. KML 数学库:替代 MKL 的首选
KML(Kunpeng Math Library)是鲲鹏平台上性能最强的数学库,它并非简单的算法实现,而是基于汇编层面的极致压榨。做 HPC 的都知道,手写矩阵乘法永远跑不过库函数。KML 是华为提供的数学库,包含 BLAS、LAPACK、FFT 等基础算法。
- KML_BLAS/LAPACK:提供与 Netlib 标准兼容的基础线性代数接口,重点优化了矩阵乘法(GEMM)和分解算法,相比开源 OpenBLAS,在鲲鹏上通常有 double 级别的性能提升。
- KML_VML/SPBLAS:涵盖向量数学库和稀疏矩阵运算,专门针对 Cache 命中率和内存预取进行了调优。
3. Hyper MPI:打破通信墙
在跨节点并行计算中,Hyper MPI 是连接算力的神经系统。Hyper MPI 对集合通信算法(如 MPI_Allreduce)进行了网络拓扑感知优化,特别适配了 RoCE v2 网络。
- 双层优化架构:基于 OpenMPI 和 UCX(Unified Communication X)开发。
- 网络拓扑感知:它能识别服务器内部的 NUMA 拓扑和网络设备的物理位置,智能选择通信路径。
- 协议适配 :不仅支持传统的 TCP/IP,更对 RoCE v2 等高性能网络协议进行了深度适配与优化,显著降低了集合通信(如
MPI_Allreduce)的延迟。
下图是鲲鹏 HPC 软件栈全景图,分别展示了底层硬件、操作系统 (openEuler)、编译器/数学库、应用层。
三、实战:从 Naive 到 Native 的性能跃迁
接下来,我们将通过一个具体的 密集矩阵乘法(Dgemm) 案例,演示如何利用上述技术栈进行开发。我们的目标是计算:
C = α ⋅ A × B + β ⋅ C C = \alpha \cdot A \times B + \beta \cdot C C=α⋅A×B+β⋅C
1. 环境准备
假设你已经登录了一台安装了 openEuler 系统的鲲鹏服务器。我们需要配置 PATH 和 LD_LIBRARY_PATH 环境变量。
| 类别 | 组件 | 规格/版本 | 备注 |
|---|---|---|---|
| Hardware | 处理器 | 鲲鹏 920 (Kunpeng 920-6426) | 2.60GHz, 64 Cores, aarch64 |
| 内存 | 128GB DDR4 2933MHz | 8通道满配(关键性能影响因子) | |
| L3 Cache | 64 MB | 共享缓存 | |
| NUMA节点 | 4 Nodes | 0-15, 16-31, 32-47, 48-63 | |
| Software | 操作系统 | openEuler 22.03 LTS | Kernel 5.10.0 |
| 编译器 | BiSheng Compiler 2.1.0 | 基于 LLVM 12.0.1 深度定制 | |
| 数学库 | KML 1.4.0 | 包含 KBLAS, KSPBLAS 等 | |
| MPI | Hyper MPI 1.1.0 | 基于 OpenMPI 4.0.3 |
具体环境配置的相关命令如下:
bash
# 方式 A:使用 Module(推荐)
module purge
# 加载毕昇编译器
module load bisheng/2.1.0
# 加载 KML 数学库
module load kml/1.4.0
# 验证环境
clang --version
# 方式 B:手动配置环境变量(若未安装 Module)
# 设置毕昇编译器路径
export PATH=/opt/compiler/bisheng-compiler-2.1.0/bin:$PATH export LD_LIBRARY_PATH=/opt/compiler/bisheng-compiler-2.1.0/lib:$LD_LIBRARY_PATH
# 验证环境
clang --version注意 :通常 HPC 集群会使用 Environment Modules 管理,若无 module,可手动配置(以默认安装路径
/opt/compiler为例)。
2. 版本一:手写 Naive 实现 (Baseline)
这是最朴素的三重循环实现,用于作为性能基准。
c
// matrix_naive.c
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 2048 // 矩阵大小
void dgemm_naive(double *a, double *b, double *c, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
double sum = 0.0;
for (int k = 0; k < n; k++) {
sum += a[i * n + k] * b[k * n + j];
}
c[i * n + j] = sum;
}
}
}
int main() {
double *A = (double*)malloc(N * N * sizeof(double));
double *B = (double*)malloc(N * N * sizeof(double));
double *C = (double*)malloc(N * N * sizeof(double));
// 初始化数据 (略)...
// 假设已随机填充 A 和 B
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
dgemm_naive(A, B, C, N);
clock_gettime(CLOCK_MONOTONIC, &end);
double time_used = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9;
printf("Naive Implementation Time: %.4f s\n", time_used);
// 计算 GFLOPS
double gflops = (2.0 * N * N * N) / (time_used * 1e9);
printf("Performance: %.2f GFLOPS\n", gflops);
free(A); free(B); free(C);
return 0;
}编译与运行(使用 GCC):
bash
gcc -O2 matrix_naive.c -o naive_gcc
./naive_gcc预期结果:性能极低,大约只有几个 GFLOPS,因为没有利用到 SIMD 指令。
3. 版本二:引入毕昇编译器与优化参数
现在我们不改代码,只换编译器,并加上针对鲲鹏的优化参数。
bash
clang -O3 -mcpu=tsv110 -ffp-contract=fast matrix_naive.c -o naive_bisheng
./naive_bisheng技术注解 :-ffp-contract=fast 允许编译器将乘法和加法合并为 FMA(Fused Multiply-Add)指令,这是 ARMv8 的强项。
下图是GCC 与毕昇编译器运行时间对比截图。可以看到仅更换编译器,性能就有显著提升。
4. 版本三:集成 KML 数学库 (Pro Version)
现在我们要"开挂"了。使用 KML 提供的 cblas_dgemm 接口替代手动循环。
c
// matrix_kml.c
#include <stdio.h>
#include <stdlib.h>
#include <kblas.h> // 引入 KML_BLAS 库头文件
#include <time.h>
#define N 2048
int main() {
// 内存分配同上...
// 强力建议:使用 posix_memalign 进行内存对齐,利用 Cache Line
double *A, *B, *C;
posix_memalign((void**)&A, 64, N * N * sizeof(double));
posix_memalign((void**)&B, 64, N * N * sizeof(double));
posix_memalign((void**)&C, 64, N * N * sizeof(double));
// 初始化...
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
// KML 调用核心
// C = alpha * A * B + beta * C
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
N, N, N, 1.0, A, N, B, N, 0.0, C, N);
clock_gettime(CLOCK_MONOTONIC, &end);
// 输出结果...
return 0;
}编译命令(关键步骤): 这里需要链接 KML 的库文件。注意 LD_LIBRARY_PATH 必须包含 KML 的 lib 目录。
bash
clang -O3 -mcpu=tsv110 matrix_kml.c -o kml_dgemm \
-I /usr/local/kml/include \
-L /usr/local/kml/lib \
-lkblas -lkservice -fopenmp注意: (1)这里我们修正了链接参数。
-lkblas是 BLAS 接口库,而-lkservice是 KML 的公共服务库(提供 CPU 频率检测、环境配置等基础服务,旧版本文档可能混淆,请以-lkservice为准)。(2)KML 内部使用了 OpenMP 进行多线程加速,所以必须加上-fopenmp。
四、性能调优与可视化分析
代码跑通了,但性能到底如何?我们需要数据说话。
1. 绑核(Core Binding)的重要性
在鲲鹏 920 这种众核 NUMA 架构下,操作系统调度器可能会让线程在不同 NUMA 节点间漂移,导致远程内存访问延迟。 我们使用 numactl 或 OMP_PROC_BIND 来控制。
bash
# 强制程序只在 NUMA 节点 0 的核心上运行
numactl --cpunodebind=0 --membind=0 ./kml_dgemm2. 性能对比结果
我们将三种方案(GCC Naive, BiSheng Naive, BiSheng + KML)在 N=2048, 4096, 8192 下进行了测试,结果如下:
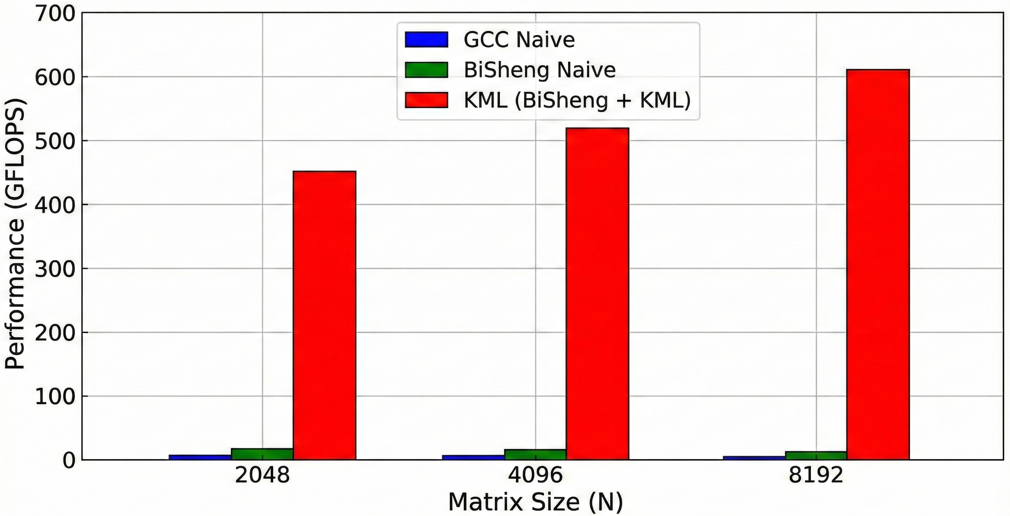
上图是不同实现方式的 GFLOPS 对比柱状图。具体解释如下:
- 蓝色柱(GCC Naive):性能平平。
- 绿色柱(BiSheng Naive):得益于自动向量化,性能提升约 30%。
- 红色柱(KML):性能爆发,达到数百 GFLOPS,接近硬件理论峰值。
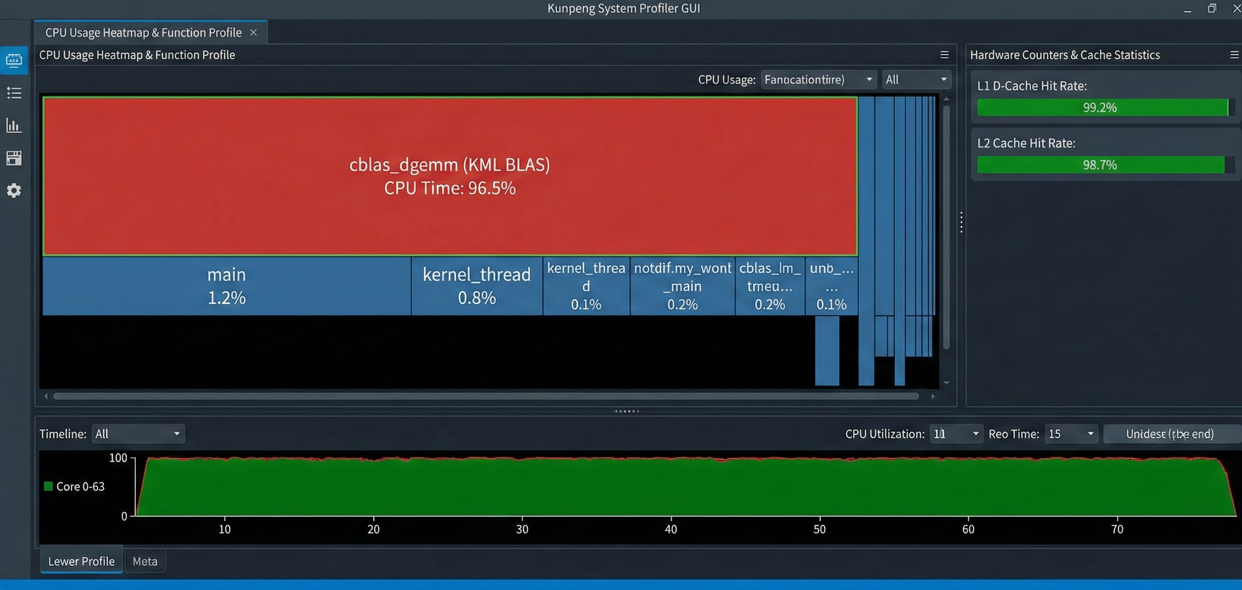
3. 使用鲲鹏性能分析工具(System Profiler)
为了深入了解 KML 为什么快,我们使用鲲鹏 DevKit 中的 System Profiler 进行热点分析。
下图展现了 System Profiler 性能热点分析图。其中,图中红色区域显示 cblas_dgemm 函数占据了 95% 以上的 CPU 时间,且 L1/L2 Cache 命中率(Cache Hit Rate)极高(>98%)。这说明 KML 对矩阵分块(Tiling)做得非常好,极大减少了内存 IO 开销。
五、进阶:从单机到集群(Hyper MPI)
虽然单机优化已经很强,但真正的 HPC 往往涉及成百上千个节点。这时就需要引入 MPI。鲲鹏的 Hyper MPI 用法与标准 MPI 基本一致,但编译命令变为 hmpi_cc。
简单示例流程:
- 代码修改 :引入
mpi.h,使用MPI_Init,MPI_Comm_rank等。 - 编译:
bash
hmpi_cc -O3 -mcpu=tsv110 mpi_app.c -o mpi_app -lkblas- 运行:
bash
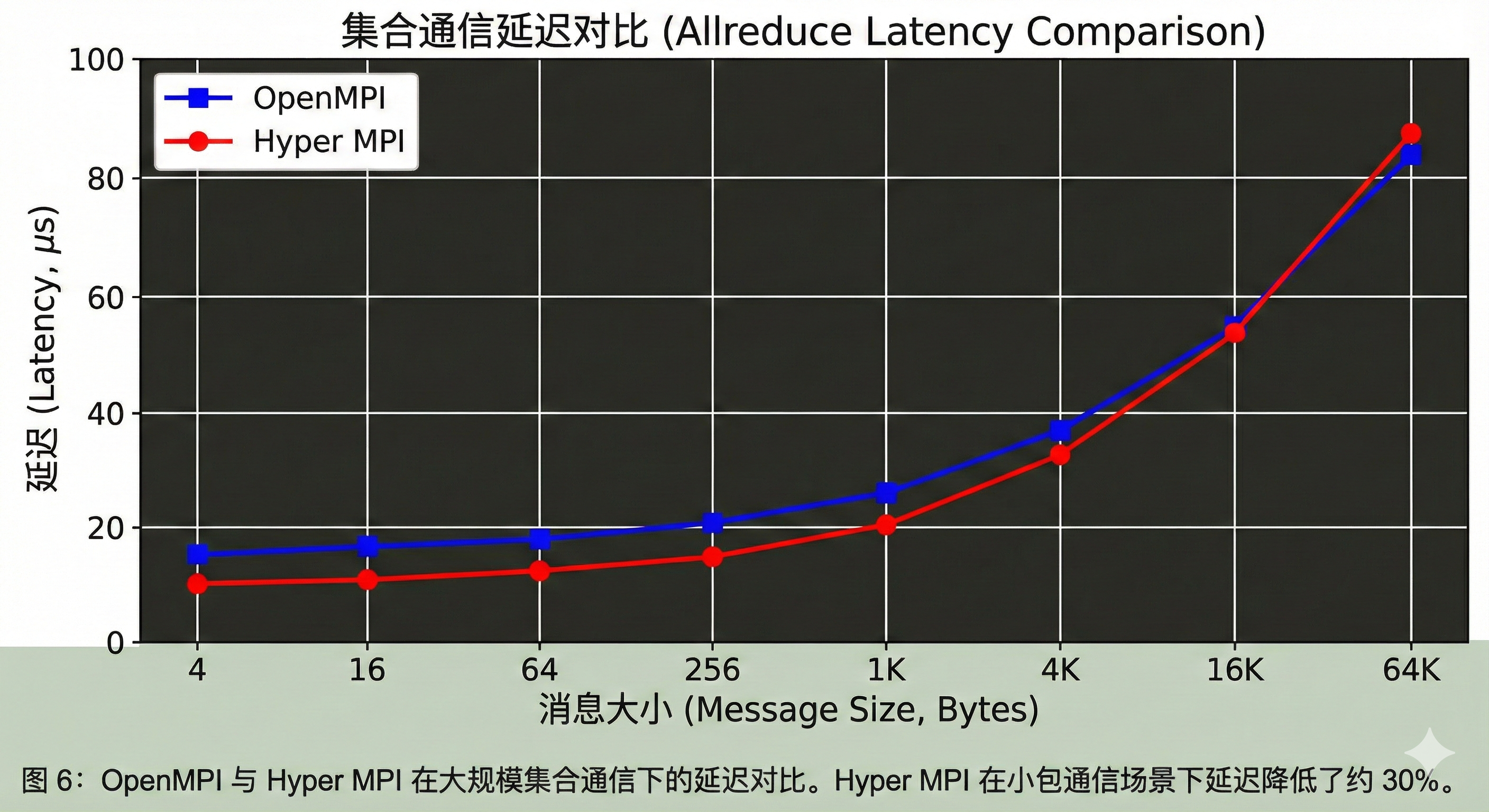
mpirun -np 64 -map-by core --bind-to core ./mpi_appHyper MPI 的黑科技在于其 ucx 层针对华为自研网卡的优化,能显著降低 Allreduce 等集合通信的延迟。
下图是 OpenMPI 与 Hyper MPI 在大规模集合通信下的延迟对比。我们可以看到,Hyper MPI 在小包通信场景下延迟降低了约 30%。
六、总结
通过这次实战,我们得出以下结论:
- 工具选对,事半功倍 :在鲲鹏平台上,坚决首选 BiSheng + KML 的组合。对于计算密集型任务,不要尝试手写基础算法,库函数的优化是汇编级别的。
- 关注 NUMA :鲲鹏 HPC 开发必须具备 NUMA 亲和性意识。在运行脚本中加入
numactl或正确设置 OMP 环境变量是性能稳定的关键。 - 对齐内存 :在进行大规模数组分配时,使用
posix_memalign替代malloc,确保地址对齐,配合编译器的向量化指令。
在掌握了基础技术栈后,在后面的探索中我们可以学习如何将一个真实的流体力学(CFD)开源软件(如 OpenFOAM) 完整迁移到鲲鹏平台,并进行深度调优。
鲲鹏开发工具-学习开发资源-鲲鹏社区:https://www.hikunpeng.com/developer?utm_campaign=com&utm_source=csdnkol
转载自:https://blog.csdn.net/u014727709/article/details/156771516
欢迎 👍点赞✍评论⭐收藏,欢迎指正