PyTorch 入门学习笔记(基础篇)
PyTorch 是基于 Python 的深度学习框架,凭借动态计算图、简洁的 API 设计和对 GPU 友好的特性,成为机器学习领域的热门工具。这份笔记整理了 PyTorch 基础入门的核心知识点,涵盖前置知识、数据处理、张量操作、梯度计算等关键内容,适合入门者系统学习与回顾,同时标注了配套配图的放置位置,便于博客排版展示。
一、前置知识(Prerequisites)
在学习 PyTorch 前,需要具备以下基础,才能更顺畅地理解和实践:
- Python 3:PyTorch 完全基于 Python 开发,熟练掌握 Python 语法、数据结构(列表、字典、类)是基础。
- 深度学习基础(Deep Learning Basics):了解神经网络的基本概念(如神经元、层、损失函数、优化器)、前向传播与反向传播的原理。
- NumPy 基础:NumPy 是 Python 科学计算的核心库,PyTorch 的张量(Tensor)操作与 NumPy 的数组操作高度相似,掌握 NumPy 的数组创建、维度变换、数学运算等内容,能快速迁移到 PyTorch 学习中。
二、PyTorch 核心概览(What's PyTorch)
- 定义 :PyTorch 是 Facebook 开源的Python 机器学习框架,专注于深度学习领域,同时也支持传统机器学习任务。
- 核心特性
- 支持**高维张量(n-dimensional Tensor)**的 GPU 加速计算,大幅提升深度学习模型的训练速度。
- 提供**自动微分(Autograd)**功能,无需手动推导梯度,简化神经网络的反向传播实现,是训练深度模型的关键。
- 动态计算图(Dynamic Computational Graph):计算图随代码执行实时构建,支持灵活的模型设计与调试,适合科研与快速迭代。
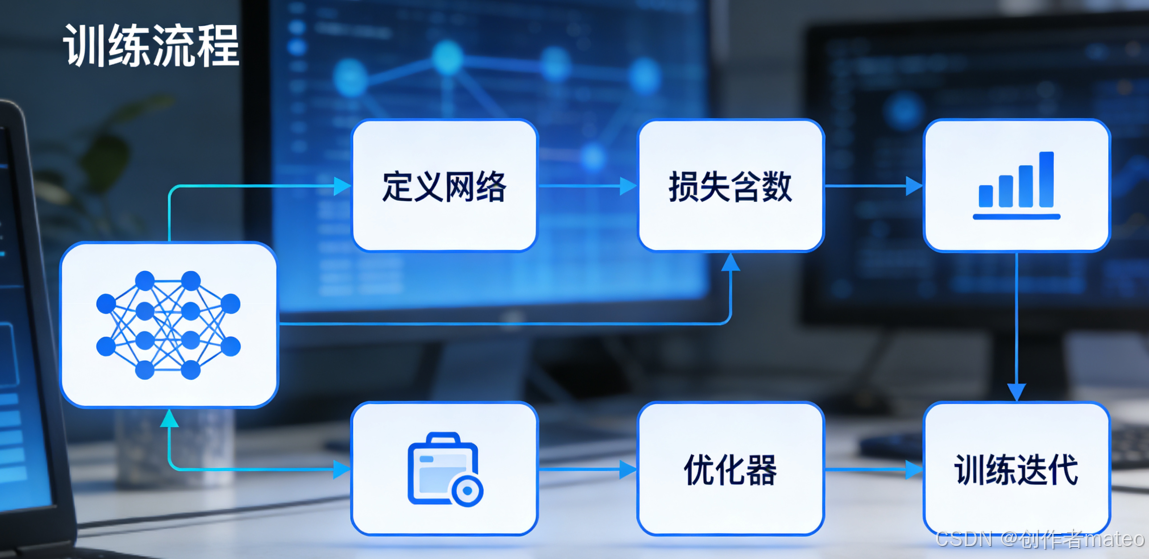
三、神经网络训练的核心流程
在 PyTorch 中训练神经网络,需遵循定义网络→定义损失函数→选择优化器→训练迭代的核心流程,同时还要完成数据的加载与验证,具体步骤如下:
- 数据处理 :通过
Dataset和DataLoader加载、预处理数据,并划分训练集(Training)、验证集(Validation)、测试集(Testing)。 - 网络定义 :基于
torch.nn模块构建神经网络的结构,定义各层的连接方式与激活函数。 - 损失函数:选择适合任务的损失函数(如分类任务用交叉熵损失,回归任务用均方误差),衡量模型预测值与真实值的差距。
- 优化器 :通过
torch.optim选择优化算法(如 SGD、Adam),用于更新网络参数以最小化损失。 - 训练迭代 :循环执行前向传播、计算损失、反向传播求梯度、优化器更新参数的步骤,同时通过验证集监控模型性能,测试集评估最终效果。
四、数据加载:Dataset 与 DataLoader
PyTorch 提供 torch.utils.data 模块处理数据,核心是 Dataset 和 DataLoader,二者分工不同但协同工作:
(一)Dataset 与 DataLoader 的区别
- Dataset :负责存储数据样本和对应的标签(预期值),是自定义数据加载逻辑的基础,需要实现数据的读取与索引。
- DataLoader :将
Dataset中的数据按批次(batch)分组,支持多进程加载(multiprocessing)和数据打乱(shuffle),解决了大数据集无法一次性加载到内存的问题,同时提升训练效率。
(二)自定义 Dataset 类
定义自己的 Dataset 需继承 torch.utils.data.Dataset,并实现以下 3 个核心方法:
python
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
# 1. __init__:初始化数据集对象,加载数据文件或路径
def __init__(self, file_path):
self.data = self.load_data(file_path) # 自定义数据加载逻辑
# 2. __getitem__:根据索引 index,返回数据集中的一个样本(数据+标签)
def __getitem__(self, index):
return self.data[index]
# 3. __len__:返回数据集的总样本数量
def __len__(self):
return len(self.data)(三)使用 DataLoader 加载数据
python
# 实例化自定义 Dataset
dataset = MyDataset("data_file.txt")
# 构建 DataLoader,设置批次大小、是否打乱等参数
dataloader = DataLoader(dataset, batch_size=5, shuffle=True) # training 时 shuffle=True,testing 时 shuffle=False
# 遍历 DataLoader 获取批次数据
for batch_data in dataloader:
# 处理批次数据(如输入模型训练)
passbatch_size:每次加载的样本数量,比如batch_size=5表示每批取 5 个样本。shuffle:布尔值,训练时设为True可打乱数据顺序,避免模型学习到数据的排列规律,提升泛化能力。
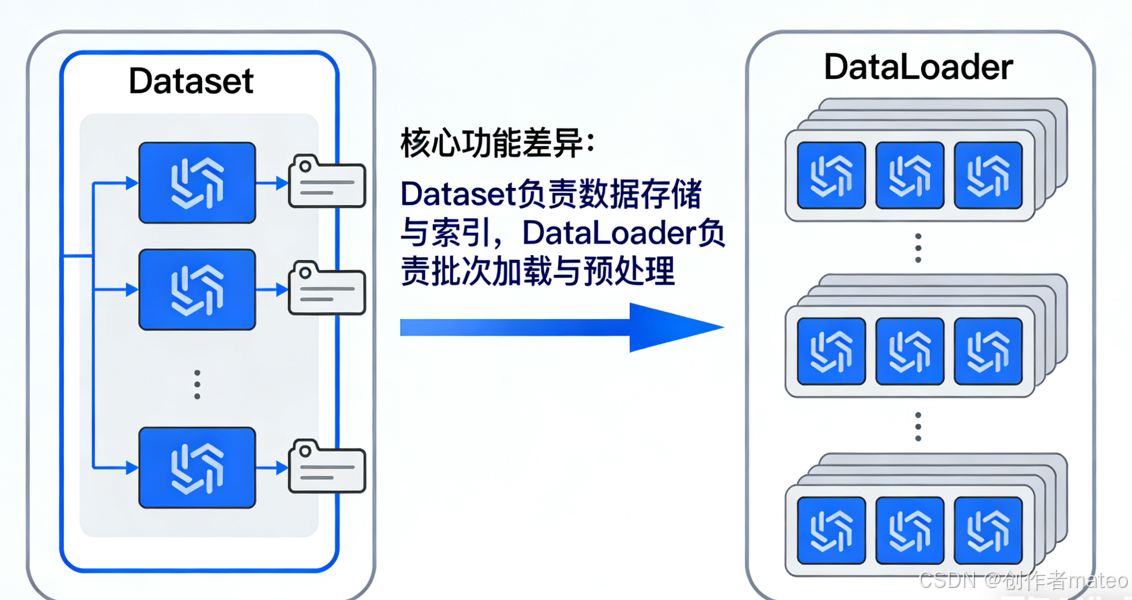
Dataset与DataLoader关系示意图,展示 Dataset 存储数据、DataLoader 按批次读取并打乱的逻辑。
五、张量(Tensors):PyTorch 的核心数据结构
张量是 PyTorch 中表示数据的基本单位,可理解为高维数组/矩阵,支持 CPU/GPU 计算,是构建神经网络的基础。
(一)张量的维度与应用场景
- 1-D Tensor(一维张量):如音频信号的时间序列数据、一维特征向量。
- 2-D Tensor(二维张量):如黑白图像(单通道,行×列)、表格数据(样本×特征)。
- 3-D Tensor(三维张量):如 RGB 图像(通道×行×列)、序列数据(序列长度×批次×特征)。
- 更高维张量 :如视频数据(帧数×通道×行×列),在深度学习中用于处理复杂的时空数据。
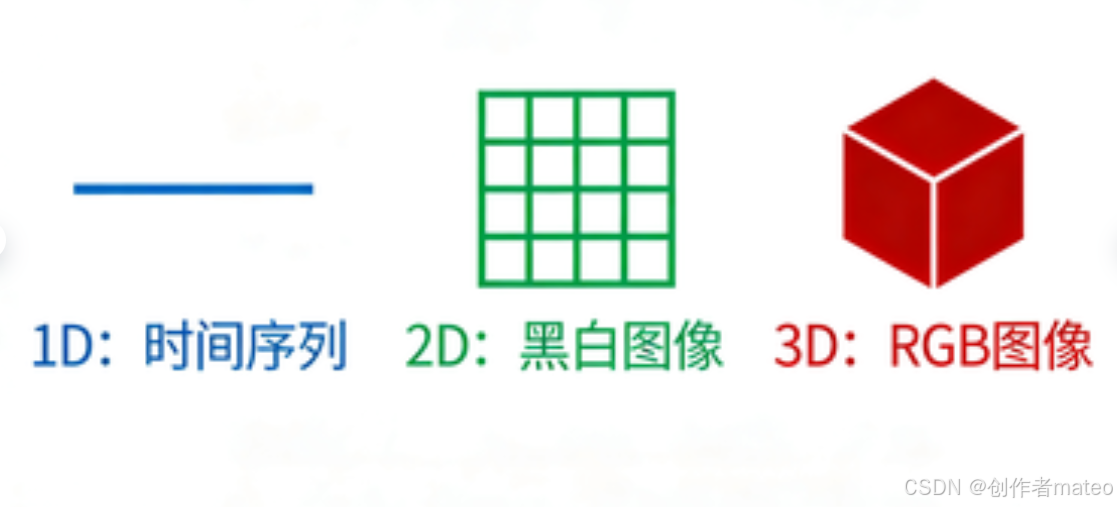
*张量维度示意图,分别展示 1D、2D、3D 张量的结构,并标注对应的应用场景(音频、黑白图像、RGB 图像)。
(二)查看张量维度
通过 .shape 属性可查看张量的维度信息,这是调试张量操作的常用方法:
python
import torch
# 创建二维张量
x = torch.tensor([[1, 2], [3, 4]])
print(x.shape) # 输出 torch.Size([2, 2]),表示 2 行 2 列- PyTorch 中的
dim(维度)与 NumPy 中的axis(轴)概念完全一致,可类比理解。
(三)创建张量的常用方法
-
从数据直接创建 :支持列表(list)或 NumPy 数组(ndarray)作为输入:
python# 从列表创建 x = torch.tensor([1, -1, -1, 1]) # 从 NumPy 数组创建 import numpy as np np_array = np.array([[1, -1], [-1, 1]]) x = torch.from_numpy(np_array) -
创建全 0/全 1 张量 :指定维度即可生成对应值的张量,常用于初始化模型参数:
python# 2×2 的全 0 张量 x_zeros = torch.zeros(2, 2) # 2×3 的全 1 张量 x_ones = torch.ones(2, 3)
(四)张量的常用操作
PyTorch 支持丰富的张量运算,涵盖算术、维度变换、拼接等,是数据处理和模型计算的核心:
-
算术运算 :支持加法、减法、幂运算、求和、求均值等:
pythonx = torch.tensor([1, 2]) y = torch.tensor([3, 4]) z_add = x + y # 加法:[4, 6] z_sub = x - y # 减法:[-2, -2] z_pow = x.pow(2) # 幂运算:[1, 4] z_sum = x.sum() # 求和:3 z_mean = x.mean() # 求均值:1.5 -
维度转置(Transpose) :交换张量的指定维度,常用于矩阵运算或数据维度调整:
pythonx = torch.zeros(2, 3) # 维度为 [2, 3] x = x.transpose(0, 1) # 交换 0 维和 1 维,维度变为 [3, 2] -
压缩维度(Squeeze) :移除长度为 1 的指定维度,简化张量结构:
pythonx = torch.zeros(1, 2, 3) # 维度为 [1, 2, 3] x = x.squeeze(0) # 移除 0 维,维度变为 [2, 3] -
扩展维度(Unsqueeze) :在指定位置新增一个长度为 1 的维度,满足模型输入的维度要求:
pythonx = torch.zeros(2, 3) # 维度为 [2, 3] x = x.unsqueeze(1) # 在 1 维新增维度,维度变为 [2, 1, 3] -
张量拼接(Cat) :在指定维度上拼接多个张量,需保证其他维度一致:
pythonx = torch.zeros(2, 1, 3) y = torch.zeros(2, 3, 3) z = torch.zeros(2, 2, 3) w = torch.cat([x, y, z], dim=1) # 在 1 维拼接,最终维度为 [2, 6, 3]
配图放置处 :此处放置张量常用操作示意图,分别展示 transpose、squeeze、unsqueeze、cat 操作的维度变化过程。
(五)张量的数据类型
使用不同数据类型的张量参与模型计算会导致报错,需匹配模型参数与数据的类型,常见类型如下:
| 数据类型(Data type) | 简写(dtype) | 张量类型(Tensor type) |
|---|---|---|
| 32位浮点数(32-bit floating point) | torch.float |
torch.FloatTensor |
| 64位有符号整数(64-bit signed integer) | torch.long |
torch.LongTensor |
六、PyTorch 与 NumPy 的对比
PyTorch 的张量操作与 NumPy 的数组操作高度相似,二者核心属性的对应关系如下,便于熟悉 NumPy 的开发者快速上手 PyTorch:
| PyTorch 特性 | NumPy 特性 | 说明 |
|---|---|---|
x.shape |
x.shape |
均用于查看数据的维度信息 |
x.dtype |
x.dtype |
均用于查看数据的类型 |
注:PyTorch 张量支持 GPU 计算和自动微分,这是与 NumPy 数组最核心的区别。
PyTorch与NumPy特性对比表的可视化图,突出二者的相似点与核心差异。

七、张量的设备分配(CPU/GPU)
PyTorch 支持张量在 CPU 和 GPU 之间灵活切换,充分利用硬件资源加速计算:
-
默认设备 :张量和模型模块默认在 CPU 上计算。
-
设备切换 :通过
.to()方法将张量移动到指定设备:pythonx = torch.tensor([1, 2]) # 移动到 CPU x = x.to("cpu") # 移动到 GPU(需显卡支持 CUDA) if torch.cuda.is_available(): x = x.to("cuda") # 或 x.to("cuda:0")(指定第 0 块 GPU) -
检查 GPU 可用性 :通过
torch.cuda.is_available()判断当前环境是否支持 GPU 计算,避免代码运行报错。 -
GPU 加速的意义:GPU 拥有大量的计算核心,适合并行处理张量的矩阵运算,能将深度学习模型的训练时间从数小时/天缩短到数分钟/小时,是大规模模型训练的必备条件。
八、PyTorch 的自动梯度计算(Gradient Calculation)
自动微分是 PyTorch 训练神经网络的核心功能,无需手动推导梯度,只需通过简单的 API 即可完成反向传播的梯度求解:
(一)梯度计算的步骤
python
# 1. 创建张量并设置 requires_grad=True,标记需要计算梯度
x = torch.tensor([[1.0, 0.0], [-1.0, 1.0]], requires_grad=True)
# 2. 定义计算过程(如求平方和)
z = x.pow(2).sum()
# 3. 反向传播,计算梯度
z.backward()
# 4. 查看梯度结果(x.grad 存储 x 的梯度)
print(x.grad) # 输出 tensor([[2., 0.], [-2., 2.]])(二)原理说明
上述例子中,z=∑i,jxij2z = \sum_{i,j} x_{ij}^2z=∑i,jxij2,对 xijx_{ij}xij 求偏导得 ∂z∂xij=2xij\frac{\partial z}{\partial x_{ij}} = 2x_{ij}∂xij∂z=2xij,因此最终梯度为原张量的 2 倍,与代码输出结果一致。PyTorch 会自动跟踪张量的计算路径,通过 backward() 完成梯度的链式求导。
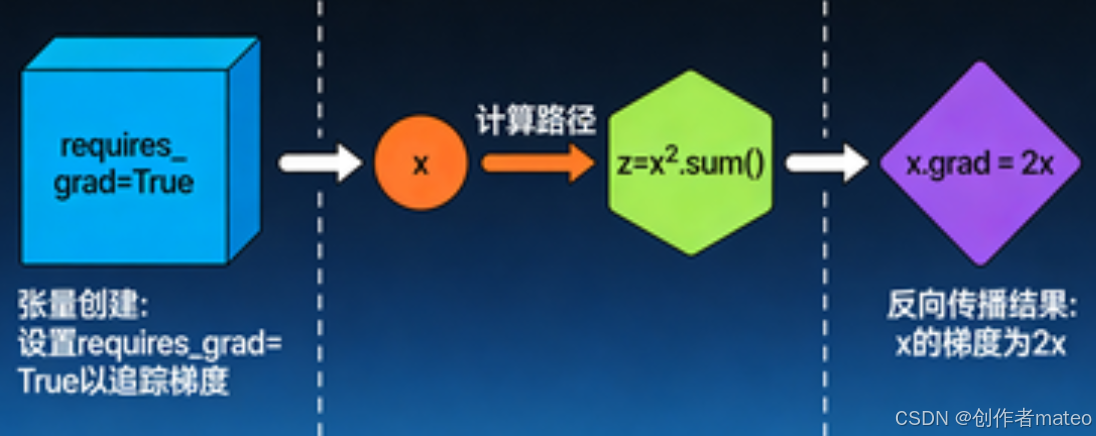
自动梯度计算过程示意图,展示从张量创建、计算图构建到反向传播求梯度的完整流程,并标注数学推导过程。