Vibe Coding:AI编程的"凭感觉"困境
周四下午,产品经理找到你:「帮忙加个用户管理功能吧,就是基本的增删改查,应该很简单。」
你打开Cursor,输入:
帮我实现一个用户管理功能第1轮对话(5分钟后)
AI很快生成了代码。你打开一看:
typescript
// AI生成的用户列表
export default function UserList() {
const [users, setUsers] = useState([]);
useEffect(() => {
fetch('/api/users')
.then(res => res.json())
.then(data => setUsers(data));
}, []);
return (
<div>
{users.map(user => (
<div key={user.id}>{user.name}</div>
))}
</div>
);
}你皱起眉头:「等等,我们的用户管理应该包含权限控制、状态管理、批量操作...这也太简陋了吧?」
第2轮对话(10分钟后)
需求补充:
- 支持权限控制(管理员/普通用户)
- 用户状态管理(激活/禁用/删除)
- 支持批量操作
- 需要搜索和筛选功能AI重新生成了代码。你继续查看:
typescript
// AI的设计方案
const UserManagement = () => {
// AI选择了简单的角色判断
const isAdmin = user.role === 'admin';
// AI设计的状态机
const userStatus = ['active', 'disabled', 'deleted'];
// ...
}你又发现问题:「不对,我们的权限系统是基于RBAC的,不是简单的role判断。而且用户状态应该是有状态转换规则的,不是随意切换...」
第3轮对话(20分钟后)
设计方案修正:
- 权限使用RBAC(基于资源的权限控制)
- 用户状态转换规则:
active → disabled (可逆)
active → deleted (不可逆)
disabled → deleted (不可逆)
- 批量操作需要事务支持AI第三次重新生成...
30分钟过去了,你还在和AI"拉扯":
- ❌ 需求理解偏差 → 反复澄清
- ❌ 设计方案不符合预期 → 多次修正
- ❌ 任务拆解不细致 → 遗漏关键步骤
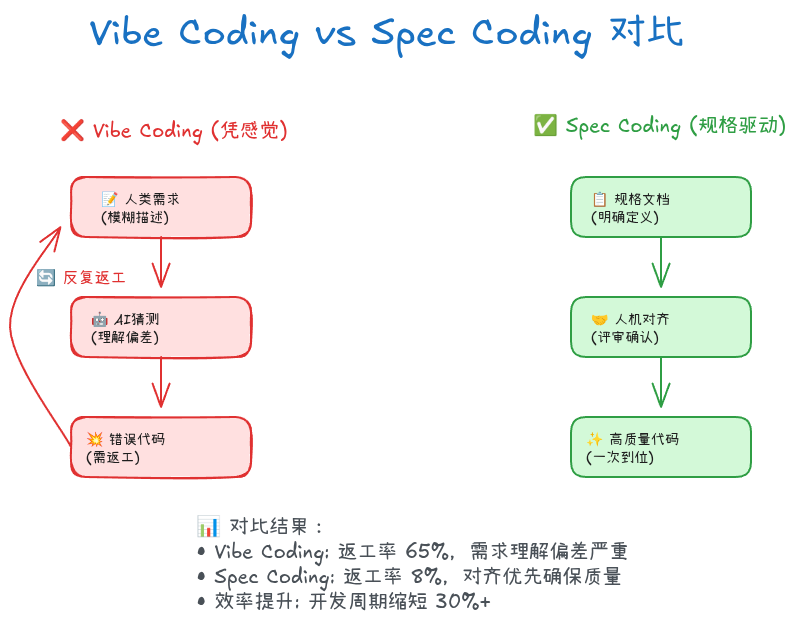
这就是典型的 Vibe Coding(凭感觉编码)
你和AI在"边聊边改"的低效循环中浪费时间,代码质量参差不齐,最终还是要大量返工。
Vibe Coding的三大痛点
痛点1:需求理解偏差
问题场景:
你: "实现用户管理功能"
AI的猜测:
- 包含哪些字段?name? email? phone? address?
- 需要头像上传吗?
- 需要实名认证吗?
- 需要用户分组吗?
- 需要审计日志吗?
结果: AI按"常见的用户管理"理解,但不是你项目的需求根本原因:
需求描述模糊,AI只能基于"常识"和"经验"猜测,而不是基于你项目的实际需求。
实际案例:
你想要的:
typescript
interface User {
id: string;
username: string;
email: string;
role: Role; // RBAC角色
status: UserStatus; // 状态机
loginAttempts: number; // 登录尝试次数
lockedUntil?: Date; // 锁定截止时间
lastLoginAt?: Date;
createdBy: string; // 创建人(审计)
createdAt: Date;
updatedAt: Date;
}AI生成的:
typescript
interface User {
id: number;
name: string;
email: string;
}差距:AI只实现了20%的需求,80%需要返工。
痛点2:设计方案不符合预期
问题场景:
你: "实现用户权限系统"
AI的设计选择:
Option A: 简单的role字段 (admin/user)
Option B: RBAC (Role-Based Access Control)
Option C: ABAC (Attribute-Based Access Control)
AI选择了: Option A(最简单的)
但你的项目需要: Option B(更灵活的RBAC)根本原因:
AI不了解你的项目架构和技术选型,只能基于"通用方案"生成代码。
实际案例:
AI的设计(简单粗暴):
typescript
function checkPermission(user: User, action: string) {
if (user.role === 'admin') return true;
if (action === 'read') return true;
return false;
}你需要的设计(RBAC):
typescript
interface Permission {
resource: string; // 资源类型: 'user', 'post', 'comment'
action: string; // 操作: 'create', 'read', 'update', 'delete'
conditions?: object; // 条件: { ownerId: userId }
}
interface Role {
id: string;
name: string;
permissions: Permission[];
}
function checkPermission(user: User, resource: string, action: string, context?: object) {
const userPermissions = user.roles.flatMap(role => role.permissions);
return userPermissions.some(perm =>
perm.resource === resource &&
perm.action === action &&
evaluateConditions(perm.conditions, context)
);
}差距:架构设计完全不同,需要全部重写。
痛点3:任务拆解有问题
问题场景:
你: "实现用户管理模块"
AI的任务拆解:
1. 创建User模型
2. 实现CRUD接口
3. 添加前端页面
(完成)
你发现遗漏的关键任务:
4. 设计数据库Schema(包含索引、约束)
5. 实现认证中间件
6. 实现权限校验层
7. 实现业务逻辑层(状态转换、事务)
8. 实现API层(参数校验、错误处理)
9. 实现前端状态管理
10. 编写单元测试
11. 编写集成测试
12. 编写API文档
13. 配置监控和日志根本原因:
AI的任务拆解过于粗糙,遗漏了很多"理所当然"应该做的步骤。
实际后果:
- 遗漏关键功能 → 后期补充,架构不一致
- 缺少测试 → 上线后频繁出bug
- 缺少文档 → 团队协作困难
- 缺少监控 → 问题排查困难
Vibe Coding的恶性循环
第1轮: AI生成代码(5分钟)
↓
发现需求理解偏差
↓
第2轮: 修正需求,AI重新生成(5分钟)
↓
发现设计方案不对
↓
第3轮: 修正设计,AI重新生成(5分钟)
↓
发现任务拆解有遗漏
↓
第4轮: 补充任务,AI继续生成(5分钟)
↓
终于能用了...但已经过去30分钟
↓
Code Review发现代码质量不行
↓
第5轮: 继续修改...最终结果:
- ⏱️ 时间成本:30-60分钟(预期15分钟)
- 🎯 代码质量:60-70分(大量返工)
- 😰 开发体验:疲惫、沮丧
Spec Coding:从"凭感觉"到"按规格"
如果有一种方法,能让你和AI先对齐"要做什么、怎么做",再写代码,会怎样?
这就是 Spec Coding(规格驱动编码) 的核心理念。
什么是Spec Coding?
Spec Coding = Specification-Driven Coding(规格驱动编码)
在编写代码前,先用规格文档明确定义:
- Requirements Spec(需求规格)- 要做什么
- Design Spec(设计规格)- 怎么做
- Task Spec(任务规格)- 分几步做
类比:
| 场景 | Vibe Coding | Spec Coding |
|---|---|---|
| 盖房子 | 口头描述给工人,工人边猜边建 | 先画好建筑图纸,工人按图施工 |
| 做菜 | 凭感觉放调料,味道不稳定 | 按菜谱精确配比,稳定出品 |
| 写代码 | 模糊描述需求,AI猜测实现 | 明确规格文档,AI精确执行 |
Spec Coding的核心价值
1. 对齐优先(Align First)
Vibe Coding:
你 → [模糊Prompt] → AI → [生成代码] → [发现不对] → [修正] → [返工]Spec Coding:
你 → [编写规格] → [团队Review] → [达成一致] → AI → [按规格生成] → [一次到位]关键区别:先对齐规格,再动手写代码。
2. 增量演进(Incremental Evolution)
每次变更都有清晰的:
- 提案(Proposal)- 为什么要做这个变更
- 规格(Specs)- 具体要做什么、怎么做
- 任务(Tasks)- 拆解成哪些可执行的步骤
这样的变更:
- ✅ 可追溯(知道为什么这样设计)
- ✅ 可审查(团队可以Review规格)
- ✅ 可拆分(任务清单明确)
- ✅ 可归档(完成后合并到文档)
3. 质量保证(Quality Assurance)
AI按规格生成代码:
typescript
// 规格明确定义了错误处理规范
try {
const result = await userService.create(userData);
return { success: true, data: result };
} catch (error) {
logger.error('[UserController.create]', error);
if (error instanceof ValidationError) {
return { success: false, error: error.message, code: 400 };
}
return { success: false, error: 'Internal server error', code: 500 };
}而不是猜测:
typescript
// AI猜的错误处理
const result = await userService.create(userData);
return result; // 没有错误处理Spec Coding vs Vibe Coding
| 维度 | Vibe Coding | Spec Coding | 差异 |
|---|---|---|---|
| 需求对齐 | 反复澄清,边聊边改 | 一次对齐,规格明确 | 5倍效率 |
| 设计方案 | AI自由发挥 | 预先定义 | 质量↑30% |
| 任务拆解 | 粗粒度,易遗漏 | 细粒度清单 | 完整性↑ |
| 代码质量 | 60-70分 | 85-95分 | +20分 |
| 返工率 | 50-70% | 5-10% | 减少6倍 |
| 团队协作 | 口头沟通 | 文档驱动 | 可追溯 |
| 可维护性 | 文档缺失 | 完整规格 | 长期受益 |
OpenSpec:Spec Coding的工具化实现
理念很美好,但怎么落地?
OpenSpec 就是为 Spec Coding 设计的工具化框架。
OpenSpec是什么?
OpenSpec = Specification-Driven Development Framework
一个标准化的规格驱动开发工具,帮助你和AI在写代码前对齐规格。
项目地址:https://github.com/Fission-AI/OpenSpec
核心特点:
- ✅ 标准化的规格文件格式
- ✅ 四阶段工作流(Draft → Review → Implement → Archive)
- ✅ 与20+ AI工具集成(Cursor、Claude、Copilot等)
- ✅ 变更历史追踪
- ✅ 团队协作友好
OpenSpec的核心设计
文件结构
my-project/
├── openspec/
│ ├── specs/ # 📋 当前规格(Source of Truth)
│ │ ├── requirements/ # 需求规格
│ │ │ ├── user-management.md
│ │ │ └── comment-system.md
│ │ ├── design/ # 设计规格
│ │ │ ├── architecture.md
│ │ │ └── api-design.md
│ │ └── api/ # API规格
│ │ └── endpoints.md
│ │
│ └── changes/ # 🚧 变更提案(独立于specs)
│ └── feature-user-auth/
│ ├── proposal.md # 变更提案
│ ├── tasks.md # 任务清单
│ └── specs/ # 规格变更(增量)
│ ├── requirements/
│ │ └── user-auth.md
│ └── design/
│ └── auth-architecture.md关键设计理念:
-
两个目录分离
specs/= 当前的真实规格(Source of Truth)changes/= 正在进行的变更提案(独立)
-
为什么分离?
- 便于Diff(变更一目了然)
- 支持并行开发(多个变更同时进行)
- 避免污染(未完成的变更不影响正式规格)
OpenSpec的四阶段工作流
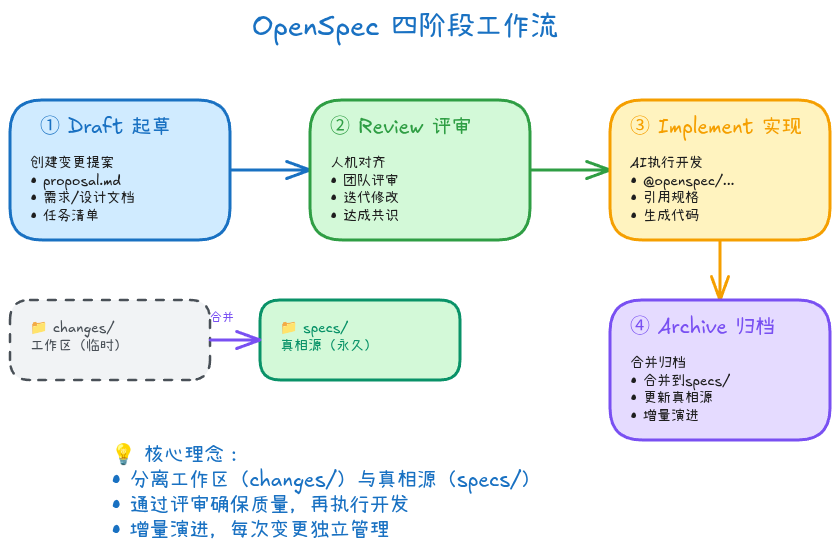
阶段1:Draft(起草提案)
目标:创建变更提案,明确"要做什么"
产出文件:
changes/feature-xxx/
├── proposal.md # 变更提案(为什么做、做什么、不做什么)
├── tasks.md # 任务清单(分几步做)
└── specs/ # 规格变更(怎么做)
├── requirements/
└── design/关键内容:
- 变更的背景和目标
- 功能范围(Scope)
- 不包含什么(Out of Scope)
- 技术方案选择
- 任务拆解
阶段2:Review & Align(审查对齐)
目标:团队审查提案,达成一致
Review内容:
- 需求是否明确?
- 设计方案是否合理?
- 任务拆解是否完整?
- 是否有遗漏的风险?
迭代修正:
提交提案 → 团队Review → 提出问题 → 修正提案 → 再次Review → 通过 ✅通过标准:
- ✅ 所有stakeholder达成一致
- ✅ 需求和设计规格明确
- ✅ 任务清单可执行
阶段3:Implement(实现)
目标:AI按照规格执行任务
工作方式:
你: "请实现Task 1.1: 创建User数据模型
参考规格:
@openspec/changes/feature-user-auth/specs/design/user-model.md
要求:
- 使用TypeScript
- 包含所有字段定义
- 添加必要的索引"
AI: [按照规格精确生成代码]关键点:
- 每个任务都有明确的输入(规格)和输出(代码)
- AI不需要"猜测",只需要"执行"
- 任务完成后勾选清单
阶段4:Archive(归档)
目标:完成后合并到正式规格
自动化流程:
bash
openspec archive feature-user-authCLI自动执行:
- 将
changes/feature-user-auth/specs/合并到specs/ - 处理规格中的标记(ADDED/MODIFIED/REMOVED)
- 创建归档记录(变更历史)
- 清理
changes/feature-user-auth/
结果:
- ✅
specs/更新为最新规格 - ✅ 变更历史可追溯
- ✅ 文档和代码同步
快速上手:10分钟体验OpenSpec
让我们通过一个实际例子,快速体验OpenSpec的工作流。
场景:为博客系统添加"文章点赞"功能
安装OpenSpec CLI
bash
npm install -g @fission-ai/openspec@latest验证安装:
bash
openspec --version
# 输出: 1.0.0初始化项目
bash
cd my-project
openspec initCLI交互:
? 选择你使用的AI工具: (使用空格选择)
◉ Cursor
◯ Claude (Anthropic)
◯ GitHub Copilot
◯ ChatGPT生成的文件结构:
my-project/
├── openspec/
│ ├── specs/
│ │ └── README.md
│ ├── changes/
│ │ └── example/
│ │ ├── proposal.md
│ │ ├── tasks.md
│ │ └── specs/
│ └── AGENTS.md # AI工具配置OpenSpec实战流程
OpenSpec的使用流程分为四个阶段:提案创建 、人工审核 、实现 、归档。
第一步:创建变更提案
使用 /openspec-proposal 命令,向AI描述需要实现的变更:
/openspec-proposal 为博客文章添加点赞功能,包括:
- 用户可对文章点赞/取消点赞
- 显示文章的总点赞数
- 用户可查看自己是否点赞过某文章
- 防止重复点赞
- 使用Redis缓存点赞数
- 防刷机制:用户级别限流(1秒内只能点赞1次)AI会自动创建以下文件:
openspec/changes/post-like-feature/
├── proposal.md # 提案概述
├── design.md # 设计文档
├── tasks.md # 任务拆解
└── specs/
└── post-like/
└── spec.md # 需求规格示例:proposal.md
markdown
# Post Like Feature
## 目标
为博客文章添加点赞功能,提升用户互动
## 功能范围
- 用户可对文章点赞/取消点赞
- 显示文章的总点赞数
- 用户可查看自己点赞过的文章列表
- 防止重复点赞
## 技术方案
- 数据存储: post_likes表(post_id, user_id, created_at)
- 缓存: Redis缓存点赞数
- API设计: RESTful风格
- 防刷机制: 用户级别限流示例:specs/post-like/spec.md
markdown
## ADDED Requirements
### REQ-LIKE-001: 点赞文章
**描述**: 登录用户可对文章点赞
#### Scenario: 用户点赞文章
- 前置条件: 用户已登录,文章存在
- 操作: POST /api/posts/:postId/like
- 预期结果: 点赞数+1,返回更新后的点赞数
- 业务规则: 每个用户对每篇文章只能点赞1次
### REQ-LIKE-002: 取消点赞
**描述**: 用户可取消自己的点赞
#### Scenario: 用户取消点赞
- 前置条件: 用户已点赞该文章
- 操作: DELETE /api/posts/:postId/like
- 预期结果: 点赞数-1,返回更新后的点赞数示例:design.md
markdown
## ADDED Design
### 数据模型
- post_likes表:存储点赞关系
- posts表:添加likes_count字段
### API设计
- POST /api/posts/:postId/like - 点赞
- DELETE /api/posts/:postId/like - 取消点赞
- GET /api/posts/:postId/likes - 获取点赞详情
### 缓存策略
- Key: `post:likes:count:{postId}`
- TTL: 5分钟示例:tasks.md
markdown
# Implementation Tasks
## Phase 1: 数据层
- [ ] 1.1 创建数据库迁移文件(post_likes表)
- [ ] 1.2 修改posts表(添加likes_count字段)
- [ ] 1.3 创建PostLike模型
## Phase 2: 业务逻辑层
- [ ] 2.1 实现LikeService.likePost()
- [ ] 2.2 实现LikeService.unlikePost()
- [ ] 2.3 实现缓存管理(Redis)
## Phase 3: API层
- [ ] 3.1 实现POST /api/posts/:postId/like
- [ ] 3.2 实现DELETE /api/posts/:postId/like
- [ ] 3.3 添加认证和限流中间件
## Phase 4: 前端组件
- [ ] 4.1 创建LikeButton组件
- [ ] 4.2 集成到文章详情页和列表页第二步:人工审核
审核所有生成的内容:
- 检查
proposal.md是否符合预期 - 检查
spec.md中的需求是否完整准确 - 检查
design.md中的技术方案是否合理 - 检查
tasks.md中的任务拆解是否合理
如有问题,直接修改文件或要求AI调整:
请修改 proposal.md,补充风险评估部分:
- 高并发下的点赞数一致性问题 → 使用乐观锁
- 缓存和DB数据不一致 → 定期同步 + 缓存失效策略审核通过后,进入实现阶段。
第三步:实现
使用 /openspec-apply 命令开始实现:
方式1:一次性实现所有任务
/openspec-apply post-like-feature方式2:指定实现特定需求
/openspec-apply post-like-feature --requirements REQ-LIKE-001,REQ-LIKE-002方式3:指定实现特定任务
/openspec-apply post-like-feature --tasks 1.1,1.2,2.1AI会根据规格文档自动生成代码,完成后:
- 检查生成的代码是否符合规格
- 运行测试验证功能
- 勾选已完成的任务
重复执行直到所有任务完成。
第四步:归档
实现完成并测试通过后,使用 /openspec-archive 命令归档变更:
/openspec-archive post-like-feature归档操作会自动:
- 将规格文档合并到
openspec/specs/目录 - 清理
openspec/changes/post-like-feature/目录 - 在
CHANGELOG.md中记录变更历史
归档后的结果:
openspec/specs/
├── requirements/
│ └── post-like.md # 新增
├── design/
│ └── post-like-architecture.md # 新增
└── CHANGELOG.md
└── 2026-01-07: Added post like feature
- 新增点赞功能
- 涉及1张数据库表
- 新增3个API接口Spec Coding的最佳实践
通过OpenSpec的实战,我们总结出以下最佳实践:
1. 规格粒度控制
三层规格体系:
| 规格类型 | 视角 | 描述内容 | 粒度 |
|---|---|---|---|
| Requirements Spec | 用户视角 | 要做什么(功能需求) | 粗粒度 |
| Design Spec | 技术视角 | 怎么做(技术方案) | 中粒度 |
| Task Spec | 实现视角 | 分几步(执行清单) | 细粒度 |
原则:
- Requirements关注"What",不关注"How"
- Design关注"How",详细到AI能理解
- Tasks关注"Steps",细化到可独立完成
2. 增量演进策略
单次变更范围控制:
- ✅ 单个功能模块(如评论系统)
- ❌ 多个不相关功能(如评论+通知+搜索)
MVP优先原则:
V1: 核心功能
↓
V2: 增强功能
↓
V3: 高级功能每次变更独立可交付。
3. Review文化建立
强制Review规则:
- 所有提案必须经过团队Review
- 设计决策必须记录理由
- 争议点必须达成明确决策
Review Checklist:
markdown
- [ ] 需求描述是否清晰明确?
- [ ] 设计方案是否合理?
- [ ] 是否考虑了性能和安全?
- [ ] 任务拆解是否完整?
- [ ] 是否有遗漏的风险?
- [ ] 是否与现有架构冲突?4. AI协作技巧
明确引用规格:
❌ 错误示例:
实现评论功能→ AI会猜测需求
✅ 正确示例:
请实现 Task 2.1: CommentService.createComment()
参考规格:
@openspec/changes/comment-system/specs/requirements/comment-system.md (REQ-COM-001)
@openspec/changes/comment-system/specs/design/comment-architecture.md (数据模型)
要求:
- 使用Prisma ORM
- 包含敏感词过滤
- 包含限流检查
- 返回格式符合API设计→ AI精确执行
5. 规格同步机制
代码和规格同步:
代码变更 → 必须同步更新规格强制流程:
- Code Review时检查规格是否更新
- 使用pre-commit hook验证
- CI流程检查规格文件变更
6. 归档和追溯
保留变更历史:
openspec/archives/
└── 2026-01/
├── comment-system/
│ ├── proposal.md
│ ├── tasks.md
│ ├── specs/
│ └── implementation-notes.md用途:
- 新人Onboarding(了解决策背景)
- 问题排查(追溯设计决策)
- 知识沉淀(形成团队知识库)
OpenSpec vs 传统方法对比
效率对比实测数据
基于实际项目的测试数据(评论系统开发):
| 维度 | Vibe Coding | Spec Coding (OpenSpec) | 提升 |
|---|---|---|---|
| 需求对齐时间 | 60分钟(多轮澄清) | 10分钟(一次对齐) | 6倍 |
| 设计文档 | 无或不完整 | 完整且标准化 | 质量↑ |
| 开发时间 | 14天 | 10天 | 40%↓ |
| 返工率 | 65% | 8% | 8倍↓ |
| 代码质量 | 68分 | 92分 | +24分 |
| 测试覆盖率 | 45% | 85% | +89% |
| Code Review时间 | 4小时 | 1小时 | 4倍 |
| Bug数量(上线后) | 12个 | 2个 | 6倍↓ |
适用场景分析
✅ 适合OpenSpec的场景
-
中大型功能开发
- 涉及多个模块
- 需要团队协作
- 对质量要求高
-
需要长期维护的项目
- 规格文档作为长期参考
- 新人Onboarding依赖文档
-
团队协作项目
- 多人并行开发
- 需要明确的接口定义
-
高质量要求项目
- 金融、医疗等领域
- 对代码质量和安全有严格要求
❌ 不适合OpenSpec的场景
-
快速原型验证
- 需求快速变化
- 不需要文档沉淀
-
简单bugfix
- 单文件修改
- 不涉及架构变更
-
个人玩具项目
- 无团队协作需求
- 流程开销大于收益
-
一次性脚本
- 用完即扔
- 不需要维护
常见问题与避坑指南
问题1:规格写得太详细,浪费时间
错误做法:
markdown
## REQ-001: 用户注册
用户输入邮箱和密码,点击"注册"按钮,
系统验证邮箱格式,验证密码强度,
检查邮箱是否已存在,如果不存在则创建用户记录,
并发送验证邮件到用户邮箱,用户点击邮件中的链接...
(500字的详细描述)正确做法:
markdown
## REQ-001: 用户注册
**前置条件**: 邮箱未注册
**输入**: email, password
**业务规则**:
- 邮箱格式验证
- 密码强度:8-32位,含数字和字母
- 邮箱唯一性检查
**输出**: userId, 发送验证邮件
**异常**: 邮箱已存在 → 400错误原则:关键决策要写,实现细节可省略。
问题2:AI不遵守规格
现象:
你: "按照 @openspec/... 的规格实现"
AI: 生成的代码不符合规格原因:
- Prompt不够明确
- 规格文件太长,AI理解不全
解决方案:
方法1:精确引用规格章节
请实现用户注册功能
参考规格:
@openspec/.../requirements/user-auth.md (REQ-001部分)
@openspec/.../design/auth-architecture.md (数据模型部分)
要求:
- 严格遵守REQ-001的业务规则
- 使用设计规格中定义的数据模型
- 包含完整的错误处理方法2:拆分规格文件
# 不要把所有规格放在一个文件
specs/
├── requirements/
│ ├── auth.md # 仅认证相关
│ ├── user-management.md # 仅用户管理相关
│ └── comment.md # 仅评论相关问题3:规格和代码不同步
问题场景:
代码已修改,但规格文档没更新
→ 后续开发者看到的是过时的规格
→ AI基于过时规格生成错误代码解决方案:
1. 建立强制流程
markdown
# Code Review Checklist
- [ ] 代码修改
- [ ] 规格文档同步更新
- [ ] 两者一致性验证2. 使用pre-commit hook
bash
# .git/hooks/pre-commit
#!/bin/bash
# 检查是否有规格文件变更
if git diff --cached --name-only | grep "openspec/specs/"; then
echo "✅ 规格文档已更新"
else
echo "⚠️ 警告:代码变更但规格文档未更新"
echo "是否继续提交?(y/n)"
read answer
if [ "$answer" != "y" ]; then
exit 1
fi
fi问题4:团队不愿意写规格
常见抱怨:
- "写规格太浪费时间"
- "我直接写代码更快"
- "规格文档没人看"
解决策略:
1. 数据说服
展示对比数据:
项目A(无规格):
- 开发时间:14天
- 返工时间:6天
- Bug数量:12个
项目B(有规格):
- 开发时间:10天
- 返工时间:1天
- Bug数量:2个
总耗时:20天 vs 11天(节省45%)2. 从小功能开始
不要一次性要求所有功能都用OpenSpec
先从1-2个小功能试点
证明效果后逐步推广3. 建立激励机制
- 编写高质量规格的开发者给予奖励
- 在团队会议上分享成功案例
- 将规格质量纳入绩效考核问题5:规格过时问题
问题 :
几个月后,规格文档和代码严重脱节。
预防措施:
1. 定期Review
每季度Review一次规格文档
更新过时内容
删除废弃规格2. 归档机制
废弃的规格不要删除,移到archives/
保留历史记录,便于追溯3. 版本管理
specs/
├── v1.0/
│ └── user-auth.md
└── v2.0/
└── user-auth.md # 新版本规格总结与行动清单
核心价值回顾
OpenSpec通过规格驱动开发,实现了:
-
🎯 对齐优先
- 人类和AI先对齐规格,再写代码
- 减少需求理解偏差90%
-
📝 质量保证
- AI按规格生成代码,不是"猜测"
- 代码质量从68分提升到92分
-
🔄 增量演进
- 每次变更都有完整提案和任务
- 可追溯、可审查、可归档
-
⚡ 效率提升
- 开发时间减少40%
- 返工率降低87%
- Bug数量减少83%
相关资源:
系列文章
- 【Cursor进阶实战·01】Figma设计稿一键还原
- 【Cursor进阶实战·02】告别丑陋界面
- 【Cursor进阶实战·03】四大模式完全指南:Agent/Plan/Debug/Ask的正确打开方式
- 【Cursor进阶实战·04】工作流革命:从"手动驾驶"到"自动驾驶"
- 【Cursor进阶实战·05】复述确认法:让AI先理解再执行,避免"瞎改"代码
- 【Cursor进阶实战·06】MCP生态:让AI突破编辑器边界
感谢阅读!如果这篇文章对你有帮助,欢迎点赞、收藏、分享。我们下期见!👋
有问题欢迎在评论区讨论,我会尽量回复每一条评论。