当CNN遇见Transformer:企业级混合模型的特征可视化与融合攻略

引言:在计算机视觉领域,CNN(卷积神经网络)曾是绝对的"顶流",凭借强大的局部特征提取能力,在图像分类、目标检测等任务中称霸多年;而Transformer的横空出世,以其卓越的全局上下文建模能力,打破了CNN的垄断格局。如今,"强强联合"的混合视觉模型已成为研究与落地的主流,而特征可视化则是解锁其"黑箱"奥秘、优化融合策略的关键钥匙。本文将从"为什么要融合""如何通过可视化看懂融合逻辑""主流融合策略"到"实战应用与未来趋势",用通俗的语言拆解这一前沿技术,帮你快速掌握CNN-Transformer混合模型的核心精髓。

一、先搞懂:CNN与Transformer的"互补密码"
要理解混合模型的价值,首先得明确CNN和Transformer各自的"擅长"与"短板"------这正是融合的核心逻辑。
CNN的优势在于局部感知能力:通过卷积核的滑动采样,能高效捕捉图像的边缘、纹理等低级视觉特征,且具备平移不变性和参数共享的特点,计算效率较高。但它的局限性也很明显:建模长距离依赖关系时需要堆叠大量网络层,导致感受野扩大缓慢,难以理解图像中跨区域的全局语义关联。
Transformer则凭借自注意力机制实现了"全局建模自由":将图像切分为Patch序列后,能直接计算任意两个Patch之间的关联,轻松捕捉全局上下文信息。但它也存在先天不足:缺乏局部归纳偏置,对低级视觉特征的捕捉能力较弱,且计算复杂度随输入尺寸呈平方级增长,在高分辨率图像任务中效率偏低。
正是这种"局部强vs全局强"的互补性,催生了CNN-Transformer混合模型------目标就是实现"1+1>2"的效果,既保留CNN对细节的敏感度,又兼具Transformer对全局的理解力。
二、关键突破口:特征可视化揭开"融合黑箱"
混合模型的性能提升有目共睹,但"为什么这样融合有效""不同层的特征到底在学习什么",仅靠准确率数据无法回答。这时候,特征可视化就成了重要工具,它能将模型内部的抽象特征转化为直观的视觉结果,为融合策略的设计和优化提供依据。
1. 三大核心可视化技术,看懂特征差异
针对CNN-Transformer混合模型,常用的可视化技术主要有三类,各自聚焦不同的分析维度:

-
热力图类可视化:比如Grad-CAM、Grad-CAM++,通过梯度反向传播定位模型的关注区域,能直观对比CNN和Transformer的"注意力焦点"。例如在目标检测任务中,CNN的热力图通常集中在目标的局部边缘,而Transformer的热力图则会覆盖目标整体及周边关联区域。
-
注意力图可视化:包括Attention Rollout等方法,专门用于分析Transformer的自注意力权重分布。通过可视化可以发现,混合模型中的注意力会同时关注局部细节和全局关联,而纯Transformer的注意力分布则相对分散。
-
降维可视化:借助t-SNE、UMAP等算法,将高维特征映射到二维/三维空间,观察不同模型的特征聚类效果。实验表明,混合模型的特征聚类更紧凑、类别边界更清晰,这也是其泛化能力更强的关键原因。
2. 可视化对比:纯模型vs混合模型的特征差异
通过可视化对比,我们能清晰看到混合模型的特征优势:
在浅层特征层面:CNN的特征图能清晰展示边缘、纹理等细节,而Transformer的浅层特征则相对模糊;混合模型会保留CNN的浅层细节特征,为后续分析打下基础。
在深层特征层面:Transformer的特征图能捕捉到目标的全局语义(比如"狗"的整体形态和背景关联),而CNN的深层特征则局限于目标局部;混合模型的深层特征会融合两者优势,既清晰保留目标细节,又能关联全局上下文。
简单来说,对比可视化(CNN vs ViT vs Hybrid)能让我们明确"哪些局部特征需要保留""哪些全局关联需要强化",从而指导融合策略的设计。
三、实战指南:4种主流融合策略,按需选择
基于对特征差异的理解,研究者们提出了多种CNN-Transformer融合策略,从简单到复杂可分为四类,各自有不同的适用场景。
1. 串行融合:先局部再全局,简单高效
核心逻辑:以CNN为"骨干网络"提取局部特征,再将特征图展平为序列输入Transformer进行全局建模,即"CNN(特征提取)→ Transformer(关系建模)"的流程。
典型代表:ViT的变体(用浅层CNN替代Patch投影层)、BoTNet(将ResNet深层的3x3卷积替换为自注意力模块)、DETR(CNN提取特征+Transformer解码预测)。
优势:结构简单,充分利用CNN在低级特征提取上的效率,降低Transformer的计算成本;缺点:前期缺乏全局交互,对需要跨区域推理的任务支持有限。
2. 并行融合:双分支同步处理,信息更丰富
核心逻辑:设计CNN和Transformer两个并行分支,同时处理输入图像,再通过拼接、相加等方式融合两个分支的特征,即"(CNN特征 ⊕ Transformer特征)"。
典型代表:CoAtNet(在同一Block中并行处理MBConv卷积分支和自注意力分支,特征相加融合)、各类双分支检测模型。
优势:能同时捕获局部细节和全局上下文,信息流更丰富;缺点:需要维护两个分支,计算量和参数量显著增加,对硬件资源要求较高。
3. 层级融合:多尺度递进融合,性能最优
核心逻辑:构建类似CNN的层次化特征金字塔,在不同尺度的特征层上引入Transformer模块,实现"局部-全局"的递进式融合,是目前最主流的融合方式。
典型代表:Swin Transformer(通过移位窗口注意力构建层次化特征图,兼容CNN的多尺度设计)、PVT(金字塔结构的Vision Transformer)、CvT(用卷积优化Transformer的Token嵌入)。
优势:兼具多尺度特征提取和全局建模能力,在图像分类、目标检测、分割等任务中均能取得SOTA性能;缺点:结构设计复杂,需要精细调参。
4. 模块替换:轻量改造,快速升级现有模型
核心逻辑:不改变现有CNN的整体结构,仅将某些特定模块替换为Transformer模块,实现"轻量升级"。
典型代表:BoTNet(替换ResNet的深层卷积)、AA-ResNet(在卷积层中插入注意力层)。
优势:实现简单,可直接改造成熟的CNN架构,快速提升性能;缺点:替换的位置和方式需要精心设计,否则可能导致计算成本飙升或性能不升反降。
小技巧:融合策略的选择原则
如果是快速验证想法或资源有限,优先选择串行融合;如果追求极致性能且硬件充足,层级融合是首选;如果需要平衡局部和全局信息,并行融合可作为备选;如果是对现有CNN模型进行升级,模块替换是最高效的方案。
四、落地场景:混合模型的"用武之地"
凭借优异的性能,CNN-Transformer混合模型已在多个领域落地,结合特征可视化技术,进一步提升了应用的可靠性。
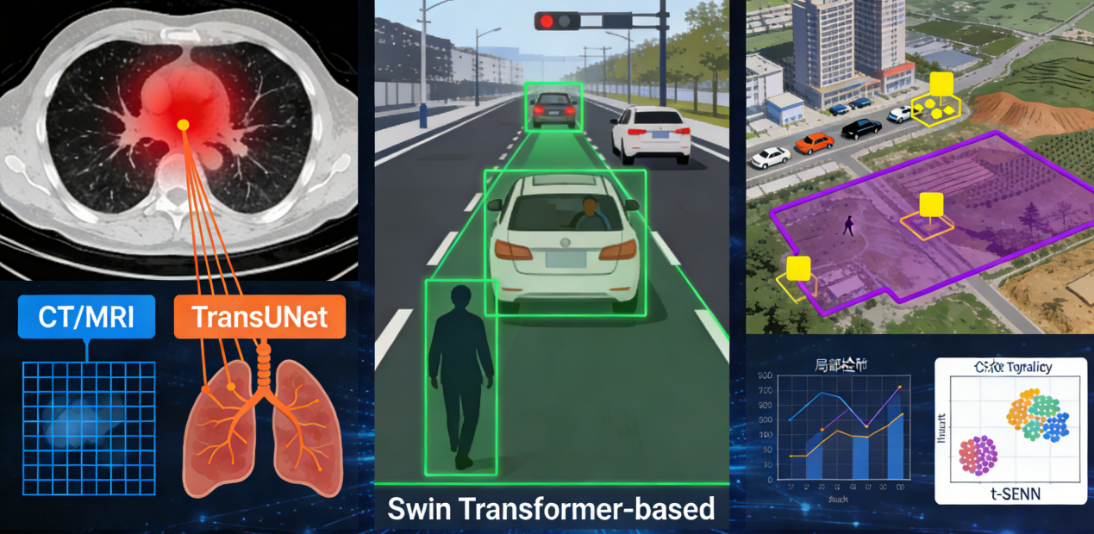
1. 医学图像分析:精准定位病灶
医学图像(如CT、MRI)对细节和全局关联的要求都极高:既要精准捕捉微小病灶(局部特征),又要结合器官整体形态判断病变范围(全局关联)。混合模型如TransUNet,通过CNN提取多尺度特征,Transformer建模全局依赖,再通过融合解码器恢复细节,显著提升了病灶分割的准确率。而特征可视化能帮助医生理解模型的判断依据,提升诊断的可信度。
2. 目标检测与分割:应对复杂场景
在自动驾驶、安防监控等场景中,目标往往存在遮挡、尺度变化大等问题。混合模型如Swin Transformer-based检测器,通过多尺度融合和全局建模,能更好地处理遮挡目标和小目标,而可视化技术可用于调试模型的注意力分布,优化检测效果。
3. 遥感图像理解:覆盖大范围场景
遥感图像通常尺寸大、目标分布分散,需要同时关注局部目标(如建筑物、车辆)和全局场景(如地形、环境)。混合模型能平衡局部细节提取和全局范围建模,结合可视化技术可清晰展示模型对不同区域的关注重点,提升遥感解译的准确性。
五、未来趋势:混合模型的下一个风口
随着研究的深入,CNN-Transformer混合模型正朝着更高效、更可解释、更通用的方向发展,以下几个趋势值得重点关注:
- 视觉基础模型的融合探索:将混合架构与大语言模型结合,实现跨模态的理解与生成,比如图像描述、视觉问答等任务。
- 小样本/零样本迁移:通过混合模型的特征迁移能力,解决小样本场景下的数据不足问题,降低落地成本。
- 能效-精度权衡:设计轻量化混合架构,在保证性能的同时降低计算成本,适配移动端、边缘设备等部署场景。
- 可解释混合架构设计:将特征可视化融入模型设计过程,构建"可解释性优先"的混合模型,提升在医疗、司法等关键领域的可靠性。
- 开源可视化工具普及:Captum、tf-explain、Visdom等工具的完善,将降低特征可视化的使用门槛,让更多开发者能高效优化融合策略。
六、总结:从可视化到融合,核心是"互补与平衡"
CNN与Transformer的融合,本质是局部感知与全局建模的互补;而特征可视化则是理解这种互补性、优化融合策略的关键手段。从串行到层级的融合策略,从医学图像到遥感理解的落地场景,混合模型的发展始终围绕"平衡性能与效率、兼顾细节与全局"的核心目标。
对于开发者而言,无需盲目追求复杂架构,可根据任务需求选择合适的融合策略,再通过特征可视化工具持续调试优化。随着技术的不断成熟,混合模型必将在更多领域释放潜能,推动计算机视觉技术走向更通用、更可靠的未来。