Prometheus 监控 ESXi 实践
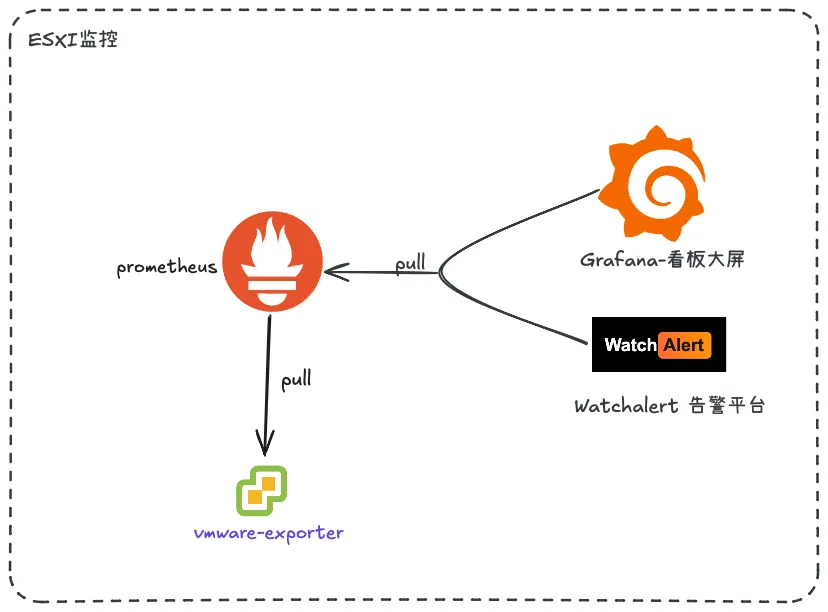
背景与目标
背景
- 数据中心/边缘节点大量使用 VMware ESXi 承载计算资源,稳定性和容量可视化是基础运维诉求。
- 统一监控体系希望纳入 ESXi 与 vCenter 的指标,统一到 Prometheus,前端由 Grafana 呈现。
- 告警统一走内部的 Watchalert 组件,支持告警的聚合、抑制、通知。
目标
- 使用 pryorda/vmware_exporter 采集 ESXi/vCenter 指标,通过 Docker 编排部署
- 将指标接入 Prometheus,并在 Grafana 中构建仪表盘展示
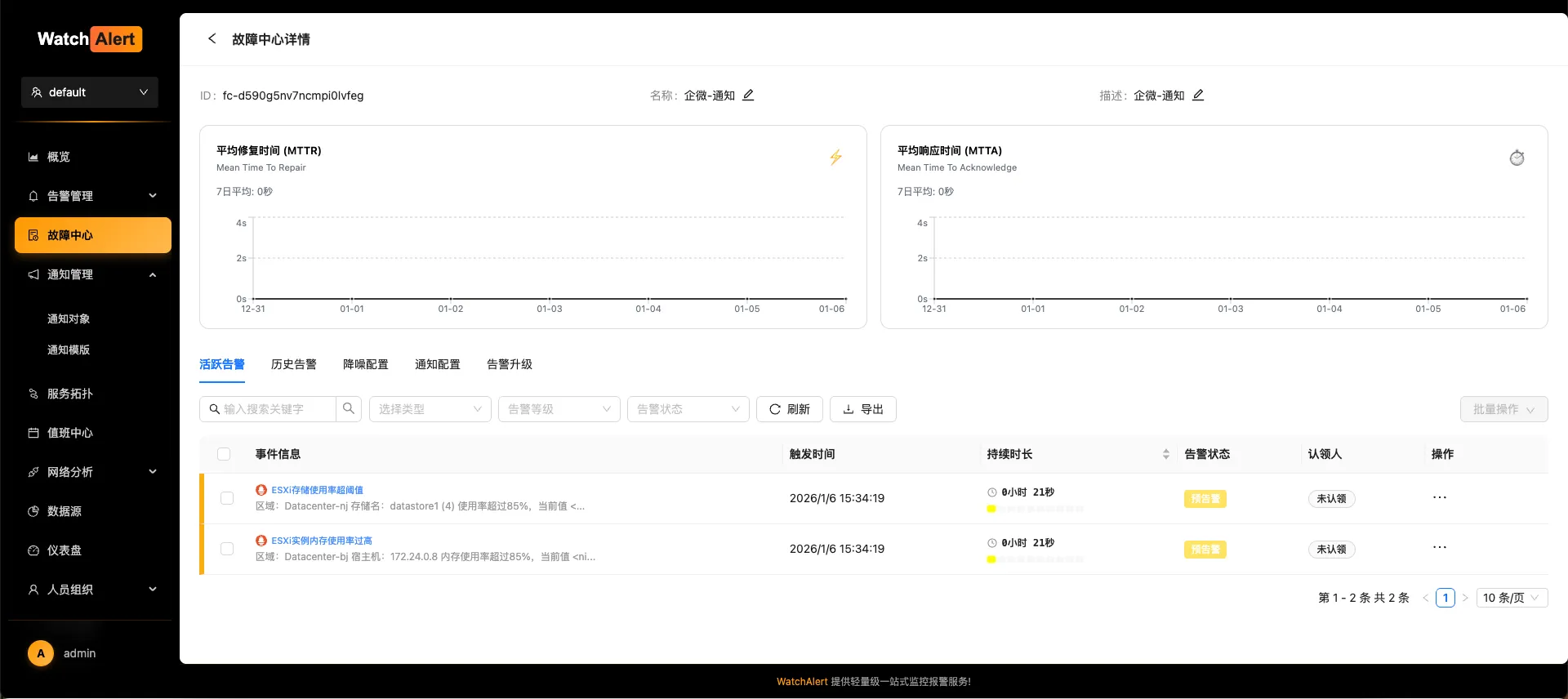
- 通过 Watchalert 完成端到端告警:规则、路由、通知
- 提供可复制的最小实践与运维排障建议
架构设计
组件清单
| 组件名称-版本 | 地址 | 说明 |
|---|---|---|
| vmware_exporter-0.18.4 | https://github.com/pryorda/vmware_exporter | 连接 vCenter 或直接 ESXi,暴露 /metrics |
| Prometheus-3.5.0 LTS | https://prometheus.io/download/ | 抓取 exporter,存储时序数据 |
| Watchalert-3.8.0 | https://github.com/opsre/WatchAlert | 接收 Prometheus数据,配置监控项,告警表达式,webhook 告警通知 |
| Grafana-10.2.3 | https://grafana.com/grafana/download?pg=oss-graf\&plcmt=hero-btn-1 | 可视化查询与仪表盘 |
环境准备
前提条件
- 可访问 vCenter 或 ESXi 的网络连通性与账户(建议只读账户),密码通过环境变量或外部秘密管理(.env / Vault),避免硬编码
- Docker 与 Compose 环境
- 部署好 Prometheus、Watchalert 与Grafana
部署 vmware_exporter(Docker-compose)
- 若编排中已包含 vmware_exporter 服务,确保以下环境变量正确:
-
VSPHERE_HOST:vCenter 或 ESXi 地址
-
VSPHERE_USER:采集账户用户名
-
VSPHERE_PASSWORD:采集账户密码
-
VSPHERE_IGNORE_SSL:自签证书场景设为 true
-
参考 config.env片段(示例)
-
这里演示多集群/多 vCenter,可挂载配置文件到容器中
config-bj.env
VSPHERE_USER=administrator@vsphere.local
VSPHERE_PASSWORD='xxxxxx'
VSPHERE_HOST=172.10.30.1
VSPHERE_IGNORE_SSL=TRUE
VSPHERE_SPECS_SIZE=2000config-nj.env
VSPHERE_USER=administrator@vsphere.local
VSPHERE_PASSWORD='xxxxxx'
VSPHERE_HOST=172.22.33.1
VSPHERE_IGNORE_SSL=TRUE
VSPHERE_SPECS_SIZE=2000
参考 Compose 片段(示例)
yaml
version: '3.8'
services:
vmware_exporter_nj:
#image: pryorda/vmware_exporter:latest
image: docker.cnb.cool/srebro/docker-images-chrom/pryorda-vmware_exporter:latest_amd64 #已配置镜像加速地址
container_name: vmware_exporter_nj
restart: always
ports:
- "9272:9272"
env_file:
- ./config-nj.env
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "9272"] # 检测本地9272端口
interval: 30s # 检测间隔
timeout: 10s # 单次检测超时时间
retries: 3 # 连续失败3次后标记为不健康
start_period: 60s # 启动后60秒开始检测
vmware_exporter_bj:
image: docker.cnb.cool/srebro/docker-images-chrom/pryorda-vmware_exporter:latest_amd64 #已配置镜像加速地址
container_name: vmware_exporter_bj
restart: always
ports:
- "9273:9272" # 主机9273映射容器9272端口
env_file:
- ./config-bj.env
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "9272"] # 检测容器内部9272端口
interval: 30s
timeout: 10s
retries: 3
start_period: 60s启动与健康检查
-
启动后访问,可见看到 vmware_ 前缀的指标
http://
:9272/metrics 和 http:// :9273/metrics -
关注容器日志,确认认证与连接正常,无大量超时
接入 Prometheus
抓取配置
在 Prometheus 的 scrape_configs 中加入 vmware_exporter, ⚠️ 注意自定义标签。
yaml
scrape_configs:
#vmware_exporter
- job_name: 'vmware_vcenter'
metrics_path: '/metrics'
static_configs:
- targets: ['172.22.33.218:9272']
labels:
project_name: "Datacenter-srebro"
nodename: "EXSI-172.1.5.17"
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- source_labels: [__address__]
regex: '.*:9272$'
target_label: datacenter
replacement: 'Datacenter-srebro'
##用于标签值的自定义
metric_relabel_configs:
- action: replace
target_label: host_name
replacement: 'EXSI-172.1.5.17' # 新值
- action: replace
target_label: dc_name
replacement: 'EXSI-172.1.5.17' # 新值初次验证
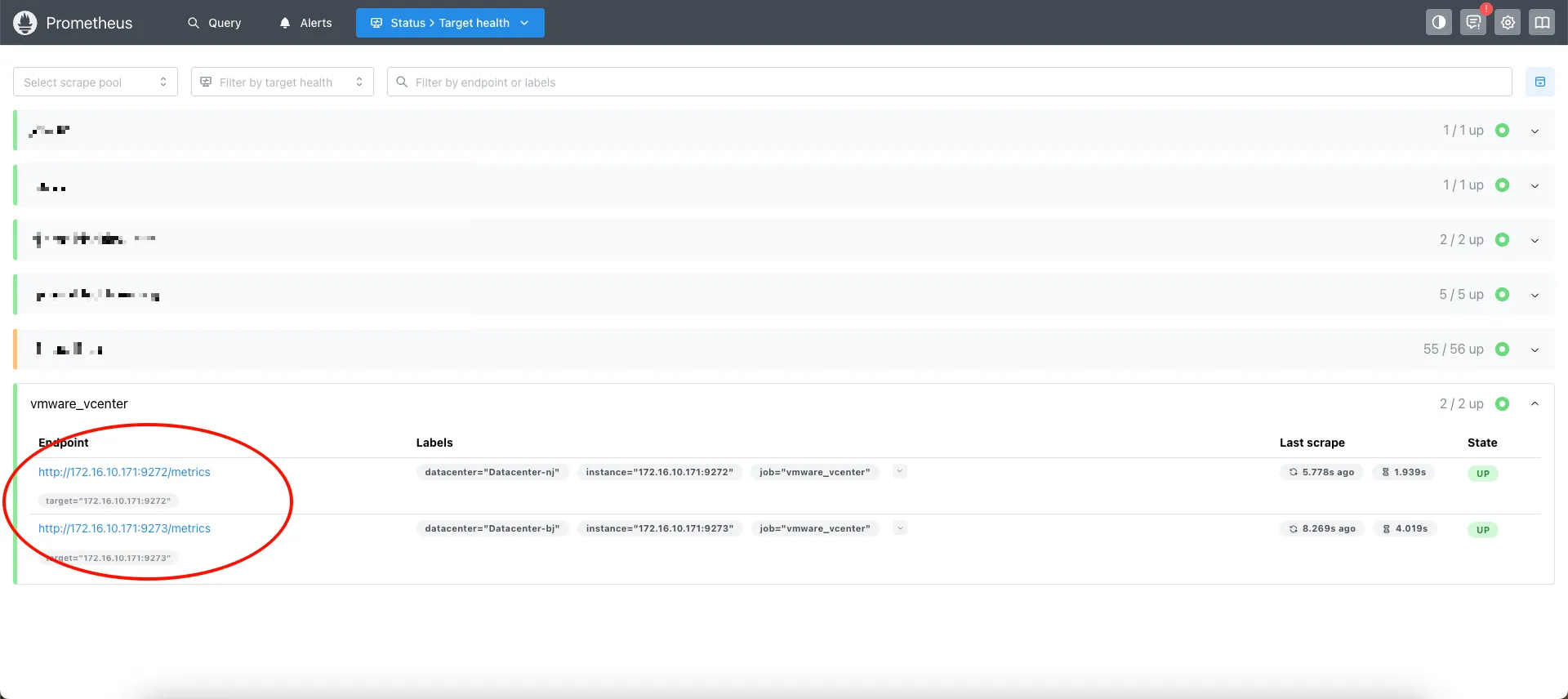
- Prometheus Targets 页面应看到 vmware_exporter 处于 UP 状态
- PromQL 中可以查询 vmware_* 指标前缀数据
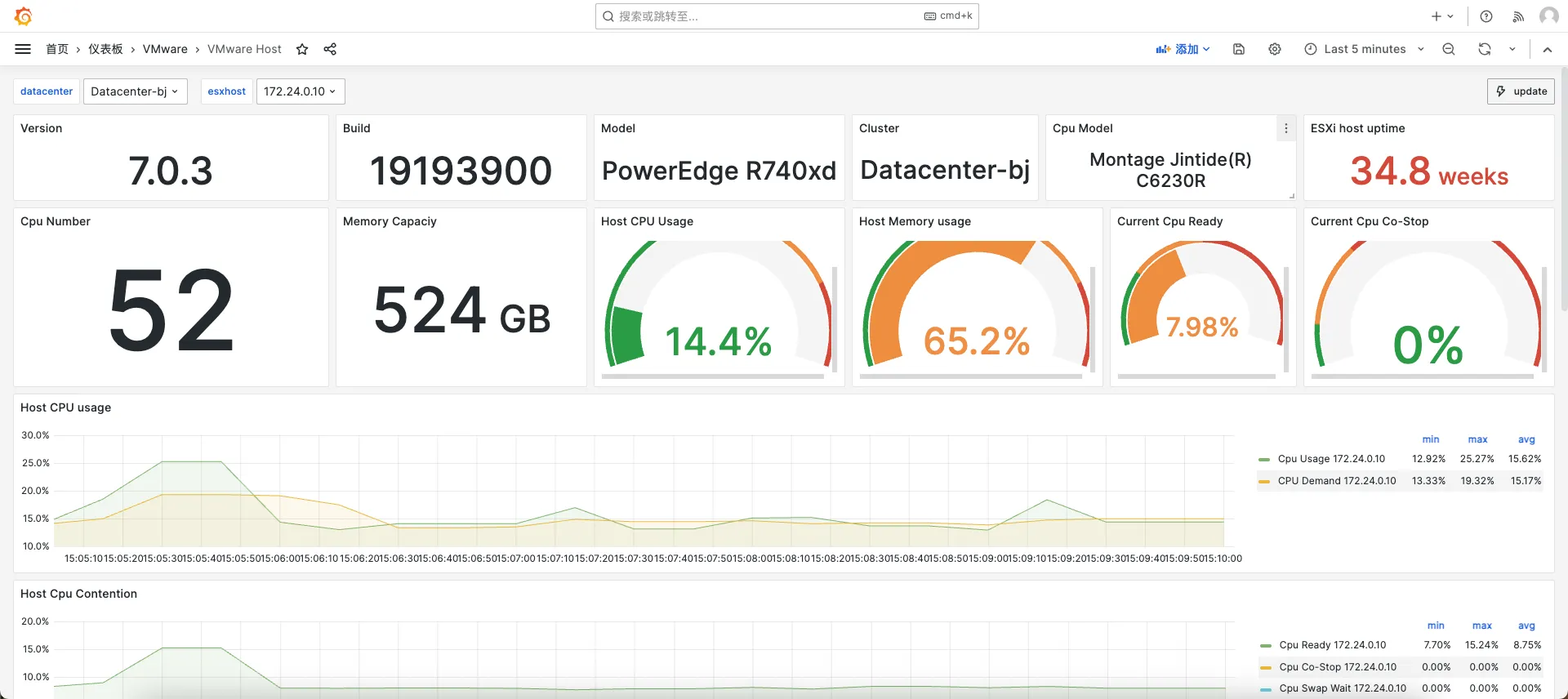
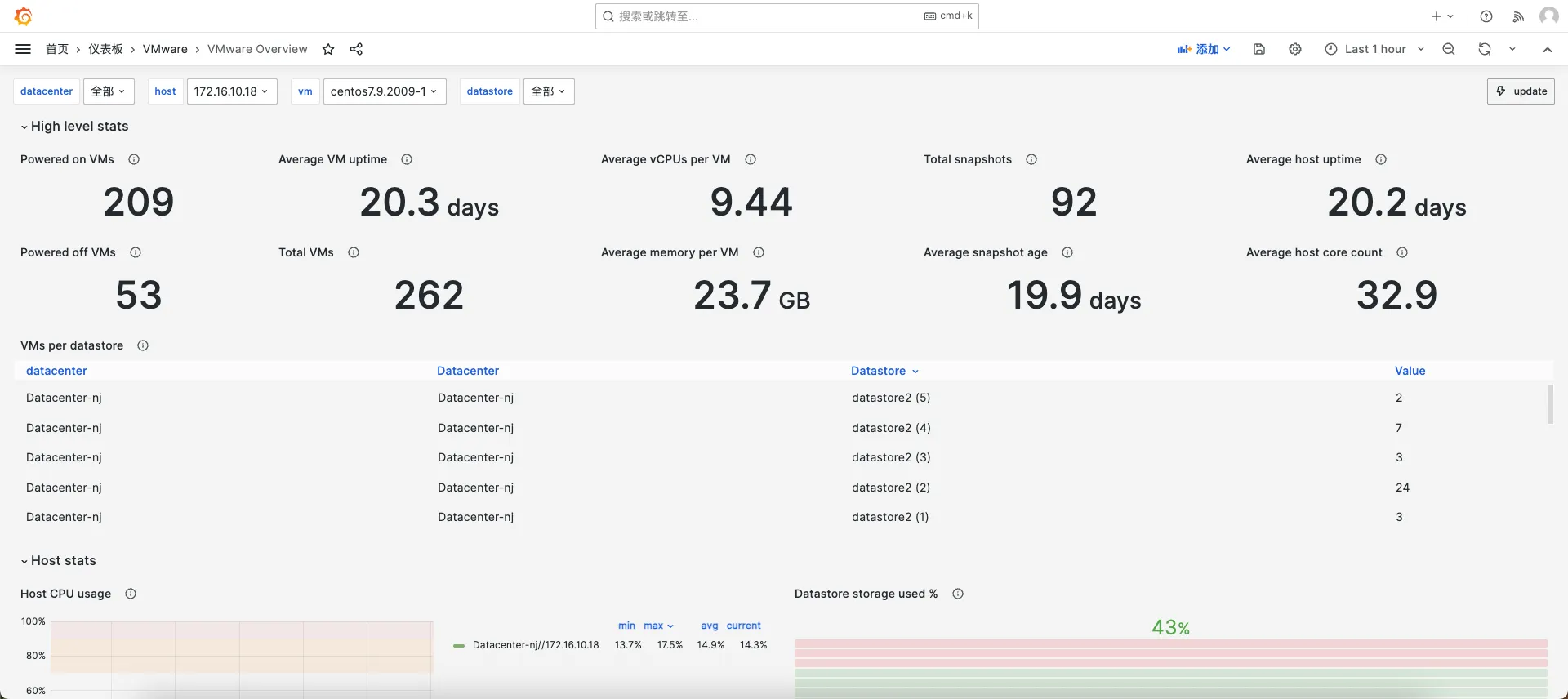
Grafana 图表展示
数据源与仪表盘
- 添加 Prometheus 数据源,指向 Prometheus HTTP 地址。
- 可导入社区仪表盘,
15446和11243,可能需要根据自己的实际情况微调。
告警规则与 Watchalert
- 这里我将提供一个标准的 prometheus 的 rules.yaml 文件,支持一键导入 watchalert 中。可能需要根据自己的实际情况微调。
示例规则(根据实际指标名调整):
yaml
rules:
- alert: ESXI宿主机离线
expr: vmware_host_power_state == 0
for: 30s
labels:
severity: 1
annotations:
summary: "ESXI宿主机离线"
description: "区域:${labels.project_name} 宿主机:${labels.host_name} ESXI宿主机离线,当前值 ${labels.value},请登录vCenter查看"
- alert: ESXi存储使用率超阈值
expr: ((1 - (vmware_datastore_freespace_size / vmware_datastore_capacity_size)) * 100) > 85
for: 1m
labels:
severity: 1
annotations:
summary: "ESXi存储使用率超阈值"
description: "区域:${labels.project_name} 存储名:${labels.ds_name} 使用率超过85%,当前值 ${labels.value}%"
- alert: ESXi虚拟机CPU使用率过高
expr: vmware_vm_cpu_usage_average / 100 >= 85
for: 30s
labels:
severity: 3
annotations:
summary: "ESXi虚拟机CPU使用率过高"
description: "区域:${labels.project_name} 主机:${labels.nodename} CPU使用率超过85%,当前值 ${labels.value}%"
- alert: ESXi虚拟机内存使用率过高
expr: vmware_vm_mem_usage_average / 100 >= 90
for: 30s
labels:
severity: 3
annotations:
summary: "ESXi虚拟机内存使用率过高"
description: "区域:${labels.project_name} 主机:${labels.nodename} 内存使用率超过90%,当前值 ${labels.value}%"
- alert: ESXi实例CPU负载过高
expr: (vmware_host_cpu_usage / vmware_host_cpu_max) * 100 > 70
for: 1m
labels:
severity: 1
annotations:
summary: "ESXi实例CPU负载过高"
description: "区域:${labels.project_name} 宿主机:${labels.host_name} CPU负载超过70%,当前值 ${labels.value}%"
- alert: ESXi实例内存使用率过高
expr: (vmware_host_memory_usage / vmware_host_memory_max) * 100 > 85
for: 30s
labels:
severity: 1
annotations:
summary: "ESXi实例内存使用率过高"
description: "区域:${labels.project_name} 宿主机:${labels.nodename} 内存使用率超过85%,当前值 ${labels.value}%"
- alert: ESXi虚拟机快照数量过多
expr: vmware_vm_snapshots > 5
for: 30s
labels:
severity: 3
annotations:
summary: "ESXi虚拟机快照数量过多"
description: "区域:${labels.project_name} 主机:${labels.nodename} 快照数量超过5个,当前值 ${labels.value}"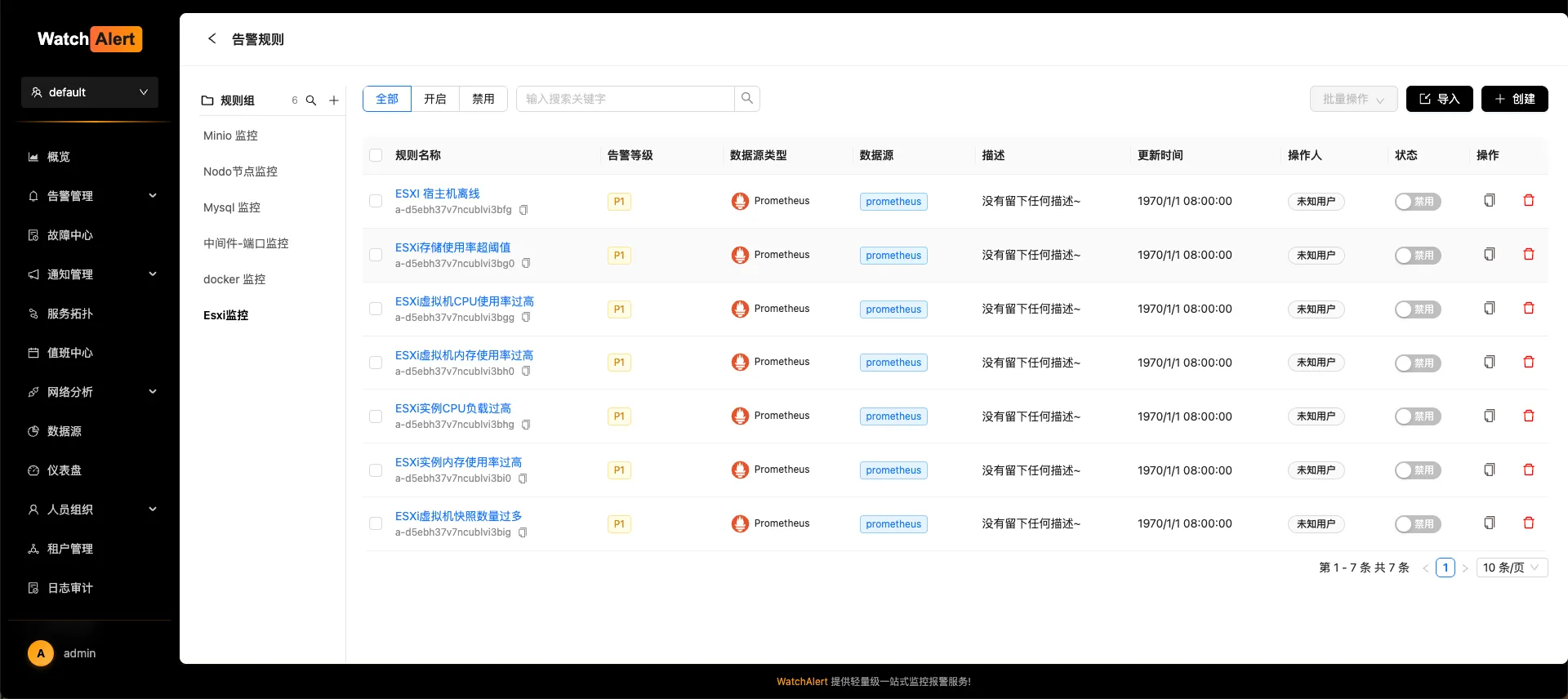

补充: 关于 vmware_exporter 配置鉴权的功能
- 很遗憾,这个https://github.com/pryorda/vmware_exporter 项目并没有提供鉴权的功能
- 我在原项目的基础上,增加了鉴权的功能,代码仓库: https://cnb.cool/sro/vmware_exporter
- 鉴权的镜像地址: docker.cnb.cool/sro/vmware_exporter:0.18.4
- 具体的鉴权使用教程可见: https://cnb.cool/sro/vmware_exporter/-/blob/master/README.md