深度学习 ,就是把我们输入转化一个高维度向量,它通过多层非线性变换,把原始数据(如图像像素,文字序列)逐层转化为高度抽象、可分离性强的特征,最终能让机器了解的模式。这种能力是深度学习的核心突破,也是它超越传统机器学习的关键。
而传统的机器学习依赖人工设计的单层特征(比如用算法提取图像的边缘、颜色分布),特征抽象程度低,难以处理复杂数据,仅适用于结构化数据(表格数据)。
每层都在前一层的特征基础上构建更复杂的特征
输入层 → 隐藏层1 → 隐藏层2 → ... → 输出层
↓ ↓ ↓ ↓
原始数据 → 低级特征 → 中级特征 → 高级特征 → 决策 深度学习的核心突破是:
-
端到端特征学习:无需手工设计特征,直接从原始数据学习
-
层级抽象能力:通过多层非线性变换,逐层构建从简单到复杂的特征表示
-
表征学习:将数据映射到有利于任务解决的特征空间
-
大数据驱动:在大规模数据上自动发现复杂模式和规律
但同时面临挑战:
-
需要大量标注数据
-
计算资源需求高
-
模型可解释性差("黑箱"问题)
-
训练过程不稳定
分类特征
分类特征 是指用于区分不同类别的特征表示。在深度学习中,这是模型最后一层学习到的高级语义特征,能够清晰地将不同类别的样本在特征空间中分离开。
我们可以将以下数据通过模型时,根据不同的要求提取不同的特征。
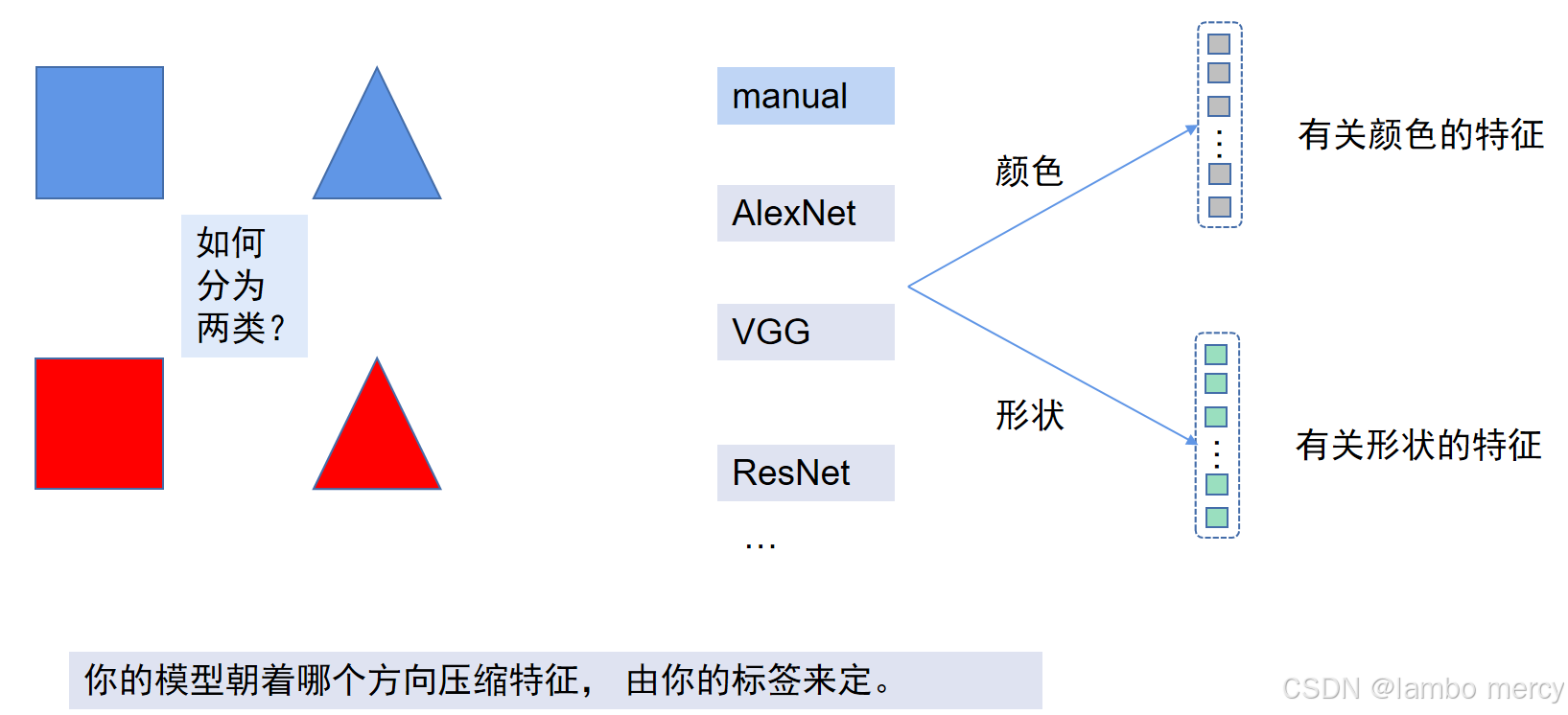
同样,下图若为带标签数据,可以根据不同标签对比,将形状相似的小球,按颜色分为不同的种类。
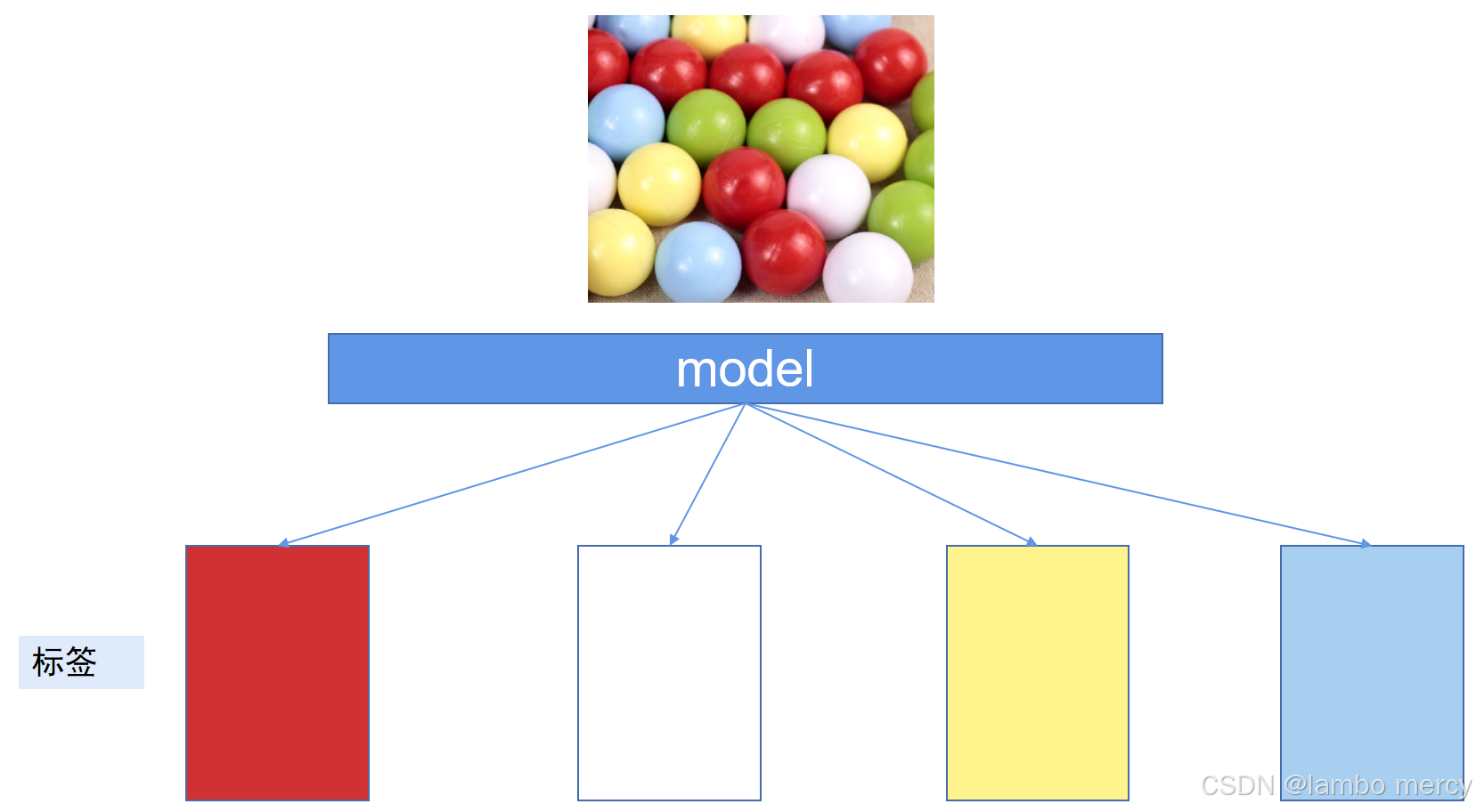
通过这两个例子,我们可以看到模型会根据需要,提取不同的特征。
特征的选择和"划分"并不是发生在一个独立的、显式的步骤里,而是贯穿于整个模型训练过程,尤其是通过前向传播、损失计算和反向传播这个循环,由模型参数(特别是权重w)的优化来动态、隐式地完成的。
权重------"特征选择器"
模型(例如神经网络)的每一层,尤其是第一层或中间的线性/卷积层,其权重矩阵本质上就是一套"特征探测器"或"特征选择器"。
神经元在学习过程中,会调整其连接各个输入的权重。
权重的大小和正负,直接决定了该神经元对上一层哪些输入特征"敏感",以及如何组合这些特征。
一个权重接近0的连接,意味着模型"选择忽略"那个输入特征。
一个权重绝对值很大的连接,意味着模型"高度重视"那个特征。
数据"划分"或"特征选择"的过程,就嵌入在工作流程中:1. 前向传播
在这个阶段,数据特征已经被权重初步筛选和组合了。但此时的权重是初始化的或上一轮迭代更新的,筛选效果可能不好。
关键点 :前向传播是"应用"当前特征选择器的过程,而不是"决定"选择器的过程。它执行了基于当前权重的变换。
2. 损失计算
损失函数 计算出一个标量值,量化当前预测的"糟糕"程度。
不同的损失函数(如均方误差用于回归,交叉熵用于分类)定义了不同的"优化目标"。这个目标就像指挥棒,告诉模型"什么样的特征组合能让我这个损失值变小"。
3. 反向传播 & 梯度下降
这是特征选择真正发生和调整的关键阶段。
计算梯度 :系统通过链式法则,从损失函数开始,向后逐层计算损失相对于每一个权重参数 的梯度。梯度 ∂L/∂w 指明了:为了减小损失,这个权重 w 应该增大还是减小,以及变化的迫切程度。
"划分"的本质 :
如果一个特征在前向传播时,有助于减小损失,那么连接到这个特征的权重的梯度就会比较大。
在接下来的参数更新(如:
w = w - learning_rate * gradient)中,这些权重就会发生显著的调整。经过无数次迭代,对最终任务目标(由损失函数定义)贡献大的特征,其通路上的权重会被强化和精细化;贡献小或造成干扰的特征,其权重会被抑制或趋向于零。
这个过程就是动态的"特征选择"。模型不是提前列一个清单,而是在梯度信号的指引下,不断调整其内部"关注点",最终形成一个复杂的权重网络,这个网络自动实现了对输入数据中最相关特征的提取和组合。
-
没有独立的"划分步骤":特征选择不是像传统机器学习中先做"特征工程筛选"那样有一个独立模块。
-
特征选择是涌现的、内嵌的 :它涌现 于整个端到端的训练过程,内嵌于模型权重之中。
-
驱动力量是损失函数和梯度 :损失函数定义了"好特征"的标准 ,反向传播产生的梯度 提供了调整每个权重以选择这些特征的具体方向和力度。
-
不同阶段:
-
前向传播:使用当前的特征选择器(权重)处理数据。
-
反向传播:根据损失函数的反馈,计算并更新特征选择器(权重),这是"划分"逻辑被调整和确定的时刻。
-
迭代完成:经过充分训练后,稳定的权重矩阵就代表了模型为完成特定任务而学到的"最优特征选择与组合方案"。
-
损失函数是总指挥,它通过梯度回传这个机制,指挥着模型参数(权重)朝着能够提取和利用最有效特征的方向进行调整。 特征的选择,就实现在这些权重的数值里。
我们上面讲的两个例子,都是面对含有的标签的数据进行分类。但现实情况下,因为对数据进行标注的费用较高,大部分的数据都是无标签的数据。那么想要充分利用这些数据,我们该如何处理?
无监督学习
无监督学习没有"老师"(即没有人工标注的标签y)。它的目标是从无标签 的数据X本身中发现内在的结构、模式或分布。
没有了损失函数这个明确的"指挥棒",无监督学习是如何进行"特征选择"或"数据划分"的呢?
答案是:通过设计不同的"内在目标"或"结构假设"。这些目标替代了监督学习中的损失函数,同样通过优化过程来驱动模型学习数据的核心特征,让模型自行发现数据中的隐藏结构。
无监督学习不是"不学习",而是学习数据自身的"故事"。它通过以下几种主要范式来实现,每一种都对应着一种不同的"特征选择"哲学:
1. 重构与压缩
核心思想 :要求模型学习一种高效的"数据表示",使得从这个表示能尽可能好地重建原始数据。
-
代表性模型:自编码器、PCA(主成分分析)。
-
特征选择如何发生:
-
编码器 将高维输入数据压缩到一个低维的潜空间。
-
这个压缩过程强制模型必须做出选择:只能保留那些最重要的、最具信息量的特征。
-
哪些特征被保留?那些对于重建数据最关键的特征,通常是数据中变化最大、最能区分不同样本的方向(在PCA中就是最大方差的方向)。
-
损失函数:重建误差(如均方误差)。通过最小化重建误差,模型学习到数据的"本质特征"。
-
PCA
PCA的主要目的是降维,它的核心思想是通过线性变换找到数据中方差最大的方向(即主成分,对于重建数据最关键的特征),并依此对数据进行投影和降维。
PCA可以间接帮助预防过拟合,其用于线性变换,无法处理复杂的非线性关系。
PCA基于方差最大的方向进行降维,但方差不一定代表信息,不一定为最有用的方向。
PCA降维之后,系统可能会丢失数据的局部信息。
重构式学习就是让AI学会"用最少的笔墨,抓住事物的神韵"。通过强迫它用有限的信息重建原始数据,它必须学会什么才是数据中真正重要的东西------这就是特征选择的本质。
2. 聚类与分组
核心思想 :假设数据可以根据其内在的相似性划分为若干个组(簇),使得同一组内的数据尽可能相似,不同组间的数据尽可能不同。
-
代表性模型:K-Means,层次聚类,DBSCAN
-
特征选择如何发生:
-
聚类算法在计算相似度时,隐式地赋予了所有输入特征权重。
-
如果某些特征对于区分簇是无关的噪声,它们会"稀释"距离计算,导致聚类效果变差。
-
特征的选择/加权是通过距离度量 和簇中心迭代更新来实现的。好的聚类结果本身就意味着模型找到了能有效分离簇的那些特征维度组合。
-
"损失函数":簇内距离之和(如K-Means的惯性)。最小化这个目标,就是寻找使数据点紧密围绕簇中心的那种特征空间表达。
-
这是一种归类的核心思想,和我们人类学习的时候一样,当一个小孩子第一次看到猫和狗的时候,他并不清楚他们是什么,但却会抓取不同动物之间的"特征",下次见到不同的猫和狗的时候,根据这些特征将他们进行分类。
聚类与分组的主要思想也是这样,将相同类的特征靠的更近一些,之后通过大量的数据进行分析总结,找到规律生成"标签"。
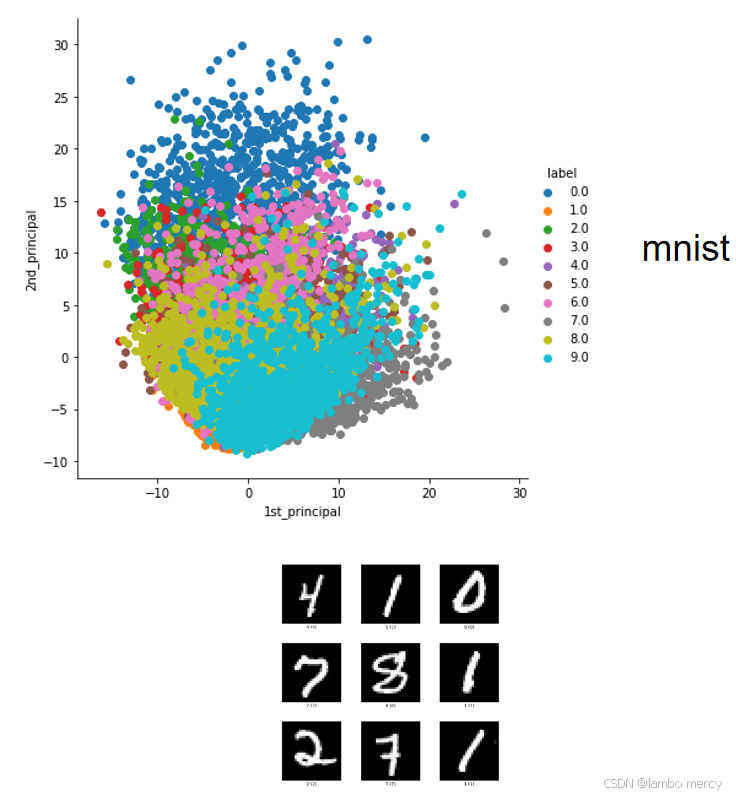
上图中,通过 PCA 降维后展示了不同数字(标签 0-9)的分布,核心目的是观察不同类别(数字)的聚集状态、类别间的重叠程度。
3. 生成与建模
核心思想 :学习整个数据集的概率分布 P(X)。学会之后,不仅可以理解现有数据,还能生成新的、类似的数据。
-
代表性模型:生成对抗网络,变分自编码器,扩散模型。
-
特征选择如何发生:
-
为了生成逼真的数据,模型必须抓住数据最根本的统计规律和特征。
-
例如,在GAN中,生成器 的目标是生成数据,欺骗判别器;判别器的目标是区分真实数据和生成数据。两者的对抗博弈,迫使生成器发现并模仿真实数据分布中的关键特征(如人脸图像中的对称性、五官布局等)。
-
在VAE中,编码器学习将数据映射到潜空间的分布参数(均值和方差),解码器从这个分布中采样并重建。模型被约束学习一个平滑、结构化的潜空间,其中的每个维度都对应着数据的某个有意义的、解耦的特征(如人脸的表情、光照、姿态)
-
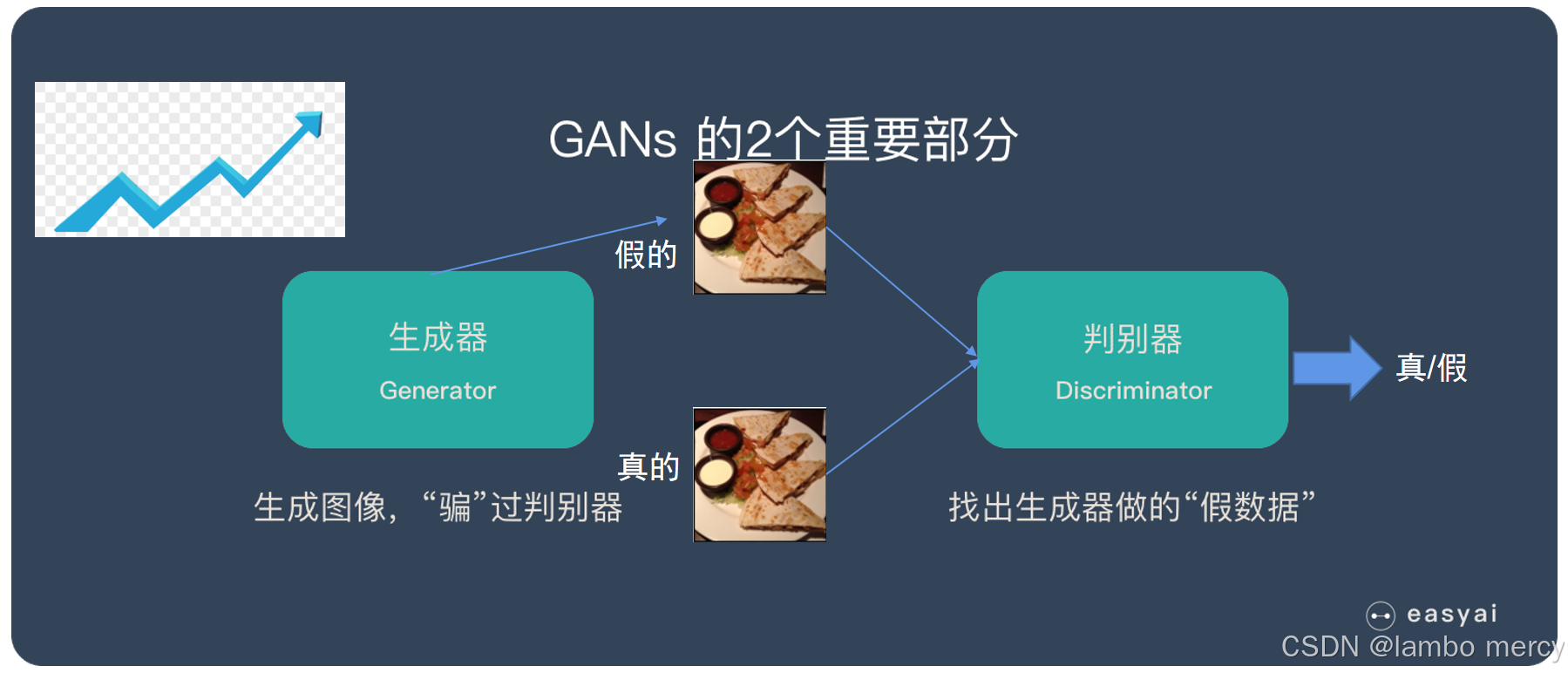
生成对抗网络GANs
生成对抗网络(GANs) 是一种深度学习模型,由两个神经网络(生成器和判别器)通过对抗训练的方式学习数据分布,从而生成逼真的新数据。GANs的核心思想是"博弈论中的零和游戏",生成器和判别器相互竞争,最终达到动态平衡。
生成对抗网络之前常常用于生成动漫人物头像,先通过大量数据集,分析并提取风格特征(如眼睛大小,夸张表情等),之后通过生成器("负责造假")模仿风格特征进行生成类似图片,判别器("负责打假")判断是否为生成器"造假"的图片,双方不断进行测试优化,最终达到一种"左脚踩右脚升天"的效果。
GAN具有以下缺点:
- "内耗式训练"太折腾。GAN这种对抗模式,必须控制好双方的动态平衡,否则很容易导致一方失衡,如判别器梯度消失,进而导致二者都崩溃。
- "想象力"太有限。GAN因为容易陷入崩溃,就像训练数据集中,有100种发型,但GAN 只能掌握10种,其他的直接"摆烂"崩溃。
- GAN的"可控性"太差,GAN只能进行模仿风格,无法像扩散模型那样,根据文本引导,精准控制生成内容。
- GAN的"胃口大",训练GAN需要大量的数据进行"投喂",使用门槛较高。
- GAN的"创新能力差",无法像扩散模型一样使用多模态任务(文字+图像),而且扩散模型还能生成一些未见过的概念。
扩散模型
简单介绍一下,扩散模型(Diffusion Models)的几个优点:
- 训练更稳:不需要两个网络打架,直接学数据分布。
- 质量更高:生成图片细节更丰富,几乎没有GAN的伪影。
- 控制更细:通过文字、草图等多维度控制生成结果。
- 脑洞更大:能组合没见过的事物(如"机械熊猫弹钢琴")。

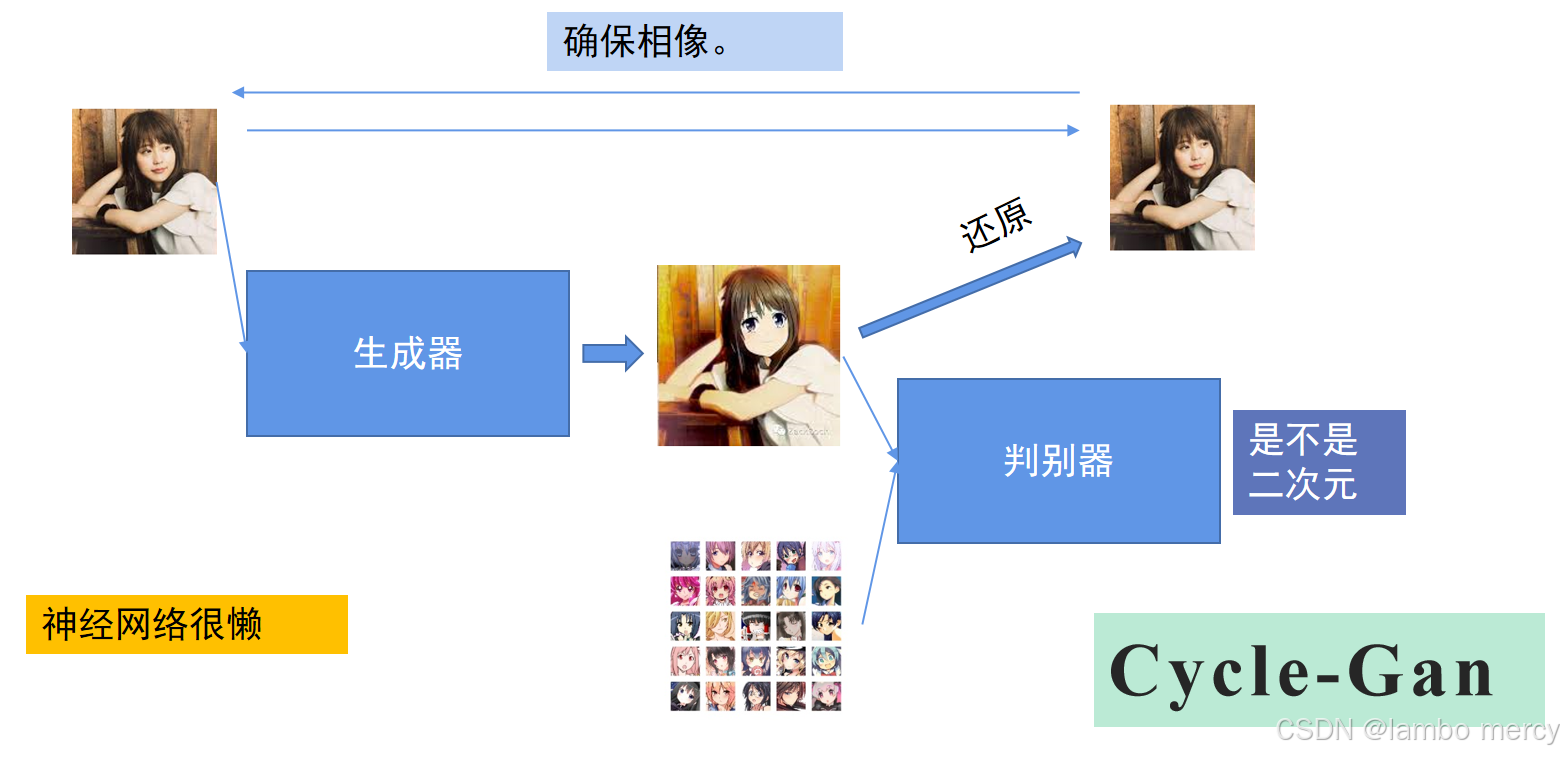
CycleGAN
CycleGAN 是一种用于无监督图像到图像转换的生成对抗网络(GAN),其核心特点是无需成对数据 即可实现跨域转换(如将马→斑马、照片→油画)。
传统的GAN的大部分图像转换任务(如照片->素描)需要成对数据(同一场景的照片和素描),可现实中很难获取到这类数据,但CycleGAN仅需要两个不同域的大量未匹配图像(如一堆马的照片 + 一堆斑马的照片),即可学会互相转换。
CycleGAN 模型架构: 两对生成器 + 判别器
CycleGAN的工作流程中,最重要的一步就是,当将原始图片改动后,除去判断外,还需要将改动后的图片改回原始图片。这个步骤可以让生成的图片确保相像,经过不断的训练最终训练出"只改风格不改内容"的流程技巧。
变分自编码器VAE
VAE的工作机制:三步法
第一步:编码------理解"这幅猫图的配方"
第二步:采样------从"配方分布"中抽取具体值
第三步:解码------用"配方值"画出新猫
观察很多猫的图片
总结猫的"统计学特征"
平均脸型
眼睛大小的变化范围
毛色的常见分布
建立一个"猫的配方本"
用配方生成新的猫
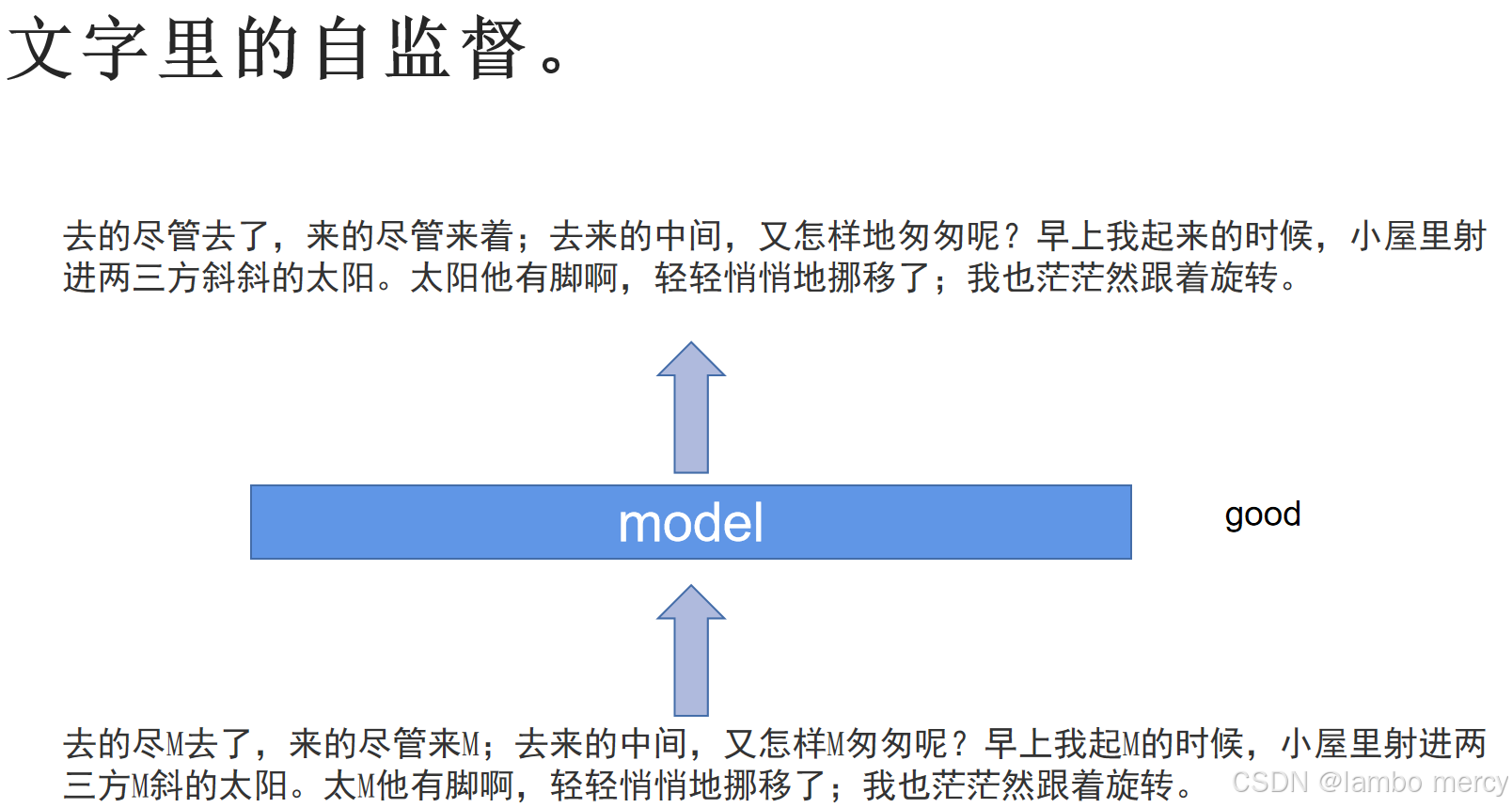
4. 自监督学习
核心思想 :这是无监督学习中最前沿和强大的范式。它自动生成伪标签,从而将无监督问题转化为监督问题来学习强大的特征表示。
-
代表性方法:遮蔽语言建模(BERT),对比学习。
-
特征选择如何发生:
-
以BERT为例 :随机遮盖句子中的一些词,让模型根据上下文来预测被遮盖的词。为了准确预测,模型必须深入理解语言的语法、语义和上下文关系。这驱动它学习到极其丰富的语言特征。
-
以对比学习(SimCLR, MoCo)为例 :对同一张图像做两种不同的随机变换(裁剪、变色等),得到两个"正样本对"。目标是让模型学会这两个不同视角下的特征是相似的,而与其他图像 的特征是不同的。这个过程迫使模型忽略无关的变换(如颜色偏移),而抓住图像的本质内容特征(如物体的形状、结构)。
-
"损失函数":交叉熵损失(预测遮盖词)、对比损失(InfoNCE)。
-
对比学习
对比学习可能是无监督学习中最直观、最符合人类认知的方式。让我们用一个生活中的类比来理解它。
对比学习的基本过程
看到一只老虎(锚点样本)
看到另一只老虎(正样本) → 它们应该是相似的
看到一只斑马(负样本) → 它应该与老虎不相似
你不需要有人告诉你"这是猫科动物"、"这是马科动物"。仅仅通过比较,你就能开始理解:
"这两只条纹大猫很像彼此"
"那只条纹大猫和黑白条纹的马很不一样"

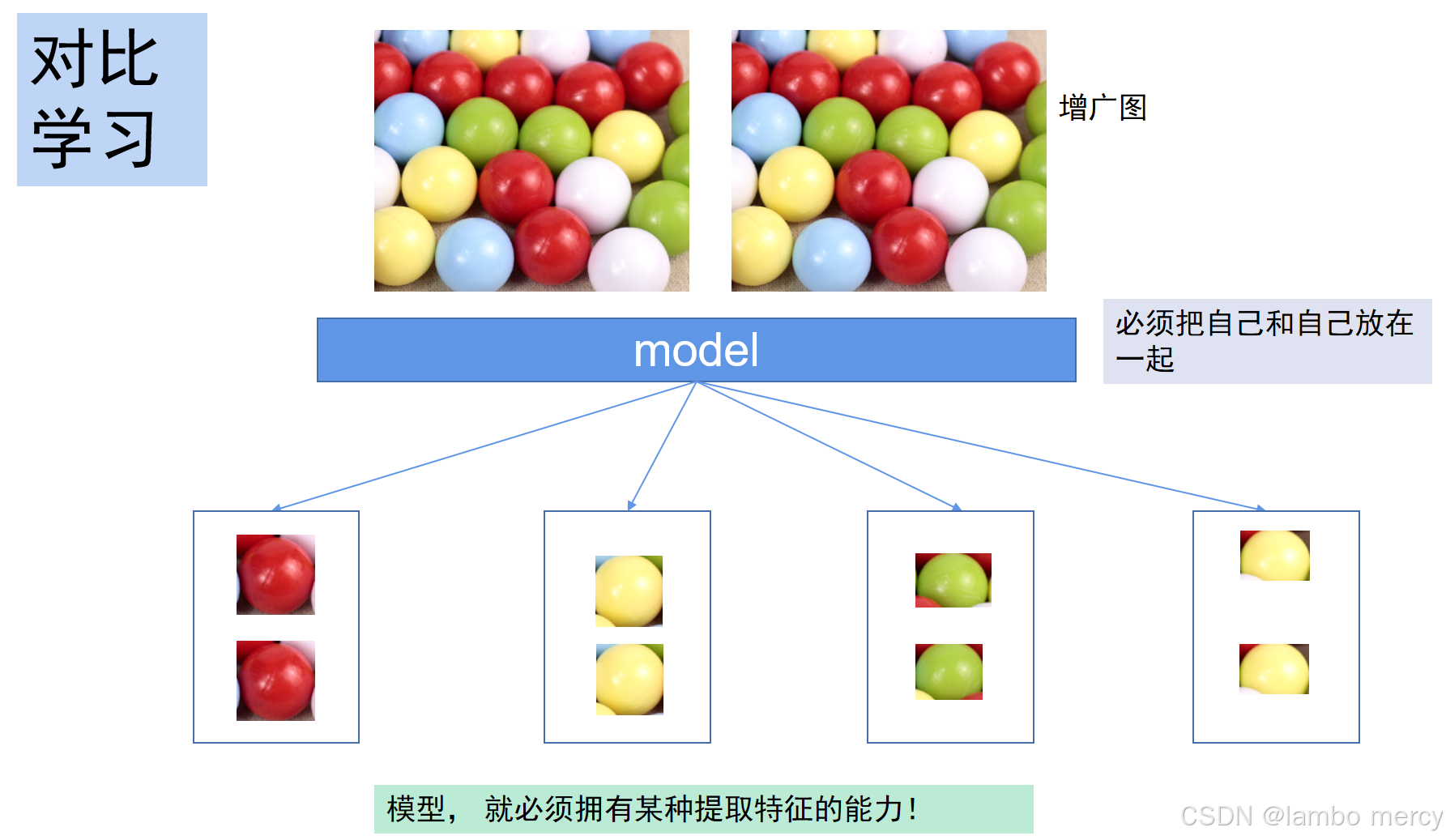
对比学习(Contrastive Learning)的核心思想是,通过拉近相似样本、推开不相似样本,学习数据的有用表示。即将相似的样本放在一起,不相似的样本进行分类放置。这种方法需要大量负样本,价格成本高,但十分适合大规模训练。
如下图,如果模型没有一点模型提取能力,就会把各个颜色的球给乱放,但使用了对比学习后就不一样了。使用对比学习,会将原图片进行增广,之后将自己与自己的增广放在一起,通过这种"靠近"和"远离"提高模型的提取特征能力。
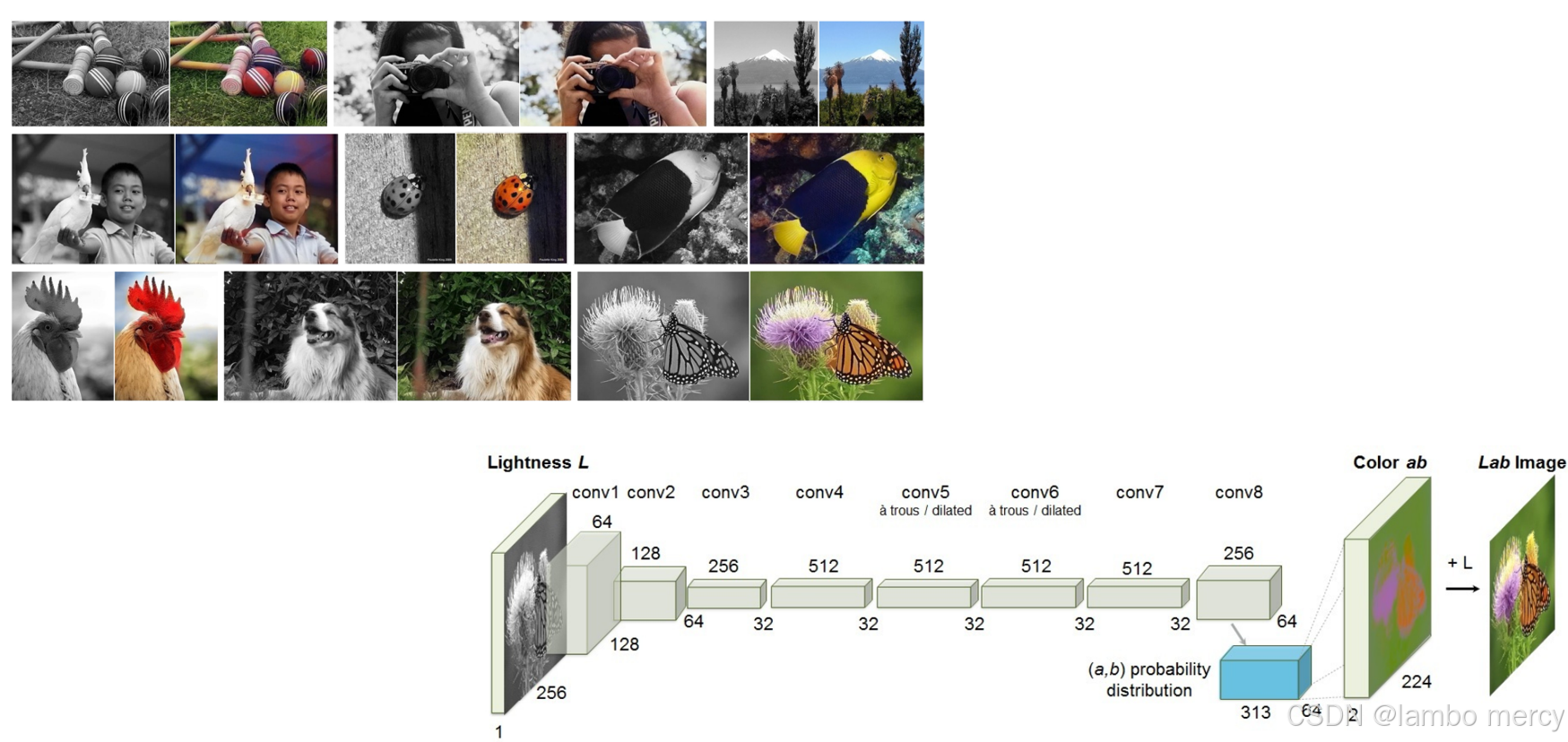
自监督学习(Generative Self-Supervised Learning)是一种让模型从数据本身生成监督信号的学习方法。它不需要人工标注的标签,而是通过设计巧妙的"任务"(称为代理任务或前置任务),让模型在完成这些任务的过程中,学习到对后续任务有用的特征。即把自己的一部分当作学习的目标。如下图,就是通过使用灰色照片还原出原本的彩色照片。
掩码预测(Masked Prediction)就是通过遮掩住自身的一部分当作学习目标,来训练模型的提取特征能力。
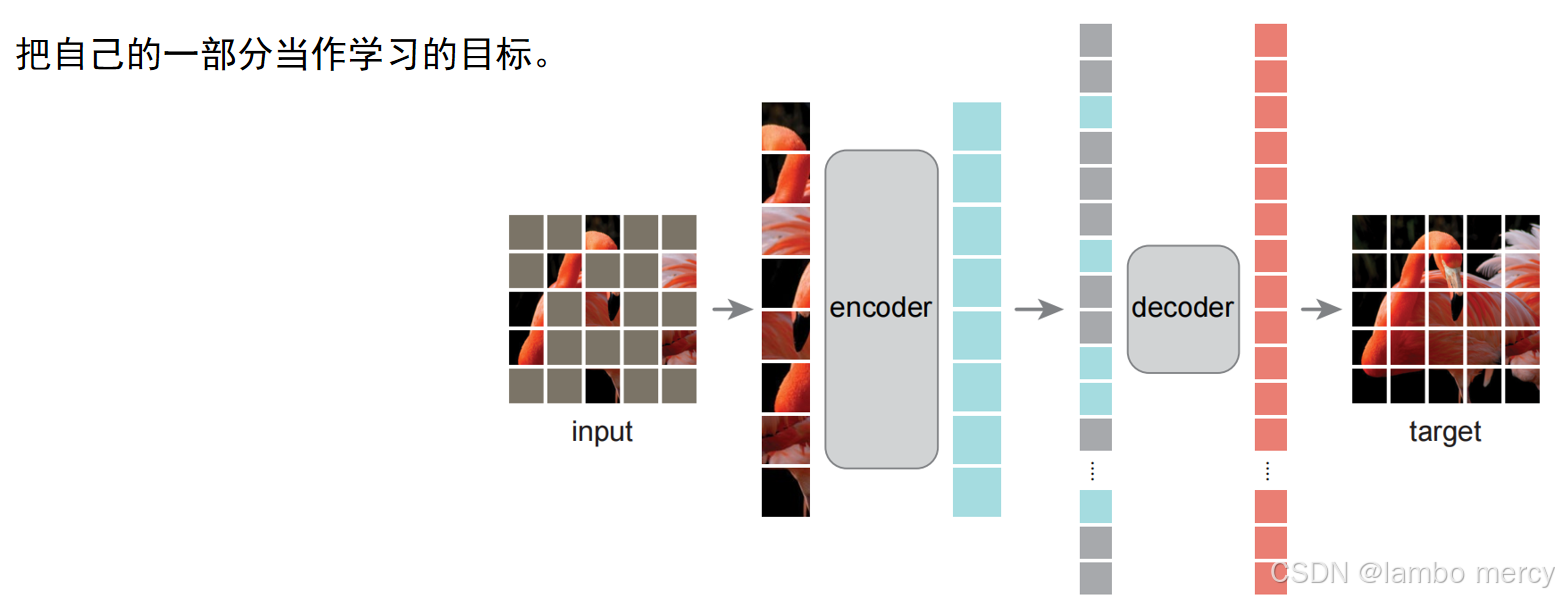
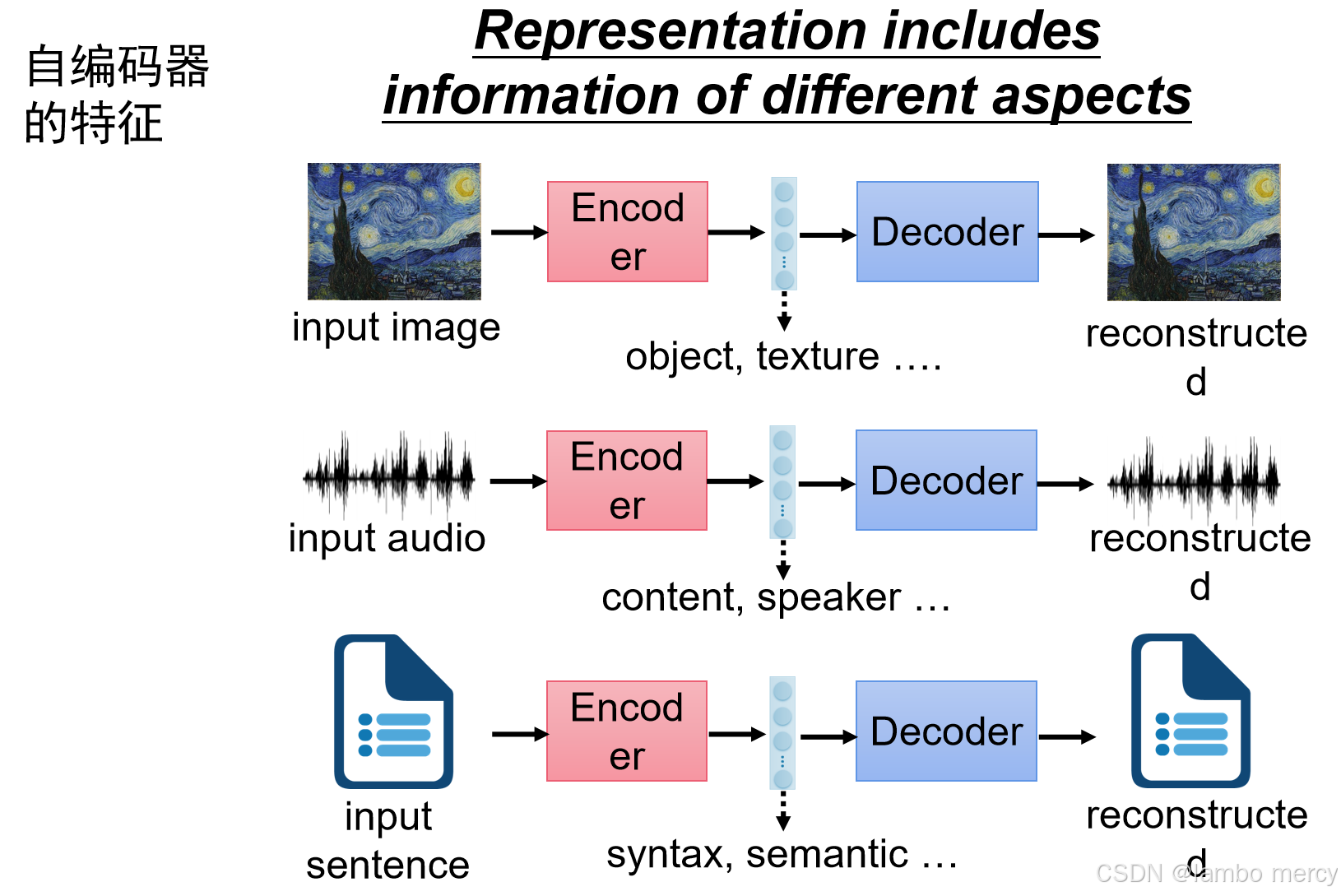
还有 自编码器(Autoencoder, AE),将数据压缩再还原,像"过隧道"一样学习特征。
通过使用编码器,将图片转化为代码,而解码器则需要根据代码重新画图。下图就是通过,自编码器,将特征分类并重组,最后生成出一些不同的内容。
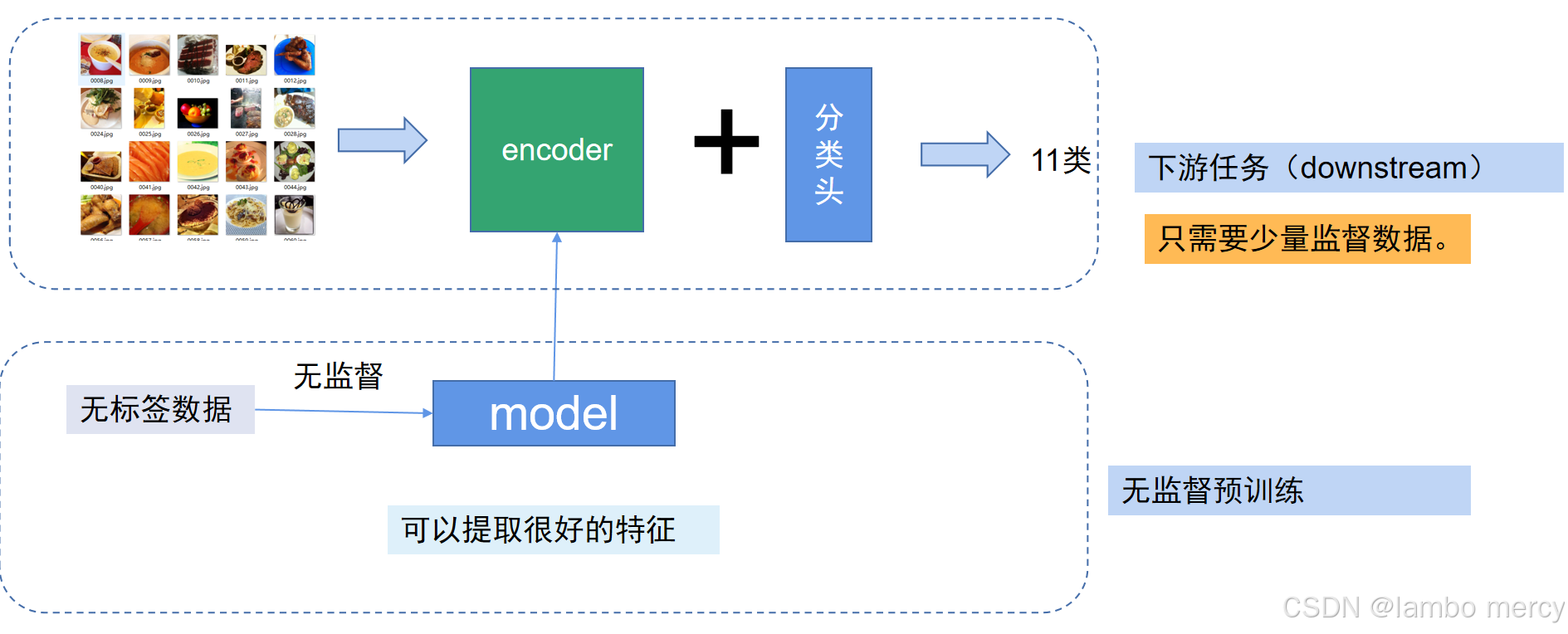
特征分离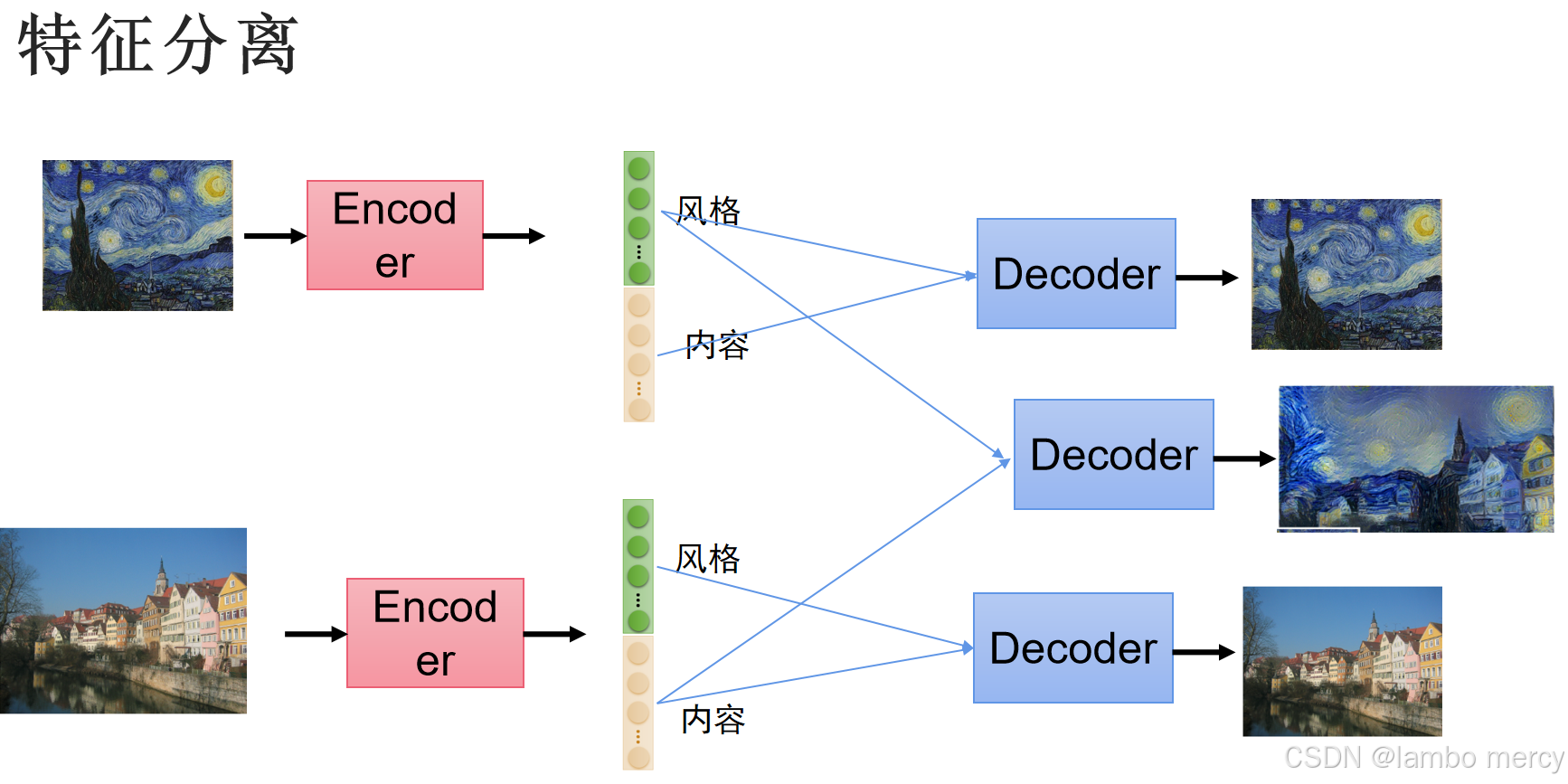
原本的无标签数据经过无监督学习进入模型后,可以提取到很好的特征。这个模型,我们就可以作为编码器与分类头一起使用去进行分类操作。除此之外,我们拥有提取特征的能力后,还可以应用到很多解决实际问题的方面,如 回归任务,生成任务,问答推理等,而这个解决实际问题的过程,我们称作下游任务(Downstream Task)
而通过无标签数据让模型预先学习通用特征,为后续的特定任务(如分类、检测)奠定基础的策略,我们称作无监督预训练(Unsupervised Pretraining) ,ChatGPT中的P就是指预训练。
总结
