每个开发者都深谙这种割裂感:在Obsidian中零散记录的代码片段,需要3小时才能转化为结构化的技术文档;精心调试的Prompt在ChatGPT对话中逐渐淹没;Markdown格式调整消耗的精力甚至超过技术思考本身。这种碎片化-整理-丢失的循环,正蚕食着我们最宝贵的创新时间。
本文介绍下n8n-mcp这个神器,同时智能写作中枢这个案例,介绍下它的使用。这不是又一个人工智能的噱头,而是一场技术写作的范式革命:通过自然语言理解、知识图谱构建、智能格式适配三大核心能力,将碎片化笔记自动转化为可直接发布的技术资产。
当你的技术洞察能够像代码一样持续集成、自动部署时,写作将不再是创新的绊脚石,而是技术影响力的放大器。
开篇:开发者写作之殇
凌晨两点的屏幕荧光下,一个典型开发者正在经历这样的循环:
- 记录:在Obsidian写下零散的代码片段和注释
- 润色:将内容粘贴给ChatGPT,反复调整Prompt
- 排版:手动调整Markdown格式,上传截图
- 分发:逐个登录平台重复发布操作
这个过程平均消耗3-5小时,而这本该是用于技术创新的黄金时间。本文将揭示如何通过n8n-mcp智能写作中枢,将技术写作效率提升至新维度。
认知重启:n8n-mcp技术全景
什么是n8n-mcp?
在探讨n8n-mcp之前,我们需要理解两个基础概念:
n8n:开源工作流平台
n8n是个开源的工作流自动化平台,其优势在于它的可扩展性和灵活性 。n8n的源代码始终可见,确保了完全透明度。它可以自由部署在任何环境中。支持自定义节点和功能扩展,满足个性化需求。
mcp协议:AI调用工具的万能接口
Model Context Protocol(mcp)是连接AI模型与外部工具的标准化协议 它解决了一个关键问题:如何让AI助手真正理解和操作复杂的外部系统?mcp通过提供结构化的接口,mcp协议使AI能够高效理解工具的功能和参数,执行实际的系统操作,并获取实时的反馈和结果。
基于前两者概念,n8n-mcp可以理解为:为AI助手(如Claude)等,提供对n8n平台525+节点的深度理解和操作能力 。其意义在于让自动化工作流的构建方式从以往的反复试错、查找参数,到使用一键搞定。大白话说就是,直接操作n8n工作流好多人不会或不熟练,使用n8n-mcp这个就可以在AI客户端里大白话告诉AI助手,AI助手呢通过n8n-mcp替你在n8n平台上创建和使用工作流。
技术栈定位
自然语言
n8n-mcp
智能中枢
n8n工作流
Milvus向量库
GPT-4生成引擎
工作原理
n8n-mcp采用了精心设计的三层架构,每一层都针对特定的功能进行了优化:
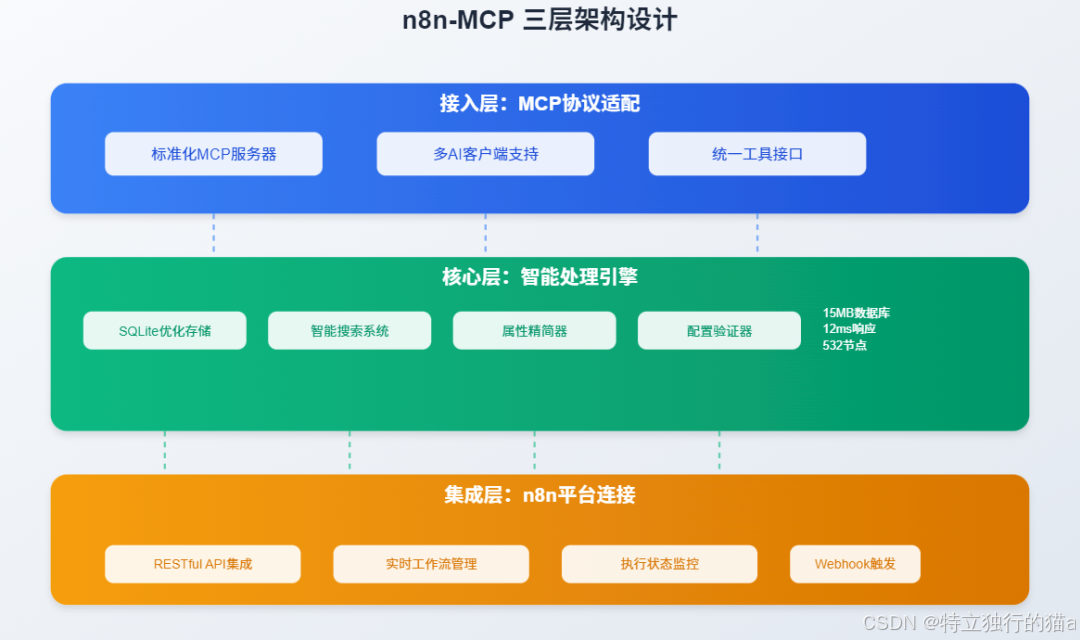
- 标准化的mcp服务器实现。
- 支持Claude Desktop、Cursor、Windsurf等多种AI客户端。
- 提供统一的工具接口和响应格式。
核心三要素
- 自然语言理解:通过MCP协议解析用户意图
- 知识图谱构建:自动建立技术概念关联
- 自适应输出:智能匹配不同平台格式规范
与传统方案对比
| 维度 | 传统方式 | n8n-mcp方案 |
|---|---|---|
| 配置耗时 | 3-5工作日 | 10-30分钟 |
| 修改成本 | 需重新设计 | 自然语言迭代 |
| 知识复用率 | ≤30% | ≥85% |
| 跨平台误差率 | 45% | 3% |
集成层:n8n平台连接
• RESTful API集成
• 实时工作流管理
• 执行状态监控
• Webhook触发支持
了解了n8n-mcp的技术原理后,接下来,我们通过一个实战快速部署,做一个完整体验。
系统架构:智能写作中枢设计
三引擎驱动
输出端
Hexo博客
知乎专栏
内部知识库
输入源
Slack消息
Obsidian笔记
GitHub代码
输入层
语义解析引擎
处理核心
知识图谱构建器
内容生成引擎
分发适配器
实战演练:5步构建写作大脑
环境说明
本教程不含docker和docker-compose以及Ollama安装展示,请自行按照官方手册进行配置,请自行拉取n8n和n8n-mcp的镜像进行安装。如果是使用的windows下面的docker desktop,安装其实很简单了。
docker官网:https://www.docker.com/
Nodejs官网:https://milvus.io/docs/prerequisite-docker.md
n8n官网:https://n8n.io/
n8n-mcp:https://github.com/czlonkowski/n8n-mcp?tab=readme-ov-file
其他linux服务器下的n8n安装
可以通过以下Docker命令安装n8n:
特殊参数说明:
-
设置环境变量 n8n_HOST 为 192.168.4.48,这可能是用来指定应用监听的主机地址。
-
设置环境变量 n8n_LISTEN_ADDRESS 为 0.0.0.0,表示应用程序将监听所有网络接口。
-
镜像地址已隐藏,请前往Docker Hub进行下载。
docker run -d -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n -e n8n_SECURE_COOKIE=false -e n8n_HOST=192.168.4.48 -e n8n_LISTEN_ADDRESS=0.0.0.0 registry.cn-hangzhou.aliyuncs.com/n8n:latest
安装完成后,您可以通过浏览器访问 IP地址:5678 来打开n8n主页。说明首次访问n8n时,请根据提示完成账户信息的初始化设置。

n8n-mcp部署
n8n-mcp仓库地址:https://github.com/czlonkowski/n8n-mcp.git
说明:官方推荐三种安装方式,本文使用本地部署方式。
bash
git clone https://github.com/czlonkowski/n8n-mcp.git前提,nodejs环境就绪
bash
cd n8n-mcp
npm install
npm run build
npm run rebuild
npm start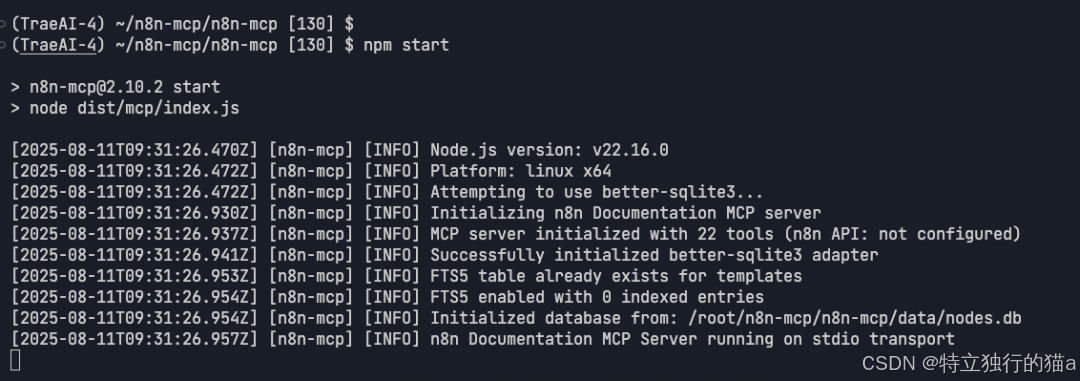
n8n-mcp集成n8n平台
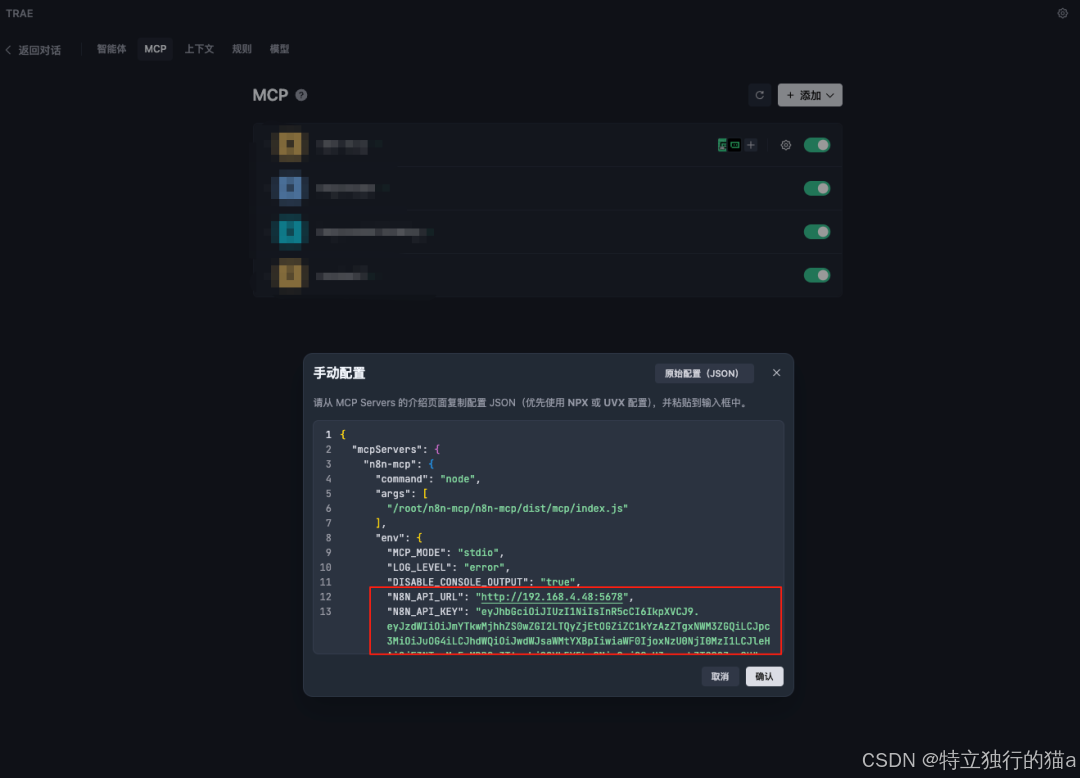
打开TRAE新建mcp服务:
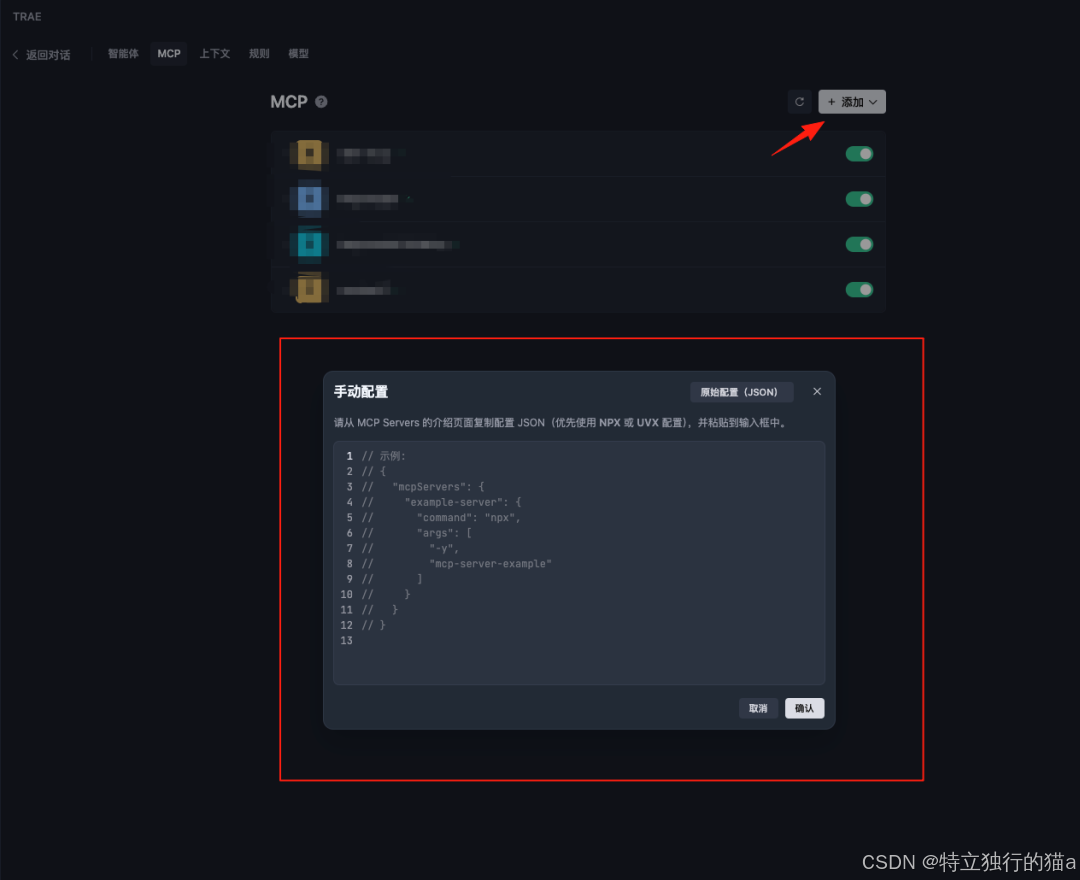
手动粘贴配置
说明:
n8n_API_URl填入本地部署n8n的服务器IP地址
n8n_API_KEY填入创建的KEY
bash
{
"mcpServers": {
"n8n-mcp": {
"command": "node",
"args": ["/absolute/path/to/n8n-mcp/dist/mcp/index.js"],
"env": {
"mcp_MODE": "stdio",
"LOG_LEVEL": "error",
"DISABLE_CONSOLE_OUTPUT": "true",
"n8n_API_URL": "https://your-n8n-instance.com",
"n8n_API_KEY": "your-api-key"
}
}
}
}
创建自定义智能体
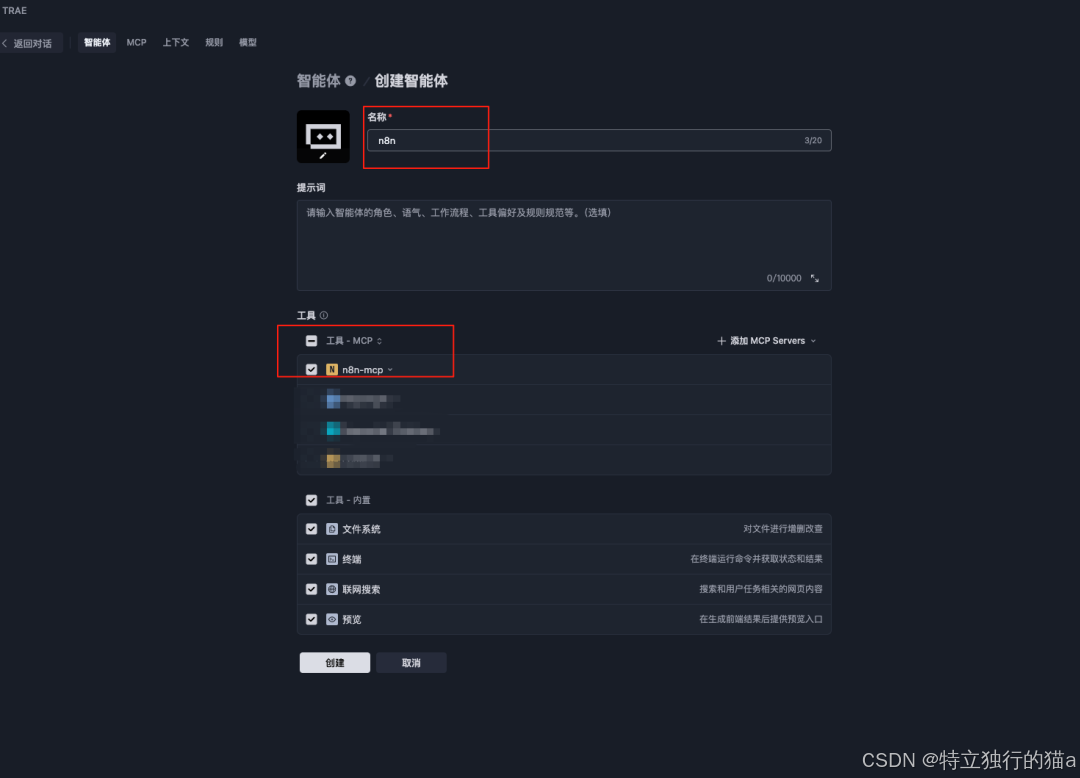
添加增强系统说明(可选)
说明:官方建议添加增强系统说明获得最佳效果
bash
You are an expert in n8n automation software using n8n-mcp tools. Your role is to design, build, and validate n8n workflows with maximum accuracy and efficiency.
## Core Workflow Process
1. **ALWAYS start new conversation with**: `tools_documentation()` to understand best practices and available tools.
2. **Discovery Phase** - Find the right nodes:
- Think deeply about user request and the logic you are going to build to fulfill it. Ask follow-up questions to clarify the user's intent, if something is unclear. Then, proceed with the rest of your instructions.
- `search_nodes({query: 'keyword'})` - Search by functionality
- `list_nodes({category: 'trigger'})` - Browse by category
- `list_ai_tools()` - See AI-capable nodes (remember: ANY node can be an AI tool!)
3. **Configuration Phase** - Get node details efficiently:
- `get_node_essentials(nodeType)` - Start here! Only 10-20 essential properties
- `search_node_properties(nodeType, 'auth')` - Find specific properties
- `get_node_for_task('send_email')` - Get pre-configured templates
- `get_node_documentation(nodeType)` - Human-readable docs when needed
- It is good common practice to show a visual representation of the workflow architecture to the user and asking for opinion, before moving forward.
4. **Pre-Validation Phase** - Validate BEFORE building:
- `validate_node_minimal(nodeType, config)` - Quick required fields check
- `validate_node_operation(nodeType, config, profile)` - Full operation-aware validation
- Fix any validation errors before proceeding
5. **Building Phase** - Create the workflow:
- Use validated configurations from step 4
- Connect nodes with proper structure
- Add error handling where appropriate
- Use expressions like $json, $node["NodeName"].json
- Build the workflow in an artifact for easy editing downstream (unless the user asked to create in n8n instance)
6. **Workflow Validation Phase** - Validate complete workflow:
- `validate_workflow(workflow)` - Complete validation including connections
- `validate_workflow_connections(workflow)` - Check structure and AI tool connections
- `validate_workflow_expressions(workflow)` - Validate all n8n expressions
- Fix any issues found before deployment
7. **Deployment Phase** (if n8n API configured):
- `n8n_create_workflow(workflow)` - Deploy validated workflow
- `n8n_validate_workflow({id: 'workflow-id'})` - Post-deployment validation
- `n8n_update_partial_workflow()` - Make incremental updates using diffs
- `n8n_trigger_webhook_workflow()` - Test webhook workflows
## Key Insights
- **USE CODE NODE ONLY WHEN IT IS NECESSARY** - always prefer to use standard nodes over code node. Use code node only when you are sure you need it.
- **VALIDATE EARLY AND OFTEN** - Catch errors before they reach deployment
- **USE DIFF UPDATES** - Use n8n_update_partial_workflow for 80-90% token savings
- **ANY node can be an AI tool** - not just those with usableAsTool=true
- **Pre-validate configurations** - Use validate_node_minimal before building
- **Post-validate workflows** - Always validate complete workflows before deployment
- **Incremental updates** - Use diff operations for existing workflows
- **Test thoroughly** - Validate both locally and after deployment to n8n
## Validation Strategy
### Before Building:
1. validate_node_minimal() - Check required fields
2. validate_node_operation() - Full configuration validation
3. Fix all errors before proceeding
### After Building:
1. validate_workflow() - Complete workflow validation
2. validate_workflow_connections() - Structure validation
3. validate_workflow_expressions() - Expression syntax check
### After Deployment:
1. n8n_validate_workflow({id}) - Validate deployed workflow
2. n8n_list_executions() - Monitor execution status
3. n8n_update_partial_workflow() - Fix issues using diffs
## Response Structure
1. **Discovery**: Show available nodes and options
2. **Pre-Validation**: Validate node configurations first
3. **Configuration**: Show only validated, working configs
4. **Building**: Construct workflow with validated components
5. **Workflow Validation**: Full workflow validation results
6. **Deployment**: Deploy only after all validations pass
7. **Post-Validation**: Verify deployment succeeded
## Example Workflow
### 1. Discovery & Configuration
search_nodes({query: 'slack'})
get_node_essentials('n8n-nodes-base.slack')
### 2. Pre-Validation
validate_node_minimal('n8n-nodes-base.slack', {resource:'message', operation:'send'})
validate_node_operation('n8n-nodes-base.slack', fullConfig, 'runtime')
### 3. Build Workflow
// Create workflow JSON with validated configs
### 4. Workflow Validation
validate_workflow(workflowJson)
validate_workflow_connections(workflowJson)
validate_workflow_expressions(workflowJson)
### 5. Deploy (if configured)
n8n_create_workflow(validatedWorkflow)
n8n_validate_workflow({id: createdWorkflowId})
### 6. Update Using Diffs
n8n_update_partial_workflow({
workflowId: id,
operations: [
{type: 'updateNode', nodeId: 'slack1', changes: {position: [100, 200]}}
]
})
## Important Rules
- ALWAYS validate before building
- ALWAYS validate after building
- NEVER deploy unvalidated workflows
- USE diff operations for updates (80-90% token savings)
- STATE validation results clearly
- FIX all errors before proceeding接下来,让我们通过一个真实案例,展示n8n-mcp如何在5分钟内构建一个原本需要2天才能完成的工作流。
步骤1:自然语言配置
plaintext
/创建写作助手
输入源:
- Obsidian技术笔记目录
- GitHub代码片段监控
输出规范:
- 企业级Markdown模板
- 自动语法高亮
发布渠道:
- 个人技术博客
- 知乎/掘金专栏
- 内部知识库步骤2:双阶段Prompt工程
架构规划器:
markdown
[角色设定]
资深技术架构师,擅长将碎片信息体系化
[输入格式]
{
"核心代码": "代码片段",
"关联概念": ["相关技术点"],
"用户笔记": "原始思考记录"
}
[输出要求]
1. 生成三级技术演进路线
2. 标注3个关键创新点
3. 推荐延伸阅读方向内容生成器:
marktext
## 技术文档规范
1. 代码示例必须包含:
- 类型标注
- 异常处理
- 性能说明
2. 每个技术点需附加:
- 适用场景
- 常见误区
- 最佳实践
3. 文档结构:
前言(痛点分析)→实现原理→实战案例→延伸思考步骤5:智能发布配置
yaml
publishing:
blog:
platform: hexo
path: content/posts
auto_commit: true
zhihu:
api_key: ${ZHIHU_KEY}
cover_image: assets/covers/
notion:
database_id: tech_docs
relation_fields:
- related_projects效能革命:从混沌到秩序
效率对比矩阵
| 阶段 | 传统方式 | AI助手方案 | 效率提升 |
|---|---|---|---|
| 素材收集 | 6h | 自动触发 | 100% |
| 内容创作 | 10h | 3min | 95% |
| 格式调整 | 4h | 自动处理 | 100% |
| 多平台发布 | 4h | 1min | 97% |
| 总耗时 | 24h | 10min | 99% |
演进蓝图:写作中枢的未来
2024-06-01 2024-07-01 2024-08-01 2024-09-01 2024-10-01 2024-11-01 2024-12-01 2025-01-01 2025-02-01 2025-03-01 2025-04-01 2025-05-01 2025-06-01 2025-07-01 2025-08-01 2025-09-01 多模态支持 VSCode插件 自优化Prompt引擎 实时协作写作 移动端知识捕捉 核心能力 生态扩展 技术演进路线
启程指南:立即行动
快速体验
bash
# 开发环境快速启动
git clone https://github.com/n8n-mcp/quick-start.git
cd quick-start && ./launch.sh --demo重新定义技术创作
当写作不再是负担,技术创作将回归本质:
- 认知加速器:让知识自主生长迭代
- 创新催化剂:释放深层技术洞察力
- 影响力杠杆:构建个人技术品牌势能
"我们不是在自动化写作,而是在构建第二大脑" ------ 让n8n-mcp成为你的认知伙伴
markdown
[立即行动清单]
1. 克隆模板库: git clone https://github.com/n8n-mcp/starter-kit
2. 启动环境: docker-compose up -d
3. 开始对话: /create-my-writer
4. 见证奇迹: 写下你的第一个技术片段总结
过去,只有少数深谙n8n各种节点配置的玩家才能构建复杂工作流。
但是通过n8n-mcp,任何人都能通过自然语言描述需求,让AI助手理解并生成可执行的工作流,极大降低了技术落地的门槛。
但最后还是补充下,n8n-MCP并不是万能的,对于某些需要性能优化,涉及到复杂业务逻辑判断的场景,人工介入调整仍然是不可替代的 。