敏捷开发中的PingCode实践:史诗-特性-用户故事-任务全流程管理指南
前言
在敏捷开发实践中,需求的有效管理是项目成功的关键。PingCode作为国内专业的敏捷项目管理工具,支持Scrum和Kanban等敏捷开发框架,在2021年被36氪评为研发管理领域Top1。本指南将系统讲解如何在PingCode中运用史诗(Epic)、特性(Feature)、用户故事(User Story)、任务(Task)的层级结构进行敏捷需求管理,帮助团队建立标准化的研发管理流程。
第一部分:理解需求层级体系
1.1 为什么需要需求分层管理
在复杂的产品开发中,如果所有需求都平铺在一个待办列表中,团队将面临以下挑战:
挑战1: 战略迷失
- 无法追溯需求与业务目标的关联
- 团队成员不清楚为什么做这个功能
- 难以评估工作对业务的真实价值
挑战2: 沟通障碍
- 产品经理说的"功能"和开发理解的"任务"不在一个层面
- 跨团队协作时缺乏统一的需求语言
- 需求评审会议冗长且低效
挑战3: 规划混乱
- 大需求和小任务混在一起难以估算
- 无法有效制定版本发布计划
- 资源分配不合理
需求分层管理的价值:
- 战略对齐: 确保每个任务都服务于更高层级的业务目标
- 清晰沟通: 建立团队统一的需求语言体系
- 灵活规划: 支持从年度规划到日常任务的多层次计划
- 渐进明细: 按需细化需求,避免过早设计
- 价值可视: 清晰展示价值交付的路径
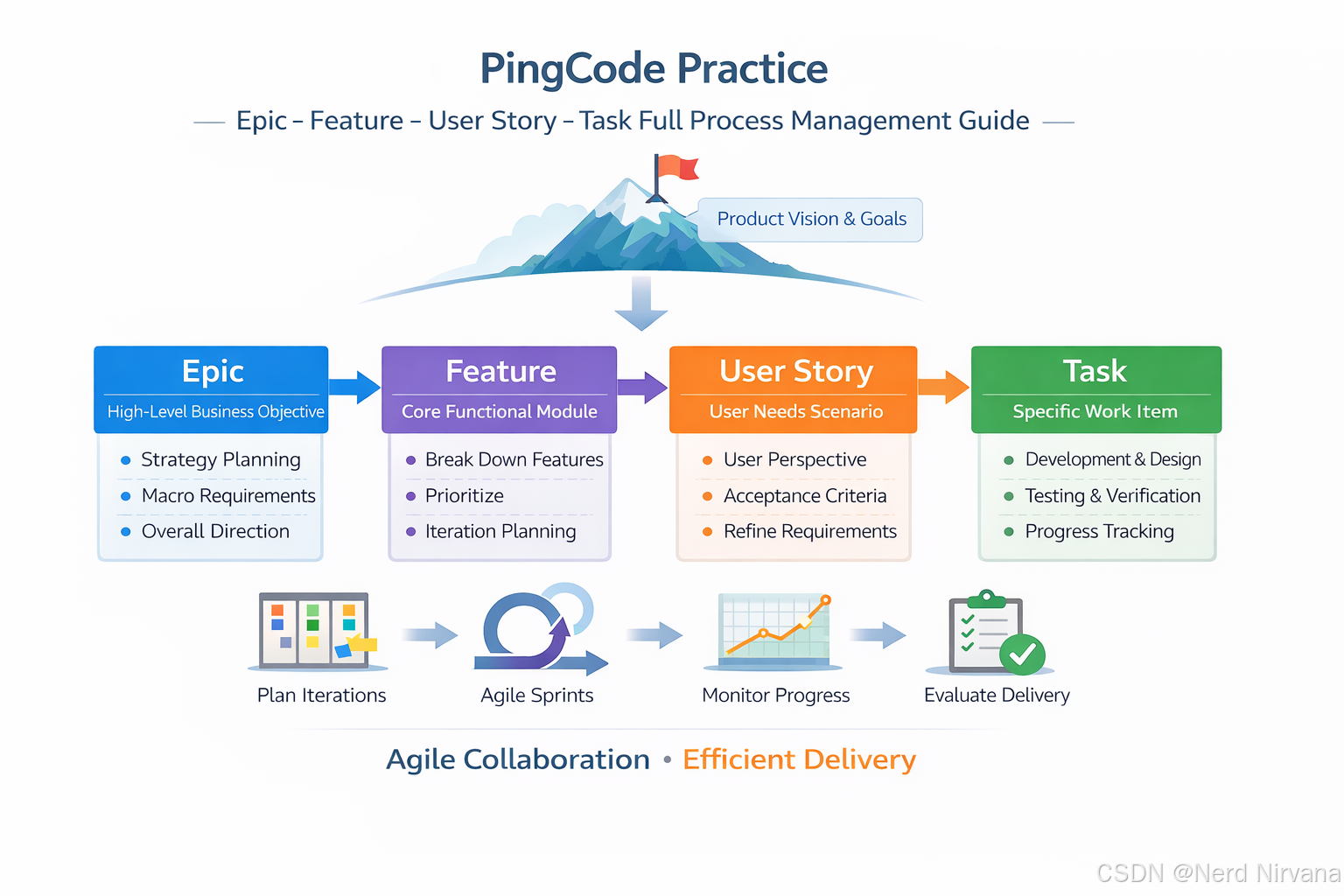
1.2 需求层级的四个维度
Epic、Feature、Story和Task用来划分需求颗粒度的标签,分别代表需求颗粒度从大到小,每个层级承载着不同的意义。
战略层 → Epic (史诗)
│
产品层 → Feature (特性)
│
交付层 → User Story (用户故事)
│
执行层 → Task (任务)时间跨度对比:
Epic ████████████████████████ (3-12个月)
Feature ██████████ (1-3个月,多个Sprint)
Story ███ (3-10天,1个Sprint内)
Task █ (1-8小时)价值维度对比:
| 层级 | 价值类型 | 受众 | 可估算性 |
|---|---|---|---|
| Epic | 战略价值 | 高管/利益相关者 | 难以精确估算 |
| Feature | 业务价值 | 产品经理/客户 | 可粗略估算 |
| Story | 用户价值 | 最终用户 | 可估算(故事点) |
| Task | 技术实现 | 开发团队 | 可估算(小时) |
第二部分:Epic(史诗)- 战略级需求
2.1 什么是Epic
Epic是项目的愿景目标,通过Epic的落地达成,使公司可以获得相应的市场地位和回报,具有战略价值,通常需要数月完成。
Epic的特征:
- 战略导向: 直接关联公司的业务战略和年度目标
- 大而复杂: 无法在单个Sprint中完成
- 需要拆分: 必须分解为多个Feature才能执行
- 长期跟踪: 跨越多个版本和迭代
2.2 Epic的编写格式
格式1: 目标驱动型
Epic名称: [业务目标或战略举措]
描述:
为了 [业务目标]
我们需要 [大的功能范围]
从而实现 [预期的业务成果]
成功指标:
- [关键指标1]
- [关键指标2]示例:
Epic: 建立在线销售渠道
描述:
为了 扩大市场覆盖,减少对线下门店的依赖
我们需要 建立完整的电商平台
从而实现 在线销售额占总销售额的30%
成功指标:
- 6个月内上线完整电商平台
- 注册用户达到10万
- 月GMV达到500万
- 客户满意度评分≥4.2/5.0格式2: 问题解决型
Epic名称: [要解决的核心问题]
当前问题:
[描述业务痛点和影响]
解决方案:
[概述解决思路]
预期收益:
[量化的业务收益]示例:
Epic: 提升客户服务响应速度
当前问题:
客户投诉响应时间平均48小时,客户流失率高达25%
NPS评分仅为-15,远低于行业平均水平30
解决方案:
建立智能客服系统,包括AI机器人、工单系统和知识库
实现7x24小时服务,智能路由和自动化流程
预期收益:
- 平均响应时间降至2小时
- 客户流失率降至15%
- NPS评分提升至40
- 客服成本降低30%2.3 在PingCode中创建Epic
步骤1: 创建Epic工作项
- 进入PingCode项目管理模块
- 选择目标项目
- 点击"需求"组件
- 点击"新建" → 选择"史诗"类型
步骤2: 填写Epic信息
必填字段:
- 标题: 简洁有力,体现战略意图
- 描述: 详细说明业务背景、目标和价值
- 负责人: 通常是产品负责人或业务负责人
- 优先级: P0(紧急)、P1(高)、P2(中)、P3(低)
推荐字段:
- 业务价值评分: 1-100分,用于优先级排序
- 目标用户: 哪些用户会受益
- 成功指标: 可量化的KPI
- 预计开始/结束时间: 大致的时间框架
- 关联OKR: 与公司目标对齐
步骤3: 添加标签和分类
标签示例:
- 战略级
- 2025H1
- 收入增长
- 用户体验优化2.4 Epic管理最佳实践
实践1: 保持Epic数量精简
❌ 过多Epic:
- 20个并行Epic → 资源分散,无法聚焦
- 每个Epic进展缓慢
✅ 聚焦关键Epic:
- 3-5个核心Epic → 集中资源
- 确保每个Epic能在合理时间内完成实践2: 定期审查Epic进展
月度Epic审查会议:
1. 审查Epic完成度(已完成Feature数/总Feature数)
2. 评估是否符合预期时间表
3. 检查成功指标达成情况
4. 决定是否调整优先级或范围实践3: Epic看板可视化
Epic看板状态:
[提出] → [评审中] → [进行中] → [验证中] → [已完成]
在PingCode中:
- 使用自定义视图创建Epic看板
- 用燃尽图跟踪Epic进度
- 在路线图中展示Epic时间线2.5 Epic拆分的时机
何时开始拆分Epic?
触发条件:
- ✅ Epic即将进入开发计划(未来3-6个月)
- ✅ 业务需求已经相对明确
- ✅ 产品负责人可以描述出主要功能
- ✅ 需要进行发布规划
不要太早拆分:
- ❌ 一年后才会做的Epic不要现在拆
- ❌ 业务方向还在探索阶段不要拆
- ❌ 避免"过早优化"浪费精力
拆分Epic的信号:
信号1: Epic在路线图上移至"下一季度"
信号2: 利益相关者要求看详细计划
信号3: 需要估算资源和时间
信号4: 准备开始产品设计第三部分:Feature(特性)- 产品级需求
3.1 什么是Feature
Feature是可以带来价值的产品功能和特性,相比Epic更具体更形象,客户可以感知,具有业务价值,通常需要数周和多个Sprint完成。
Feature的特征:
- 客户可感知: 客户能够直接体验和使用
- 独立交付: 可以单独发布给用户
- 业务价值明确: 能清晰说明带来的价值
- 适度规模: 2-4周,2-3个Sprint可完成
3.2 Feature与Epic的关系
关系模型:
一个Epic通常包含5-10个Feature
示例:
Epic: 建立在线销售渠道
├─ Feature 1: 商品浏览和搜索
├─ Feature 2: 购物车管理
├─ Feature 3: 订单结算
├─ Feature 4: 支付集成
├─ Feature 5: 订单跟踪
├─ Feature 6: 客户账户管理
└─ Feature 7: 评价和反馈系统MMF概念 (Minimal Marketable Feature)
MMF是一组最小的、可以市场化的机能,它能够提交到用户手中使用,并可以从用户那里得到相应的回报。
Feature设计原则 - MMF:
✅ Minimal: 最小化,只包含核心价值
✅ Marketable: 可市场化,用户愿意使用
✅ Feature: 完整功能,可独立交付
反例: 不是MMF
❌ "完成数据库设计" - 用户无法感知
❌ "实现API接口" - 不是完整功能
❌ "优化查询性能" - 无法独立交付价值
正例: 是MMF
✅ "用户可以搜索并筛选产品"
✅ "用户可以通过支付宝完成支付"
✅ "用户可以跟踪订单状态"3.3 Feature的编写格式
标准格式:
Feature名称: [用户可感知的功能]
业务价值:
为 [目标用户]
提供 [功能能力]
使其能够 [达成的目标]
验收标准(高层级):
1. [关键场景1]
2. [关键场景2]
3. [关键场景3]
不包含(范围边界):
- [明确不做什么]示例1: 电商功能
Feature: 商品浏览和搜索
业务价值:
为 在线购物用户
提供 快速查找商品的能力
使其能够 在海量商品中找到想要的商品,提升购物效率
验收标准:
1. 用户可以通过关键词搜索商品
2. 用户可以按类别、价格、评分筛选
3. 搜索结果按相关性智能排序
4. 支持热门搜索推荐
5. 移动端和PC端体验一致
不包含:
- 不包含语音搜索
- 不包含AR试用功能
- 不包含智能推荐算法(在Feature 8中)示例2: 企业系统功能
Feature: 智能工单路由
业务价值:
为 客服管理人员
提供 自动分配工单的能力
使其能够 减少手动分配工作量,提升工单响应速度30%
验收标准:
1. 系统根据工单类型自动分配给对应团队
2. 考虑客服人员当前工作负载
3. 支持VIP客户优先级规则
4. 管理员可配置路由规则
5. 提供路由效果分析报表
不包含:
- 不包含AI智能分类(Phase 2)
- 不包含多语言支持3.4 在PingCode中创建和管理Feature
步骤1: 创建Feature
- 在Epic下点击"添加子工作项"
- 选择"特性"类型
- 填写Feature信息
步骤2: 设置Feature属性
关键属性:
基本信息:
- 标题: 简洁描述功能
- 描述: 详细业务背景和价值
- 父级Epic: 关联到对应Epic
- 负责人: 产品经理或Feature Owner
优先级管理:
- 业务价值评分: 1-100
- 紧急程度: 高/中/低
- 技术风险: 高/中/低
- 综合优先级: 自动计算
计划信息:
- 目标版本: 如"V2.5"
- 预计开始时间
- 预计结束时间
- 所属Sprint: 可关联多个
依赖关系:
- 前置Feature: 必须先完成的
- 后续Feature: 依赖本Feature的
- 阻塞问题: 当前阻碍步骤3: Feature状态流转
PingCode中Feature生命周期:
[待规划] → [规划中] → [设计中] → [开发中] → [测试中] → [已发布]
各阶段产出:
待规划: Feature概述
规划中: 详细需求文档,Story拆分
设计中: UI/UX设计,技术方案
开发中: Story逐个完成
测试中: 集成测试,用户验收测试
已发布: 生产环境可用3.5 Feature拆分最佳实践
拆分维度1: 用户旅程
Feature: 订单结算流程
拆分为:
├─ Feature 1.1: 收货地址管理
├─ Feature 1.2: 配送方式选择
├─ Feature 1.3: 支付方式选择
└─ Feature 1.4: 订单确认和提交拆分维度2: 用户类型
Feature: 商品发布功能
拆分为:
├─ Feature 2.1: 个人卖家商品发布
├─ Feature 2.2: 企业卖家商品发布
└─ Feature 2.3: 批量导入商品拆分维度3: 数据类型
Feature: 多媒体内容管理
拆分为:
├─ Feature 3.1: 图片管理
├─ Feature 3.2: 视频管理
└─ Feature 3.3: 文档管理拆分维度4: MVP + 增强
Feature: 智能搜索
拆分为:
├─ Feature 4.1: 基础关键词搜索(MVP)
├─ Feature 4.2: 高级筛选
├─ Feature 4.3: 搜索建议
└─ Feature 4.4: 个性化排序3.6 Feature发布规划
在PingCode中创建版本计划:
版本规划视图:
版本: V2.0 (2025年3月发布)
├─ Epic 1: 在线销售渠道
│ ├─ Feature 1.1: 商品浏览 ✓
│ ├─ Feature 1.2: 购物车 ✓
│ ├─ Feature 1.3: 结算 (进行中)
│ └─ Feature 1.4: 支付 (计划中)
│
└─ Epic 2: 客户服务优化
├─ Feature 2.1: 在线客服 ✓
└─ Feature 2.2: 工单系统 (进行中)
进度: 4/6 Feature完成 (67%)使用PingCode路线图功能:
- 进入"路线图"视图
- 按时间轴展示Feature
- 设置Feature的开始和结束时间
- 标识Feature间的依赖关系
- 导出给利益相关者
第四部分:User Story(用户故事)- 交付级需求
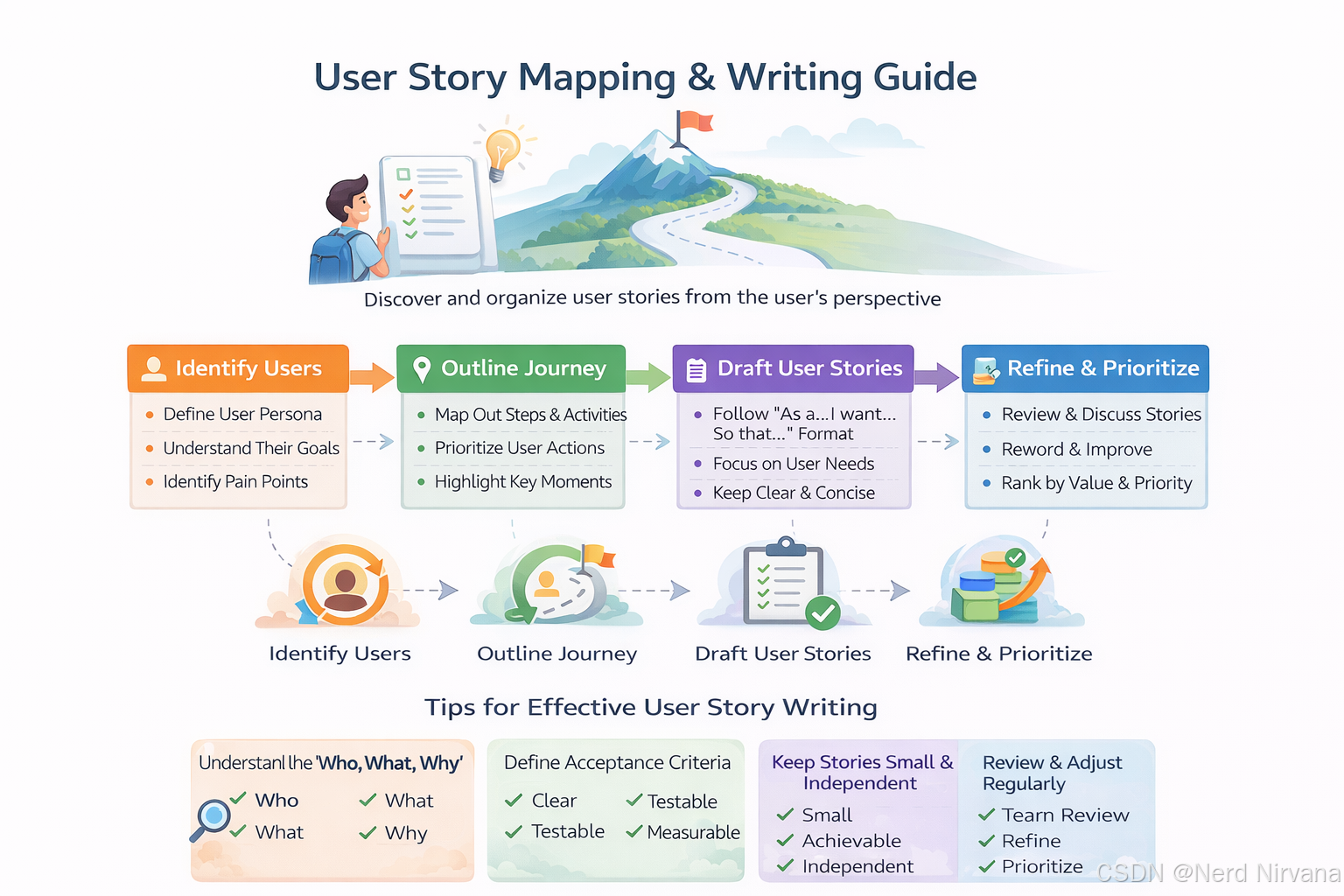
4.1 什么是User Story
Story是从用户角度对产品功能的详细描述,承接Feature,并放入产品Backlog中,持续规划,滚动调整,始终让高优先级Story交付给客户,具有用户价值。
User Story的特征:
- 用户视角: 从用户角度描述需求
- 可交付: 一个Sprint内可完成
- 可演示: 可以向干系人展示工作软件
- 符合INVEST原则: 独立、可协商、有价值、可估算、小、可测试
4.2 User Story与Feature的关系
关系模型:
一个Feature通常包含3-8个User Story
示例:
Feature: 商品浏览和搜索
├─ Story 1: 用户可以输入关键词搜索商品
├─ Story 2: 用户可以按类别筛选商品
├─ Story 3: 用户可以按价格区间筛选
├─ Story 4: 用户可以按评分排序
├─ Story 5: 用户可以查看搜索历史
└─ Story 6: 系统提供热门搜索推荐4.3 User Story的编写格式
标准格式(3W):
作为 [角色]
我想要 [功能]
以便于 [价值]
验收标准:
场景: [场景名称]
Given [前置条件]
When [用户操作]
Then [预期结果]完整示例:
Story: 用户可以按价格区间筛选商品
作为 在线购物用户
我想要 设置商品价格范围
以便于 只看到我预算内的商品,快速做出购买决策
验收标准:
场景1: 设置价格区间筛选
Given 我在商品列表页面
And 有100个不同价格的商品
When 我设置价格区间为"100-500"
Then 列表只显示价格在100-500元的商品
And 显示筛选结果数量
And 可以清除价格筛选
场景2: 价格区间与其他筛选组合
Given 我已选择了"电子产品"类别
And 我设置价格区间为"1000-3000"
When 系统应用筛选
Then 只显示"电子产品"类别且价格在1000-3000的商品
And 筛选条件清晰可见
场景3: 无匹配结果处理
Given 我设置价格区间为"10000-20000"
And 当前类别下没有此价格区间的商品
When 系统应用筛选
Then 显示"暂无符合条件的商品"
And 提供"清除筛选"或"调整筛选条件"建议
性能标准:
✓ 筛选操作响应时间<2秒
✓ 支持至少10,000个商品的筛选
设计约束:
✓ 移动端使用滑动条选择价格
✓ PC端支持输入框输入
✓ 保持与其他筛选项的UI一致性4.4 在PingCode中创建和管理User Story
步骤1: 在Feature下创建Story
方法1: 从Feature详情页创建
1. 打开Feature详情
2. 点击"添加子工作项"
3. 选择"用户故事"
4. 填写Story信息
方法2: 从需求列表批量创建
1. 进入"需求"视图
2. 点击"批量创建"
3. 快速输入多个Story标题
4. 后续补充详细信息
方法3: 从Excel导入
1. 下载Story模板
2. 批量填写Story信息
3. 导入到PingCode
4. 自动关联到Feature步骤2: 填写Story详细信息
必填字段:
Story信息卡:
┌─────────────────────────────────┐
│ 标题: 用户可以按价格区间筛选商品 │
│ 类型: 用户故事 │
│ 父级: Feature 1 - 商品浏览搜索 │
│ 负责人: 张三 │
│ 状态: 待开发 │
│ 优先级: P1 │
│ 故事点: 5 │
│ │
│ 描述: [3W格式] │
│ 验收标准: [Given-When-Then] │
│ │
│ 附件: 原型图.png, 交互设计.pdf │
│ 关联测试用例: 15个 │
└─────────────────────────────────┘推荐字段:
计划信息:
- 所属Sprint: Sprint 12
- 预计工时: 2天
- 实际工时: (开发中填写)
技术信息:
- 技术风险: 中
- 依赖项: Story 45必须先完成
- 影响范围: 前端+后端+移动端
协作信息:
- 产品负责人: 李四
- 开发负责人: 张三
- 测试负责人: 王五
- UI设计师: 赵六步骤3: Story在Sprint中的管理
Sprint规划会中:
1. 审查Story的Ready状态:
✓ 描述清晰
✓ 验收标准完整
✓ 故事点已估算
✓ 依赖已识别
✓ UI设计已完成
2. 团队讨论实现方案:
- 技术选型
- 任务拆分
- 风险识别
3. 承诺Story到Sprint:
- 拖拽Story到Sprint Backlog
- 设置Sprint目标
- 分配开发人员开发过程中:
Story状态流转:
[待开发] → [开发中] → [代码审查] → [测试中] → [已完成]
每日站会更新:
- 昨天: 完成了登录界面开发
- 今天: 进行数据验证逻辑
- 阻碍: 等待API接口联调
在PingCode中操作:
1. 拖动Story卡片到对应列
2. 更新完成百分比
3. 添加评论记录进展
4. 关联代码提交4.5 Story拆分技巧
何时需要拆分Story?
拆分信号:
❌ 故事点>13 → 太大,无法在一个Sprint完成
❌ 需要3个以上开发人员 → 太复杂,协作困难
❌ 涉及多个子系统 → 范围太广
❌ 依赖太多 → 无法独立开发
❌ 验收标准>10条 → 包含太多场景Story拆分方法(SPIDR):
1. Spike(探索)
原Story: 集成第三方支付
太大且不确定性高
拆分为:
├─ Spike Story: 调研第三方支付方案(2天)
└─ Implementation Story: 实现支付宝集成(5天)2. Paths(路径)
原Story: 用户注册功能
按路径拆分:
├─ Story 1: 邮箱注册(正常路径)
├─ Story 2: 手机号注册(备选路径)
├─ Story 3: 第三方登录注册(便捷路径)
└─ Story 4: 注册异常处理(异常路径)3. Interfaces(接口)
原Story: 商品详情页
按接口拆分:
├─ Story 1: Web版商品详情
├─ Story 2: 移动App商品详情
└─ Story 3: 小程序商品详情4. Data(数据)
原Story: 商品导入功能
按数据拆分:
├─ Story 1: 导入实体商品
├─ Story 2: 导入虚拟商品
└─ Story 3: 导入服务类商品5. Rules(规则)
原Story: 订单折扣计算
按规则拆分:
├─ Story 1: 单品折扣
├─ Story 2: 满减优惠
├─ Story 3: 会员折扣
└─ Story 4: 优惠券抵扣4.6 Story估算实践
Story Point估算会议:
准备工作:
会前准备(产品负责人):
1. 确保所有Story符合INVEST
2. 准备好原型和交互设计
3. 明确验收标准
4. 识别技术依赖
会议参与者:
- 产品负责人(主持)
- 开发团队(全员)
- Scrum Master(引导)估算流程(Planning Poker):
Step 1: 产品负责人讲解Story
- 用户价值
- 验收标准
- 技术要求
Step 2: 团队讨论和提问
- 澄清不明确的点
- 识别技术风险
- 讨论实现方案
Step 3: Planning Poker估算
斐波那契数列: 1, 2, 3, 5, 8, 13, 21
每人选择一个数字:
- 1-2: 非常简单,几小时完成
- 3-5: 简单,1-2天完成
- 8: 中等,3-4天完成
- 13+: 复杂,需要拆分
Step 4: 讨论差异
如果估算差异大(如3和13):
- 最小估算者说明理由
- 最大估算者说明理由
- 团队讨论达成共识
Step 5: 达成一致
- 记录最终故事点
- 在PingCode中更新在PingCode中记录估算:
Story详情:
- 故事点: 5
- 估算依据:
* 需要新建3个API接口
* 前端2个页面
* 包含数据验证逻辑
* 参考类似Story用时
- 估算日期: 2025-01-05
- 估算参与人: 开发团队全员第五部分:Task(任务)- 执行级工作
5.1 什么是Task
Task聚焦实现价值,通过过程性的任务来实现Story的功能,通常是1-8个小时,Task的描述是一个动作。
Task的特征:
- 技术导向: 描述具体的技术实现步骤
- 小时级: 可在几小时内完成
- 动作明确: 使用动词开头
- 不对外: 用户不直接感知Task
5.2 Task与User Story的关系
关系模型:
一个User Story通常拆分为5-10个Task
示例:
Story: 用户可以按价格区间筛选商品
├─ Task 1: 设计价格筛选数据模型
├─ Task 2: 实现后端价格筛选API
├─ Task 3: 编写API单元测试
├─ Task 4: 实现前端价格筛选UI组件
├─ Task 5: 集成API与前端
├─ Task 6: 编写前端单元测试
├─ Task 7: 执行集成测试
├─ Task 8: 修复测试中发现的Bug
└─ Task 9: 更新技术文档5.3 Task的类型和命名
开发Task:
格式: [动词] + [对象] + [详细说明]
示例:
✓ 设计价格筛选数据库表结构
✓ 实现商品价格区间查询API
✓ 开发价格筛选前端组件
✓ 重构商品列表查询逻辑
✓ 优化价格筛选SQL性能测试Task:
✓ 编写价格筛选功能单元测试
✓ 执行价格筛选集成测试
✓ 进行价格筛选性能测试
✓ 编写自动化验收测试脚本技术Task (Engineering Task):
✓ 升级React版本到18.2
✓ 配置价格筛选日志记录
✓ 设置价格筛选监控告警
✓ 重构价格计算工具类文档Task:
✓ 编写价格筛选API文档
✓ 更新价格筛选用户手册
✓ 记录价格筛选技术决策5.4 在PingCode中创建和管理Task
步骤1: 从Story拆分Task
方法1: Story详情页创建
1. 打开Story详情
2. 点击"添加子任务"
3. 快速输入Task标题
4. 分配给具体开发人员
方法2: Sprint Planning会议中拆分
1. 团队讨论Story实现方案
2. 识别所需的技术步骤
3. 在白板或PingCode中记录Task
4. 估算每个Task工时步骤2: Task属性设置
Task信息卡:
┌─────────────────────────────────┐
│ 标题: 实现商品价格区间查询API │
│ 类型: 任务 │
│ 父级: Story 156 - 价格筛选功能 │
│ 负责人: 张三(后端开发) │
│ 状态: 进行中 │
│ │
│ 预估工时: 4小时 │
│ 实际工时: 3小时 │
│ 剩余工时: 1小时 │
│ │
│ 描述: │
│ 1. 设计API接口规范 │
│ 2. 实现价格区间查询逻辑 │
│ 3. 处理边界条件 │
│ 4. 编写单元测试 │
│ │
│ 技术栈: Spring Boot + MyBatis │
│ 相关代码: PR #234 │
└─────────────────────────────────┘步骤3: Task进度跟踪
每日站会中:
任务更新模板:
"我昨天完成了 [Task A],
今天计划完成 [Task B],
目前遇到 [阻碍/无阻碍]"
在PingCode中操作:
1. 更新Task状态
2. 填写实际工时
3. 更新剩余工时
4. 添加工作日志Task看板:
Sprint任务板:
┌─────────┬─────────┬─────────┬─────────┐
│ 待办 │ 进行中 │ 代码审查│ 完成 │
├─────────┼─────────┼─────────┼─────────┤
│ Task 1 │ Task 3 │ Task 5 │ Task 7 │
│ (张三) │ (李四) │ (王五) │ (赵六) │
│ │ │ │ │
│ Task 2 │ Task 4 │ Task 6 │ Task 8 │
│ (张三) │ (张三) │ (李四) │ (王五) │
└─────────┴─────────┴─────────┴─────────┘
颜色标识:
🟢 正常进行
🟡 有轻微阻碍
🔴 严重阻塞5.5 Task工时管理
估算Task工时:
工时估算原则:
- 单个Task: 1-8小时
- 超过8小时 → 应该拆分
- 少于1小时 → 可能太细
估算考虑因素:
✓ 编码时间
✓ 单元测试时间
✓ 代码审查时间
✓ 文档编写时间
✓ 10-20%的缓冲时间在PingCode中记录工时:
工时记录:
- 预估工时: 6小时
- 实际工时: 8小时
- 差异原因: API接口变更,需要额外适配
工时统计报表:
Story 156总工时:
├─ 预估: 40小时
├─ 实际: 45小时
├─ 偏差: +12.5%
└─ 分析: 低估了测试时间燃尽图跟踪:
Sprint燃尽图:
剩余工时
120h │╲
100h │ ╲
80h │ ╲ 实际
60h │ ╲╱
40h │ ╲ 理想
20h │ ╲╱
0h └──────╲────────
D1 D5 D10 D14
(Sprint天数)
分析:
- D1-D5: 进度正常
- D6-D8: 进度放缓(发现技术难题)
- D9-D14: 赶进度,成功完成5.6 Task完成标准
Definition of Done (DoD):
Task完成检查清单:
代码质量:
□ 代码编写完成
□ 代码符合团队规范
□ 通过静态代码检查
□ 代码复杂度合理
□ 没有已知Bug
测试:
□ 单元测试编写完成
□ 单元测试通过率100%
□ 代码覆盖率≥80%
□ 本地功能测试通过
协作:
□ 代码已提交到Git
□ Pull Request已创建
□ 代码审查已通过
□ 已合并到主分支
文档:
□ 代码注释完整
□ API文档已更新
□ 技术决策已记录
在PingCode中:
□ Task状态设为"完成"
□ 实际工时已记录
□ 相关工作日志已填写第六部分:PingCode中的端到端实践
6.1 案例背景
公司: 某在线教育平台
目标: 建立智能学习推荐系统,提升用户学习效果和平台粘性
团队: 产品经理1人,开发团队8人,测试2人
时间: 6个月,12个Sprint
6.2 第一步:创建Epic
在PingCode中操作:
-
进入项目管理 → 需求 → 新建 → 史诗
-
填写Epic信息:
标题: 智能学习推荐系统
描述:
为了 提升用户学习效果和平台活跃度
我们需要 建立AI驱动的个性化学习推荐系统
从而实现 用户日活提升30%,课程完成率提升50%业务背景:
当前平台拥有5000+课程,但用户常常不知道学什么
用户流失率高达40%,主要原因是找不到合适的课程
竞品已经推出推荐功能,对我们构成威胁成功指标:
- 推荐点击率>20%
- 推荐课程完成率>60%
- 日活用户数提升30%
- NPS评分提升15分
- 6个月内完成上线
目标用户:
- 主要:平台注册用户(100万)
- 次要:潜在用户(浏览但未注册)
负责人: 产品总监 - 王经理
优先级: P0 (最高)
预计时间: 2025-01-01 至 2025-06-30 -
添加标签:
- #战略级
- #AI创新
- #用户增长
- #2025H1
- 关联OKR:
- 公司年度OKR: 用户增长50%
- 产品OKR: DAU提升30%
6.3 第二步:拆分Feature
Epic分解会议:
参与人: 产品团队、开发Leader、架构师、UX设计师
产出: 7个Feature
在PingCode中创建Feature:
Feature 1:
标题: 用户画像构建
业务价值:
为 推荐系统
提供 准确的用户特征数据
使其能够 实现精准的个性化推荐
验收标准:
1. 收集用户基础属性(年龄、职业、学历)
2. 分析用户学习行为(浏览、购买、完成)
3. 构建用户兴趣标签体系
4. 实现用户画像实时更新
5. 提供画像数据查询API
不包含:
- 不包含跨平台用户行为(Phase 2)
- 不包含社交关系分析
优先级: P0
预计时间: Sprint 1-2 (4周)
前置条件: 无
依赖: 需要数据团队提供埋点支持其他Feature(简要):
Feature 2: 课程内容标签化 (Sprint 2-3)
Feature 3: 推荐算法引擎 (Sprint 3-5)
Feature 4: 推荐结果展示 (Sprint 4-5)
Feature 5: A/B测试框架 (Sprint 5-6)
Feature 6: 推荐效果分析 (Sprint 6-7)
Feature 7: 推荐规则配置 (Sprint 7-8)Feature关系视图:
在PingCode路线图中:
Sprint 1 ████ Feature 1: 用户画像
Sprint 2 ████████ Feature 1 + Feature 2: 课程标签
Sprint 3 ████████████ Feature 2 + Feature 3: 算法引擎
Sprint 4 ████████████ Feature 3 + Feature 4: 结果展示
Sprint 5 ████████ Feature 4 + Feature 5: A/B测试
Sprint 6 ████████ Feature 5 + Feature 6: 效果分析
Sprint 7 ████ Feature 7: 规则配置
Sprint 8 ████ 优化和收尾6.4 第三步:Feature细化为Story
以Feature 1为例:
Backlog精化会议:
- 时间: Sprint 1开始前1周
- 参与人: 产品经理、Tech Lead、开发代表
产出: 6个User Story
Story 1:
标题: 收集用户基础属性
作为 系统管理员
我想要 收集用户的基础属性信息
以便于 为推荐系统提供用户基础画像
验收标准:
场景1: 用户注册时填写基础信息
Given 用户在注册页面
When 用户填写年龄、职业、学历、兴趣领域
Then 信息保存到用户画像数据库
And 数据格式符合画像标准
And 敏感信息已加密存储
场景2: 已注册用户补全信息
Given 用户已登录且未完善基础信息
When 用户访问任何页面
Then 显示信息完善引导弹窗
And 用户可选择"立即完善"或"稍后"
And "稍后"不会频繁打扰
场景3: 信息修改
Given 用户想修改基础信息
When 用户进入"个人设置"页面
Then 可以编辑所有基础属性
And 修改立即生效
And 推荐结果会相应调整
技术约束:
✓ 使用MongoDB存储用户画像
✓ 属性字段可扩展
✓ 支持100万用户规模
优先级: P0
故事点: 5
Sprint: Sprint 1
负责人: 张三(全栈开发)其他Story(列表):
Story 2: 采集用户浏览行为 (8点, Sprint 1)
Story 3: 采集用户购买行为 (5点, Sprint 1)
Story 4: 采集用户学习进度 (8点, Sprint 2)
Story 5: 构建用户兴趣标签 (13点, Sprint 2)
Story 6: 提供画像查询API (5点, Sprint 2)6.5 第四步:Story拆分为Task
Sprint Planning会议:
- 时间: Sprint 1 第一天上午
- 选中Story: Story 1 - 收集用户基础属性
团队拆分Task:
Story 1拆分为9个Task:
后端Task:
Task 1: 设计用户画像数据模型 (2h, 张三)
Task 2: 创建用户画像MongoDB表 (1h, 张三)
Task 3: 实现用户属性保存API (4h, 张三)
Task 4: 实现用户属性查询API (2h, 张三)
Task 5: 编写API单元测试 (3h, 李四)
前端Task:
Task 6: 设计信息完善UI组件 (3h, 王五)
Task 7: 实现注册表单增强 (4h, 王五)
Task 8: 实现信息完善弹窗 (3h, 赵六)
Task 9: 集成后端API (2h, 王五)
测试Task:
Task 10: 编写功能测试用例 (2h, 测试A)
Task 11: 执行集成测试 (3h, 测试A)
Task 12: 执行用户验收测试 (2h, 产品经理)
总预估: 31小时在PingCode中创建Task:
操作步骤:
1. 打开Story 1详情
2. 点击"添加子任务"
3. 批量输入Task标题
4. 分配负责人
5. 估算工时
6. 设置Task优先级
7. 关联到Sprint看板6.6 第五步:Sprint执行与跟踪
Day 1: Sprint开始
PingCode看板初始状态:
Sprint 1 任务板
┌──────────┬──────────┬──────────┬──────────┐
│ 待办(9) │ 进行中(0)│ 审查(0) │ 完成(0) │
├──────────┼──────────┼──────────┼──────────┤
│ Task 1 │ │ │ │
│ Task 2 │ │ │ │
│ Task 3 │ │ │ │
│ Task 4 │ │ │ │
│ Task 5 │ │ │ │
│ Task 6 │ │ │ │
│ Task 7 │ │ │ │
│ Task 8 │ │ │ │
│ Task 9 │ │ │ │
└──────────┴──────────┴──────────┴──────────┘
Story进度: 0/31小时 (0%)Day 3: 开发进行中
每日站会后更新:
┌──────────┬──────────┬──────────┬──────────┐
│ 待办(5) │ 进行中(2)│ 审查(1) │ 完成(3) │
├──────────┼──────────┼──────────┼──────────┤
│ Task 5 │ Task 3 │ Task 2 │ Task 1✓ │
│ Task 6 │ (张三) │ │ Task 4✓ │
│ Task 7 │ │ │ Task 10✓ │
│ Task 8 │ Task 9 │ │ │
│ Task 11 │ (王五) │ │ │
└──────────┴──────────┴──────────┴──────────┘
Story进度: 12/31小时 (39%)
阻碍:
🔴 Task 3遇到MongoDB连接问题
→ 已创建技术支持工单
→ 预计今天下午解决Day 7: Sprint中期检查
PingCode中查看Sprint燃尽图:
剩余工时
35h │●
30h │ ●
25h │ ●
20h │ ●● 理想线
15h │ ●╲
10h │ ●╲ 实际线
5h │ ●╲
0h └────────●─────
D1 D2 D3 D4 D5 D6 D7
分析:
✓ 前3天进度略慢(技术问题)
✓ D4-D7赶上进度
✓ 预计按时完成Day 10: Story完成
验收检查清单:
Story 1验收:
□ 所有Task状态为"完成"
□ 代码已合并到主分支
□ 单元测试覆盖率85%
□ 集成测试全部通过
□ 用户验收测试通过
验收标准检查:
✓ 场景1: 注册时填写基础信息 - 通过
✓ 场景2: 已注册用户补全信息 - 通过
✓ 场景3: 信息修改 - 通过
✓ 技术约束: MongoDB存储,支持100万用户 - 通过
产品负责人签字: 王经理 ✓
日期: 2025-01-10
在PingCode中操作:
1. Story状态改为"已完成"
2. 添加验收评论
3. 更新燃尽图
4. 关联部署记录6.7 第六步:Sprint评审与回顾
Sprint评审会:
PingCode中准备演示:
评审议程:
1. Sprint目标回顾 (5分钟)
- 计划完成3个Story
- 实际完成3个Story ✓
2. Story演示 (30分钟)
在PingCode中逐个展示:
Story 1: 收集用户基础属性
- 展示注册流程
- 展示信息完善功能
- 展示后台画像数据
- 对照验收标准确认
Story 2: 采集用户浏览行为
- 展示埋点采集
- 展示行为数据存储
- 展示数据查询接口
Story 3: 采集用户购买行为
- 展示购买事件追踪
- 展示购买数据分析
3. 收集反馈 (15分钟)
利益相关者提问和建议
4. Product Backlog调整 (10分钟)
根据反馈调整优先级Sprint回顾会:
PingCode中的度量数据:
Sprint 1回顾数据:
计划vs实际:
- 计划Story点: 18点
- 完成Story点: 18点
- 完成率: 100% ✓
工时统计:
- 计划工时: 120小时
- 实际工时: 135小时
- 偏差: +12.5%
- 原因: 低估了测试时间
速率:
- Sprint 1速率: 18点
- 预计速率: 15-20点
- 下一Sprint承诺: 20点
缺陷统计:
- Sprint中发现: 8个
- Sprint中修复: 8个
- 遗留到下一Sprint: 0个
代码质量:
- 代码审查通过率: 95%
- 测试覆盖率: 82%
- 技术债: 2个(已记录)回顾要点:
做得好的:
✓ Task拆分合理,粒度适中
✓ 每日站会高效,问题快速解决
✓ 代码审查质量高
需要改进:
△ 测试Task预估偏低
△ MongoDB技术储备不足
△ 前后端联调时间不够
行动项:
1. 下Sprint增加20%测试缓冲时间
2. 组织MongoDB技术分享(李四负责)
3. 每Sprint中期安排前后端联调时间第七部分:PingCode高级功能应用
7.1 需求层级可视化
史诗地图视图:
在PingCode中启用"史诗地图"视图:
Epic: 智能学习推荐系统 [65%完成]
│
├─ Feature 1: 用户画像构建 [100%✓]
│ ├─ Story 1: 收集基础属性 ✓
│ ├─ Story 2: 采集浏览行为 ✓
│ └─ Story 3: 采集购买行为 ✓
│
├─ Feature 2: 课程内容标签化 [80%]
│ ├─ Story 4: 课程标签体系 ✓
│ ├─ Story 5: 自动标签提取 ✓
│ └─ Story 6: 人工标签审核 (进行中)
│
├─ Feature 3: 推荐算法引擎 [30%]
│ ├─ Story 7: 协同过滤算法 (进行中)
│ ├─ Story 8: 内容推荐算法 (待开始)
│ └─ Story 9: 混合推荐策略 (待开始)
│
└─ Feature 4-7: [未开始]
功能:
- 点击任意层级查看详情
- 拖拽调整优先级
- 筛选特定状态
- 导出为图片/PDF依赖关系图:
在PingCode中创建依赖视图:
Feature 1 ──前置──→ Feature 3
│ │
└──前置──→ Feature 2─┘
│
└──前置──→ Feature 4
说明:
- 实线: 硬依赖(必须先完成)
- 虚线: 软依赖(建议先完成)
- 红色: 当前阻塞
- 绿色: 依赖已满足
操作:
1. 在Feature详情中添加"前置依赖"
2. 系统自动生成依赖图
3. 识别关键路径
4. 优化开发顺序7.2 需求优先级管理
价值vs复杂度矩阵:
在PingCode中创建自定义视图:
高价值
↑
│ [快速见效] [战略重点]
│ Feature 4 Feature 3
│ Feature 6 Feature 1
│
│ [可以延后] [复杂但必要]
│ Feature 7 Feature 5
│
└────────────────────────→ 高复杂度
低复杂度
优先级策略:
1. 先做战略重点(高价值+高复杂度)
2. 再做快速见效(高价值+低复杂度)
3. 接着做复杂但必要(低价值+高复杂度)
4. 最后考虑可以延后(低价值+低复杂度)WSJF优先级计算:
WSJF = (业务价值 + 时间敏感度 + 风险降低) / 工作量
在PingCode中配置自定义字段:
Feature 3: 推荐算法引擎
- 业务价值: 8/10
- 时间敏感度: 9/10
- 风险降低: 7/10
- 工作量: 13点
WSJF = (8+9+7) / 13 = 1.85
PingCode自动计算并排序:
1. Feature 3: WSJF=1.85 (最高优先级)
2. Feature 1: WSJF=1.67
3. Feature 2: WSJF=1.50
4. Feature 4: WSJF=1.33
...7.3 版本发布管理
在PingCode中创建版本:
版本规划:
版本 V1.0 - MVP (2025-03)
├─ Feature 1: 用户画像构建 ✓
├─ Feature 2: 课程标签化 ✓
├─ Feature 3: 推荐算法引擎 ✓
└─ Feature 4: 推荐结果展示 (开发中)
发布范围:
- 完成Story: 15个
- 计划Story: 18个
- 完成率: 83%
发布检查清单:
□ 所有计划Story已完成
□ 回归测试通过
□ 性能测试达标
□ 安全扫描无高危
□ 用户文档已更新
□ 运维团队已培训
□ 发布计划已批准
版本 V1.1 - 增强 (2025-05)
├─ Feature 5: A/B测试框架
├─ Feature 6: 效果分析
└─ 新增: 推荐解释功能发布进度跟踪:
PingCode版本仪表板:
V1.0发布倒计时: 15天
功能完成度:
████████████████░░░░ 80%
代码质量:
- 单元测试: ████████████████████ 100%
- 覆盖率: ████████████████░░░░ 82%
- 技术债: 3个(可接受)
测试进度:
- 功能测试: ████████████████████ 100%
- 集成测试: ████████████████░░░░ 85%
- 性能测试: ████████████░░░░░░░░ 60%
- UAT: ░░░░░░░░░░░░░░░░░░░░ 待开始
风险和问题:
🟡 性能测试进度落后
→ 加派2名测试人员
→ 预计3天内完成
🟢 其他指标正常7.4 团队协作功能
@提醒和协作:
在PingCode工作项中:
Story 7评论区:
─────────────────────
产品经理(2025-01-15 10:30):
@张三 协同过滤算法需要考虑冷启动问题
能否设计一个降级方案?
张三(2025-01-15 11:20):
@产品经理 可以这样设计:
1. 新用户前期使用热门推荐
2. 收集足够数据后切换个性化推荐
详细方案我会更新到技术方案文档
测试负责人(2025-01-15 14:00):
@张三 @李四
测试环境准备好了,可以开始联调
测试数据在: /test/data/users_1000.json
技术经理(2025-01-15 16:30):
@团队 明天下午3点技术评审会
地点: 会议室3
请大家准备演示
─────────────────────
功能:
- @提醒自动发送通知
- 评论支持Markdown
- 可上传附件
- 邮件同步通知工作流自动化:
在PingCode中配置自动化规则:
规则1: Story自动流转
触发条件: 所有子Task状态="完成"
执行动作:
→ Story状态改为"待测试"
→ 通知测试负责人
→ 添加标签"ready-for-test"
规则2: Bug自动分配
触发条件: 新建Bug工作项
执行动作:
→ 根据模块自动分配负责人
→ 设置优先级(严重程度)
→ 关联到当前Sprint
→ @提醒责任人
规则3: Epic进度警报
触发条件: Epic完成度<50% 且 剩余时间<30%
执行动作:
→ 发送警报邮件给产品负责人
→ 在Epic上添加"风险"标签
→ 触发状态同步会议
规则4: Story超时提醒
触发条件: Story在"开发中"状态>5天
执行动作:
→ @提醒Story负责人
→ 通知Scrum Master
→ 在每日站会议程中标记7.5 报表和度量
Epic进度报表:
在PingCode中生成Epic报表:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Epic: 智能学习推荐系统
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
整体进度:
██████████████░░░░░░░░░░░░░░░░ 47%
Feature完成情况:
Feature 1: ████████████████████ 100% ✓
Feature 2: ████████████████░░░░ 80%
Feature 3: ████████░░░░░░░░░░░░ 40%
Feature 4: ░░░░░░░░░░░░░░░░░░░░ 0%
Feature 5: ░░░░░░░░░░░░░░░░░░░░ 0%
Feature 6: ░░░░░░░░░░░░░░░░░░░░ 0%
Feature 7: ░░░░░░░░░░░░░░░░░░░░ 0%
Story统计:
- 总计: 42个Story
- 已完成: 15个
- 开发中: 8个
- 待开始: 19个
关键指标:
- 计划时间: 6个月
- 已用时间: 2.5个月
- 剩余时间: 3.5个月
- 进度健康度: ⚠️ 需要加速
(时间进度42% vs 功能进度47%)
风险:
🔴 Feature 3开发遇到技术难题
影响后续Feature 4-5
建议: 增加技术资源或简化需求
🟡 Feature 2标签质量不达标
可能需要返工
建议: 加强质量审查
成功指标追踪:
- 推荐点击率: 12% (目标20%, 未达标)
- 课程完成率: 45% (目标60%, 接近)
- 日活提升: 15% (目标30%, 未达标)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━速率趋势图:
团队速率分析:
Story点完成趋势:
25点│ ●
20点│ ● ╱
15点│ ╱ ●
10点│ ●╱
5点│●
0点└──────────────
S1 S2 S3 S4 S5
平均速率: 18点/Sprint
趋势: 上升(团队成熟度提升)
预测: Sprint 6可达到22点
建议:
✓ 当前速率稳定
✓ 可以适当增加Story承诺
✓ 注意不要过度承诺技术债务跟踪:
在PingCode中管理技术债:
技术债务列表:
┌───────────────────────────────────┐
│ 技术债1: 推荐算法代码需重构 │
│ 影响: 性能、可维护性 │
│ 优先级: 高 │
│ 预估: 8小时 │
│ 计划: Sprint 6 │
│ │
│ 技术债2: 用户画像表结构优化 │
│ 影响: 查询性能 │
│ 优先级: 中 │
│ 预估: 13小时 │
│ 计划: Sprint 7 │
│ │
│ 技术债3: 补充单元测试 │
│ 影响: 代码质量 │
│ 优先级: 中 │
│ 预估: 20小时 │
│ 计划: 每Sprint分摊 │
└───────────────────────────────────┘
债务趋势:
15个│ ●━━● 技术债总数
10个│ ╱ ╲
5个│ ● ●
0个└───────────────
S1 S2 S3 S4
策略:
- 每Sprint分配20%时间处理技术债
- 高优先级债务优先处理
- 不允许债务持续累积第八部分:最佳实践和团队规范
8.1 需求层级管理原则
原则1: 自上而下规划,自下而上估算
规划方向(↓):
Epic → Feature → Story → Task
(产品经理主导)
估算方向(↑):
Task → Story → Feature → Epic
(开发团队主导)
平衡点:
- 产品经理负责Epic和Feature的优先级
- 开发团队负责Story和Task的估算
- 在Feature层面达成共识原则2: 渐进明细
时间维度的明细程度:
当前Sprint:
- Story: 详细验收标准 ✓
- Task: 明确工时估算 ✓
下一Sprint:
- Story: 基本描述 ✓
- Task: 暂不拆分
未来2-3个Sprint:
- Feature: 高层描述 ✓
- Story: 可能需要调整
3个月后:
- Epic: 战略方向 ✓
- Feature: 可能变化
原则:
"Don't over-engineer未来的需求"原则3: 保持层级独立性
❌ 错误做法:
Epic包含100个Story → 跳过Feature层级
Feature包含Task → 跳过Story层级
✅ 正确做法:
Epic → Feature → Story → Task
每个层级职责明确,不交叉
例外情况:
小型简单需求可以简化:
Feature → Story → Task
(跳过Epic)8.2 在PingCode中建立团队规范
命名规范:
Epic命名:
格式: [业务目标] - [预期成果]
示例:
✓ 智能学习推荐 - 提升用户粘性
✓ 支付体系升级 - 提升成功率
❌ 推荐系统 (太笼统)
❌ Epic-001 (无业务含义)
Feature命名:
格式: [用户可感知的功能]
示例:
✓ 用户画像构建
✓ 智能工单路由
✓ 多语言支持
❌ 数据库优化 (技术导向)
❌ Phase 1开发 (无业务含义)
Story命名:
格式: [角色]可以[动作][对象]
示例:
✓ 用户可以搜索商品
✓ 管理员可以查看报表
✓ 系统可以发送通知
❌ 搜索功能 (缺少角色)
❌ US-123 (无业务含义)
Task命名:
格式: [动词][对象][补充说明]
示例:
✓ 实现商品搜索API
✓ 设计用户画像数据模型
✓ 编写推荐算法单元测试
❌ 开发 (太笼统)
❌ Task-001 (无技术含义)编号规范:
在PingCode中配置编号前缀:
Epic: EPIC-001, EPIC-002...
Feature: FEAT-001, FEAT-002...
Story: US-001, US-002...
Task: TASK-001, TASK-002...
Bug: BUG-001, BUG-002...
优势:
- 快速识别工作项类型
- 方便代码提交关联
- 清晰的追溯性
Git提交示例:
git commit -m "FEAT-003: 实现用户画像API #US-012"状态流转规范:
Story生命周期:
新建 → 待规划 → Ready → 开发中 → 代码审查
→ 测试中 → UAT → 已完成
关键检查点:
待规划 → Ready:
✓ 验收标准完整
✓ UI设计完成
✓ 技术方案评审通过
✓ 依赖已识别
✓ 故事点已估算
开发中 → 代码审查:
✓ 功能开发完成
✓ 单元测试通过
✓ 代码已提交
✓ PR已创建
测试中 → UAT:
✓ 功能测试通过
✓ 集成测试通过
✓ Bug已修复
✓ 测试报告完成
UAT → 已完成:
✓ 产品负责人验收通过
✓ 文档已更新
✓ 部署到生产环境
✓ 用户通知已发送8.3 定义完成标准(DoD)
Story级DoD:
Story完成检查清单:
功能完整性:
□ 所有验收标准通过
□ 边界条件已测试
□ 异常场景已处理
□ UI与设计稿一致
代码质量:
□ 代码审查已通过
□ 单元测试覆盖率≥80%
□ 无严重代码异味
□ 遵循团队编码规范
测试:
□ 功能测试通过
□ 集成测试通过
□ 回归测试通过
□ 性能测试达标(如适用)
文档:
□ API文档已更新
□ 用户文档已更新
□ 技术决策已记录
□ 知识库已更新
集成:
□ 代码已合并到主分支
□ CI/CD流水线通过
□ 部署到测试环境成功
□ 产品负责人已验收
在PingCode中:
□ Story状态为"已完成"
□ 实际工时已记录
□ 工作日志已填写
□ 相关附件已上传Feature级DoD:
Feature完成检查清单:
功能交付:
□ 所有Story已完成
□ Feature验收标准通过
□ 用户可以使用完整功能
□ 满足非功能需求
质量保证:
□ 端到端测试通过
□ 用户验收测试通过
□ 性能测试达标
□ 安全测试通过
发布准备:
□ 生产环境配置就绪
□ 监控和告警配置完成
□ 回滚方案已准备
□ 应急预案已制定
文档和培训:
□ 用户手册完整
□ 培训材料准备好
□ 运维文档完成
□ FAQ文档更新
反馈循环:
□ 发布公告已发送
□ 收集早期用户反馈
□ 监控关键指标
□ 制定优化计划8.4 常见陷阱和解决方案
陷阱1: Epic太大太模糊
症状:
- Epic持续1年以上无法完成
- 包含30+个Feature
- 成功标准不明确
- 团队失去方向感
解决方案:
1. 重新审视Epic,是否应该拆分为多个Epic
2. 明确MVP范围,聚焦核心价值
3. 设置阶段性里程碑
4. 定义可量化的成功指标
在PingCode中:
- 创建Epic拆分工作坊
- 使用标签标识Epic阶段
- 设置Epic季度审查提醒陷阱2: Feature和Story边界模糊
症状:
- Feature只包含1-2个Story
- Story需要2-3个Sprint完成
- 团队分不清Feature和Story
判断方法:
Feature: 用户可以独立感知的功能
Story: 实现Feature的一个方面或场景
示例对比:
✓ Feature: 订单管理系统
├─ Story: 用户可以创建订单
├─ Story: 用户可以修改订单
└─ Story: 用户可以取消订单
❌ Feature: 创建订单
└─ Story: 实现创建订单功能
(Feature和Story重复)陷阱3: Story拆分过细或过粗
过细的问题:
- Story只需要2-3小时完成
- Story数量过多难以管理
- Sprint Planning会议冗长
过粗的问题:
- Story需要2-3周完成
- 多人并行开发困难
- 难以跟踪进度
最佳实践:
Story大小: 3-10天工作量
如果<3天: 考虑合并
如果>10天: 必须拆分
在PingCode中:
- 设置Story点数警告(>13点)
- 使用颜色标识Story大小
- 在Backlog精化会中识别陷阱4: Task拆分不合理
症状:
- Task过于技术化,业务方看不懂
- Task之间依赖复杂
- 一个人承担过多Task
改进方法:
1. 按垂直切片拆分Task:
✓ 前后端Task成对出现
✓ Task可以独立交付价值
2. 平衡Task分配:
避免: 张三10个Task,李四1个Task
改进: 均衡分配,结对编程
3. Task粒度一致:
避免: Task A 1小时, Task B 16小时
改进: 统一在2-8小时范围
在PingCode中:
- 使用看板视图识别瓶颈
- 设置Task WIP限制
- 生成工作负载平衡报表第九部分:度量和持续改进
9.1 关键度量指标
Epic层面:
战略对齐度:
- Epic与OKR关联率: 100%目标
- Epic成功指标达成率: ≥80%
- Epic ROI: 投入vs收益比
进度健康度:
- Epic按时完成率: ≥70%
- Epic范围变更率: ≤20%
- Epic风险等级分布
在PingCode中配置:
- Epic仪表板
- 战略对齐矩阵
- Epic健康度评分卡Feature层面:
交付效率:
- Feature周期时间: 平均4周
- Feature吞吐量: 每月2-3个
- Feature首次通过率: ≥85%
价值实现:
- Feature使用率: ≥60%用户
- Feature业务价值得分: 平均≥7/10
- Feature客户满意度: ≥4.0/5.0
在PingCode中跟踪:
- Feature燃尽图
- Feature价值流分析
- Feature A/B测试结果Story层面:
开发效率:
- Story平均周期时间: 5-7天
- Story首次测试通过率: ≥80%
- Story返工率: ≤15%
质量指标:
- Story缺陷密度: ≤2个Bug/Story
- Story技术债比率: ≤10%
- Story自动化测试覆盖率: ≥75%
在PingCode中监控:
- Sprint燃尽图
- 速率趋势图
- 质量趋势图Task层面:
执行效率:
- Task平均完成时间: 4小时
- Task工时估算准确度: ±20%
- Task阻塞率: ≤5%
协作效率:
- Task交接次数: ≤2次
- Task等待时间: ≤4小时
- Task并行效率: ≥60%
在PingCode中分析:
- Task流动效率
- 阻塞原因分析
- 工时偏差报表9.2 PingCode报表配置
自定义Epic仪表板:
在PingCode创建自定义仪表板:
Epic总览:
┌─────────────────────────────────┐
│ Epic总数: 5 │
│ 进行中: 3 │
│ 已完成: 2 │
│ 平均完成度: 67% │
└─────────────────────────────────┘
Epic进度对比:
Epic 1 ████████████████████ 100%
Epic 2 ████████████████░░░░ 80%
Epic 3 ████████████░░░░░░░░ 60%
Epic 4 ████░░░░░░░░░░░░░░░░ 20%
Epic 5 ░░░░░░░░░░░░░░░░░░░░ 0%
Epic健康度:
🟢 Epic 1, Epic 2: 健康
🟡 Epic 3: 需要关注
🔴 Epic 4: 风险高
Epic时间线:
2025年
Q1 ├─Epic 1─┤├─Epic 2──┤
Q2 ├──Epic 3───┤
Q3 ├─Epic 4─┤
Q4 ├─Epic 5─┤Feature价值流分析:
Feature生命周期分析:
平均周期时间: 28天
├─ 待规划: 3天 (11%)
├─ 规划中: 5天 (18%)
├─ 设计中: 4天 (14%)
├─ 开发中: 12天 (43%) ← 瓶颈
├─ 测试中: 3天 (11%)
└─ 发布准备: 1天 (3%)
改进机会:
🔴 开发阶段占比过高
→ 建议: Story拆分更细
→ 建议: 增加开发资源
🟡 规划设计时间长
→ 建议: 提前准备设计
→ 建议: 建立设计系统
在PingCode中:
- 启用"价值流度量"功能
- 设置周期时间目标
- 标识瓶颈环节Sprint速率趋势:
团队速率分析:
速率趋势(最近6个Sprint):
25│ ●──●
20│ ●─╱
15│ ●─╱
10│●
5│
0└─────────────
S1 S2 S3 S4 S5 S6
统计数据:
- 平均速率: 18点/Sprint
- 标准差: 3点
- 预测速率: 20-22点
- 趋势: 上升
速率稳定性: ⚠️ 中等
建议:
- 保持当前承诺水平
- 减少Sprint中断
- 持续改进流程
在PingCode中:
- 自动计算团队速率
- 预测未来Sprint容量
- 识别异常Sprint9.3 持续改进流程
月度需求质量审查:
审查议程(2小时):
第一部分: 数据回顾(30分钟)
- Epic/Feature/Story完成情况
- 速率和周期时间趋势
- 质量指标(缺陷率、返工率)
- 从PingCode导出数据
第二部分: 问题识别(45分钟)
- Story质量问题(不符合INVEST)
- 估算偏差分析
- 需求变更频率
- 团队痛点收集
第三部分: 改进计划(45分钟)
- 确定Top 3改进机会
- 制定具体行动计划
- 分配改进负责人
- 设定下次检查点
输出:
- 质量审查报告
- 改进行动项列表
- PingCode中创建改进Story季度Epic回顾:
回顾会议(4小时):
Part 1: Epic成果展示
- 已完成Epic演示
- 业务价值验证
- 成功指标达成情况
Part 2: Epic经验总结
做得好的:
✓ Epic拆分合理
✓ 跨团队协作顺畅
✓ 技术方案创新
需要改进:
△ 需求变更太频繁
△ 技术债务累积
△ 测试资源不足
Part 3: 下季度Epic规划
- 审查Epic优先级
- 调整Epic范围
- 识别资源需求
- 制定风险应对计划
在PingCode中记录:
- Epic回顾文档
- 经验教训库
- 改进行动跟踪第十部分:模板和检查清单
10.1 Epic创建模板
markdown
# Epic: [Epic名称]
## 业务背景
[描述当前业务痛点或机会]
## 目标
为了 [业务目标]
我们需要 [大的功能范围]
从而实现 [预期的业务成果]
## 目标用户
- 主要用户: [描述]
- 次要用户: [描述]
## 成功指标
1. [关键指标1] - 目标值: [X]
2. [关键指标2] - 目标值: [Y]
3. [关键指标3] - 目标值: [Z]
## 业务价值
- 收入影响: [量化]
- 成本节省: [量化]
- 风险降低: [描述]
- 客户满意度: [预期提升]
## 范围
### 包含
- [功能领域1]
- [功能领域2]
### 不包含
- [明确不做什么]
## 依赖和风险
### 依赖项
- [外部依赖1]
- [内部依赖2]
### 主要风险
- [风险1] - 应对策略: [...]
- [风险2] - 应对策略: [...]
## 时间规划
- 预计开始: [日期]
- 预计完成: [日期]
- 关键里程碑:
- [里程碑1]: [日期]
- [里程碑2]: [日期]
## 关联信息
- 相关OKR: [链接]
- 市场调研: [链接]
- 竞品分析: [链接]
## 在PingCode中的配置
- Epic ID: [EPIC-XXX]
- 负责人: [姓名]
- 优先级: [P0-P3]
- 标签: [#标签1, #标签2]10.2 Feature创建模板
markdown
# Feature: [Feature名称]
## 业务价值
为 [目标用户]
提供 [功能能力]
使其能够 [达成的目标]
## 用户场景
[描述用户如何使用这个功能的典型场景]
## 验收标准(高层级)
1. [关键场景1]
2. [关键场景2]
3. [关键场景3]
## 功能范围
### 包含
- [具体功能点1]
- [具体功能点2]
### 不包含
- [明确不做的1]
- [明确不做的2]
## 非功能需求
- 性能: [要求]
- 安全: [要求]
- 可用性: [要求]
- 兼容性: [要求]
## UI/UX要求
- 设计稿: [链接]
- 交互原型: [链接]
- 设计规范: [遵循XX规范]
## 技术约束
- 技术栈: [说明]
- 架构要求: [说明]
- 第三方依赖: [列举]
## 测试策略
- 测试类型: [单元/集成/端到端]
- 测试覆盖率: [目标%]
- 测试数据: [准备要求]
## 发布计划
- 目标版本: [V X.X]
- 预计发布日期: [日期]
- 发布范围: [全量/灰度/A/B]
## Story拆分(初步)
- Story 1: [标题]
- Story 2: [标题]
- ...
## 依赖关系
- 前置Feature: [FEAT-XXX]
- 后续Feature: [FEAT-XXX]
- 技术依赖: [说明]
## 在PingCode中的配置
- Feature ID: [FEAT-XXX]
- 父Epic: [EPIC-XXX]
- 负责人: [产品经理]
- 开发负责人: [Tech Lead]
- 优先级: [P0-P3]
- 预估: [粗略故事点]
- 所属Sprint: [Sprint X-Y]10.3 User Story创建模板
markdown
# User Story: [Story标题]
## 用户故事(3W)
作为 [角色]
我想要 [功能]
以便于 [价值]
## 业务价值
[详细说明这个Story带来的价值]
## 验收标准
### 场景1: [场景名称]
Given [前置条件]
And [额外条件]
When [用户操作]
Then [预期结果]
And [额外结果]
### 场景2: [场景名称]
...
### 场景3: 边界条件
...
### 场景4: 异常处理
...
## 性能标准
- 响应时间: [X秒]
- 并发支持: [Y用户]
- 数据量: [Z条记录]
## UI/UX要求
- 设计稿: [链接]
- 交互说明: [链接]
- 响应式: [要求]
- 无障碍: [要求]
## 技术要点
- API接口: [说明]
- 数据模型: [说明]
- 算法逻辑: [说明]
- 第三方集成: [说明]
## 测试要点
- 单元测试: [覆盖范围]
- 集成测试: [测试场景]
- 端到端测试: [用户流程]
- 性能测试: [负载要求]
## 依赖和风险
- 依赖Story: [US-XXX]
- 技术风险: [说明]
- 业务风险: [说明]
## Definition of Done
- [ ] 所有验收标准通过
- [ ] 代码审查通过
- [ ] 单元测试覆盖率≥80%
- [ ] 集成测试通过
- [ ] 产品负责人验收
- [ ] 文档已更新
- [ ] 部署到测试环境
## 在PingCode中的配置
- Story ID: [US-XXX]
- 父Feature: [FEAT-XXX]
- 负责人: [开发人员]
- 产品负责人: [PO]
- 测试负责人: [QA]
- 优先级: [P0-P3]
- 故事点: [1-13]
- Sprint: [Sprint X]
- 标签: [#标签]10.4 检查清单集合
Epic Ready检查清单:
□ Epic名称清晰,描述业务目标
□ 业务背景和价值明确
□ 成功指标可量化
□ 目标用户已识别
□ 范围边界清晰(包含/不包含)
□ 关联到公司OKR
□ 时间框架合理(3-12个月)
□ 主要风险已识别
□ 依赖关系已记录
□ 利益相关者已确认
□ Epic负责人已分配
□ 在PingCode中正确配置Feature Ready检查清单:
□ Feature名称体现用户价值
□ 关联到父Epic
□ 业务价值清晰描述
□ 用户场景完整
□ 高层验收标准明确
□ 功能范围清晰界定
□ 非功能需求已定义
□ UI/UX设计已完成
□ 技术方案已评审
□ 测试策略已制定
□ 依赖关系已识别
□ Feature负责人明确
□ 预计时间合理(2-4周)
□ 可拆分为3-8个Story
□ 在PingCode中正确配置Story Ready检查清单 (DoR):
□ Story符合INVEST原则
- □ Independent (独立)
- □ Negotiable (可协商)
- □ Valuable (有价值)
- □ Estimable (可估算)
- □ Small (小型)
- □ Testable (可测试)
□ 用户故事格式完整(作为...我想要...以便于...)
□ 验收标准完整且可测试
□ UI/UX设计已完成
□ 技术依赖已识别
□ 测试用例已准备
□ Story点数已估算
□ 可在一个Sprint完成
□ 团队理解Story内容
□ 产品负责人已确认