文章目录
- 摘要
- Abstract
- 一、PageIndex项目
-
- [1. 主运行脚本](#1. 主运行脚本)
- [2. PDF目录提取与结构化处理](#2. PDF目录提取与结构化处理)
-
- [2.1 PDF文件预处理](#2.1 PDF文件预处理)
- [2.2 检测并提取目录](#2.2 检测并提取目录)
- [二、《EAST: An Efficient and Accurate Scene Text Detector》论文阅读](#二、《EAST: An Efficient and Accurate Scene Text Detector》论文阅读)
-
- [1. 摘要](#1. 摘要)
- [2. 核心内容](#2. 核心内容)
-
- [2.1 研究背景与任务定义](#2.1 研究背景与任务定义)
- [2.2 模型架构与核心设计](#2.2 模型架构与核心设计)
-
- [2.2.1 整体流水线](#2.2.1 整体流水线)
- [2.2.2 网络结构](#2.2.2 网络结构)
- [2.2.3 标签生成与损失函数](#2.2.3 标签生成与损失函数)
- [2.2.4 局部感知 NMS](#2.2.4 局部感知 NMS)
- [3. 技术创新](#3. 技术创新)
- [4. 解决问题](#4. 解决问题)
- 总结
摘要
本周主要了解PageIndex项目的命令行接口和主要参数,学习如何调用PageIndex处理PDF和Markdown文件以及对PDF目录提取与结构化处理部分核心内容进行学习解读。
同时,阅读一篇OCR相关的论文,论文提出一种高效且精准的场景文本检测流水线(EAST),旨在解决传统方法多阶段流程导致的性能与效率瓶颈。
Abstract
This week, I mainly learned about the command-line interface (CLI) and key parameters of the PageIndex project. I studied how to invoke PageIndex to process PDF and Markdown files, and also conducted in-depth interpretation of the core content related to PDF table of contents extraction and structured processing.
Meanwhile, I read a paper related to OCR, which proposes an efficient and accurate scene text detection pipeline (EAST). This pipeline is designed to address the performance and efficiency bottlenecks caused by the multi-stage workflows of traditional methods.
一、PageIndex项目
PageIndex是一个基于推理的无向量RAG 框架,专门用来查 PDF 文档里的内容。
它通过将PDF文档转换为语义化的层次树结构,就像阅读书籍的顺序:一级标题,二级标题,小节、段落,最后才是具体句子。使大型语言模型能够以类似人类的方式导航和检索文档内容(比如先定位到某一章,再钻进某一节,最后精准找到想要的那句话)。无需传统的向量数据库或文档分块技术( "把书撕成碎片再找碎片"),而是 "直接拿着带目录的整本书,按目录导航找内容",速度快,准确度高,同时还保持了文档内容的完整性和上下文关系。
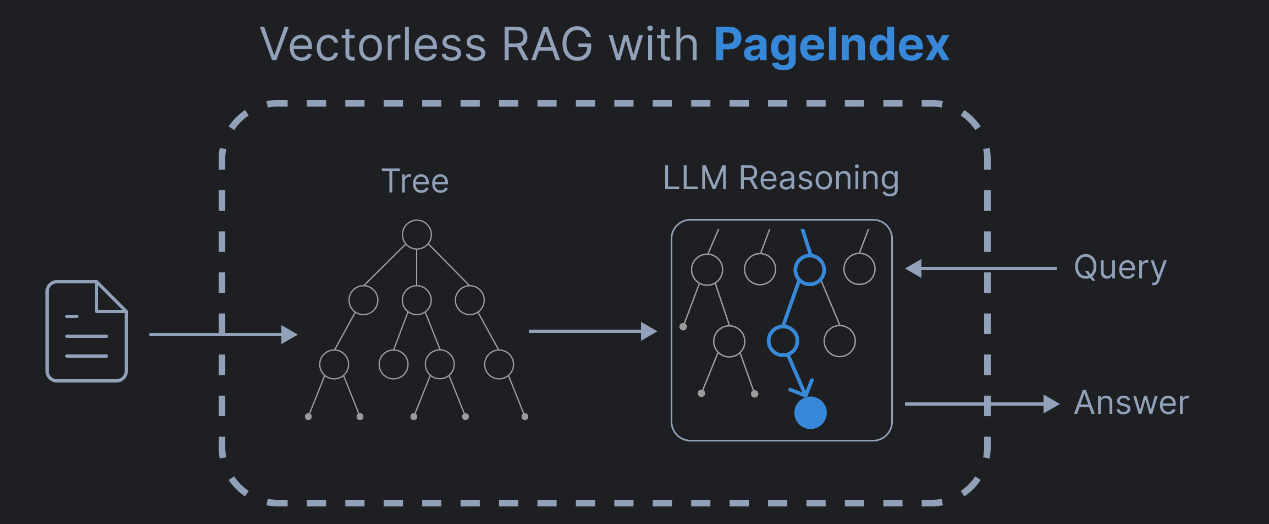
1. 主运行脚本
项目提供命令行交互入口,支持针对不同的 PDF/Markdown 文档的输入,根据两种文档格式的特性,分别完成解析、层级提取、生成统一结构的树形数据,最后将结构化结果持久化保存为 JSON 文件。
2. PDF目录提取与结构化处理
本段代码是能自动处理PDF目录的工具核心部分。主要通过六个关键环节(PDF文件预处理、检测并提取目录、适配不同目录场景做转换、验证并修复错误目录、构建层级树形结构、补充节点信息)形成完整处理流程,能从解析PDF开始,最终输出清晰的结构化目录。
2.1 PDF文件预处理
先校验输入是否为有效PDF(文件路径或流),再解析PDF每页的文本内容并统计令牌数,为后续处理整理好原始数据
1,page_index_main(输入验证与初始化)
校验输入文件类型是否为有效 PDF通过判断文件路径或者BytesIO 流。
(1)page_index_builder:异步构建函数
作用:在 tree_parser 生成基础树形结构后,根据配置参数(opt)完成节点信息增强,并最终组装返回标准化的 PDF 处理结果
(2)structure = await tree_parser(page_list, opt, doc=doc, logger=logger) 获取基础树形结构
-
write_node_id :补充节点唯一 ID
当配置 if_add_node_id 为 yes 时,为树形结构中的每个节点生成并添加唯一标识 ID,方便后续对节点进行定位、关联、检索等操作,保证每个节点的唯一性。
-
add_node_text : 补充节点正文文本
当配置 if_add_node_text 为 yes 时,将每个节点对应的 PDF 正文文本提取并填充到节点中,为后续生成 AI 摘要提供原始文本数据,也方便直接查看节点对应的完整内容。
-
generate_summaries_for_structure : 生成节点 AI 摘要
若未配置添加节点文本(if_add_node_text == 'no'),先临时添加正文文本(因为生成摘要需要原始文本支撑);
调用 await 执行异步方法,调用指定的 AI 模型(opt.model,默认 gpt-4o),为每个节点生成简洁摘要;
若未配置添加节点文本,摘要生成完成后立即调用 remove_structure_text 移除正文文本,仅保留摘要,达到节省存储空间、精简结果数据的目的。
-
create_clean_structure_for_description、generate_doc_description : 生成文档整体描述
当配置 if_add_doc_description 为 yes 时,先清理树形结构中的冗余字段,生成干净的结构数据,再调用 AI 模型生成整个 PDF 文档的整体描述,概括文档核心内容。
补充:
- Await:异步函数内部若要调用其他异步函数,必须使用 await 关键字,await 会暂停当前协程的执行,等待被调用的异步任务完成并返回结果后,再继续执行后续代码,保证逻辑的有序性。
- 配置参数:opt
疑问1:async 是什么?
async 是 Python 中用于定义异步函数(也叫协程函数) 的关键字,被 async 修饰的函数不会直接执行并返回结果,而是会返回一个协程对象。
疑问2:协程对象是什么?
协程对象就像一个待执行的任务清单,它只是描述了要做什么,并没有真正开始执行,需要通过特定方式触发执行。
疑问3:协程对象的执行方式?
方式 1:使用 await 关键字(仅能在其他协程函数内部使用),会触发协程对象执行,等待其完成并返回结果。
方式 2:使用 asyncio.run() 函数(顶层调用方式,用于启动整个异步程序),这是最常用的启动协程的方式,会创建一个异步事件循环,执行协程对象并返回最终结果。
2,get_page_tokens(PDF内容解析与提取)
解析 PDF 每页文本内容并统计令牌数,整理成标准化page_list原始数据,为后续所有处理环节打下基础。
(1)pdf_parser == "PyPDF2",pdf_parser == "PyMuPDF":
使用PyPDF2或PyMuPDF解析PDF文档
(2)使用for循环提取每页的文本内容:页号,内容,每页的token数量
返回 page_list 结构: (page_text_1, token_count_1), (page_text_2, token_count_2), ...
2.2 检测并提取目录
检测并提取目录:从PDF首页开始逐页检查,判断页面是否含目录(排除摘要、图表列表等非目录内容),连续收集目录页直至遇到非目录页;若首次找到的目录无页码,会继续遍历后续页面寻找带页码的完整目录,最终提取目录文本并整理成统一格式
1,find_toc_pages(检测)
2,toc_extractor(提取)
3,find_toc_pages:从 PDF 首页逐页检查
1,调用toc_detector_single_page判断是否为目录页,排除摘要、图表列表等
连续收集目录页
4,toc_extractor:提取目录文本并统一格式(省略号转冒号),若首次目录无页码,还会继续遍历寻找完整目录
二、《EAST: An Efficient and Accurate Scene Text Detector》论文阅读
1. 摘要
该论文提出一种高效且精准的场景文本检测流水线(EAST),旨在解决传统方法多阶段流程导致的性能与效率瓶颈。EAST 基于全卷积网络(FCN),可直接从整幅图像中预测任意方向、四边形或旋转矩形形状的单词或文本行,省去候选区域聚合、单词分割等冗余中间步骤,仅通过 "FCN 预测 + 非极大值抑制(NMS)" 两阶段完成检测。在 ICDAR 2015、COCO-Text、MSRA-TD500 等标准数据集上的实验表明,该算法在准确率和效率上均显著超越当时最先进方法。其中,在 ICDAR 2015 数据集上,720p 分辨率下实现 0.782 的 F-score,推理速度达 13.2fps,多尺度测试时 F-score 进一步提升至 0.8072。
2. 核心内容
2.1 研究背景与任务定义
场景文本检测是文本信息提取与理解的前置关键步骤,需从自然场景图像中精准定位文本区域(含任意方向、不同尺度、复杂背景下的文本)。传统方法(无论是手工设计特征还是深度学习驱动)多采用多阶段流水线(如候选区域提取、过滤、聚合、文本行形成等),存在流程冗余、参数调优复杂、误差累积等问题,导致在挑战性场景(低分辨率、几何畸变、背景杂乱)下的准确率和效率难以兼顾。EAST 的核心目标是构建简洁的端到端流水线,直接输出最终文本区域,平衡检测精度与推理速度。
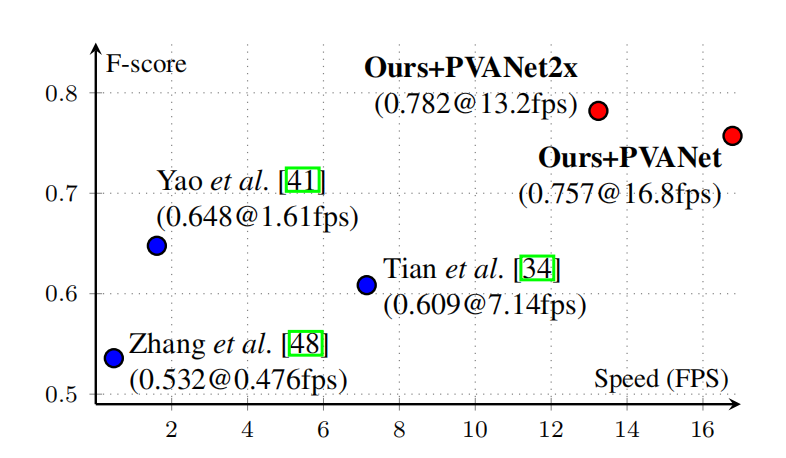
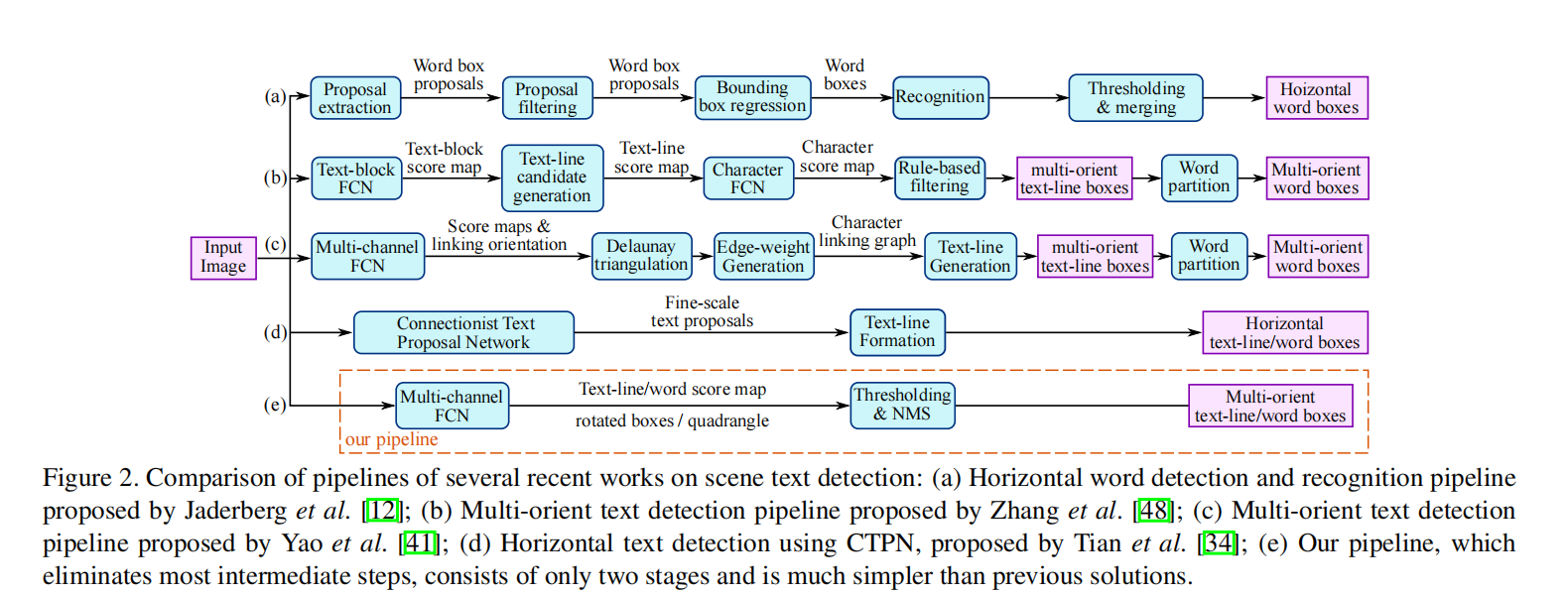
2.2 模型架构与核心设计
2.2.1 整体流水线
EAST 遵循 "输入图像→FCN 预测→阈值筛选→NMS 合并" 的两阶段流程:
第一阶段:FCN 输出像素级的文本得分图(Score Map)和几何形状图(Geometry Map),得分图表示像素属于文本区域的置信度,几何图描述文本区域的形状参数;
第二阶段:对置信度高于阈值的几何形状,通过改进的局部感知 NMS 合并冗余预测,得到最终文本检测框(旋转矩形 RBOX 或四边形 QUAD)。
2.2.2 网络结构
网络采用类 U-Net 的编码器 - 解码器架构,分为特征提取主干、特征融合分支和输出层三部分:
特征提取主干:采用 PVANET(轻量型)、PVANET2x(通道数翻倍)或 VGG16 作为预训练主干,提取 4 个不同尺度的特征图(分辨率分别为输入的 1/32、1/16、1/8、1/4),兼顾全局语义和局部细节;
特征融合分支:通过上采样(Unpool)将高层特征与低层特征逐阶段拼接,经 1×1 卷积降维与 3×3 卷积特征融合,既利用高层特征识别大文本,又通过低层特征精准定位小文本,同时控制计算开销;
输出层:通过 1×1 卷积将融合特征映射为 1 通道得分图和多通道几何图,几何图支持两种格式(RBOX:5 通道,含轴对齐框参数 + 旋转角;QUAD:8 通道,含四边形 4 个顶点偏移量)。
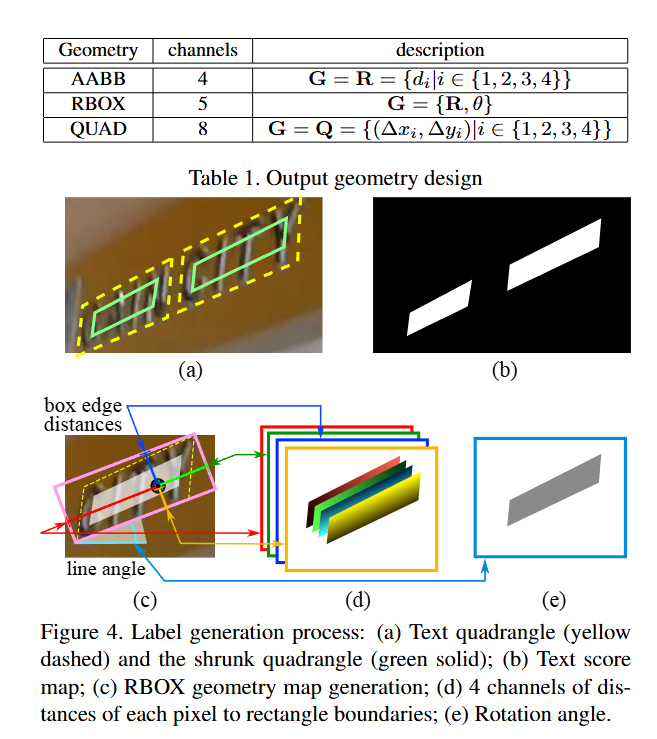
2.2.3 标签生成与损失函数
标签生成:得分图标签为文本区域的收缩版(避免边缘像素干扰),通过计算顶点参考长度并向内收缩边缘生成;几何图标签根据数据集标注格式(RBOX/QUAD)生成,RBOX 标签含边界距离和旋转角,QUAD 标签含顶点坐标偏移量;
损失函数:总损失为得分图损失与几何图损失的加权和(λ_g=1):
得分图损失:采用类别平衡交叉熵,自动平衡文本与背景像素的比例,无需手动采样或难例挖掘;
几何图损失:RBOX 采用 IoU 损失(尺度不变,适配不同大小文本)+ 角度损失(1-cos (θ-θ*));QUAD 采用尺度归一化平滑 L1 损失,通过短边长度归一化,避免大文本区域主导损失。
2.2.4 局部感知 NMS
针对传统 NMS 的 O (n²) 复杂度,提出局部感知 NMS:假设相邻像素的预测几何形状高度相关,按行优先顺序遍历预测框,仅与当前行的上一个有效框判断是否合并,合并时按置信度加权平均坐标。该方法在最佳场景下复杂度降至 O (n),大幅提升后处理速度,且通过投票机制提升视频文本检测的稳定性。
3. 技术创新
1,极简端到端流水线设计:摒弃传统多阶段流程(候选提取、过滤、聚合等),通过单一 FCN 直接预测文本区域的置信度和几何形状,实现 "图像→文本框" 的端到端检测,减少中间步骤的误差传递和计算开销。
2,多尺度特征融合与灵活几何表示:借鉴 U-Net 架构逐阶段融合高低层特征,平衡大文本识别与小文本定位;支持旋转矩形(RBOX)和四边形(QUAD)两种几何输出,适配不同场景需求(如 RBOX 适配任意方向文本,QUAD 适配不规则畸变文本)。
3,针对性损失函数设计:得分图采用类别平衡交叉熵,解决文本与背景像素不均衡问题,无需复杂采样策略;几何图损失采用尺度不变设计(IoU 损失、归一化平滑 L1 损失),确保不同大小文本的检测精度一致。
4,高效局部感知 NMS:提出行优先的局部合并策略,大幅降低 NMS 复杂度,同时通过置信度加权平均实现预测框投票融合,提升检测稳定性,尤其适配视频文本检测场景。
5,轻量型模型适配与泛化:支持 PVANET 等轻量主干网络,在保证精度的同时提升推理速度,满足实时部署需求;模型不依赖特定文本布局或语言,在中英双语、不同标注格式的数据集上均表现优异,泛化能力强。
4. 解决问题
1,传统多阶段检测的流程冗余与效率低下问题:通过单 FCN 直接输出最终结果,省去候选区域生成、文本行聚合等冗余步骤,将推理速度提升数倍,解决大规模部署的效率瓶颈。
2,不同尺度文本的检测精度失衡问题:通过多尺度特征融合,高层特征捕捉大文本的全局语义,低层特征定位小文本的精细位置,结合尺度不变损失函数,实现大小文本的精准检测。
3,文本与背景像素不均衡导致的训练偏差问题:采用类别平衡交叉熵损失,自动调整正负样本的权重,避免模型偏向背景像素,提升文本区域的召回率和精度。
4,传统 NMS 的高复杂度与冗余预测问题:局部感知 NMS 通过空间相关性假设降低计算复杂度,同时加权合并相邻预测框,减少冗余输出,提升检测结果的简洁性。
5,复杂场景文本的鲁棒性不足问题:通过灵活的几何表示(RBOX/QUAD)适配任意方向、畸变文本,结合多尺度特征和强泛化主干网络,提升在低分辨率、复杂背景、光照变化等场景下的检测鲁棒性。
总结
项目内容:
PageIndex专门用来查 PDF 文档里的内容。将PDF文档转换为语义化的层次树结构,使大型语言模型能够以类似人类的方式导航和检索文档内容,按目录导航找内容",速度快,准确度高,同时还保持了文档内容的完整性和上下文关系。
论文内容:
模型的核心优势在于 "简洁与高效的统一"------ 通过端到端设计减少误差传递,通过轻量架构与优化后处理平衡速度与精度,其设计思路对后续文本检测乃至通用目标检测领域均有重要参考价值。