jwt
先伪造cookie
curl -H "Cookie: token=你的JWT" http://challenge1.pctf.top:31322/dashboard
Week2-Do_you_know_session?
先在search用ssti{{config}}找到secret_key
伪造session:先抓包可以知道他的admin格式,base64解密cookie。
python flask_session_cookie_manager3.py encode -s "1919810#mistyovo@foxdog@lzz0403#114514" -t "{'username':'admin'}"
读取环境文件/proc/self/environ
Week1-EZPHP
bp爆破数字,之后分析代码,用include+data://数据封装流执行命令。
Week1-We_will_rockyou
用bp结合他提示的字典爆破
Week1-sql_in
普通的sql注入语句就可以
Week1-php_with_md5
MD5绕过手段都搜到的,最后命令执行而已
Week1-复读机
ssti注入,flag在环境变量
Week2-what_is_jsfuck
根据源码的提示输入,可以获得jsfuck加密字符串,解密即可。
Week1-test_your_nc
#!/usr/bin/env python3
"""
PCTF2025 PWN题目终极解题脚本
处理跨行长表达式和高精度计算
"""
import socket
import re
def convert_to_base(num, target_base):
"""将10进制数字转换为目标进制"""
if num == 0:
return "0"
if num < 0:
# 处理负数
return "-" + convert_to_base(-num, target_base)
digits = "0123456789abcdefghijklmnopqrstuvwxyz"
result = ""
while num > 0:
result = digits[num % target_base] + result
num //= target_base
return result
def solve_expression(expression, base):
"""解决数学表达式"""
expression = expression.strip()
if '%' in expression:
# 模运算
parts = expression.split('%')
num1 = parts[0].strip()
num2 = parts[1].strip()
val1 = int(num1, base)
val2 = int(num2, base)
return val1 % val2
elif '+' in expression:
# 加法
parts = expression.split('+')
num1 = parts[0].strip()
num2 = parts[1].strip()
val1 = int(num1, base)
val2 = int(num2, base)
return val1 + val2
elif '*' in expression:
# 乘法
parts = expression.split('*')
num1 = parts[0].strip()
num2 = parts[1].strip()
val1 = int(num1, base)
val2 = int(num2, base)
return val1 * val2
elif '-' in expression:
# 减法 - 需要处理以负数开头的情况
# 如果表达式以'-'开头,第一个操作数包含负号
if expression.startswith('-'):
# 找到第二个操作符的位置
# 跳过开头的负号,从第二个字符开始查找
operator_pos = -1
for i in range(1, len(expression)):
if expression[i] in '+-*%':
operator_pos = i
break
if operator_pos > 0:
num1 = expression[:operator_pos].strip() # 包含负号的第一个操作数
num2 = expression[operator_pos+1:].strip() # 第二个操作数
operator = expression[operator_pos]
else:
# 只有一个负数,没有操作符
return int(expression, base)
else:
# 正常的减法
parts = expression.split('-')
num1 = parts[0].strip()
num2 = parts[1].strip()
operator = '-'
# 计算结果
val1 = int(num1, base)
val2 = int(num2, base)
if operator == '-':
return val1 - val2
elif operator == '+':
return val1 + val2
elif operator == '*':
return val1 * val2
elif operator == '%':
return val1 % val2
return None
def clean_and_parse_question(data):
"""清理并解析题目数据"""
# 移除ANSI转义序列
import re
ansi_escape = re.compile(r'\x1b\[[0-9;]*m')
clean_data = ansi_escape.sub('', data)
# 移除多余的空白字符
clean_data = re.sub(r'\s+', ' ', clean_data)
# 查找题目模式
pattern = r'\[(\d+)\]\s*\(base\s*(\d+)\)\s*(.+?)\s*=\s*\?'
match = re.search(pattern, clean_data)
if match:
question_num = int(match.group(1))
base = int(match.group(2))
expression = match.group(3).strip()
return question_num, base, expression
return None, None, None
def main():
"""主函数"""
host = "challenge2.pctf.top"
port = 30758
print(f"=== PCTF2025 PWN终极解题器 ===")
print(f"连接到 {host}:{port}...")
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
print("连接成功!")
# 接收欢迎信息
welcome = sock.recv(4096).decode('utf-8')
print("欢迎信息:")
print(welcome)
question_count = 0
correct_count = 0
buffer = ""
while True:
try:
# 接收数据
data = sock.recv(4096).decode('utf-8')
if not data:
print("连接断开")
break
print(f"收到服务器数据: {repr(data[:200])}...")
buffer += data
# 检查是否包含flag
if "flag{" in buffer.lower():
print("\n🎉 找到flag!")
# 提取flag
flag_match = re.search(r'flag\{[^}]+\}', buffer, re.IGNORECASE)
if flag_match:
print(f"Flag: {flag_match.group()}")
break
# 检查是否需要回答
if "Your answer" in buffer:
question_count += 1
# 解析题目
question_num, base, expression = clean_and_parse_question(buffer)
if question_num and base and expression:
print(f"\n--- 题目 {question_num} ---")
print(f"识别题目: {expression} (base {base})")
# 计算结果
result = solve_expression(expression, base)
if result is not None:
print(f"计算结果: {result} (base 10)")
# 转换回目标进制
answer = convert_to_base(result, base)
print(f"答案: {answer} (base {base})")
# 发送答案
sock.send((answer + '\n').encode('utf-8'))
print(f"已发送答案: {answer}")
else:
print("无法解析表达式")
sock.send(('\n').encode('utf-8'))
else:
print("无法匹配题目格式")
print(f"缓冲数据: {buffer[:200]}...")
sock.send(('\n').encode('utf-8'))
# 清空缓冲区
buffer = ""
# 检查完成情况
if "Correct answer:" in buffer or "Incorrect" in buffer:
print(f"检测到答案反馈: {buffer}")
result_match = re.search(r'You answered (\d+) out of (\d+) correctly', buffer)
if result_match:
correct = int(result_match.group(1))
total = int(result_match.group(2))
correct_count = correct
print(f"\n进度: {correct}/{total} 正确")
if correct >= total:
print("所有题目完成!")
# 等待flag
flag_data = sock.recv(4096).decode('utf-8')
print(f"最终数据: {flag_data}")
if "flag{" in flag_data.lower():
flag_match = re.search(r'flag\{[^}]+\}', flag_data, re.IGNORECASE)
if flag_match:
print(f"\n🎉 Flag: {flag_match.group()}")
break
except Exception as e:
print(f"处理题目时出错: {e}")
break
sock.close()
print("连接已关闭")
except Exception as e:
print(f"连接错误: {e}")
print("请检查网络连接或服务是否可用")
if __name__ == "__main__":
main()Week1-type_err
nc之后依次输入
2147483649
2147483648这两个字符串是爆破出来的
- 条件1 : 作为无符号整数,必须 < 2,147,483,650
- 2147483649 < 2,147,483,650
- 条件2 : 作为有符号整数,必须 < 0
- 2147483649在32位有符号表示中为 -2147483647 < 0
Week1-RSA&编码_五字神人
from Crypto.Util.number import *
a = b'W'
b = long_to_bytes(434923072869)
c = 1
d = 0
flag = b"flag{" + a + b + long_to_bytes(6878244986667165023) + str(d).encode() + str(c).encode() + b"_world_"
print(flag.decode())
from math import isqrt
from Crypto.Util.number import long_to_bytes
from sympy import isprime, nextprime
n = 330377051065383704146824011492521741219622541923276552221323283
c = 12491539177637031796988115750114582945111875502808737291015600
e = 65537
# 从 √n 向下找相邻素数对 (p, q) 满足 q = nextprime(p) 且 p*q = n
base = isqrt(n)
if base & 1 == 0:
base -= 1
p = base
while p > 2:
if isprime(p):
q = nextprime(p) # 真正的下一个素数
if p * q == n:
break
p -= 2
else:
raise RuntimeError('找不到相邻素数对')
# 标准 RSA 解密
phi = (p - 1) * (q - 1)
d = pow(e, -1, phi)
pt = pow(c, d, p * q)
print(long_to_bytes(pt).decode())week2-添油加醋
# 公钥数据
PUBLIC_KEY_DATA = {
"gf": 251,
"o": 2,
"v": 4,
"n": 6,
"public_polynomials": [
{
"x0^2": 102, "x0*x1": 108, "x0*x2": 97, "x0*x3": 103,
"x1^2": 123, "x1*x2": 67, "x1*x3": 48, "x2^2": 48,
"x2*x3": 107, "x3^2": 49, "x0*x4": 110, "x0*x5": 103,
"x1*x4": 95, "x1*x5": 119, "x2*x4": 49, "x2*x5": 116,
"x3*x4": 104, "x3*x5": 95, "constant": 0
},
{
"x0^2": 48, "x0*x1": 105, "x0*x2": 108, "x0*x3": 95,
"x1^2": 38, "x1*x2": 95, "x1*x3": 118, "x2^2": 49,
"x2*x3": 110, "x3^2": 101, "x0*x4": 103, "x0*x5": 52,
"x1*x4": 114, "x1*x5": 95, "x2*x4": 89, "x2*x5": 117,
"x3*x4": 109, "x3*x5": 125, "constant": 0
}
]
}
def extract_flag():
polynomials = PUBLIC_KEY_DATA['public_polynomials']
v, n = PUBLIC_KEY_DATA['v'], PUBLIC_KEY_DATA['n']
flag_chars = []
for polynomial in polynomials:
# 醋-醋项
for i in range(v):
for j in range(i, v):
term = f"x{i}^2" if i == j else f"x{i}*x{j}"
if term in polynomial and 32 <= polynomial[term] <= 126:
flag_chars.append(chr(polynomial[term]))
# 醋-油项
for i in range(v):
for j in range(v, n):
term = f"x{i}*x{j}"
if term in polynomial and 32 <= polynomial[term] <= 126:
flag_chars.append(chr(polynomial[term]))
return ''.join(flag_chars)
if __name__ == "__main__":
print(extract_flag())Week2-flower_dance
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
RC4解密脚本 - 从37字节验证数据中解出flag
密钥: "This_is_a_rc4_key"
加密算法: RC4 + 额外XOR 0x56操作
"""
def rc4_key_scheduling(key):
"""RC4密钥调度算法(KSA)"""
if isinstance(key, str):
key = key.encode('utf-8') # 将字符串转换为字节
key_length = len(key)
sbox = list(range(256))
j = 0
for i in range(256):
j = (j + sbox[i] + key[i % key_length]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
return sbox
def rc4_decrypt(data, key):
"""RC4解密函数"""
sbox = rc4_key_scheduling(key)
result = []
i = 0
j = 0
for byte in data:
i = (i + 1) % 256
j = (j + sbox[i]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
keystream_byte = sbox[(sbox[i] + sbox[j]) % 256]
# 关键:额外的XOR 0x56操作
modified_keystream = keystream_byte ^ 0x56
# 解密:ciphertext XOR keystream = plaintext
decrypted_byte = byte ^ modified_keystream
result.append(decrypted_byte)
return result
def main():
print("=== RC4解密 ===")
# 从程序中提取的37字节验证数据
stored_data = [
0x3E, 0x3, 0x28, 0x28, 0x81, 0x5A, 0xF9, 0x67, 0x8B, 0x75,
0x4A, 0xA2, 0x7D, 0xE0, 0xE8, 0x24, 0x8F, 0x3E, 0xAA, 0x6D,
0xD1, 0x6B, 0x35, 0x30, 0xFF, 0x84, 0x5A, 0x38, 0x75, 0xCB,
0x84, 0x9, 0x91, 0x27, 0x22, 0xBB, 0xFC
]
rc4_key = "This_is_a_rc4_key"
print(f"密钥: {rc4_key}")
print(f"数据长度: {len(stored_data)}字节")
# 解密
decrypted_data = rc4_decrypt(stored_data, rc4_key)
# 转换为可读字符串
flag = ''.join(chr(b) if 32 <= b <= 126 else f'\\x{b:02X}' for b in decrypted_data)
print(f"\\n解出的Flag: {flag}")
return flag
if __name__ == "__main__":
flag = main()Week2-ZeroTwo的权限
找到加密逻辑,去分析可以知道是在两个函数下面的对几个字符进行加密,解密之后运行程序输入就有flag
Week1-xor
key='X0R_SECRET_KEY'
v3=len(key)
enflag=[ 0x3E, 0x5C, 0x33, 0x38, 0x28, 0x36, 0x2A, 0x3F, 0x35, 0x38,
0x3A, 0x14, 0x3D, 0x36, 0x2A, 0x6F, 0x37, 0x31, 0x30, 0x37, 0x3A,
0x22, 0x31, 0x3D, 0x30, 0x25, 0x1A, 0x30, 0x2B, 0x6F, 0x25,
0x3A, 0x32, 0x2E, 0x3E]
c=len(enflag)
d=[]
i = 0
for i in range(0,c):
d=(ord(key[i%v3])^enflag[i])
print(chr(d),end='')Week1-upx
先脱壳,分析即可
key='X0R_SECRET_KEY'
v3=len(key)
enflag=[ 0x3E, 0x5C, 0x33, 0x38, 0x28, 0x36, 0x2A, 0x3F, 0x35, 0x38,
0x3A, 0x14, 0x30, 0x29, 0x20, 0x6F, 0x37, 0x31, 0x30, 0x37,
0x3A, 0x22, 0x31, 0x3D, 0x30, 0x25, 0x1A, 0x30, 0x2B, 0x6F,
0x25, 0x3A, 0x32, 0x2E, 0x3E]
c=len(enflag)
d=[]
for i in range(c):
d = (ord(key[i % 14]) ^ enflag[i])
print(chr(d), end='')Week1-base64
反编译,找到加密的base64字符串,解密即可
Week1-debugme
下断点,调试,数相同长度的字符串,找一下就有flag
Week1-ez_mobile
反编译直接找
Week1-flag
反编译直接找
Week1-who_is_machael_jackson
视频的图片对应跳舞的小人编码表,可以手搓
Week1-gcd&crt_rrrrabin
from gmpy2 import invert, mpz, powmod, gcd
from Crypto.Util.number import long_to_bytes
from itertools import product
def crt(remainders, moduli):
total = 0
M = 1
for m in moduli:
M *= m
for r, m in zip(remainders, moduli):
Mi = M // m
inv_Mi = invert(Mi, m)
total = (total + r * Mi * inv_Mi) % M
return total
p = mpz(52422530353062237701049766700758290753760741218584617696202165436435945548779)
q = mpz(73587958582711192545620173640651831661334658634186062105530360928110736463979)
r = mpz(18802950065093203880462134501728259512922582655586839741017760978309385635111)
s = mpz(67269415591498763228702900529068791749234991976857322064319402525861709343187)
ct = mpz(4448091925469096128068885100781363182770716164621345138110800781463583645604601074359479867405570427757659265270005212008739526641120214624390515483386638617312015652637296539797410174836497599067284286827607368418935274414553340354052637307884036774512146783697275824973418837479154090897687904529294888249)
e = 65537 << 4
n = p * q * r * s
phi = (p-1) * (q-1) * (r-1) * (s-1)
g = gcd(e, phi)
print("g =", g)
e_prime = e // g
d_prime = invert(e_prime, phi)
m_prime = powmod(ct, d_prime, n)
print("m_prime computed")
factors = [p, q, r, s]
solutions = []
for prime in factors:
a = m_prime % prime
o = (prime - 1) // 2
k = invert(16, o)
x0 = powmod(a, k, prime)
x1 = (-x0) % prime
solutions.append([x0, x1])
print("Solutions for prime found")
found = False
for comb in product(*solutions):
x = crt(comb, factors)
try:
flag = long_to_bytes(x)
if b'flag' in flag:
print(flag.decode())
found = True
break
except:
continue
if not found:
print("Not found")week2-看不见的答案
先Unicode隐写术提取隐藏字节为二进制,把二进制转成ascii
def extract_zero_width_binary(text):
"""
从文本中提取零宽字符隐藏的二进制
:param text: 包含零宽字符的原始文本(如文档中的诗句)
:return: 提取的二进制字符串、ASCII解码结果
"""
# 定义零宽字符与二进制的映射(文档隐写常用规则,匹配此前分析逻辑)
zero_width_map = {
'\u200b': '0', # 零宽度空格 → 0
'\u200c': '1', # 零宽度非连接符 → 1
'\u200d': '', # 零宽度连接符(若存在可根据实际调整,此处暂设为空)
'\u2060': '' # 零宽度非换行空格(同上,根据文本实际情况补充)
}
# 1. 提取文本中的所有零宽字符
zero_width_chars = [char for char in text if char in zero_width_map.keys()]
if not zero_width_chars:
return "未检测到零宽字符", "无解码结果"
# 2. 将零宽字符转换为二进制字符串
binary_str = ''.join([zero_width_map[char] for char in zero_width_chars])
# 确保二进制长度为8的倍数(ASCII解码要求),不足时补0(实际隐写通常会对齐)
if len(binary_str) % 8 != 0:
pad_length = 8 - (len(binary_str) % 8)
binary_str += '0' * pad_length
print(f"提示:二进制长度非8的倍数,已补{pad_length}个0对齐")
# 3. 将二进制字符串按8位一组解码为ASCII(还原隐藏内容)
ascii_result = ""
for i in range(0, len(binary_str), 8):
byte_binary = binary_str[i:i + 8]
# 二进制转十进制再转ASCII(过滤不可见字符)
char_code = int(byte_binary, 2)
if 32 <= char_code <= 126: # 只保留可打印ASCII字符(空格-~)
ascii_result += chr(char_code)
return binary_str, ascii_result
# ------------------- 示例:读取文档并提取 -------------------
if __name__ == "__main__":
# 1. 读取包含零宽字符的txt文件(需替换为你的文件路径)
file_path = "poem.txt" # 确保文件与代码在同一目录,或写绝对路径(如"C:/test/poem.txt")
try:
with open(file_path, 'r', encoding='utf-8') as f:
poem_text = f.read()
except FileNotFoundError:
print(f"错误:未找到文件 {file_path},请检查路径是否正确")
exit()
# 2. 提取二进制并解码
hidden_binary, decoded_content = extract_zero_width_binary(poem_text)
# 3. 输出结果
print("=" * 50)
print("1. 提取的隐藏二进制序列:")
print(hidden_binary)
print("\n2. 二进制解码为ASCII内容(可打印字符):")
print(decoded_content if decoded_content else "未解码出可打印字符")
print("=" * 50)
0f121d78192b2d1b56037c533f106a54137713455102670714116a5d287460405667070c在另一个文件中可以找到密钥
把提取出来的十六进制和密钥进行xor,解密之后再base64解密即可
hex_data = '0f121d78192b2d1b56037c533f106a54137713455102670714116a5d287460405667070c'
# 转换为字节数据
data = bytes.fromhex(hex_data)
# XOR解密函数
def xor_decrypt(data, key):
key_bytes = key.encode('utf-8')
return bytes(data[i] ^ key_bytes[i % len(key_bytes)] for i in range(len(data)))
key = 'ZWS-KEY-2025'
result = xor_decrypt(data, key)
print('XOR解密结果:')
print('密钥:', key)
print('解密数据:', result.hex())
print('Base64字符串:', result.decode('utf-8'))
# Base64解码
import base64
try:
flag = base64.b64decode(result).decode('utf-8')
print('最终FLAG:', flag)
except Exception as e:
print('Base64解码错误:', e)Week2-base64_pro
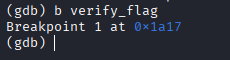
使用kali的gdb进行调试,在verify_flag函数这边下一个断点,可以通过ida反编译来知道这个函数
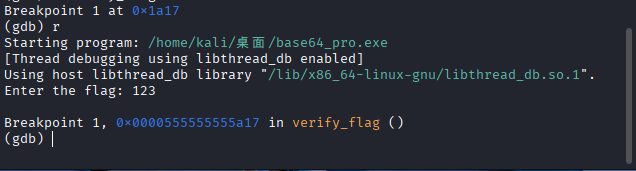
之后run一下,随意输入flag就会停在这个函数
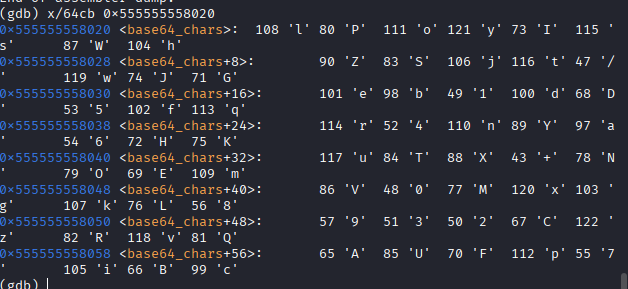
通过disassemble函数去看base64_encode的汇编代码,在这里可以看到base64_chars开始的地址
这边用到一个命令:x/<n><f><u> <address>
n:要检查的内存单元数量(这里是64,表示检查 64 个单元)。f:显示格式(这里是c,表示按 ASCII 字符显示;b是单位)。u:每个单元的大小(这里是b,表示 1 字节,即byte)。
用x/64cb 0x555555558020这个命令可以看这个地址后的64个字节的内容,也就是这题用到的真正的码表
用这个码表去解密base64即可,加密字符串在ida里面很简单可以找到
def custom_base64_decode(encoded_str):
# 自定义Base64码表(严格与C代码一致)
base64_chars = 'lPoyIsWhZSjt/wJGeb1dD5fqr4nYa6HKuTX+NOEmV0MxgkL8932CzRvQAUFp7iBc'
char_to_idx = {c: i for i, c in enumerate(base64_chars)}
# 处理填充符
pad_count = encoded_str.count('=')
encoded = encoded_str.rstrip('=')
decoded = bytearray()
# 按4字符一组处理(与C代码的3字节一组对应)
for i in range(0, len(encoded), 4):
group = encoded[i:i + 4]
g_len = len(group)
# 解析4个字符的索引(严格对应C代码的拆分顺序)
a = char_to_idx[group[0]] if g_len >= 1 else 0
b = char_to_idx[group[1]] if g_len >= 2 else 0
c = char_to_idx[group[2]] if g_len >= 3 else 0
d = char_to_idx[group[3]] if g_len >= 4 else 0
# 重组24位数据(完全逆向C代码的v16计算)
# C代码:v16 = (v15 << 8) + (v14 << 16) + v8
# 解密时需还原 v14, v15, v8
combined = (a << 18) | (b << 12) | (c << 6) | d
# 提取原始字节(对应C代码的v14, v15, v8)
v14 = (combined >> 16) & 0xFF # 第一个原始字节
v15 = (combined >> 8) & 0xFF # 第二个原始字节
v8 = combined & 0xFF # 第三个原始字节
# 根据原始数据长度添加字节(关键修复)
# 原始数据长度 = (总字符数 * 6) // 8
total_chars = len(encoded) + pad_count
original_len = (total_chars * 6) // 8
current_pos = (i // 4) * 3 # 当前组在原始数据中的起始位置
# 严格按位置判断是否保留字节
if current_pos < original_len:
decoded.append(v14)
if current_pos + 1 < original_len:
decoded.append(v15)
if current_pos + 2 < original_len:
decoded.append(v8)
return bytes(decoded)
# 解密测试
if __name__ == "__main__":
encoded_str = "DIwDbmkDdswKrvsgYWSTrvkK4W5C6hS8Hf5NqzSTavDvwsizrfSg4qz="
try:
decoded_bytes = custom_base64_decode(encoded_str)
# 尝试所有可能的中文编码
encodings = ['utf-8', 'gbk', 'gb2312', 'utf-16le', 'utf-16be']
for enc in encodings:
try:
print(f"{enc}解码:{decoded_bytes.decode(enc)}")
except UnicodeDecodeError:
print(f"{enc}解码失败")
print("十六进制:", decoded_bytes.hex())
except Exception as e:
print("错误:", e)