摘要
本周学习了模型攻击中的黑箱攻击,了解其基本原理,同时对模型的防御方法被动防御进行了学习。
abstract
This week, I studied black-box attacks in model adversarial attacks, learned their fundamental principles, and also explored passive defense methods for model protection.
一、对于模型的白箱攻击和黑箱攻击
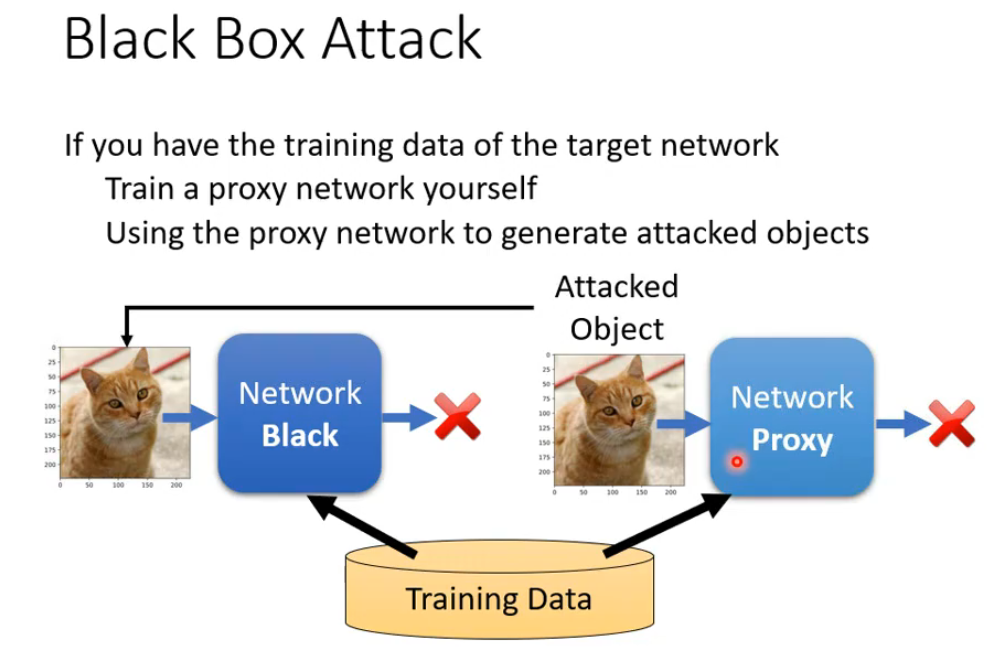
白箱攻击需要知道目标模型的相关参数,但并不是将模型保护的够好就不会受到攻击,攻击者可以使用黑箱攻击,黑箱攻击是一种针对机器学习模型的对抗攻击方式,其核心在于攻击者无需知晓目标模型的内部结构、参数或训练细节,仅能通过模型的输入输出进行有限交互。图2中黑箱攻击流程,如果攻击者拥有与目标模型训练数据分布相似的数据,可首先训练一个代理模型来模拟目标模型;随后在代理模型上使用白箱攻击方法生成对抗样本,或许能产生期待的效果,最终将这些样本输入目标黑箱模型,利用对抗样本的跨模型可迁移性实施攻击。如果缺乏训练数据,攻击者还可通过查询目标模型收集输入输出对,以数据重建或模型窃取的方式构建代理模型。黑箱攻击反映了机器学习模型在真实开放环境中的安全脆弱性,常见的防御手段包括对抗训练、输入预处理及查询访问控制等。

二、模型攻击为什么容易
VGG-16、ResNet系列和GoogLeNet等经典模型在对抗攻击下的准确率骤降现象,直观揭示了对抗攻击之所以容易成功,根本原因在于深度神经网络的内在脆弱性。这种脆弱性源于高维输入空间中的线性行为,使微小扰动能经维度累积被急剧放大。

三、被动防御
被动防御是一种在不改变目标模型内部结构和参数的前提下,通过预处理、过滤或检测输入数据来抵御对抗攻击的策略。其核心思路是在对抗样本输入模型分类前,利用图像变换(如随机缩放、JPEG压缩)、滤波去噪(如高斯模糊、中值滤波)或随机化操作(如随机像素丢弃)等方法,破坏对抗性扰动的结构,使其"无害化",同时尽可能保留原始图像的语义信息,从而维持模型对正常样本的正确分类性能。被动防御部署简单、兼容性强。

