HBM(High Bandwidth Memory,高带宽内存)是面向 AI、HPC 等高性能场景的3D 堆叠 DRAM 解决方案 ,通过 TSV(硅通孔)与ubump技术实现多层 DRAM 垂直集成,搭配 CoWoS-S/CoW oS-L 等先进封装与处理器高密度互联,核心价值在于以超宽位宽 + 短传输路径 突破传统内存带宽瓶颈.专为未来 GPU 与高性能计算(HPC)系统设计的内存标准,解决这类场景对超高内存带宽的需求。
一、核心定义与架构原理
1. 基本概念与本质定位
HBM 作为 3D 堆叠内存技术,是当前 AI 训练芯片、高端 GPU 的核心组件之一,其通过 TSV(硅通孔)实现多层 DRAM 垂直互联,结合 CoWoS 等先进封装技术,可提供 TB/s 级带宽,同时兼顾功耗与面积效率,是突破 "内存墙" 的关键技术之一。

HBM 并非单一芯片,而是系统级接口与封装技术规范,定义了 DRAM 如何通过 3D 堆叠与高密互连实现 TB/s 级带宽的完整方案:
-
核心组件:4-16 层 DRAM 裸片 + 基础逻辑层(Base Die/TSV Die);
-
互连技术:TSV(垂直互连)+ Microbump(芯片间互连);利用裸片堆叠技术提供的大量信号通道,实现极高内存带宽;
-
封装形态:多以HBM Stack形式通过 CoWoS 中介层与 SoC/GPU 集成;
-
核心优势:降低 I/O 传输的能耗成本;配合先进内存控制器,可更充分地利用峰值带宽;
2. 关键架构组成(以 HBM3 为例)
| 层级 | 核心功能 | 技术细节 |
|---|---|---|
| DRAM 堆叠层 | 数据存储核心 | 4-12 层 DRAM 裸片,单颗容量 8-36GB,通过 TSV 垂直互联 |
| 基础逻辑层 | 控制与接口转换 | 含 PLL、I/O 接口、ECC 电路,负责与外部通信 |
| 微凸块阵列 | 芯片间互连 | 10-50μm 间距,提供 1024+bit 宽数据通道 |
| 硅通孔 (TSV) | 垂直数据传输 | 直径 5-10μm,贯穿硅片实现堆叠层间信号 / 电源传输 |
| CoWoS 中介层 | 系统级互联 | 连接 HBM Stack 与 SoC/GPU,提供高密信号路由 |
3. 工作原理
- SoC/GPU 通过 CoWoS 中介层向 HBM 发送内存访问请求
- 基础逻辑层解析请求,通过 TSV 与微凸块阵列访问指定 DRAM 层
- 数据经 TSV 垂直传输至基础逻辑层,再通过中介层返回处理器
- 全链路传输距离从传统 PCB 的毫米级缩短至微米级,显著降低延迟与功耗
| 设计维度 | 检查项 | 规范要求(以 HBM3e 为例) | 设计目标 | 验证方式 |
|---|---|---|---|---|
| 一、HBM Stack 基础参数确认 | 1. 堆叠层数与容量 | 支持 4-12 层 DRAM 裸片,单 Stack 容量≥24GB | 匹配 SoC 带宽 / 容量需求 | 厂商规格书核对 |
| 2. 位宽配置 | 1024/2048bit,ECC 功能可选 | 满足目标带宽(如 1.2TB/s) | 接口协议仿真 | |
| 3. 物理尺寸 | 裸片尺寸≤11mm×11mm,堆叠高度≤1mm | 适配中介层布局空间 | 机械尺寸测量 | |
| 二、微凸块(Microbump)设计 | 1. 间距与尺寸 | 凸块间距 15-30μm,直径 8-15μm | 提升互连密度,降低接触电阻 | 光学显微镜检测 |
| 2. 数量与布局 | 单 Stack 凸块数≥1000,按 HBM 规范阵列布局 | 满足 1024/2048bit 总线需求 | 布局图评审 | |
| 3. 材料与工艺 | 采用 Cu/Sn 微凸块,键合温度≤260℃ | 保证键合良率≥99.9% | 工艺兼容性测试 | |
| 三、硅通孔(TSV)设计 | 1. 尺寸与密度 | TSV 直径 5-10μm,间距≥20μm,密度≥5000 个 / 裸片 | 实现垂直高速传输,无信号串扰 | 截面电镜(SEM)检测 |
| 2. 深宽比 | 深宽比≥10:1 | 保证 TSV 填充质量与可靠性 | 工艺仿真 + 良率统计 | |
| 3. 功能分区 | 分离信号 TSV、电源 TSV、接地 TSV,避免串扰 | 电源完整性(PI)达标,信号损耗≤5% | 电磁仿真(EMC/EMI) | |
| 四、中介层集成设计(CoWoS 适配) | 1. 中介层类型选择 | - CoWoS-S:硅中介层(TSV+RDL)- CoWoS-R:全 RDL 中介层- CoWoS-L:局部硅 + 全局 RDL | 平衡带宽、成本与可靠性 | 技术方案评审 |
| 2. RDL 布线规范 | 硅中介层 RDL 线宽 / 线距≤1μm/1μmRDL 中介层线宽 / 线距≥4μm/4μm | 满足信号传输速率≥16Gbps | 布线仿真 + 阻抗测试 | |
| 3. HBM 与 SoC 互连 | 中介层上 HBM 与 SoC 的互连路径最短,差分对等长 | 信号延迟≤1ns,串扰≤-25dB | 时序仿真 + 眼图测试 |
4 . HBM 标准定义
(1)标准定义的内容:保障兼容性
-
键合布局:规范 HBM 堆叠与中介层 / 处理器的物理连接形态,确保不同厂商的 HBM 与封装组件可互配;
-
接口信号:统一 HBM 与内存控制器之间的电信号格式,避免因信号差异导致的传输错误;
-
命令与协议:明确内存访问的指令规则(如读写、刷新),让控制器能跨厂商驱动 HBM;
-
可选功能:ECC 支持为高可靠性场景提供基础规范;基础层逻辑 / 重布线 / I/O 裸片则是 HBM 堆叠的核心组件框架,保障功能实现的底层兼容性。
(2)标准未定义的内容:预留创新空间
-
堆叠内部架构:允许厂商自主设计 DRAM 裸片的堆叠方式、内部数据通路等,支持技术差异化(如不同层数的堆叠方案);
-
精确 DRAM 时序参数:厂商可根据自身工艺优化时序(如读写延迟),在性能、功耗与良率之间自主平衡。
HBM 内存通道的 "完全独立性" 设计,其技术价值体现在以下方面:
(1)独立维度的具体表现
-
时钟与时序独立:每个通道可根据自身数据传输需求调整时钟频率、读写延迟,无需与其他通道同步;
-
命令独立:内存控制器可向不同通道并行发送读写、刷新等指令,互不干扰;
-
内存阵列独立:每个通道对应独立的存储单元,数据存储与访问相互隔离。
(2)设计的核心价值
-
提升带宽利用率:8 个独立通道可并行传输数据,避免单通道瓶颈,最大化 HBM 的高带宽特性(例如 HBM2 的单通道带宽 32GB/s,8 通道总带宽可达 256GB/s);
-
降低信号干扰:通道间无相互影响,减少串扰、时序冲突等问题,提升信号完整性;
-
增强可靠性:单个通道的故障不会扩散至其他通道,可通过冗余设计进一步提升系统稳定性。
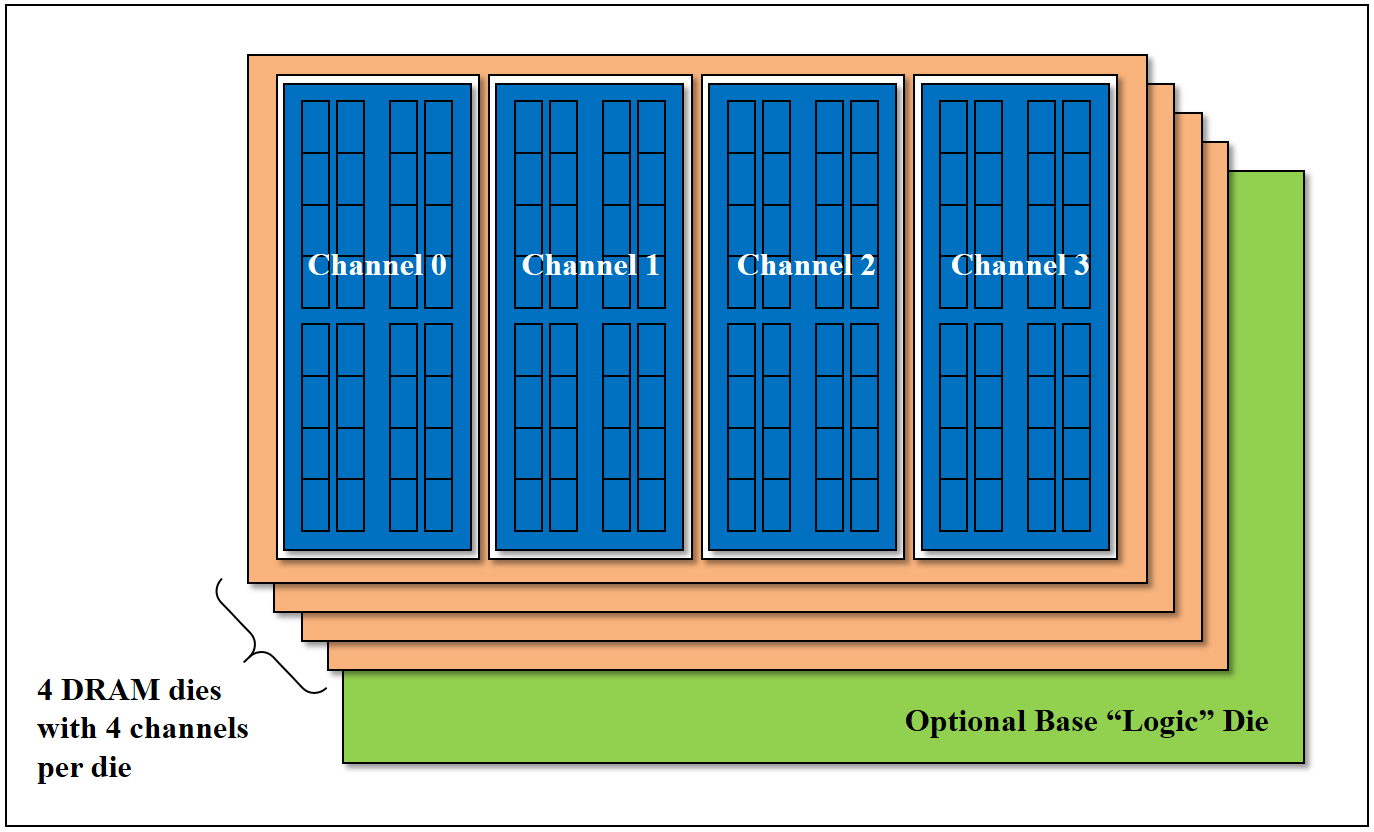
这是 HBM DRAM 的堆叠结构示意图(源自 JEDEC JESD235 标准,2013 年 10 月),核心组成:
-
DRAM 裸片层:共 4 层 DRAM 裸片,每层裸片内置 2 个独立内存通道(如示意图中的 Channel 0、Channel 1);
-
基础逻辑裸片:底部可选的 "逻辑裸片",负责接口转换、重布线等功能,为通道的独立控制提供硬件支撑。
该结构是 HBM "8 个独立通道" 的硬件基础:每层裸片分 2 个通道,4 层裸片恰好组成 8 个物理隔离的通道,同时基础逻辑裸片实现通道的独立信号传输与控制,从硬件层面保障了通道间的完全独立性。
每个通道提供 128 位数据接口每个信号的数据速率为 1-2 Gbps(对应 500-1000 MHz DDR)每个通道的带宽为 16-32 GB / 秒每个堆叠含 8 个通道每个堆叠的带宽为 128-256 GB / 秒。
|-------------------------------------------------------------------------------------------|
| * 带宽计算逻辑:单通道带宽 = 位宽(128bit)× 数据速率(1-2Gbps)÷8(字节转换)=16-32GB/s,8 通道堆叠的总带宽即 128-256GB/s; |
二、技术演进与关键规格对比(HBM1→HBM4)
HBM 通过位宽扩展 + 频率提升 + 堆叠层数增加持续迭代,带宽从 HBM1 的 128GB/s 跃升至 HBM4 的超 3TB/s:
| 代际 | 发布时间 | 核心规格 | 典型带宽 | 功耗特性 | 代表应用 |
|---|---|---|---|---|---|
| HBM1 | 2013 | 1024bit 位宽,500MHz | 128GB/s | 1.2V,低功耗 | 早期高端 GPU |
| HBM2 | 2016 | 1024bit,1GHz | 256GB/s | 1.2V,支持双通道 | AMD MI25、NVIDIA V100 |
| HBM2e | 2019 | 1024bit,1.2GHz | 307GB/s | 电压优化 | 数据中心加速卡 |
| HBM3 | 2022 | 1024-2048bit,1.6GHz | 819GB/s | 1.1V,ECC 增强 | NVIDIA H100、AMD MI300 |
| HBM3e | 2024 | 2048bit,2GHz+ | 1.2TB/s | 低功耗优化,更高堆叠密度 | NVIDIA GB200、AI 训练芯片 |
| HBM4 | 2025 (规划) | 2048-4096bit,2.4GHz+ | 3TB/s+ | 更低电压,Chiplet 兼容 | 下一代超算 / AI 芯片 |
三、核心技术优势与价值分析
1. 四大核心优势(对比 GDDR6/DDR5)
-
带宽 "碾压级" 领先:HBM3e 单 Stack 带宽达 1.2TB/s,相当于 10 + 颗 GDDR6 组合,H100 8 颗 HBM3 总带宽达 3.35TB/s
-
功耗效率更优:通过增加位宽而非提升频率实现高带宽,同等带宽下功耗降低 30-50%,适合 AI 芯片 "千卡集群" 场景
-
物理尺寸更小:8 层 HBM Stack 面积约 11mm×11mm,远小于同容量 GDDR6 阵列,支持更高密度系统集成美光科技
-
延迟显著降低:传输路径从 PCB 级(厘米级)缩短至芯片级(微米级),内存访问延迟降低 40%+
2. 解决的核心痛点
AI 大模型训练中,HBM 将 GPT-3 训练时间从 DDR5 的 20 天缩短至 HBM3 的 5 天,直接提升算力利用率 300%+,本质是解决了计算性能与内存带宽的失衡问题。
三、HBM 封装与集成方案
1. 主流封装架构:CoWoS 是 "黄金标准"
HBM 与处理器的集成高度依赖2.5D CoWoS 封装,形成三大技术路径:
| 封装方案 | 核心特征 | 带宽能力 | 适用场景 |
|---|---|---|---|
| CoWoS-S | 硅中介层 + TSV | 3.35TB/s(H100) | AI 训练、高端 GPU |
| CoWoS-R | RDL 中介层 | 1-2TB/s | 中端 AI 推理、网络芯片 |
| CoWoS-L | 局部硅互连 + 全局 RDL | 2-3TB/s | 超大型 AI 系统(如 GB200) |
关键流程:
-
HBM Stack 通过 Microbump 与硅 / RDL 中介层键合
-
中介层实现 HBM 与 SoC 的高密度信号路由
-
整体封装在有机基板上,提供对外引脚
2. 先进封装创新方向
-
3D HBM-on-GPU:HBM 直接堆叠在处理器上方,带宽提升至 1.2TB/s,互联距离缩短至纳米级
-
混合键合(Hybrid Bonding):替代 Microbump,互连密度提升 10 倍,接触电阻降低 90%,为 HBM4/5 奠定基础
-
Chiplet+CoWoS 融合:HBM 作为独立 Chiplet 通过 SoIC 与计算 Chiplet 集成,提升良率与灵活性
四、HBM 关键技术参数与设计考量
1. 核心参数表(HBM3/HBM3e)
| 参数类别 | 关键指标 | 设计影响 |
|---|---|---|
| 堆叠结构 | 8-12 层 DRAM,单颗容量 24-36GB | 决定容量与热管理难度 |
| 位宽配置 | 1024/2048bit | 直接影响带宽上限 |
| 微凸块 | 间距 15-30μm,数量 1000+ | 决定互连密度与良率 |
| TSV | 直径 5-10μm,数量 5000+ | 影响垂直传输效率 |
| 功耗密度 | 20-30W/cm² | 热仿真与散热设计核心指标 |
| 中介层 | 硅中介层厚度 50-100μm | 影响热应力与可靠性 |
2. 封装设计工程师核心挑战与对策
| 挑战类型 | 具体问题 | 解决方案 |
|---|---|---|
| 热管理 | 堆叠层热堆积,C4 焊点失效风险 | 1. 优化中介层散热路径2. 采用热界面材料(TIM)3. 设计散热通孔 |
| 信号完整性 | 1024bit 宽总线串扰、损耗 | 1. 差分对设计 + 阻抗匹配2. 中介层 RDL 分层隔离3. 电源完整性(PI)仿真 |
| 可靠性 | TSV 断裂、Microbump 脱落 | 1. 热应力仿真优化布局2. 采用柔性 RDL 缓冲应力3. 冗余互连设计 |
| 良率控制 | 多层堆叠与键合良率损失 | 1. 分步检测 + 修复流程2. 优化 Microbump 共面性3. 分级测试策略 |
总结
HBM 以3D 堆叠 + CoWoS 封装的技术组合,彻底重塑了高性能计算的内存架构,其核心优势不仅在于 TB/s 级带宽,更在于为 AI 时代提供了 **"带宽 - 功耗 - 面积" 的最优解 **。对封装设计工程师而言,掌握 HBM 的堆叠原理、互连技术与封装集成要点,是适配下一代 AI 芯片的必备能力,需重点关注热管理、信号完整性与可靠性三大核心挑战,实现性能与良率的平衡。