目录
[1.瓶颈分析基础与 Roofline 模型](#1.瓶颈分析基础与 Roofline 模型)
[1. 向量化计算基础](#1. 向量化计算基础)
[2. 低精度计算优化](#2. 低精度计算优化)
[3. 性能对比分析](#3. 性能对比分析)
[1. 并行规约问题引入](#1. 并行规约问题引入)
[2. 原子操作基础](#2. 原子操作基础)
[3. 规约策略优化](#3. 规约策略优化)
[4. 性能对比与瓶颈分析](#4. 性能对比与瓶颈分析)
[1. GPU 内存架构概述](#1. GPU 内存架构概述)
[2. 共享内存与访存优化](#2. 共享内存与访存优化)
[3. 树状归约的优化实现](#3. 树状归约的优化实现)
[Warp 级优化](#Warp 级优化)
[1. Warp 调度与线程组织](#1. Warp 调度与线程组织)
[2. Warp Shuffle 操作](#2. Warp Shuffle 操作)
[3. Warp 级规约优化](#3. Warp 级规约优化)
[跨 Block 规约](#跨 Block 规约)
[1. 跨 Block 规约的挑战](#1. 跨 Block 规约的挑战)
[2. Two-Pass 规约策略](#2. Two-Pass 规约策略)
[Bank Conflict 分析与优化](#Bank Conflict 分析与优化)
[1. Bank Conflict 的概念与影响](#1. Bank Conflict 的概念与影响)
[2. Bank Conflict 的检测工具](#2. Bank Conflict 的检测工具)
[3. 优化策略](#3. 优化策略)
本文介绍如何通过 Roofline 模型分析内存和计算瓶颈,并详细讲解如何利用向量化、低精度计算、内存对齐、访存合并等技术优化 CUDA 程序的性能。
性能瓶颈分析与优化方法论
1.瓶颈分析基础与 Roofline 模型
-
• 内存瓶颈与计算瓶颈的识别
-
• 如何定位性能天花板
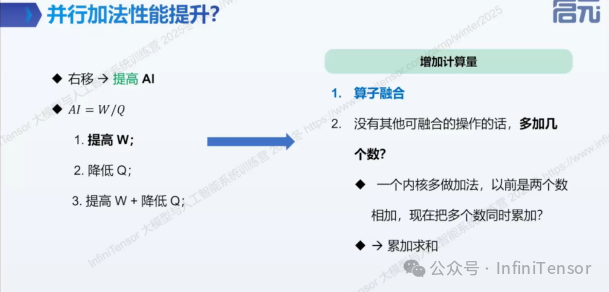
2.性能优化方法论
-
• 右移优化:提升计算强度(AI)
-
• 算子融合与计算密度提升方法
向量化与低精度优化
1. 向量化计算基础
-
• 介绍向量化计算的概念
-
• 内存对齐与访存合并的重要性
2. 低精度计算优化
-
• 半精度(Half)计算的优势
-
• 混合精度计算策略(如 half2)
3. 性能对比分析
- • 不同精度与向量化级别下的性能表现
并行规约与原子操作
1. 并行规约问题引入
- • 从向量加法到累加求和的并行化挑战
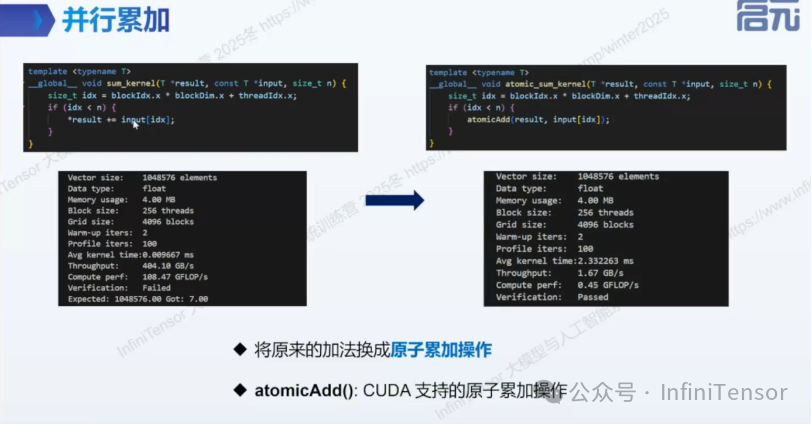
2. 原子操作基础
-
• 原子操作的定义与用途
-
• atomicAdd 的使用与性能影响

3. 规约策略优化
-
• Warp 级规约:
左侧的代码 reduce_warp_global_kernel 采用了 Grid-Stride Loop(网格跨步循环) 模式,使其能够处理超出网格尺寸的数据量;为了提高效率,逻辑中加入了 Warp 层级的控制,仅让每个 Warp 中的第一个线程(Lane 0)负责执行循环累加,计算出该 Warp 的局部和(partial sum)。右侧文字总结了关键点:通过这种方式减少了不必要的线程工作,最后利用 atomicAdd(原子加) 操作将各个 Warp 计算出的局部和安全地汇总到全局输出中,从而避免了数据竞争并完成了最终的规约。

-
• Block 级规约
-
• 树状规约算法
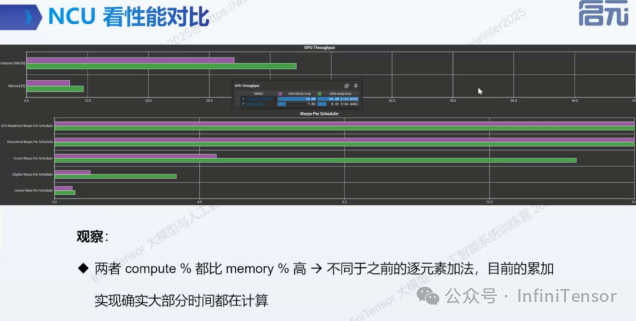
4. 性能对比与瓶颈分析
-
• 不同规约策略的性能差异
-
• 原子操作导致的串行化问题
内存层次结构与访存优化
1. GPU 内存架构概述
- • 物理内存层次:
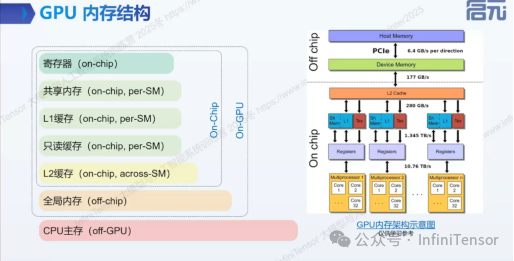
- • 逻辑内存模型:
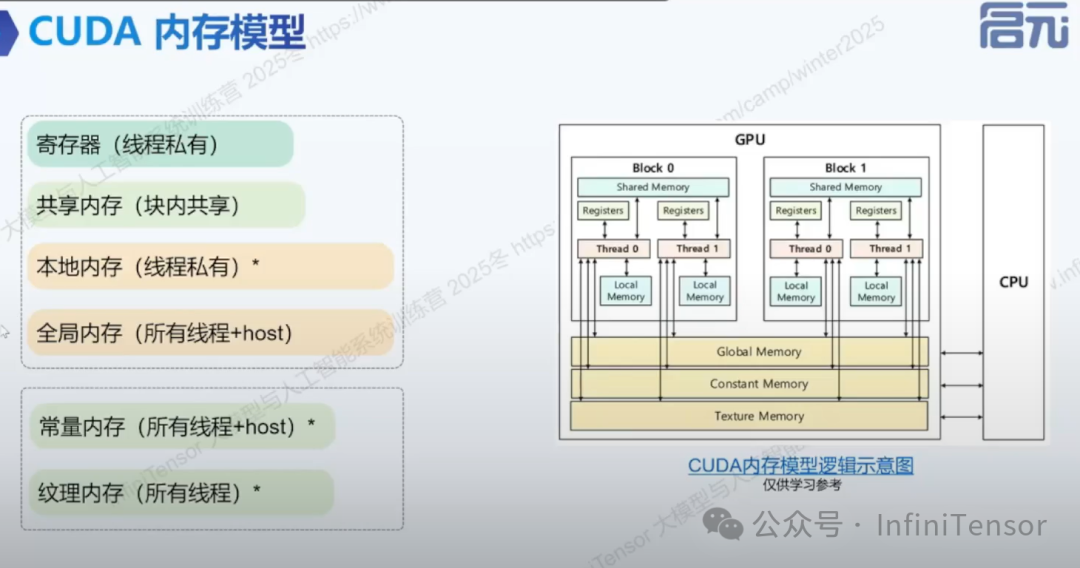
2. 共享内存与访存优化
-
• 共享内存的分配与使用(静态/动态)
-
• 同步操作:
__syncthreads()
3. 树状归约的优化实现
-
• 共享内存中的规约实现
-
• 访存模式优化避免 Bank Conflict
Warp 级优化
1. Warp 调度与线程组织
-
• Warp 与 Lane 的概念
-
• Warp 级同步与通信
2. Warp Shuffle 操作
-
•
__shfl_down_sync()的使用与优势 -
• 基于寄存器的数据交换
3. Warp 级规约优化
-
• 结合 Warp Shuffle 与共享内存的规约策略:在并行累加中一种基于 Warp Shuffle(线程束洗牌) 的进阶优化方案,核心在于引入了
__shfl_down_sync函数。它改变了传统利用"共享内存"进行线程间通信的方式,允许线程直接通过寄存器 高效地读取同一 Warp 内下游线程(
lane_id + offset)的数据;代码展示了如何通过一个从 16 到 1 的循环步长,在不进行显式同步(无__syncthreads)且无需处理复杂边界条件的情况下,极快地完成 Warp 内部的数值归约,最终仅由 0 号线程将结果原子加到全局内存中,这显著降低了访存延迟并提升了 Kernel 的执行效率。

跨 Block 规约
1. 跨 Block 规约的挑战
- • 原子操作 vs 多核函数规约
2. Two-Pass 规约策略

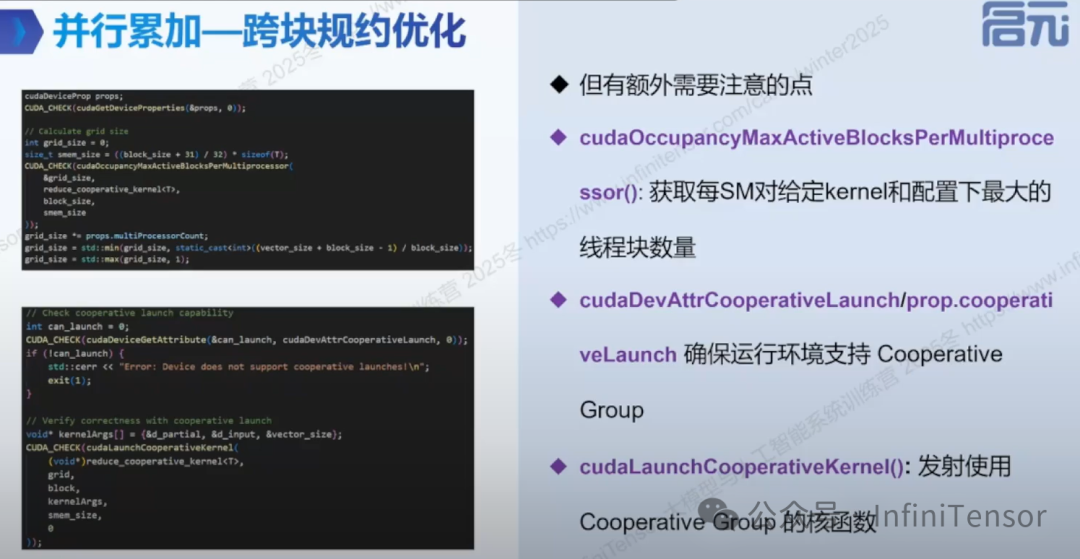
3.跨块规约优化
一次 Kernel 发射完成全局求和,所必须采用的 Cooperative Groups(协作组) 及其 Host 端启动配置。
由于标准的 CUDA 编程模型中不同 Thread Block 之间无法直接同步,要实现全局规约通常需要多次 Kernel 启动。而图中展示的方案通过 cudaLaunchCooperativeKernel 实现了 Grid 级别的全局同步,但这要求开发者必须进行严格的资源管理:首先使用 cudaOccupancyMaxActiveBlocksPerMultiprocessor 精确计算出硬件能同时承载的最大活跃线程块数量(因为所有 Block 必须同时驻留在 GPU 上才能避免死锁),接着验证设备是否支持 Cooperative Launch 属性,最后通过特定的 API 启动核心,从而在单次发射中完成从局部到全局的高效累加。
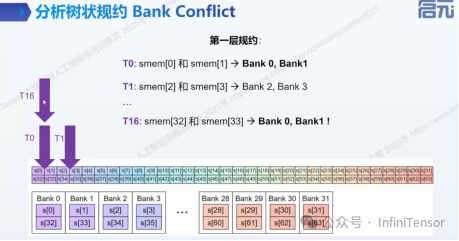
Bank Conflict 分析与优化
1. Bank Conflict 的概念与影响
-
• 共享内存的 Bank 组织与访问模式
-
• 冲突类型:共享内存的读/写 Bank Conflict


2. Bank Conflict 的检测工具
- • NCU 工具中的相关指标分析
3. 优化策略
- • 访存模式优化(如树状规约的调整)
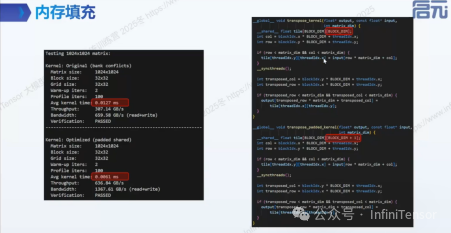
- • Padding(内存填充)技术
总结
本文重点掌握使用 CUDA 进行并行计算的核心概念,并学会使用各种工具和技术分析和优化程序性能,特别是解决常见的访存瓶颈和并行规约问题。后续将解决 Bank conflict 的另一技巧!