目录
目录
[一、3. 无重复字符的最长子串](#一、3. 无重复字符的最长子串)
[二、438. 找到字符串中所有字母异位词](#二、438. 找到字符串中所有字母异位词)
前言
碎碎念:笑迎是基本常识。 躲,避,藏,拒,推拉摇移。经历过才严肃感受到:对外交往的人,应以严肃的水准严格筛选他们。

不是所有的二重循环时间复杂度都是ON方的
再明确
转换一下邪修刷题思路:
第一轮(5天):每天20道题,过一遍思路后看答案手敲,不会就看答案,不要求拿到题能做出来。 然后总结模版到csdn。 有空就看当天的总结,养成用嘴说思路的习惯,第二轮一边敲一边念。
第二轮(一直repeat until 面试):每天10道题+5道题(前一天main),表格记录每道题做多少遍错多少次,错因是什么。用acm格式写法
由于每天刷题量变多,用更轻薄地方式记录笔记便于复习(代码逻辑,剪枝初始化手写记录
滑动窗口
双指针同向型的特殊形式,两个指针共同维护一个窗口区间(有点像毛毛虫爬),通过扩展右指针,收缩左指针的方式让窗口满足特定条件,让窗口内的元素是当前处理的有效范围
一、3. 无重复字符的最长子串
1、题目描述
你需要解决的问题是:给定一个字符串
s,找出其中不含有重复字符的最长子串的长度。
- 子串定义:连续的字符序列(区别于子序列)。
- 示例:
- 输入:
s = "abcabcbb",输出:3(最长无重复子串是 "abc");- 输入:
s = "bbbbb",输出:1(最长无重复子串是 "b");- 输入:
s = "pwwkew",输出:3(最长无重复子串是 "wke");- 边界条件:字符串为空时输出 0,字符串长度为 1 时输出 1。
2、简单理解?
维护窗口里一直都是最长的子串
- 子串」是字符串中连续的字符序列(区别于子序列);
- 子串中不能有重复字符(比如
"abc"合法,"abca"不合法); - 若字符串为空,返回 0;若字符串所有字符都重复(如
"bbbbb"),返回 1。
3、用图示意
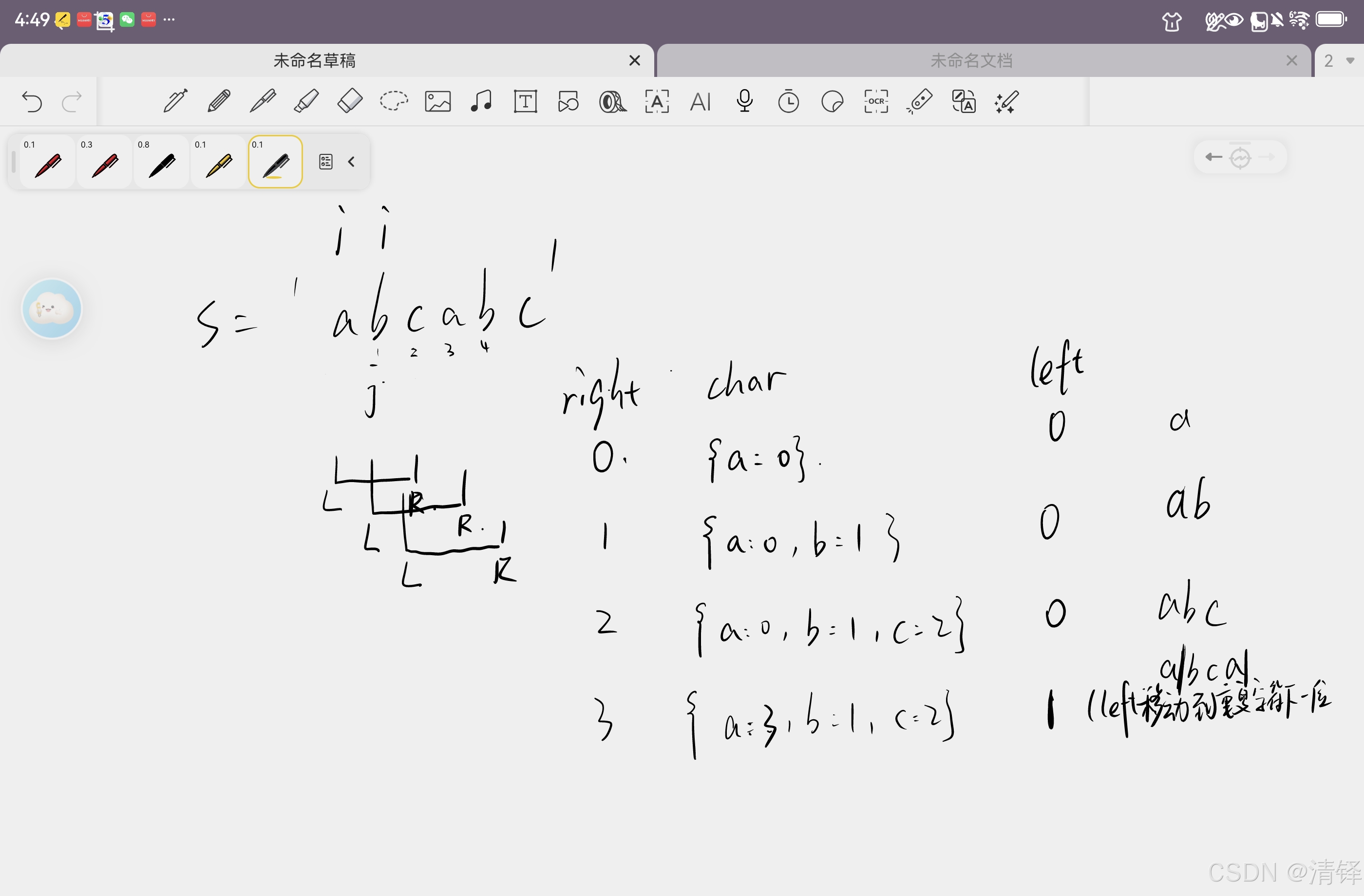
4、暴力法
python
def main():
import sys
s = sys.stdin.readline().strip() # ACM 格式读取输入
n = len(s)
max_len = 0 # 初始化最长长度为0(边界条件:空字符串直接返回0)
# 枚举所有起始位置i
for i in range(n):
seen = set() # 每次起始位置重置集合,记录当前子串的字符
current_len = 0 # 当前子串长度
# 枚举结束位置j,从i开始
for j in range(i, n):
if s[j] in seen: # 遇到重复字符,终止当前子串遍历
break
seen.add(s[j]) # 无重复则加入集合
current_len += 1 # 当前长度+1
if current_len > max_len: # 更新最长长度
max_len = current_len
print(max_len) # ACM 格式输出结果
if __name__ == "__main__":
main()5、优化法
python
def main():
import sys
s = sys.stdin.readline().strip() # ACM 格式读取输入
char_index = {} # 哈希表:键=字符,值=字符最后出现的索引(初始化空字典)
max_len = 0 # 最长无重复子串长度(初始化0,处理空字符串)
left = 0 # 滑动窗口左指针(初始化0,窗口起始位置)
# 右指针right遍历字符串,相当于窗口右边界扩展
for right, char in enumerate(s):
# 关键:若字符已存在且在当前窗口内(索引≥left),则移动左指针到重复字符的下一位
if char in char_index and char_index[char] >= left:
left = char_index[char] + 1
# 更新当前字符的最后出现索引为当前right
char_index[char] = right
# 计算当前窗口长度,更新max_len
current_len = right - left + 1
if current_len > max_len:
max_len = current_len
print(max_len) # ACM 格式输出结果
if __name__ == "__main__":
main()6、疑惑点/新知识 ? 之前见过但没注意到的?
判断语句是否要前置???
二、438. 找到字符串中所有字母异位词
1、题目描述
你需要解决的问题是:给定两个字符串
s和p,找到s中所有p的字母异位词的子串,返回这些子串的起始索引。
- 字母异位词定义:由相同字母重排形成的字符串(字符种类和数量完全相同,顺序不同);
- 子串要求:连续且长度与
p完全一致;- 示例:
- 输入:
s = "cbaebabacd",p = "abc",输出:[0, 6](s[0:3] = "cba"、s[6:9] = "bac"都是abc的异位词);- 输入:
s = "abab",p = "ab",输出:[0, 1, 2];- 边界条件:
- 若
len(s) < len(p),直接返回空列表;- 若
p为空字符串,按题意返回空列表;- 若
s为空字符串且p非空,返回空列表。
2、简单理解?
返回起点。这种异位词的好像都是用字符计数法,字符计数法可以用字典或者哈希表
3、能不能用图示意?

4、暴力法
python
def main():
import sys
# ACM 格式读取输入(按行读取s和p)
s = sys.stdin.readline().strip()
p = sys.stdin.readline().strip()
len_s = len(s)
len_p = len(p)
result = [] # 初始化结果列表,存储符合条件的起始索引
# 边界条件:s比p短,直接返回空列表
if len_s < len_p:
print(result)
return
# 统计p的字符计数(用字典)
def count_chars(string):
count = {}
for c in string:
count[c] = count.get(c, 0) + 1
return count
p_count = count_chars(p)
# 枚举所有长度为len_p的子串
for i in range(len_s - len_p + 1):
# 截取子串并统计字符计数
sub_s = s[i:i+len_p]
sub_count = count_chars(sub_s)
# 对比计数,一致则记录索引
if sub_count == p_count:
result.append(i)
# ACM 格式输出结果(列表形式)
print(result)
if __name__ == "__main__":
main()5、优化法
python
def main():
import sys
# ACM 格式读取输入
s = sys.stdin.readline().strip()
p = sys.stdin.readline().strip()
len_s = len(s)
len_p = len(p)
result = [] # 初始化结果列表
# 边界条件1:p为空 或 边界条件2:s比p短,直接返回空列表
if len_p == 0 or len_s < len_p:
print(result)
return
# 初始化字符计数数组(a-z对应索引0-25)
p_count = [0] * 26
s_count = [0] * 26
# 第一步:统计p的字符计数 + 统计s前len_p个字符的计数
for i in range(len_p):
# ord(c) - ord('a') 将字符转为0-25的索引
p_count[ord(p[i]) - ord('a')] += 1
s_count[ord(s[i]) - ord('a')] += 1
# 检查初始窗口(索引0)是否匹配
if p_count == s_count:
result.append(0)
# 第二步:滑动窗口(从索引1开始,到len_s - len_p结束)
for i in range(1, len_s - len_p + 1):
# 移除窗口左侧的字符(i-1位置)
left_char = s[i-1]
s_count[ord(left_char) - ord('a')] -= 1
# 加入窗口右侧的新字符(i + len_p - 1位置)
right_char = s[i + len_p - 1]
s_count[ord(right_char) - ord('a')] += 1
# 对比计数,一致则记录当前起始索引i
if s_count == p_count:
result.append(i)
# ACM 格式输出结果
print(result)
if __name__ == "__main__":
main()6、疑惑点/新知识 ?之前见过但没注意到的?
在母串中枚举所有长度是len_子串,范围是 len_母串-len_子串+1
写错了 s i : i+len(p) 是冒号不是逗号
for i in range(len_p):
p_count=p_count[ord(p[i])-ord('a')]+1 #这里是p[i] 不是ord(i)
s_count=s_count[ord(s[i])-ord('a')]+1 #这里是s[i]必须这样写p_count[ord(p[i])-ord('a')]+=1,上面这样写是错的为什么不用for i in range(0,len_s-len_p+1): left_char=si?
遍历变量 i:代表「要移除的字符索引」,而非窗口起始索引;
\滑动窗口的核心操作是:从窗口 i 滑到窗口 i+1 时,需要移除「窗口 i 的最左字符」,并加入「窗口 i+1 的最右字符」。
可以用result.append(i + 1) 替代
自动不包含初始化的那个成功子串