👋 手搓 GZIP 实现的文件分块压缩上传
1 前言
已经半年多的时间没有闲下来写文章了。一方面是重新迷上了玩游戏,另一方面是 AI 时代的到来,让我对普通技术类文章的阅读频率减少了很多,相应的,自己动笔的动力也减缓了不少。
但经过这段时间的摸索,有一点是可以确定的:具有一定技术深度、带有强烈个人风格或独特创意的文章,在 AI 时代仍具有不可替代的价值。
所以,本篇来了。
在上一篇文章中,我们实现了在浏览器中记录结构化日志,现在,我们需要将这部分日志上传到云端,方便工程师调试。
我们面临的首要问题就是,文件太大了,必须分片上传。
我们将从零构建一套大文件上传系统。和普通的大文件上传系统(如阿里 OSS、七牛云常见的方案)相似,我们具备分片上传、断点续传的基础能力。但不同的是,我们为此引入了两个高阶特性:
- AWS S3 预签名直传(Presigned URL) :降低服务端带宽压力。
- 独立分片 Gzip 压缩:在客户端对分片进行独立压缩,但最终在服务端合并成一个合法的 Gzip 文件。
阅读本篇,你将收获:
- Gzip (RFC 1952) 与 Deflate (RFC 1951) 协议的底层实现原理。
- 基于 AWS S3 实现大文件分片直传的完整架构。
- 一个生产级前端上传 SDK 的设计思路。
2 基础方案设计
在正式开始设计之前,我们需要先了解以下知识:AWS 提供服务端的大文件上传或下载能力,但不直接提供直传场景(presign url)的大文件分片上传能力。
基于 AWS 实现的常规流程的大文件上传 flow 为:
-
后端先启用 CreateMultipartUpload,得到 uploadId,返回前端
-
在启用时,需遵循以下规则:
- ✅ 分段上传的最大文件大小为 5TB
- ⚠️ 最大分段数为 10000
- ⚠️ 分段大小单次限制为 5MB-5GB,最后一段无限制
-
需提前定义 x-amz-acl
-
需提前定义使用的校验和算法 x-amz-checksum-algorithm
-
需提前定义校验和类型 x-amz-checksum-type
-
-
在上传时,可以通过 presign url 上传
- 每一段都必须在 header 中包含 uploadId
- 每一段都建议计算校验和,并携带到 header 中(声明时如定义了 **x-amz-checksum-algorithm 则必传)**
- 每一段上传时,都必须携带分段的序号 partNumber
- 上传后,返回每一段的 ETag 和 PartNumber,如果使用了校验和算法,则也返回;该返回数据需要记录下来
-
上传完成后,调用 CompleteMultipartUpload
- 必须包含参数 part,使用类似于:
- ⚠️ 除了最后一段外,单次最小 5MB,否则 complete 阶段会报错
好在这并不意味着我们要在「直传」和「分片上传」中间二选一。
来看到我们的架构图,我们在 BFF 总共只需要三个接口,分别负责「创建上传任务」「获取分片上传 URL」「完成分片上传」的任务,而实际上传时,调用预授权的 AWS URL。
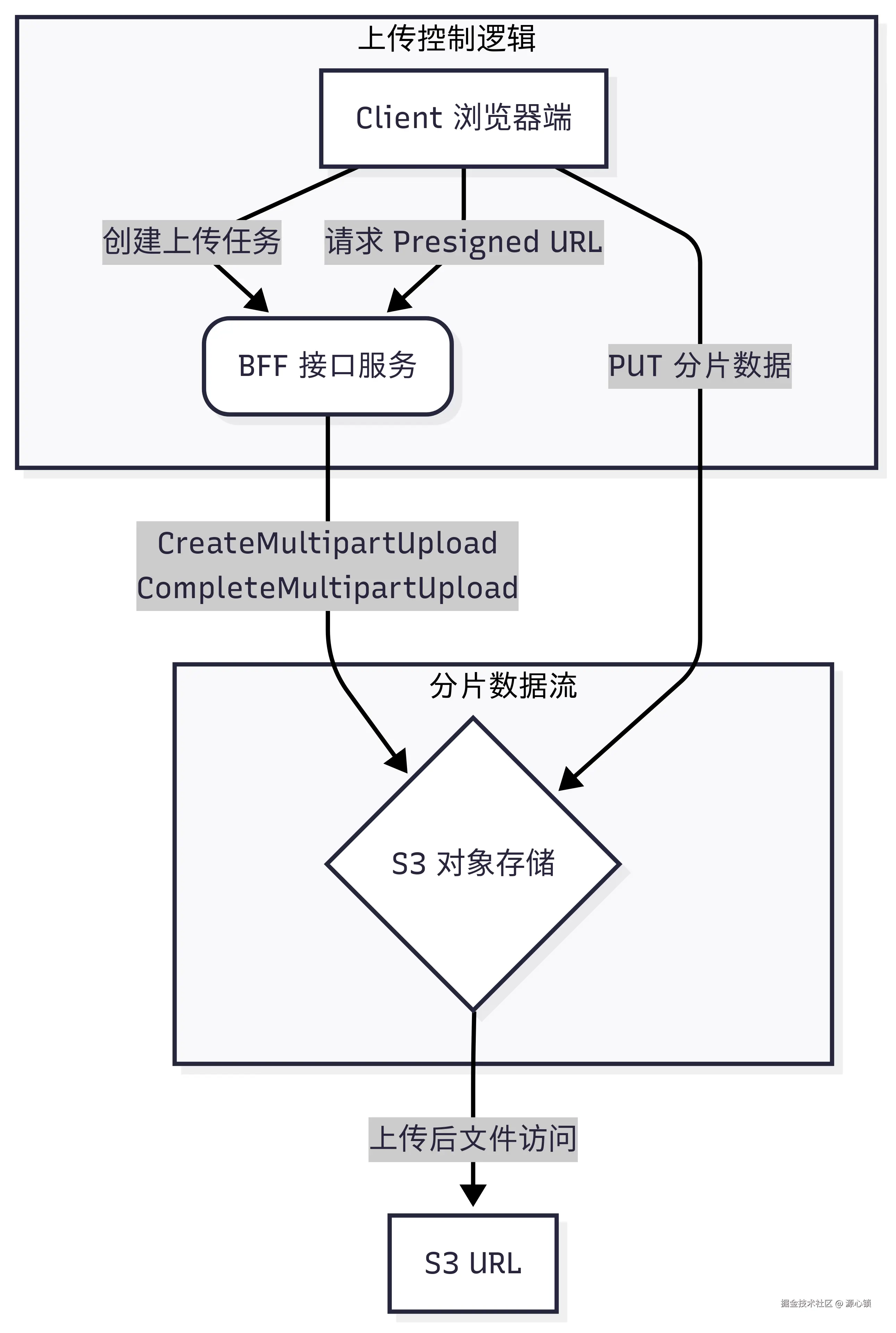
更细节的部分,可以参考这份时序图。
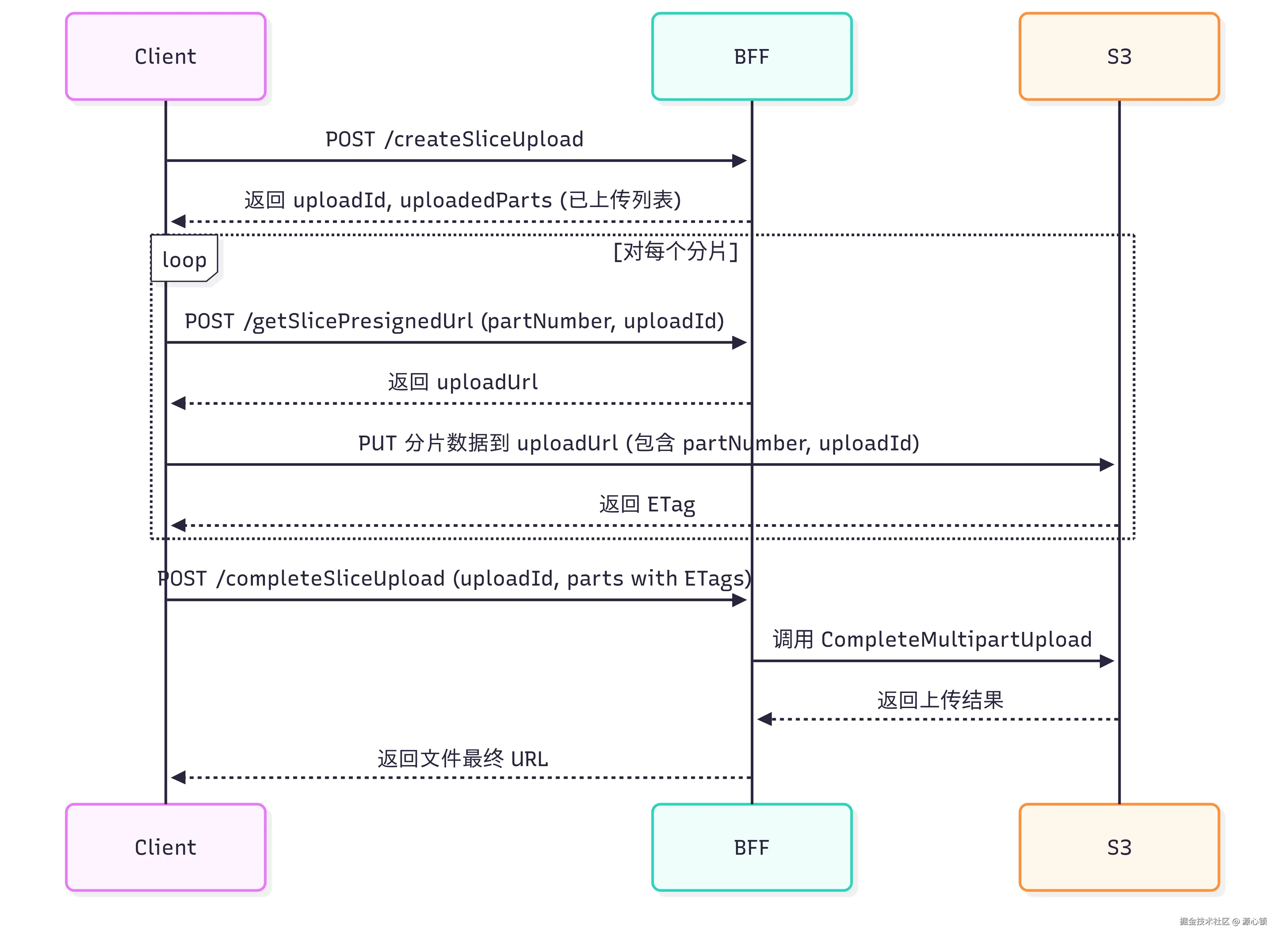
2.1 关键接口
📤 创建上传任务
-
接口地址 :
POST /createSliceUpload -
功能:
- 检查文件是否已存在
- 检查是否存在未完成的上传任务
- 创建新的分片上传任务
-
返回示例:
-
✅ 文件已存在:
js{ "id": "xxx", "fileName": "example.txt", "url": "https://..." } -
🔄 任务进行中:
js{ "id": "xxx", "fileName": "example.txt", "uploadId": "abc123", "uploadedParts": [1, 2, 3] } -
🆕 新建任务:
js{ "id": "xxx", "fileName": "example.txt", "uploadId": "abc123", "uploadedParts": [] }
-
🔗 获取分片上传 URL
-
接口地址 :
POST /getSlicePresignedUrl -
功能:获取指定分片的预签名上传 URL
-
请求参数:
js{ "id": "xxx", "fileName": "example.txt", "partNumber": 1, "uploadId": "abc123" } -
返回示例:
js{ "uploadUrl": "https://..." }
在 /getSlicePresignedUrl 接口中,我们通过 AWS SDK 可以预签一个直传 URL
js
import { UploadPartCommand } from '@aws-sdk/client-s3';
import { getSignedUrl } from '@aws-sdk/s3-request-presigner';
const uploadUrl = await getSignedUrl(
s3client,
new UploadPartCommand({
Bucket: AWS_BUCKET,
Key: fileKey,
PartNumber: partNumber,
UploadId: uploadId,
}),
{ expiresIn: 3600 },
);✅ 完成分片上传
-
接口地址 :
POST /completeSliceUpload -
功能:合并所有已上传的分片
-
请求参数:
js{ "id": "xxx", "fileName": "example.txt", "uploadId": "abc123", "parts": [ { "ETag": "etag1", "PartNumber": 1 }, { "ETag": "etag2", "PartNumber": 2 } ] } -
返回示例:
js{ "id": "xxx", "location": "https://..." }
2.2 前端设计
为了方便使用,我们尝试构建一套方便使用的 SDK,设计的 Options 如下
js
interface UploadSliceOptions {
fileName: string;
id: string;
getContent: (
uploadSlice: (params: { content: ArrayBufferLike; partNumber: number; isLast?: boolean }) => Promise<void>,
) => Promise<void>;
acl?: 'public-read' | 'authenticated-read';
contentType?: string;
contentEncoding?: 'gzip';
}这些参数的设计意图是:
-
fileName: 分片最终合并时呈现的名字 -
id:同名文件可能实际并不同,可以使用hash值来区分 -
核心上传逻辑的抽象(
getContent函数):-
职责:负责异步地生成或获取每一个文件分片(比如从本地文件中读取一块数据)
-
不直接接收文件内容,而是接收一个回调函数
uploadSlice作为参数。uploadSlice的职责是:负责异步地将这一个分片的数据(content)和它的序号(partNumber)发送到服务器。
-
-
可选的文件属性(HTTP 头部相关):
-
contentType?: string: 可选。指定文件的 MIME 类型(例如'image/jpeg'或'application/pdf')。这在云存储中很重要,它会影响文件被访问时的Content-Type响应头。 -
contentEncoding?: 'gzip': 可选。指明文件内容是否(或如何)被压缩的。在这里,它明确只支持'gzip',意味着如果提供了这个选项,上传的内容会被进行独立分片压缩。
2.2.1 核心功能实现
📤 单个分片上传
uploadSlice 函数实现逻辑如下:
- 通过
FileClient获取预签名 URL - 使用
fetchAPI 将分片内容上传到该 URL - 获取
ETag,并返回上传结果
js
export const uploadSlice = async ({ id, fileName, partNumber, content, uploadId }: UploadSliceParams) => {
const { uploadUrl: presignedUrl } = await FileClient.getSlicePresignedUrl({
id,
fileName,
partNumber,
uploadId,
});
const uploadRes = await fetch(presignedUrl, {
method: 'PUT',
body: content,
});
const etag = uploadRes.headers.get('etag');
if (!etag) throw new Error('Upload failed');
return {
ETag: etag,
PartNumber: partNumber,
};
};🔁 分片上传流程控制
uploadSliceFile 实现完整上传逻辑:
- 创建上传任务,获取
uploadId - 若返回完整 URL(如小文件无需分片),则直接返回
- 调用
getContent回调,获取各分片内容并上传 - 对失败的分片进行重试
- 所有分片上传完成后,调用接口合并分片
js
const uploadTask = await FileClient.createSliceUpload({
fileName,
id,
acl,
contentEncoding,
contentType,
});
if (uploadTask.url) {
return uploadTask.url; // 代表这个 id 的文件实际上已经上传过了
}
const { uploadedParts = [] } = uploadTask;
const uploadId = uploadTask.uploadId as string;
const parts: { PartNumber: number; ETag: string }[] = [...(uploadedParts as { PartNumber: number; ETag: string }[])];
await getContent(async ({content,isLast})=>{
...
const part = await uploadSlice({
content: new Blob([content]),
partNumber: currentPartNumber,
uploadId,
id,
fileName,
});
parts.push(part);
})
return FileClient.completeSliceUpload(...)❗ 错误处理与重试机制
- 最大重试次数:
MAX_RETRY_TIMES = 3 - 重试延迟时间:
RETRY_DELAY = 1000ms - 若分片上传失败,则按策略重试
- 合并上传前需校验所有分片是否上传成功
🔄 分片去重处理
合并前对已上传分片进行去重:
- 按分片序号排序
- 使用
Set记录已处理的分片编号 - 构建唯一的分片列表
2.2.2 使用示例
虽然咋一看有些奇怪,但这种方式对于流式上传支持度更好,且在普通场景也同样适用。如下边这份代码是普通文件的上传 demo
js
// 示例:上传一个大文件
const fileId = 'unique-file-id';
const fileName = 'large-file.mp4';
const file = /* 获取文件对象 */;
const chunkSize = 5 * 1024 * 1024; // 每片5MB
const chunks = Math.ceil(file.size / chunkSize);
const fileUrl = await uploadSliceFile({
fileName,
id: fileId,
getContent: async (uploadSlice) => {
for (let i = 0; i < chunks; i++) {
const start = i * chunkSize;
const end = Math.min(file.size, start + chunkSize);
const chunk = file.slice(start, end);
await uploadSlice({
content: chunk,
partNumber: i + 1, // 分片编号从1开始
});
}
},
});
console.log('文件上传成功,访问地址:', fileUrl);3 进阶:分块 GZIP 压缩
我们的日志,其以字符串的形式保存,上传时,最终也是要上传成一份文本型文件。
所以,我们可以考虑在上传前进行压缩,以进一步减少上传时的体积------这个过程中,我们可以考虑使用 gzip、brotli、zstd 等算法。
从兼容性考虑 💭,现在 Web 浏览器支持率最高的算法是 gzip 和 brotli 算法。但 brotli 的原理决定了我们可能很难完整发挥出 brotli 算法的效果。
原因有几个。
第一个致命的原因是,brotli(RFC 7932) 是一种 raw stream 格式,它的数据流由一个或多个"元块"(Meta-Block) 组成。流中的最后一个元块会包含一个特殊的 ISLAST 标志位,它相当于一个「文件结束符」
当我们单独压缩每一个分散的文本片段时:
文本A->片段A.br(最后一个元块包含ISLAST=true)文本B->片段B.br(最后一个元块包含ISLAST=true)文本C->片段C.br(最后一个元块包含ISLAST=true)- ...
当我们把它们合并在一起 时(例如通过 cat A.br B.br C.br > final.br),我们得到的文件结构是: [A的数据... ISLAST=true] [B的数据... ISLAST=true] [C的数据... ISLAST=true]
当一个标准的 Brotli 解码器(比如浏览器)读取这个 final.br 文件时:
- 解码器开始读取
[A的数据...]。 - 解码器读取到
A的最后一个元块,看到了ISLAST=true标志。 - 解码器立即停止解码,因为它认为流已经结束了。
[B的数据...]和[C的数据...]会被完全忽略,当成文件末尾的"垃圾数据"。
最终结果 : 我们只能成功解压出 文本A,所有后续的文本内容都会丢失。
------即便我们手动将 IS_LAST 修改正确,但「独立压缩」会导致另一个严重问题------压缩率的极大损失。
因为 br 的压缩过程中,需要先建立一个滑动窗口字典。而如果我们对每一个分片都进行压缩,br 实际上需要为每一个分片建立一个字典。
这意味着这个过程中,最核心的字典不断被重置,br 压缩器丢失了用于判断内部重复的关键工具, 进而会导致压缩率极大的下降。
而对于 gzip 来讲,虽然 gzip body 采用的 deflate 算法同样需要字段,但其窗口大小只有 32KB(br 则是 4-16MB),而我们单个分片单最小大小即是 %MB,所以对于 gzip 来说,分成 5MB 再压缩还是 500MB 直接压缩区别并不大。
所以,我们选择 gzip 来做分块压缩。
Gzip 协议是一种文件格式,它充当一个"容器"。这个容器包裹了使用 DEFLATE (RFC 1951) 算法压缩的数据块,并为其添加了元信息和校验和,以确保文件的完整性和可识别性。
一个 gzip 文件由三个核心部分组成:
- Header (头部) :识别文件并提供元信息。
- Body (主体) :包含
DEFLATE压缩的数据流。 - Footer (尾部) :提供数据完整性校验。
这意味着,我们进行分块压缩时,可以通过手动创建 header + body + footer 的方式进行分块压缩。
3.1 HEADER & FOOTER
头部至少有 10 个字节。
| 偏移量 (字节) | 长度 (字节) | 字段名 | 固定值 / 描述 |
|---|---|---|---|
| 0 | 1 | ID1 |
0x1f (或 31)。这是识别 gzip 文件的"魔术数字"第一部分。 |
| 1 | 1 | ID2 |
0x8b (或 139)。"魔术数字"第二部分。 |
| 2 | 1 | CM |
0x08 (或 8)。表示压缩方法 (Compression Method) 为 DEFLATE。 |
| 3 | 1 | FLG |
标志位 (Flags)。这是一个极其重要的字节,它的每一位都代表一个布尔值,用于控制是否存在"可选头部"。 |
| 4 | 4 | MTIME |
文件的最后修改时间 (Modification Time),以 4 字节的 Unix 时间戳格式存储。 |
| 8 | 1 | XFL |
额外标志 (Extra Flags)。通常用于指示 DEFLATE 压缩器使用的压缩级别(例如 0x02 = 最高压缩率,0x04 = 最快压缩率)。 |
| 9 | 1 | OS |
操作系统 (Operating System)。0x03 = Unix, 0x00 = Windows/FAT, 0xFF = 未知。 |
其中的核心部分是 FLG,即标志位。这是头部第 4 个字节 (偏移量 3),我们需要按位 (bit) 来解析它:
| Bit (位) | 掩码 (Hex) | 字段名 | 描述 |
|---|---|---|---|
| 0 (最低位) | 0x01 |
FTEXT |
如果置 1,表示文件可能是 ASCII 文本文件(这只是一个提示)。 |
| 1 | 0x02 |
FHCRC |
如果置 1,表示头部包含一个 2 字节的头部校验和 (CRC-16) 。 |
| 2 | 0x04 |
FEXTRA |
如果置 1,表示头部包含一个扩展字段 (extra field) 。 |
| 3 | 0x08 |
FNAME |
如果置 1,表示头部包含原始文件名。 |
| 4 | 0x10 |
FCOMMENT |
如果置 1,表示头部包含注释。 |
| 5 | 0x20 |
RESERVED |
保留位,必须为 0。 |
| 6 | 0x40 |
RESERVED |
保留位,必须为 0。 |
| 7 | 0x80 |
RESERVED |
保留位,必须为 0。 |
然后,根据 FLG 标志位的设置,紧跟在 10 字节固定头部后面的,可能会按顺序出现以下字段:
-
FEXTRA(如果FLG&0x04为真):XLEN(2 字节): 扩展字段的总长度 N。EXTRA(N 字节): N 字节的扩展数据。
-
FNAME(如果FLG&0x08为真):- 原始文件名,以
NULL(0x00) 字节结尾的 C 风格字符串。
- 原始文件名,以
-
FCOMMENT(如果FLG&0x10为真):- 注释,以
NULL(0x00) 字节结尾的 C 风格字符串。
- 注释,以
-
FHCRC(如果FLG&0x02为真):- 一个 2 字节的 CRC-16 校验和,用于校验整个头部(包括所有可选部分)的完整性。
我们的话,我们需要写入 filename,所以转换成代码,就是如下的实现:
js
/**
* 生成标准 GZIP Header(10 字节)
* 符合 RFC 1952 规范。
* 可用于拼接 deflate raw 数据生成完整 .gz 文件。
*/
/**
* 生成包含文件名的标准 GZIP Header
* @param {string} filename - 要嵌入头部的原始文件名
*/
export function createGzipHeader(filename: string): Uint8Array {
// 1. 创建基础的10字节头部,并将Flags位设置为8 (FNAME)
const header = new Uint8Array([
0x1f,
0x8b, // ID1 + ID2: magic number
0x08, // Compression method: deflate (8)
0x08, // Flags: 设置FNAME位 (bit 3)
0x00,
0x00,
0x00,
0x00, // MTIME: 0
0x00, // Extra flags: 0
0x03, // OS: 3 (Unix)
]);
// 动态设置 MTIME
const mtime = Math.floor(Date.now() / 1000);
header[4] = mtime & 0xff;
header[5] = (mtime >> 8) & 0xff;
header[6] = (mtime >> 16) & 0xff;
header[7] = (mtime >> 24) & 0xff;
// 2. 将文件名字符串编码为字节
const encoder = new TextEncoder(); // 默认使用 UTF-8
const filenameBytes = encoder.encode(filename);
// 3. 拼接最终的头部
// 最终头部 = 10字节基础头 + 文件名字节 + 1字节的null结束符
const finalHeader = new Uint8Array(10 + filenameBytes.length + 1);
finalHeader.set(header, 0);
finalHeader.set(filenameBytes, 10);
// 最后一个字节默认为0,作为null结束符
return finalHeader;
}
footer 则相对简单一些,尾部是固定 8 字节的块,由 CRC32 和 ISIZE 组成:
| 偏移量 | 长度 (字节) | 字段名 | 描述 |
|---|---|---|---|
| 0 | 4 | CRC-32 |
原始未压缩数据的 CRC-32 校验和。 |
| 4 | 4 | ISIZE |
原始未压缩数据 的大小 (字节数)。由于它只有 4 字节,gzip 文件无法正确表示大于 4GB 的文件(解压后的大小)。 |
这两个值是 gzip 压缩过程中需要从整个文件角度计算的信息,由于两者均可以增量计算,问题不大。(crc32 本身计算量不大,推荐直接使用 sheetjs 库就行)
这样的话,我们就得到了这样的代码:
js
export function createGzipFooter(crc32: number, size: number): Uint8Array {
const footer = new Uint8Array(8);
const view = new DataView(footer.buffer);
view.setUint32(0, crc32, true);
view.setUint32(4, size % 0x100000000, true);
return footer;
}3.2 BODY
对我们来说,中间的 raw 流是最麻烦的。
gzip body 中的 DEFLATE 流 (RFC 1951) 并不是一个单一的、连续的东西,它本身就有一套非常重要的"特殊规则"。
DEFLATE 流的真正结构是由一个或多个数据"块" (Block) 拼接而成的。
gzip压缩器在工作时,会根据数据的情况,智能地将原始数据分割成不同类型的"块"来处理。它可能会先用一种块,然后再换另一种,以达到最佳的压缩效果。
DEFLATE 流中的每一个"块",都必须以一个 3-bit (比特) 的头部开始。这个 3-bit 的头部定义了这个块的所有规则。
这 3 个 bit (比特) 分为两部分:
-
BFINAL(1-bit): "最后一块"标记1: 这是整个DEFLATE流的最后一个块。解压器在处理完这个块后,就应该停止,并去寻找gzip的 Footer (CRC-32 和 ISIZE)。0: 后面还有更多的块,请继续。
-
BTYPE(2-bits): "块类型"- 这 2 个 bit 决定了紧随其后的整个块的数据要如何被解析。
BTYPE 字段有三种可能的值,每一种都代表一套完全不同的压缩规则:
****规则 1:BTYPE = 00 (无压缩块) 压缩器在分析数据时,如果发现数据是完全随机的(比如已经压缩过的图片、或加密数据),它会发现压缩后的体积反而变大了。
-
此时,它会切换到
00模式,意思是:"我放弃压缩,直接原文存储。" -
结构:
(BFINAL, 00)这 3-bit 头部。- 跳到下一个字节边界 (Byte-alignment)。
LEN(2 字节): 声明这个块里有多少字节的未压缩数据(长度 N)。NLEN(2 字节):LEN的"反码"(NOT LEN),用于校验LEN是否正确。- N 字节的原始数据(原文照搬)。
规则 2:BTYPE = 01 (静态霍夫曼压缩)
-
这是"标准"规则。 压缩器使用一套固定的、在 RFC-1951 规范中预先定义好的霍夫曼树(Huffman Tree)来进行压缩。
-
这套"静态树"是基于对大量英语文本统计分析后得出的最佳通用编码表(例如,'e'、'a'、' ' 的编码非常短)。
-
优点: 压缩器不需要在数据流中包含霍夫曼树本身,解压器直接使用它内置的这套标准树即可。这节省了头部空间。
-
缺点: 如果你的数据不是英语文本(比如是中文或代码),这套树的效率可能不高。
-
结构:
(BFINAL, 01)这 3-bit 头部。- 紧接着就是使用"静态树"编码的
LZ77 + 霍夫曼编码的数据流。 - 数据流以一个特殊的"块结束"(End-of-Block, EOB) 符号(静态树中的
256号符号)结尾。
规则 3:BTYPE = 10 (动态霍夫曼压缩)
-
这是"定制"规则,也是压缩率最高的规则。
-
压缩器会先分析这个块的数据,统计出所有字符的准确频率,然后为这个块"量身定做"一套最优的霍夫曼树。
-
优点: 压缩率最高,因为它完美贴合了当前数据块的特征(比如在压缩 JS 时,
{}().的编码会变得极短)。 -
缺点: 压缩器必须把这套"定制树"本身也压缩后,放到这个块的开头,以便解压器知道该如何解码。这会占用一些头部空间。
-
结构:
(BFINAL, 10)这 3-bit 头部。- 一个"定制霍夫曼树"的描述信息(这部分本身也是被压缩的)。
- 紧接着是使用这套"定制树"编码的
LZ77 + 霍夫曼编码的数据流。 - 数据流以一个特殊的"块结束"(End-of-Block, EOB) 符号(定制树 中的
256号符号)结尾。
------不过,于我们而言,我们先通过静态霍夫曼压缩即可。
这个过程中,我们需要借助三方库,目前浏览器虽然支持 CompressionStream API,但并不支持我们进行精确流控制。
js
import pako from 'pako';
export async function compressBufferRaw(buf: ArrayBufferLike, isLast?: boolean): Promise<ArrayBufferLike> {
const originalData = new Uint8Array(buf);
const deflater = new pako.Deflate({ raw: true });
deflater.push(originalData, isLast ? pako.constants.Z_FINISH : pako.constants.Z_SYNC_FLUSH);
if (!isLast) {
deflater.onEnd(pako.constants.Z_OK);
}
const compressedData = deflater.result;
return compressedData.buffer;
}我们用一个示例来表示一个完整 gzip 文件的话,方便理解。假设我们压缩一个叫 test.txt 的文件,它的 Gzip 文件 test.txt.gz 在十六进制编辑器中可能如下所示:
js
Offset Data
------ -------------------------------------------------------------
0000 1F 8B (ID1, ID2: Gzip 魔术数字)
0002 08 (CM: DEFLATE)
0003 08 (FLG: 0x08 = FNAME 标志位置 1)
0004 XX XX XX XX (MTIME: 4 字节时间戳)
0008 04 (XFL: 最快压缩)
0009 03 (OS: Unix)
(可选头部开始)
000A 74 65 73 74 (t e s t)
000E 2E 74 78 74 (. t x t)
0012 00 (FNAME: NULL 终结符)
(Body 开始)
0013 ED C0 ... (DEFLATE 压缩流开始...)
...
... ... (...此块数据流的末尾包含一个 EOB 符号...)
(... DEFLATE 压缩流结束)
(Footer 开始)
XXXX YY YY YY YY (CRC-32: 原始 test.txt 文件的校验和)
XXXX+4 ZZ ZZ ZZ ZZ (ISIZE: 原始 test.txt 文件的大小)
至此,我们完成了一套社区前列的分片上传方案。S3 将所有上传的部分按序合并后,在S3上形成的文件结构是:[Gzip Header][Deflate_Chunk_1][Deflate_Chunk_2]...[Deflate_Last_Chunk][Gzip Footer] 这个拼接起来的文件是一个完全合法、可流式解压的 .gz 文件。
4 性能 & 对比
为了验证该方案(Smart S3 Gzip)的实际效果,我们构建了一个基准测试环境,将本文方案与「普通直传」及「传统前端压缩上传」进行全方位对比。
4.1 测试环境
- 测试文件:1GB Nginx Access Log (纯文本)
- 网络环境:模拟家用宽带上行 50Mbps (约 6.25MB/s)
- 测试设备:MacBook Pro (M1 Pro), 32GB RAM
- 浏览器:Chrome 143
4.2 核心指标对比
| 核心指标 | 方案 A:普通直传 | 方案 B:前端整体压缩 | 方案 C:本文方案 (分片 Gzip 流) |
|---|---|---|---|
| 上传总耗时 | ~165 秒 | ~45 秒 (但等待压缩很久) | ~38 秒 (边压边传) |
| 首字节发送时间 | 0 秒 (立即开始) | 30 秒+ (需等待压缩完成) | 0.5 秒 (首个分片压缩完即发) |
| 峰值内存占用(计算值) | 50MB (流式) | 2GB+ (需读入全量文件) | 100MB (仅缓存并发分片) |
| 网络流量消耗 | 1GB | ~120MB | ~121MB (略多出的 Header 开销可忽略) |
| 客户端 CPU 负载 | 极低 (<5%) | 单核 100% (持续一段时间,可能 OOM) | 多核均衡 (并发压缩,利用率高) |
4.3 深度解析
🚀 1. 速度提升的秘密:流水线效应
在方案 B(整体压缩)中,用户必须等待整个 1GB 文件在本地压缩完成,才能开始上传第 1 个字节。这是一种「串行阻断」模型。 而本文方案 C 采用了「流水线(Pipeline)」模型:压缩第 N 个分片的同时,正在上传第 N-1 个分片。 对于高压缩率的文本文件(通常压缩比 5:1 到 10:1),网络传输往往比本地 CPU 压缩要慢。这意味着 CPU 的压缩几乎是"免费"的,因为它掩盖在了网络传输的时间里。
💰 2. 成本分析:不仅是快,还省钱
AWS S3 的计费主要包含存储费和流量费。
- 存储成本:1GB 的日志存入 S3,如果未压缩,每月存储费是压缩后的 5-10 倍。虽然 S3 本身很便宜,但对于 PB 级日志归档,这笔费用惊人。
- 传输加速成本:如果使用了 S3 Transfer Acceleration,费用是按流量计算的。压缩后上传意味着流量费用直接打一折。
🛡️ 3. 内存安全性
方案 B 是前端的大忌。试图将 1GB 文件读入 ArrayBuffer 进行整体 gzip 压缩,极其容易导致浏览器 Tab 崩溃(OOM)。本文方案将内存控制在 分片大小 * 并发数 (例如 5MB * 5 = 25MB) 的安全范围内,即使上传 100GB 文件也不会爆内存。
4.4 适用场景与局限性
✅ 强烈推荐场景:
- 日志归档 / 数据备份:CSV, JSON, SQL Dump, Log 文件。压缩率极高,收益巨大。
- 弱网环境:上传带宽受限时,压缩能显著减少等待时间。
❌ 不推荐场景:
- 已经压缩的文件:MP4, JPG, ZIP, PNG。再次 Gzip 几乎无压缩效果,反而浪费 CPU。
- 超低端设备 :如果用户的设备是性能极差的老旧手机,CPU 压缩速度可能低于网络上传速度,反而成为瓶颈。建议在 SDK 增加
navigator.hardwareConcurrency检测,自动降级。
5 结语
通过深入理解 HTTP、AWS S3 协议以及 Gzip 的二进制结构,我们打破了"压缩"与"分片"不可兼得的魔咒。这套系统目前已在我们内部的日志回放平台稳定运行,有效减少文件上传时长。
有时候,技术的突破口往往就藏在那些看似枯燥的 RFC 文档里。希望这篇"硬核"的实战总结,能给你带来一些启发。