前言
作为 C++ 学习者,光会用 STL list 总觉得差点意思 ------ 这次手写模拟实现,就是想从底层搞懂它:双向链表节点咋设计?迭代器为啥能 "++/--"?插入删除咋做到不影响其他元素?
这篇笔记是我的实践记录:从节点、迭代器到容器接口,一步步还原 list 的核心逻辑,把 "用容器" 变成 "懂容器"。
☃ C++ 初阶
【......】
目录
[℡. 节点结构](#℡. 节点结构)
[℡. 迭代器结构](#℡. 迭代器结构)
[℡. 链表结构](#℡. 链表结构)
[2.1 operator*](#2.1 operator*)
[℡. Ref参数的作用?](#℡. Ref参数的作用?)
[2.2 operator->](#2.2 operator->)
[℡. ptr模版参数的作用?](#℡. ptr模版参数的作用?)
[2.3 operator前置++/--](#2.3 operator前置++/--)
[2.4 operator后置++/--](#2.4 operator后置++/--)
[2.5 operator!=/==](#2.5 operator!=/==)
[2.6 迭代器拷贝构造问题?](#2.6 迭代器拷贝构造问题?)
一、List的介绍
list 是 STL 中支持在任意位置高效(常数时间)插入、删除的双向迭代序列式容器,底层基于带头双向链表实现 ------ 每个元素存于独立节点,通过指针连接前后元素;它和 forward_list 类似但后者是单链表、仅支持前向迭代;和 array、vector、deque 相比,list 的插入删除效率更优,但缺点是不支持随机访问(访问第 n 个元素需线性遍历),且每个节点的指针会占用额外空间(对存储小元素的大 list 影响较明显)。
二、默认成员函数
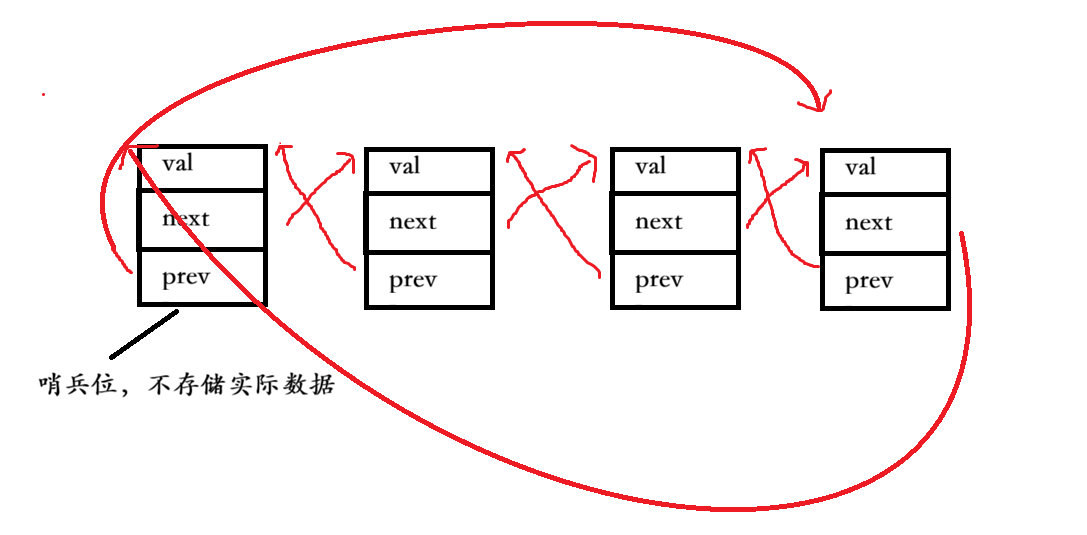
1、List的节点结构、容器结构
℡. 节点结构
cpp
namespace ljh
{
// 定义list的双向链表节点结构(模板类,支持任意数据类型T)
template<class T>
struct list_node
{
// 构造函数:初始化节点值,前后指针默认置空
list_node(const T& val)
: _next(nullptr) // 指向下一个节点的指针
, _prev(nullptr) // 指向上一个节点的指针
, _val(val) // 节点存储的数据
{}
T _val; // 节点数据域
list_node<T>* _next; // 后继节点指针
list_node<T>* _prev; // 前驱节点指针
};
}成员变量设为公有,是为了让后续写 list 容器 / 迭代器时,能直接操作节点的_next/_prev/_val,省写 get/set,简化代码。
℡. 迭代器结构
这段迭代器结构目前还不完整,后面的讲解会逐步完善链表迭代器的实现:
cpp
namespace ljh
{
// 链表迭代器模板类
template<class T>
struct _list_iterator
{
typedef list_node<T> Node; // 节点类型别名
// 构造:用节点指针初始化迭代器
_list_iterator(Node* node)
:_node(node)
{}
Node* _node; // 指向链表节点的指针
};
}链表的迭代器为啥不能直接用原生指针?
因为链表的原生指针(比如list_node*)只能访问节点本身,而迭代器需要模拟 "像普通指针一样解引用取数据、++/-- 遍历" 的行为 ------ 链表节点里存的是_val(实际数据),原生指针解引用得到的是整个节点,不是数据;且链表的 "下一个元素" 需要通过_next指针跳转,原生指针的++是地址 + 1(不符合链表的节点连接逻辑),所以得封装迭代器类来重载*、++等运算符,不能直接用原生指针。
迭代器结构为啥用struct?
迭代器结构体用 struct,是因为迭代器只是遍历容器的工具 ------ 哪怕直接定义迭代器对象,没有对应的容器支撑,也没法实际访问有效数据,所以不用刻意封装成私有,用 struct 让成员(比如这里的 node 指针)直接暴露,能简化后续迭代器功能的实现。
迭代器为啥不能写析构函数?
不能为迭代器编写析构函数 ------ 因为节点的内存是由容器管理的,迭代器只是 "借用节点指针来访问元素",本身并不持有节点的所有权。若在迭代器析构时释放节点,会导致容器内的节点被非法销毁,进而引发内存错误。
℡. 链表结构
cpp
namespace ljh
{
template<class T>
class list
{
typedef list_node<T> Node; // 链表节点类型别名
private:
Node* _head; // 指向链表头节点的指针
size_t _size; // 链表中有效元素的个数
};
}2、List构造函数
cpp
// 初始化空链表(创建哨兵位)
void empty_init()
{
_head = new Node(-1); // 新建头节点(用-1占位)
_head->_prev = _head; // 头节点前驱指向自身(循环链表)
_head->_next = _head; // 头节点后继指向自身(循环链表)
_size = 0; // 链表初始长度为0
}
// 链表构造函数
list()
{
empty_init();
}3、List拷贝构造函数
cpp
// 拷贝构造函数:用已有的list对象lt初始化新对象
list(const list<T>& lt)
{
empty_init(); // 先初始化空链表(创建头节点)
// 遍历lt的每个元素,逐个尾插到新链表中
for (auto& e : lt)
{
push_back(e);
}
}4、List赋值运算符重载
cpp
void swap(list<T>& lt)
{
std::swap(_head, lt._head); // 交换头节点指针
std::swap(_size, lt._size); // 交换元素个数
}
// 赋值运算符重载
list<T>& operator=(list<T> lt) // 传值调用,自动拷贝出临时对象lt
{
swap(lt); // 交换当前对象与临时对象的资源
return *this; // 返回当前对象,临时对象会自动销毁旧资源
}利用拷贝构造 + 交换实现赋值运算符重载,高效且安全
5、List析构函数
cpp
// 清空链表中所有有效元素(保留头节点)
void clear()
{
iterator it = begin(); // 获取链表起始迭代器
while (it != end()) // 遍历所有有效元素
{
it = erase(it); // 删除当前元素,erase返回下一个元素的迭代器
}
_size = 0; // 重置有效元素个数为0
}
// 链表析构函数:释放所有资源
~list()
{
clear(); // 先清空所有有效元素
delete _head; // 释放头节点的堆内存
_head = nullptr; // 将头节点指针置空,避免野指针
}三、迭代器
1、begin/end
cpp
// 普通迭代器:元素可读写
typedef _list_iterator<T, T&, T*> iterator;
// const迭代器:元素只读
typedef _list_iterator<T, const T&, const T*> const_iterator;
// 普通正向迭代器:指向第一个有效元素
iterator begin()
{
return iterator(_head->_next);
}
// 普通正向迭代器:指向尾后位置(头节点)
iterator end()
{
return iterator(_head);
}
// const正向迭代器:指向第一个有效元素(只读)
const_iterator begin() const
{
return const_iterator(_head->_next);
}
// const正向迭代器:指向尾后位置(只读)
const_iterator end() const
{
return const_iterator(_head);
}迭代器类的单参数构造函数支持隐式类型转换,可将Node*自动转为iterator/const_iterator对象(我知道大家对迭代器类型typedef里那三个模板参数会有点疑惑,等后面实现迭代器的运算符重载,就能明白它们的作用啦)
目前我们先不写反向迭代器,等学到后面的容器适配器部分时,我会讲解它的实现方式
2、迭代器的运算符重载
cpp
//typedef _list_iterator<T, T& , T*> iterator;
//typedef _list_iterator<T, const T& , const T*> iterator;
// 链表迭代器模板类(T:元素类型 Ref:元素引用类型 Ptr:元素指针类型)
template<class T, class Ref, class Ptr >
struct _list_iterator
{
typedef list_node<T> Node; // 链表节点类型别名
typedef _list_iterator<T, Ref, Ptr> self; // 迭代器自身类型别名,简化后续使用
Node* _node; // 指向链表节点的核心指针
// 单参数构造函数
_list_iterator(Node* node)
:_node(node)
{
}
// 解引用运算符重载:返回元素的引用(Ref决定是可读写/只读)
Ref operator*()
{
return _node->_val;
}
// ->运算符重载:返回元素的指针(Ptr决定是可读写/只读,用于访问自定义类型成员)
Ptr operator->()
{
return &this->_node->_val;
}
// 前置++运算符重载:移动到下一个节点,返回自身引用(高效,无临时对象)
self& operator++()
{
_node = _node->_next;
return *this;
}
// 后置++运算符重载:移动到下一个节点,返回原位置迭代器(int是占位符,区分前后置)
self operator++(int)
{
self tmp(*this); // 保存当前迭代器状态
_node = _node->_next; // 移动到下一个节点
return tmp; // 返回原位置的临时迭代器
}
// 前置--运算符重载:移动到前一个节点,返回自身引用
self& operator--()
{
_node = _node->_prev;
return *this;
}
// 后置--运算符重载:移动到前一个节点,返回原位置迭代器(int是占位符)
self operator--(int)
{
self tmp(*this); // 保存当前迭代器状态
_node = _node->_prev; // 移动到前一个节点
return tmp; // 返回原位置的临时迭代器
}
// 判不等运算符重载:判断两个迭代器是否指向不同节点(const保证不修改参数)
bool operator!=(const self& it) const
{
return _node != it._node;
}
// 判相等运算符重载:判断两个迭代器是否指向同一个节点
bool operator==(const self& it)
{
return _node == it._node;
}
};2.1 operator*
这里返回的是_node节点存储的数据,返回类型用T&(目的是避免传递自定义类型时产生不必要的拷贝开销)
℡. Ref参数的作用?
而我们在代码里用Ref替代了具体的返回值类型,是为了通过这个模板参数适配const迭代器:当第二个模板参数传入的是const T&时,就代表这是一个const迭代器(此时解引用返回的是只读引用)
2.2 operator->
重载这个运算符,是为了应对数据是结构体的场景:当存储的数据是结构体时,仅用operator*解引用后,没办法直接访问结构体的成员(得通过.来访问);而重载->后,就能直接通过迭代器用->访问结构体成员,用起来更便捷。
但这里又有个问题:我们通过operator->拿到的是_node节点的指针,而不是节点里存储的结构体成员 ------ 这显然不是我们想要的访问效果。

我们看这段代码的实际效果:当用迭代器it访问结构体A的成员时,理论上应该写it->->_a2(因为operator->()返回的是A*指针,需要再用->访问成员),但编译器做了特殊处理 ------ 自动省略了一个->,所以直接写it->_a1/it->_a2就能正常访问。
这背后的逻辑是:operator*()返回的是A&引用(所以可以用(*it)._a1访问),而operator->()返回的是A*指针;为了让迭代器的用法和原生指针一致(原生指针可以直接用->访问成员),C++ 编译器对迭代器的operator->做了 "语法糖" 优化,允许省略一次->,让it->_a2等价于(it.operator->())->_a2,用起来更自然简洁。
℡. ptr模版参数的作用?
Ptr的作用在此体现:区分普通迭代器返回的T*(可读写结构体成员)和const迭代器返回的const T*(只读),实现一套模板复用,保证const迭代器的安全性。
至于为啥要将迭代器重命名为self把迭代器重命名为self,是因为它的完整类型名太长了,用self代替能简化代码书写。
2.3 operator前置++/--
前置++和--的逻辑很相似:都是直接修改当前迭代器的节点指针(_node),然后返回自身的引用。
比如前置++是把_node指向 "下一个节点",前置--是指向 "前一个节点";返回自身引用的好处是支持链式操作 (比如++(++it)、--(--it)),而且没有临时对象的开销,效率更高。
2.4 operator后置++/--
后置++和--的核心是 "先返回原状态,再移动":
函数参数里的int是个占位符 (没有实际意义,只是用来区分前置 / 后置),实现时会先创建一个临时迭代器tmp保存当前状态,然后移动_node到下一个 / 前一个节点,最后返回这个临时迭代器。
这样外部使用时,it++拿到的是 "移动前的迭代器",而it本身已经完成了移动 ------ 不过因为会创建临时对象,它的效率比前置版本略低。
2.5 operator!=/==
这两个运算符的逻辑很直接:判断两个迭代器的_node指针是否指向同一个节点。
operator!=返回_node != it._node,表示 "两个迭代器是否指向不同节点";
operator==返回_node == it._node,表示 "两个迭代器是否指向同一个节点"。其中operator!=后面加了const,是为了保证 "调用这个函数时不会修改当前迭代器的状态",更符合const正确性的规范。
2.6 迭代器拷贝构造问题?
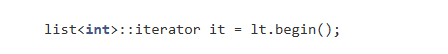
lt.begin()返回临时迭代器,it是用它拷贝构造而来的。编译器默认生成的拷贝构造是浅拷贝,只会复制内部节点指针,让it和原临时迭代器指向链表中同一个节点。
这刚好满足需求,深拷贝不仅要逐个拷贝链表节点、构建值相同但独立的新链表,完全多此一举,还会带来巨大开销,对迭代器来说毫无意义。
因此迭代器不用写拷贝构造。
四、list增删查改
1、push_back
cpp
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
++_size;
}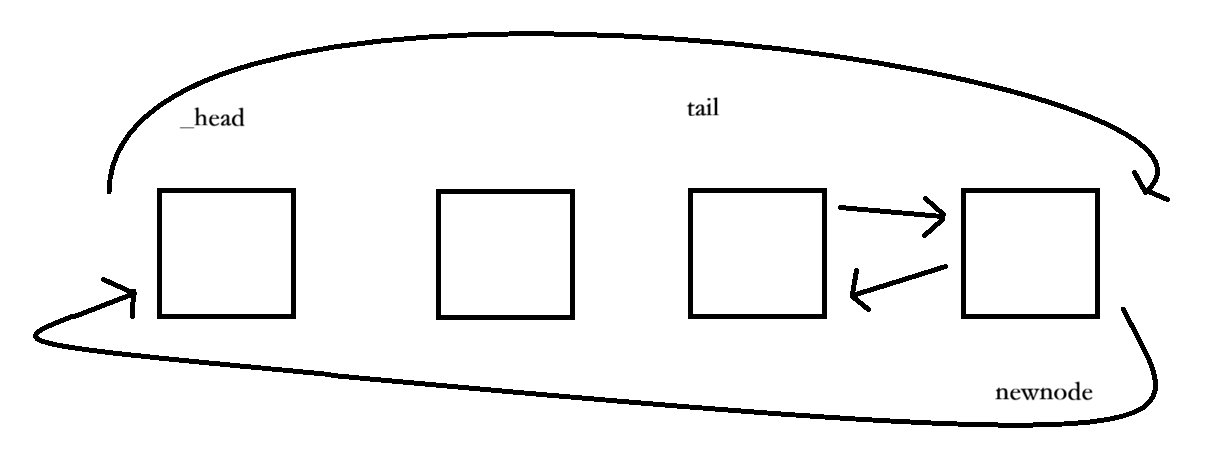
先找到链表的尾节点tail(通过头节点_head的_prev拿到),再创建新节点newnode;
接着把tail的next指向新节点、新节点的prev指向tail,完成新节点和原尾节点的连接;
最后让新节点的next指向头节点、头节点的prev指向新节点,维持链表的循环结构 ------ 这样新节点就成了新的尾节点,尾插完成。
2、insert
cpp
// pos位置之前插入
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;//迭代器指向的节点
Node* prev = cur->_prev;
Node* newnode = new Node(x);
prev->_next = newnode;
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
++_size;
return newnode;//返回新节点的迭代器
}先从迭代器pos里拿到它指向的节点cur,再找到cur的前驱节点prev,同时创建新节点newnode;
把prev的next指向新节点、新节点的next指向cur,再让cur的prev指向新节点、新节点的prev指向prev------ 这样就把新节点 "夹" 在了prev和cur之间;
最后更新链表长度_size,并返回新节点对应的迭代器,方便后续操作。
3、push_front
cpp
void push_front(const T& x)
{
insert(begin(), x);
}直接复用insert,在begin()(头节点迭代器)前插入元素x,既简化代码又保证逻辑一致
4、pop_back
cpp
void pop_back()
{
// 断言:确保链表不为空(避免删除空链表的元素)
assert(_head->_next != _head);
// 找到要删除的尾节点
Node* del = _head->_prev;
// 找到尾节点的前驱节点(新的尾节点)
Node* tail = del->_prev;
// 建立新尾节点和头节点的双向连接,断开原尾节点
tail->_next = _head;
_head->_prev = tail;
// 释放原尾节点的内存
delete del;
// 更新链表元素个数
_size--;
}先断言链表非空,找到尾节点和它的前驱节点,重新建立前驱节点与头节点的循环连接,释放原尾节点内存,最后更新链表长度。
5、erase
cpp
// pos位置删除
iterator erase(iterator pos)
{
// 断言:确保删除的不是尾后迭代器(无效节点)
assert(pos != end());
// 提取待删除节点cur
Node* cur = pos._node;
// 找到cur的前驱和后继节点
Node* prev = cur->_prev;
Node* next = cur->_next;
// 建立前驱和后继的双向连接,跳过待删除节点
prev->_next = next;
next->_prev = prev;
// 释放待删除节点内存
delete cur;
// 更新链表元素个数
--_size;
// 返回后继节点迭代器,避免迭代器失效
return next;
}先断言避免删除无效节点,找到待删节点的前后节点并重新建立连接,释放待删节点内存,更新链表长度后返回后继节点迭代器防止失效。
6、pop_front
cpp
void pop_front()
{
// 复用erase函数,删除头节点(begin()对应的迭代器)
erase(begin());
}直接复用erase函数,删除begin()对应的头节点,既简化代码又保证逻辑一致。
7、list迭代器失效问题
insert 操作:list 节点物理离散,插入仅新增节点、不改变原有节点地址,因此原迭代器不会失效;返回新节点迭代器,可按需更新使用。
erase 操作:仅被删除节点的迭代器失效(节点内存被释放),其他迭代器仍有效;返回被删节点的后继节点迭代器,需用它更新原迭代器,避免访问失效节点。
双向链表的insert操作虽然不会导致迭代器失效,但依然返回新节点对应的迭代器,核心目的就是为了保证接口统一
五、其他接口
1、swap
cpp
void swap(list<T>& lt)
{
// 交换两个链表的头节点指针
std::swap(_head, lt._head);
// 交换两个链表的元素个数
std::swap(_size, lt._size);
}通过std::swap分别交换两个链表的头节点指针和元素个数,实现两个链表数据的高效交换(无需拷贝 / 移动节点,仅交换两个核心成员,时间复杂度 O (1))。
2、clear
cpp
void clear()
{
// 从链表头开始遍历
iterator it = begin();
// 遍历至尾后迭代器
while (it != end())
{
// 删当前节点,并通过返回值更新迭代器(避免失效)
it = erase(it);
}
// 重置链表元素个数
_size = 0;
}通过遍历 + 复用erase删除所有节点,利用erase返回的后继迭代器避免失效,最后重置_size完成清空。
3、迭代器性质方面分类

单向迭代器 :仅支持++(向后移动),对应底层是单向链表 / 哈希结构的容器(如forward_list、unordered_map);
双向迭代器 :支持++/--(前后移动),对应底层是双向链表 / 树形结构的容器(如list、map、set);
随机迭代器 :支持++/--/+/-(任意位置跳转),对应底层是连续存储的容器(如vector、string、deque)。
4、sort
问题1:list不能用std::sort的原因
std::sort算法要求迭代器是随机迭代器 (支持+/-等随机跳转操作),但list的迭代器是双向迭代器 (仅支持++/--),不满足std::sort的要求,因此list无法直接使用全局的std::sort。
问题2:list的内置sort成员函数
list提供了自己的sort成员函数,但它的效率存在局限性:
因为链表是离散存储 的,元素不连续,缓存利用率低,所以list::sort的效率比std::sort(基于连续存储的高效排序)要差;
仅在数据量较小 时,list::sort的效率尚可;数据量较大时,和std::sort的效率差异会非常明显。
std::sort和list::sort效率对比
cpp
void test_op()
{
srand((unsigned)time(NULL));
const int N = 5000000;
vector<int> v;
v.reserve(N);
list<int> lt1;
for (int i = 0; i < N; ++i)
{
auto e = rand();
v.push_back(e);
lt1.push_back(e);
}
// vector用std::sort排序
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
// 链表用list::sort排序
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}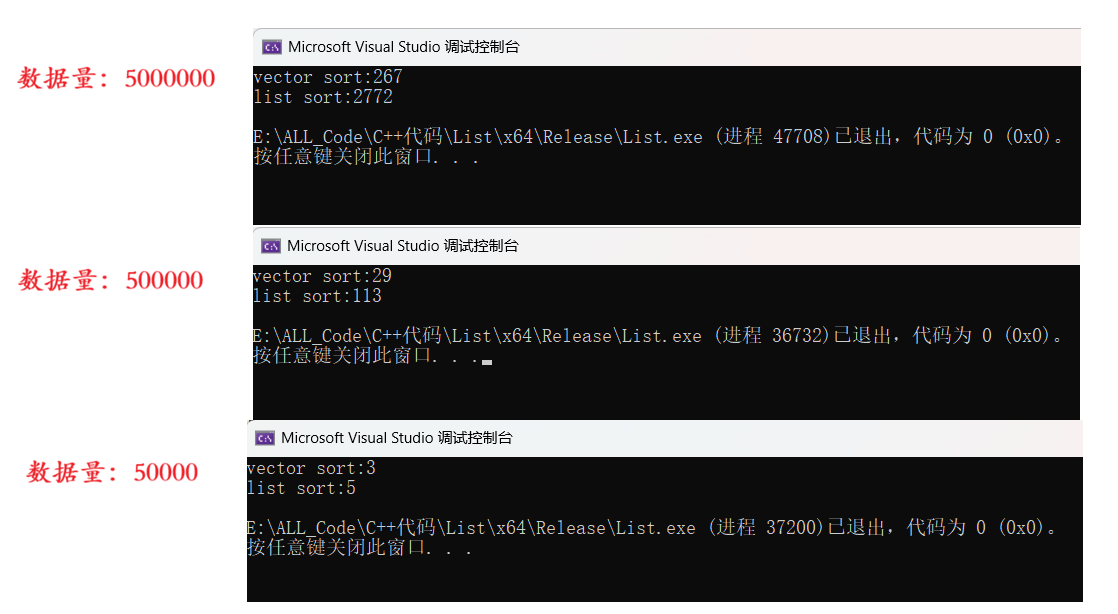
数据量越小,差异越小 当数据量仅 5 万时,vector sort耗时 3,list sort耗时 5,两者效率接近;
数据量越大,差异越悬殊 数据量到 500 万时,vector sort仅需 267,list sort却要 2772------ 耗时是前者的 10 倍以上;
核心原因 vector是连续存储,std::sort能利用缓存高效排序;而list是离散节点,list::sort缓存利用率低,数据量放大后效率劣势会被急剧放大。
这个结果也验证了 "list::sort仅适合小数据量" 的结论。
优化方案
1、拷贝数据 :把std::list中的元素拷贝到std::vector中(利用vector的连续存储特性);
2、高效排序 :用std::sort对vector中的数据排序(std::sort适配随机迭代器,效率高);
3、拷贝回写 :将排序后的vector数据再拷贝回std::list。
借助vector的连续存储 + 缓存友好 ,结合std::sort的高效实现,能大幅提升list数据的排序性能(尤其适合大数据量场景)。
需要权衡 "两次数据拷贝的成本"------ 但大数据量下,std::sort的效率收益远大于拷贝开销,整体性价比更高。
cpp
void test_op()
{
srand((unsigned)time(NULL));
// 定义数据量(500万,可按需调整)
const int N = 5000000;
// 定义两个相同的list,保证对比公平
list<int> lt1;
list<int> lt2;
// 生成随机数,存入两个list
for (int i = 0; i < N; ++i)
{
auto e = rand();
lt1.push_back(e);
lt2.push_back(e);
}
// 方案1:list→vector→std::sort→回写list
int begin1 = clock();
vector<int> v;
// 预留空间,避免vector扩容开销,提升效率
v.reserve(N);
// 1. list数据拷贝到vector
for (auto& e : lt1)
{
v.push_back(e);
}
// 2. 用std::sort对vector高效排序
sort(v.begin(), v.end());
// 3. 排序后的数据回写list
int i = 0;
for (auto& e : lt1)
{
e = v[i++];
}
int end1 = clock();
// 方案2:直接调用list内置sort成员函数
int begin2 = clock();
lt2.sort();
int end2 = clock();
// 打印两种方案的耗时(CPU时钟周期数)
printf("list→vector→std::sort 耗时:%d\n", end1 - begin1);
printf("list::sort 直接排序 耗时:%d\n", end2 - begin2);
}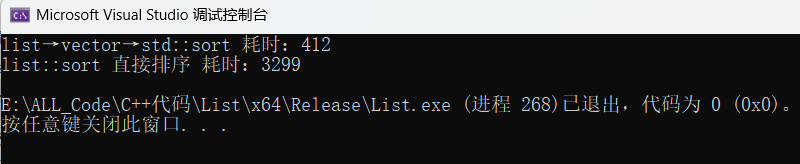
从运行结果能明显看到:"list→vector→std::sort" 仅耗时 412,而 "list::sort 直接排序" 耗时 3299,前者效率是后者的 8 倍左右,充分体现了借助 vector+std::sort 优化 list 排序的显著优势。
