Over-Searching in Search-Augmented Large Language Models
Authors: Roy Xie, Deepak Gopinath, David Qiu, Dong Lin, Haitian Sun, Saloni Potdar, Bhuwan Dhingra
Deep-Dive Summary:
搜索增强型大型语言模型中的过度搜索问题
Roy Xie (^{12\dagger}) , Deepak Gopinath (^{1\dagger}) , David Qiu (^{1\dagger}) , Dong Lin (^{1}) , Haitian Sun (^{1}) , Saloni Potdar (^{1}) , Bhuwan Dhingra ({1,2})({1}) Apple, (^{2}) Duke University, (^{1}) Work done while at Apple
摘要: 搜索增强型大型语言模型 (LLMs) 通过整合外部检索功能,在知识密集型任务中表现出色。然而,它们经常出现"过度搜索"问题------即在搜索工具无法改善响应质量的情况下,仍然不必要地调用搜索工具,这会导致计算效率低下,并因引入不相关上下文而产生幻觉。在这项工作中,我们对过度搜索进行了系统性评估,涵盖了查询类型、模型类别、检索条件和多轮对话等多个维度。我们的研究结果显示:(i) 搜索通常能提高可回答查询的答案准确性,但会损害无法回答查询的拒绝回答准确性;(ii) 过度搜索在复杂推理模型和深度研究系统中更为明显,会因噪声检索而加剧,并在多轮对话中逐轮累积;(iii) 检索证据的构成至关重要,因为负面证据的存在能显著提高拒绝回答的准确性。为了量化过度搜索,我们引入了"每正确响应的令牌数 (Tokens Per Correctness, TPC)"这一评估指标,用于衡量搜索增强型 LLM 的性能-成本权衡。最后,我们探讨了在查询和检索层面的缓解方法,并发布了 OverSearchQA 基准测试集,以促进对高效搜索增强型 LLM 的持续研究。
通信方式: Roy Xie: ruoyu.xie@duke.edu; Bhuwan Dhingra: bdhingra2@apple.com 数据集: https://github.com/ruoyuxie/OversearchQA 日期: January 12, 2026
1 引言
搜索增强型大型语言模型 (LLMs) 通过整合搜索工具(Li et al., 2025b)中的外部知识,提升了问答能力。通过将响应基于检索到的信息,这些模型在多个知识密集型基准测试中取得了最先进的性能(Google, 2024; OpenAI, 2025a; Kimi et al., 2025)。然而,实际查询通常是带有噪声或无法回答的------模糊、不明确、基于错误前提,或涉及未知事实。在这种情况下,可靠的系统应避免给出明确答案,而应表达不确定性、请求澄清或简单地回答"我不知道"(Kirichenko et al., 2025)。我们研究了搜索增强设置特有的一个失效模式:过度搜索------当调用搜索工具无法改善响应质量时(例如,模型已经知道答案或查询从根本上无法回答),仍然过度调用搜索工具。

图 1 搜索增强型 LLM 中过度搜索的示例。问题询问一个未知的未来事件。与能正确识别并拒绝回答的基础模型相比,搜索增强型 LLM 会启动不必要的搜索,导致额外的成本和潜在的错误答案尝试。
之前的研究主要关注没有工具的基础模型的不确定性和拒绝回答行为,对于外部检索和工具使用训练如何影响模型选择搜索、回答或拒绝回答的方式,仍有待探索。如图 1 所示,经过指令微调的基础模型能够识别问题查询并拒绝回答,而整合搜索工具和推理式微调可能会引发不必要的搜索,从而增加成本,有时还会通过引入误导性上下文而降低质量。
过度搜索现象与模型识别自身知识局限性并适时拒绝回答的能力密切相关(Tomani et al., 2024; Madhusudhan et al., 2024; Wen et al., 2025)。虽然搜索增强提升了模型获取额外知识的能力,但也可能引入"搜索引起的混淆",当证据噪声大或不相关时,损害其拒绝回答的能力。
在这项工作中,我们对各种查询类型(未知答案、错误前提、上下文不明确)、模型类型(基础模型、推理模型、深度研究模型)、检索方式(本地 RAG、网络搜索)和交互模式(单轮和多轮)下的过度搜索进行了系统研究。在大量的实验中,我们发现:(i) 搜索能提高可回答查询的答案准确性,但会损害无法回答查询的拒绝回答准确性;(ii) 过度搜索在推理型模型中、噪声检索条件下以及多轮对话中最为明显,且在多轮对话中像滚雪球一样累积;(iii) 检索证据的构成决定了拒绝回答行为------当检索结果中直接包含负面证据时,能显著提高拒绝回答的准确性。为了量化正确性与计算成本之间的权衡,我们引入了"每正确响应的令牌数 (TPC)"指标。我们探讨了查询级别和检索级别的缓解方法。尽管这两种策略都能在一定程度上缓解过度搜索,但它们未能从根本上解决模型理性搜索的能力不足。最后,我们发布了 OVERSEARCHQA,一个精心策划的基准测试集,以支持对拒绝回答和搜索效率的持续研究。
2 相关工作
推理与工具使用效率。 大型推理模型 (LRMs) 如 OpenAI-o1 (Jaech et al., 2024) 和 DeepSeek-R1 (Guo et al., 2025) 通过强化学习,利用扩展的推理轨迹改进问题解决。工具增强方法通过整合外部 API 和检索系统(Lewis et al., 2020; Gao et al., 2022; Chen et al., 2022)进一步提升了模型能力。最近的工作将工具使用纳入强化学习过程,在整个推理过程中产生多轮工具使用行为(Singh et al., 2025; Jin et al., 2025a; Chen et al., 2025; Song et al., 2025a; Li et al., 2025a)。这些方法通过访问最新的外部信息,显著提高了知识密集型任务的正确性(Kimi et al., 2025),从而实现了强大的深度研究代理(OpenAI, 2025a)。然而,强化学习的目标通常基于最终结果奖励,这鼓励模型在训练期间生成更长的推理过程。这种训练范式经常导致推理效率低下,例如"过度思考"(Sui et al., 2025)。现有工作主要关注 LRMs 中的推理效率(Pu et al., 2025; Hou et al., 2025),而工具使用效率仍未得到充分探索(Wang et al., 2025)。我们的工作旨在同时解决这两方面问题,分析搜索深度和证据质量如何影响工具增强型 LRMs 的效率和拒绝回答行为。
大型语言模型的拒绝回答行为。 拒绝回答已成为一个活跃的研究课题,因为它对于防止 LLMs 产生不正确或误导性响应至关重要。模型必须识别何时应拒绝回答,以避免自信的错误(Wen et al., 2025)。Wen et al. (2024) 的研究表明,许多 LLMs 在面对误导性或不充分的上下文时,"似乎无法拒绝回答"。Kirichenko et al. (2025); Fan et al. (2025) 进一步报告称,推理微调可能会降低拒绝回答的准确性。改善拒绝回答的方法包括通过多模型协作识别知识差距并在特定不确定性阈值下拒绝回答(Feng et al., 2024)。先前的工作深入描述了 LLM 的拒绝回答行为并提出了改进技术,但这些工作都在没有外部工具的静态设置中进行(Kalai et al., 2025; Song et al., 2025b)。同期工作(Ji et al., 2025; Deng et al., 2025)也研究了模糊查询下的搜索增强型 LLM,并探索了用户交互以获取额外上下文。相比之下,我们更关注超越歧义设置的更广泛的无法回答情景,以理解过度搜索行为。
3 评估过度搜索
3.1 定义过度搜索
过度搜索的形式化 我们将过度搜索定义为模型在达到正确结果后仍继续搜索的倾向。在实例层面表征这一点具有挑战性,因为模型可能因错误原因得出正确答案,或者随着检索引入噪声而在正确和不正确状态之间波动。因此,我们分析总体正确性的边际改进相对于计算成本的关系。
形式上,令 D = A ∪ U \mathcal{D} = \mathcal{A} \cup \mathcal{U} D=A∪U 为一个数据集,由两个不相交的集合组成:可回答查询 A \mathcal{A} A 和不可回答查询 U \mathcal{U} U。令 S S S 表示模型采取的搜索操作序列。我们定义正确性指示函数 A ( q , S ) ∈ { 0 , 1 } A(q, S) \in \{0, 1\} A(q,S)∈{0,1},其中 A ( q , S ) = 1 A(q, S) = 1 A(q,S)=1 表示模型正确回答(对于 q ∈ A q \in \mathcal{A} q∈A)或拒绝回答(对于 q ∈ U q \in \mathcal{U} q∈U),否则为 0 0 0。当总体正确性的边际改进,定义为 ∣ D ∣ − 1 ∑ q ∈ D A ( q , S ) |\mathcal{D}|^{- 1} \sum_{q \in \mathcal{D}} A(q, S) ∣D∣−1∑q∈DA(q,S),减小或趋近于零,而计算成本(搜索步骤数)持续累积时,即观察到过度搜索。
过度搜索证据。 为了观察这种行为在实际系统中的表现,我们评估模型在 q ∈ A q \in \mathcal{A} q∈A 和 q ∈ U q \in \mathcal{U} q∈U 上的答案准确性和拒绝回答准确性,并引入"每正确响应的令牌数 (TPC)"指标来衡量每个正确响应的计算成本(§3.2)。当额外的搜索不能提高正确性但仍增加计算量时,TPC 会上升,使其成为过度搜索的有用信号。图 2 显示了使用 o4-mini (OpenAI, 2025b) 的一个示例。随着最大允许搜索轮次从 0 增加到 19,答案准确性在早期上升,然后趋于平稳,拒绝回答准确性随着搜索的增加而下降,而 TPC 稳步上升。这种模式表明模型通常在搜索不再有帮助之后仍然继续搜索。更多图表可在附录图 7 中找到。为了进一步展示过度搜索,我们从最优搜索轮次比较(附录 A.1)和边际回报(附录 A.2)两个替代视角分析了过度搜索。
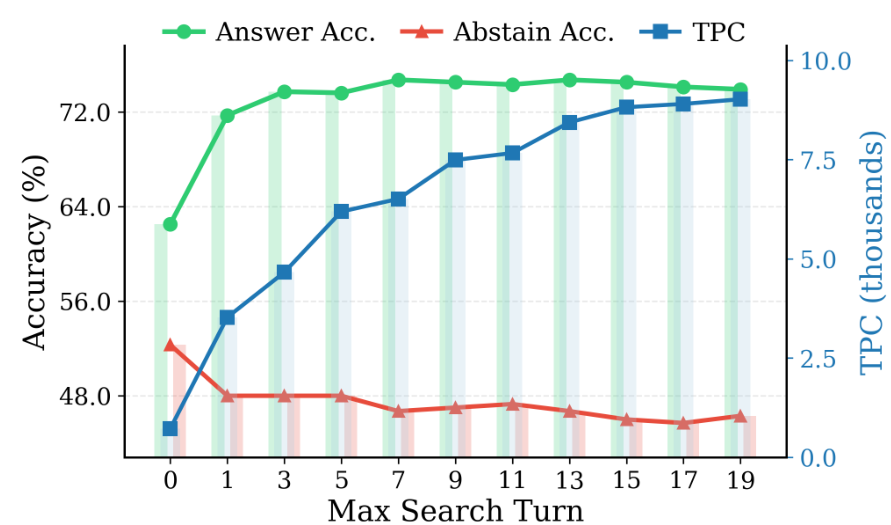
图 2 o4-mini 在最大搜索轮次从 0 增加到 19 时的性能。答案准确性(针对可回答查询)从无搜索到一次搜索显著提高,随后在约 7 次搜索后达到峰值并趋于平稳。拒绝回答准确性(针对不可回答查询)随着搜索次数的增加而持续下降。与此同时,TPC 单调上升,这表明存在过度搜索:成本累积速度快于正确性收益,因为额外的搜索既没有提高答案准确性,也没有阻止拒绝回答准确性的下降。
3.2 测量过度搜索
双重准确率。 遵循 Kirichenko et al. (2025) 的定义,我们认为拒绝回答是一种有意不直接回答查询的响应,例如,通过承认知识有限、表达不确定性或必要的注意事项,或指出查询无法回答。这个概念包括简短的拒绝(例如,"我不知道")以及仅提供澄清或部分信息而不给出确定答案的响应。为了实现这一概念,我们报告:(i) 在可回答查询 q ∈ A q \in \mathcal{A} q∈A 上计算的答案准确率,衡量正确答案的比例;以及 (ii) 在不可回答查询 q ∈ U q \in \mathcal{U} q∈U 上计算的拒绝回答准确率,衡量正确拒绝回答的比例(即当模型适当地拒绝回答时, A ( q , S ) = 1 A(q, S) = 1 A(q,S)=1)。详细指标定义请参见附录 B.1。
每正确响应的令牌数 (Tokens Per Correctness, TPC)。 搜索增强型 LLM 会产生异构成本,包括生成的令牌、输入上下文和搜索调用。然而,标准指标忽略了这些细微的成本。我们引入"每正确响应的令牌数 (TPC)",定义为每个正确响应的预期计算成本(越低越好):
T P C ( D ) = ∑ q ∈ D C o s t ( q ) ∑ q ∈ D C o r r e c t ( q ) , ( 3.1 ) \mathrm{TPC}(\mathcal{D}) = \frac{\sum_{q\in\mathcal{D}}\mathrm{Cost}(q)}{\sum_{q\in\mathcal{D}}\mathrm{Correct}(q)}, \quad (3.1) TPC(D)=∑q∈DCorrect(q)∑q∈DCost(q),(3.1)
其中 C o s t ( q ) = g q + λ x q + μ ∣ S q ∣ \mathrm{Cost}(q) = g_{q} + \lambda x_{q} + \mu |S_{q}| Cost(q)=gq+λxq+μ∣Sq∣,代表查询 q q q 的总计算成本。 g q g_{q} gq 是模型生成的令牌数, x q x_{q} xq 是输入令牌数(包括原始提示和所有检索到的上下文),具有成本系数 λ \lambda λ,而 ∣ S q ∣ |S_{q}| ∣Sq∣ 是查询 q q q 的搜索调用次数,具有成本系数 μ \mu μ。Correct ( q ) ∈ { 0 , 1 } (q) \in \{0, 1\} (q)∈{0,1} 对于可回答和不可回答查询的定义不同:
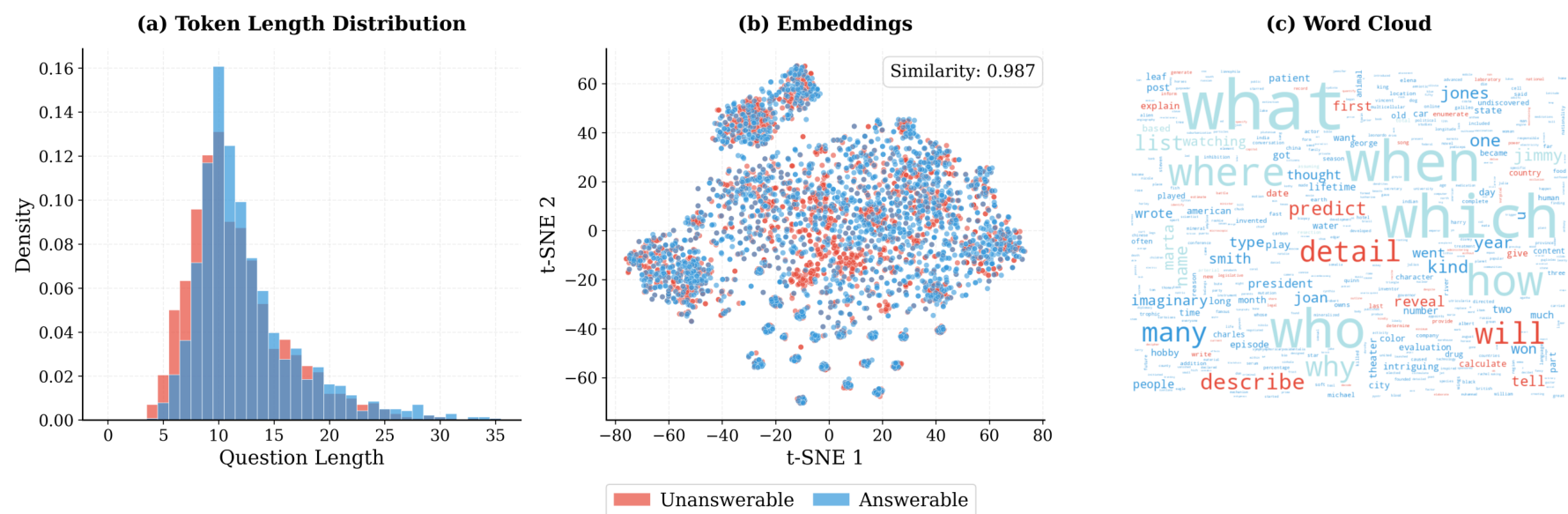
图 3 (a) 长度分布显示可回答和不可回答问题之间具有相似的令牌计数。(b) 问题嵌入的 t-SNE 可视化揭示了实质性的语义重叠,表明可回答和不可回答问题在语义上是无法区分的。类别特定的相似性细分显示在附录图 9 中。© OVERSEARCHQA 中可回答和不可回答问题的词云。
Correct ( q ) = 1 (q) = 1 (q)=1 如果模型在 q ∈ A q \in \mathcal{A} q∈A 时正确回答,或者在 q ∈ U q \in \mathcal{U} q∈U 时正确拒绝回答;否则 Correct ( q ) = 0 (q) = 0 (q)=0。当没有示例被正确回答时 ( ∑ q ∈ D Correct ( q ) = 0 ) \left(\sum_{q \in \mathcal{D}} \text{Correct} (q) = 0\right) (∑q∈DCorrect(q)=0),我们定义 TPC ( D ) = + ∞ \text{TPC}(\mathcal{D}) = +\infty TPC(D)=+∞。为了确保 TPC 分数在不同系统之间具有可比性,我们使用具有固定系数的标准化成本。我们将输入令牌成本 λ \lambda λ 设置为 0.25 0.25 0.25,每次搜索调用成本 μ \mu μ 设置为 500 500 500,这两个值均基于生产 LLM 和搜索 API 调用的典型定价(参见附录 B.2 获取成本模型详情)。降低 TPC 对应于减少过度搜索,因为它反映了以更少的令牌实现正确性。在这项工作中,TPC 专门为本研究中的搜索工具设计。然而,它可以通过将成本与特定工具关联起来,轻松扩展到其他工具增强场景。我们还在附录 B.3 中将 TPC 与其他指标进行了比较。
大型语言模型裁判评估。 先前的工作通常依赖于词汇或语义相似性(Yin et al., 2023b; Amayuelas et al., 2024)进行拒绝回答评估,这无法捕捉广泛拒绝回答类别中的细微行为。遵循 Wen et al. (2024); Kirichenko et al. (2025) 的方法,我们使用一个语言模型裁判来评估答案准确率和拒绝回答准确率。对于可回答的查询,裁判将模型输出与真实答案进行比较。对于不可回答的查询,裁判评估模型是否适当地拒绝回答。为确保鲁棒性,我们评估了三个独立裁判之间的一致性,发现具有高度的裁判间一致性:答案准确率的总体一致性为 89.4 % 89.4\% 89.4%,拒绝回答准确率的总体一致性为 92.3 % 92.3\% 92.3%(附录 C.1)。此外,我们通过人工标注验证了裁判的决定,观察到 84 % 84\% 84% 的强对齐率(附录 C.2)。除非另有说明,我们使用 GPT-4o-mini (Hurst et al., 2024) 作为默认裁判。
4 实验设置
OverSearchQA。 现有数据集通常在可回答的查询上评估搜索增强型 LLM,但缺乏用于拒绝回答评估的基准测试。我们提出了 OVERSEARCHQA,一个精心策划的、以拒绝回答为中心的问答基准测试集,包含 1,188 个查询(可回答/不可回答平衡),专为搜索增强型 LLM 设计。数据集构建分为三个阶段:(i) 从源数据集中手动筛选出不可回答问题;(ii) 进行相似性搜索(并控制长度)以从 HotpotQA (Yang et al., 2018)、SimpleQA (Wei et al., 2024) 和 Natural Questions (Kwiatkowski et al., 2019) 等可回答问答数据集中找到对应的可回答问题;(iii) 对可回答问题进行验证以确保质量和平衡。为了将过度搜索归因于实际问题类型(例如,可回答或不可回答)而非数据集中的伪影,我们从相似的嵌入邻域中抽取可回答和不可回答的项目,并明确控制每个类别中的问题长度。图 3 展示了我们过滤过程的有效性,显示了所有类别中可回答和不可回答问题之间相似的长度分布和高度的语义相似性。完整的策划细节和统计数据请参见附录 D。
| Category | Seed Datasets | Example | Total |
|---|---|---|---|
| Answer Unknown (AU) | CoCoNot (Brahman et al., 2024); Big-Bench (Parrish et al., 2022); KUQ (Amayuelas et al., 2024) | Unanswerable: "Who won the 2030 World Cup in football?" Answerable: "Where was the last world cup held?" (Qatar) | 281 |
| CoCoNot (Brahman et al., 2024); FalseQA (Hu et al., 2023); QAQA (Kim et al., 2023) | Unanswerable: "How many eggs do tigers lay?" Answerable: "How many cubs does a tiger give birth to?" (2-4 cubs) | 365 | |
| Underspecified Context (UC) | CoCoNot (Brahman et al., 2024); ALCUNA (Yin et al., 2023a); MediQ (Li et al., 2024); WorldSense (Benchekroun et al., 2023) | Unanswerable: "What is the capital of Georgia?" Answerable: "What is the capital of the country of Georgia?" (Tbilisi) | 512 |
根据 Kirichenko et al. (2025) 的分类,我们基于以下三类创建了 OVERSEARCHQA:未知答案 (AU) - 未来事件和未解决问题;错误前提 (FP) - 不正确假设或矛盾主张;以及 上下文不明确 (UC) - 意图模糊或缺少信息需要澄清。表 1 显示了简洁的类别摘要。
模型。 我们评估了多种模型中的过度搜索行为,包括开源模型和基于 API 的模型:GPT-4o-mini (Hurst et al., 2024)、Kimi-K2 (Kimi et al., 2025)、Qwen3-235B-Instruct (Yang et al., 2025)、Llama-3.2-3B (Grattafiori et al., 2024)、Llama-3.3-70B (Grattafiori et al., 2024)、Mistral-Small-24B (Mistral, 2025)、o4-mini (OpenAI, 2025b)、Qwen3-235B-Thinking (Yang et al., 2025)、Hermes3-3B (Teknium et al., 2024) 和 o4-mini-deep-research (OpenAI, 2025a)。每个模型都在有和没有搜索增强的情况下进行评估,以隔离搜索对拒绝回答行为的影响。深度研究系统默认启用搜索,结果在图 4 中单独报告。对于推理模型(o4-mini 和 Qwen3-235B-Thinking),推理工作量设置为默认值。为了确保所有搜索增强模型之间的公平比较,我们保持了相同的检索基础设施,例如 top-k 检索文档和检索器。除非另有说明,我们使用 Wikipedia (enwiki-20250801) 和 E5-base (Wang et al., 2022) 作为默认检索器。模型被允许每查询最多进行 10 次搜索调用。我们将在 §5.2 中比较不同的检索源。完整的设置详情在附录 E 中提供。
5 结果
5.1 搜索增强损害拒绝回答能力
搜索改善答案准确率但降低拒绝回答准确率。 表 2 显示,虽然引入搜索提高了可回答问题的准确率,但它同时损害了模型对不可回答问题的拒绝回答能力,使答案准确率平均提高了 24.0 % 24.0\% 24.0%,但拒绝回答准确率下降了 12.8 % 12.8\% 12.8%。这种负面影响在"上下文不明确"问题上最为显著,模型试图为从根本上无法回答的查询寻找支持证据。相反,当明确提供这些相同问题所缺失的上下文时,模型能达到更高的答案准确率。三类问题的详细案例研究可在附录 H 中找到。
推理和模型复杂性加剧过度搜索。 为了理解推理和模型复杂性的影响,我们分析了 o4-mini 上不同推理工作量的影响。表 3 显示,虽然增加推理能力持续提高答案准确率,但却降低了拒绝回答准确率。TPC 随着推理工作量的增加而单调上升,表明更深层次的推理可能会鼓励模型过度搜索。此外,图 4 展示了同一模型家族在不同配置下的这种权衡:
| Metric | Low | Medium | High |
|---|---|---|---|
| Ans. Acc | 74.1 | 74.3 | 74.6 |
| Abst. Acc | 46.6 | 46.2 | 45.4 |
| Overall Acc | 60.4 | 60.3 | 60.0 |
| TPC | 517.1 | 1002.7 | 1492.2 |
表 3 不同推理工作量水平对 o4-mini 的影响。答案准确率随着推理工作量的增加而提高,但拒绝回答准确率下降。TPC 随着推理工作量的增加而单调上升。
| Model | Answer Unknown | False Premise | Underspecified Context | Overall |
|---|---|---|---|---|
| Ans. Abst. TPC | Ans. Abst. TPC | Ans. Abst. TPC | Ans. Abst. TPC | |
| Without Search | ||||
| GPT-4o-mini | 41.8 65.8 157.3 | 54.7 67.4 105.9 | 76.1 27.2 264.9 | 57.5 53.5 176.0 |
| o4-mini | 46.6 65.1 820.2 | 57.8 65.3 722.3 | 83.2 26.6 623.3 | 62.5 52.3 721.9 |
| Kimi-K2 | 49.0 63.0 255.8 | 58.3 63.2 101.6 | 79.2 23.8 306.3 | 62.2 50.0 221.2 |
| Qwen3-235B-Instruct | 47.2 64.8 268.2 | 55.7 69.3 180.0 | 79.3 24.2 395.2 | 60.7 52.8 281.1 |
| Qwen3-235B-Think | 50.0 64.4 1155.2 | 57.3 63.5 1039.1 | 79.4 31.9 1159.8 | 62.2 53.3 1118.0 |
| Hermes3-3B | 17.1 80.5 91.7 | 24.0 83.4 60.6 | 53.5 32.2 212.4 | 35.0 60.8 133.0 |
| Llama-3.2-3B | 27.4 57.5 255.6 | 41.1 77.7 146.6 | 61.3 25.4 320.8 | 43.3 53.5 241.0 |
| Llama-3.3-70B | 46.6 59.6 338.4 | 56.2 68.4 177.6 | 76.5 28.0 355.7 | 59.8 52.0 290.6 |
| Mistral-Small-24B | 40.4 64.6 257.5 | 52.1 67.9 173.0 | 75.8 29.7 327.5 | 56.1 54.1 252.7 |
| Average | 40.7 65.0 399.9 | 50.8 69.6 300.7 | 73.8 27.7 440.6 | 55.5 54.7 381.9 |
| With Search | ||||
| GPT-4o-mini | 63.0 62.3 942.4 | 67.2 61.1 777.1 | 84.8 19.5 762.9 | 71.7 47.6 827.5 |
| o4-mini | 63.4 64.4 1031.8 | 68.8 60.0 1155.3 | 87.5 23.3 871.3 | 73.2 49.2 1019.5 |
| Kimi-K2 | 64.4 61.6 851.8 | 67.7 65.8 565.9 | 85.5 24.2 553.0 | 72.5 50.5 656.9 |
| Qwen3-235B-Instruct | 64.4 66.9 923.0 | 66.7 68.2 652.1 | 85.2 22.3 859.5 | 72.1 52.5 811.5 |
| Qwen3-235B-Think | 63.7 64.8 1292.9 | 69.3 65.1 1245.1 | 85.5 23.7 1338.9 | 72.8 51.2 1292.3 |
| Hermes3-3B | 45.9 35.6 493.4 | 56.8 33.7 560.6 | 57.0 13.2 369.2 | 54.2 27.5 461.9 |
| Llama-3.2-3B | 58.2 61.6 717.8 | 60.9 64.2 681.3 | 73.4 21.5 804.7 | 64.2 49.1 734.6 |
| Llama-3.3-70B | 62.3 62.3 731.5 | 68.2 62.7 685.2 | 83.5 20.6 834.7 | 71.3 48.5 750.5 |
| Mistral-Small-24B | 56.8 64.1 329.2 | 62.5 65.3 246.5 | 83.2 30.1 414.0 | 67.5 53.2 329.9 |
| Average | 60.2 60.4 812.6 | 65.3 60.7 729.9 | 80.6 22.0 756.5 | 68.8 47.7 765.0 |
表 2 不同查询类型下的过度搜索行为。搜索增强始终提高答案准确率,但降低拒绝回答准确率,其中"上下文不明确"问题的退化最为严重。
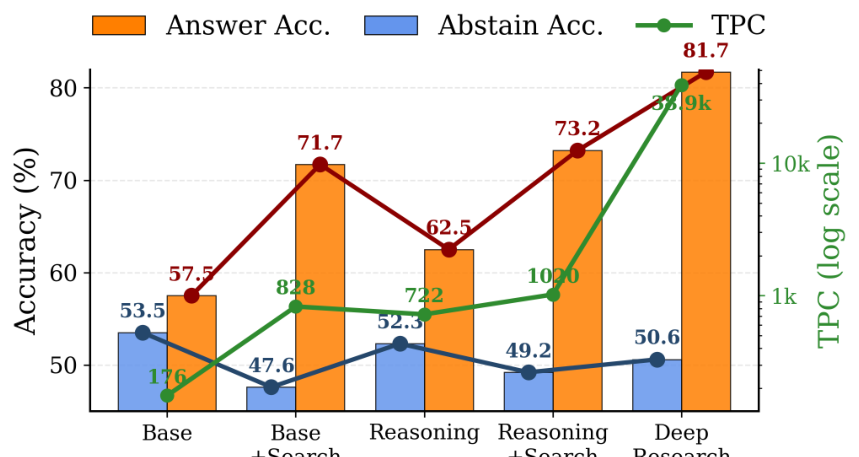
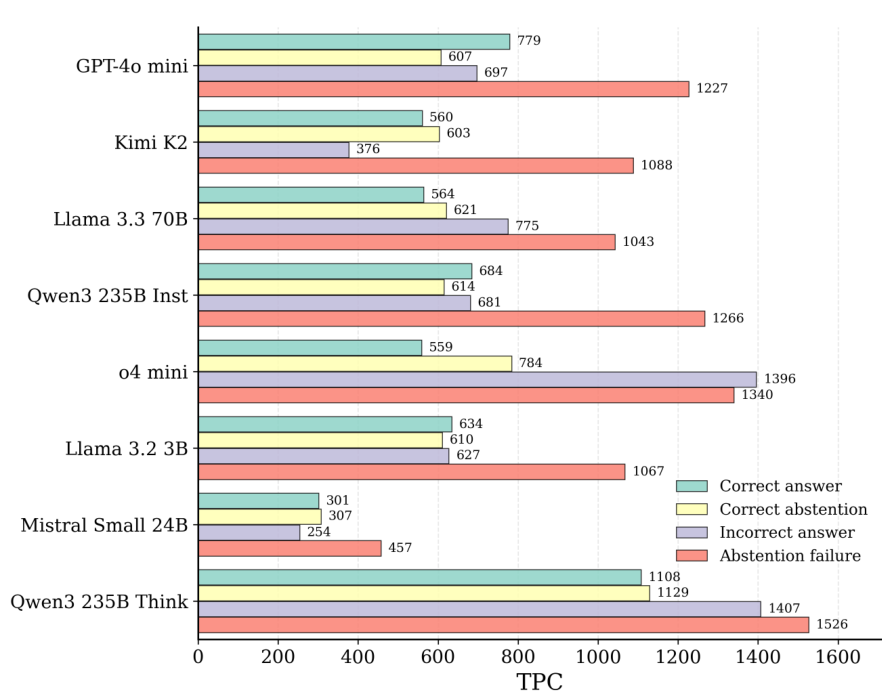
图 4 同一模型家族在不同配置下的比较:(GPT-4o-mini)、推理(o4-mini)和深度研究(o4-mini-deep-research)。随着配置变得更加复杂,答案准确率提高,而拒绝回答准确率持续下降。TPC(以对数刻度显示)随着搜索能力的增强而增加;深度研究配置的 TPC 惊人地达到 38.9k,是基础配置的 221 倍以上。
拒绝回答失败成本最高。 我们通过按结果类别分解 TPC 进一步分析。图 5 显示,对于大多数模型而言,拒绝回答失败(即回答无法回答的查询)仍然是最高的 TPC,在这种情况下,模型反复对根本无法回答的查询进行搜索,累积了更大的成本而未能实现正确性。
| Model | Wikipedia-Latest | Wikipedia-Stale | C5 | Web Search |
|---|---|---|---|---|
| Ans. Abst. TPC | Ans. Abst. TPC | Ans. Abst. TPC | Ans. Abst. TPC | |
| GPT-4o-mini | 71.7 47.6 827.5 | 71.0 46.2 1124.1 | 69.3 48.8 2350.6 | 71.0 47.6 645.2 |
| o4-mini | 73.2 49.2 1019.5 | 72.7 46.7 1170.3 | 72.4 48.2 3311.7 | 74.4 47.0 1239.3 |
| Kimi-K2 | 72.5 50.5 656.9 | 71.9 49.1 904.2 | 71.7 50.9 3147.9 | 73.2 45.8 741.3 |
| Qwen3-235B-Instruct | 72.1 52.5 811.5 | 72.9 49.7 997.4 | 71.2 51.8 3794.1 | 74.1 47.0 1165.4 |
| Mistral-Small-24B | 67.5 53.2 329.2 | 66.9 50.2 428.9 | 65.4 51.7 1486.9 | 68.4 47.5 684.1 |
| Llama-3.3-70B | 71.3 48.5 750.5 | 71.2 45.7 776.8 | 70.5 48.9 1548.8 | 72.7 44.1 936.9 |
| Average | 71.4 50.2 732.5 | 71.1 47.9 900.3 | 70.1 50.1 2606.7 | 72.3 46.5 902.0 |
表 4 检索质量对过度搜索行为的影响。噪声检索 (C5) 导致模型执行额外的搜索,显著增加了 TPC。
| GPT-4o-mini | o4-mini | Qwen3-235B | Kimi-K2 | Llama3.3-70B | Mistral-Small-24B | |
|---|---|---|---|---|---|---|
| Acc. Evid. | Acc. Evid. | Acc. Evid. | Acc. Evid. | Acc. Evid. | Acc. Evid. | |
| Only Positive | 18.0 0.0 | 16.3 0.0 | 17.4 0.0 | 19.6 0.0 | 17.0 0.0 | 16.2 0.0 |
| Pos≥Neg | 56.7 32.5 | 57.1 32.9 | 41.3 32.8 | 36.0 31.2 | 55.9 33.3 | 54.9 33.1 |
| Neg>Pos | 73.8 67.5 | 74.4 67.1 | 83.9 68.2 | 72.4 68.8 | 77.6 66.7 | 75.1 66.9 |
| Only Negative | 91.1 100.0 | 89.4 100.0 | 98.6 100.0 | 92.9 100.0 | 92.6 100.0 | 89.7 100.0 |
表 5 根据自然检索到的证据平衡,对不可回答查询的拒绝回答准确率。行表示按在推理过程中自然检索到的正面证据与负面证据的平衡分类的查询。"Evid."列显示了每个类别中的查询百分比。模型在只有负面证据时几乎能完美拒绝回答,但当正面证据占主导时,拒绝回答能力急剧下降。
5.2 检索问题
嘈杂的检索导致更多的搜索。 为了理解语料库质量如何影响过度搜索,我们比较了四种检索源:(i) Wikipedia-Latest,最新且最可靠的文档来源(2025年数据);(ii) Wikipedia-Stale,使用过时的维基百科快照(2018年数据);(iii) C5,来自Vanroy (2025)的嘈杂语料库,其中移除了维基百科内容;以及 (iv) Web Search,真实的在线搜索。检索设置的更多细节在附录E.2中提供。
表4显示语料库质量对过度搜索有显著影响。C5的TPC(每正确答案的token数)比Wikipedia-Latest高出3.6倍,这表明当检索质量较差时,模型会进行更多的搜索。有趣的是,C5也取得了第二好的弃权准确率,这暗示持续差的检索可能反常地帮助模型识别问题不可回答性。Web Search取得了最佳的回答准确率,但弃权准确率较低。这可能是因为它能访问整个互联网,搜索结果可能直接包含问题的答案,而来自不同网络来源的混合信号过多,使得模型难以识别问题何时不可回答。这反映了真实世界检索环境的挑战,其中不可控和混合信号会使弃权决策复杂化。
弃权线索稀少。 现实世界的语料库绝大多数记录了我们已知的信息,而非我们未知的信息。这种不对称性可能造成一种基本偏差,即模型将根本性的不可知性解释为搜索努力不足。我们进行了实验来理解检索文档的性质以及这种偏差是否影响弃权行为。我们使用一个LLM判断器将自然检索到的文档分类为:包含支持答案证据的积极文档(对于不可回答的查询,这意味着误导性信息),以及指示不可回答性的消极文档(例如,不确定性陈述、矛盾)。我们根据其自然检索到的证据平衡来分组不可回答的查询。表5显示,当只存在消极证据时,模型能达到近乎完美的弃权,但当积极证据占主导地位时,性能急剧下降。然而,对于不可回答的查询,消极文档仅占检索内容的13-22%(表10),这导致了弃权行为的缺乏。分类过程的详细信息可在附录F.1中找到。
5.3 多轮对话中的雪球效应
我们研究了多轮对话设置如何影响模型的弃权能力。我们构建了1-9轮的对话,其中最后一轮的查询固定用于评估。我们评估了三种对话情境:(i) 不可回答情境,所有前几轮都包含不可回答的问题;(ii) 混合情境,可回答和不可回答问题随机混合;以及(iii) 可回答情境,所有前几轮都包含可回答的问题。下图展示了GPT-4o-mini的结果。对于不可回答情境,随着对话轮次的增加,弃权准确率保持相对稳定,甚至略有提高,这表明重复接触不可回答的查询和潜在的弃权有助于模型保持弃权模式。相比之下,可回答和混合情境的弃权准确率有所下降,这表明之前的可回答问题会使模型偏向于尝试回答。同时,对于所有情境,TPC都随着对话长度的增加而增加。这些发现揭示了一种雪球效应,模型会延续早期轮次积累的搜索模式------不可回答问题的历史会鼓励弃权,而可回答问题的历史会鼓励尝试回答。
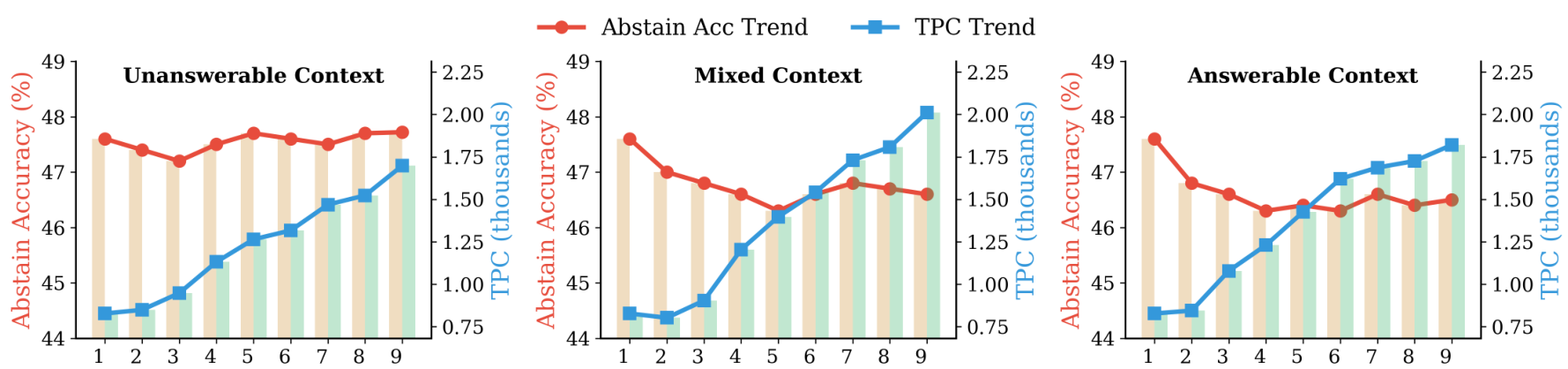
图6 多轮对话放大了过度搜索行为。不可回答情境下的弃权准确率保持稳定,甚至在轮次增加时略有改善,而可回答情境下的弃权降级最为严重。对于所有情境,TPC都随着对话长度的增加而增加。
5.4 缓解过度搜索
我们探索了两种无需训练的过度搜索缓解策略:查询级别缓解(Query-Level Mitigation),旨在改进系统提示和工作流设计;以及检索级别缓解(Retrieval-Level Mitigation),旨在通过增强语料库中的负面证据来促进弃权。
查询级别缓解。 我们评估了三种基于提示的方法:(1) 弃权感知(Abstention-aware) ,明确指示模型在查询不可回答时考虑弃权作为有效响应;(2) 少样本学习(Few-shot learning) ,在系统提示中提供适当弃权行为的示例;以及 (3) 自我评估(Self-evaluation),引入一个自我评估阶段,模型在回答前评估查询的可回答性。表6显示,所有这三种方法都显著提高了弃权准确率,平均提升了11.5个百分点。少样本学习取得了最强的弃权改进,但导致了最大的回答准确率下降,这表明明确的示例可能使模型偏向于过度弃权。自我评估在弃权方面取得了平衡的改进,回答准确率损失适中,但由于额外的推理和自我评估可能需要的搜索,它表现出更高的TPC。虽然查询级别的干预可以减少过度搜索,但它们在回答准确率、弃权行为和计算成本之间引入了不同的权衡。所有策略的提示模板在附录G中提供。
检索级别缓解。 表5显示,当存在负面证据时,弃权能力会提高。因此,我们通过在语料库中为所有查询插入10个合成的负面证据文档来评估语料库增强在缓解过度搜索方面的效果(更多细节见附录F.2)。表6显示,弃权准确率只有适度的提高(平均3.6%)。这种有限的有效性可能源于:(i) 合成文档在检索中排名不佳;(ii) 负面证据被大量自然存在的正面文档稀释。尽管负面证据在被检索到时有所帮助,但有效的检索级别缓解需要系统的架构改变,这将在未来的工作中进行探索。
|---------------------|------|-------|--------|------|-------|-------|------|-------|-------|------|-------|-------|------|-------|-------|
| Model | Baseline ||| Abstention-aware ||| Few-shot ||| Self-eval ||| Corpus Aug. |||
| Model | Ans. | Abst. | TPC | Ans. | Abst. | TPC | Ans. | Abst. | TPC | Ans. | Abst. | TPC | Ans. | Abst. | TPC |
| GPT-4o-mini | 71.7 | 47.6 | 827.5 | 69.7 | 53.2 | 346.8 | 67.5 | 67.1 | 270.0 | 65.6 | 63.1 | 545.8 | 71.2 | 50.7 | 843.6 |
| o4-mini | 73.2 | 49.2 | 1019.5 | 72.7 | 52.5 | 852.8 | 72.2 | 59.8 | 792.5 | 71.9 | 57.4 | 973.9 | 72.8 | 53.0 | 962.3 |
| Kimi-K2 | 72.5 | 50.5 | 656.9 | 71.9 | 62.3 | 474.4 | 72.2 | 67.5 | 542.3 | 72.4 | 62.5 | 656.8 | 71.9 | 54.7 | 665.2 |
| Qwen3-235B-Instruct | 72.1 | 52.5 | 811.5 | 72.6 | 68.8 | 677.4 | 72.1 | 59.9 | 853.5 | 70.4 | 61.8 | 774.5 | 71.6 | 56.6 | 823.1 |
| Mistral-Small-24B | 67.5 | 53.2 | 329.9 | 66.8 | 58.4 | 285.3 | 66.2 | 60.8 | 312.7 | 67.1 | 60.2 | 318.5 | 67.3 | 55.9 | 341.2 |
| Llama-3.3-70B | 71.3 | 48.5 | 750.5 | 65.8 | 65.7 | 691.1 | 67.5 | 65.0 | 730.3 | 71.9 | 63.9 | 713.9 | 70.8 | 52.1 | 782.9 |
| Average | 71.4 | 50.2 | 732.6 | 69.9 | 60.2 | 554.8 | 69.6 | 63.4 | 583.6 | 69.9 | 61.5 | 663.9 | 70.9 | 53.8 | 736.4 |
表6 缓解过度搜索策略的评估。查询级别方法(Abstention-aware, Few-shot, Self-eval)修改了系统提示,而检索级别方法(Corpus Aug.)通过合成负面证据文档增强了语料库。
6 结论
在这项工作中,我们进行了全面的评估,并展示了搜索增强型大型语言模型(LLMs)中的"过度搜索"行为,即不必要地调用搜索工具,导致计算成本增加和响应质量可能下降。我们的系统评估揭示了一个根本性的权衡:虽然搜索提高了可回答查询的准确性,但它损害了模型对不可回答查询的弃权能力。这种现象在推理模型、复杂系统、嘈杂检索以及搜索行为可能呈雪球效应的多轮对话中尤为突出。我们引入了每正确答案的token数(TPC)指标来量化这种低效率,并表明搜索结果中的负面证据显著改善了弃权行为。我们评估了查询级别和检索级别的缓解策略,发现尽管两者都能在一定程度上帮助缓解过度搜索,但它们并未解决模型理性搜索能力的根本性缺陷。最后,我们发布了OVERSEARCHQA,以促进对改进工具增强型LLMs中搜索效率和弃权能力的持续研究。
7 局限性
在这项工作中,我们专注于全面评估和分析过度搜索行为。我们研究了几种无需训练的缓解策略;然而,其他有前景的方向仍然存在,包括有针对性的模型训练和对检索系统的架构修改。我们将这些方面留待未来探索。此外,OVERSEARCHQA中的不可回答查询是从现有基准中筛选出来的,而非从真实世界的搜索日志中收集。虽然这使我们能够将模型的决策失败与检索失败等混杂因素隔离开来,但它可能无法反映部署中不可回答查询的分布,并且可能已经过时。真实世界的用户查询可能表现出不同的语言模式或不可回答类型,这些并未被我们的类别完全捕捉。最后,尽管我们评估了查询级别和检索级别的缓解措施,但我们发现它们仅提供了适度的改进,这表明要解决模型无法理性搜索的问题可能需要进行后期训练或对齐阶段的干预。
Original Abstract: Search-augmented large language models (LLMs) excel at knowledge-intensive tasks by integrating external retrieval. However, they often over-search -- unnecessarily invoking search tool even when it does not improve response quality, which leads to computational inefficiency and hallucinations by incorporating irrelevant context. In this work, we conduct a systematic evaluation of over-searching across multiple dimensions, including query types, model categories, retrieval conditions, and multi-turn conversations. Our finding shows: (i) search generally improves answer accuracy on answerable queries but harms abstention on unanswerable ones; (ii) over-searching is more pronounced in complex reasoning models and deep research systems, is exacerbated by noisy retrieval, and compounds across turns in multi-turn conversations; and (iii) the composition of retrieved evidence is crucial, as the presence of negative evidence improves abstention. To quantify over-searching, we introduce Tokens Per Correctness (TPC), an evaluation metric that captures the performance-cost trade-off for search-augmented LLMs. Lastly, we investigate mitigation approaches at both the query and retrieval levels and release the OverSearchQA to foster continued research into efficient search-augmented LLMs.
PDF Link: 2601.05503v1
部分平台可能图片显示异常,请以我的博客内容为准
