
引言
AI是现在的潮流,我也试着收集了一些资料,分享一下,也是了解了解ai前言的东西~
自 ChatGPT 掀起全球 AI 浪潮以来,大模型(Large Models)已成为人工智能领域的核心支柱,其能力边界不断拓展,从自然语言处理到计算机视觉,从单一任务适配到跨场景通用,深刻重塑了技术研发范式与产业应用逻辑。大模型的规模化发展带来了能力的跃升,但也面临着计算成本激增、多模态数据融合不彻底等核心挑战。在此背景下,稀疏 MoE(Mixture of Experts)与原生多模态双驱动技术应运而生,成为突破大模型性能瓶颈、拓展应用场景的关键方向。
MoE(混合专家模型)核心思想是将模型拆分为多个"专家"子网络,通过门控机制动态激活部分专家处理输入数据,实现"算力按需分配";而多模态学习则聚焦于跨越文本、图像、音频等不同数据模态的语义鸿沟,让模型具备更全面的感知与理解能力。两者的深度融合与协同发展,正推动大模型从"单一模态规模化"向"多模态高效化"演进。本文将深入探讨稀疏 MoE 与原生多模态双驱动的核心原理、技术进展,并结合实际代码与流程图具象化展示关键实现,最终展望 2025 年相关技术的发展趋势及其对各行业的深远影响。
第一部分:理解稀疏 MoE
1.1 稀疏 MoE 的定义与工作原理
稀疏 MoE(Sparse Mixture of Experts)是 MoE 模型的优化形态,其核心定义是:通过构建多个专业化的"专家网络"(Expert Network)和一个"门控网络"(Gating Network),使模型在处理每一个输入样本时,仅激活全部专家中的一小部分(通常为 10%-20%)完成计算,而非激活整个模型,从而在保证模型参数规模的同时,显著降低计算开销。
其工作流程可拆解为三个核心步骤:① 输入编码:将原始输入(如文本 Token、图像特征)转换为统一维度的特征向量;② 门控选择:门控网络基于输入特征计算每个专家的激活权重,筛选出权重最高的 K 个专家(K 为超参数,通常取 1-4);③ 专家计算与融合:被选中的 K 个专家分别对输入特征进行处理,门控网络输出的权重对专家结果进行加权求和,得到最终输出。
与传统稠密模型相比,稀疏 MoE 的核心优势在于"参数复用"与"算力稀疏"的平衡。传统稠密模型的所有参数对每个输入都参与计算,导致参数规模扩大时计算成本呈线性增长;而稀疏 MoE 中大量专家参数处于"休眠"状态,仅在匹配输入时被激活,使得模型可通过增加专家数量提升容量,却无需同步增加计算量,实现了"大参数规模"与"高效推理"的兼得。
1.2 稀疏 MoE 相比传统模型的优势
除了核心的"高效算力利用"外,稀疏 MoE 还具备以下显著优势:
- 更强的任务适配性:不同专家可通过训练适配不同类型的输入或任务(如部分专家专注处理语法结构,部分专注语义理解),门控网络动态匹配输入与专家,提升模型在复杂场景下的泛化能力;
- 更低的训练门槛:相较于同等参数规模的稠密模型,稀疏 MoE 可在单卡或小规模集群上完成训练,降低了大模型研发的硬件门槛;
- 更好的可扩展性:通过横向增加专家数量,可灵活提升模型容量,而无需重构模型架构,适配从中小规模到超大规模的不同应用需求。
1.3 稀疏 MoE 的 PyTorch 实现示例
以下实现一个简单的稀疏 MoE 层,包含 8 个专家网络(单层全连接)和一个简单的门控网络(线性层),每次激活 2 个专家:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SparseMoELayer(nn.Module):
def __init__(self, input_dim: int, output_dim: int, num_experts: int = 8, top_k: int = 2):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_experts = num_experts
self.top_k = top_k
# 定义专家网络:num_experts 个全连接层,共享输入输出维度
self.experts = nn.ModuleList([
nn.Linear(input_dim, output_dim) for _ in range(num_experts)
])
# 门控网络:输入特征 -> 每个专家的权重
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: [batch_size, input_dim]
batch_size = x.shape[0]
# 1. 门控网络计算专家权重,并筛选 top-k 专家
gate_weights = self.gate(x) # [batch_size, num_experts]
top_k_weights, top_k_indices = torch.topk(gate_weights, k=self.top_k, dim=1) # 权重和索引:[batch_size, top_k]
top_k_weights = F.softmax(top_k_weights, dim=1) # 归一化权重
# 2. 收集 top-k 专家的输出
output = torch.zeros(batch_size, self.output_dim, device=x.device)
for i in range(batch_size):
for k in range(self.top_k):
expert_idx = top_k_indices[i, k]
expert_output = self.experts[expert_idx](x[i].unsqueeze(0)) # [1, output_dim]
output[i] += top_k_weights[i, k] * expert_output.squeeze(0)
return output
# 测试代码
if __name__ == "__main__":
moe_layer = SparseMoELayer(input_dim=128, output_dim=128, num_experts=8, top_k=2)
test_input = torch.randn(32, 128) # 32个样本,每个样本128维特征
output = moe_layer(test_input)
print(f"输入形状: {test_input.shape}")
print(f"输出形状: {output.shape}") # 输出形状应与输入批次一致:[32, 128]
# 统计激活的专家数量占比
gate_weights = moe_layer.gate(test_input)
top_k_indices = torch.topk(gate_weights, k=2, dim=1)
activated_experts = torch.unique(top_k_indices)
print(f"激活的专家数量: {len(activated_experts)}/{moe_layer.num_experts}")上述代码实现了稀疏 MoE 的核心逻辑:通过门控网络筛选 top-k 专家,加权融合专家输出。实际工业级实现(如 Google 的 Switch Transformer)会在此基础上优化,包括专家负载均衡、分布式训练、梯度裁剪等机制,提升模型稳定性与训练效率。
第二部分:探索原生多模态双驱动
2.1 原生多模态双驱动的定义与应用价值
原生多模态双驱动,区别于"后期拼接式"多模态融合(如先分别训练文本模型和图像模型,再通过简单线性层融合特征),其核心定义是:从模型架构设计之初,就构建统一的模态交互与融合机制,让不同模态数据(文本、图像、音频、视频等)在模型底层实现深度协同,同时依托"模态感知分支"和"通用语义分支"双驱动,既保留各模态的专属特征,又提取跨模态的通用语义信息。
在处理复杂数据类型时,原生多模态双驱动具备不可替代的优势:现实世界中的信息往往是多模态共生的(如医疗诊断中的"CT影像+病历文本"、自动驾驶中的"摄像头图像+雷达点云+语音指令"),原生架构能够更精准地捕捉模态间的语义关联,避免后期拼接导致的信息损耗。其典型应用场景包括:多模态内容生成(文本生成图像、图像生成语音)、跨模态检索(用文本搜索图像)、复杂场景理解(智能座舱多模态交互)等。
2.2 原生多模态双驱动的最新进展
近年来,原生多模态双驱动技术呈现三大发展趋势:
- 统一模态tokenization:将不同模态数据转换为统一格式的"模态token",如文本token、图像patch token、音频frame token,使模型可采用统一的Transformer架构进行处理(如 GPT-4V、Gemini Pro);
- 动态模态交互机制:引入模态注意力机制(如 Cross-Attention、Modality-Aware Self-Attention),让模型根据输入数据的模态类型,动态调整注意力分配权重,提升跨模态融合的精准度;
- 低资源模态适配:通过模态迁移学习,利用高资源模态(如文本)的知识,提升低资源模态(如稀有语言音频)的处理能力,降低多模态模型的训练数据需求。
当前主流模型已实现多模态的深度融合,例如 Gemini Ultra 可同时处理文本、图像、音频、视频和代码,通过统一的Transformer编码器,实现跨模态的理解与生成;GPT-4V 通过图像patch embedding与文本embedding的原生融合,具备精准的图像语义理解和文本生成能力。
2.3 原生多模态双驱动的工作流程与代码实现
2.3.1 工作流程流程图
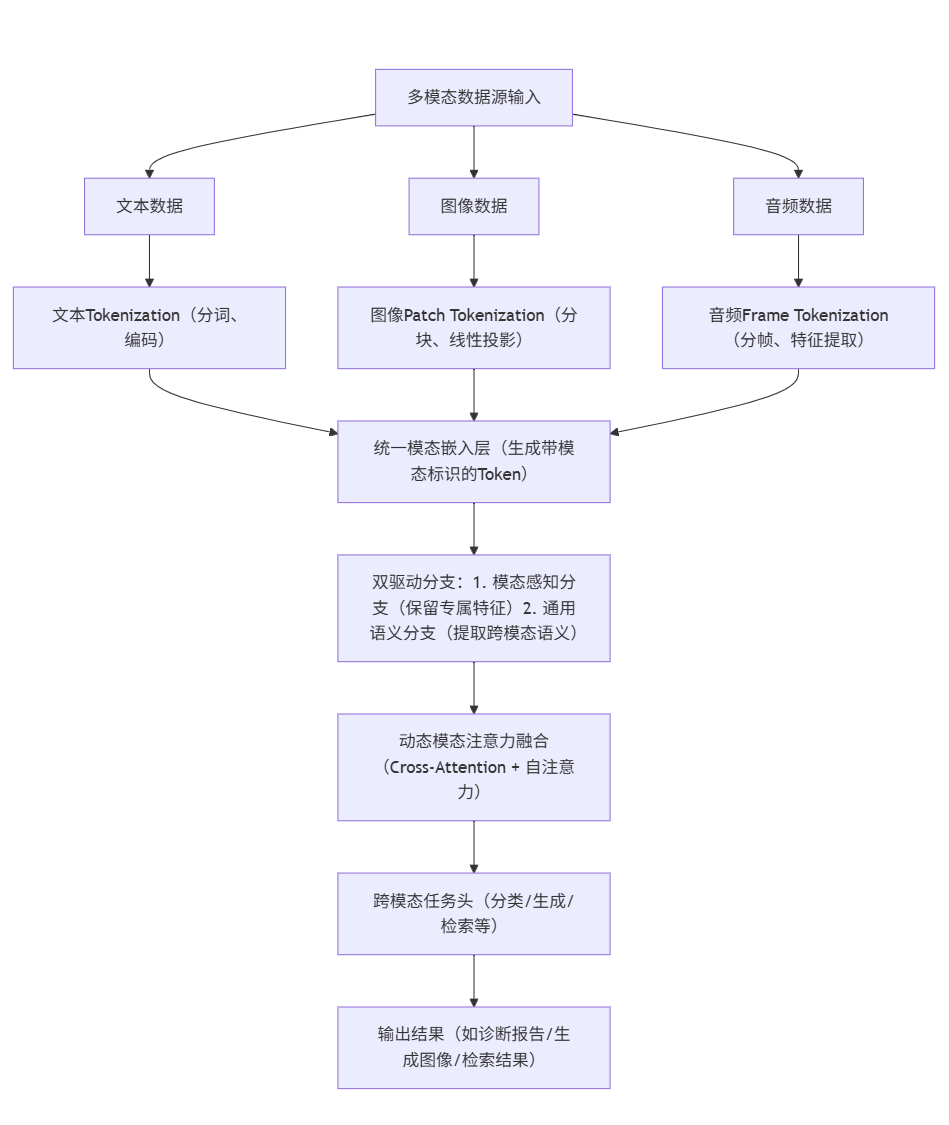
2.3.2 多模态数据源加载与预处理代码示例
以下代码基于 PyTorch,实现文本、图像、音频三种模态数据的加载与预处理,生成统一格式的模态Token:
python
import torch
from PIL import Image
import librosa
import torchvision.transforms as transforms
from transformers import BertTokenizer, ViTImageProcessor, Wav2Vec2Processor
# 初始化各模态处理器
text_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
audio_processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
class MultimodalDataProcessor:
def __init__(self):
# 图像预处理:Resize -> ToTensor -> Normalize
self.image_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
])
def process_text(self, text: str) -> dict:
"""处理文本数据,生成文本Token"""
inputs = text_tokenizer(
text,
max_length=64,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# 添加模态标识:文本模态标识为 0
text_tokens = inputs["input_ids"]
modal_ids = torch.zeros_like(text_tokens)
return {"tokens": text_tokens, "modal_ids": modal_ids}
def process_image(self, image_path: str) -> dict:
"""处理图像数据,生成图像Patch Token"""
image = Image.open(image_path).convert("RGB")
image_tensor = self.image_transform(image).unsqueeze(0) # [1, 3, 224, 224]
# 生成图像Patch Token(模拟ViT的Patch Embedding)
patch_size = 16
num_patches = (224 // patch_size) ** 2
patch_embedding = nn.Conv2d(3, 768, kernel_size=patch_size, stride=patch_size)
image_tokens = patch_embedding(image_tensor).flatten(2).transpose(1, 2) # [1, num_patches, 768]
# 添加模态标识:图像模态标识为 1
modal_ids = torch.ones(1, num_patches)
return {"tokens": image_tokens, "modal_ids": modal_ids}
def process_audio(self, audio_path: str) -> dict:
"""处理音频数据,生成音频Frame Token"""
# 加载音频数据(采样率16000,单通道)
audio_data, sr = librosa.load(audio_path, sr=16000, mono=True)
# 预处理:特征提取(梅尔频谱)
inputs = audio_processor(
audio_data,
sampling_rate=sr,
return_tensors="pt",
padding="max_length",
max_length=16000*3 # 3秒音频
)
audio_tokens = inputs["input_values"].unsqueeze(2) # [1, 48000, 1] -> 转换为frame token
# 添加模态标识:音频模态标识为 2
modal_ids = torch.full((1, audio_tokens.shape[1]), 2)
return {"tokens": audio_tokens, "modal_ids": modal_ids}
# 测试代码
if __name__ == "__main__":
processor = MultimodalDataProcessor()
# 处理三种模态数据
text_data = processor.process_text("This is a test text for multimodal processing.")
image_data = processor.process_image("test_image.jpg") # 替换为实际图像路径
audio_data = processor.process_audio("test_audio.wav") # 替换为实际音频路径
print(f"文本Token形状: {text_data['tokens'].shape}, 模态标识: {text_data['modal_ids'].shape}")
print(f"图像Token形状: {image_data['tokens'].shape}, 模态标识: {image_data['modal_ids'].shape}")
print(f"音频Token形状: {audio_data['tokens'].shape}, 模态标识: {audio_data['modal_ids'].shape}")
# 输出示例(因输入数据不同略有差异):
# 文本Token形状: torch.Size([1, 64]), 模态标识: torch.Size([1, 64])
# 图像Token形状: torch.Size([1, 196, 768]), 模态标识: torch.Size([1, 196])
# 音频Token形状: torch.Size([1, 48000, 1]), 模态标识: torch.Size([1, 48000])上述代码通过主流预训练处理器,将文本、图像、音频转换为带模态标识的Token,为后续原生多模态融合提供了统一的输入格式。实际原生多模态模型会在此基础上,通过统一编码器实现模态Token的深度融合。
第三部分:2025年的大模型技术展望
3.1 稀疏 MoE 与原生多模态双驱动的发展方向预测
结合当前技术演进趋势,2025 年稀疏 MoE 与原生多模态双驱动技术将呈现以下四大发展方向:
- 稀疏 MoE 的自适应专家调度:门控网络将引入强化学习机制,根据任务类型、输入特征、硬件资源动态调整激活专家数量与类型,实现"任务-专家-算力"的最优匹配,进一步提升模型效率;
- 多模态 MoE 融合架构:将稀疏 MoE 与原生多模态结合,构建"模态专家网络"(如文本专家、图像专家、跨模态专家),门控网络动态激活适配当前输入模态组合的专家,实现多模态任务的高效处理;
- 轻量化原生多模态模型:通过模型压缩(剪枝、量化)与稀疏化结合,开发适用于端侧设备(手机、智能穿戴)的轻量化原生多模态模型,推动多模态技术的普惠化应用;
- 可控性多模态生成:在原生多模态架构中引入可控性模块,实现对生成内容的模态类型、风格、精度的精准控制(如指定文本生成"卡通风格图像"、"严肃语气语音")。
3.2 技术进步对各行业的影响
稀疏 MoE 与原生多模态双驱动的技术进步,将对各行各业产生颠覆性影响:
- 医疗健康:构建"多模态医疗诊断系统",融合 CT 影像、病理切片、病历文本、基因序列等多模态数据,实现疾病的早期精准诊断;通过多模态生成技术,模拟手术过程,辅助临床培训;
- 教育领域:开发个性化多模态教学助手,根据学生的文本答题、语音互动、图像笔记数据,精准判断学习薄弱点,生成定制化学习方案(如文本讲义+动画演示+语音讲解);
- 自动驾驶:基于原生多模态双驱动,融合摄像头、雷达、激光雷达、语音指令等多源数据,提升复杂路况(如暴雨、大雾)下的环境感知精度,降低自动驾驶事故率;
- 内容创作:多模态生成工具将实现"一次输入,多模态输出"(如输入文本描述,同时生成图像、视频、背景音乐),大幅提升内容创作效率,推动新媒体、游戏、影视行业的创新发展。
3.3 技术带来的挑战与机遇
技术进步的同时,也带来了新的挑战与机遇:
挑战方面:① 数据隐私与安全:多模态数据包含大量个人敏感信息(如医疗影像、语音特征),如何在模型训练与应用中保护数据隐私,避免信息泄露成为关键问题;② 模型公平性:不同模态数据的分布差异可能导致模型存在偏见(如对少数族裔的语音识别准确率较低);③ 技术伦理:多模态生成技术可能被用于制作虚假内容(如深度伪造视频),引发社会信任危机。
机遇方面:① 新兴产业崛起:将催生出多模态数据标注、多模态模型运维、多模态内容审核等新职业与新产业;② 跨学科融合:推动 AI 与医疗、教育、汽车等传统行业的深度融合,催生新的商业模式(如订阅制多模态医疗服务);③ 技术普惠:轻量化模型将让多模态技术走进普通消费者生活,提升生活便捷度(如端侧智能助手的多模态交互)。
结论
稀疏 MoE 以其"高效算力利用"的核心优势,解决了大模型规模化发展中的计算成本瓶颈;原生多模态双驱动则通过"原生架构融合",突破了单一模态模型的能力边界,实现了复杂场景下的多模态信息精准理解与生成。两者的协同发展,已成为 2025 年大模型技术演进的核心主线。
从技术落地来看,稀疏 MoE 与原生多模态双驱动正从实验室走向产业应用,深刻改变医疗、教育、自动驾驶等多个领域的发展逻辑。未来,随着自适应专家调度、轻量化架构、可控性生成等技术的突破,大模型将更加高效、普惠、安全。
持续关注这些技术发展,不仅对技术研发人员至关重要,也对企业决策者、行业从业者具有重要意义。鼓励更多研究者与开发者投身相关领域,探索技术创新与产业应用的结合点,共同推动 AI 技术向更智能、更实用的方向演进。