接着上一篇的stack和queue,讲一下和有关的deque和priority_deque
目录
[1.1 vector 和 list 的优点与缺点 (重点)](#1.1 vector 和 list 的优点与缺点 (重点))
[1.2 CPU高速缓存 是什么鬼东西?](#1.2 CPU高速缓存 是什么鬼东西?)
[1.3.3 deque的缺点](#1.3.3 deque的缺点)
[1.3.4 deque 和 vector 访问数据的效率对比](#1.3.4 deque 和 vector 访问数据的效率对比)
[2.priority_queue 优先级队列 堆](#2.priority_queue 优先级队列 堆)
[2.1priority_queue 优先级队列 的底层实现](#2.1priority_queue 优先级队列 的底层实现)
[2.1.1 push](#2.1.1 push)
[2.1.2 pop](#2.1.2 pop)
1.deque
1.0deque的简单实用和概念
deque是双端队列,不要被名字误导了,它和队列没有关系。它已经不是普通队列了。
在功能上可以认为是list和vector的结合体,但底层完全不一样。
deque支持迭代器,方括号 访问,还有list和vector的插入删除操作,头文件<deque>:
它的使用对我们来说,根本不是难事,容器都类似的。简单搞定了。
能不能用deque来替代, vector 和 list ?
答案肯定是不能。功能上看似没问题,但是底层问题可大了。我们先从vector和list的优缺点讲起:
1.1 vector 和 list 的优点与缺点 (重点)
vector
| 优点1 | 支持快速下标随机访问( 访问),方便快捷 |
|---|---|
| 优点2 | 尾插尾删效率很高 O(1) |
| 优点3 | CPU高速缓存访问命中率高,数据访问效率高 |
| 缺点1 | 头部或中间位置插入删除效率很低,频繁挪动数据 O(N) |
| 缺点2 | 插入可能扩容,扩容对性能有一定损耗(比较小),也可能浪费空间 |
list
|---------|---------------------------|
| 缺点1 | 不支持快速下标随机访问 |
| 缺点2 | CPU高速缓存访问命中率低,数据访问效率低 |
| 优点1 | 任意位置插入删除效率很高 O(1) |
| 优点2 | 插入不存在扩容,按需申请释放内存 |
两者的优缺点基本是相反。看到上面的表格。那什么是"CPU高速缓存访问命中率"?
1.2 CPU高速缓存 是什么鬼东西?
数据访问效率高低我们还是略知一二的,究其原因就是vector底层是连续的数组空间,所以数据访问效率高。而list底层节点之间不是连续的空间,所以数据访问效率不高。
那 CPU高速缓存 就涉及到 CPU 的知识:CPU 会把最近访问的内存数据(及相邻数据)缓存到高速缓存 里,因为程序通常有 "局部性原理":访问了一个数据,大概率会访问它附近的数据。
计算机有两个很常用的存储介质,一个是内存,一个是硬盘。内存相对快,硬盘相对慢,但还有更快的。 CPU的本质是执行指令 ,比如范围for遍历访问容器,代码转换为指令后,CPU就要去取内存的数据来执行命令。所以CPU是要访问内存的。但是内存的访问速度对于CPU比较慢 ,所以CPU就还有几个存储介质,一个是缓存,一个是寄存器。寄存器特别小,一般都是4/8/16个字节大概。每个CPU都有一堆寄存器。如果要运行的数据比较大,就放不进寄存器,那就涉及到了三级缓存。大一点的数据就会读到三级缓存内。三级缓存会慢一些,但比内存快得多。
那CPU执行命令时,就会根据**"局部性原理"** ,
这就是CPU的高速缓存,缓存命中率。

1.3deque底层原理
基于以上的CPU相关知识 ,祖师爷为了设计一个兼容vector和list优点的容器 ,于是研究了deque。
设计**(中控数组)指针数组,并且第一个小buffer的二级指针放在中控数组中间(这样方便中控数组头插)** ,每个元素都指向一个小buffer数组,这样就设计好了deque的雏形。
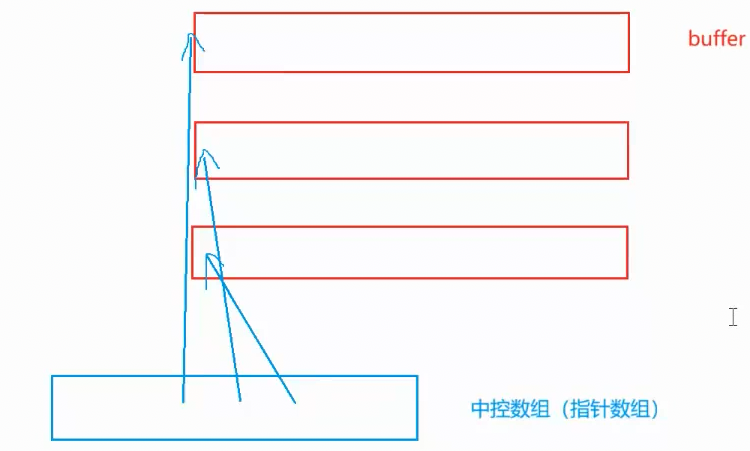

这样既有高速缓存(每个小buffer连续一段空间,可连续访问),也不怎么浪费空间(每个buffer长度设计在10左右,即便只存入一两个元素,那也不会浪费太多空间)。还可计算下标位置(图2),实现方括号 访问、方便头插头删效率。
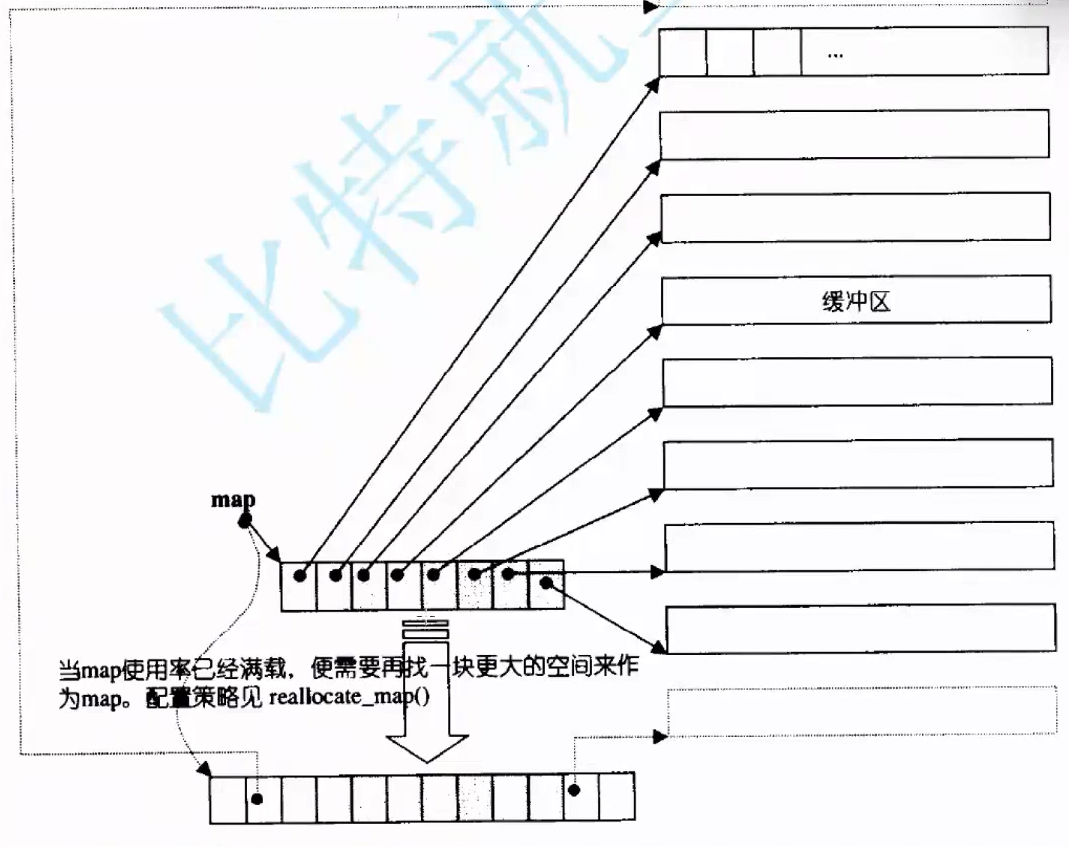
中控数组如果满了需要扩容,但扩容代价不高 ,拷贝指针就行,vector的扩容,要拷贝大量数据。
1.3.1deque迭代器
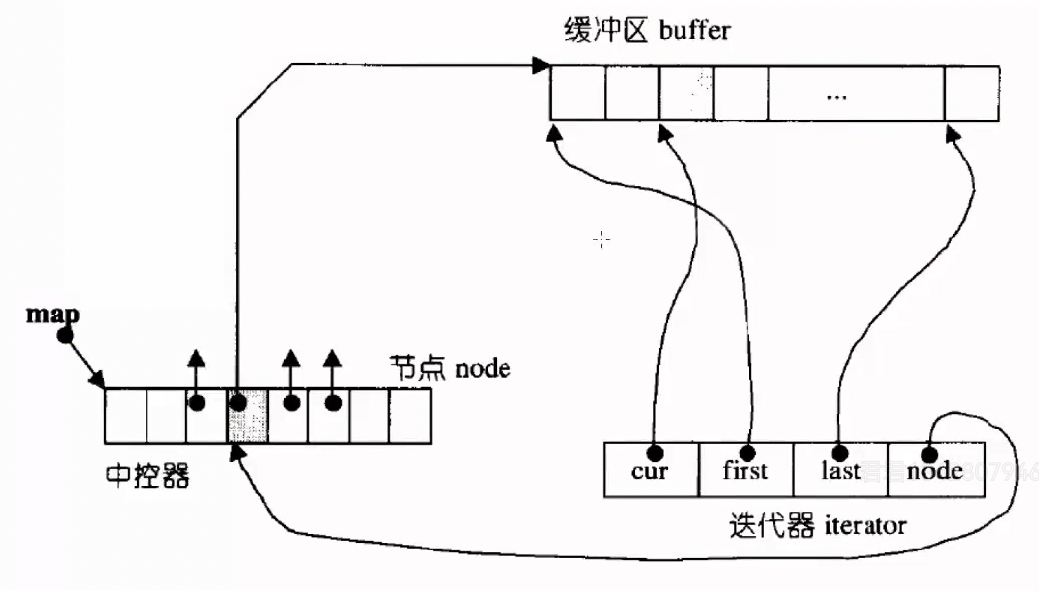
deque的迭代器比较复杂。如图,其迭代器由四个指针封装而成,作用与名字相同。
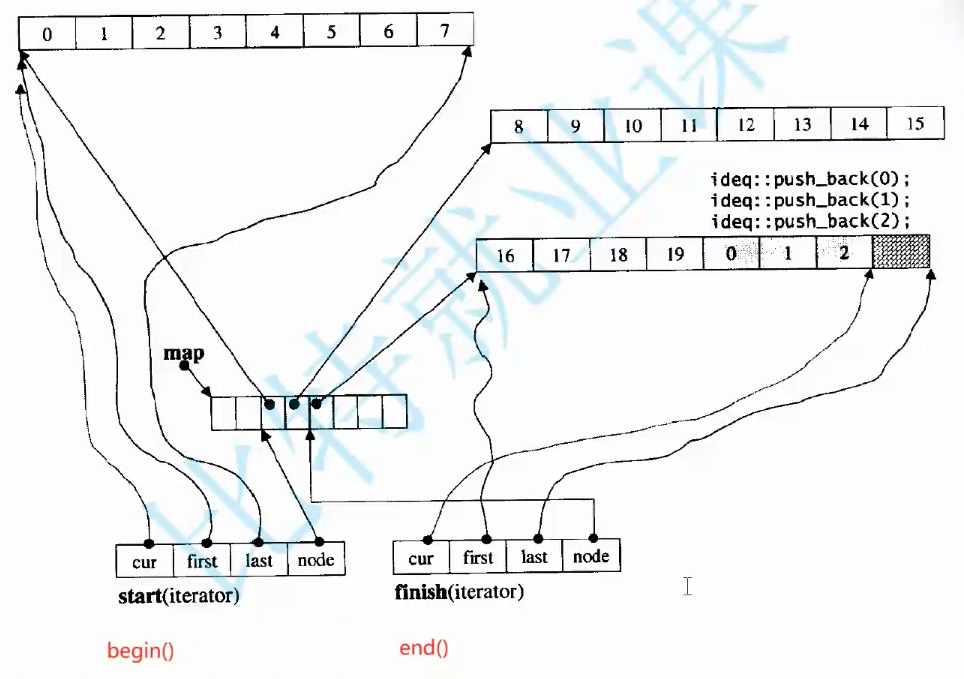
他的迭代器,begin()的返回值是start迭代器,end()的返回值是finish迭代器,这两个迭代器分别代表最前和最后的两个buffer的各种位置。
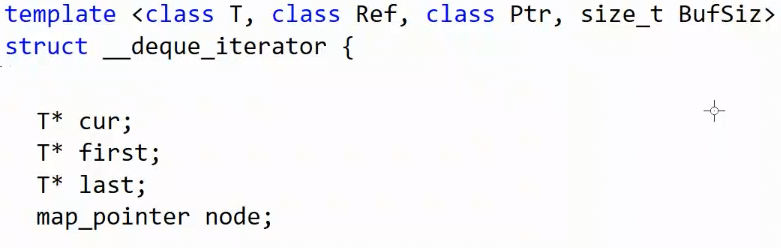
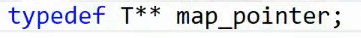
这是deque的源码,map_pointer 其实就是 T** 的重命名,二级指针,因为node作为一个指针指向一个指针。

deque的主要成员,map就是指向中控数组成员的指针,也是二级指针。
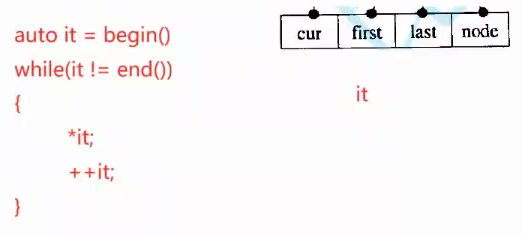
既然支持迭代器,那就支持遍历访问。他的迭代器是怎么遍历的? 联想到我们之前学链表的迭代器,方法就是重载运算符。
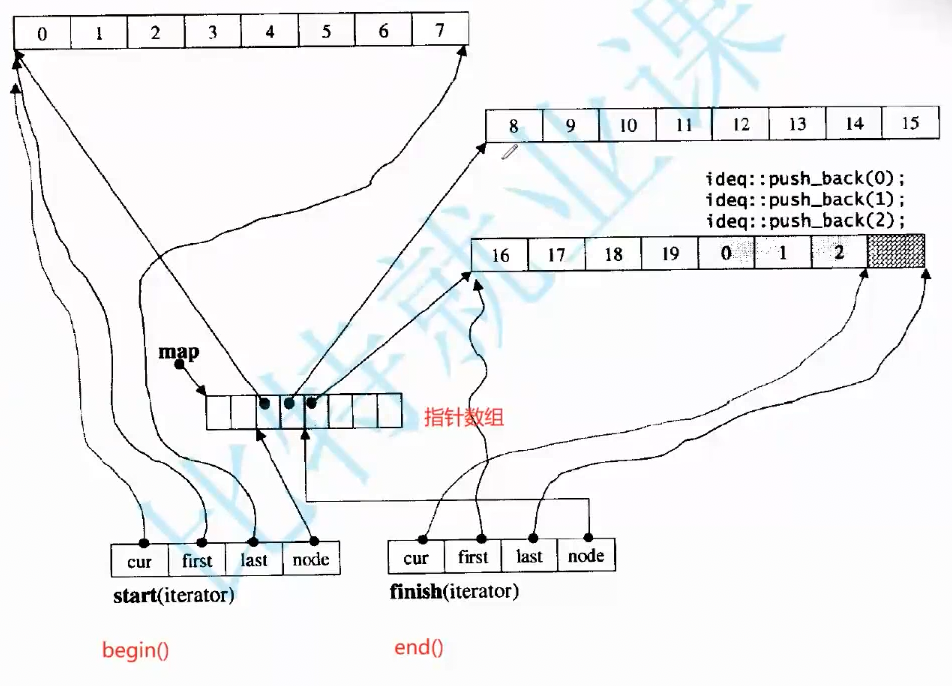
operator*:*it ,目的就是得到当前迭代器指向的位置的数据,那operator* 理应是返回*cur。
operator++:++it,目的是让cur往后走,那operator++就理应是返回++cur 。那如果当前小buffer遍历完(比如上图中遍历到了第一个buffer的最后一个元素数据7,怎么衔接到数据8)怎么办?当 cur==last 那就该修改node了,让node++(node是指向中控数组元素的指针,node++,指向下一个小buffer),node++得到的就是下一个buffer的起始地址,把这个值同步给给cur和first,然后last = first+10(假设每个buffer固定10长度),那迭代器就更新完成。
operator== :很简单,判断迭代器内的cur指针(地址)是否相等就行(注意,判断指针指向的值不可取,因为值可能重复),假设右操作数是x,x.cur访问其cur指针,直接返回 cur==x.cur
operator!= :既然实现了==,那直接复用operator==就行。


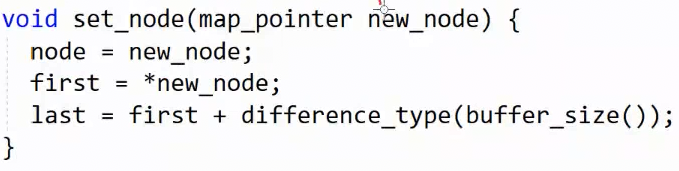
这就是它迭代器,接下来看插入删除操作。
1.3.2deque插入删除操作
尾插
插入一个数据,并且让++cur,如果当前buffer满了,那就新开一个buffer,并且更新finish的迭代器指向。
尾删
先删除数据(必须删除),然后--cur,如果buffer空了,删除当前buffer,并且更新finish的迭代器指向
头插
在头部插入一个新数据,如果满了需要开个新buffer,然后更新迭代器指向。先插buffer尾部,所以是--cur(下图)

头删
先删除数据(必须删除),然后++cur,如果buffer到结尾了(反向删空了),删除当前buffer,并更新start迭代器的指向
1.3.3 deque的缺点

缺点1:vector是真正完全连续的,并且下标不需要经过除模运算。所以大量的下标访问,deque还是存在很大缺陷。
缺点2:中间插入删除 会导致前后挪动数据,这和vector没什么区别,但是deque效率更低(有一种情况,如果插入的靠近头或者尾部,deque的效率远高于vector,插入靠中间则deque效率略低),因为空间并非完全连续。
有一个解决办法:给插入所在的buffer扩容。但是这会导致每个buffer大小不一样,后续除模运算访问下标很困难。所以库里没采用此方法。
虽然deque缺陷还是很大,但是他的优点很适合作为stack和queue的默认适配容器,所以总体还是设计成功的。
1.3.4 deque 和 vector 访问数据的效率对比
和之前vector对比list的代码一样,这里仅展示结果:数据量:1000000
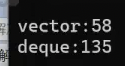

结论:vector访问 大量数据 效率是deque的几倍。
2.priority_queue 优先级队列 堆


它也是一个容器适配器。 叫优先级队列

优先级队列,默认出优先级最高的数据 。大的,或者小的就是优先级最高的。 根据我们数据结构学过的
这实际是就是个堆 。默认是大顶堆。
为什么不直接叫堆呢? 因为有些人可能没学过数据结构,不知道这是 堆,所以取名 优先级队列
优先级队列没有单独的头文件,它属于queue,所以它的头文件是 queue ->
同样,作为容器适配器,它没有迭代器 ,想要遍历就需要top,pop循环:
结果:(大顶堆)


其实它可以调整优先级 ,将 最大 为优先级调整为 最小 为优先级,这需要用到它的第三个模板参数:

less是库里实现的一个仿函数类型,仿函数后面会讲。简单说就是重载了一个operator(),使它能像函数一样使用 。类似于:
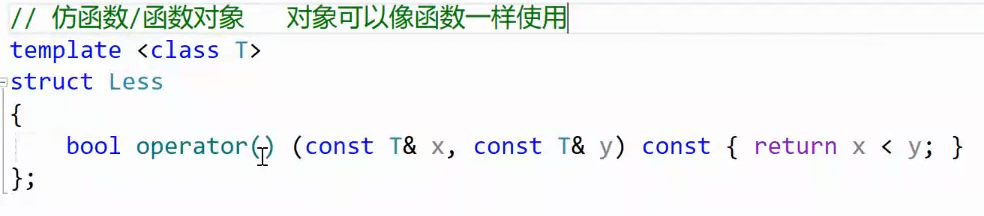
说回来,我们要让它变成 小顶堆 ,只需要把第三个参数less 改成 greater:

要修改第三个参数的缺省值,那我们得手动写出第二个参数,这里可以是vector(默认是vector)也可以是deque只要符合需求就行 改成如图所示,就是小顶堆了。
2.1priority_queue 优先级队列 的底层实现
仿函数还没学习,所以我们暂时不添加第三个参数:
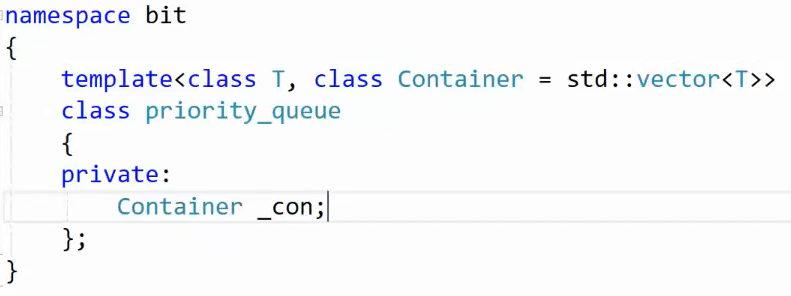
那么和之前一样的,这是一个容器适配器,我们也让它默认为 vector ,实现一个大顶堆
2.1.1 push
那要知道这个优先级队列怎么插入数据,我们就得回到 堆 这个概念,堆的底层理论上是连续的数组空间 ,但实际上 也不一定比如deque也行,deque是多个不一定连续的小buffer组成。 不搞那么复杂,我们现在拿vector,连续的动态数组空间来看待这个问题:
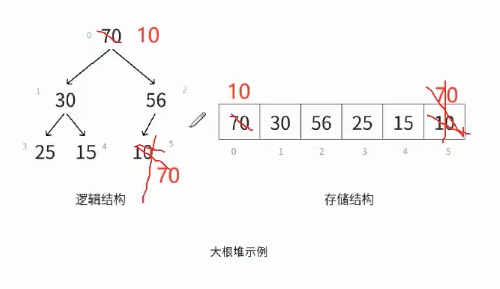
如图,堆总是一颗完全二叉树 ,而数组空间也可以看作是完全二叉树。所以数组和堆天然契合


这是二叉树计算孩子和双亲节点的方法。以下图对象,带入公式总能得到正确的节点位置。
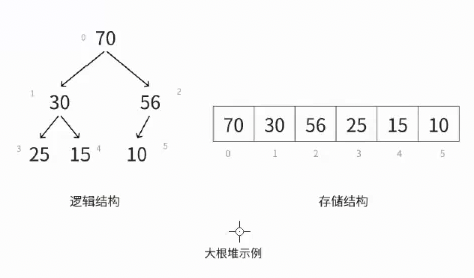
如果我们现在要插入一个x,x<=56,那没问题。但是如果x>56,它就会破坏掉右子树的 大顶堆 ,因为叶子比父节点大了。
此时需要 向上调整,把x放到合适的位置,最坏的情况就是一路替换到根节点 。那这就是优先级队列push的底层逻辑 。
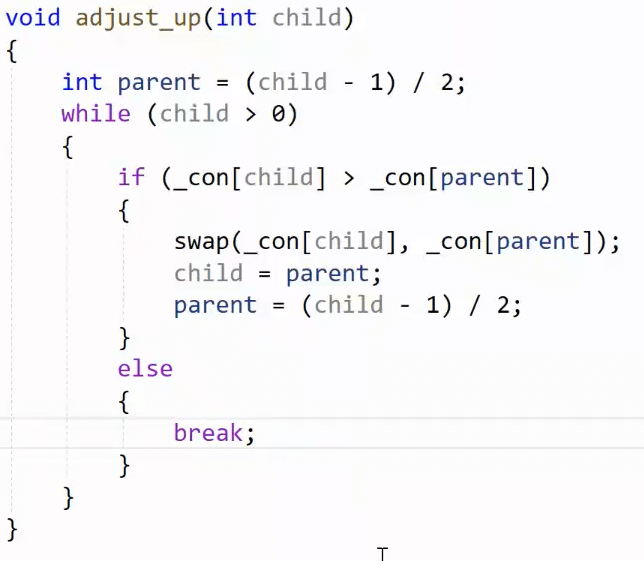
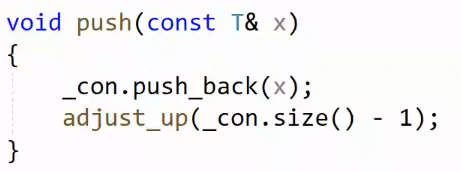
外层循环条件child>0:根节点是0,=0结束,说明已经调整到根节点调整完了。内层的break:如果调整到孩子小于父亲了,那就停止循环。
另外,_con.size()-1代表的是最后一个数据的位置,因为size()指向最后的下一个嘛,
取堆顶,很简单
2.1.2 pop
这里的删除是删除优先级最高的数 据,所以是删除堆顶 。那就是头删。 这里的删除可不是像vector那样,直接把后面的数据覆盖前面的,那样整个 堆 的结构会乱套,正确的做法是:
1.交换 堆顶 和 堆尾 数据 2.删除堆尾 3.向下调整
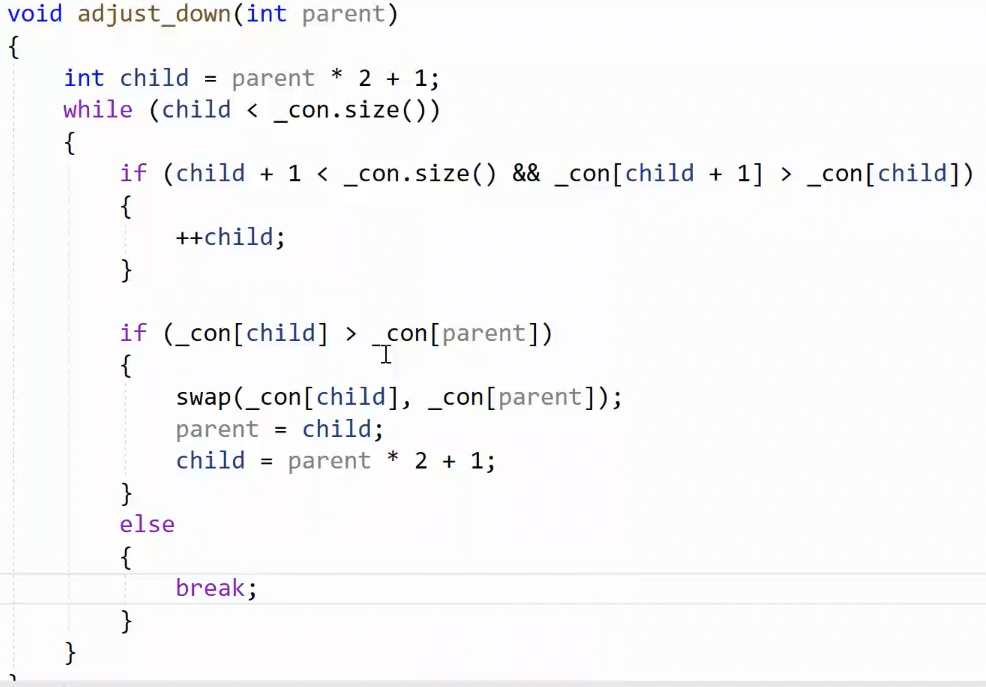
向下调整 用到了假设法。先假设左孩子大,和右孩子比较。因为不知道一开始谁更大。
方法的大前提是有右孩子,所以外层循环条件是左孩子 < _con.size();
如果孩子比父亲大,那就交换一下,不然就break。

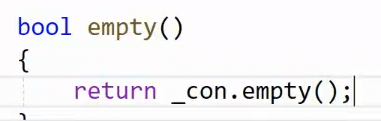 判空,顺手的事
判空,顺手的事
2.1.3迭代器区间构造
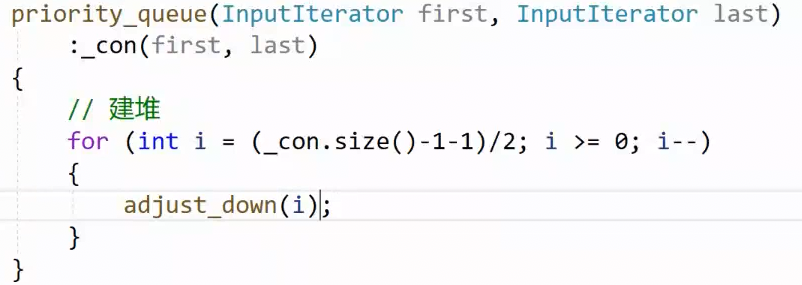
通过迭代器给构造_con,但它可能是乱的 ,不符合优先级队列 。那我们参考上面的头删,利用向下调整让这个乱堆变成大的优先级队列,先找到最后一个父节点,此时是最小的二叉树,一步步向下调整(让大顶堆一步步完善)调整完找更上一级的父节点(让大顶堆更大)直到根节点调整完(最大的大顶堆,全部排序好了)
向下调整就是让当前节点及其以下的都调整成大堆,那一步步调整到根节点,那就是调整完了。
2.1.4强制编译器生成默认构造
因为显式写了一个构造,编译器不会生成默认构造函数了,我们需要自己写一个默认构造。直接 priority_queue(){ } 也行!不一定要加default,但一定要加{ } 。别混淆了函数声明和函数定义。
实践一下: 迭代器区间构造
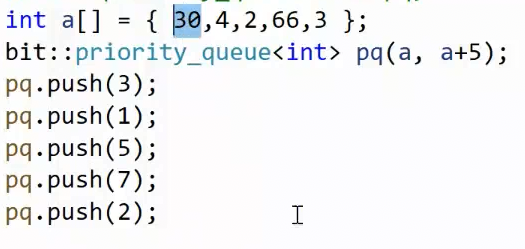
 注:上图的迭代器区间传的是指向数组的指针
注:上图的迭代器区间传的是指向数组的指针
因为迭代器区间可以传容器,也可以传指向数据结构的指针
这样,优先级队列 的底层就实现好了。
关于仿函数的内容下篇进行讲解,请各位多多支持