本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day 1 - Redis核心架构与线程模型
1.1 Redis定位:不仅是缓存
Redis(Remote Dictionary Server)的定位远超传统缓存中间件。在架构设计中,它扮演三个核心角色:
-
高性能内存数据库:支持持久化,可作为主数据库使用(如Twitter时间线)
-
分布式系统协调器:分布式锁、配置中心、消息队列
-
计算型存储引擎:通过Lua脚本和原生数据结构,将计算下沉到存储层
1.2 Redis整体架构剖析
Redis的整体架构可以分解为以下几个核心层次:
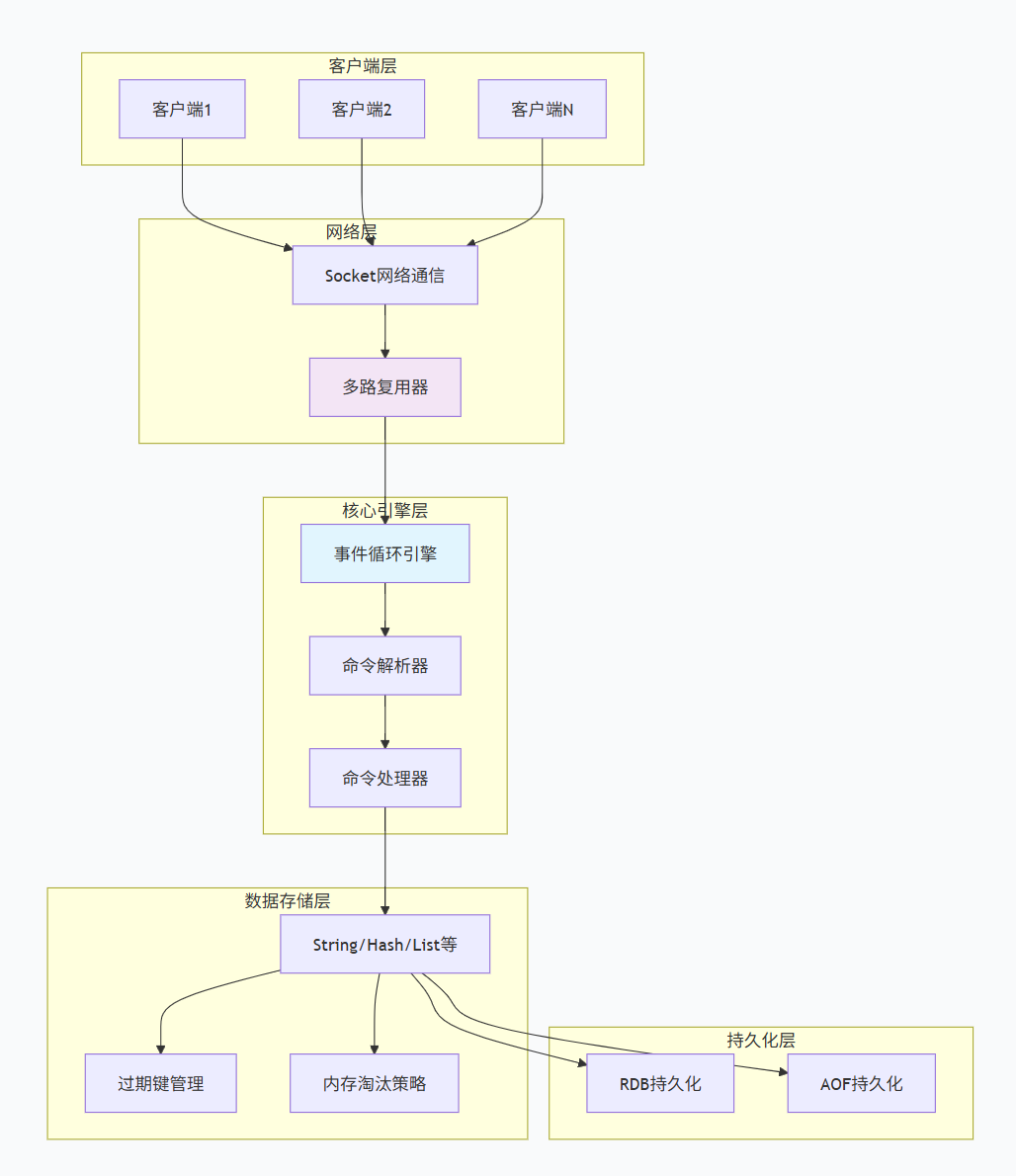
架构核心组件说明:
-
网络层:基于TCP的RESP协议,支持管道和连接复用
-
事件驱动层:采用Reactor模式,单线程处理所有客户端请求
-
命令处理层:解析RESP协议,调用对应的命令处理器
-
数据存储层:基于内存的键值存储,支持多种数据结构
-
持久化层:可选RDB快照和AOF日志两种持久化方式
1.3 ⭐I/O多路复用实现机制
1.3.1 什么是多路复用?
- 多路(Multiplexing)指的是多个独立的I/O通道,在Redis上下文中,具体指:
-
多个客户端Socket连接:成千上万的客户端TCP连接
-
多个文件描述符:包括监听socket、客户端连接socket、可能的磁盘文件等
-
多个I/O事件:读事件、写事件、异常事件
- 复用(Multiplexing)指的是复用一个或多个线程,具体是:
-
复用一个线程:在Redis 6.0之前,单个线程处理所有I/O事件
-
复用少数线程:在Redis 6.0+中,复用少量I/O线程处理网络数据读写
-
复用CPU时间片:避免线程切换,让CPU专注处理就绪的I/O操作
通俗解释 :I/O多路复用就像是一个高效的餐厅服务员(线程),他不需要一直站在某个客人(客户端)旁边等待点餐,而是:
-
同时照看所有客人(多路)
-
当有客人举手示意(I/O就绪)时才过去服务
-
一个服务员服务整个餐厅(复用)
1.3.2 为什么需要I/O多路复用?
解决的核心问题:
传统阻塞I/O模型中"一个连接一个线程"的方式在高并发场景下面临严重挑战:
| 问题 | 传统阻塞I/O | I/O多路复用 |
|---|---|---|
| 线程数量 | 1个连接 = 1个线程 | 1个线程监控数千连接 |
| 内存消耗 | 每个线程栈1-2MB | 仅需少量监控数据结构 |
| 上下文切换 | 频繁切换,开销大 | 几乎无切换 |
| CPU利用率 | 等待期间CPU空闲 | CPU高效处理就绪事件 |
| 并发上限 | 受限于线程数 | 受限于文件描述符数 |
1.3.3 I/O多路复用如何工作?
核心工作机制:
-
注册监控:应用程序告诉内核需要监控哪些文件描述符,以及关心的事件(读、写、异常)
-
等待通知:应用程序调用等待函数(如select、poll、epoll_wait),进入等待状态
-
事件就绪:内核监控所有注册的描述符,当任意一个就绪时,通知应用程序
-
处理事件:应用程序处理所有就绪的事件
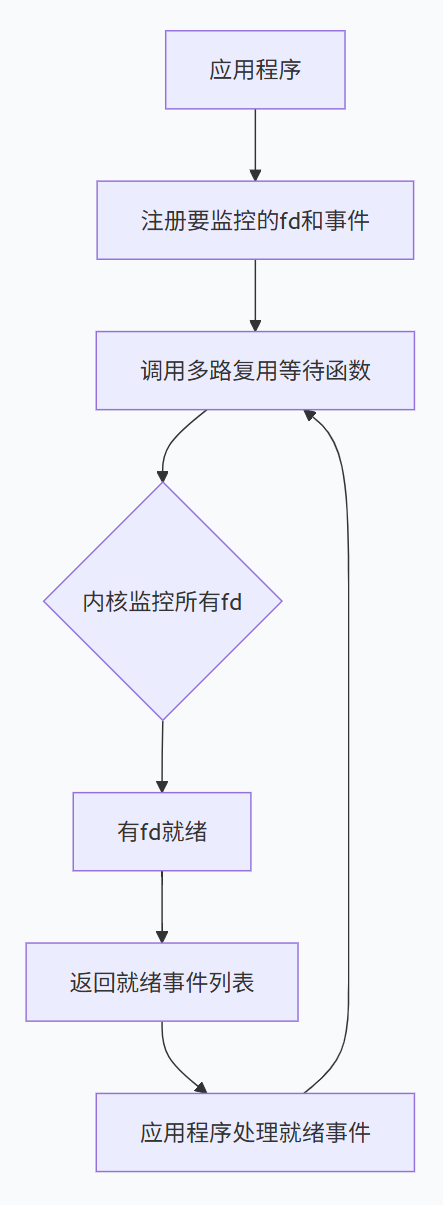
关键设计模式:Reactor模式
I/O多路复用通常基于Reactor模式实现,包含三个核心组件:
Initiation Dispatcher(事件分发器):
- 注册/注销事件处理器
- 运行事件循环,等待事件发生
- 当事件发生时,分发给对应的事件处理器
Event Handler(事件处理器):
- 定义处理事件的接口
- 具体实现处理逻辑
Concrete Event Handler(具体事件处理器):
- 实现特定事件的处理逻辑
1.4 ⭐三种主流I/O多路复用技术
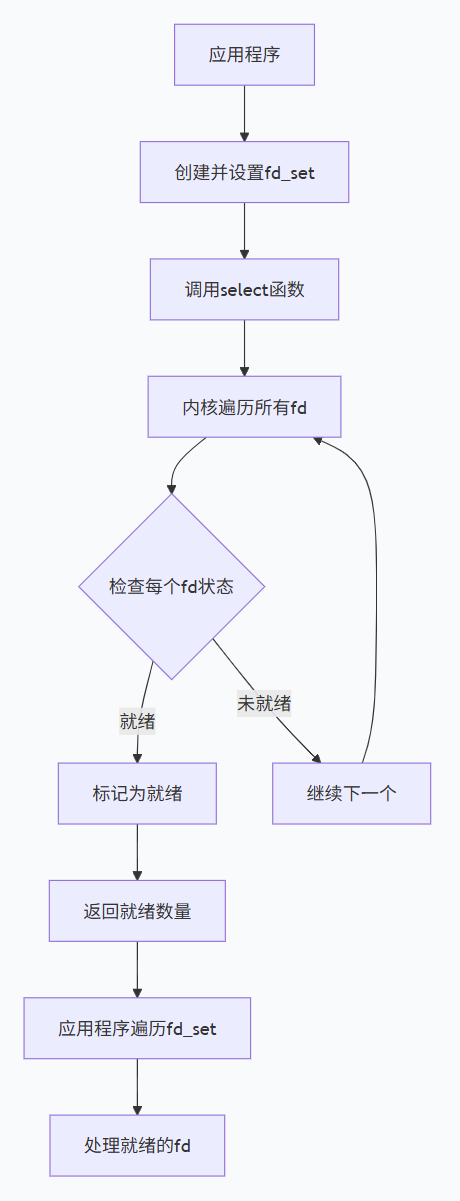
1.4.1 select:最古老但广泛支持
是什么:
select是POSIX标准中最早的多路复用接口,几乎在所有Unix-like系统上都可用。
工作原理:
-
应用程序创建三个fd_set(读、写、异常)
-
将需要监控的文件描述符设置到对应集合中
-
调用select(),内核遍历所有监控的fd
-
返回就绪的fd数量,并修改fd_set指示哪些fd就绪
-
应用程序遍历所有fd,检查是否在就绪集合中
工作流程图:
优点:
-
✅ 跨平台支持:几乎所有Unix-like系统都支持
-
✅ 超时精度高:支持微秒级超时
-
✅ 编程简单:API相对简单,易于理解
缺点:
-
❌ 性能瓶颈:O(n)时间复杂度,每次都要遍历所有fd
-
❌ 连接数限制:通常限制为1024(FD_SETSIZE)
-
❌ 内存拷贝开销:每次调用都需要在用户空间和内核空间之间复制fd_set
-
❌ 水平触发:可能重复通知相同事件
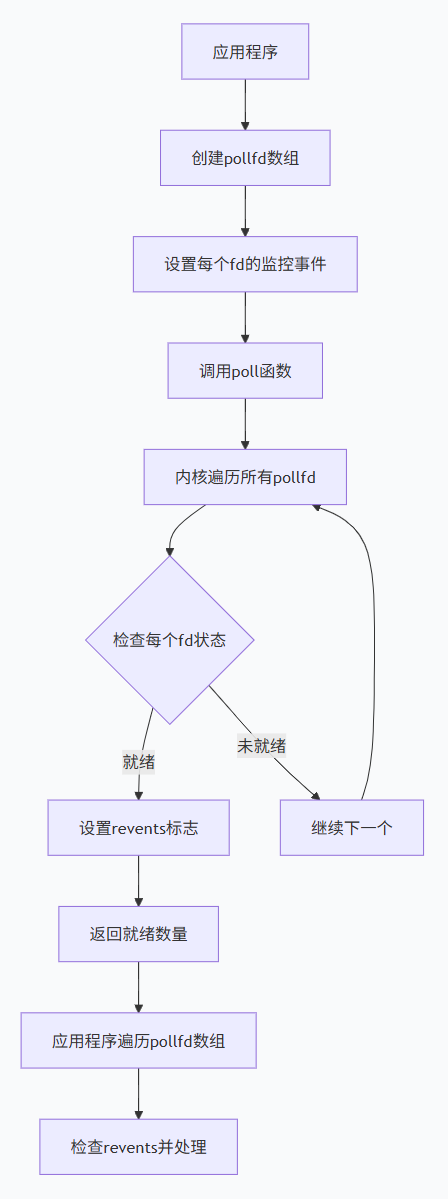
1.4.2 poll:改进的select
是什么:
poll是select的改进版本,解决了select的一些限制,但基本工作原理相似。
核心改进:
-
去除fd数量限制:使用链表结构,理论上无上限
-
更精细的事件定义:使用pollfd结构体,支持更多事件类型
工作流程:
优点(相比select):
-
✅ 无连接数限制:理论上支持无限连接
-
✅ 事件定义更丰富:支持更多事件类型
-
✅ 无需每次重建集合:pollfd可以重复使用
缺点:
-
❌ 性能问题依然存在:仍然是O(n)遍历
-
❌ 内存拷贝开销:每次调用都需要复制整个pollfd数组
-
❌ 水平触发:与select相同的问题
1.4.3 epoll:Linux的高性能解决方案
是什么:
epoll是Linux特有的高性能I/O多路复用机制,专为处理大量并发连接而设计。
核心创新:
-
事件驱动架构:只有状态变化的fd才会被处理
-
内核回调机制:内核主动通知应用程序
-
内存共享:减少用户空间和内核空间之间的数据拷贝
epoll的两种工作模式:
-
水平触发(LT - Level Triggered):
-
默认模式
-
只要fd就绪,每次epoll_wait都会返回该事件
-
编程简单,不容易遗漏事件
-
-
边缘触发(ET - Edge Triggered):
-
需要显式设置(EPOLLET)
-
只在fd状态变化时通知一次
-
性能更高,但编程复杂
-
工作流程:
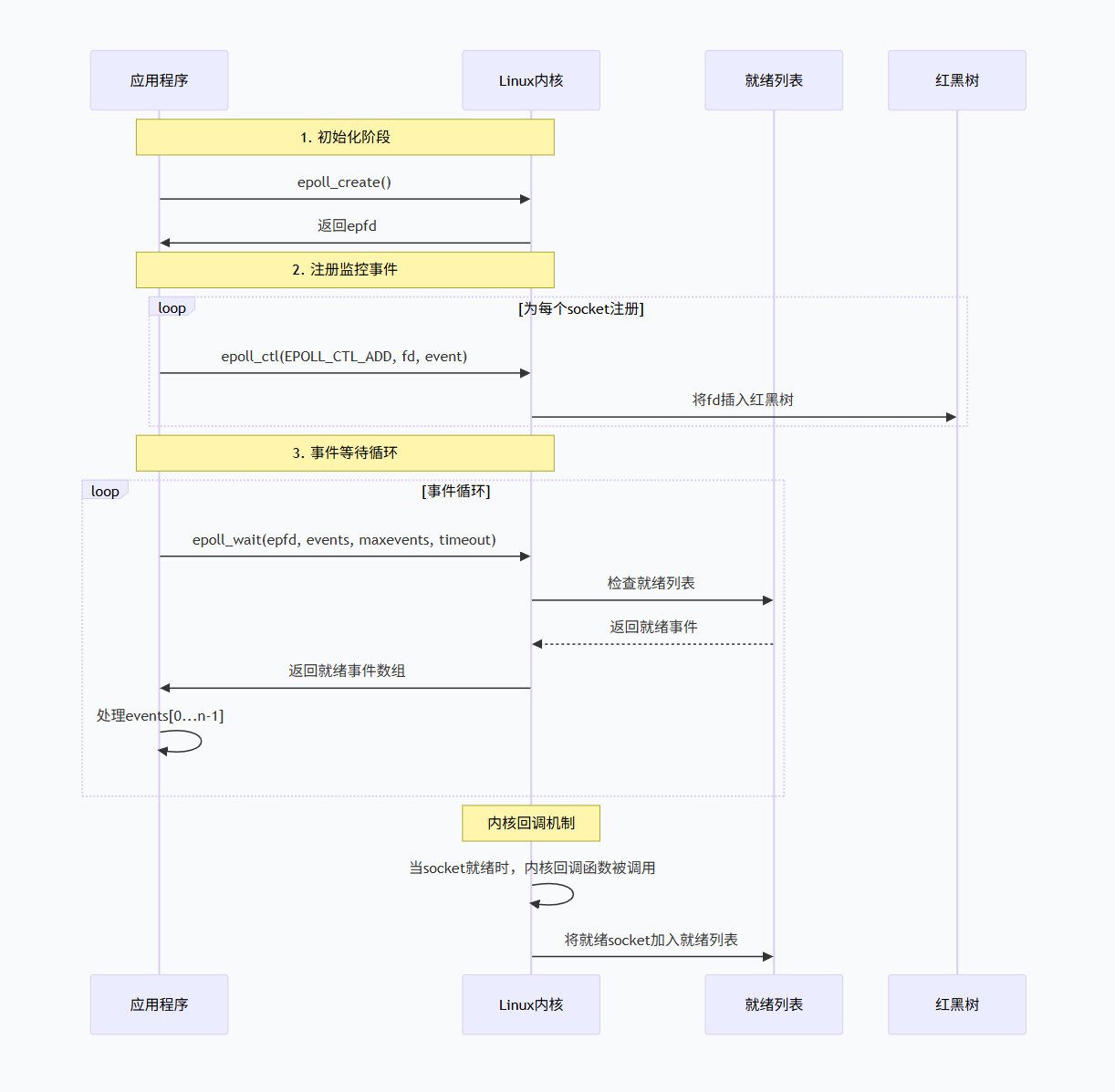
epoll内部数据结构:
-
红黑树:存储所有监控的fd,实现快速查找(O(log n))
-
就绪列表:存储就绪的fd,epoll_wait直接返回这个列表
-
回调机制:当fd状态变化时,内核自动调用回调函数
优点:
-
✅ 高性能:O(1)时间复杂度,只处理就绪的fd
-
✅ 无连接数限制:仅受系统内存限制
-
✅ 内存效率高:内核与用户空间共享内存,减少数据拷贝
-
✅ 支持边缘触发:减少重复通知,提高性能
-
✅ 可扩展性强:轻松支持数十万并发连接
缺点:
-
❌ 仅限Linux:不是跨平台标准
-
❌ 编程复杂度较高:特别是ET模式
1.4.4 I/O多路复用三剑客对比
| 特性 | select | poll | epoll (Redis默认) | kqueue (macOS) |
|---|---|---|---|---|
| 监听上限 | 1024(fd_set大小) | 无限制 | 无限制 | 无限制 |
| 时间复杂度 | O(n) | O(n) | O(1) | O(1) |
| 触发模式 | LT | LT | LT/ET(Redis用ET) | LT/ET |
| 数据拷贝 | 每次调用拷贝 | 每次调用拷贝 | mmap共享内存 | 共享内存 |
| 性能 | 10K连接后急剧下降 | 10万连接勉强可用 | 100万连接稳定 | 100万连接稳定 |
1.5 线程模型演进
1.5.1 Redis6.0
演进背景:
- Redis 5.0前:纯单线程(所有操作:I/O + 命令执行)。
- 瓶颈 :I/O读写(如大key
GET)成为瓶颈,CPU空闲但I/O等待。
Redis 6.0:多线程I/O(核心突破)
- 设计原则 :仅多线程处理I/O (
read/write),命令执行仍单线程。 - 注意:这不是多线程处理命令,而是多线程处理网络I/O:
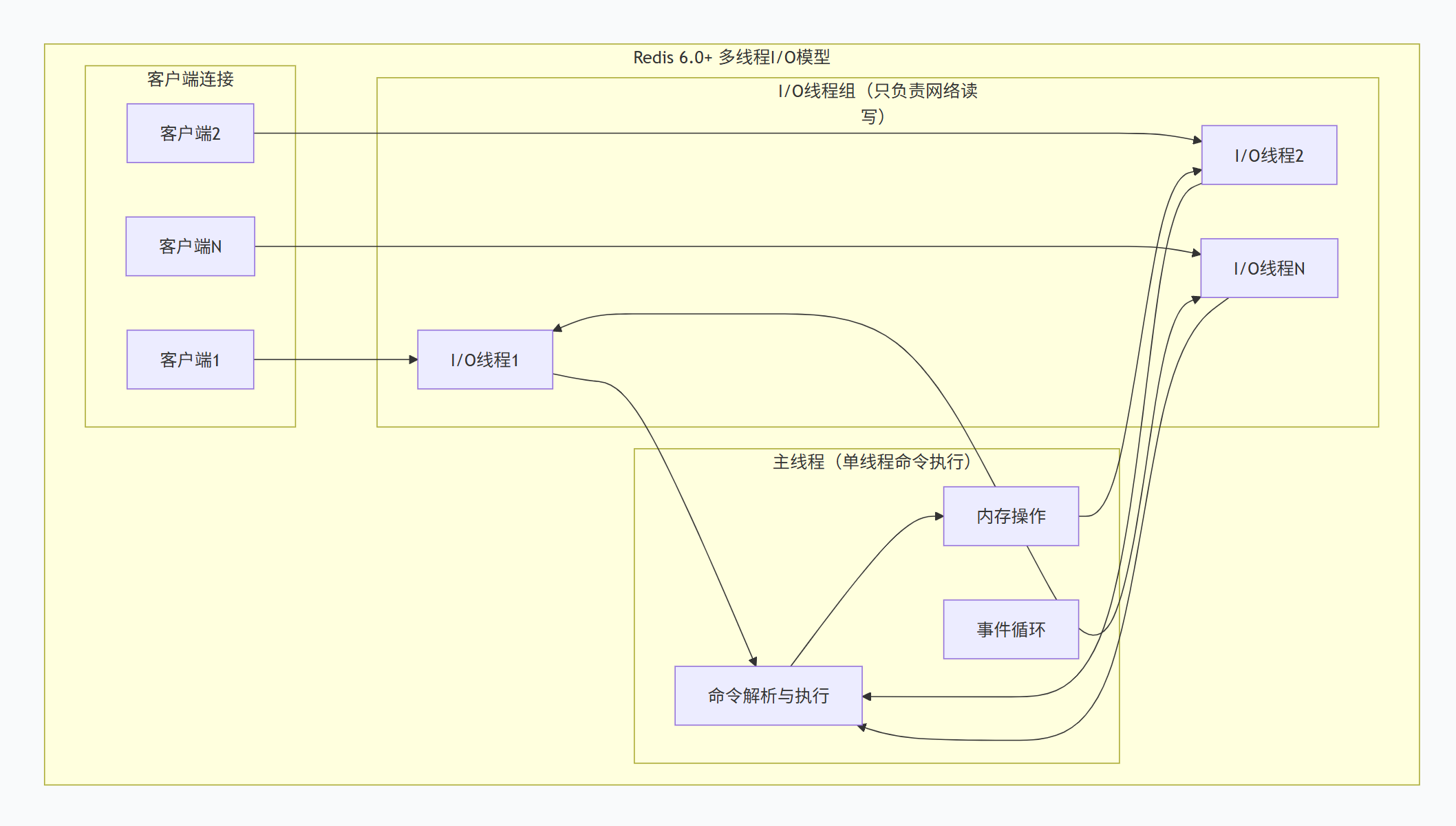
1.5.2 Redis7.0
Redis 7.0并未引入"命令执行多线程"(那将是Redis的哲学颠覆),而是对IO线程进行了精细化优化:
改进点1:IO线程负载动态自适应
// networking.c中新增的动态调整逻辑
if (server.io_threads_busy && processed < 100) {
// IO线程持续繁忙但任务量小,说明有大Key阻塞
// 后续请求由主线程直接处理,避免排队
handleClientsWithoutBlocking(c);
}改进点2:大Key自动识别与降级
# Redis 7.0配置新增
io-threads-max-idle-time 30 # IO线程空闲超时时间
io-threads-big-key-threshold 16384 # 大于16KB的Key不启用IO线程改进点3:无锁队列优化 Redis 7.0使用环形缓冲区 + CAS原子操作替代Redis 6.0的互斥锁.
7.0线程模型如图
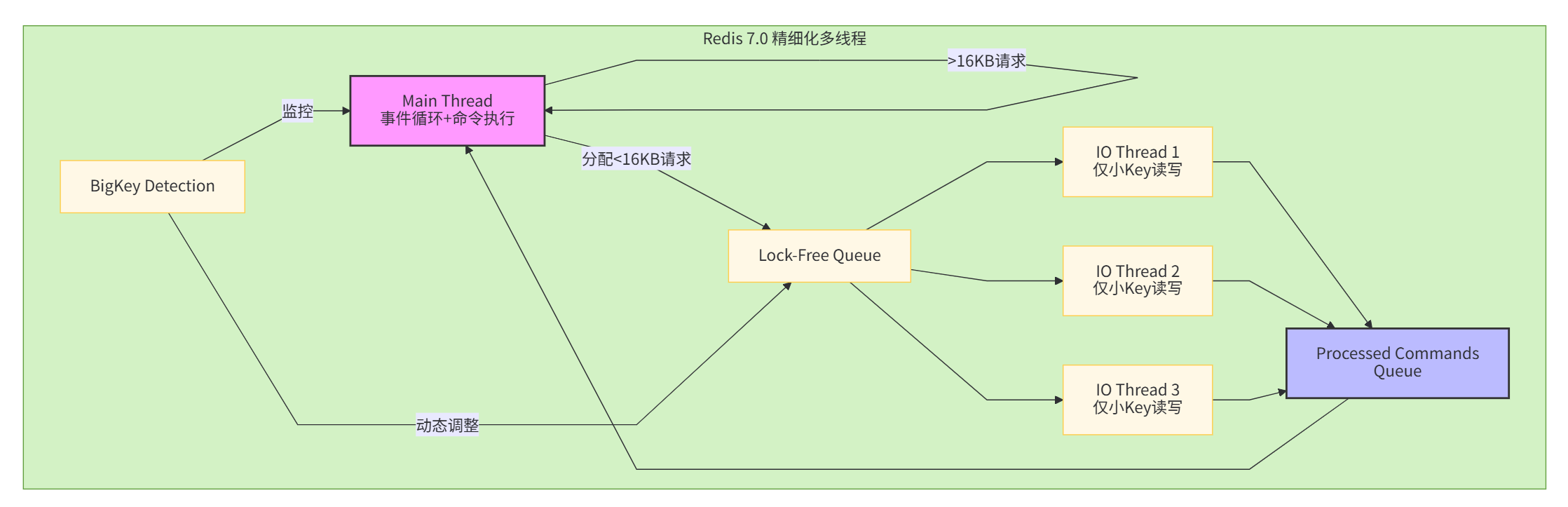
1.6 ⭐面试高频考点
考点1:epoll比select/poll优势在哪里?
面试回答:
epoll相比select/poll的主要优势:
-
时间复杂度:epoll O(1) vs select/poll O(n)
-
描述符限制:epoll支持数万连接,select通常1024限制
-
事件通知机制:epoll只返回就绪事件,无需遍历所有描述符
-
内存使用:epoll内核与用户空间共享内存,减少数据拷贝
-
边缘触发模式:epoll支持ET模式,减少事件通知次数
Redis会根据操作系统自动选择最高效的多路复用技术,Linux下优先使用epoll。
考点2:Redis真的是单线程吗?为什么单线程还这么快?
面试官心理:考察对Redis线程模型的深度理解,是否了解6.0后的演进
标准回答 : "这是一个演化性问题。Redis 6.0之前命令执行是单线程 ,但6.0之后引入了多线程IO。
快的原因四点:
-
内存操作:纯内存访问,无磁盘IO,延迟在微秒级
-
IO多路复用:单线程通过epoll管理10万+连接,事件驱动避免阻塞
-
高效数据结构:SDS、跳表等定制化优化,减少计算开销
-
无锁设计:单线程执行命令,无锁竞争和上下文切换,CPU L1/L2缓存命中率高
但单线程的代价:
-
大Key删除会阻塞整个实例(DEL 100万元素需100ms+)
-
CPU密集型操作(如Lua复杂计算)会拖慢所有请求
Redis 6.0+的优化 : 引入IO线程池处理网络read/write,主线程专注命令执行。实测10KB以上的Value,QPS提升73%。但命令执行依然是单线程,保证了原子性。