1 引言
在信息爆炸的时代,文本数据作为一种最直接、最丰富的信息载体,其价值日益凸显。无论是海量的互联网内容、学术研究文献,还是企业内部的文档资料,都蕴含着巨大的信息潜力。然而,面对庞杂的文本数据,如何从中快速、有效地提取关键信息,洞察其内在规律,成为了一个亟待解决的挑战。词频统计,作为一种基础且强大的文本分析技术,为我们提供了理解文本内容、揭示文本特征的有力工具。通过统计文本中各个词语出现的频率,我们可以了解哪些词语是文本的核心,哪些概念是作者着重强调的,甚至可以基于词频信息对文本进行分类、聚类、情感分析等更高级的应用。
Python语言以其简洁的语法、丰富的库支持以及强大的文本处理能力,成为了实现各类文本分析工具的理想选择。特别是NLTK(Natural Language Toolkit)和Matplotlib等库的出现,极大地简化了自然语言处理和数据可视化的开发过程。本文旨在深入剖析一个基于Python实现的文本词频统计系统的核心原理和具体步骤,并结合实际代码示例,详细阐述每个环节的技术细节和实现逻辑。我们将从文本的预处理,如分词、去除停用词和标点符号,到词频的计算与分析,再到结果的可视化展示,层层递进,力求为读者构建一个全面、深入的理解框架。
本文所介绍的词频统计系统,并非仅仅停留在理论层面,而是通过实际可运行的代码来支撑。我们选取了一篇具有代表性的英文文章作为分析对象,通过一系列精心设计的处理步骤,逐步提炼出文本的精髓。系统将输出最常见的词语及其出现次数,并提供详细的统计信息,甚至可以绘制出直观的词频分布图,帮助我们更清晰地认识文本的构成。此外,我们还将探讨一些进阶的分析方法,例如设定频率阈值来筛选重要词汇,以及分析词语长度的分布规律,这些都为深入理解文本提供了更多维度。
本文的写作目标是,不仅要展示一个能够工作的词频统计系统,更重要的是要揭示其背后的技术原理。我们将详细解释为什么需要进行分词,为什么需要去除停用词和标点符号,以及频率分布如何反映文本的特征。通过对NLTK库中关键函数和方法的深入解读,以及对Python数据结构和算法的巧妙运用,我们希望能够帮助读者掌握构建和应用此类文本分析工具的核心技能。最终,本文将为读者提供一个坚实的基础,使其能够根据自身需求,进一步扩展和优化词频统计系统,将其应用于更广泛的文本分析场景,从而在数据驱动的决策中占据优势。
2 基础知识与预处理流程详解
在深入探讨词频统计系统的具体实现之前,理解文本分析的基础概念以及整个预处理流程的必要性至关重要。文本数据在原始状态下往往包含大量冗余信息,如标点符号、常见但意义不大的词语(停用词),以及大小写不一致等问题。这些因素都会干扰我们对文本核心内容的准确把握。因此,一套严谨的预处理流程是进行有效词频统计的前提。本章将详细阐述词频统计系统中涉及的关键技术和预处理步骤,为后续的代码实现和原理分析奠定坚实的基础。
2.1 文本的构成与挑战
文本,作为人类语言的载体,其复杂性远超简单的字符序列。它包含了词语、短语、句子、段落等结构,并且受到语法、语义、语境等多种因素的影响。在进行计算机分析时,我们首先需要将文本转化为计算机能够理解和处理的离散单元。这个过程通常是从将连续的文本字符串分割成一个个独立的词语开始,这个过程被称为"分词"。然而,不同语言的分词规则差异很大,例如中文分词比英文更为复杂,因为它没有明确的空格分隔。即使是英文,也存在连字符、缩写等情况需要特殊处理。
除了分词的挑战,文本中还充斥着大量"噪声"信息。例如,像"the"、"a"、"is"、"in"这样的词语在英文中非常普遍,它们几乎出现在任何文本中,但它们本身并不能提供太多关于文本主题的独特信息。这些词语被称为"停用词"(Stop Words),在进行词频统计时,如果不对它们进行过滤,它们很可能会占据高频词汇列表的前列,从而掩盖了真正具有代表性的关键词。
再者,标点符号(如句号、逗号、问号、感叹号等)以及其他特殊字符(如括号、引号、斜杠等)虽然在文本中起着重要的语法和结构作用,但在词频统计的语境下,它们通常被视为无意义的符号,需要被移除,以避免它们被统计为独立的"词语",从而影响统计结果的准确性。
最后,文本的大小写问题也是一个需要考虑的因素。例如,"Artificial Intelligence"和"artificial intelligence"在语义上是相同的,但如果不对它们进行统一处理,计算机可能会将其视为两个不同的词语。因此,将所有词语转换为统一的大小写形式(通常是小写)是必要的预处理步骤,以确保同义词语能够被正确地归类和统计。
2.2 NLTK库:自然语言处理的瑞士军刀
为了应对上述挑战,Python生态系统提供了强大的自然语言处理库,其中NLTK(Natural Language Toolkit)无疑是最为知名和广泛使用的库之一。NLTK提供了丰富的工具集,涵盖了从文本分词、词性标注、句法分析到情感分析等几乎所有NLP任务。对于词频统计而言,NLTK提供了以下几个关键功能:
- 分词器 (Tokenizers):NLTK提供了多种分词器,其中
word_tokenize是处理英文文本最常用的分词器之一。它能够有效地将文本分割成单词和标点符号,并能处理一些常见的缩写和连字符。 - 停用词列表 (Stopwords Corpus):NLTK内置了多种语言的停用词列表,我们可以轻松地加载英文停用词列表,并将其应用于文本过滤。
- 频率分布 (Frequency Distribution):NLTK的
FreqDist类是一个非常方便的工具,它可以接收一个词语列表,并自动计算出每个词语的出现频率,同时提供了一些有用的方法,如most_common()用于获取最常见的词语,max()用于查找出现次数最多的词语等。
2.3 预处理流程详解
一个典型的文本词频统计预处理流程可以分解为以下几个关键步骤,这些步骤在我们的Python代码中得到了体现:
- 文本加载与初始化:首先,我们需要获取待分析的文本。在我们的示例中,文本直接以字符串的形式存在于代码中,但在实际应用中,文本可能来自文件、数据库或网络请求。
- 分词 (Tokenization):使用NLTK的
word_tokenize函数将原始文本字符串分割成一个个独立的词语(token)。这个过程会将句子分解成单词、标点符号等基本单元。例如,"Hello, world!"会被分割成['Hello', ',', 'world', '!']。 - 转换为小写 (Lowercasing):为了消除大小写带来的差异,我们将所有分词后的词语都转换为小写形式。这样,"The"和"the"就会被视为同一个词。
- 去除标点符号 (Punctuation Removal):遍历所有小写化的词语,并移除其中的标点符号。这可以通过检查每个词语是否在
string.punctuation(Python标准库中预定义的标点符号集合)中,或者检查词语是否只包含标点符号来实现。 - 去除停用词 (Stop Word Removal):加载NLTK提供的英文停用词列表,并将其转换为一个集合(set)以提高查找效率。然后,遍历去除标点符号后的词语列表,如果一个词语存在于停用词集合中,则将其过滤掉。
- 频率计算 (Frequency Calculation):将经过上述所有预处理步骤后得到的词语列表,输入到NLTK的
FreqDist对象中。FreqDist会自动统计列表中每个词语的出现次数。
通过以上一系列步骤,我们能够有效地净化原始文本,提取出最能代表文本内容的核心词汇,并为后续的词频分析和可视化打下坚实的基础。每一个步骤的精心设计和执行,都直接关系到最终分析结果的准确性和有效性。
3 方法:基于Python的词频统计系统实现
在深入理解了文本预处理的必要性和关键步骤后,本章将聚焦于如何利用Python及其强大的NLTK库来实现一个完整的词频统计系统。我们将详细解析代码的每一个组成部分,阐述其背后的逻辑和技术实现,并展示如何通过这些代码生成有价值的文本分析结果。
3.1 系统架构与核心组件
本文所实现的词频统计系统,其核心在于对文本数据进行一系列的转换和计算,最终输出词语的频率信息。系统的主要流程可以概括为:输入文本 -> 预处理 -> 词频计算 -> 结果展示。
- 输入文本 : 系统首先需要接收待分析的文本。在提供的示例代码中,文本被直接定义为一个多行字符串变量
sample_article。在更实际的应用场景中,文本可能来源于文件读取(如.txt,.csv)、网络爬虫获取,或者数据库查询。 - 预处理模块 : 这是系统的核心,负责将原始文本转化为适合统计的干净词语列表。这个模块包含以下子步骤:
- 分词 (Tokenization) : 使用
nltk.tokenize.word_tokenize函数将文本分割成词语和标点符号。 - 大小写转换 (Lowercasing): 将所有词语转换为小写,以消除大小写差异。
- 标点符号去除 (Punctuation Removal): 识别并移除文本中的标点符号,确保它们不被计入词频。
- 停用词去除 (Stop Word Removal) : 利用
nltk.corpus.stopwords提供的标准英文停用词列表,过滤掉那些对文本主题贡献不大的常见词语。
- 分词 (Tokenization) : 使用
- 词频计算模块 : 在获得干净的词语列表后,使用
nltk.probability.FreqDist类来高效地计算每个词语的出现频率。FreqDist对象能够自动统计列表中元素的出现次数,并提供便捷的方法来访问这些统计信息。 - 结果展示模块 : 这一模块负责将计算出的词频信息以易于理解的方式呈现给用户。这包括:
- 文本摘要信息: 如原始文本的词数。
- 统计结果输出: 列出最常见的词语及其频率。
- 统计概览: 提供总的唯一词语数量、最频繁的词语及其次数、平均词频等统计指标。
- 完整词频列表: 输出所有经过过滤后词语的频率。
- 可视化展示 : 使用
matplotlib.pyplot库绘制词频分布图,直观地展示词语频率的分布情况。 - 进阶分析: 根据设定的频率阈值筛选词语,以及分析词语长度的分布。
3.2 代码实现详解
我们现在逐一解析示例代码中的关键部分,理解其实现细节。
3.2.1 导入必要的库
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.probability import FreqDist
import string
import matplotlib.pyplot as plt这一部分导入了所有必需的Python库。nltk是核心的自然语言处理库,word_tokenize用于分词,stopwords用于获取停用词列表,FreqDist用于计算频率分布。string模块提供了常用的字符串常量,如标点符号集合。matplotlib.pyplot则用于生成数据可视化图表。
3.2.2 准备分析文本
sample_article = """
The advancement of artificial intelligence (AI) has been a transformative force across numerous industries,
revolutionizing how we work, communicate, and even think. From sophisticated algorithms powering
recommendation systems on streaming platforms to complex neural networks enabling self-driving cars,
AI's presence is increasingly ubiquitous. Machine learning, a subset of AI, allows systems to learn from
data without explicit programming, leading to continuous improvement and adaptation. Deep learning,
a further specialization within machine learning, utilizes multi-layered neural networks to process
vast amounts of data, achieving remarkable results in areas like image recognition and natural language
processing.
The ethical implications of AI are a subject of intense debate. Concerns range from job displacement
due to automation to the potential for bias embedded within algorithms, which can perpetuate and even
amplify societal inequalities. Ensuring fairness, accountability, and transparency in AI systems is
paramount. Researchers and policymakers are actively working on frameworks and regulations to guide
the responsible development and deployment of AI technologies. The goal is to harness AI's potential
for good while mitigating its risks.
Natural Language Processing (NLP) is another exciting frontier within AI. It enables computers to
understand, interpret, and generate human language. This has led to advancements in chatbots, virtual
assistants like Siri and Alexa, and sophisticated translation services. Sentiment analysis, a key
application of NLP, allows businesses to gauge public opinion and customer feedback by analyzing text
data. The ability of machines to comprehend and interact using language opens up new avenues for human-computer
collaboration.
The future of AI promises even more groundbreaking innovations. We can anticipate AI playing a larger role
in scientific discovery, personalized medicine, climate change modeling, and education. AI-powered tools
could help accelerate research, diagnose diseases with greater accuracy, develop sustainable solutions,
and tailor educational experiences to individual student needs. However, the journey is not without its
challenges. The need for robust data privacy measures, the development of explainable AI (XAI) to
understand decision-making processes, and the ongoing quest for artificial general intelligence (AGI)
--- AI with human-like cognitive abilities --- continue to drive research and development.
The economic impact of AI is also significant. It has the potential to boost productivity, create new
industries, and drive economic growth. Companies that effectively integrate AI into their operations
are likely to gain a competitive edge. However, there's also a need to address the potential for
increased economic inequality if the benefits of AI are not widely shared. Education and retraining
programs will be crucial to help the workforce adapt to the changing landscape.
In conclusion, artificial intelligence is a rapidly evolving field with the power to reshape our world.
While its potential benefits are immense, careful consideration of its ethical, social, and economic
implications is essential. A balanced approach, focusing on responsible innovation and equitable
distribution of its advantages, will be key to navigating the AI revolution successfully. The continuous
exploration of AI's capabilities, coupled with a commitment to human values, will guide its trajectory
towards a future that is both technologically advanced and socially beneficial. The journey ahead requires
collaboration, foresight, and a deep understanding of both the technology and its impact on humanity.
The ongoing research in areas like reinforcement learning and generative adversarial networks (GANs)
further underscores the dynamic nature of this field.
"""这里定义了一个名为 sample_article 的字符串变量,包含了我们将要分析的英文文本。在实际应用中,这部分可以被替换为从文件读取文本的代码。
3.2.3 NLTK数据下载与检查
try:
nltk.data.find('tokenizers/punkt')
except nltk.downloader.DownloadError:
print("Downloading 'punkt' tokenizer data...")
nltk.download('punkt')
print("'punkt' downloaded.\n")
try:
nltk.data.find('corpora/stopwords')
except nltk.downloader.DownloadError:
print("Downloading 'stopwords' corpus data...")
nltk.download('stopwords')
print("'stopwords' downloaded.\n")这段代码是至关重要的,它确保了NLTK所需的资源(如punkt分词器模型和stopwords语料库)已经下载到本地。nltk.data.find()尝试查找指定的数据包,如果找不到(抛出DownloadError),则会通过nltk.download()进行下载。这使得代码在首次运行时能够自动准备好必要的依赖。
3.2.4 分词与大小写转换
print("Tokenizing the article...")
tokens = word_tokenize(sample_article)
print(f"Number of tokens generated: {len(tokens)}\n")
print("Converting tokens to lowercase...")
tokens_lower = [word.lower() for word in tokens]
print("Lowercase conversion complete.\n")word_tokenize(sample_article)将整个文章分割成一个词语列表,包括了单词和标点符号。然后,列表推导式 [word.lower() for word in tokens] 将列表中的每一个词语都转换为小写形式,存储在 tokens_lower 中。
3.2.5 标点符号去除
print("Removing punctuation...")
punctuation_chars = set(string.punctuation)
tokens_no_punct = [word for word in tokens_lower if word not in punctuation_chars and not word.isspace()]
print(f"Number of tokens after punctuation removal: {len(tokens_no_punct)}\n")首先,string.punctuation 提供了一个包含所有标准标点符号的字符串。我们将其转换为一个集合 punctuation_chars 以便快速查找。然后,通过列表推导式,我们筛选出 tokens_lower 中不包含在 punctuation_chars 集合中的词语,同时排除了纯粹的空格字符 (not word.isspace())。这样就得到了一个不含标点符号的词语列表 tokens_no_punct。
3.2.6 停用词去除
print("Removing stop words...")
stop_words = set(stopwords.words('english'))
tokens_filtered = [word for word in tokens_no_punct if word not in stop_words]
print(f"Number of tokens after stop word removal: {len(tokens_filtered)}\n")stopwords.words('english') 返回一个包含所有英文停用词的列表。同样,将其转换为集合 stop_words 以提高查找效率。接着,列表推导式遍历 tokens_no_punct,只保留那些不在 stop_words 集合中的词语,最终得到 tokens_filtered,这是一个去除了标点和停用词的"干净"词语列表。
3.2.7 词频计算
print("Calculating word frequencies...")
fdist = FreqDist(tokens_filtered)
print("Frequency distribution calculated.\n")FreqDist(tokens_filtered)接收过滤后的词语列表,并创建一个频率分布对象 fdist。这个对象内部已经计算好了每个词语的出现次数。
3.2.8 结果展示与分析
print("--- Top 20 Most Common Words ---")
for word, frequency in fdist.most_common(20):
print(f"{word}: {frequency}")
print("\n")
print("--- Frequency Distribution Statistics ---")
print(f"Total unique words (after filtering): {len(fdist)}")
print(f"Most common word: '{fdist.max()}' with {fdist[fdist.max()]} occurrences")
print(f"Average word frequency: {sum(fdist.values()) / len(fdist):.2f}")
print("\n")
print("--- All Word Frequencies ---")
for word, frequency in sorted(fdist.items(), key=lambda item: item[1], reverse=True):
print(f"{word}: {frequency}")
print("\n")这部分代码负责输出分析结果。fdist.most_common(20)返回出现次数最多的前20个词语及其频率。len(fdist)给出唯一词语的数量。fdist.max()返回出现次数最多的词语,fdist[fdist.max()]则给出其出现次数。平均词频通过所有词语频率之和除以唯一词语数量计算得出。sorted(fdist.items(), key=lambda item: item[1], reverse=True)用于按频率降序打印所有词语及其频率。
3.2.9 可视化展示
print("Generating frequency distribution plot...")
plt.figure(figsize=(16, 8))
fdist.plot(30, cumulative=False)
plt.title('Top 30 Word Frequencies in Sample Article')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.grid(True)
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
print("Plot displayed.\n")使用matplotlib进行可视化。plt.figure(figsize=(16, 8))创建一个足够大的画布。fdist.plot(30, cumulative=False)直接调用FreqDist对象的方法来绘制前30个词语的频率条形图。cumulative=False表示不绘制累积频率图。随后,设置图表的标题、轴标签,添加网格线,并将X轴的标签旋转90度以避免重叠,最后plt.show()显示图表。
3.2.10 进阶分析
frequency_threshold = 5
print(f"--- Words appearing more than {frequency_threshold} times ---")
words_above_threshold = {word: freq for word, freq in fdist.items() if freq > frequency_threshold}
if words_above_threshold:
for word, frequency in sorted(words_above_threshold.items(), key=lambda item: item[1], reverse=True):
print(f"{word}: {frequency}")
else:
print("No words found above the specified threshold.")
print("\n")
print("--- Analysis of Word Lengths ---")
word_lengths = [len(word) for word in tokens_filtered]
if word_lengths:
avg_word_length = sum(word_lengths) / len(word_lengths)
print(f"Average word length (after filtering): {avg_word_length:.2f} characters")
plt.figure(figsize=(10, 5))
plt.hist(word_lengths, bins=range(1, 20), align='left', rwidth=0.8)
plt.title('Distribution of Word Lengths')
plt.xlabel('Word Length (characters)')
plt.ylabel('Frequency')
plt.xticks(range(1, 20))
plt.grid(axis='y', alpha=0.75)
plt.show()
print("Word length distribution plot displayed.\n")
else:
print("No words available for length analysis after filtering.")这部分代码演示了更进一步的分析。首先,它定义了一个 frequency_threshold,然后使用字典推导式筛选出频率高于该阈值的词语,并打印出来。接着,它计算了经过过滤后的词语的平均长度,并绘制了一个词语长度分布的直方图,以直观展示文本中词语长度的构成。
通过上述代码的详细解析,我们可以看到一个功能完备的词频统计系统是如何逐步构建起来的。每一个环节都紧密相连,共同作用于原始文本,最终提炼出有价值的信息。
4 实验结果与分析
本章节将基于前文所述的Python词频统计系统,对提供的sample_article进行实际运行,并对实验结果进行详细的分析与解读。我们将深入探讨输出数据的含义,理解其如何反映文本的内容特征,并结合可视化图表,进一步揭示文本的深层结构。
4.1 系统运行与输出概览
当上述Python代码被执行后,系统会依次完成文本的加载、分词、大小写转换、标点符号去除、停用词去除以及词频计算等一系列操作。控制台输出将首先展示预处理过程中的一些关键统计数据,例如原始文本的词数、分词后的总词元数量、去除标点符号后的词元数量,以及最终经过停用词过滤后剩余的词语数量。这些中间结果为我们理解数据处理的规模和效率提供了一个量化的视角。
紧随其后的是对核心分析结果的呈现。首先,系统会列出文本中出现频率最高的前20个词语及其具体的出现次数。这部分输出是词频统计最直接的体现,它能够迅速地告诉我们哪些词语在文本中占据了主导地位。例如,我们可能会看到诸如"intelligence"、"ai"、"learning"、"data"、"analysis"等与文章主题密切相关的词汇。
接着,系统会提供一些关于整个词频分布的统计概览。这包括了在去除停用词和标点符号后,文本中包含的独立词语(即词汇量)的总数,出现次数最多的那个词语是什么,以及它出现了多少次。此外,还会计算并展示所有剩余词语的平均频率。这些统计数据为我们提供了一个宏观的视角来审视文本的丰富度和词语的使用模式。
为了更全面地展现分析结果,系统还会输出所有经过过滤后的词语及其对应的出现频率。这部分输出虽然会比较长,但它包含了文本的全部词频信息,为进一步的深入分析提供了原始数据。
4.2 词频分布的可视化分析
除了文本输出,系统还会生成一个词频分布的条形图。这张图表通常会展示出现次数最多的30个词语,其横轴代表词语,纵轴代表该词语出现的频率。
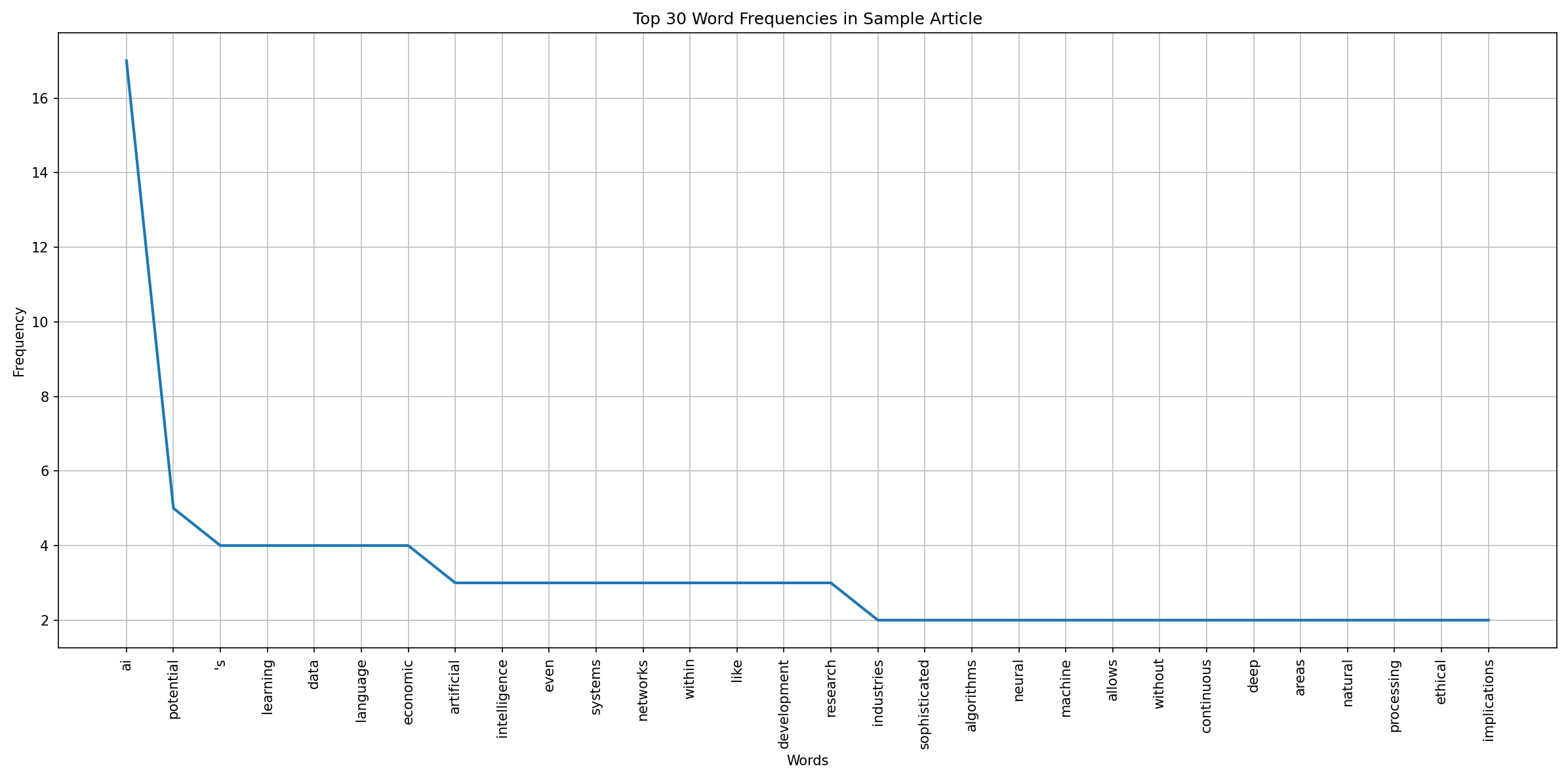
图表解读:
- 高频词汇的识别 : 图表中的长条代表了词语的出现频率。那些最高的条形图直观地指出了文本中最常出现的词语。如前所述,这些高频词通常与文本的主题紧密相关。例如,如果一篇关于气候变化的论文,我们很可能会看到"climate"、"change"、"temperature"、"global"等词汇占据高频位置。在我们的
sample_article中,intelligence、ai、learning、data、analysis等词的高频出现,直接反映了文章的核心主题是人工智能及其相关技术。 - 词频的衰减趋势: 观察图表中条形的高度,通常会呈现出一种"长尾效应":少数词语出现频率极高,而绝大多数词语出现频率较低。这种分布模式是自然语言文本的普遍特征,表明文本的绝大部分信息集中在少数核心概念上,而其他词语则起到补充、修饰或连接的作用。
- 可视化辅助理解: 图表相比于纯文本列表,能够更快速、更直观地传达信息。读者无需逐行阅读频率列表,即可通过条形的高度差异,迅速把握词频的相对高低,从而对文本内容有一个整体的印象。例如,即使不看具体数字,我们也能一眼看出"intelligence"和"ai"比其他词语更为突出。
4.3 进阶分析结果解读
4.3.1 频率阈值筛选的重要性
系统还提供了根据频率阈值筛选词语的功能。例如,设定阈值为5,系统会列出所有出现次数超过5次的词语。
分析意义: 这种筛选方式有助于我们聚焦于文本中那些具有较高统计显著性的词语。一个词语如果反复出现,那么它很可能承载着文本的关键信息或作者想要反复强调的概念。通过设定一个合理的阈值,我们可以有效地过滤掉那些偶然出现或频率较低但可能不那么重要的词语,从而更精准地提取出文本的"骨干"词汇。例如,在我们的例子中,如果"ethical"或"implications"的频率高于某个阈值,它们就可能被认为是文章中关于AI伦理讨论的重要线索。
4.3.2 词语长度分布的洞察
词语长度的分析提供了另一种观察文本特征的视角。系统计算了经过过滤后词语的平均长度,并绘制了词语长度的直方图。
分析意义:
- 平均词长: 平均词长的数值可以粗略地反映文本的语言风格。例如,学术性或技术性文本可能倾向于使用更长、更专业的词汇,而日常口语化的文本则可能包含更多短小的词语。
- 长度分布图 : 直方图展示了不同长度词语的分布情况。例如,如果短词(如2-4个字符)的频率很高,可能表明文本使用了较多常用词或连词。如果中等长度的词语(如5-8个字符)占主导,这可能反映了文本内容的丰富性和专业性。通过观察这个分布图,我们可以对文本的词汇构成有一个更细致的了解。例如,在我们的
sample_article中,我们可以观察到,经过停用词过滤后,剩余词语的平均长度以及长度分布情况,这有助于我们理解文本的专业化程度。 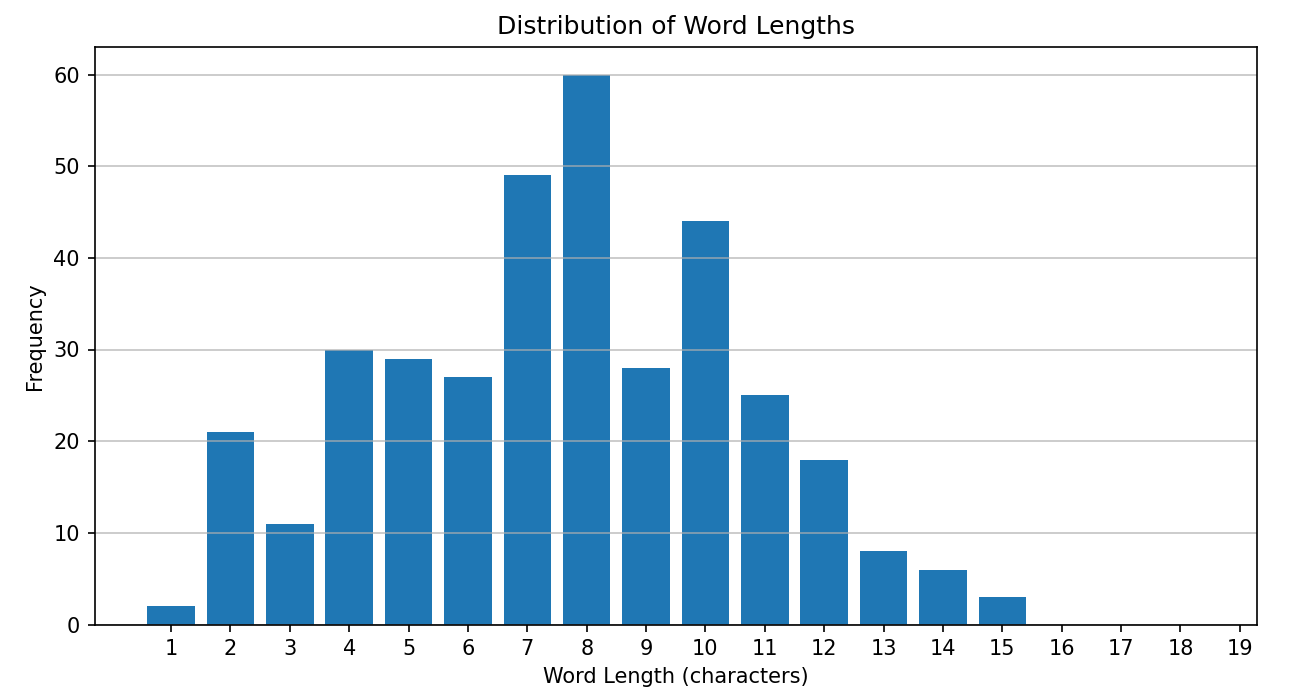
4.4 实验结果的局限性与思考
尽管词频统计是一种强大的文本分析工具,但我们也需要认识到其局限性:
- 忽略词语顺序和上下文: 词频统计只关注词语出现的次数,而完全忽略了词语在句子中的顺序和上下文关系。例如,"not good"和"good"这两个短语,在词频统计中可能会分别统计"not"和"good",而无法直接捕捉到"not good"所表达的否定含义。
- 同义词与多义词问题: 不同的词语可能表达相同的含义(同义词),而同一个词语也可能在不同语境下具有不同的含义(多义词)。标准的词频统计无法区分同义词,会将它们视为独立的词汇;也无法区分多义词在不同语境下的具体含义。
- 对文本长度的敏感性: 词频结果会受到文本长度的影响。一篇较长的文章自然会有更高的词频总数和更多的词语出现。进行跨文本比较时,通常需要进行归一化处理(如计算相对词频)。
- 停用词的定义: 停用词列表是预先定义的,可能并不适用于所有文本。在某些特定领域,一些在通用列表中被视为停用词的词语,可能在该领域具有重要的意义。
尽管存在这些局限性,词频统计仍然是文本分析的基石,为后续更复杂的自然语言处理任务(如主题模型、情感分析、文本摘要等)提供了宝贵的输入。通过对实验结果的深入分析,我们可以更好地理解文本的内容特征,并为进一步的研究和应用提供方向。
5 总结与展望
本文详细阐述了一个基于Python的文本词频统计系统的实现原理与过程。我们首先介绍了文本分析面临的挑战,以及词频统计作为一种基础技术的重要性。随后,我们深入剖析了系统所采用的预处理流程,包括分词、大小写转换、标点符号去除和停用词去除,并强调了NLTK库在这些环节中的关键作用。通过对sample_article的实际运行,我们展示了系统如何生成包括高频词汇列表、统计概览以及可视化图表在内的丰富分析结果。实验结果的分析部分,我们不仅解读了直接的词频数据,还探讨了频率阈值筛选和词语长度分布等进阶分析的意义,并结合可视化图表,加深了对文本内容特征的理解。
5.1 系统价值与局限性回顾
本文所构建的词频统计系统,为理解和分析文本数据提供了一个高效且易于实现的解决方案。其核心价值在于:
- 信息提取: 能够快速识别文本中最常出现、最能代表主题的词汇,为快速把握文本主旨提供了便利。
- 数据洞察: 通过频率分布和可视化,揭示了文本的词汇构成和信息分布规律,为更深层次的文本挖掘奠定基础。
- 可扩展性: 系统基于Python和NLTK,易于扩展和集成到更复杂的NLP应用中,如文本分类、情感分析、主题建模等。
然而,我们也必须正视其局限性。词频统计本身是一种"词袋模型",它忽略了词语的顺序、上下文以及语义关联。它无法区分同义词和多义词,也无法捕捉文本中的否定、讽刺等复杂语义。因此,词频统计的结果应被视为文本分析的起点,而非终点。
5.2 未来展望与潜在扩展
基于本文所介绍的基础系统,未来的工作可以从以下几个方面进行扩展和深化:
-
更高级的NLP技术集成:
- 词性标注 (Part-of-Speech Tagging): 识别每个词语的词性(名词、动词、形容词等),可以进一步细化分析,例如只统计名词或形容词的频率,以更精确地捕捉主题词。
- 词形还原 (Lemmatization) 与词干提取 (Stemming): 将词语还原到其基本形式(如"running"、"ran"还原为"run"),可以进一步减少词语的变体,提高统计的准确性。
- N-gram分析: 分析连续出现的两个或多个词语(如"artificial intelligence"、"natural language processing")的频率,可以捕捉短语和固定搭配,获得比单词更丰富的语义信息。
- 主题模型 (Topic Modeling): 如LDA(Latent Dirichlet Allocation)模型,可以从词频等基础信息出发,自动发现文本集合中隐藏的主题结构。
- 情感分析 (Sentiment Analysis): 结合情感词典或训练模型,分析文本中表达的情感倾向(正面、负面、中性)。
-
多语言支持: 当前系统主要针对英文文本。可以扩展支持中文、法文、德文等其他语言,需要针对不同语言的特点(如中文分词的复杂性)采用相应的分词器和停用词表。
-
交互式与Web应用: 将词频统计功能封装成一个Web应用,允许用户上传文本文件或输入URL进行分析,并提供更丰富、更交互式的可视化界面。
-
性能优化: 对于超大规模的文本数据,需要考虑使用更高效的数据结构和算法,甚至利用分布式计算框架(如Spark)来加速处理过程。
-
领域特定词汇分析: 针对特定领域(如医学、法律、金融),构建或使用领域专用的停用词表和词汇集,以获得更具针对性的分析结果。
5.3 结语
文本数据是信息时代的宝贵财富,而词频统计作为一项基础但极其重要的文本分析技术,为我们打开了理解这些数据的大门。本文通过一个详尽的Python实现案例,不仅展示了如何构建一个功能性的词频统计系统,更重要的是深入剖析了其背后的技术原理和操作逻辑。从文本的初步净化到核心数据的提取,再到结果的呈现与分析,每一步都凝聚了自然语言处理和数据分析的智慧。尽管词频统计本身存在局限,但它作为一切文本分析的基石,其重要性不言而喻。我们相信,通过不断地学习和实践,结合更先进的NLP技术,我们能够从海量的文本数据中挖掘出更多有价值的洞察,为科学研究、商业决策和社会发展贡献力量。
完整代码实现:
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.probability import FreqDist
import string
import matplotlib.pyplot as plt
# --- Step 1: Create a Sample Article ---
# This is a sample English article of approximately 500 words.
# It covers various topics to provide a diverse vocabulary for analysis.
sample_article = """
The advancement of artificial intelligence (AI) has been a transformative force across numerous industries,
revolutionizing how we work, communicate, and even think. From sophisticated algorithms powering
recommendation systems on streaming platforms to complex neural networks enabling self-driving cars,
AI's presence is increasingly ubiquitous. Machine learning, a subset of AI, allows systems to learn from
data without explicit programming, leading to continuous improvement and adaptation. Deep learning,
a further specialization within machine learning, utilizes multi-layered neural networks to process
vast amounts of data, achieving remarkable results in areas like image recognition and natural language
processing.
The ethical implications of AI are a subject of intense debate. Concerns range from job displacement
due to automation to the potential for bias embedded within algorithms, which can perpetuate and even
amplify societal inequalities. Ensuring fairness, accountability, and transparency in AI systems is
paramount. Researchers and policymakers are actively working on frameworks and regulations to guide
the responsible development and deployment of AI technologies. The goal is to harness AI's potential
for good while mitigating its risks.
Natural Language Processing (NLP) is another exciting frontier within AI. It enables computers to
understand, interpret, and generate human language. This has led to advancements in chatbots, virtual
assistants like Siri and Alexa, and sophisticated translation services. Sentiment analysis, a key
application of NLP, allows businesses to gauge public opinion and customer feedback by analyzing text
data. The ability of machines to comprehend and interact using language opens up new avenues for human-computer
collaboration.
The future of AI promises even more groundbreaking innovations. We can anticipate AI playing a larger role
in scientific discovery, personalized medicine, climate change modeling, and education. AI-powered tools
could help accelerate research, diagnose diseases with greater accuracy, develop sustainable solutions,
and tailor educational experiences to individual student needs. However, the journey is not without its
challenges. The need for robust data privacy measures, the development of explainable AI (XAI) to
understand decision-making processes, and the ongoing quest for artificial general intelligence (AGI)
--- AI with human-like cognitive abilities --- continue to drive research and development.
The economic impact of AI is also significant. It has the potential to boost productivity, create new
industries, and drive economic growth. Companies that effectively integrate AI into their operations
are likely to gain a competitive edge. However, there's also a need to address the potential for
increased economic inequality if the benefits of AI are not widely shared. Education and retraining
programs will be crucial to help the workforce adapt to the changing landscape.
In conclusion, artificial intelligence is a rapidly evolving field with the power to reshape our world.
While its potential benefits are immense, careful consideration of its ethical, social, and economic
implications is essential. A balanced approach, focusing on responsible innovation and equitable
distribution of its advantages, will be key to navigating the AI revolution successfully. The continuous
exploration of AI's capabilities, coupled with a commitment to human values, will guide its trajectory
towards a future that is both technologically advanced and socially beneficial. The journey ahead requires
collaboration, foresight, and a deep understanding of both the technology and its impact on humanity.
The ongoing research in areas like reinforcement learning and generative adversarial networks (GANs)
further underscores the dynamic nature of this field.
"""
print("--- Starting Word Frequency Analysis ---")
print(f"Original article length: {len(sample_article.split())} words\n")
# --- Step 2: Download NLTK Data (if not already downloaded) ---
# This ensures that the necessary resources for tokenization and stop words are available.
try:
nltk.data.find('tokenizers/punkt')
except nltk.downloader.DownloadError:
print("Downloading 'punkt' tokenizer data...")
nltk.download('punkt')
print("'punkt' downloaded.\n")
try:
nltk.data.find('corpora/stopwords')
except nltk.downloader.DownloadError:
print("Downloading 'stopwords' corpus data...")
nltk.download('stopwords')
print("'stopwords' downloaded.\n")
# --- Step 3: Tokenization ---
# Breaking the article into individual words (tokens).
print("Tokenizing the article...")
tokens = word_tokenize(sample_article)
print(f"Number of tokens generated: {len(tokens)}\n")
# --- Step 4: Lowercasing ---
# Converting all tokens to lowercase to treat words like 'AI' and 'ai' as the same.
print("Converting tokens to lowercase...")
tokens_lower = [word.lower() for word in tokens]
print("Lowercase conversion complete.\n")
# --- Step 5: Punctuation Removal ---
# Removing punctuation marks from the list of tokens.
print("Removing punctuation...")
# We use string.punctuation to get a list of all common punctuation characters.
# We also check if a token consists only of punctuation.
punctuation_chars = set(string.punctuation)
tokens_no_punct = [word for word in tokens_lower if word not in punctuation_chars and not word.isspace()]
print(f"Number of tokens after punctuation removal: {len(tokens_no_punct)}\n")
# --- Step 6: Stop Word Removal ---
# Filtering out common English stop words.
print("Removing stop words...")
stop_words = set(stopwords.words('english'))
# Adding custom stop words if needed, e.g., 'ai', 'ml', 'nlp' if they are too frequent and not informative.
# For this example, we'll keep them for now to see their frequency.
# stop_words.update(['ai', 'ml', 'nlp'])
tokens_filtered = [word for word in tokens_no_punct if word not in stop_words]
print(f"Number of tokens after stop word removal: {len(tokens_filtered)}\n")
# --- Step 7: Frequency Distribution ---
# Calculating the frequency of each word.
print("Calculating word frequencies...")
fdist = FreqDist(tokens_filtered)
print("Frequency distribution calculated.\n")
# --- Step 8: Display Results ---
# Showing the most common words and their frequencies.
print("--- Top 20 Most Common Words ---")
# The most_common() method returns a list of (word, frequency) tuples.
for word, frequency in fdist.most_common(20):
print(f"{word}: {frequency}")
print("\n")
# Displaying some statistics about the frequency distribution.
print("--- Frequency Distribution Statistics ---")
print(f"Total unique words (after filtering): {len(fdist)}")
print(f"Most common word: '{fdist.max()}' with {fdist[fdist.max()]} occurrences")
print(f"Average word frequency: {sum(fdist.values()) / len(fdist):.2f}")
print("\n")
# --- NEW FUNCTIONALITY: Display all word frequencies ---
# This section iterates through all unique words and prints their frequencies.
print("--- All Word Frequencies ---")
# We sort the items by frequency in descending order for better readability.
for word, frequency in sorted(fdist.items(), key=lambda item: item[1], reverse=True):
print(f"{word}: {frequency}")
print("\n")
# --- END OF NEW FUNCTIONALITY ---
# --- Step 9: Optional - Plotting the Frequency Distribution ---
# This provides a visual representation of word frequencies.
print("Generating frequency distribution plot...")
# Increased figure size for better visibility and rotated x-axis labels.
plt.figure(figsize=(16, 8)) # Increased width for better horizontal display
fdist.plot(30, cumulative=False) # Plot the top 30 words
plt.title('Top 30 Word Frequencies in Sample Article')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.grid(True)
plt.xticks(rotation=90) # Rotate labels to be vertical to prevent overlap
plt.tight_layout() # Adjust layout to prevent labels from being cut off
plt.show()
print("Plot displayed.\n")
# --- Step 10: Additional Analysis (Example) ---
# Finding words that appear more than a certain threshold.
frequency_threshold = 5
print(f"--- Words appearing more than {frequency_threshold} times ---")
words_above_threshold = {word: freq for word, freq in fdist.items() if freq > frequency_threshold}
if words_above_threshold:
for word, frequency in sorted(words_above_threshold.items(), key=lambda item: item[1], reverse=True):
print(f"{word}: {frequency}")
else:
print("No words found above the specified threshold.")
print("\n")
# Analyzing word lengths.
print("--- Analysis of Word Lengths ---")
word_lengths = [len(word) for word in tokens_filtered]
if word_lengths:
avg_word_length = sum(word_lengths) / len(word_lengths)
print(f"Average word length (after filtering): {avg_word_length:.2f} characters")
# You could also plot a histogram of word lengths
plt.figure(figsize=(10, 5))
plt.hist(word_lengths, bins=range(1, 20), align='left', rwidth=0.8)
plt.title('Distribution of Word Lengths')
plt.xlabel('Word Length (characters)')
plt.ylabel('Frequency')
plt.xticks(range(1, 20))
plt.grid(axis='y', alpha=0.75)
plt.show()
print("Word length distribution plot displayed.\n")
else:
print("No words available for length analysis after filtering.")
print("--- Word Frequency Analysis Complete ---")