什么是机器学习?------ 用 "买西瓜" 讲透核心逻辑
快速导读
- 难度:入门
- 位置:第 1 篇
- 读完可接:第 2 篇《机器学习基本术语大拆解 ------ 用西瓜数据集逐个对应》

文章目录
- [什么是机器学习?------ 用 "买西瓜" 讲透核心逻辑](#什么是机器学习?—— 用 “买西瓜” 讲透核心逻辑)
-
- 快速导读
- [一、先看人类怎么 "学习" 挑西瓜](#一、先看人类怎么 “学习” 挑西瓜)
-
- [1. 积累 "数据"------ 收集经验](#1. 积累 “数据”—— 收集经验)
- [2. 总结 "规律"------ 训练模型](#2. 总结 “规律”—— 训练模型)
- [3. 判断 "新瓜"------ 模型预测](#3. 判断 “新瓜”—— 模型预测)
- 二、机器学习的官方定义(用人话翻译)
- 三、机器学习和传统编程的区别(用挑西瓜对比)
- 四、机器学习能做什么?不止挑西瓜
- 五、小结:机器学习的核心逻辑一句话总结
一、先看人类怎么 "学习" 挑西瓜
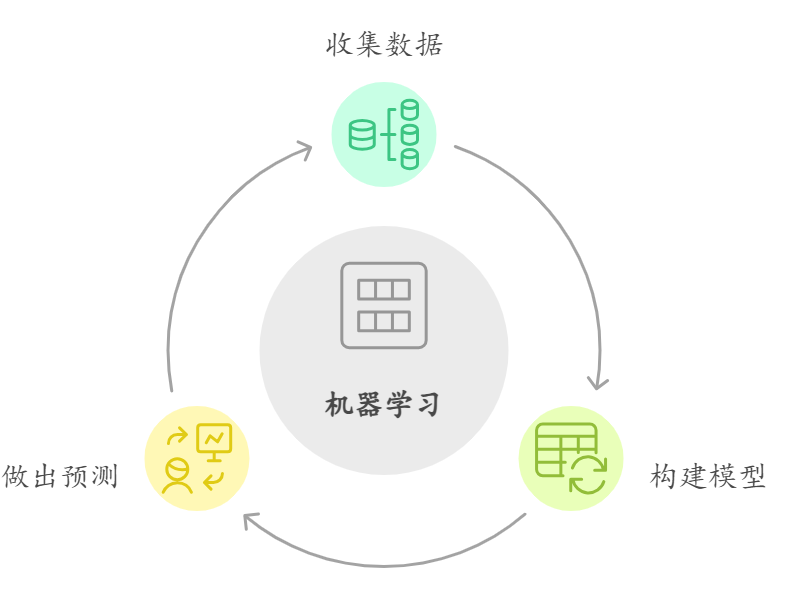
你之所以能快速挑到好瓜,背后藏着三个关键步骤,这和机器学习的核心流程完全对应:
1. 积累 "数据"------ 收集经验
你第一次买西瓜时可能不懂分辨,要么听老板推荐,要么凭感觉选。但买的次数多了,就会默默记下各种 "线索":
- 色泽:青绿的好像比浅白的好;
- 根蒂:蜷缩的比硬挺的甜;
- 敲声:浊响的比清脆的熟得透。
这些你记在心里的 "线索 + 结果"(比如 "青绿 + 蜷缩 + 浊响 = 好瓜"),就是机器学习里的 "数据"------ 计算机学习的基础,就是大量这样带 "线索" 和 "结果" 的记录。
2. 总结 "规律"------ 训练模型
买的西瓜多了,你会不自觉地总结出一套 "挑瓜规则":
如果 色泽 = 青绿 AND 根蒂 = 蜷缩 AND 敲声 = 浊响 → 好瓜;如果 色泽 = 浅白 OR 根蒂 = 硬挺 → 大概率是差瓜。
这个你大脑里总结出的 "规则集合",就是机器学习中的 "模型"。它不是凭空来的,而是从之前的 "数据" 中提炼出来的 ------ 计算机的核心工作,就是代替大脑做这个 "总结规律" 的过程。
3. 判断 "新瓜"------ 模型预测
下次再买瓜时,你不会再盲目尝试,而是直接用总结好的 "规则" 去套新瓜:看到一个青绿、蜷缩、浊响的瓜,立刻判断是好瓜,果断下手。
这个用 "旧规则判断新情况" 的过程,就是机器学习的 "预测"------ 模型训练好后,面对没见过的 "新数据",给出明确判断。
二、机器学习的官方定义(用人话翻译)
看完买西瓜的例子,再看机器学习的定义就好懂了:
机器学习是一门研究如何让计算机通过 "数据" 积累经验,自动生成 "模型"(规律),并利用模型对 "新数据" 做出准确预测的学科。
拆解成三个核心要素,还是和挑西瓜对应:
- 数据:计算机的 "经验"(比如 1000 个西瓜的色泽、根蒂、敲声和是否为好瓜的记录);
- 模型:计算机从数据中总结的 "规律"(可以是规则、公式、曲线等);
- 预测:用规律判断新数据(比如判断一个新西瓜是不是好瓜)。
这里要特别强调一个关键 ------泛化能力。你总结的挑瓜规则,不是为了记住 "上次那个青绿瓜是好瓜",而是为了判断 "所有没见过的瓜";计算机的模型也一样,核心不是 "记熟训练数据",而是 "举一反三" 处理新数据。如果一个模型只能记住训练过的西瓜,换个新瓜就判断错,那这个模型就是失败的(这叫 "过拟合",后面会详细讲)。
三、机器学习和传统编程的区别(用挑西瓜对比)
可能有人会问:"让程序员写个挑瓜规则的程序,不也能判断好瓜吗?"这就说到点子上了 ------ 机器学习和传统编程的核心区别,在于 "规律是谁总结的":
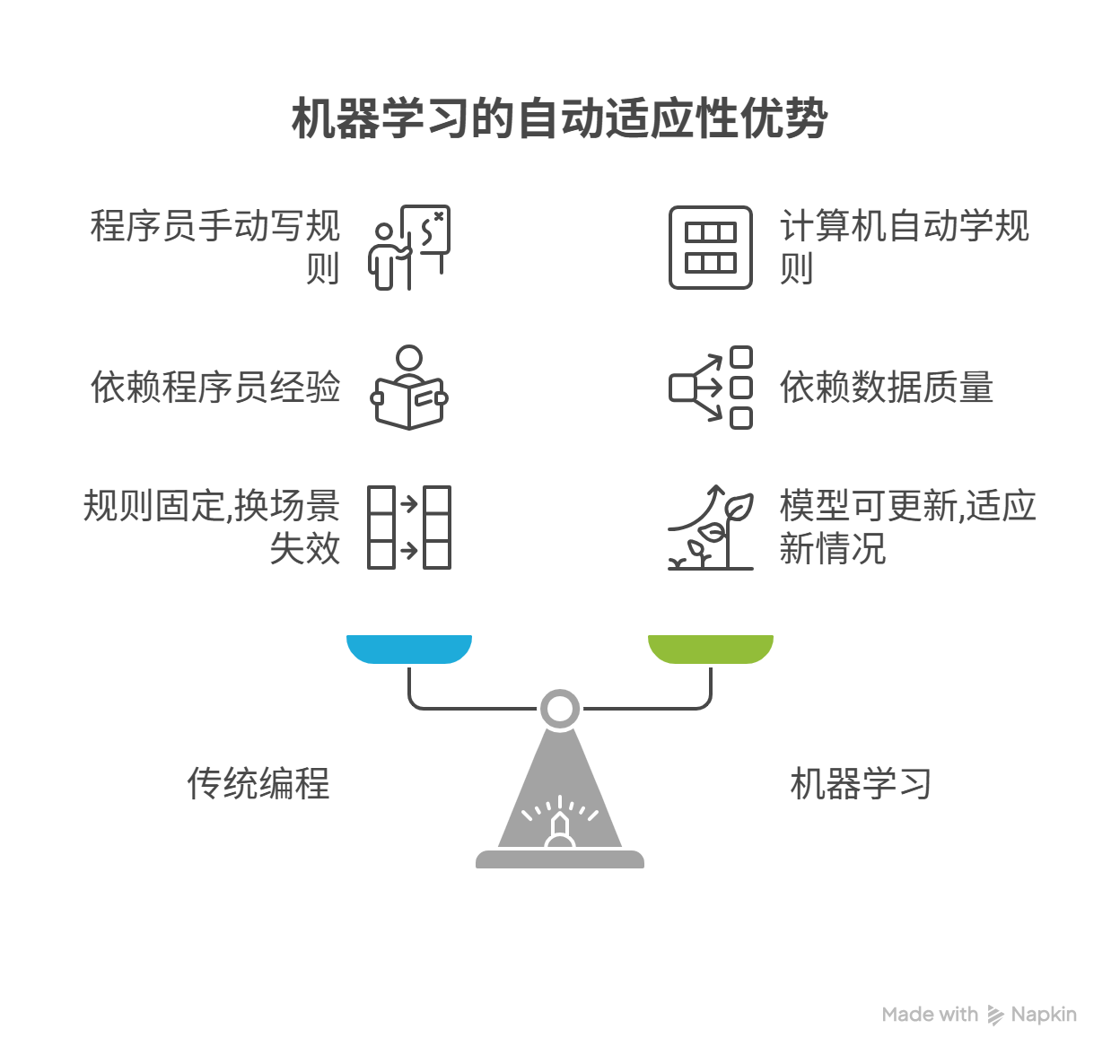
| 对比维度 | 传统编程 | 机器学习 |
|---|---|---|
| 核心逻辑 | 程序员手动写规则(比如 "青绿 + 蜷缩 = 好瓜") | 计算机从数据中自动学规则 |
| 依赖对象 | 程序员的经验(如果程序员不会挑瓜,程序就废了) | 数据的质量(数据越多、越准确,规则越靠谱) |
| 灵活性 | 规则固定,换场景就失效(比如换一种品种的瓜,规则就不准了) | 模型可更新,换数据就能学新规则 |
举个例子:如果西瓜品种变了,浅白的瓜也可能很甜。传统编程需要程序员重新修改规则;而机器学习只要给计算机喂新的 "浅白好瓜" 数据,它就能自动更新模型,不用人工干预 ------ 这就是机器学习的优势:自动适应新情况。
四、机器学习能做什么?不止挑西瓜
从挑西瓜的简单场景延伸出去,机器学习的应用遍布生活各处,核心都是 "从数据中找规律,预测新情况":
- 电商推荐:根据你之前的购买记录(数据),学出你的喜好(模型),推荐你可能想买的商品(预测);
- 自动驾驶:通过摄像头收集的路况数据(数据),学出 "看到红灯停、看到行人避让" 的规则(模型),处理新的路况(预测);
- 垃圾邮件识别:分析大量邮件内容(数据),学出垃圾邮件的特征(比如 "恭喜中奖""点击链接")(模型),判断新邮件是不是垃圾邮件(预测);
- 医疗诊断:根据病人的症状、检查数据(数据),学出疾病和症状的关联(模型),辅助医生判断病情(预测)。
这些场景看似复杂,但核心逻辑和挑西瓜完全一致 ------ 只是数据更复杂、模型更精密而已。
五、小结:机器学习的核心逻辑一句话总结
机器学习 = 数据(经验)+ 学习算法(总结规律的方法)+ 模型(规律)+ 预测(用规律判断新情况)。
它的本质,就是让计算机像人一样 "从经验中学习",不用程序员手动写死规则,就能自动适应不同场景 ------ 这也是为什么机器学习能成为当下最热门的技术之一:它让计算机具备了 "自主进化" 的能力。
下一篇,我们会拆解机器学习的核心术语,比如 "数据集、样本、特征、标签" 这些听起来专业的词,依然用西瓜数据集逐个对应,让你彻底搞懂每个概念的含义。
如果现在让你用 "挑西瓜" 的逻辑,想想你身边还有哪些场景能用机器学习解决?欢迎在评论区留言讨论~