预训练模型BERT
BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年提出的一种预训练语言模型,它在自然语言处理(NLP)领域引起了广泛的关注和应用。BERT的核心思想是通过双向Transformer编码器(双向的编码器部分)来捕捉文本中的上下文信息,从而生成更丰富的语言表示。
参考链接:https://cloud.tencent.com/developer/article/2481320
BERT模型结构
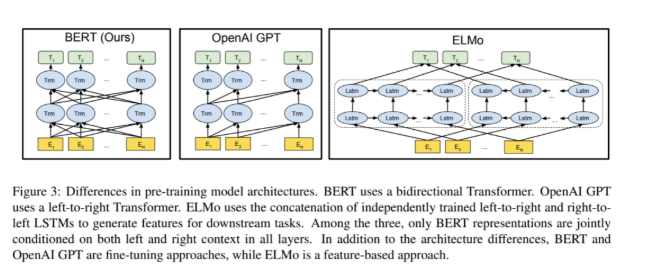
BERT基于Transformer架构,特别是Transformer的编码器部分。BERT使用了多层Transformer编码器堆叠在一起,每一层都包含多头自注意力机制和前馈神经网络。
BERT使用双向Transformer,OpenAI GPT使用从左到右的Transformer,而ELMo则使用独立训练的从左到右和从右到左的LSTM的拼接来为下游任务生成特征。在这三种模型中,只有BERT的表示在所有层中都同时依赖于左右上下文。
宏观上BERT分三个主要模块:
- 最底层黄色标记的Embedding模块.
- 中间层蓝色标记的Transformer模块.
- 最上层绿色标记的预微调模块.
Embedding模块
BERT中的该模块是由三种Embedding共同组成
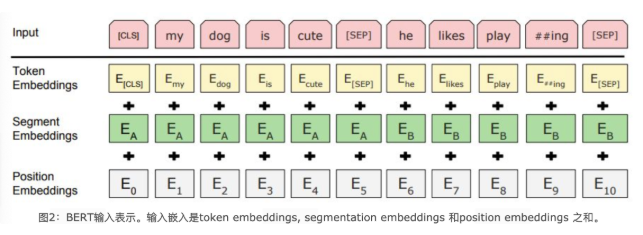
- Token Embeddings 是词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务
- Segment Embeddings 是句子分段嵌入张量, Segment Embedding 帮助模型区分句子之间的关系
- Position Embeddings 是位置编码张量, 和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得出来的
BERT 的输入表示是通过将上述三种 Embedding 相加得到的.
双向Transformer模块
BERT中只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分. 而两大预训练任务也集中体现在训练Transformer模块中。
预微调模块
经过中间层Transformer的处理后, BERT的最后一层根据任务的不同需求而做不同的调整
通常取最后一层输出的第一个位置(即CLS标记的表示),然后通过一个全连接层(Dense Layer)进行分类。
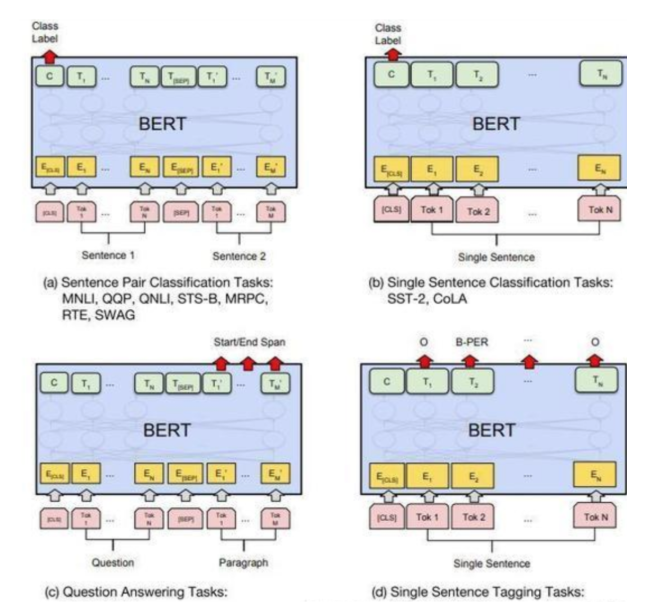
对于不同的任务, 微调都集中在预微调模块, 几种重要的NLP微调任务架构图:
- 句子对分类任务(Sentence Pair Classification Tasks)
- 单句子分类任务(Single Sentence Classification Tasks)
- 问答任务(Question Answering Tasks)
- 单句子标注任务(Single Sentence Tagging Tasks)
BERT的预训练方式
预训练(Pre-training)是大语言模型(如BERT、GPT)训练的第一阶段,其核心目标是通过自监督学习从海量无标注文本中学习通用的语言表示(Language Representation)。这一阶段的目标是让模型掌握语言的语法、语义、常识等基础能力,为后续的微调(Fine-tuning)打下基础。
BERT包含两个预训练任务,帮助模型学习到丰富的语言表示:
任务一: Masked LM (带mask的语言模型训练)
任务二: Next Sentence Prediction (下一句话预测任务)
任务一: Masked LM
带 Mask 的语言模型训练(Masked Language Model, MLM)是 BERT 的核心预训练任务之一。它的主要目的是通过遮蔽输入序列中的某些词,让模型根据上下文预测这些被遮蔽的词。MLM 的设计使得 BERT 能够学习到双向的上下文信息。
在原始训练文本中, 随机的抽取15%的token作为参与MASK任务的对象,在这些被选中的token中, 数据生成器并不是把它们全部变成MASK, 而是有下列3种情况:
- 在80%的概率下, 用MASK标记替换该token, 比如my dog is hairy -> my dog is MASK
- 在10%的概率下, 用一个随机的单词替换token, 比如my dog is hairy -> my dog is apple
- 在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
任务二: Next Sentence Prediction
在NLP中有一类重要的问题比如QA(Quention-Answer), NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务. 采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话。
所有参与任务训练的语句都被选中作为句子A,其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本),其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)。
GPT的预训练:因果语言建模CLM(Causal Language Modeling)
GPT的因果语言建模(CLM)通过单向自回归,擅长生成连贯文本,但无法利用后文,更适配"创作"任务;而BERT的掩码语言建模(MLM)类似双向"完形填空",更擅长上下文理解,适配"理解"任务。
在GPT的预训练中,模型使用因果语言建模(CLM)通过单向上下文(仅前文)预测下一个词(数学表达为 P(wt∣w1,...,wt−1)),像"逐字听写"或"打字机"一样,每次只能看到之前输入的内容,逐步生成后续文本。
GPT系列模型(GPT-1/2/3/4)均基于CLM,通过Transformer的单向注意力掩码实现。
(1)任务:基于前文预测下一个词,类似于人类逐字阅读文本的过程。
(2)示例:输入"The cat sits on the",模型需要预测下一个词是"mat"。
BERT微调以及在不同NLP任务中的应用
Bert 可以被微调以广泛用于各类任务,仅需额外添加一个输出层,无需进行针对任务的模型结构调整,就在文本分类,语义理解等一些任务上取得了 state-of-the-art 的成绩。
Bert 的论文中对预训练好的 Bert 模型设计了两种应用于具体领域任务的用法,一种是 fine-tune(微调) 方法,一种是 feature extract(特征抽取) 方法。
- fine tune(微调)方法指的是加载预训练好的 Bert 模型,其实就是一堆网络权重的值,把具体领域任务的数据集喂给该模型,在网络上继续反向传播训练,不断调整原有模型的权重,获得一个适用于新的特定任务的模型。这很好理解,就相当于利用 Bert 模型帮我们初始化了一个网络的初始权重,是一种常见的迁移学习手段。
- feature extract(特征抽取)方法指的是调用预训练好的 Bert 模型,对新任务的句子做句子编码,将任意长度的句子编码成定长的向量。编码后,作为你自己设计的某种模型(例如 LSTM、SVM 等都由你自己定)的输入,等于说将 Bert 作为一个句子特征编码器,这种方法没有反向传播过程发生,至于如果后续把定长句子向量输入到 LSTM 种继续反向传播训练,那就不关 Bert 的事了。这也是一种常见的语言模型用法,同类的类似 ELMo。
微调方法: BERT微调基于预训练-微调范式,首先在大规模无标注文本上进行预训练,学习通用语言表示,随后在特定任务的标注数据上进行微调以适应下游应用。
关键步骤包括:
- 输入表示:输入序列通过Tokenization转换为WordPiece编码,并融入词嵌入、位置嵌入和段落嵌入,以保留上下文信息。
- 预训练任务:核心为掩码语言建模(MLM)和下一句预测(NSP),其中MLM通过随机遮蔽15%的词汇(80%替换为MASK、10%为随机词、10%保持不变)迫使模型双向利用上下文预测被遮蔽内容。
- 微调过程:在下游任务中,加载预训练BERT参数后添加任务特定输出层(如分类头),并通过反向传播优化所有参数,使模型快速适应新任务。
在不同NLP任务中的应用: BERT通过微调在多种NLP任务中取得显著效果,其双向架构尤其擅长理解性任务。具体应用包括:
- 文本分类与情感分析:微调后可高效处理文档分类或情感倾向判断,例如在新闻分类或评论情感分析中表现优异。
- 命名实体识别(NER):通过序列标注输出识别文本中的实体(如人名、地点),在信息抽取场景中准确率高。
- 问答系统:BERT能深入理解问题与上下文的关系,精准定位答案片段,广泛应用于智能客服和知识库查询。
- 机器翻译与文本生成:虽非专为生成设计,但其上下文表示可辅助翻译质量提升或作为生成模型的组件。
- 搜索优化与内容推荐:在搜索引擎中理解查询意图,在推荐系统中分析用户偏好,提升相关性。