Java虚拟机的非堆内存
非堆内存是 JVM 规范中除 Java 堆(Heap)之外的所有内存区域的统称。
非堆内存包含多个区域,下面我将逐一介绍。
方法区
方法区(Method Area)是JVM 规范层面定义的一块所有线程共享的内存区域,并非具体实现,生命周期与 JVM 进程一致,用于存储已被 JVM 加载的类信息、字段信息、方法信息、常量池(运行时常量池)、静态变量、即时编译器编译后的代码缓存等核心数据。
方法区的存储内容:
- 类元数据:类的核心结构信息,是方法区的基础存储内容
- 基础标识:类的全限定名、父类 / 实现的接口信息;
- 结构定义:字段(成员变量的名称、类型、访问修饰符)、方法(参数列表、返回值类型、字节码指令、异常表、访问修饰符);
- 附加信息:类的注解、访问标志(如 public、abstract、final)等。
- 运行时常量池:每个类 / 接口对应一个运行时常量池,是类字节码中常量池的运行时表现形式
- 编译期静态内容:字面量(如字符串常量、数字常量)、符号引用(如类名、方法名、字段名的符号标识,运行时会解析为直接引用);
- 运行时动态内容:可通过代码动态添加常量(如 String.intern() 会将字符串常量池中的对象引用存入运行时常量池);
- 版本注意:JDK 7 及以后,字符串常量池从永久代移至 Java 堆,但运行时常量池仍属于方法区。
- 静态变量(类变量):属于类而非实例的变量,与类的生命周期绑定
- 存储时机:在类初始化阶段(
<clinit>方法执行时)完成分配与初始化。
- 存储时机:在类初始化阶段(
- 辅助数据:支撑 JVM 执行优化的关键数据
- 即时编译器(JIT)代码缓存:存储热点代码(被频繁执行的代码)编译后的机器码,避免重复解释执行,提升运行效率;
- 其他辅助信息:方法的字节码属性表、类加载器的引用、反射相关的缓存数据等。
方法区是规范,不同 JVM 厂商对方法区的具体实现不同,HotSpot VM 的实现分两个阶段:
- JDK 6/7:永久代(PermGen)
永久代是 HotSpot 对方法区的物理实现,且属于 JVM 堆内存的一部分(堆的第三个分区,与新生代、老年代并列);
核心参数(大小严格受限):
-XX:PermSize=5M:永久代初始大小(默认值随 JDK 版本不同,如 JDK6 默认 64M);
-XX:MaxPermSize=5M:永久代最大大小(超出则抛出 java.lang.OutOfMemoryError: PermGen space);
局限:永久代大小受 JVM 堆总内存(-Xmx)约束,难以精准配置,易因动态类过多触发溢出。 - JDK 8 及以上:元空间(Metaspace)------ 方法区的本地内存实现
JDK 8 彻底移除永久代,改用元空间作为方法区的实现;元空间的内存来源为操作系统本地内存(Native Memory),不再属于 JVM 堆;
核心参数:
-XX:MetaspaceSize=5M:元空间触发 GC 的阈值(并非初始大小,默认约 21MB),当元空间使用量超过该值时,JVM 会触发元空间 GC;
-XX:MaxMetaspaceSize=40M:元空间最大上限(不指定则默认无上限,JVM 会耗尽操作系统可用本地内存,此时抛出java.lang.OutOfMemoryError: Metaspace);
优势:摆脱 JVM 堆内存限制,利用操作系统本地内存,降低固定大小导致的溢出风险。
先引入 CGLIB 依赖
xml
<dependencies>
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>2.2.2</version>
</dependency>
</dependencies>
java
import net.sf.cglib.beans.BeanGenerator;
import net.sf.cglib.beans.BeanMap;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class PermTest {
public static void main(String[] args) {
int i = 0;
try {
for (i = 0; i < 1000000; i++) {
CglibBean bean = new CglibBean("cn.tx.Perm"+i , new HashMap());
System.out.println(bean);
}
}catch(Exception e){
e.printStackTrace();
}
}
}
class CglibBean {
/**
* 实体Object, 通过动态的类创建的对象的引用
*/
public Object object = null;
/**
* 属性map
*/
public BeanMap beanMap = null;
public CglibBean() {
super();
}
@SuppressWarnings("unchecked")
public CglibBean(Map propertyMap) {
this.object = generateBean(propertyMap);
this.beanMap = BeanMap.create(this.object);
}
public CglibBean(String msg, Map propertyMap) throws ClassNotFoundException {
propertyMap.put(msg, msg.getClass());
this.object = generateBean(propertyMap);
this.beanMap = BeanMap.create(this.object);
}
/**
* 给bean属性赋值
* @param property 属性名
* @param value 值
*/
public void setValue(String property, Object value) {
beanMap.put(property, value);
}
/**
* 通过属性名得到属性值
* @param property 属性名
* @return 值
*/
public Object getValue(String property) {
return beanMap.get(property);
}
/**
* 得到该实体bean对象
* @return
*/
public Object getObject() {
return this.object;
}
/**
* 创建代理类的对象
* @param propertyMap
* @return
*/
private Object generateBean(Map propertyMap) {
BeanGenerator generator = new BeanGenerator();
Set keySet = propertyMap.keySet();
for (Iterator i = keySet.iterator(); i.hasNext();) {
String key = (String) i.next();
generator.addProperty(key, (Class) propertyMap.get(key));
}
return generator.create();
}
}
/**
* 了解cglib动态创建类。
*/
class CglibTest {
@SuppressWarnings("unchecked")
public static void main(String[] args) throws ClassNotFoundException {
// 设置类成员属性
HashMap propertyMap = new HashMap();
propertyMap.put("id", Class.forName("java.lang.Integer"));
propertyMap.put("name", Class.forName("java.lang.String"));
propertyMap.put("address", Class.forName("java.lang.String"));
// 生成动态 Bean
CglibBean bean = new CglibBean(propertyMap);
// 给 Bean 设置值
bean.setValue("id", new Integer(123));
bean.setValue("name", "454");
bean.setValue("address", "789");
// 从 Bean 中获取值,当然了获得值的类型是 Object
System.out.println(" >> id = " + bean.getValue("id"));
System.out.println(" >> name = " + bean.getValue("name"));
System.out.println(" >> address = " + bean.getValue("address"));
// 获得bean的实体
Object object = bean.getObject();
// 通过反射查看所有方法名
Class clazz = object.getClass();
Method[] methods = clazz.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
System.out.println(methods[i].getName());
}
}
}这段Java代码基于CGLIB框架实现了运行时动态生成Java Bean类的核心功能:通过自定义的CglibBean工具类封装CGLIB的BeanGenerator,接收"属性名-属性类型"的Map参数,在程序运行时动态创建出带有对应属性和自动生成的get/set方法的Bean实例,同时借助BeanMap以键值对的便捷方式(替代手动调用get/set)对动态Bean进行赋值、取值操作;代码中还包含两个测试场景,CglibTest类直观演示了动态Bean的完整使用流程(定义属性、生成Bean、赋值取值、反射验证方法),而PermTest类则通过循环100万次创建不同属性名的动态Bean,测试大量动态类创建的极限情况,验证这种方式会因动态生成的类无法被JVM卸载,最终导致元空间/永久代内存溢出的问题。
-XX:+PrintGCDetails -XX:PermSize=5M -XX:MaxPermSize= 5m
这里指定了初始永久区5MB,最大永久区5MB,即当5MB空间耗尽时,系统将抛出内存溢出
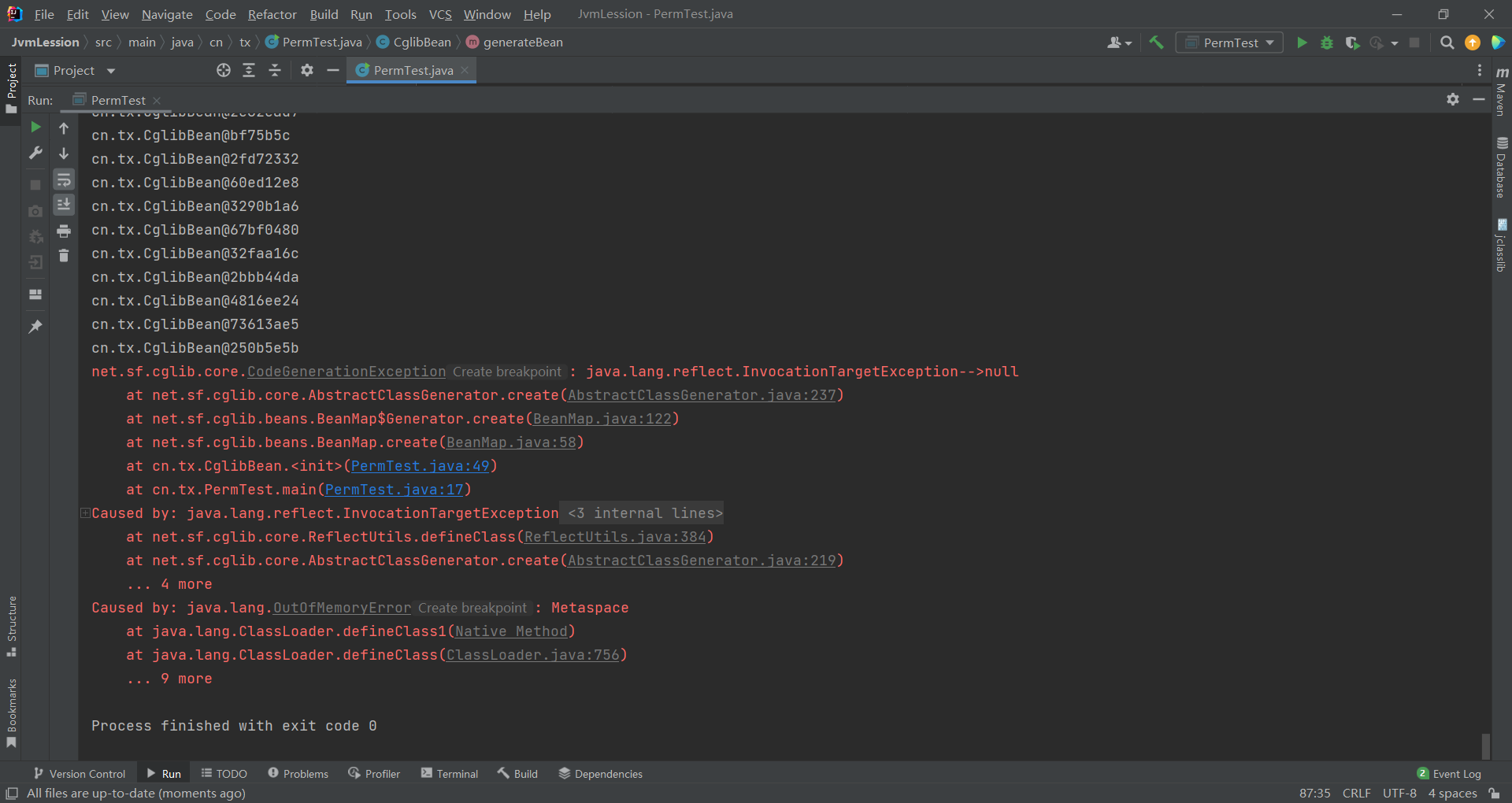
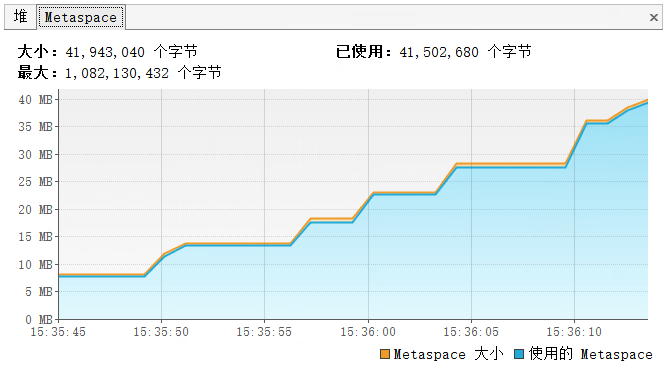
使用如下参数运行: -XX:MetaspaceSize=5m -XX:MaxMetaspaceSize=40m
通过 Visual VM 也可以查看到溢出情况,运行 C:\Program Files\Java\jdk1.8.0_261\bin\jvisualvm.exe,如图:
虚拟机栈
虚拟机栈存储栈帧,栈帧包括局部变量表、操作数栈、帧数据区。
虚拟机栈在我的这篇博客里有详细介绍 Java虚拟机栈
Java 虚拟机提供 -Xss 参数来指定每个线程的栈内存大小,该参数直接决定了方法调用的最大深度。
直接内存配置
直接内存是 Java 中非堆内存的重要组成部分,特别是在NIO被广泛使用后,直接内存的使用也变得非常普遍,是 JDK NIO 为提升 IO 性能引入的特性。直接内存跳过了Java堆,使Java程序可以直接访问原生堆空间,因此,从一定程度上加快了内存空间的访问速度。但是,武断地认为使用直接内存一定可以提高内存访问速度也是不正确的。
最大可用直接内存可以使用参数-XX:MaxDirectMemorySize设置,如不设置,默认值为最大堆空间,即-Xmx。当直接内存使用量达到 -XX:MaxDirectMemorySize 时,就会触发垃圾回收,如果垃圾回收不能有效释放足够空间,将抛出 OutOfMemoryError: Direct buffer memory。
一般来说,直接内存的访问速度(读或者写)会快于堆内存。下面的代码对比了直接内存与堆内存的读写耗时。
java
import java.nio.ByteBuffer;
public class AccessDirectBuffer {
public void directAccess() {
long starttime = System.currentTimeMillis();
//分配直接内存一个缓冲区
ByteBuffer b = ByteBuffer.allocateDirect(500);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 99; j++)
b.putInt(j);
b.flip();
for (int j = 0; j < 99; j++)
b.getInt();
b.clear();
}
long endtime = System.currentTimeMillis();
System.out.println("testDirectWrite:" + (endtime - starttime));
}
public void bufferAccess() {
long starttime = System.currentTimeMillis();
//分配一个堆中的缓冲区
ByteBuffer b = ByteBuffer.allocate(500);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 99; j++)
b.putInt(j);
b.flip();
for (int j = 0; j < 99; j++)
b.getInt();
b.clear();
}
long endtime = System.currentTimeMillis();
System.out.println("testBufferwrite:" + (endtime - starttime));
}
public static void main(String[] args) {
AccessDirectBuffer alloc = new AccessDirectBuffer();
alloc.bufferAccess();
alloc.directAccess();
alloc.bufferAccess();
alloc.directAccess();
}
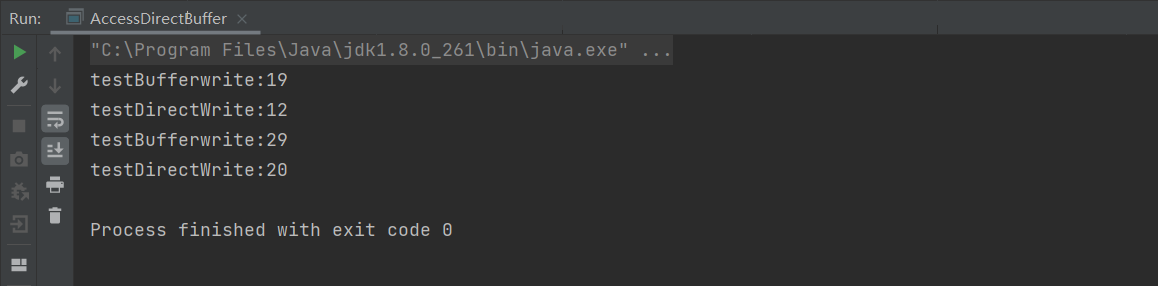
}直接内存(allocateDirect)和堆内存(allocate)的缓冲区容量均设为 500 字节,且读写逻辑完全一致(10 万次循环、每次写入与读取 99 个 int);99 个 int 总计 396 字节,小于缓冲区容量,避免因缓冲区溢出导致测试结果失真。
热身调用的必要性:程序中对两个测试方法各调用两次,首次调用的核心作用是触发 JVM 的 JIT 编译(将字节码编译为机器码)------ 若直接使用首次调用结果,会因未优化的字节码执行掩盖真实性能差异,因此仅关注第二次调用的输出结果。
核心结论:从第二次调用的耗时结果可明确看出,直接内存的读写速度显著优于堆内存,这是因为直接内存绕过了 Java 堆与操作系统内核缓冲区之间的数据拷贝环节,减少了 IO 操作的性能损耗。
执行结果如下:
尽管直接内存在读写操作上具备显著的性能优势,但在内存空间申请(分配) 环节,直接内存的效率远低于堆内存,甚至可以说毫无优势。以下代码通过高频次分配缓冲区的场景,直观对比两者的分配耗时差异:
java
import java.nio.ByteBuffer;
public class AllocDirectBuffer {
public void directAllocate() {
long starttime = System.currentTimeMillis();
for (int i = 0; i < 200000; i++) {
//分配一个1000个长度的直接内存的缓冲区
ByteBuffer b = ByteBuffer.allocateDirect(1000);
}
long endtime = System.currentTimeMillis();
System.out.println("directAllocate:" + (endtime - starttime));
}
public void bufferAllocate() {
long starttime = System.currentTimeMillis();
for (int i = 0; i < 200000; i++) {
//分配一个1000个长度的堆中的缓冲区
ByteBuffer b = ByteBuffer.allocate(1000);
}
long endtime = System.currentTimeMillis();
System.out.println("bufferAllocate:" + (endtime - starttime));
}
public static void main(String[] args) {
AllocDirectBuffer alloc = new AllocDirectBuffer();
alloc.bufferAllocate();
alloc.directAllocate();
}
}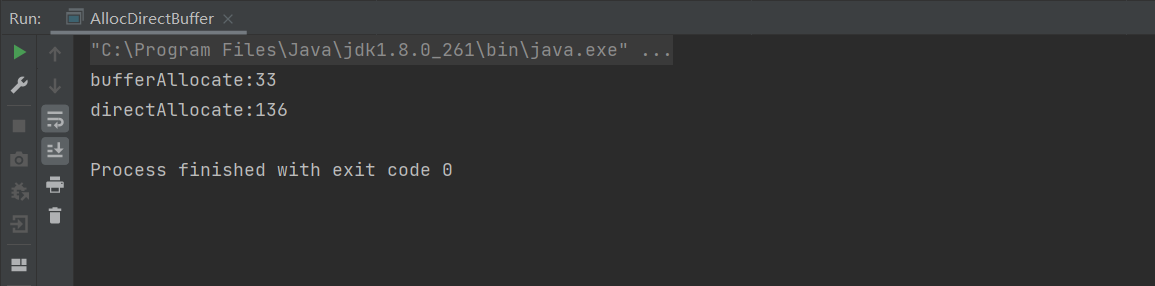
两类内存的分配逻辑完全一致,均循环 20 万次、每次分配 1000 字节的缓冲区,排除分配次数与缓冲区大小不同对测试结果的干扰,仅聚焦分配方式本身的性能差异。运行后可明显看到 directAllocate 方法的执行耗时远高于 bufferAllocate,直接印证直接内存分配效率远低于堆内存。
分配性能差异的底层原理:
堆内存分配是JVM 用户态操作:仅需在 Java 堆的空闲内存区域标记、分配,全程由 JVM 内部管理,无需与操作系统交互,速度极快;
直接内存分配是跨用户态 - 内核态的操作:allocateDirect 本质是调用操作系统的系统级 API 申请本地内存,涉及从用户态切换到内核态的上下文切换,且操作系统的内存分配与管理开销远大于 JVM,因此耗时显著更高。
核心结论:直接内存的分配成本远高于堆内存,这也是其核心短板,直接内存仅适合分配次数少、读写频率高的场景;若业务场景需要频繁创建与销毁缓冲区,堆内存反而是更优选择。
直接内存选型的核心判断维度
是否选择直接内存需结合业务场景的核心特征,可通过以下 4 个维度系统性判断(满足越多,越适合使用直接内存):
- 数据量规模:数据量通常超过 KB 级
底层依据:小数据量场景下,直接内存的分配开销(用户态 - 内核态切换)占比过高,零拷贝带来的性能收益无法覆盖分配成本;只有当数据量达到 KB 级及以上时,零拷贝的优势才会凸显。 - IO 交互频率:数据需与文件、网络套接字、JNI 本地库频繁交互
底层依据:直接内存可实现用户态与内核态的零拷贝,避免堆内存数据写入磁盘 / 网络时,需要先拷贝到内核缓冲区的二次开销;若 IO 交互频率低,这种优势无法体现。 - 数据生命周期:数据生命周期较长(如长连接的缓存数据),或被超高频率访问
底层依据:直接内存的分配成本高,但读写成本低;单次分配、多次复用的模式可摊薄分配开销 ------ 生命周期长或访问频率高,意味着分配开销会被多次读写的性能收益抵消。 - GC 性能瓶颈:堆内大量 IO 操作导致 Young GC 频繁触发、Full GC 耗时过长,或吞吐量下降
底层依据:直接内存不受堆 GC 直接管理,存储大尺寸 IO 数据可减少堆内存占用,缓解 GC 压力;但需注意,直接内存的回收依赖 JVM 的Cleaner机制或显式调用clean()方法,若未正确释放仍会引发内存泄漏。
直接内存的典型适用场景:
- 高性能网络通信 Netty
在启动时配置PooledByteBufAllocator.DEFAULT,创建直接内存缓冲区池。每个TCP连接复用它来读写网络数据。 - 消息中间件 RocketMQ,Kafka
在Broker端,使用内存映射文件(MappedByteBuffer)来持久化消息。生产/消费消息时,直接操作此映射内存。 - 分布式缓存 Redis(网络部分)自研缓存服务
Redis处理客户端连接时,使用直接内存作为Socket缓冲区。一些自研缓存服务会将热点数据存储在直接内存中。 - 实时音视频/图像处理 FFmpeg (Java JNI封装)
在Java层分配直接内存缓冲区,传递给JNI层,由本地库(如FFmpeg、OpenCv)直接填充或处理视频帧、图像数据。 - 大数据计算/列式存储 Apache Arrow Parquet Reader
Arrow定义进程间共享的列式内存格式,数据存储在直接内存中。Parquet读取器可将列数据直接读入直接内存进行分析。 - 数据库连接池与驱动 MySQL JDBC(useServerPrepStmts)
当使用服务器端预编译语句时,驱动程序可能使用直接内存来高效接收大型结果集或BLOB字段。
适合堆的场景:
- Web应用与微服务中的业务对象
场景:处理HTTP请求时创建的Controller、Service、POJo实体、DTO传输对象等。
原因:这些对象数量极大、生命周期极短(通常在一次请求内创建和回收),结构复杂(嵌套对象、集合)。堆内存的快速分配和自动GC完美契合,开发效率最高。 - 高并发下的瞬时计算与缓存
场景:电商促销时生成订单、秒杀系统中创建临时库存记录、实时风控中的规则计算中间结果。
原因:这些场景下,系统需要在极短时间内创建并丢弃海量小对象。堆内存的分配速度和GC对新世代(YoungGC)的高效回收是关键保障。 - 数据结构和集合操作
场景:在内存中构建Map<UserId,UserProfile>等复杂数据结构,并进行排序、过滤、聚合等操作。
原因:这些操作依赖于Java对象头、引用等堆内存的内在特性,在直接内存中模拟会极其笨重且低效。 - 应用层缓存(如Guava Cache,Caffeine)
场景:缓存数据库查询结果、热点计算结果。
原因:缓存对象通常是标准的Java对象,且需要根据容量和策略被灵活地淘汰。堆内存的GC机制可以与这些缓存的淘汰策略良好协作。
本地方法栈
本地方法栈是 JVM 非堆内存的重要组成部分,也是线程私有的内存区域,生命周期与线程完全一致。其功能定位与 Java 虚拟机栈类似 ------ 虚拟机栈为 Java 方法(字节码)的执行提供上下文,本地方法栈则专为 Java 程序中 native 方法(如调用 C/C++ 原生代码的方法)的执行提供专属的运行支撑。
主流 JVM(如 HotSpot)对虚拟机栈和本地方法栈采用 "物理合并、逻辑区分" 的实现方式:它们共用同一块内存区域,因此 -Xss 参数(设置线程栈大小)会同时影响这两个区域的可用空间;但在逻辑层面,两者各自维护独立的栈帧结构,分别承载 Java 方法和 native 方法的执行上下文。
从 JVM 规范来看,虚拟机栈的栈帧结构、操作流程有严格规定,而本地方法栈的约束相对宽松,仅要求其支持 native 方法的执行即可。
本地方法栈的异常机制与 Java 虚拟机栈完全一致:
当 native 方法出现无限递归等情况,导致栈帧深度超出内存区域限制时,抛出 StackOverflowError;
当 JVM 无法为新线程分配本地方法栈内存(如 -Xss 设置过大、线程数量过多)时,抛出 OutOfMemoryError: unable to create new native thread。
程序计数器
程序计数器是 JVM 非堆内存中体积最小、最基础的内存区域,也是线程私有的内存区域 ------ 每个线程都会分配独立的程序计数器,生命周期与线程完全一致。其核心定位是线程执行的 "导航仪",负责记录当前线程正在执行的字节码指令地址,保证线程切换后能精准回到之前的执行位置。
程序计数器的核心特性:
- 无 OOM:JVM 规范明确要求,程序计数器永远不会抛出 OutOfMemoryError(内存溢出),这是 JVM 内存区域中唯一有此保障的区域;
- 执行效率:在 HotSpot 虚拟机中,程序计数器直接映射到 CPU 的寄存器(或 CPU 高速缓存),执行效率接近硬件级别,无额外开销;
- 无配置参数:程序计数器的大小固定且极小(仅存储指令地址的整数),是 JVM 中唯一没有内存大小配置参数的区域。
程序计数器的核心价值是保障线程执行的连续性和正确性,具体作用:
- 存储当前线程执行的字节码指令地址
当线程执行 Java 方法(非native方法)时,程序计数器存储的是当前正在执行的字节码指令的 "地址偏移量"(即该指令在方法字节码数组中的位置)。 - 支撑多线程的切换与恢复
JVM 的多线程在单 CPU 核心下是时间片轮转的并发执行(同一 CPU 核心同一时间只能执行一个线程),在多 CPU 核心下则是并发与并行的结合,程序计数器是线程切换的核心保障。 - 处理 native 方法的特殊情况
当线程执行 native 方法时,程序计数器的取值为 undefined,因为 native 方法是 C/C++ 编写的原生代码,没有 Java 字节码指令,无需记录字节码地址;待 native 方法执行完毕切回 Java 方法时,程序计数器会恢复为 Java 方法的指令地址。 - 辅助异常调试与代码执行追踪
程序计数器记录的指令地址是 JVM 调试工具(如 JDB、IDEA 调试器)的核心依据:
调试时的 "断点" 本质是标记某条字节码指令的地址,当程序计数器指向该地址时,JVM 暂停线程执行;
调试中的 "单步执行",就是让程序计数器逐个更新为下一条字节码指令的地址,实现逐行执行的效果。
其他非堆内存
比如 JIT 编译器的代码缓存、JVM 内部管理内存(垃圾回收器的统计信息、日志缓冲区等),属于 JVM 的辅助内存。