文章目录
-
- [1. 为什么要对提示词进行微调?](#1. 为什么要对提示词进行微调?)
- 2.深度解析P-Tuning微调核心思想
- 3.总结与思考
-
- 3.1传统离散提示词存在什么问题?
- [3.2 P-tuning中虚拟Token的作用是什么?](#3.2 P-tuning中虚拟Token的作用是什么?)
- [3.3 在P-Tuning中使用LTSM和MLP有什么共同点和区别?](#3.3 在P-Tuning中使用LTSM和MLP有什么共同点和区别?)
- [3.4和LoRA tuning相比,P-tuning有什么本质上的区别?](#3.4和LoRA tuning相比,P-tuning有什么本质上的区别?)
1. 为什么要对提示词进行微调?
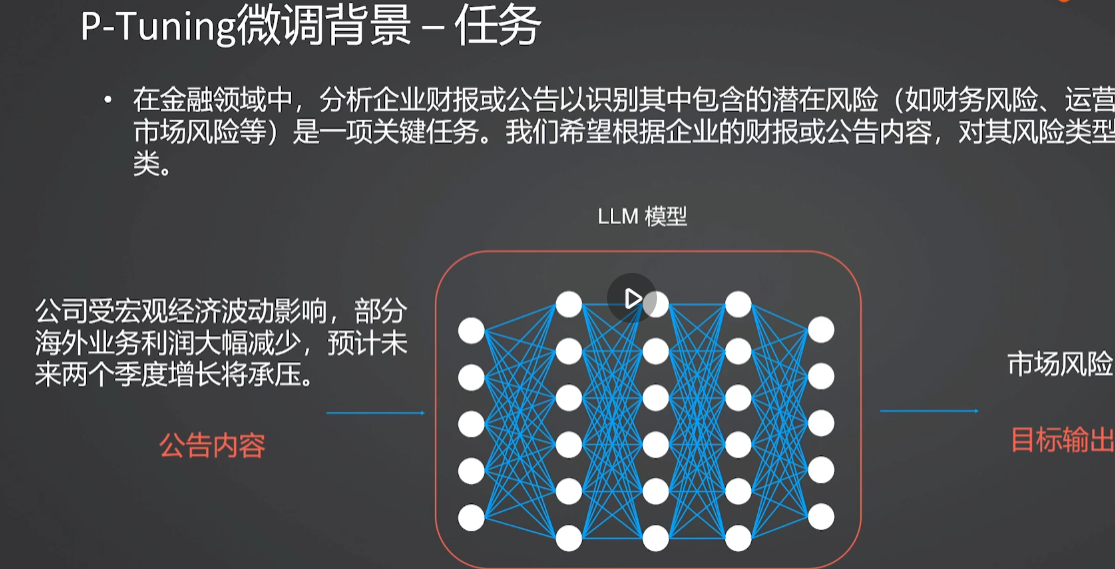


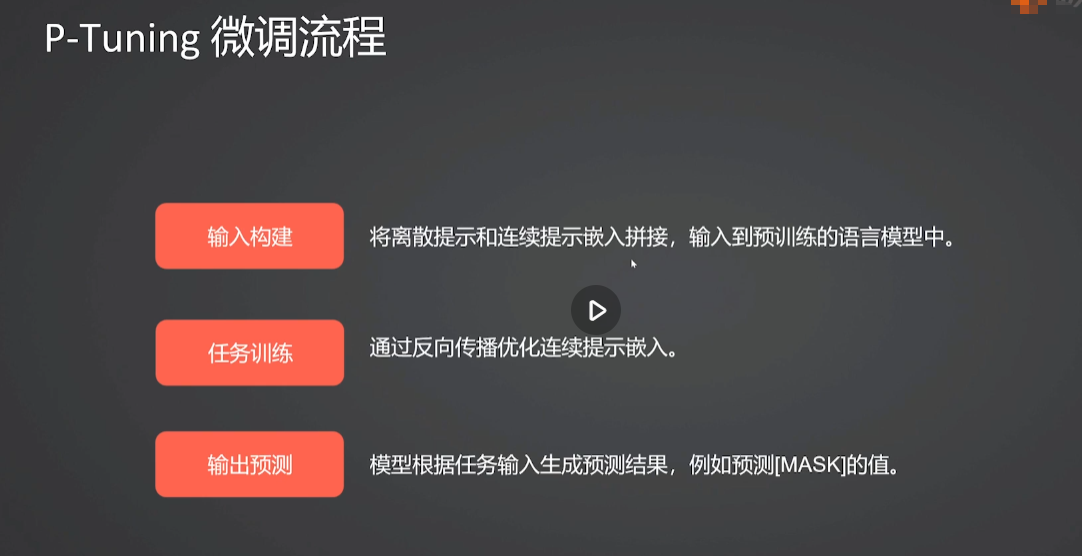
2.深度解析P-Tuning微调核心思想

3.总结与思考
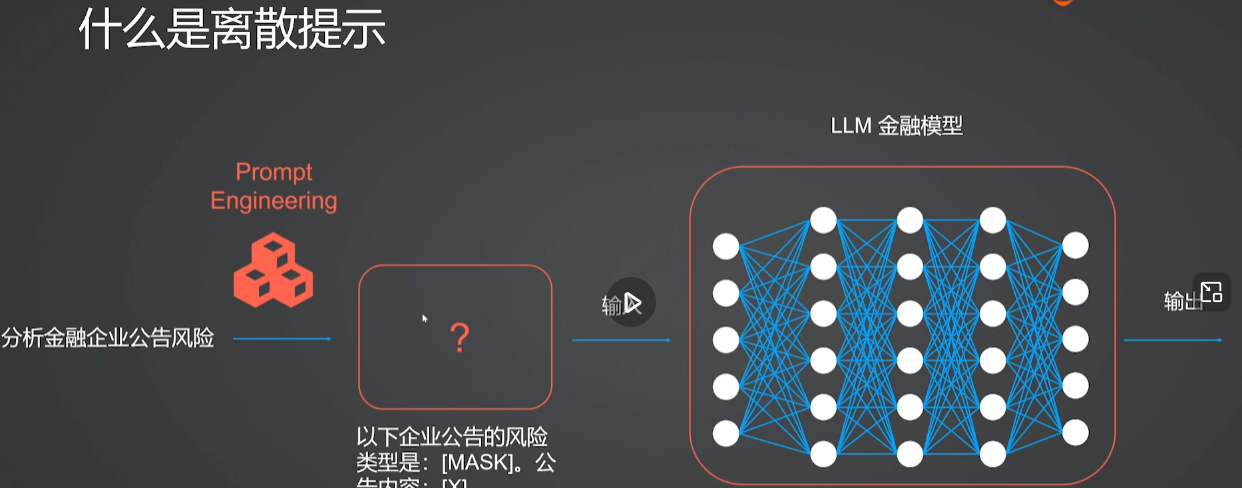
3.1传统离散提示词存在什么问题?
- 性能极度不稳定(脆弱性),这是离散提示最致命的弱点。模型的输出结果对提示词的措辞极其敏感。
- 优化困难(不可微分),离散提示是由具体的、独立的词汇组成的,这导致了它在数学上是不可微分的。
- 鲁棒性差(易受干扰),面对输入扰动时表现脆弱,无关的符号、标点错误等
- 可能产生"反直觉"的结果,包含嘈杂、无意义甚至违反直觉的词汇组合
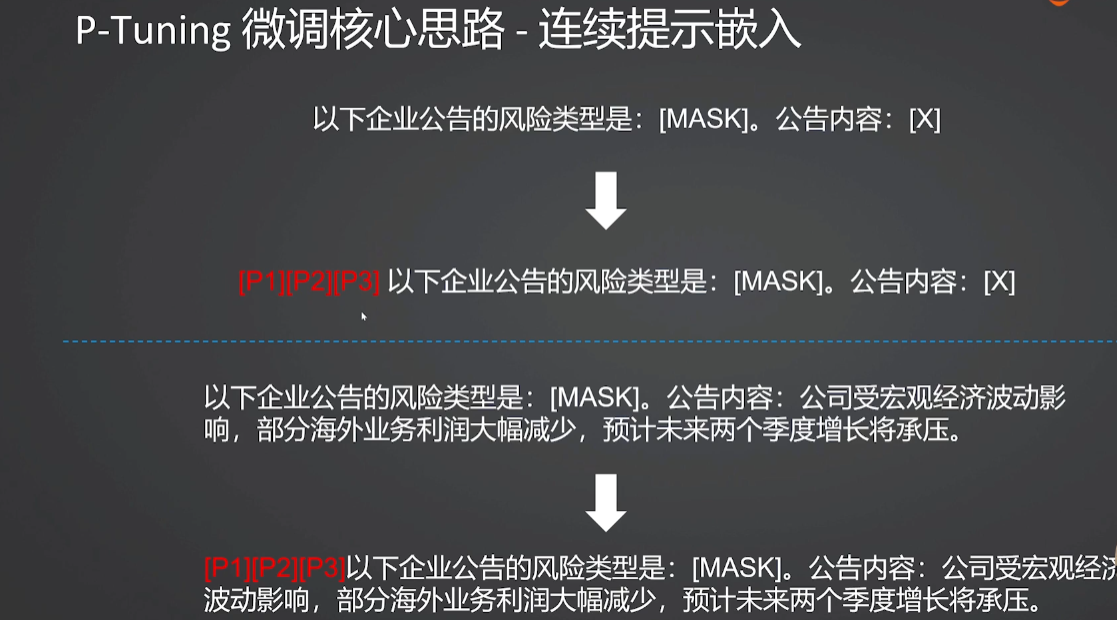
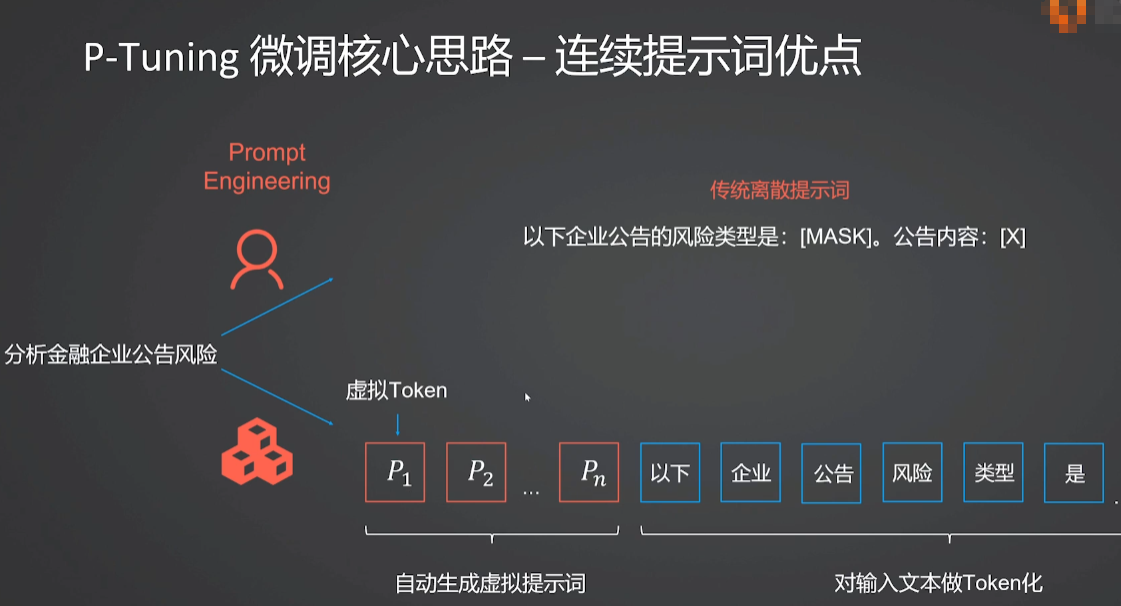
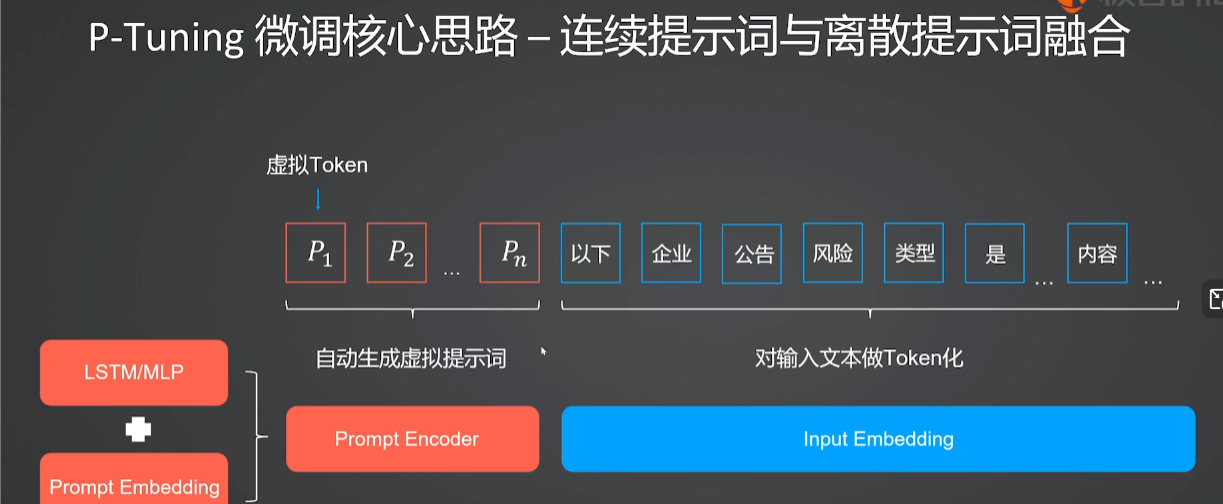
3.2 P-tuning中虚拟Token的作用是什么?
| 特性 | 传统离散提示词 (人工编写) | P-Tuning 虚拟 Token |
|---|---|---|
| 形式 | 具体的自然语言文字 (如 "Translate:") | 随机初始化的向量,训练后变为抽象表示 |
| 优化方式 | 人工试错、暴力搜索 | 梯度反向传播、自动优化 |
| 稳定性 | 敏感,易受措辞影响 | 稳定,鲁棒性强 |
| 主要作用 | 告诉模型"怎么做" | 编码任务信息,引导模型注意力 |
3.3 在P-Tuning中使用LTSM和MLP有什么共同点和区别?
LSTM(Long Short-Term Memory长短期记忆网络 RNN循环神经网络的变体 )/MLP(多层感知机)
| 维度 | MLP (多层感知机) | LSTM (长短期记忆网络) |
|---|---|---|
| 核心能力 | 非线性映射 | 序列建模 |
| 结构特点 | 全连接前馈网络,无记忆功能。 | 带有门控机制的循环神经网络,能捕捉序列依赖。 |
| 对 Token 的处理 | 将每个虚拟 Token 独立处理或通过全连接层进行简单的非线性组合。 | 将虚拟 Token 视为一个序列,考虑它们之间的顺序和依赖关系。 |
| 参数量 | 相对较少,结构简单。 | 相对较多,结构复杂(包含遗忘门、输入门、输出门)。 |
| 训练难度 | 训练速度快,收敛相对容易。 | 训练速度较慢,可能更难收敛。 |
| 适用场景 | 推荐使用。对于大多数 NLP 任务,简单的非线性变换已经足够有效。 | 特定需求。如果你认为提示词之间的顺序非常重要,需要模型"记忆"前面的虚拟 Token 来决定后面的输出时使用。 |
3.4和LoRA tuning相比,P-tuning有什么本质上的区别?
P-Tuning 是在"喂数据"上下功夫(优化输入),而 LoRA 是在"改结构"上做文章