论文:Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
会议:ACL 2025 long
作者:Xiangci Li et al. (AWS AI Labs, Amazon)
一、动机 & 问题背景
该工作聚焦于解决对话式商品搜索(CPS)中的意图澄清。对话式商品搜索(CPS)属于电商搜索范畴。
1. 1 传统电商搜索
传统电商搜索是通过关键词搜到候选列表再进行筛选。
其存在的问题包括:
- 用户负担高,由用户需求描述不准确导致多轮试错带来的
- -无法主动澄清用户偏好
1.2 对话式商品搜索
对话式商品搜索 (Conversational Product Search,CPS)希望通过对话逐步确认用户需求。
现有 CPS 面临的问题包括:
- 数据极度稀缺,商业数据无法公开 并且 人工标注昂贵。
- 合成数据质量低, 模板化严重并且对话不自然、用户过于理性,不符合真实行为。
- LLM 直接生成对话不可控,容易幻觉、对话路径冗长、随意而且无法保证一定找到目标商品。
由此,本问用一种可控、可扩展、低成本的方式,生成真实、目标导向、可用于下游任务的电商对话数据,并提出 TRACER,核心思想是:
用决策树负责"找什么",用 LLM 负责"怎么说"
二、TRACER 方案概述
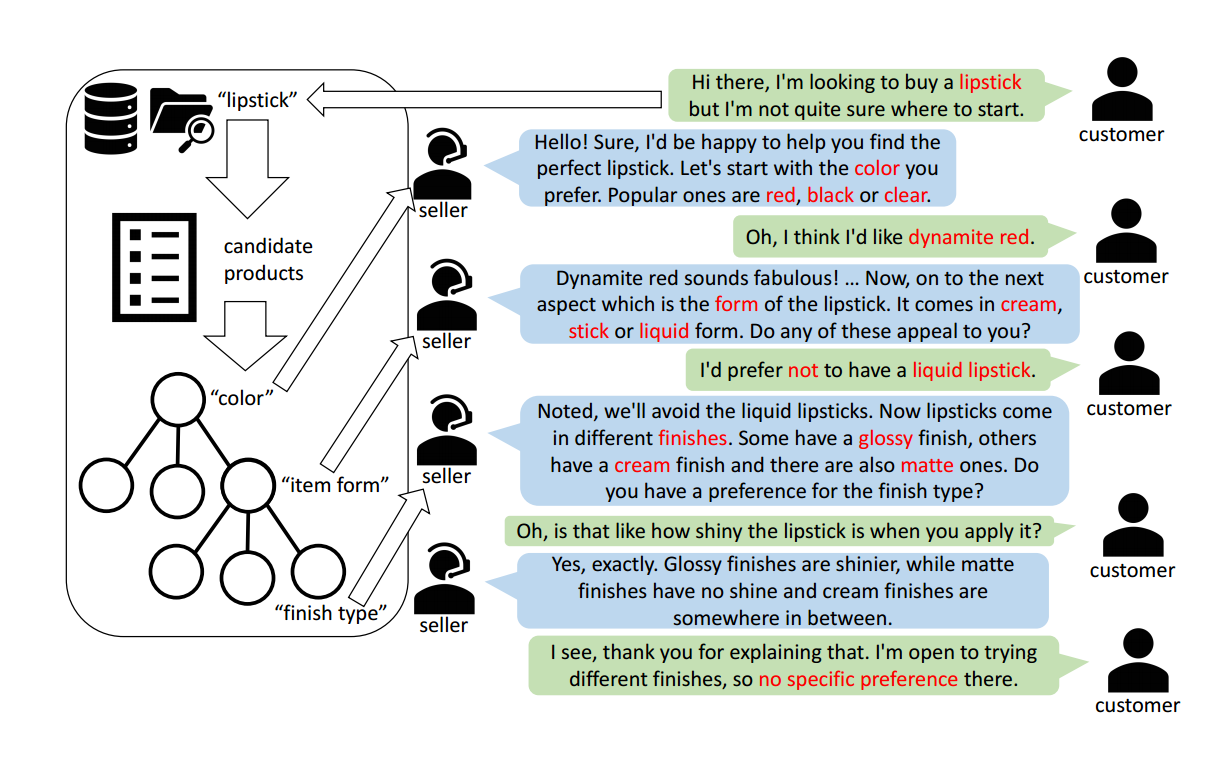
TRACER (T arget orientede commeR ce diA logue generation with deC isiontrE e bR anching)是一种结合决策树(DT)与大型语言模型(LLM)的目标导向对话生成方案,核心目标是生成自然且高效的产品咨询对话。
TRACER 通过决策树(DT) 结构化分解用户目标偏好(如产品属性偏好),并利用LLM生成符合对话历史和用户偏好的自然语言交互,确保对话覆盖所有必要产品属性(wanted、optional、unwanted),同时保持连贯性和自然性。
TRACER 利用大语言模型(LLM)来生成不同购物领域的真实和自然的对话。
TRACER的新颖之处在于将对话计划的生成,这是从决策树模型预测的产品搜索轨迹。
TRACER 用决策树规划"最短搜索路径",用大模型语言化该路径,从而生成可控、真实、目标导向的电商对话数据,并被验证在下游任务中具有显著价值。
三、 模块一:Customer Preference Sampling(顾客偏好抽样)
将产品的多维度属性(如颜色、品牌、材质等), 按用户需求将 interest values(兴趣值) 分为三类(wanted、optional、unwanted),明确对话需覆盖的核心特征和排除范围,为后续对话计划提供基础。
1、 基本设定
每个产品关联一组特征或属性值对。从商品库中随机采样一个目标商品 ( p ),其属性值对组合为:
p = ( A 1 , V 1 ) , ( A 2 , V 2 ) , . . . , ( A m , V m ) p = {(A_1, V_1), (A_2, V_2), ..., (A_m, V_m)} p=(A1,V1),(A2,V2),...,(Am,Vm)
例如:[(颜色=红), (材质=TPU), (型号=iPad)]
TRACER 将每个属性的 interest values(兴趣值) 按用户需求分为三类:
- Wanted :表示用户明确需要的属性
- Unwanted :表示用户明确不需要的属性
- Optional :表示用户明确排除的属性
2、 最终偏好表示
preference = P C , ( A 1 , V 1 , I 1 ) , . . . , ( A m , V m , I m ) \text{preference} = PC, (A_1,V_1,I_1), ..., (A_m,V_m,I_m) preference=PC,(A1,V1,I1),...,(Am,Vm,Im)
其中PC 表示 产品类别(Product Category), A i A_i Ai表示第i个属性的属性名, V i V_i Vi表示第i个属性的属性值, I i I_i Ii表示第i个属性的兴趣值。
四、 模块二:Dialogue Planning with Decision Tree(基于决策树的对话规划方法)
通过决策树(DT)优化产品属性的询问顺序,以最小化用户对话轮次,确保高效缩小搜索空间。
即给定用户的一组偏好表示 ,对话规划确定对话中将要获取的产品属性或产品特征的顺序。达到用最少的问题,把搜索空间缩到目标商品,等价于最大化每轮对话的信息增益。
因此,在每一轮对话中,给定部分显示的偏好RevP ref,决策树选择下一个产品属性,最大限度地划分当前的搜索空间。
这里再重复一遍,这些变量的符号表示,设商品集合为:
P = p 1 , p 2 , . . . , p n P = {p_1, p_2, ..., p_n} P=p1,p2,...,pn
每个商品:
p i = ( A 1 , V 1 ) , ( A 2 , V 2 ) , . . . , ( A m , V m ) p_i = {(A_1, V_1), (A_2, V_2), ..., (A_m, V_m)} pi=(A1,V1),(A2,V2),...,(Am,Vm)
已知偏好(逐轮累积,是当前对话已获取到的信息。)
R e v P r e f t = P C , ( A i 1 , V i 1 ) , . . . , ( A i k , V i k ) RevPref_t = PC, (A_{i_1},V_{i_1}), ..., (A_{i_k},V_{i_k}) RevPreft=PC,(Ai1,Vi1),...,(Aik,Vik)

Step 1:候选商品检索
首先,在需要搜索的每个回合,从搜索系统中检索满足RevP ref的一组产品(Po)
P 0 = search ( R e v P r e f ) P_0 = \text{search}(RevPref) P0=search(RevPref)
- 规则过滤
- 所有满足当前偏好的商品
Step 2:构造临时训练集
使用Po中的产品属性或特征来构建一个临时训练数据集(用来拟合决策树的数据集)
对每个商品 ( p ∈ P 0 ) (p \in P_0) (p∈P0):
- 特征 X:所有商品属性
- 标签 Y:属性-值组合字符串
示例:
text
X = [color=blue, material=TPU, model=iPad]
Y = "color:blue&material:TPU&model:iPad"Step 3:训练临时决策树
拟合的Tree包含节点的结构化集合,其属性(Attributes)是产品某方面特征或属性名称(比如品牌),并且分裂条件是对应的属性值(aspect values,比如华为)。
T r e e = D e c i s i o n T r e e . f i t ( X , Y ) Tree = DecisionTree.fit(X, Y) Tree=DecisionTree.fit(X,Y)
- 每一层节点 ,都是 一个商品属性
- 分裂条件 ,依据 不同属性值
注意!每一轮对话都会重新训练一棵树
Step 4:生成对话规划
给定拟合的Tree和偏好,生成最佳对话规划(Aspect-ValueInterest元组的序列)
本方案从根节点开始遍历,根据用户偏好对应的兴趣值和 父节点中的属性选择下一个子节点。决策树会为每个属性进行独立的拟合。
这个搜索和规划过程(Algorithm 1)迭代,直到P0 中的每个产品都满足偏好,或者直到没有更多的产品属性要讨论 而结束。
P l a n = ( A 1 , V 1 , I 1 ) , . . . , ( A d , V d , I d ) Plan = {(A_1, V_1, I_1), ..., (A_d, V_d, I_d)} Plan=(A1,V1,I1),...,(Ad,Vd,Id)
最终的 Plan 本质是一条从"模糊需求"到"商品收敛"的最短探索路径。
五、 模块三:Verbalization(自然语言化)
Verbalization 聚焦于将对话计划(Dialogue Planning)转化为自然、流畅且符合用户需求的人类对话的过程。该章节通过互动生成(Interactive Generation) 和单轮生成(Single-Pass Generation) 两种策略,结合特定提示词模板和函数调用机制,确保对话覆盖所有关键产品特征,同时避免冗余、逻辑冲突或信息遗漏。

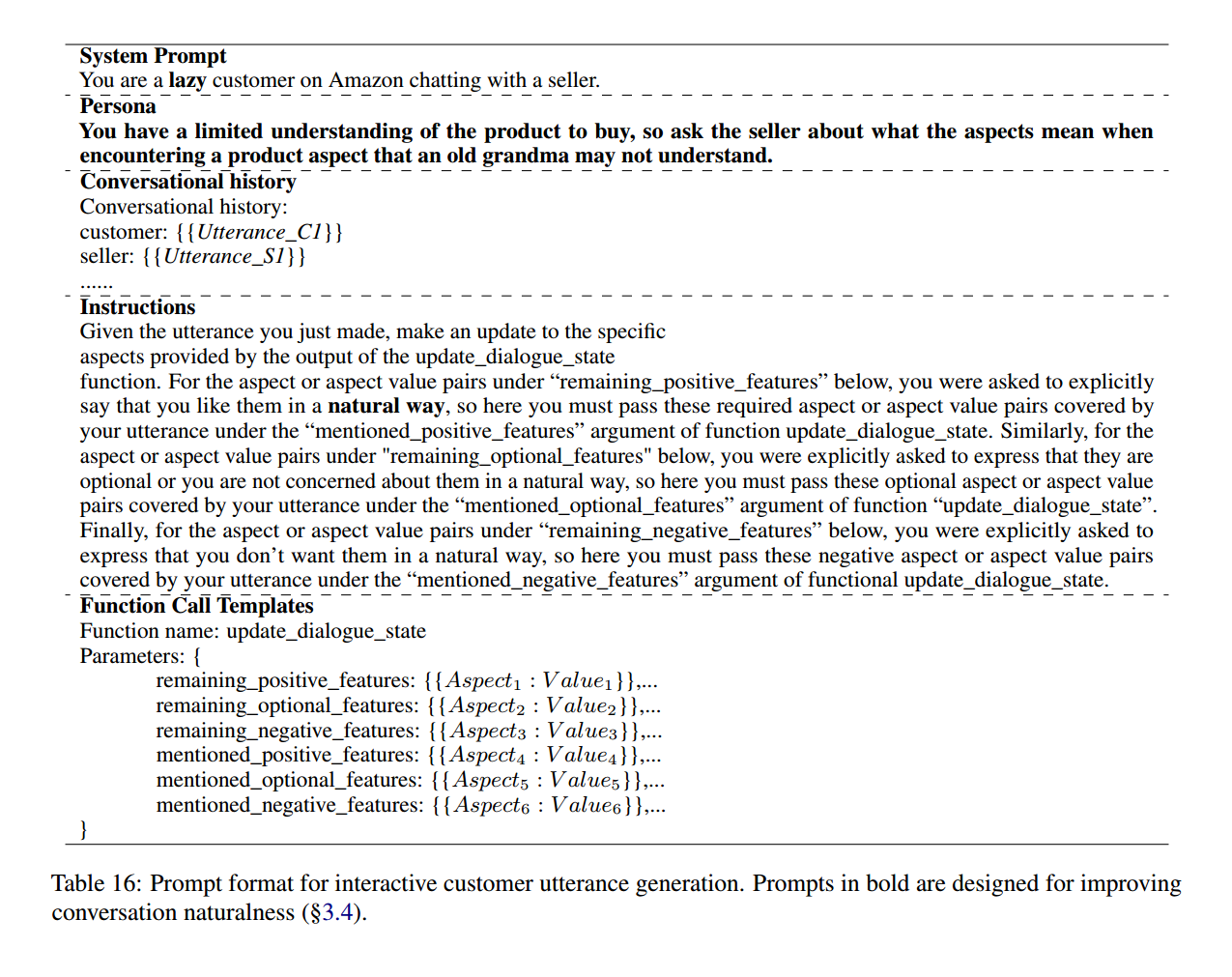
1. 互动生成(Interactive Generation)
互动生成(Interactive Generation)对卖家代理(Seller)和用户代理(Customer)使用不同的提示,使他们交替地逐个话语地相互说话。并引入 Dialogue State Tracker 跟踪客户的需求、可选和已提及的不需要的功能。但这种方式的缺点是容易失控或上下文冲突。
-
角色分工:
- Seller(卖家)负责引导对话、澄清需求,每次聚焦1-2个产品- 特征提问;
- Customer(客户)被动回应,仅针对卖家提出的特征进行澄清(如"是/否/可选")。
-
提示词设计:
-
Seller模板(Table 15):要求友好提问,优先覆盖未澄清特征,避免重复或引入新特征,需包含remaining_features(待澄清特征)、mentioned_positive/optional/negative_features(已确认特征)等参数,通过函数调用update_dialogue_state传递状态。

-
Customer模板(Table 16):被动回应,针对卖家提问的特征明确表达"wanted/optional/unwanted"态度,同样通过update_dialogue_state更新对话状态。
-
2. 单轮生成(Single-Pass Generation)
单轮生成(Single-Pass Generation)将决策树计划预先确定的所有产品属性元组 输入到单个LLM中,并通过一次生成整个对话。这种方式生成的对话更加稳定、自然。

六、 模块四:Enhancing Conversational Naturalness(对话自然性增强)
在 TRACER 方法中,决策树负责规划对话的属性和提问顺序,但生成的对话可能显得生硬或缺乏人性化的细节 ,因此需要通过优化使得对话更加自然、流畅。自然度对用户体验有着至关重要的影响,避免僵化和机械化的对话。
本文针对自然度提出来以下四点核心要求:
1、How conversation starts(对话如何开始)
确保对话自然、流畅地启动,而不是突然进入对话主题,避免给用户带来突兀感。这里的关键是卖家的问候非常简洁自然,且没有强迫性,而是引导顾客清晰表述需求。
2、How conversation ends(对话如何结束)
让对话在找到目标产品或完成用户需求后自然结束 ,避免对话无意义地拖延或中途断开。一旦满足顾客需求,对话便进入推荐阶段,避免多余的信息输入。对话结束的标准是当所有商品都符合用户需求,即搜索结果已经收敛到一个产品簇。
3、Improving naturalness by adding hints(通过添加提示提升自然度)
提升用户对产品特征的理解,使他们能够更轻松地做出选择,避免因为不清楚选项而产生不必要的混乱或停顿。
-
提供常见选项 ,涉及顾客不熟悉的产品特征时,卖家会主动给出提示(例如产品的典型值或常见选择)。这种做法可以帮助顾客更快速理解选择的意义,并明确自己的偏好。
-
引导理解:当顾客不熟悉某个产品特性(例如固态硬盘的存储大小)时,卖家的提示能够帮助顾客快速理解这个特性,并做出选择。
-
减轻认知负担:为顾客提供有代表性的选项,可以避免顾客因无法理解或没有足够知识而感到困惑。
4、Improving naturalness by LLM knowledge(通过 LLM 知识提升自然度)
LLM 内部拥有丰富的世界知识可以用来解释一些顾客不太明白的产品特性,尤其是对于顾客不理解的技术性术语,LLM 会主动做解释。通过解释复杂的属性,LLM 能够让对话更具人性化,减少顾客的认知负担。
这些优化确保了 TRACER 的对话在具有目标导向性和高效性 的同时也保持了自然性、流畅性,从而提升了用户的体验感和满意度。
七、下游任务
Conversational Query Generation(CQG)
以完整的买卖对话作为输入,目标是将对话内容转换为搜索系统可直接使用的结构化查询表示。
Conversational Product Retrieval(CPR)
基于对话中所表达的用户需求,对候选商品进行检索与排序,以评估目标商品是否能够被有效检索出来。
八、方法优势与局限性
优势:
1、理论创新,决策树 与 LLM 明确分工,搜索最优性有理论支撑
2、高可控性, 明确的对话结构,能保证一定能收敛到目标商品
3、数据实用性强,能显著提升 CQG / CPR
4、可扩展性强,新品类与新商品表基本一致,无需重新标注
局限性:
1、 不支持商品对比
2、 决策树忽略语义相似性(属性值是离散标签,未利用 embedding)
3、强依赖商品结构质量,垃圾属性会被放大
TRACER 在决策树规划的基础上,通过 LLM 对生成的对话进行润色,加入更多人性化的元素 。提供提示优化、名词解释、语境调整以及对话状态追踪等功能,大幅提升对话的自然性和流畅度; 通过这些优化,TRACER 在保证对话目标导向和高效性的同时生成的对话更加自然、流畅和易于理解 。用户对这种"高自然度"对话的满意度显著提高。