论文 :https://arxiv.org/pdf/2203.17270.pdf
代码 :https://github.com/fundamentalvision/BEVFormer
1、为什么要做这个研究(理论走向和目前缺陷) ?
transformer在BEV层面做时序(自注意力)和空间特征融合(交叉注意力)有天然优势。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
利用时序自注意力(temporal self-attention)和空间交叉注意力(spatial cross-attention)分别和时序(历史)信息和空间信息(多相机)做融合。具体来说,一个可训练的BEV query map中对应感知的范围(-51.2m, 51.2m),每个query利用和deformble attention和上一帧的BEV特征(需要做运动补偿)做交互,即时序自注意力;同时每个query需要对应4个不同高度的参考点,这4个参考点分别投影到当前帧不同图像上,取每个参考点对应的临近的四个采样点特征做交互(deformble attention),即空间交叉注意力。
里面也有一些小trick,比如:1)运动补偿,和上一帧BEV特征做交互之前,上一帧BEV特征需要做运动补偿转换到当前帧坐标系下。2)偏移预测优化。时序自注意力中的deformable attention获取参考点的采样点时,需要将当前帧的BEV query和历史帧的BEV特征concat一起后预测偏移(原始的deformable attention只利用query预测偏移)。3)加外参噪声模拟真实自动驾驶车辆的外参不准的情况。
3、发现了什么(总结结果,补充和理论的关系)?
提出的BEVFormer效果非常好,由于加了时序信息故能做速度估计,且对外参要求没那么高。但是主干网络依然用的是CNN,可以可以考虑全部替换为transformer结构。
摘要
本文提出了BEVFormer,可以通过预定义的grid形式(bev)的query在时间和空间上做交互来实现最大化信息利用。空间上的交互即bev的query利用空间交叉注意力和不同的摄像头的对应区域的特征做交互,时间上的交互即利用bev的query利用时间自注意力上和之前此位置的的bev特征做交互。在nuscences上NDS达到56.9,和pointpillar还有一定差距,但效果已经非常好了。
1 引言
借助多路图像实现3D目标检测的一个思路就是每一路单独做单目3D目标检测,然后再融合后处理,这种方案的缺点就是不能融合跨相机的信息,性能和效率低下。
相较单目3D的融合方案,BEV的特征表达对感知和规划任务更友好,之前的BEV方案需要借助深度估计来实现将2D特征转换到BEV空间,缺点就是对深度值或深度分布很敏感,会有累计误差。
作者不想用深度估计先验,而且也需要融合时间和空间信息,而transformer具有天然优势,BEVFormer应运而生。
本文提出的BEVFormer不需要深度估计,而是直接借助Transformer提取BEV特征。
BEVFormer有3个关键设计:1)grid形的bev query,方便利用transformer融合时间和空间信息。2)提出的空间交叉注意力可以和多相机特征做信息交互。3)提出的时序注意力模块可以从历史的BEV特征中提取时序信息,有利于速度估计和遮挡目标检测。
本文主要贡献点:
1)所提出的BEVFormer实际是一个时空transformer编码器,可以把多相机和时间信息融入到BEV特征表达中,有了这样一个统一的BEV特征,就可以同时做多种下游任务,如3D目标检测和地图分割。
2)设计的可学习的BEV query以及附带的空间交叉注意力和时间自注意力可以分别实现多相机信息交互和历史BEV特征交互,然后把他们聚合到统一的BEV特征中。
3)nuscences上测下来3D目标检测比DETR3D效果好,车道分割比LSS原文效果好。
2 相关研究
2.1 基于transformer的2D感知
DETR(训练太慢), Deformable DETR提出deformable attention,只在参考点附近采样几个点实现只做局部区域的注意力,效率更高,训练更快。Deformable attention公式如下,本文沿用Deformable attention但是拓展到了3D领域。
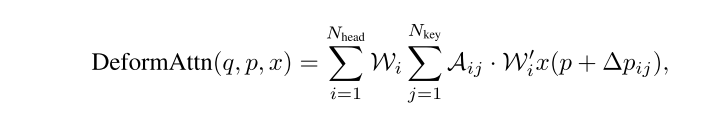
2.2基于相机的3D感知
主要是3个阶段,早期:先做2D检测,然后2D检测框通过IPM转3D。中期:单目3D方案,如DETR3D。当前:基于BEV的3D检测,这种一般需要深度估计或深度先验。
之前通过transformer空间信息(多相机)交互时用的是全局注意力,计算量太大了,根本没法用。做时间上信息交互时采用的是堆叠(stack)BEV特征的方式,这种就是需要是固定时间间隔的BEV特征,而且增加了计算量,限制也比较多。本文BEVFormer在时序信息交互采用的RNN风格的方式,相对堆叠BEV特征的方式不增加计算量。
3 BEVFormer
3.1 总体架构
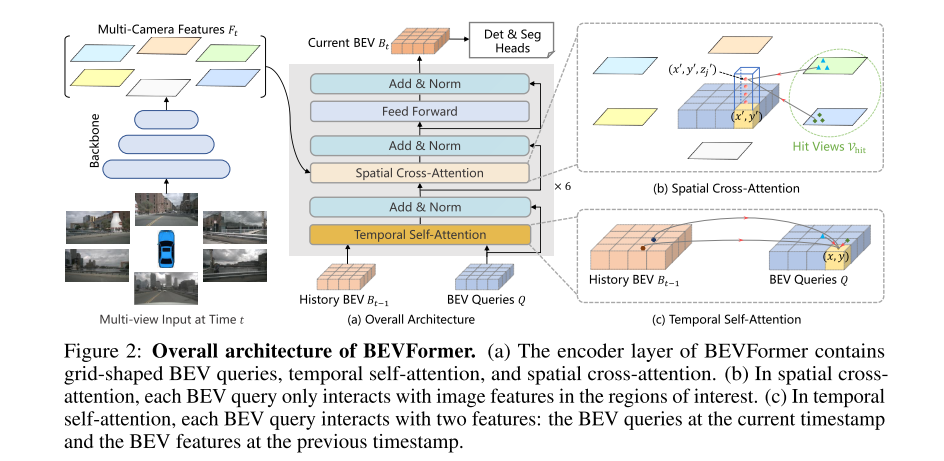
下图所示,encoder有6层,和经典的transformer编码器整体结构相同,但是有3个定制化的设计:BEV query, 空间交叉注意力,时间自注意力。
推理阶段的输入有两个,一个是当前帧各个图像经过CNN主干网络提取到的特征图,以及上一帧的BEV特征图,在每个encoder layer, 首先利用BEV query和上一帧的BEV特征做时序上的自注意力,然后利用空间交叉注意力在当前帧的多相机特征之间做空间上的交互。经过前馈网络(FFN)后就可以输出精细化的BEV特征了。有了这样的BEV特征后就可以做3D目标检测和语义分割了。
3.2 BEV Queries
大小:HWC,每个grid对应一个真实物理世界的位置,也即一个query,其大小即1*C, 特点:参数可学习。同时在做信息交互时也会添加可学习的位置编码。
3.3 空间交叉注意力( Spatial cross-attention)
采用的是deformable attention,避免global attention,而是每个相机特征图的局部区域做attention,从而减少计算量。原生的deformable attention是2D的,适配3D故需要做一些微调。
如上图(b)所示,每个pillar/grid取4个固定高度间隔的3D参考点(此过程即lift),然后把四个3D点投影(共用同一个query, 记作Q_p)到2D视图上作为2D参考点,然后对2D参考点附近的特征(提供k,v)进行采样(空间交叉注意力SCA),最后对这些采样到的特征进行加权求和。公式如下:

2D参考点附近的特征聚合是通过deformabale attention做的,即先利用一个线性层计算偏移,然后query和经过偏移的几个点进行交叉注意力。
3.4时序注意力(temporal self-attention, TSA)
没有时序信息的话很难估计速度和检测遮挡障碍物。这里时序注意力的输入是当前帧的query和上一帧的BEV特征,首先需要上一帧的BEV特征做自车运动补偿变换到当前帧,使得当前帧的一个Query的grid和上一帧BEV特征(已做过运动补偿)同一个位置grid在世界坐标系下对应的是同一个位置。然后需要预测deformable attention中的采样点的偏移,具体做法就是把Query(grid map)对应和变换过的上一帧BEV特征图concat到一起然后预测一个x和y的偏移值,这里和原始的deformable attention差异在于原始的deformable attention预测偏移值时输入只有query。
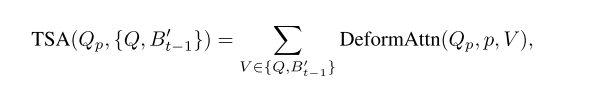
相对于之前的把历史多帧的特征图concat到一起的做法,时序注意力利用可变形注意力实现历史一帧做交互,计算更叫高效。
3.5 BEV特征的应用
经过时序自注意力和空间交叉注意力得到的BEV特征图信息非常丰富,可以应用于各种各样的任务比如3D目标检测或地图分割。
3.6 实现细节
训练阶段:对于每一个关键帧,在其历史两秒内随机采样三帧和关键帧组合成一个训练单元,对于历史三帧,循环前向推理获得BEV特征{Bt−3, Bt−2, Bt−1} ,这个过程不需要记录梯度,而对于关键帧Bt,其和Bt−1做交互时需要记录梯度。注意Bt−3由于是起始帧,其和前一帧做时序交互时实际还是它自身做交互。
推理阶段:按时间顺序推理,每一帧都和上一帧做时序交互并把BEV特征保存下来备用。
4 实验
4.1 数据集
nuScenes和Waymo
nuScenses的摄像头数据是360度的,而waymo的只有252度,但是Waymo的标注是360度的,故需要把不在摄像头FOV内的真值标注给剔除掉。
4.2 实验设置
网络backbone: ResNet101-DCN和VoVnet-99,利用了3层的多尺度FPN特征,特征通道数是256。BEV query是200x200,代表-51.2m, 51.2m,每个格子宽度是0.512m。BEV queryhi可学习的,编码器有6个编码层。做空间交叉注意力时,每个BEV query先在pillar层面根据高度范围-5m, 3m平均lift成4个参考点,每个参考点都应到对应的2D特征上后再利用可变性注意力获取4个采样点特征交互。
4.3 3D目标检测
nuScenses上比DETR3D提升NDS 9个点,而且可以预测速度(mAVE)
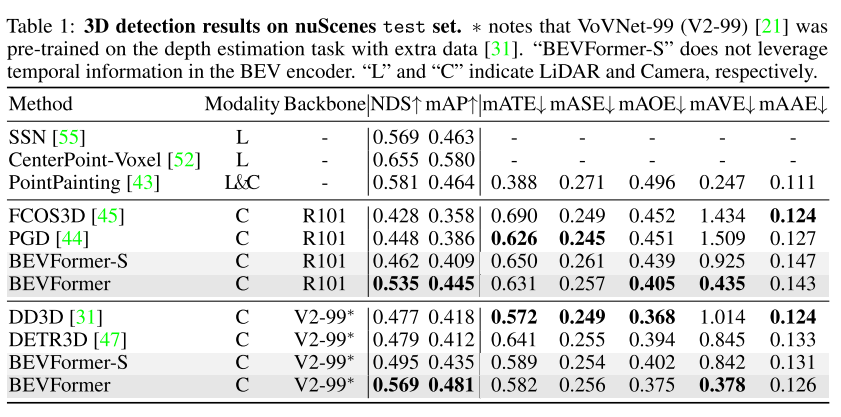
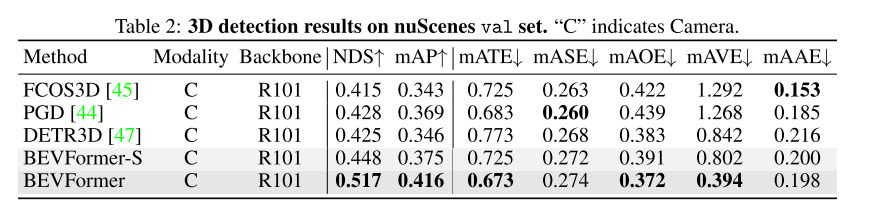
即使是只做单目3D目标检测,效果也比之前的纯视觉方案(CaDNN)好。

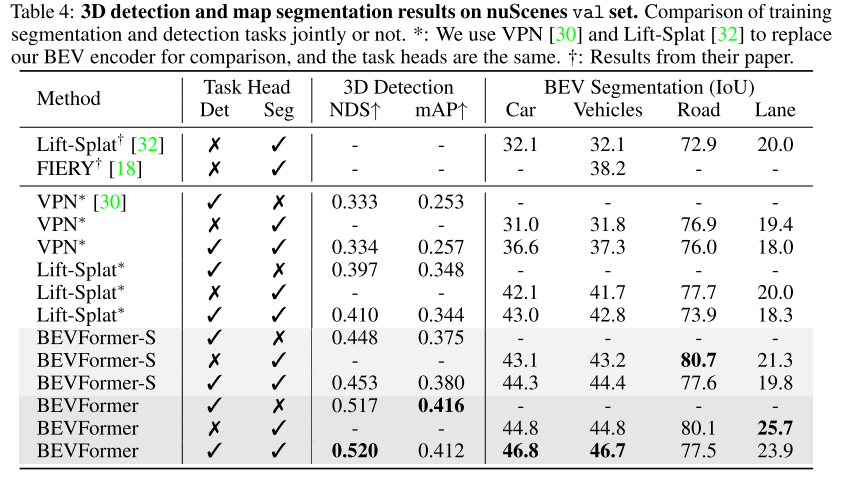
4.4 多任务网络
3D目标检测和语义分割一块做时,整体是有提升,但是融入时序信息时road分割结果略有下降。在多任务训练网络相对于单任务网络,对road和lane分割任务并未有提升,其他论文中已有提及。
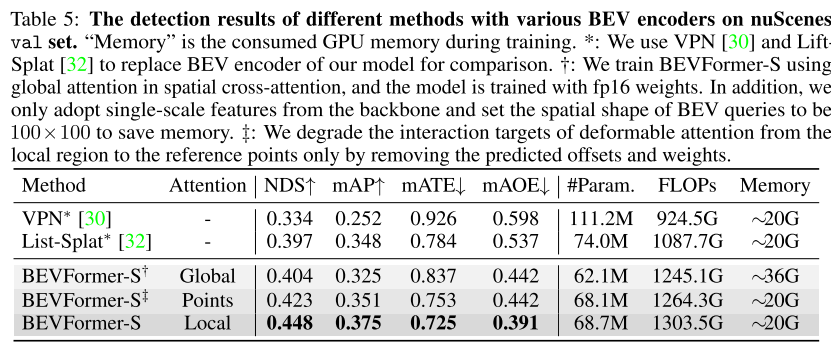
4.5 消融实验
空间交叉注意力:分别做了全局注意力(global att),单点注意力,和局部区域注意力(deformable att),采用全局注意力效果显存消耗太大,单点注意力感受也受限,局部区域注意力效果最后而且显存消耗也不大。
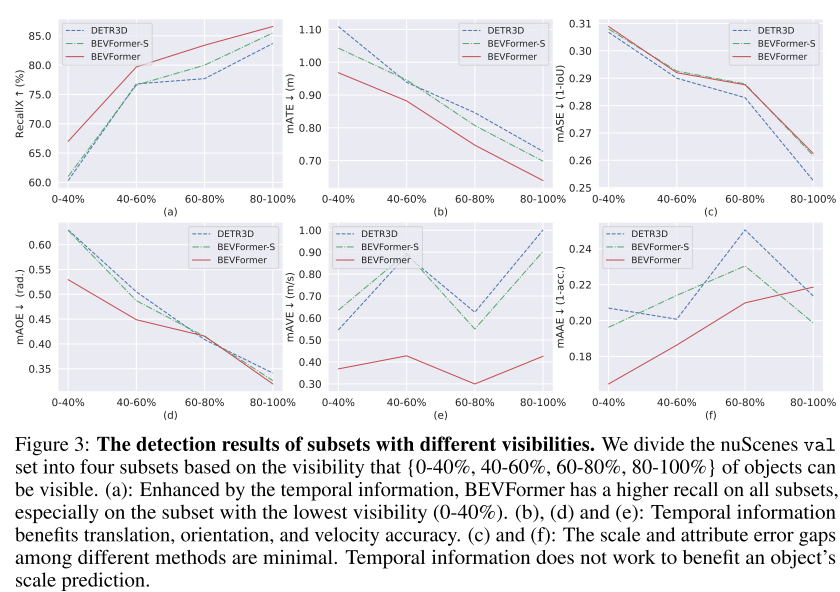
时序自注意力:引入时序信息的几大好处:1)可以估估计速度,2)目标预测位置和超限更准,3)对于遮挡目标有更高的召回率(下图所示)。
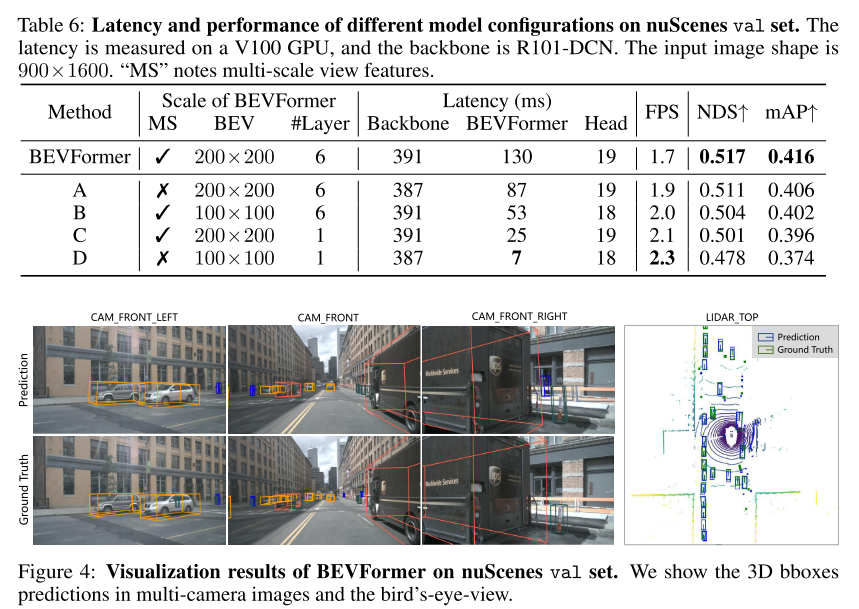
模型规模和延迟对比:
V100 GPU测试,图像输入大小是900x1600, backbone是R101-DCN, 主要耗时点在Backbone。
5 结论
BEVFormer融合时序信息和空间信息非常高效,支持多任务。