与AI对话的暗语:Prompt、分词器与Token的生存指南
当你对ChatGPT说出"你好"时,它看到的不是汉字,而是一串神秘数字;你以为自己在对话,实际上是在用一套精密暗语为它编写思维剧本。欢迎来到大语言模型的前台后台。
序章:一道翻译谜题
假设你受命制造一台能理解一切的翻译机器。
你首先发现,人类的语言千变万化------英语单词间有空格,中文汉字却紧密相连,日语混杂着三种文字系统。你的机器需要一套统一的方法,把所有这些流水般的句子,切成它能够处理的标准颗粒。
接着你意识到,机器不懂"爱"、"革命"或"量子"的含义。它只认识数字。因此,每个颗粒都必须对应一个唯一的数字身份证。
最后你明白了,机器不会主动思考。你必须把问题,转化成它能执行的明确指令剧本。
这三个发现,分别对应着今天故事的三个主角:分词器、Token与ID、以及Prompt。它们共同构成了人类与AI那座看不见的桥梁。
第一幕:分词器 ------ 模型的"阅读眼镜"
分词器,是大语言模型理解人类文字的第一步,也是最被低估的一步。你可以把它想象成模型佩戴的一副特制"阅读眼镜"。
-
它做了什么? 它的任务是将你输入的自然语言(无论是"Hello world!"还是"你好,世界!"),切割成模型能够消化的小单元,这些单元就是Token。
-
为什么需要它? 因为计算机无法直接理解字符的含义。通过将文本转化为Token序列,模型便有了可计算、可模式化的基础输入。
一个关键洞察是:Token ≠ 单词,尤其对中文而言。
-
对于英文,"cat"可能是一个Token,"sitting"可能被切成"sit"和"ting"两个Token。常见的单词通常自成一体,生僻长词会被拆分。
-
对于中文,一个汉字(如"猫")通常就是一个Token,但常见的词语(如"人工智能")可能会被组合成一个Token,因为这更高效。分词器内置的"词典"决定了如何切分。
python
# 分词过程的极简示意(非真实代码)
输入文本: "我爱北京天安门"
GPT-4分词结果: ['我', '爱', '北京', '天安门']
# 注意:"北京"和"天安门"作为常见实体,被保留为整体Token。
其他分词器结果: ['我', '爱', '北', '京', '天', '安', '门']
# 不同的分词策略,会导致完全不同的Token序列。为什么分词器重要? 它直接影响了模型的"世界观"。糟糕的分词会破坏语义(如将"特朗普"错误切开),增加处理长度,并降低效率。一个好的分词器,是模型高效理解语言的基础设施。
第二幕:Token与Token ID ------ 语言的"数字基因"
经过分词器切割后,我们得到了一串Token 。这是大模型世界里信息交换的基本货币。
-
Token是什么? 它是语言在模型中的离散化表示。可以是单词、子词、汉字或标点。你可以把它理解为模型思维流中的一个"意义颗粒"。
-
Token ID是什么? 这是Token在模型"词典"中的唯一编号。这个词典(通常有数万到数十万个词条)在模型训练前就已固定。例如,在GPT的词典中,"猫"可能对应ID 12345,"the"可能对应ID 456。
这个过程,就是文本的数字化编码:
python
人类: "你好,世界"
分词器: ["你", "好", ",", "世界"]
Token ID: [123, 456, 789, 1024] # 假设的ID模型处理的就是 [123, 456, 789, 1024] 这串数字。它通过海量训练,学会了这些数字ID背后复杂的统计关系和语义关联。当它想输出"你好"时,实际上是在计算下一个ID是 123 和 456 的概率最高。
理解Token的实用意义:
- 计费依据 :所有主流AI API都按Token数量计费。输入和输出的Token总数决定了你的花费。

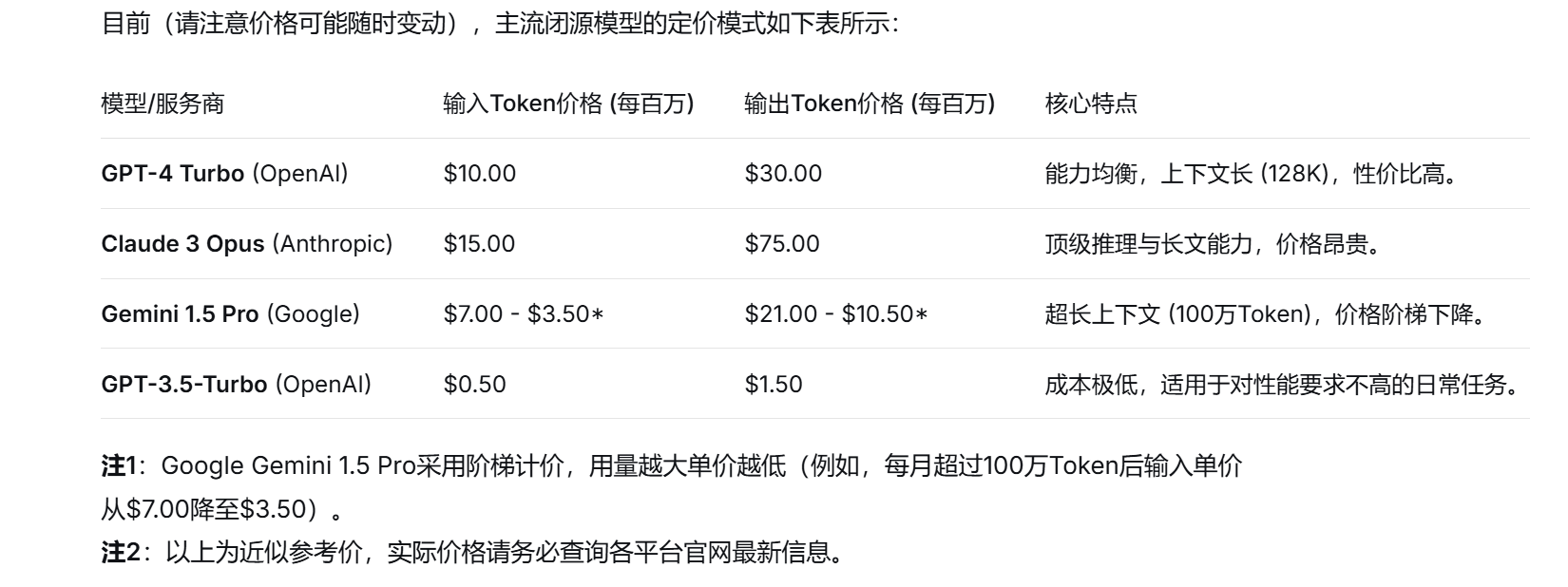
- 上下文长度限制 :模型的"记忆力"由其上下文窗口(如128K Tokens)决定。这限制了单次对话能处理的信息总量。

128K Tokens不是内容在硬盘上的"大小"(那叫文件体积,单位是MB/GB),而是模型在处理时,能同时"照亮"和"考虑"的Token的"最大数量"。
模型必须把当前对话中的所有文本(你的问题+它的回答+你提供的文件内容+历史记录)都转换成Tokens,并全部装载进这个"工作台"里才能进行运算。如果总Token数超过128K,最开始的那些信息就会像从工作台边缘掉落一样,被彻底遗忘,模型将无法基于它们进行推理。
- 性能影响:处理更长的Token序列需要更多的计算资源和时间。
第三幕:Prompt ------ 对话的"导演脚本"
如果说Token是演员(信息单元),那么Prompt 就是导演写给AI这位主演的完整剧本和即时指令。它是你与模型交互的全部输入,决定了AI将扮演什么角色、如何思考以及输出什么。
Prompt不仅仅是一个问题。它是一个精心构造的"思维上下文"。
-
基础Prompt:"法国的首都是哪里?" (直接提问)
-
角色扮演Prompt:"假设你是一位资深历史学家,请用易于理解的方式,解释法国首都巴黎在18世纪的重要性。" (定义角色、风格和任务)
-
思维链Prompt:"请一步步推理:如果所有猫都会飞,而我的宠物咪咪是一只猫,那么咪咪会飞吗?" (要求展示推理过程)
-
少样本学习Prompt:给出几个输入输出的例子,然后让模型完成新的。例如:
python例子1: 输入: "商品: 手机,情感: 满意" 输出: "这款手机真是太棒了,流畅度高,拍照清晰,完全满足了我的期待!" 输入: "商品: 快递服务,情感: 失望" 输出:(模型会模仿示例的格式和风格进行生成)
Prompt Engineering(提示词工程) 之所以成为一门学问,就是因为模型的输出质量极度依赖于Prompt的写法。一个清晰的Prompt,能引导模型调动相关知识,组织逻辑,并格式化输出,就像一位好导演能激发演员的最佳表演。
终章:协作的哲学
理解这套流程后,我们与AI的对话便呈现出一种新的图景:
-
你构思一个意图,并将其组织成自然语言(Prompt)。
-
分词器介入,像手术刀一样将你的句子切割成Token序列。
-
这些Token被瞬间转换为冰冷的Token ID数字流。
-
大模型这个"数字宇宙"开始运转,在这串数字和它万亿参数所编码的知识海洋中,进行一场庞大的概率计算,寻找最可能的下一串数字。
-
这串新的数字ID被反向查找,变回Token,再组合成自然语言。
-
你读到了回答,仿佛一次普通的交流。
整个过程,人类用模糊、丰富的自然语言发起,机器用精确、离散的数字进行计算,最终又回归人类可读的语言。Prompt是意图的封装,Token是信息的载体,分词器是翻译的规则。
这提醒我们两件事:
第一,你永远在通过一个有限的"词典"和一套固定的"切片规则"与AI交流 ,这从根本上划定了沟通的边界。
第二,最有效的对话,始于你成为一个好的"编剧"------知道如何用清晰的Prompt,为你那拥有万亿参数的超级"演员",写下最能激发其潜能的剧本。
下次当你与AI对话时,或许可以停顿一秒,想象你的话语正被转化为星河般的数字流,在一个人造大脑中掀起风暴。而你,正是这场风暴最初的那阵微风。