almalinux下部署promethues+grafana服务-容器化
- 一、简介:
- 二、环境准备:
- 三、安装步骤:
- 四、报错记录:
- 五、命令总结
-
- [1、docker compose](#1、docker compose)
- 2、grafana监控项查看
- 3、prometheus的核心架构和工作流程
一、简介:
在工作中经常使用prometheus和grafana组件进行监控数据收集和展示,或者是将grafana页面再二次开发展现在对应的监控页面中。知其然这么久了,在本地虚机部署下知其所以然一下。
prometheus+grafana+linux_exporter是prometheus生态中最经典的linux主机监控方案,实用性和灵活性都很强。
- linux_exporter负责监控数据收集,运行在linux主机上的轻量组件,通过读取系统内核文件(/proc和/sys等),实时采集CPU、内存、硬盘、网络等系统级指标,在通过9100端口的metrics接口以prometheus规范暴露数据。
- prometheus是监控核心引擎,负责从linux_exporter定期"抓取"指标数据,存储到内置的TSDB(时序数据库)中,同时支持多维度数据查询(PromQL语法),告警规则配置和告警触发。
- grafana是可视化展示端,作为专业的监控仪表盘工具,通过对接prometheus数据源,将原始指标数据转化为直观的图表(折线图、柱状图、仪表盘等),支持自定义仪表盘、多数据源整合和告警可视化。
prometheus+grafana+linux_exporter监控方案特点:
- 轻量高效,部署成本低:linux_exporter资源占用小(内存通常小于50MB),prometheus和grafana支持容器化部署,单节点即可满足中小规模监控需求,集群模式可横向扩展。
- 数据实时性强,查询灵活:prometheus默认15秒抓取一次数据,支持自定义抓取间隔;PromQL语法可实现多维度筛选(如按照主机、指标类型过滤)、聚合计算(如平均值、最大值),快速定位问题。
- 可视化能力强大:grafana提供丰富的预制仪表盘模版(可直接导入linux监控模版),也支持拖拽式自定义仪表盘,支持多指标组合展示、时间范围缩放,直观呈现系统资源变化趋势。
- 告警体系完善:prometheus可配置自定义告警规则(如CPU使用率大于百分之八十持续五分钟触发告警),支持对接邮件、钉钉、slack等告警渠道,grafana也可基于图表配置告警,实现"可视化+告警"联动。
- 开源免费,生态成熟:三者均为开源项目,无商业授权成本,社区活跃,文档丰富,支持与k8s、云平台等其他组件无缝集成。
prometheus+grafana+linux_exporter监控方案适用场景:
- 中小规模linux主机集群监控:适用于企业内部物理机、虚拟机集群(10-100主机),需统一监控资源使用状态。
- 容器化环境linux节点监控:在docker或者k8s集群中,通过容器化部署linux_exporter,监控每个节点的底层资源使用情况,补充k8s监控的不足。
- 开发或测试环境监控需求:无需复杂配置,快速搭建监控体系,满足开发、测试阶段对主机资源的实时观察和问题排查需求。
- 需要自定义监控需求场景:支持通过PromQL自定义指标计算,grafana自定义仪表盘,适配不同业务的监控侧重点(如重点监控磁盘IO、网络带宽等)。
- 轻量级告警需求:适用于需要基础告警能力(如资源使用率超标告警),无需复杂运维平台的场景,告警规则配置简单易懂。
官网地址放在这里,兄弟们有需求自取。
promethues官网:promethues官网地址
grafana官网:grafana官网地址
接着查看下各组件官网文档确定下当前版本有哪些,要部署就整个最新还能看看有啥新功能。
promethues官方文档:查看promethues官方文档中版本
grafana官方文档:查看grafana官方文档中版本
github查看下node_exporter的版本node_exporter版本
二、环境准备:
这里准备两台虚机,一台机器-server将prometheus+grafana服务部署上,另外一台虚机-node安装个node_exporter将监控数据上报过去;然后在本地的笔记本上安装一个window的exporter监控下win的监控数据。
如果你没有docker安装源或者是连机器都没有可以参考这篇文章:almalinux系统-基础环境准备
机器信息:
| 操作系统 | IP地址 |
|---|---|
| almalinux | 192.168.100.30【prometheus+grafana+node_exporter】 |
| almalinux | 192.168.100.31 【node_exporter】 |
| window10 | 192.168.100.1 【Windows_exporter】 |
版本记录如下:
| 软件名 | 版本 |
|---|---|
| docker-ce | 29.1.4 |
| docker compose | v5.0.1 |
| prometheu | v3.7.0 |
| grafana | 12.3.0 |
| node_exporter | 1.10.1 |
| windows_exporter | 0.31.3 |
下面实验使用到的容器镜像和windows_exporter的软件的百度云链接:proetheus+grafana+exporter软件百度云下载地址
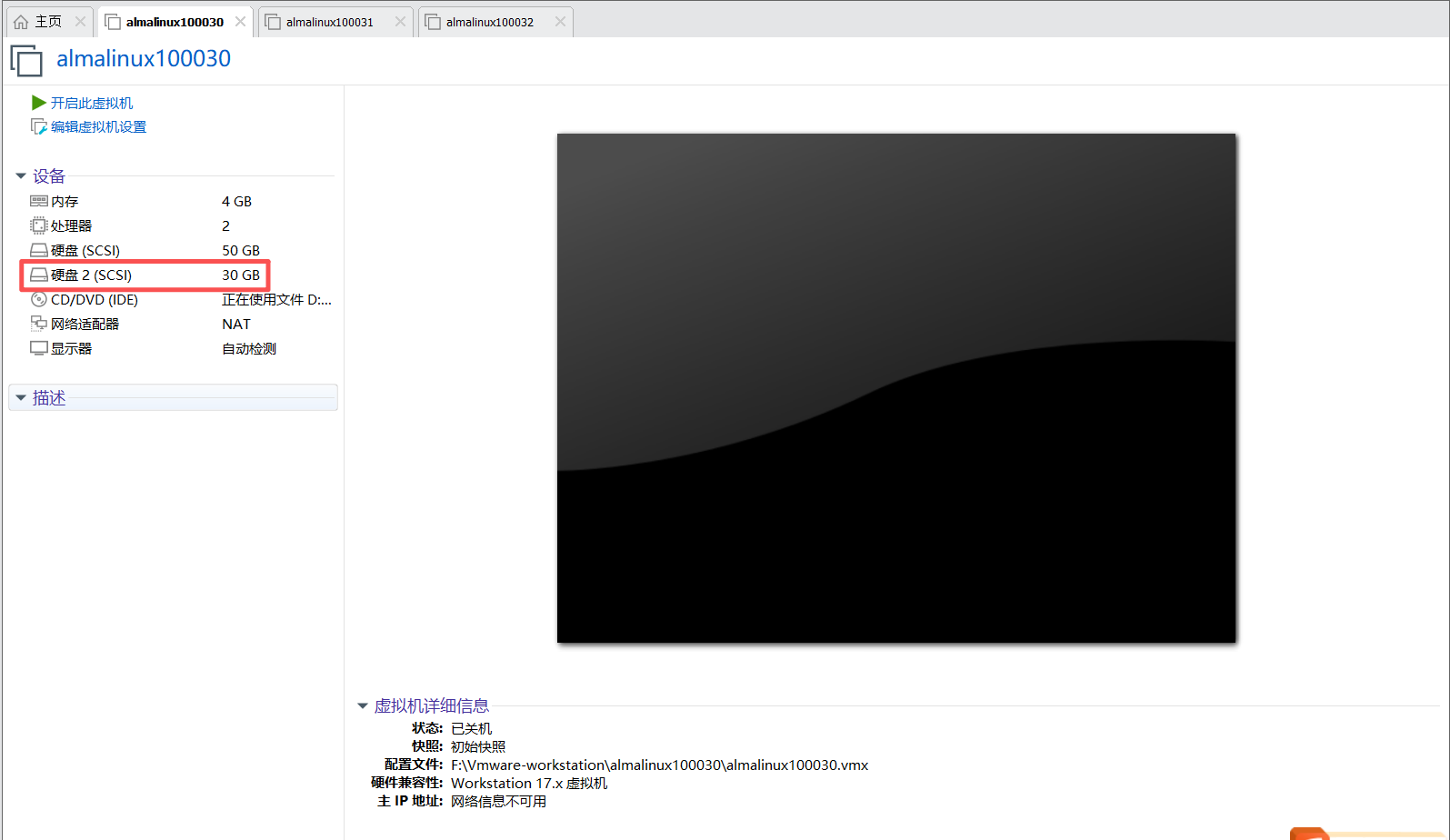
这里给第一台虚机添加一个磁盘作为数据存储;
三、安装步骤:
0、格式化数据盘并挂载
第一台机器-进入虚机先将数据盘格式化设置个开机自动挂载;
bash
#查看磁盘系统是正常识别的
lsblk /dev/sdb
#将这块数据盘分一个区给全部容量
parted --script /dev/sdb mklabel gpt mkpart primary ext4 0% 100%
#将磁盘格式化成xfs格式
mkfs.xfs /dev/sdb1
#查看下格式化磁盘的UUID写入fstab确保开机自启
blkid /dev/sdb1
echo 'UUID="25b1d60b-3a95-4b41-923e-6d9d185d0840" /data xfs defaults 0 0' >> /etc/fstab
#创建下挂载目录
mkdir /data
#(非必须)这个是我操作时候mount -a时候提示我执行
systemctl daemon-reload
#通过fstab文件进行磁盘挂载并且查看挂载目录是正常的
mount -a
df -h /data/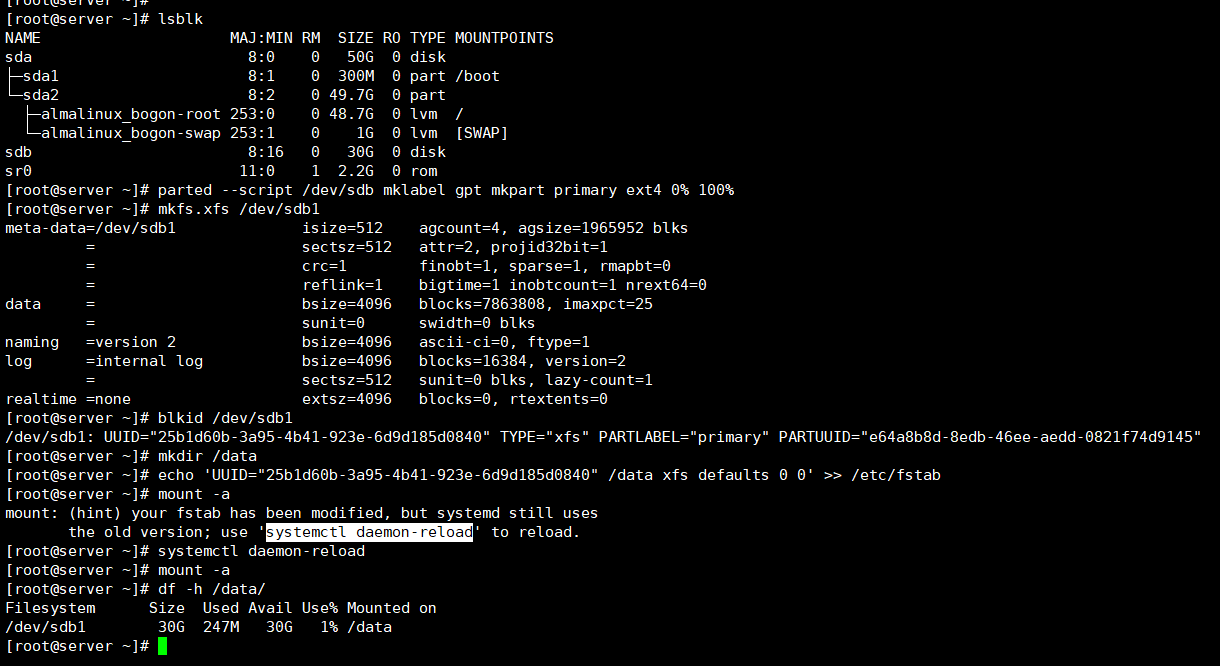
1、docker-ce安装
安装docker-ce等软件并设置开机自启;
PS:这里就在第一台机器上执行就好,第二台机器执行步骤在下面。
dnf install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
systemctl enable --now docker
docker --version ------》Docker version 29.1.4, build 0e6fee6
docker compose version ------》Docker Compose version v5.0.12、时间同步和部署文件
安装下时间同步软件chronyd,在almalinux的软件包源中没有ntp服务。
PS:这里就在第一台机器上执行就好,第二台机器执行步骤在下面。
bash
# 安装软件并设置为开机自启
dnf install -y chrony.x86_64
systemctl enable --now chronyd
# 备份下chronyd配置文件然后写入新的重启下服务
cp /etc/chrony.conf /etc/chrony.conf.bak
cat > /etc/chrony.conf << EOF
# 国内时间服务器列表
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
# 同步硬件时间
rtcsync
# 当系统时间与硬件时间差异较大时,允许调整硬件时间
makestep 1.0 3
# 日志文件路径
logdir /var/log/chrony
EOF
systemctl restart chronyd创建数据目录和部署目录;
bash
# 数据目录
mkdir -p /data/prometheus-grafana/{prometheus,grafana}
# Grafana 容器默认使用 UID=472 的 grafana 用户运行,直接给宿主机目录授权这个 UID 即可(无需开放 777 宽权限):
chown -R 472:472 /data/prometheus-grafana/grafana
# Prometheus 容器默认以 nobody 用户(UID=65534)运行,授权命令:
chown -R 65534:65534 /data/prometheus-grafana/prometheus
# 部署目录
mkdir -p /opt/prometheus-grafana/{prometheus,grafana}
cd /opt/prometheus-grafana准备prometheus和docker compose的配置文件;
bash
pwd------》/opt/prometheus-grafana
[root@server prometheus-grafana]# vim prometheus/prometheus.yml
global:
scrape_interval: 15s # 全局采集周期:每 15 秒拉取一次指标(可根据需求调整)
evaluation_interval: 15s # 规则评估周期:每 15 秒评估一次告警规则
scrape_configs:
# 采集 Prometheus 自身指标
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集 Node-Exporter 指标(关键配置)
- job_name: 'node-exporter-local' # 任务名,可自定义(Grafana 模板会用到)
static_configs:
# 目标地址:容器间通信用服务名(node-exporter)+ 端口(9100)
# 若 Node-Exporter 部署在其他 Linux 主机,此处改为 <目标主机IP>:9100(需放行 9100 端口)
- targets: ['node-exporter:9100']
labels:
hostname: 'almalinux-server-192e168e100e30' # 自定义主机名标签
env: 'production' # 自定义环境标签
# 采集目标Linux虚机指标(关键配置)
- job_name: 'node-exporter-remote' # 任务名,自定义(如虚机 hostname)
static_configs:
# 目标地址:目标虚机IP + 9100端口(多个虚机用逗号分隔)
- targets: ['192.168.100.31:9100'] # 替换为你的目标虚机实际IP
labels:
hostname: 'almalinux-server-192e168e100e31' # 自定义主机名标签
env: 'production' # 自定义环境标签
# 如果有多台机器的话可以这么写
# - targets: [
# '192.168.1.200:9100', # 虚机1
# '192.168.1.201:9100', # 虚机2
# '192.168.1.202:9100' # 虚机3
# ]
# labels:
# env: 'production' # 统一标签,方便筛选
# 采集 Windows 机器的 Windows Exporter 指标
- job_name: 'windows-exporter' # 任务名,自定义
static_configs:
# 目标地址:Windows 机器 IP + 9182 端口(多个 Windows 机器用逗号分隔)
- targets: ['192.168.100.1:9182']
labels:
hostname: 'windows10-192e168e100e1' # 自定义主机名标签
env: 'production' # 自定义环境标签
[root@server prometheus-grafana]#
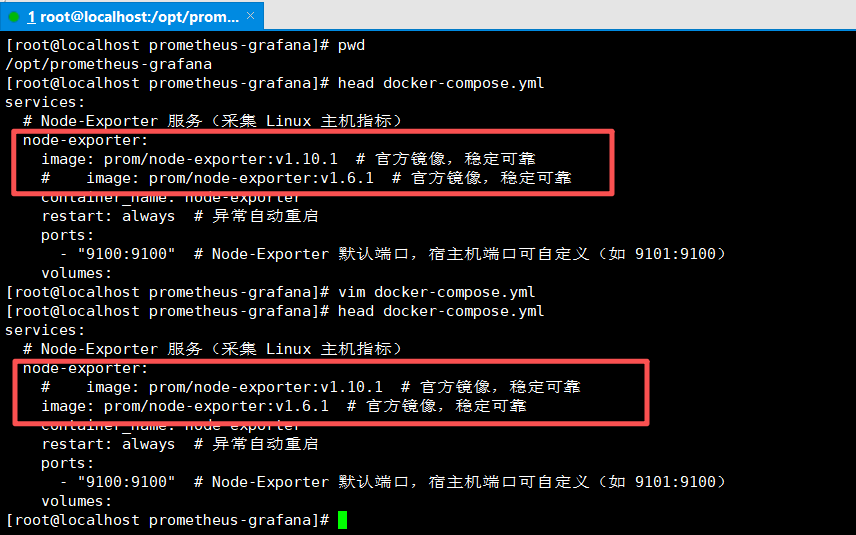
[root@server prometheus-grafana]# vim docker-compose.yml
services:
# Node-Exporter 服务(采集 Linux 主机指标)
node-exporter:
# image: prom/node-exporter:v1.10.1 # 官方镜像,稳定可靠
image: prom/node-exporter:v1.6.1 # 官方镜像,稳定可靠
container_name: node-exporter
restart: always # 异常自动重启
ports:
- "9100:9100" # Node-Exporter 默认端口,宿主机端口可自定义(如 9101:9100)
volumes:
# 挂载宿主机核心目录,用于采集系统指标(必须挂载,否则无数据)
- /proc:/host/proc:ro # 只读权限,避免容器修改宿主机文件
- /sys:/host/sys:ro
- /:/rootfs:ro
- /run/systemd:/run/systemd:ro # 挂载systemd文件
- /var/run/dbus:/var/run/dbus:ro # 提供 dbus socket 文件
- /etc/localtime:/etc/localtime:ro # 挂载宿主机时区,保持时间同步
- /etc/timezone:/etc/timezone:ro # 同步时区配置
command:
# 告知 Node-Exporter 挂载目录的实际路径(关键参数,否则指标采集异常)
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)' # 忽略无关挂载点,减少无用指标
- '--collector.pressure' # 支持 Pressure 面板(node_pressure_* 指标)
- '--collector.processes' # 支持进程/线程/PID面板(node_processes_* 指标)
- '--collector.systemd' # 支持 Systemd 面板(node_systemd_* 指标)
- '--collector.hwmon' # 支持硬件温度/风扇面板(node_hwmon_* 指标)
- '--collector.interrupts' # 支持 IRQ 中断面板(node_interrupts_* 指标)
- '--collector.cpu' # 确保 CPU 相关指标正常(默认已开,显式声明更稳妥)
- '--collector.meminfo' # 确保内存指标正常
- '--collector.diskstats' # 确保磁盘指标正常
- '--collector.netdev' # 确保网络指标正常
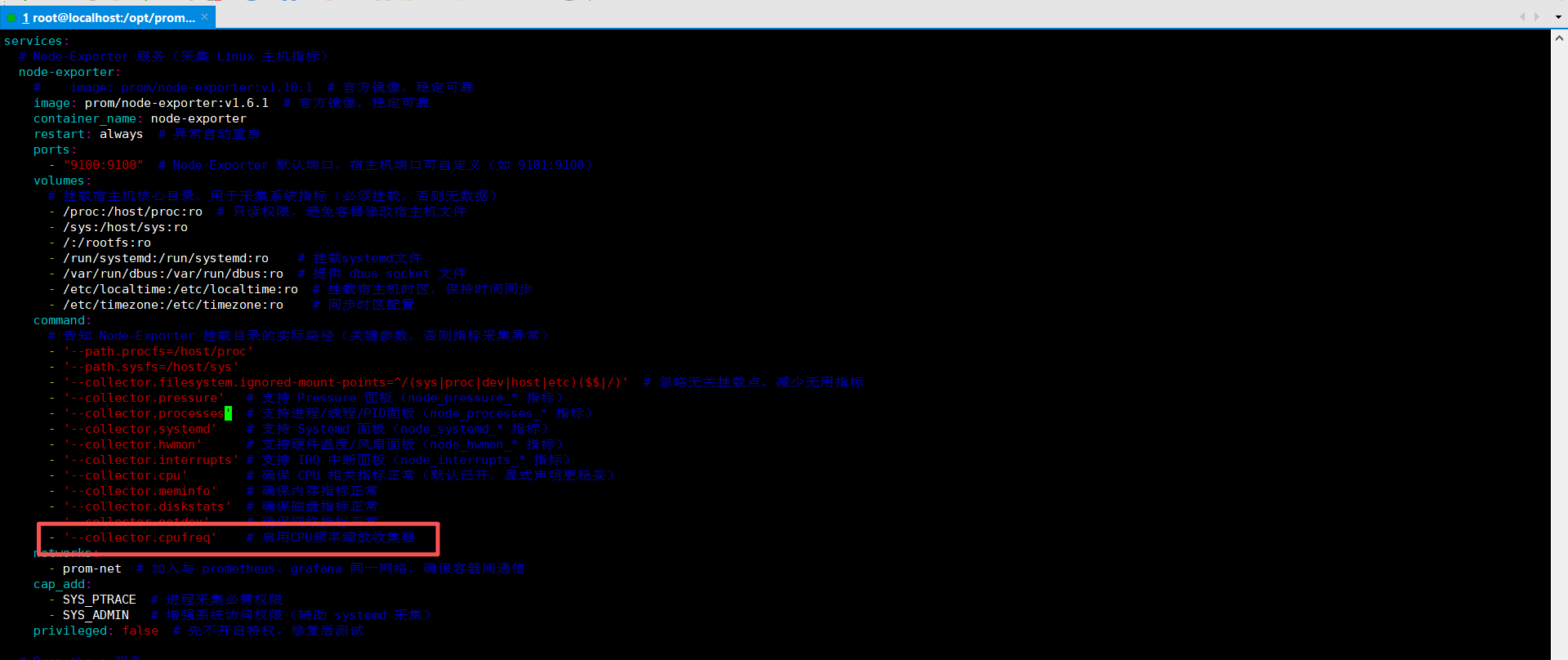
- '--collector.cpufreq' # 启用CPU频率缩放收集器
networks:
- prom-net # 加入与 prometheus、grafana 同一网络,确保容器间通信
cap_add:
- SYS_PTRACE # 进程采集必需权限
- SYS_ADMIN # 增强系统访问权限(辅助 systemd 采集)
privileged: false # 先不开启特权,修复后测试
# Prometheus 服务
prometheus:
image: prom/prometheus:v3.7.0 # 稳定版本(可替换为最新版)
container_name: prometheus
restart: always # 开机自启
ports:
- "9090:9090" # 宿主机端口:容器端口
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml # 挂载配置文件
- /data/prometheus-grafana/prometheus:/prometheus # 自定义宿主机目录-绑定挂载
#- prometheus-data:/prometheus # 默认用法-命名数据卷(仅指定数据卷名称,docker会自动在宿主机/var/lib/docker/volumes/下创建存储目录)
- /etc/localtime:/etc/localtime:ro # 挂载宿主机时区,保持时间同步
- /etc/timezone:/etc/timezone:ro # 同步时区配置
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
networks:
- prom-net # 加入与 prometheus、grafana 同一网络,确保容器间通信
# Grafana 服务
grafana:
image: grafana/grafana:12.3.0 # 稳定版本(可替换为最新版)
container_name: grafana
restart: always
ports:
- "3000:3000" # 宿主机端口:容器端口
volumes:
- /data/prometheus-grafana/grafana:/var/lib/grafana # 自定义宿主机目录-绑定挂载
#- grafana-data:/var/lib/grafana # 默认用法-命名数据卷(仅指定数据卷名称,docker会自动在宿主机/var/lib/docker/volumes/下创建存储目录)
- /etc/localtime:/etc/localtime:ro # 挂载宿主机时区,保持时间同步
- /etc/timezone:/etc/timezone:ro # 同步时区配置
environment:
- GF_SECURITY_ADMIN_PASSWORD=Admin@123 # 自定义 Grafana 管理员密码(建议修改)
depends_on:
- prometheus # 依赖 Prometheus 服务,启动顺序保证
networks:
- prom-net # 加入与 prometheus、grafana 同一网络,确保容器间通信
# 统一网络:确保 3 个服务在同一网络,容器间可通过服务名(如 node-exporter)通信
networks:
prom-net:
driver: bridge
## 默认用法-命名数据卷(仅指定数据卷名称,docker会自动在宿主机/var/lib/docker/volumes/下创建存储目录)
#volumes:
# prometheus-data:
# grafana-data:
[root@server prometheus-grafana]# 3、容器镜像导入
这是镜像导出之前查看的镜像信息,在导入之后对比下确定容器镜像是正常导入;
bash
[root@localhost ~]# docker images --digests
REPOSITORY TAG DIGEST IMAGE ID CREATED SIZE
grafana/grafana 12.3.0 sha256:70d9599b186ce287be0d2c5ba9a78acb2e86c1a68c9c41449454d0fc3eeb84e8 70d9599b186c 8 days ago 989MB
prom/node-exporter v1.10.1 sha256:b01f6d5e6945d5001894165cce46a80fd8d0cfee68c35c8b251c50d8d446ba75 b01f6d5e6945 4 weeks ago 41.4MB
prom/node-exporter v1.6.1 sha256:81f94e50ea37a88dfee849d0f4acad25b96b397061f59e5095905f6bc5829637 81f94e50ea37 2 years ago 37.2MB
prom/prometheus v3.7.0 sha256:29c1e0b48ad816750245dea3d65ac3ce57dda30547e67b1e9a5176e2953cc4dc 29c1e0b48ad8 6 weeks ago 507MB
[root@localhost ~]# 这里将云盘的镜像压缩包放到机器上导入之后查看下镜像信息;
PS:注意目录我这里习惯性将东西放到secure用户家目录下面,你自己在哪就在那执行哈!
bash
cd /home/secure/images-prometheus+grafana-20251127/
docker load -i prom_prometheus_v3.7.0.tar
docker load -i grafana_grafana_12.3.0.tar
docker load -i prom_node-exporter_v1.10.1.tar
docker load -i prom_node-exporter_v1.6.1.tar
docker images --digests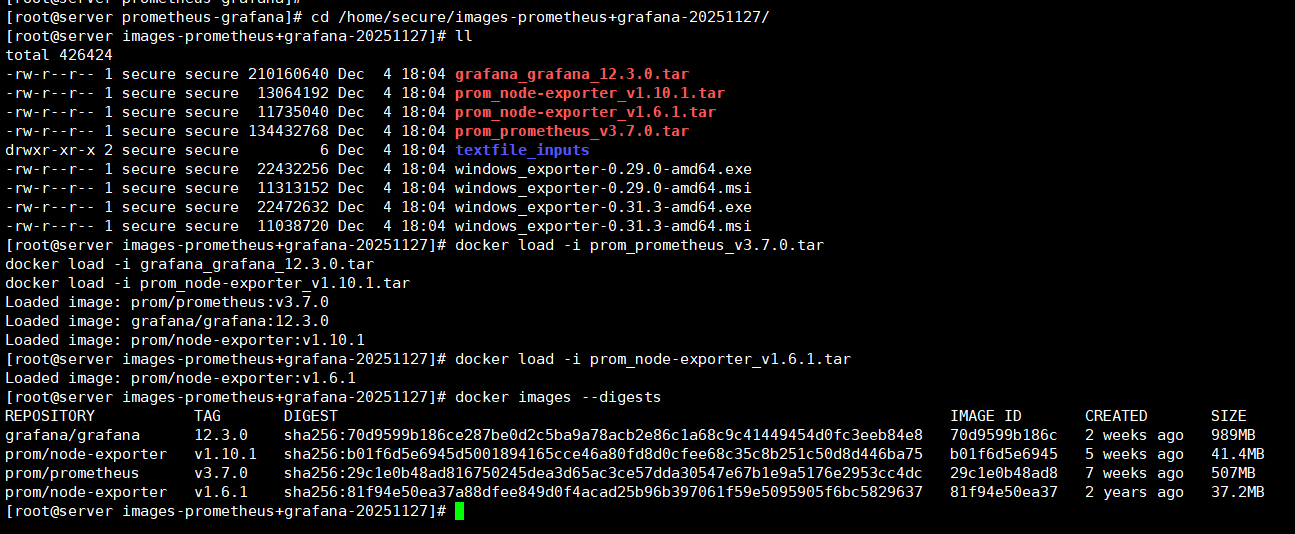
4、启动容器
启动之前可以进入docker-compose文件中将那个linux_exporter的镜像版本改成1.10.1,最新的。
PS:之前实验的时候第一次使用最新版本linux_exporterv1.10.1容器镜像在grafana加载的linux的模版之后监控图表有十三个没有监控数据,豆包了下说是镜像版本太高导致监控项名称改变和我导入的grafana的1860模版不匹配,所以换了个v1.6.1的镜像,结果更换了还是有13个监控图表没有监控数据,换不换效果一样。
PPS:linux_exporter的1.6.1和1.10.1两个版本镜像都是导入的,用那个都行。
通过docker compose来进行容器拉起;
pwd------》/opt/prometheus-grafana
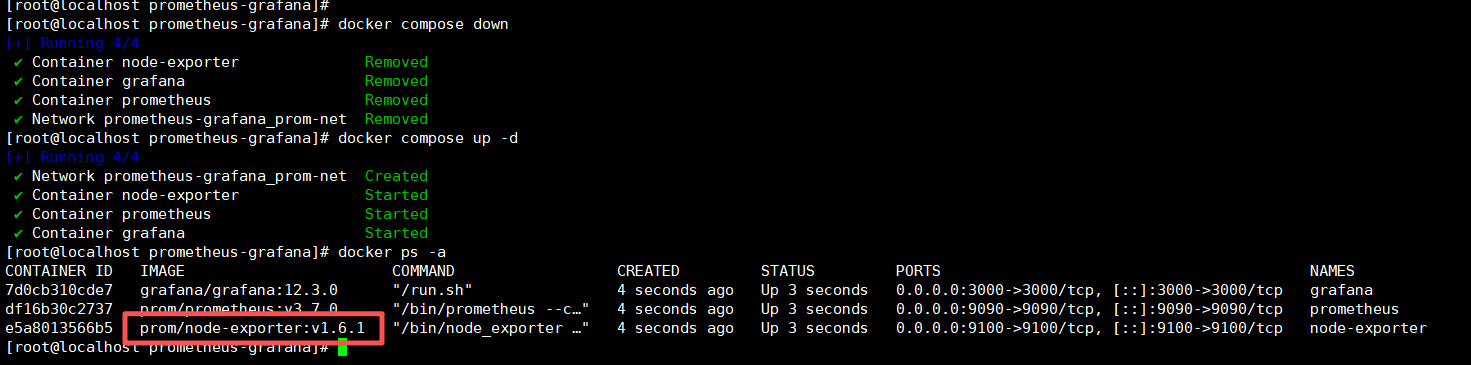
docker compose up -d
docker ps -a
5、浏览器访问
登录promethues页面------》http://192.168.100.30:9090
PS:这里地址是我自己虚机的地址,你虚机地址配置什么这里修改成对应地址。
PPS:如果你使用的是谷歌浏览器,你就使用无痕模式访问,不然有几率会被安全检查机制拦截,无痕模式就没有这种情况。
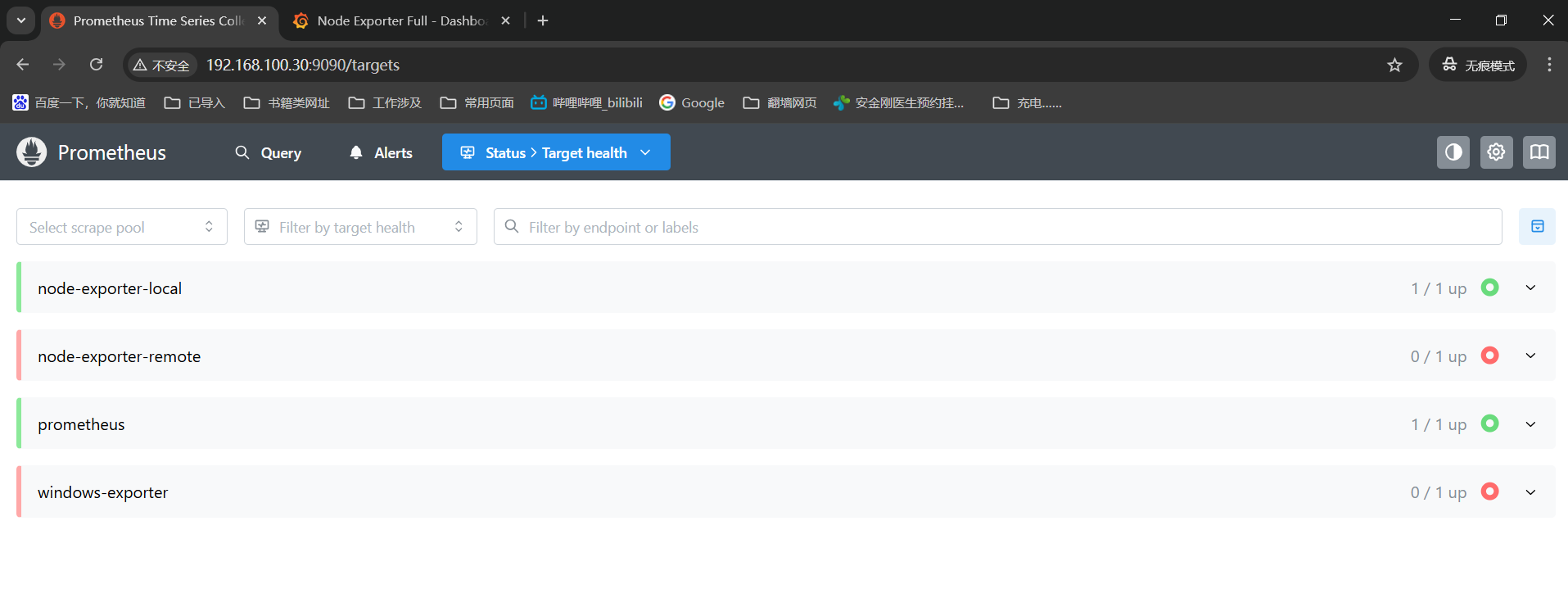
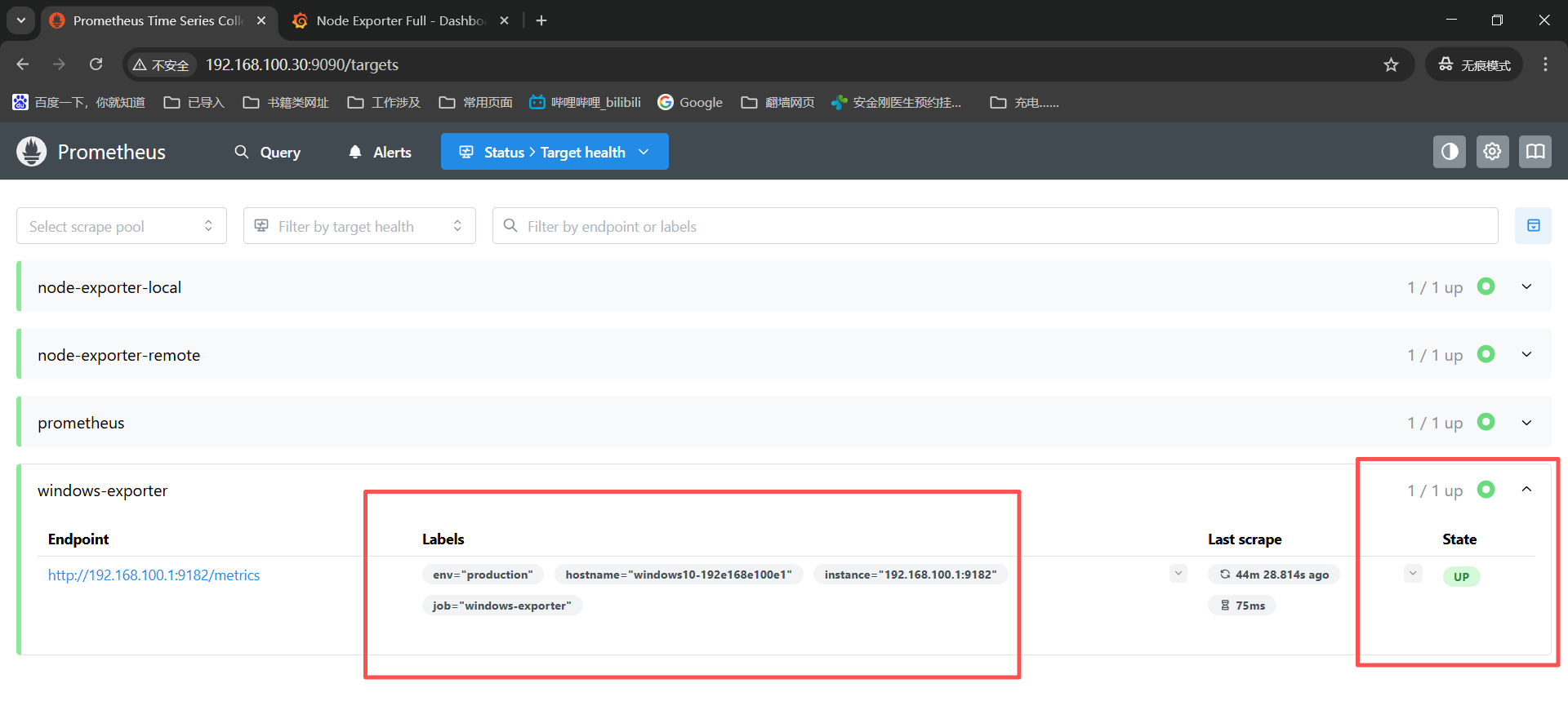
这里可以查看下监控机状态:
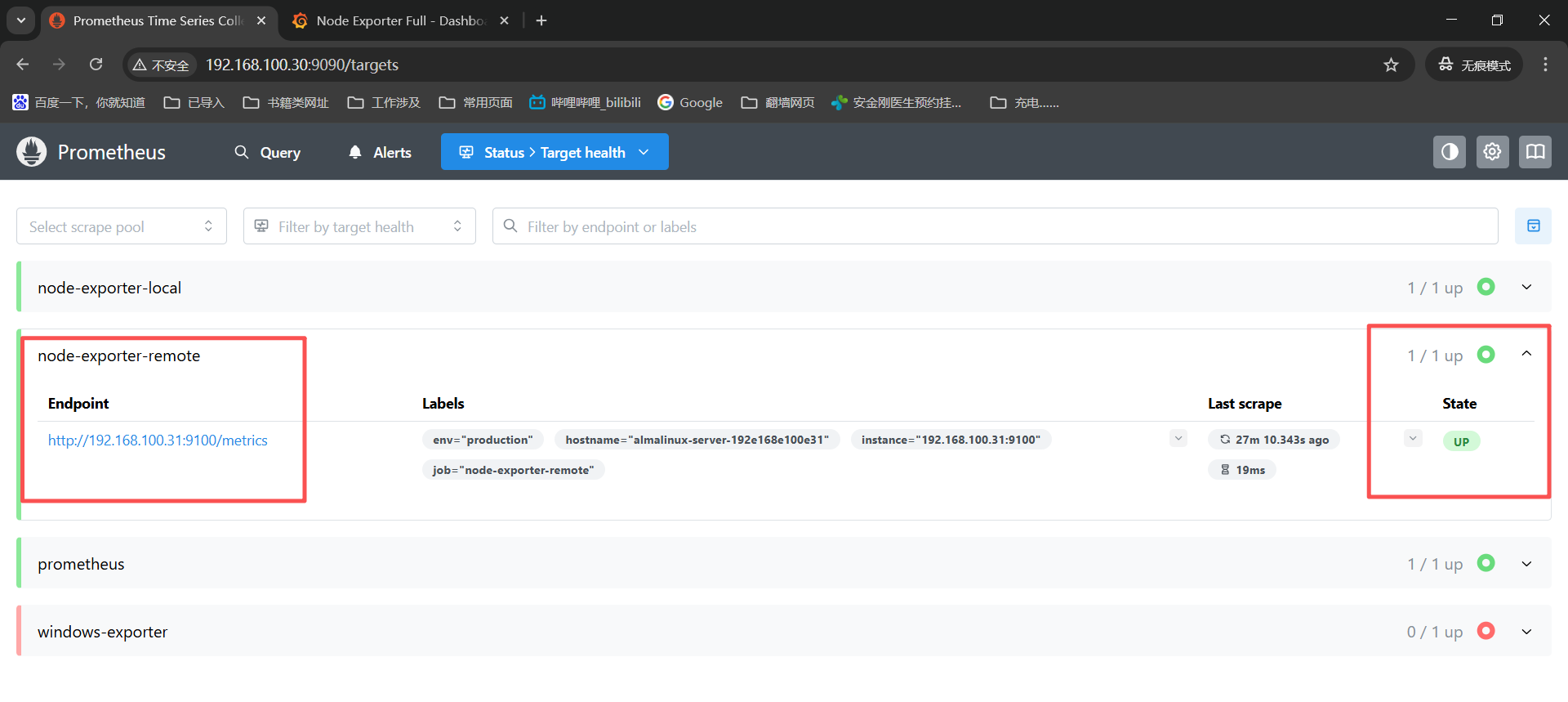
status------》target health下面能看到四个记录,现在能看到两个绿色的是up,另外两个是红色的up,这一个是node机器的exporter没有安装导致的,一个是win机器的exporter没安装,是红色就对了。
登录grafana页面------》http://192.168.100.30:3000【账号/密码:admin/Admin@123】
输入账号密码能看到这个页面说明我们grafana的容器是正常启动的,想看监控数据加载模版步骤在下面。
6、linux-node_exporter安装
node节点安装个时间同步,再安装个docker-ce了,然后将容器镜像下载,将node_exporter容器镜像导入就可以了。
bash
# 时间同步
dnf install -y chrony.x86_64
systemctl enable --now chronyd
cp /etc/chrony.conf /etc/chrony.conf.bak
cat > /etc/chrony.conf << EOF
# 国内时间服务器列表
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
# 同步硬件时间
rtcsync
# 当系统时间与硬件时间差异较大时,允许调整硬件时间
makestep 1.0 3
# 日志文件路径
logdir /var/log/chrony
EOF
systemctl restart chronyd
# 容器安装
yum install docker-ce -y
systemctl enable --now docker
# 容器镜像导入
pwd------》/home/secure/images-prometheus+grafana-20251127/
docker load -i prom_node-exporter_v1.6.1.tar
docker load -i prom_node-exporter_v1.10.1.tar
docker images --digests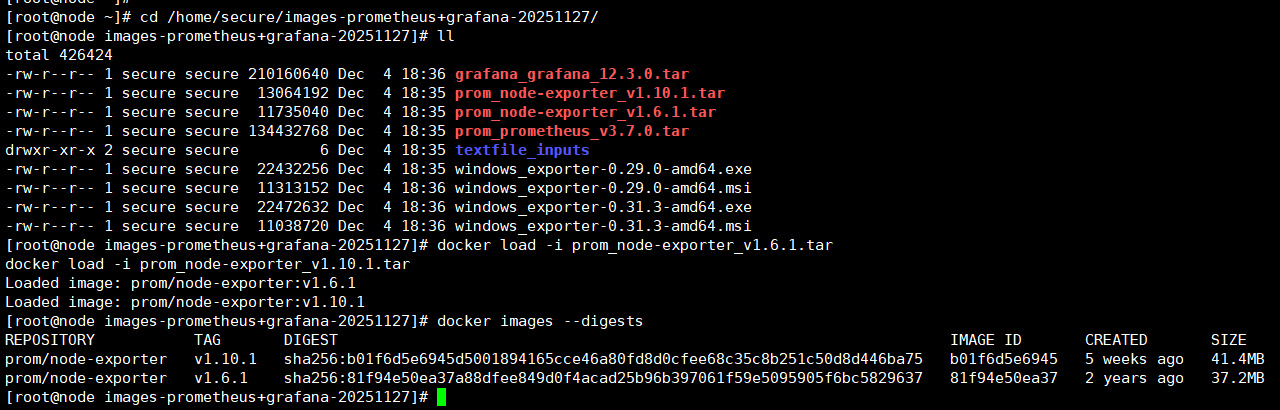
创建node_exporter容器将监控数据上报到prometheus中,
bash
docker run -d \
--name node-exporter \
--restart always \
-p 9100:9100 \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /:/rootfs:ro \
-v /run/systemd:/run/systemd:ro \
-v /var/run/dbus:/var/run/dbus:ro \
-v /etc/localtime:/etc/localtime:ro \
-v /etc/timezone:/etc/timezone:ro \
--cap-add=SYS_PTRACE \
--cap-add=SYS_ADMIN \
--privileged=false \
prom/node-exporter:v1.10.1 \
--path.procfs=/host/proc \
--path.sysfs=/host/sys \
--collector.pressure \
--collector.processes \
--collector.systemd \
--collector.hwmon \
--collector.interrupts \
--collector.cpu \
--collector.meminfo \
--collector.diskstats \
--collector.netdev \
--collector.cpufreq
docker ps -a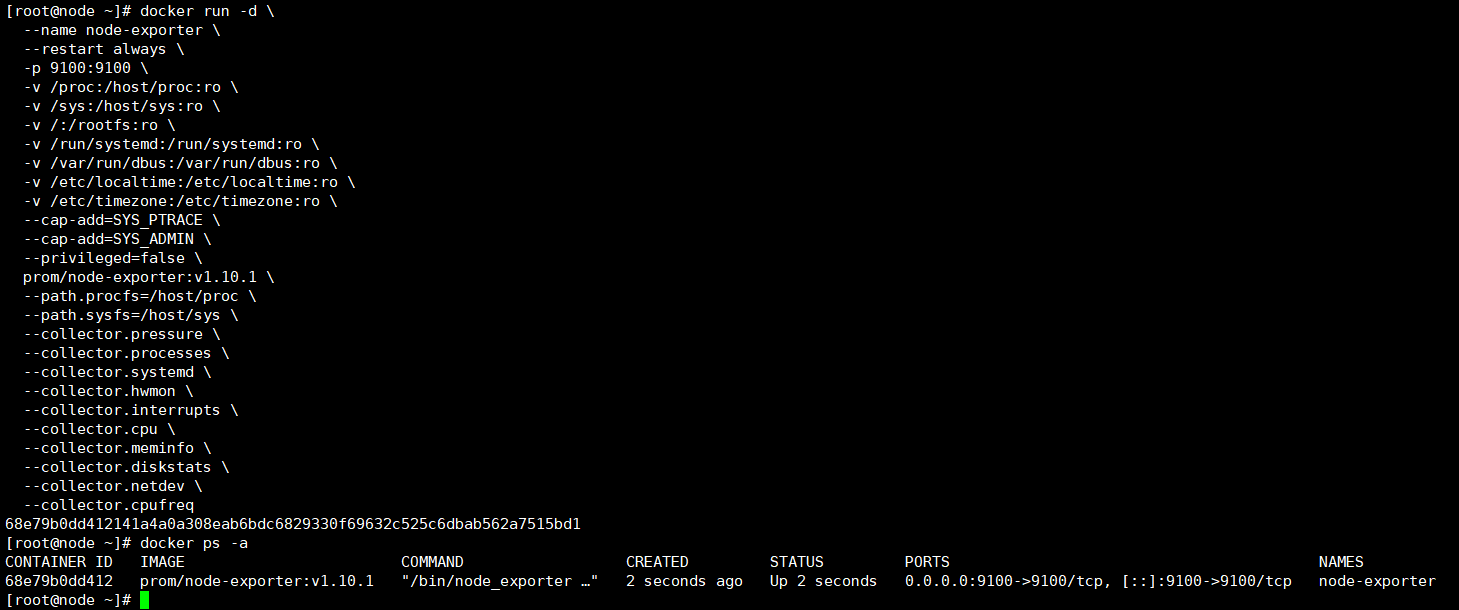
接着等待个三五秒刷新下prometheus页面就能看到这台linux机器有监控数据了,妥了;
7、windows_exporter安装
windows的exporter需要上github下载安装下:window-exporter的github下载地址
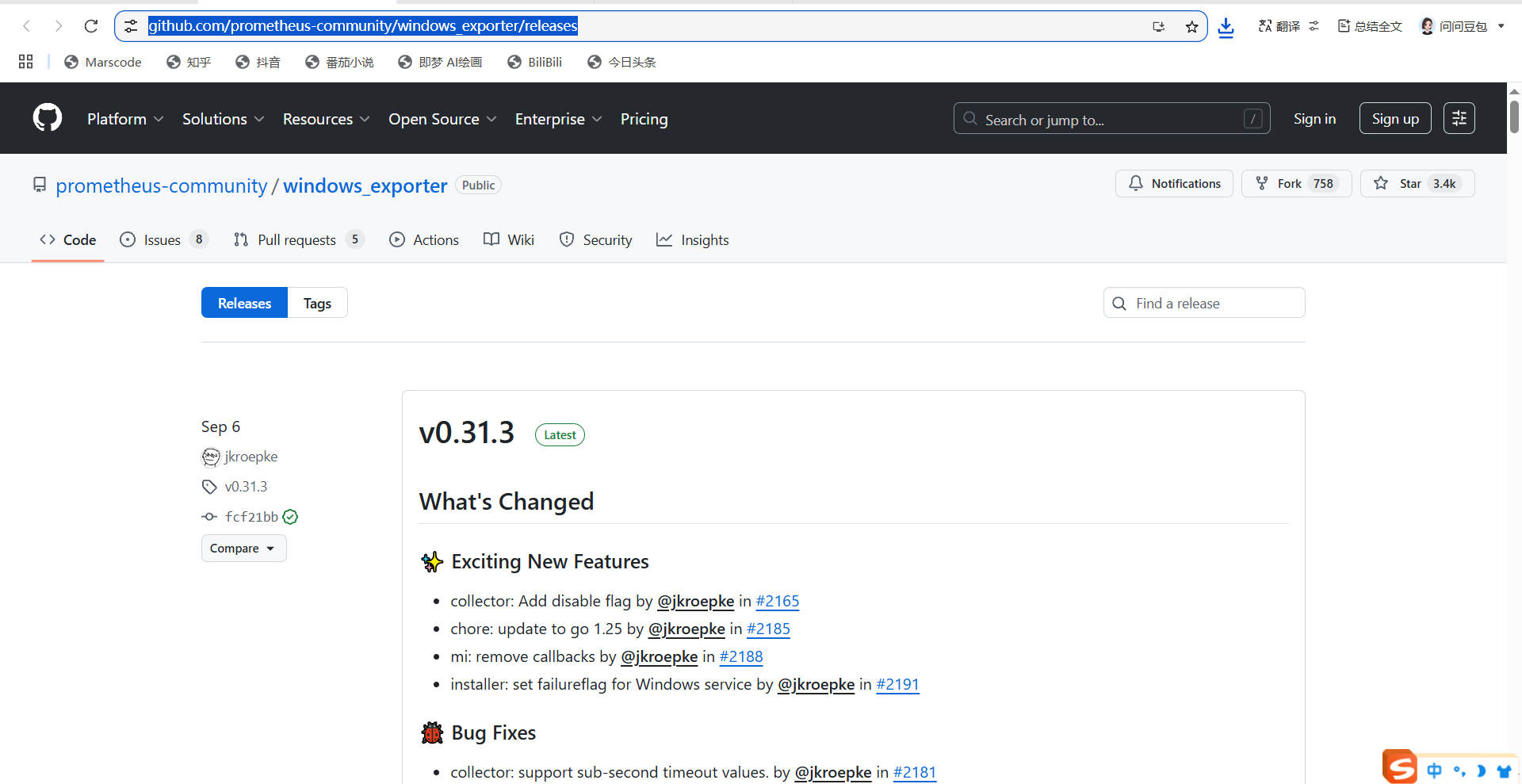
接着往下扒拉找到这个amd64位的服务就好了;
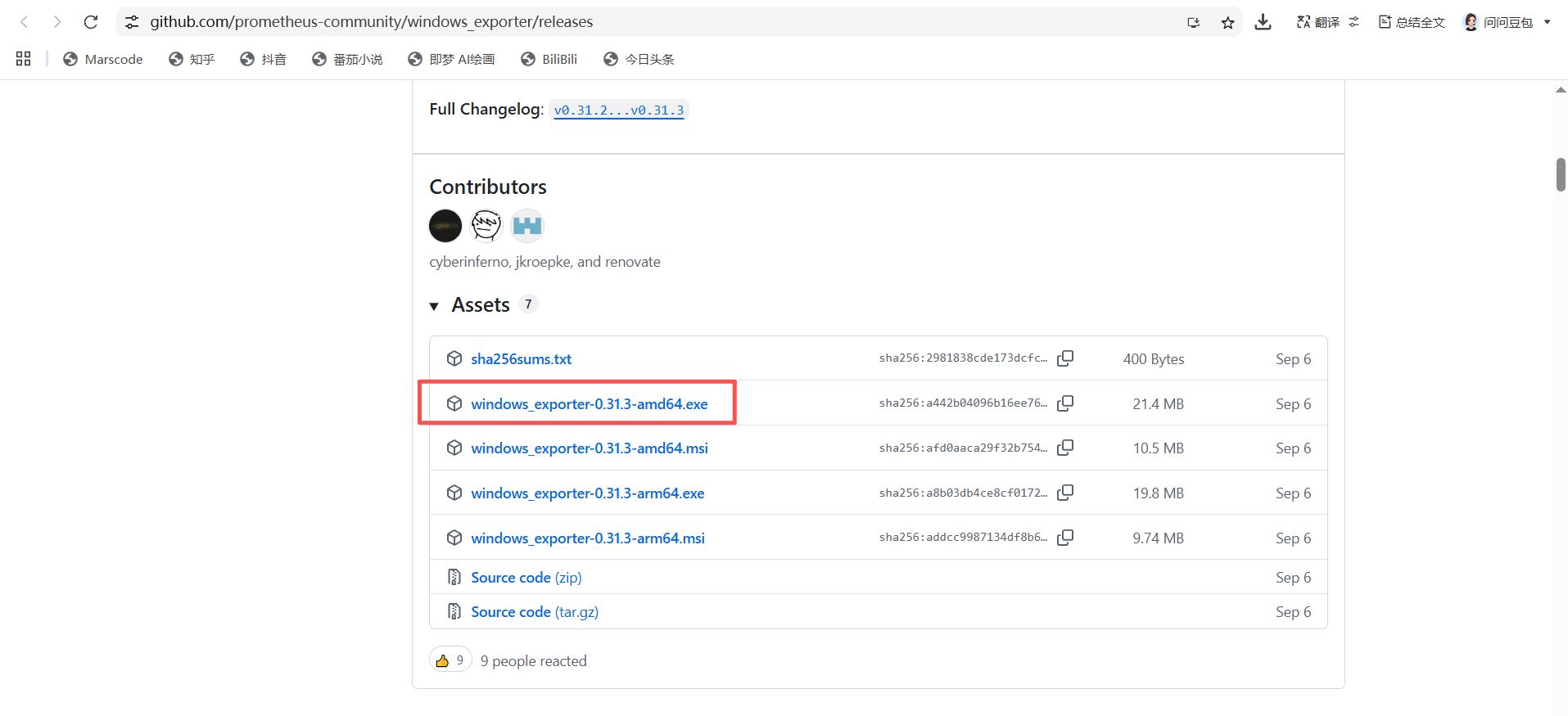
我百度云盘中有下载好的,直接使用也是可以的:
一个是exe结尾的双击之后会打开一个终端,这是临时的,关闭终端windows_exporter也就关闭了;
一个是msi结尾的这个是一个常驻在后端的exporter,使用那个都可以。
我这是使用exe,安装过程中跳出来的防火墙都允许,最后就是这个终端状态了;
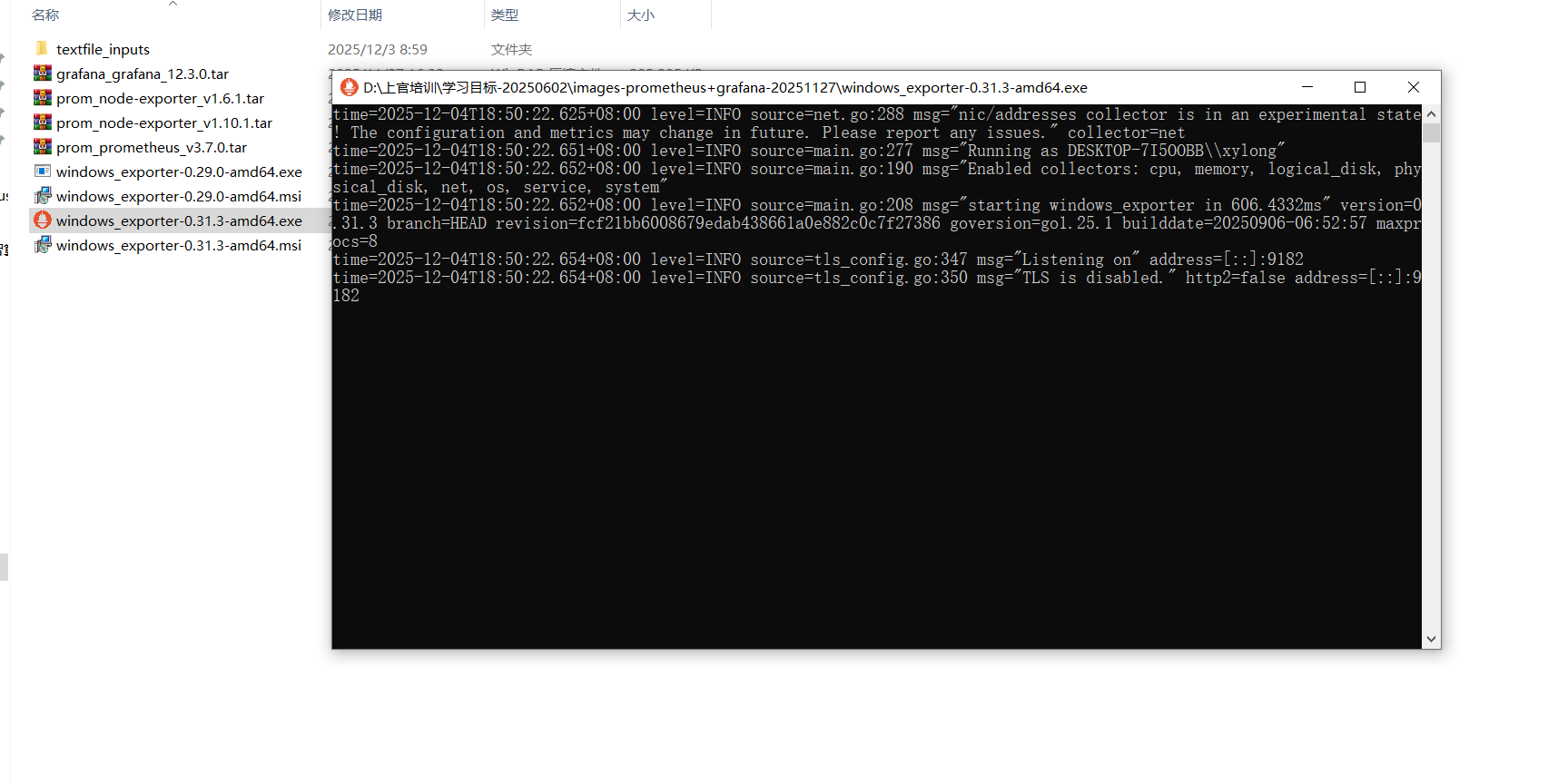
接着等待三五秒然后刷线下prometheus的页面就可以看到机器状态up了,这就妥了;
8、加载grafana模版
经过上面的步骤我们在两台linux虚机和本地win电脑上都将agent启动了,现在监控数据源都有了,让我们上grafana上添加模版看下监控数据吧。
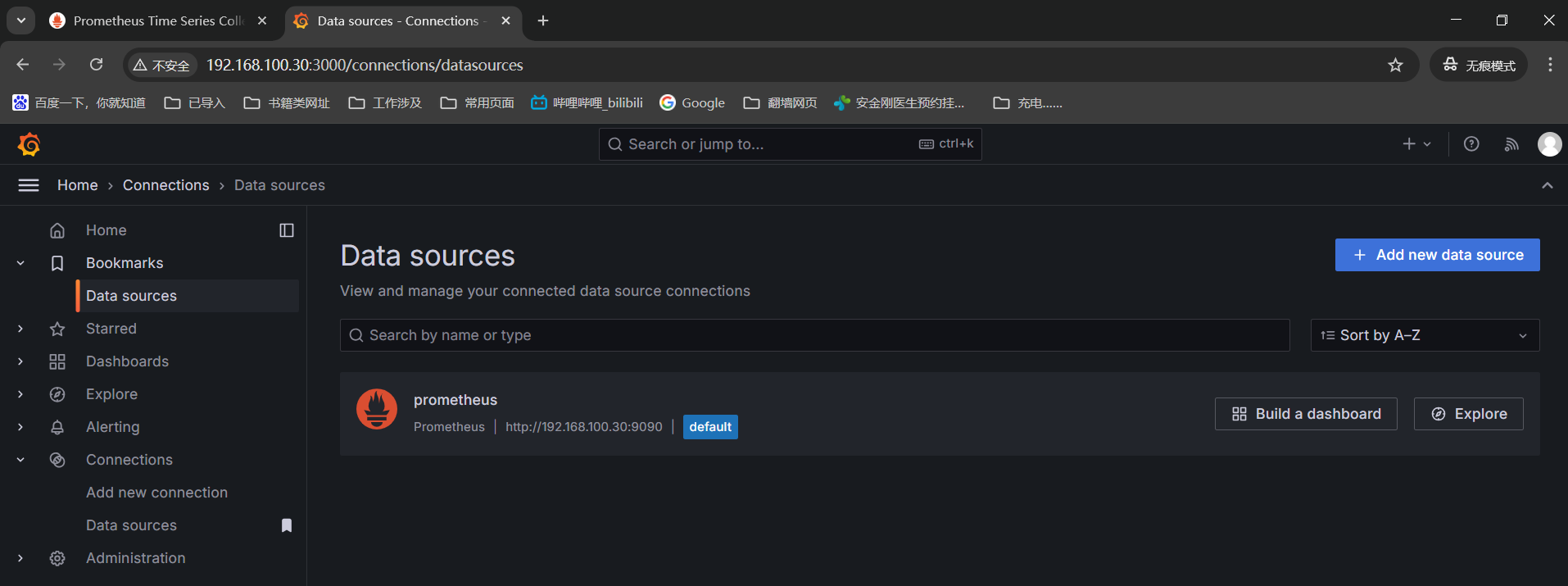
首先,将promethues的数据源添加进来grafana页面 ------》Connections------》Data sources ------》add data source-选择promethues在settings页面的connection写入上面promethues地址【http://192.168.100.30:9090】------》往下巴拉到最底下点击【save & test】
再点击data source就能看到我们添加的promethues数据源了
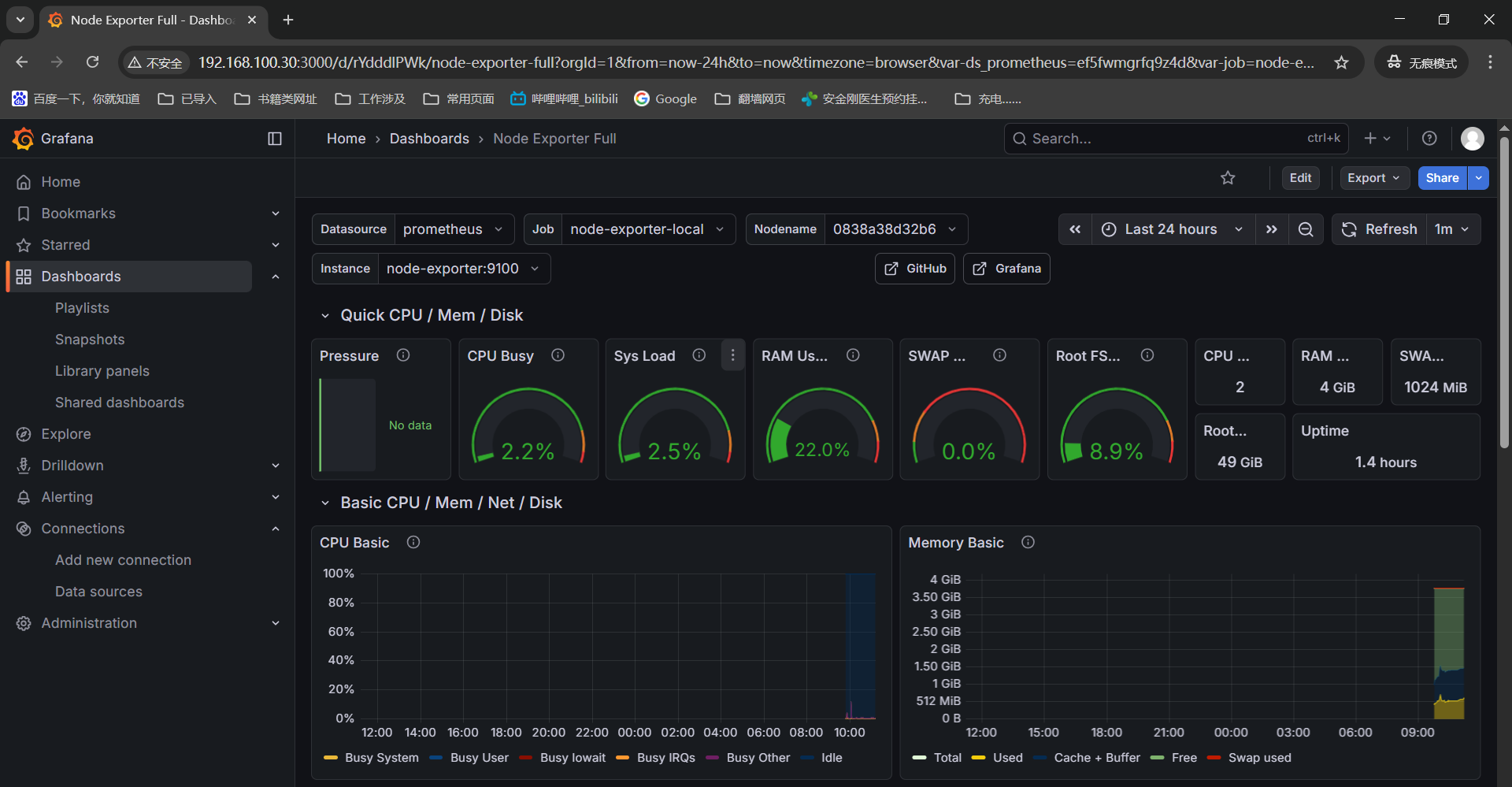
创建一个dashboard进行监控数据展示------》点击dashboards------》左上角找到NEW点击下选择import------》输入ID【1860】grafana官方的linux监控面板-点击load------》点击import导入就好。
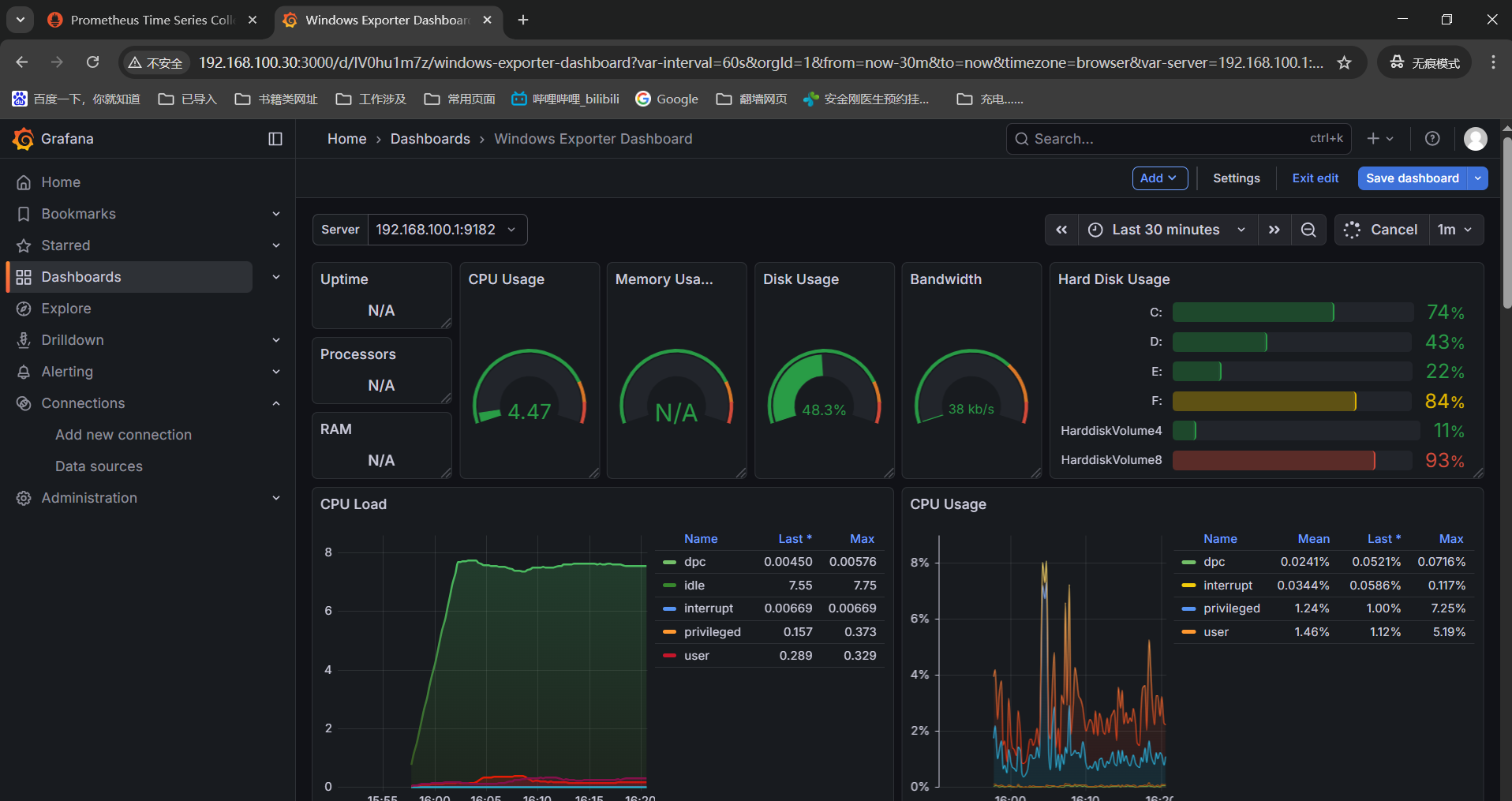
再创建一个window的dashboard:左边点击dashboard------》NEW------》import------》输入【21697】grafana的window模版------》load------》选择下数据源prometheus,就可以看到window机器的监控了。
到这里我们导入linux和window的监控模版可以看到监控数据那就是完成了,在almalinux系统下简单部署一个prometheus+grafana的容器化的监控环境就完成了。
四、报错记录:
报错1:拉取promethues和grafana容器镜像失败
我这里使用的是docker-ce默认的仓库镜像源是没法直接拉取镜像的,还是导入容器镜像。

解决步骤:
看【三-3、容器镜像导入】就可以了。
报错2:grafana添加promethues数据源导入1860监控模版等待五分钟之后看不到监控数据
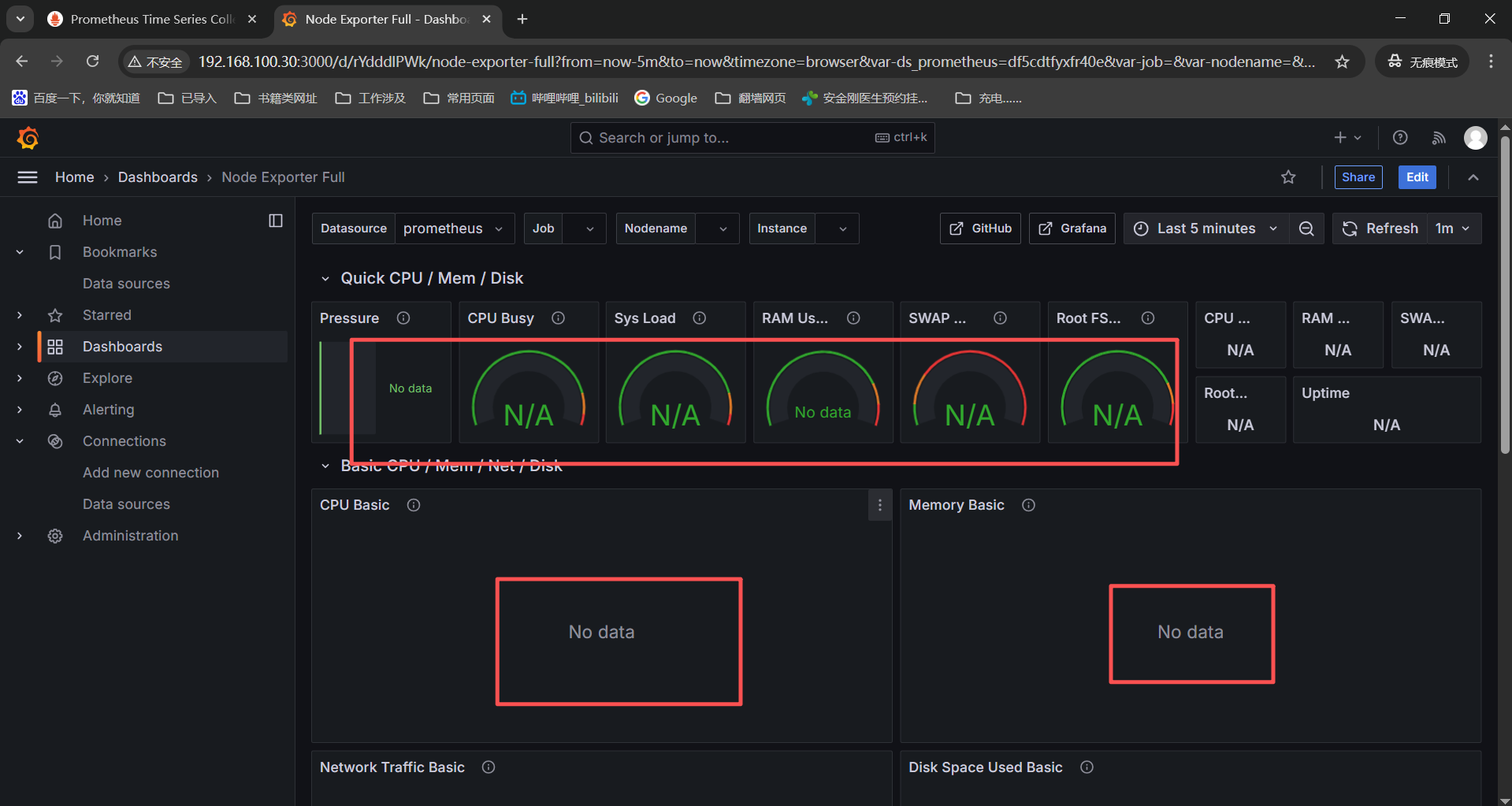
解决方案:
明确下监控数据走向:确认prometheus采集监控数据------》排查grafana数据源配置正常------》定位模版与数据匹配问题
排查发现是没有部署node_exporter导致监控数据没有正常收集,按照上面步骤安【三、6、linux-mnode_exporter安装】就可以了。
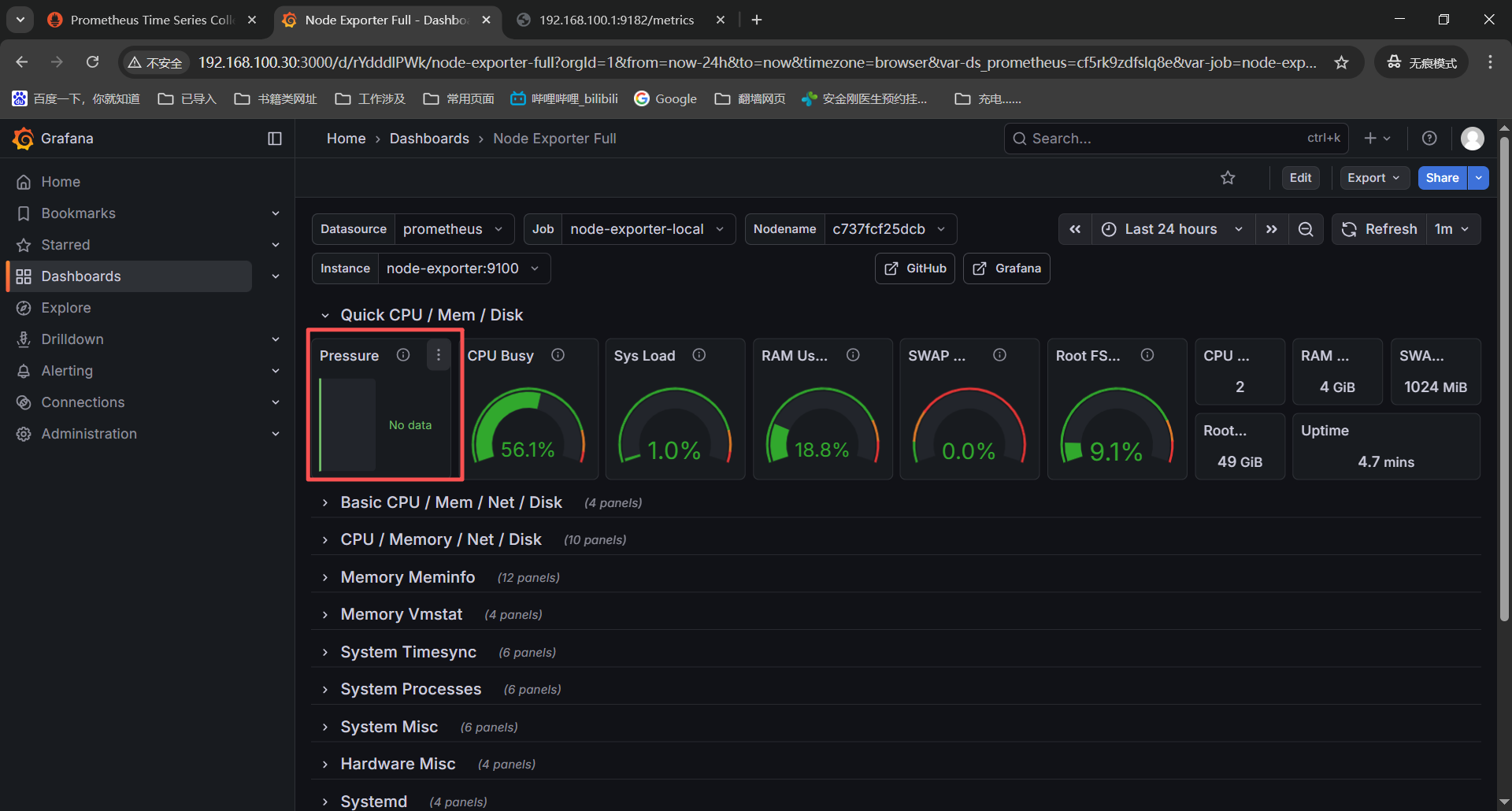
报错3:grafana加载了linux的1860模版后部分监控图表没有正常显示
PS:下面是在grafana导入监控模版之后查看有部分监控项没有监控数据,我也是信了豆包的邪,检查监控项更换exporter的镜像版本最后还是没有监控数据,但是这个排查过程我想记录下所以有了这个报错。
首先查看监控图表确定这个告警视图是没得监控数据的,
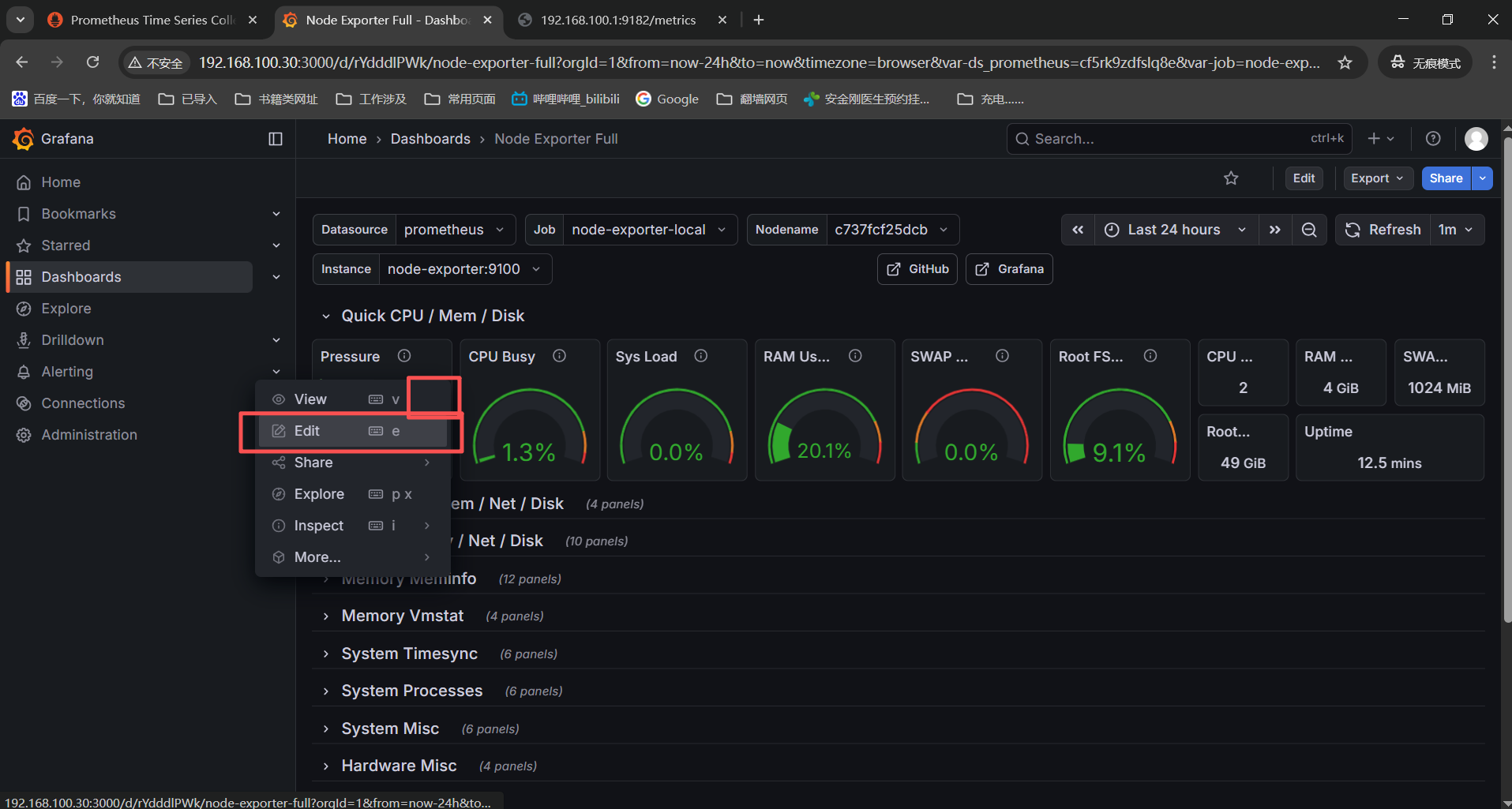
点击监控图表右上角三个点然后选择【Edit】
这时候我们就可以看到对应的监控项获取命令了,通过查看这个监控项获取命令再进一步排查为什么没有监控数据。
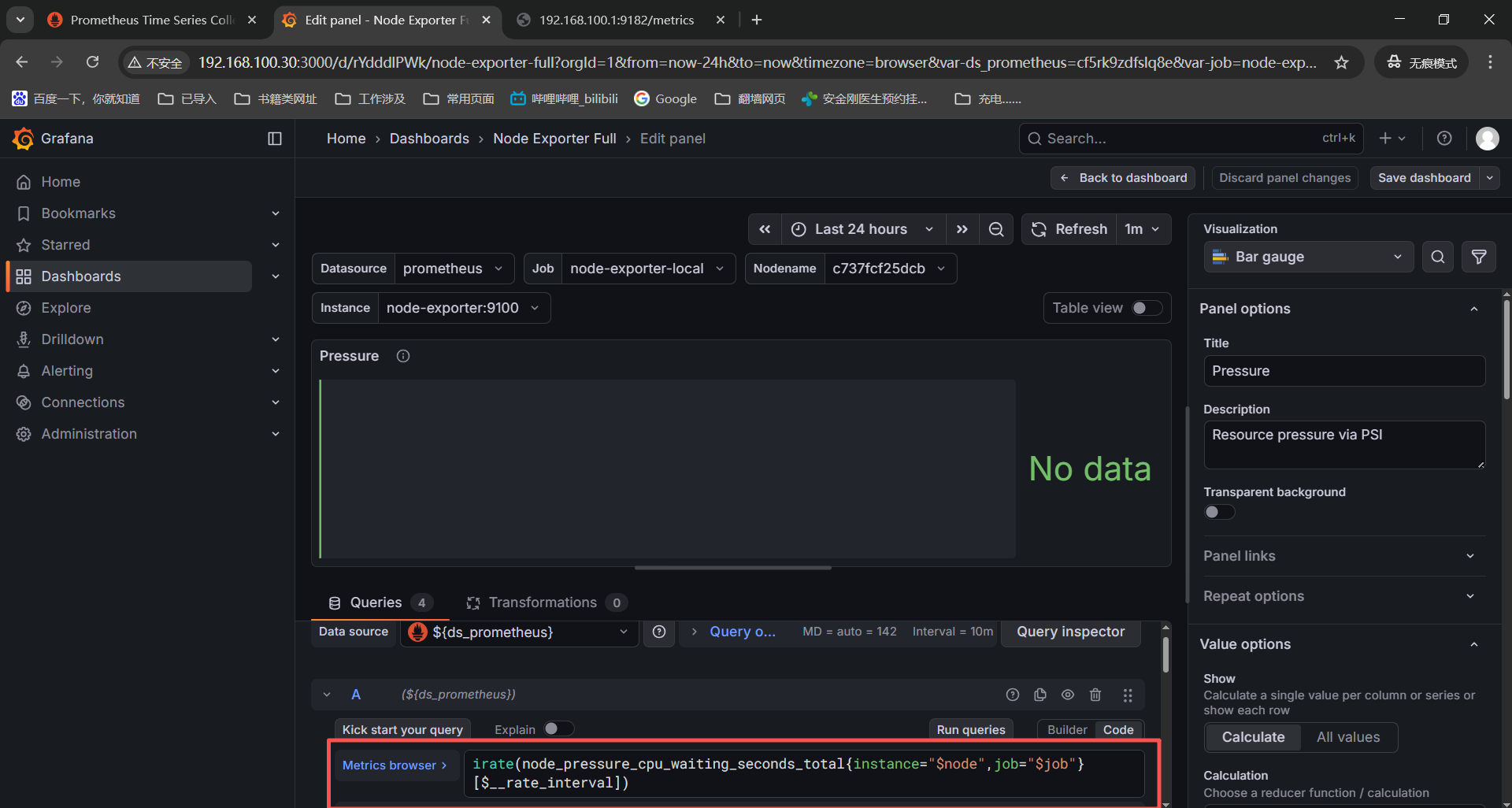
确定监控项之后可以到被监控机器的监控项中搜索或者是prometheus中搜索都可以。
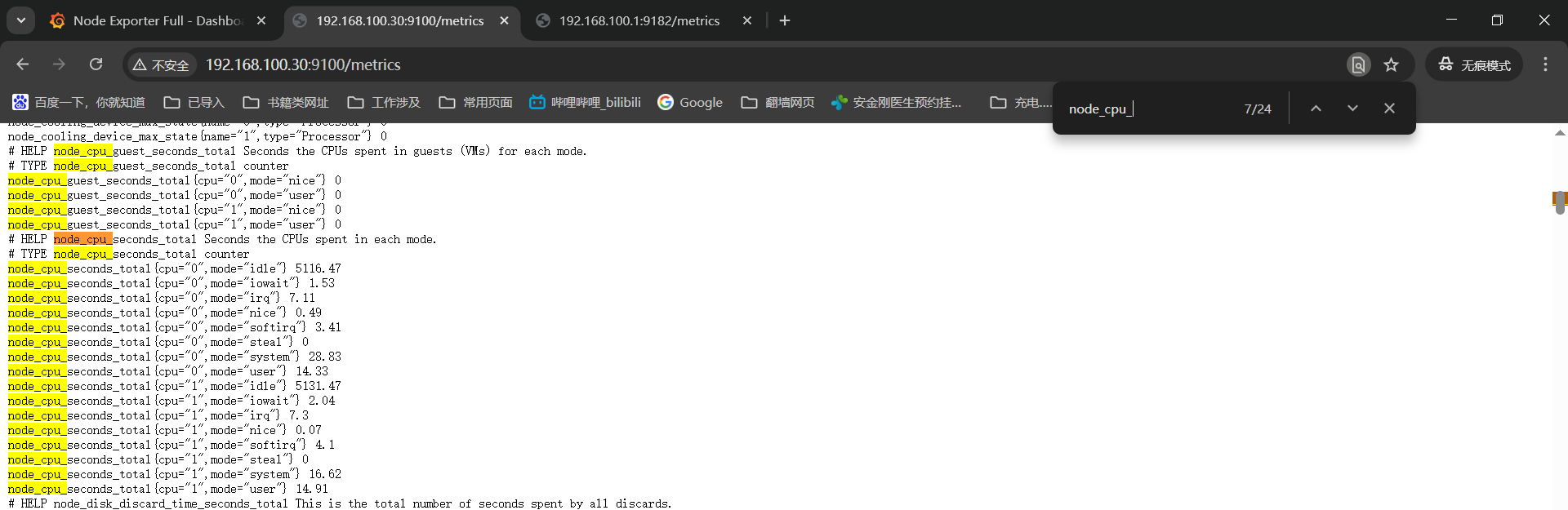
被监控机查看监控项------》http://192.168.100.30:9100/metrics
记录下没有监控数据的监控图表名称和对应的监控项获取命令:
1、Quick CPU / Mem / Disk------》Pressure------》irate(node_pressure_cpu_waiting_seconds_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
3+4+5、System Timesync
------》Processes Detailed States------》node_processes_state{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》PIDs Number and Limit------》node_processes_pids{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》Threads Number and Limit------》node_processes_threads{instance=" n o d e " , j o b = " node",job=" node",job="job"}
6+7、System Misc
------》CPU Frequency Scaling------》node_cpu_scaling_frequency_hertz{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》IRQ Detail------》irate(node_interrupts_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ * on(chip) gro...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ ------》Hardware Fa...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ * on(chip) gro...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ 10+11+12+13、Sy...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 24: ...te="activating"}̲ ------》Systemd Soc...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ ------》Systemd Soc...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
------》Systemd Sockets Refused------》irate(node_systemd_socket_refused_connections_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}$__rate_interval)
直接使用监控项进入节点页面进行检索的的确是没有的;


豆包了下,可能是linux_exporter的版本高【最新版本v1.10.1】监控项名称有变化,使用新的监控项搜索也是没有,诡异了!
bash
失效监控项 → 最新监控项映射表(含修改后查询)
原失效监控项(v0.x) 最新监控项(v1.10.1) 说明
node_pressure_cpu_waiting_seconds_total ------》node_cpu_pressure_waiting_seconds_total 指标前缀新增cpu,明确指向 CPU 压力
node_processes_state ------》node_processes_states 指标名末尾加s(复数形式),标签state保留
node_processes_pids ------》node_processes_max_processes 原指标拆分,此指标表示最大进程数(兼容原监控意图)
node_processes_threads ------》node_processes_max_threads 原指标拆分,此指标表示最大线程数
node_cpu_scaling_frequency_hertz ------》node_cpu_scaling_frequency_hertz 指标名未变!需检查是否启用cpu收集器(默认启用)
node_interrupts_total ------》node_interrupts_total 指标名未变!需检查是否启用interrupts收集器(默认启用)
node_hwmon_temp_celsius(关联 chip_name)------》node_hwmon_temp_celsius(标签变更) 标签chip_name → 改为name,关联指标node_hwmon_chip_names → node_hwmon_chip_info
node_hwmon_fan_rpm(关联 chip_name) ------》node_hwmon_fan_rpm(标签变更) 同上(风扇转速指标,标签关联逻辑一致)
node_systemd_units{state="activating"} ------》node_systemd_unit_state 指标名改为node_systemd_unit_state,标签state保留
node_systemd_socket_current_connections ------》node_systemd_socket_connections_current 指标名调整(current_connections → connections_current)
node_systemd_socket_accepted_connections_total ------》node_systemd_socket_connections_accepted_total 指标名调整(accepted_connections → connections_accepted)
node_systemd_socket_refused_connections_total ------》node_systemd_socket_connections_refused_total 指标名调整(refused_connections → connections_refused)



接着豆包了下,grafana的1860模版和linux_exporter的v1.6.1模版完全适配,将linux_exporter版本降低了看下监控项是否全部具备。
将linux_exporter版本降低为v1.6.1之后查看缺少的监控页面还是和v1.10.1版本一样,这应该就和版本没啥关系了。
Quick CPU / Mem / Disk------》Pressure------》irate(node_pressure_cpu_waiting_seconds_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
System Timesync
------》Processes Detailed States------》node_processes_state{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》PIDs Number and Limit------》node_processes_pids{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》Threads Number and Limit------》node_processes_threads{instance=" n o d e " , j o b = " node",job=" node",job="job"}
System Misc
------》CPU Frequency Scaling------》node_cpu_scaling_frequency_hertz{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》IRQ Detail------》irate(node_interrupts_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ * on(chip) gro...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ ------》Hardware Fa...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ * on(chip) gro...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ Systemd ------》Sys...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 24: ...te="activating"}̲ ------》Systemd Soc...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲ ------》Systemd Soc...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
------》Systemd Sockets Refused------》irate(node_systemd_socket_refused_connections_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}$__rate_interval)
直接在监控页面搜索也是没有对应监控项的;


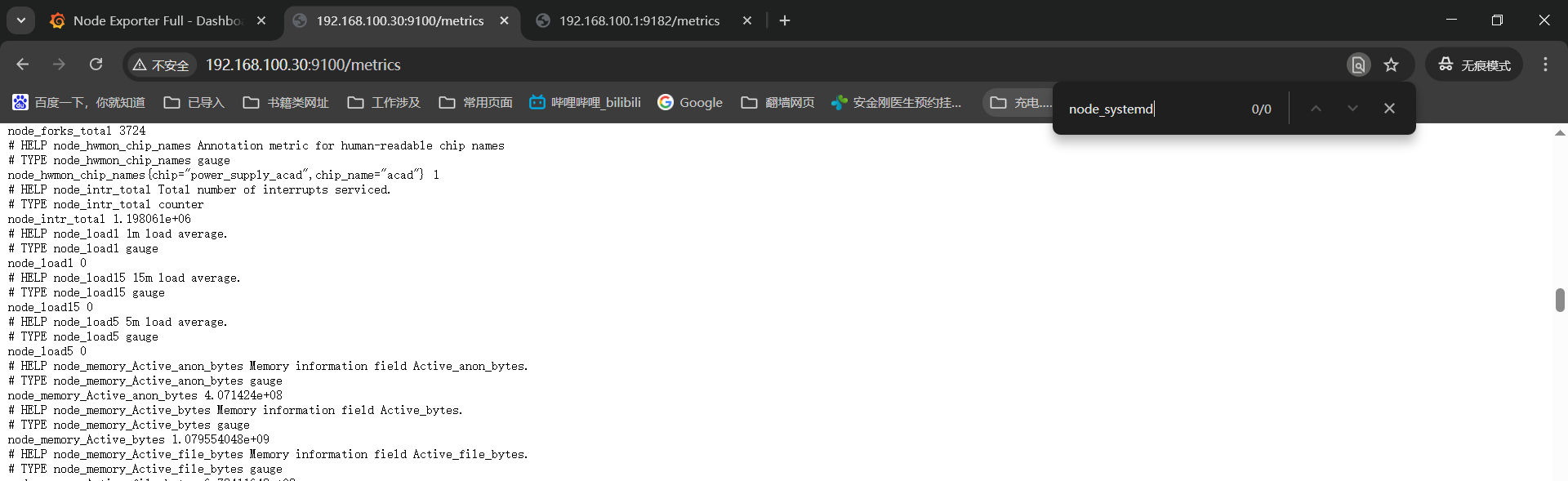
查看node-exporter的日志提示找不到systemd的文件------》这里应该还是启动参数有问题;

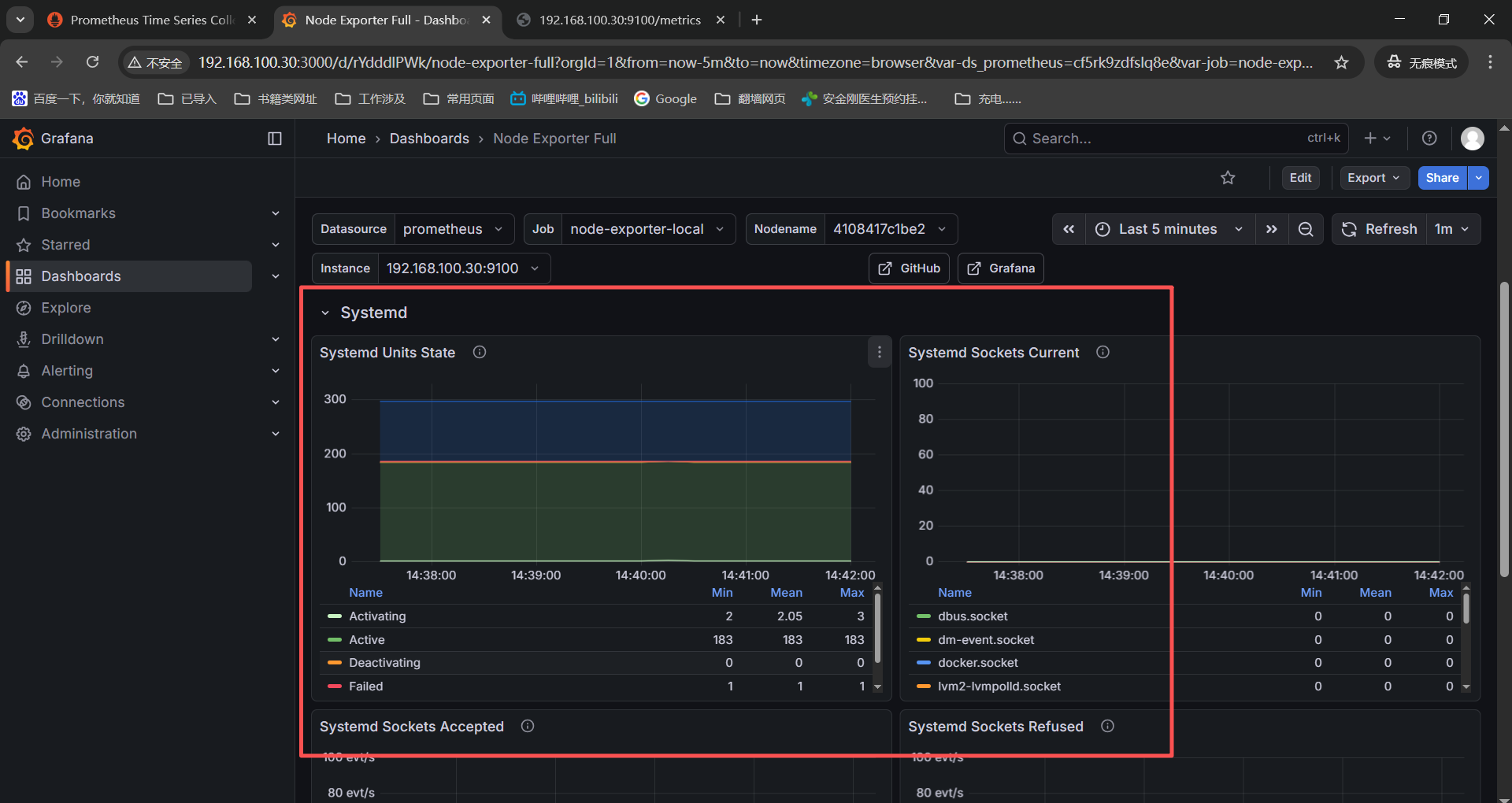
这里豆包下报错然后重新启动之后systemd相关的监控项有了,监控数据也有了。
Systemd
------》Systemd Units State------》node_systemd_units{instance=" n o d e " , j o b = " node",job=" node",job="job",state="activating"}
------》Systemd Sockets Current------》node_systemd_socket_current_connections{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》Systemd Sockets Accepted------》irate(node_systemd_socket_accepted_connections_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
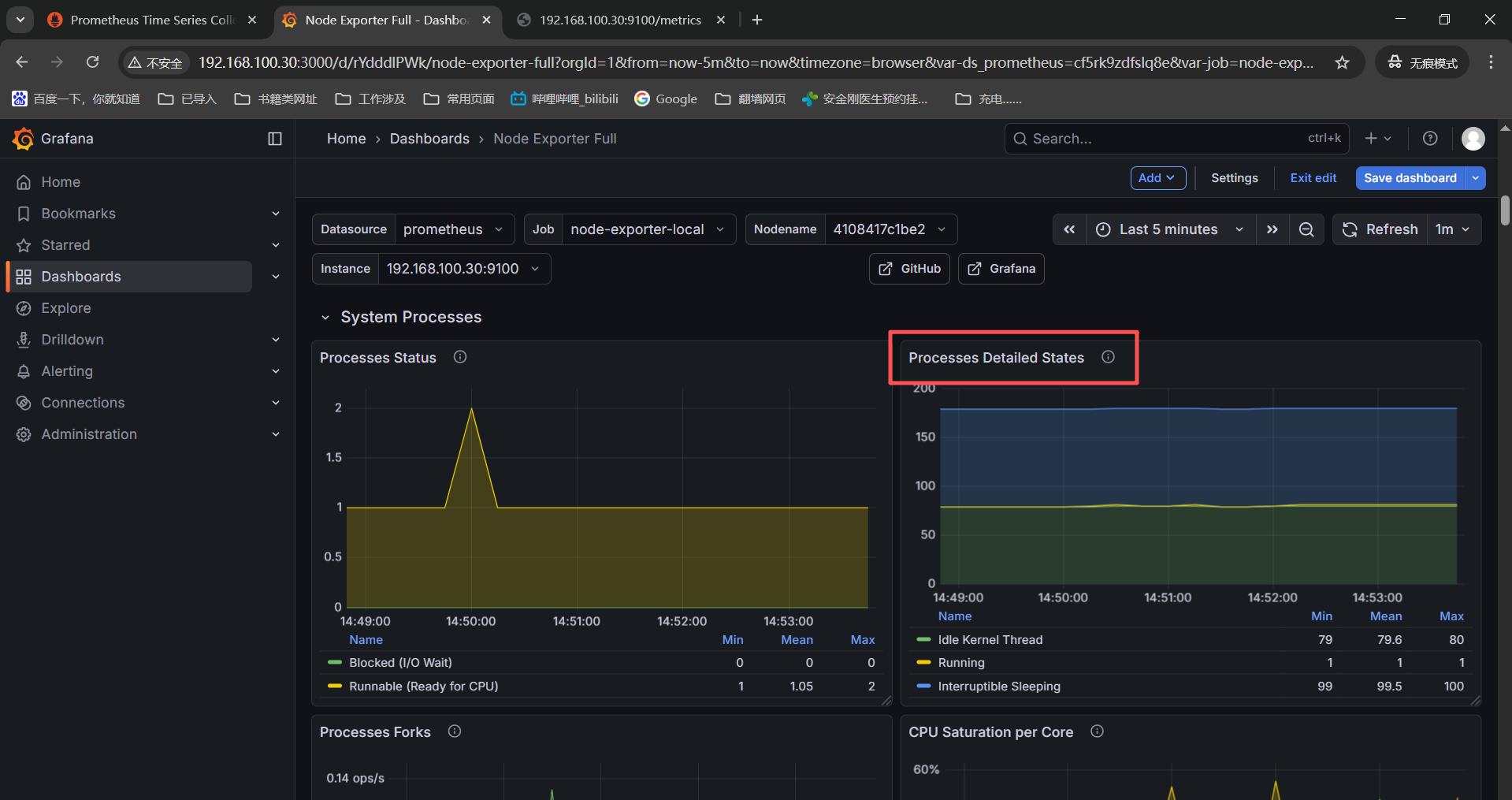
接着排查下发现system timesync的三个没有监控数据的监控项,去了system processes
System Timesync
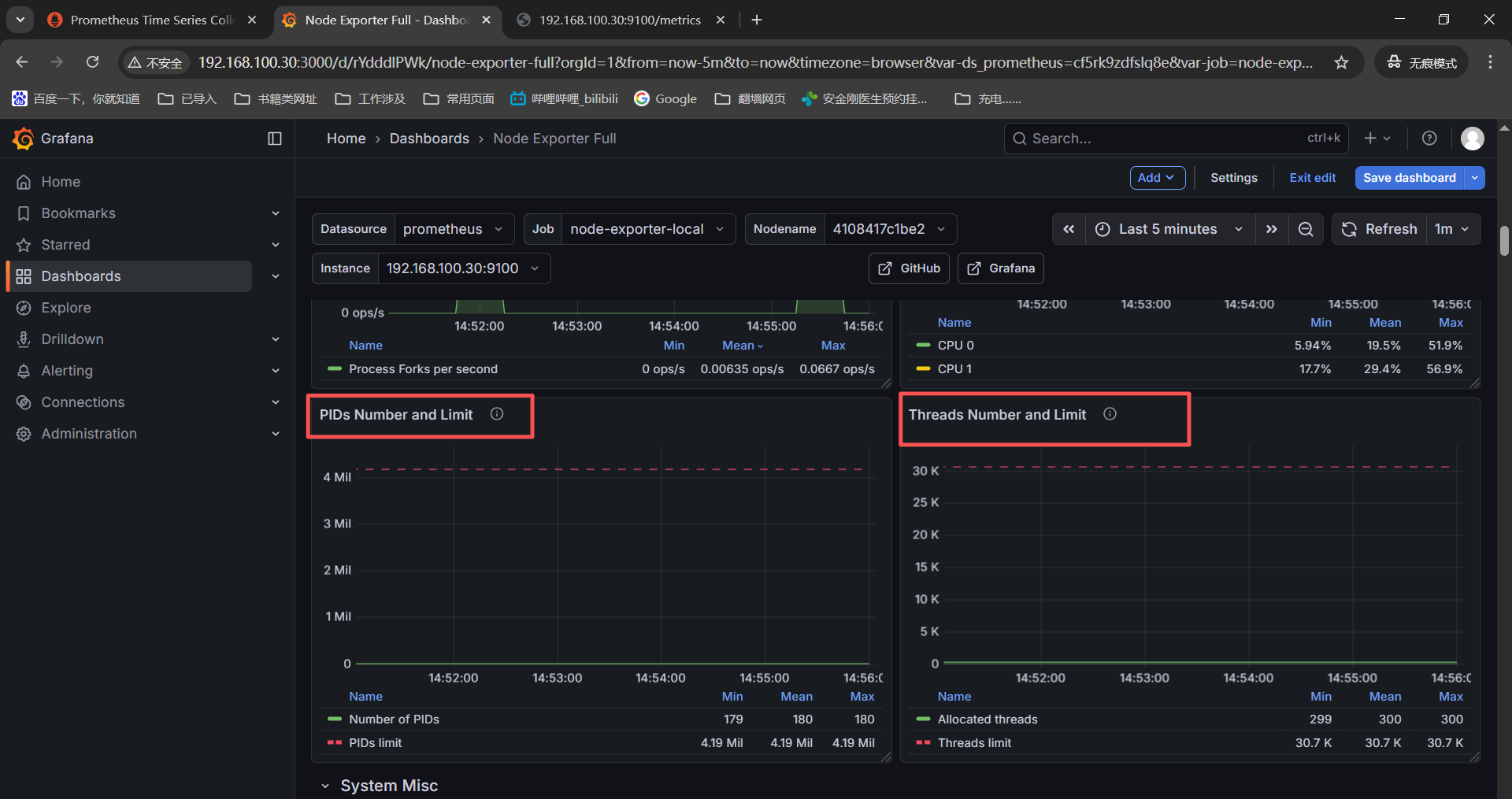
------》Processes Detailed States------》node_processes_state{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》PIDs Number and Limit------》node_processes_pids{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》Threads Number and Limit------》node_processes_threads{instance=" n o d e " , j o b = " node",job=" node",job="job"}
检查IRQ的监控数据也是有了;
System Misc
------》IRQ Detail------》irate(node_interrupts_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}$__rate_interval)
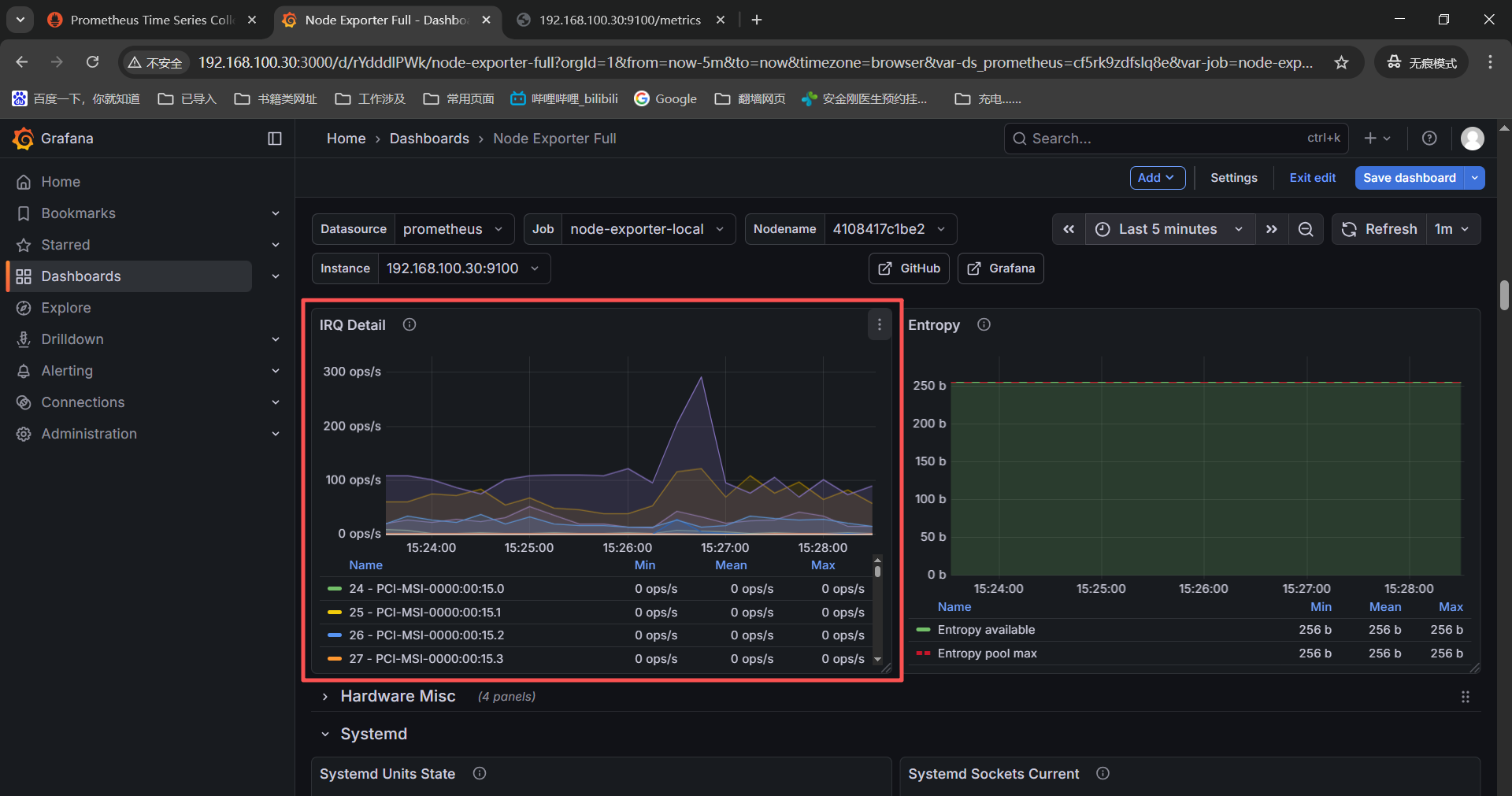
这两个监控项依赖系统内核版本,检查虚机本地都没有【/proc/pressure】目录,这是内核不支持没有监控项是正常的。
Quick CPU / Mem / Disk------》Pressure------》irate(node_pressure_cpu_waiting_seconds_total{instance=" n o d e " , j o b = " node",job=" node",job="job"}KaTeX parse error: Expected group after '_' at position 1: _̲_rate_interval...node",job="KaTeX parse error: Expected 'EOF', got '}' at position 5: job"}̲__rate_interval)
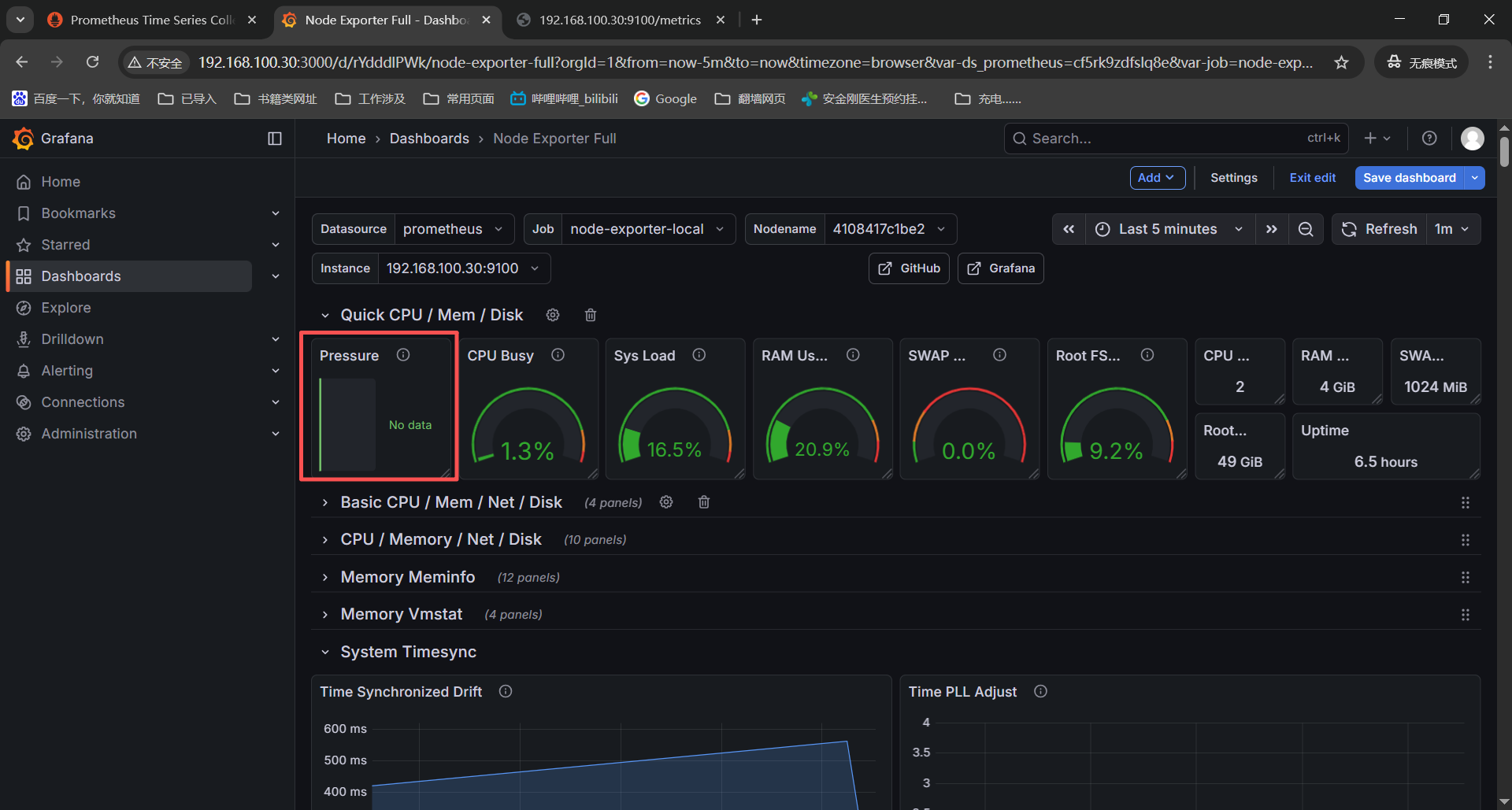
这两个监控项是针对硬件温度和风扇,但是我们是虚拟机环境没有服务器硬件传感器,没有这个监控项也是正常的;
Hardware Misc
------》Hardware Temperature Monitor------》node_hwmon_temp_celsius{instance=" n o d e " , j o b = " node",job=" node",job="job"} * on(chip) group_left(chip_name) node_hwmon_chip_names{instance=" n o d e " , j o b = " node",job=" node",job="job"}
------》Hardware Fan Speed------》node_hwmon_fan_rpm{instance=" n o d e " , j o b = " node",job=" node",job="job"} * on(chip) group_left(chip_name) node_hwmon_chip_names{instance=" n o d e " , j o b = " node",job=" node",job="job"}
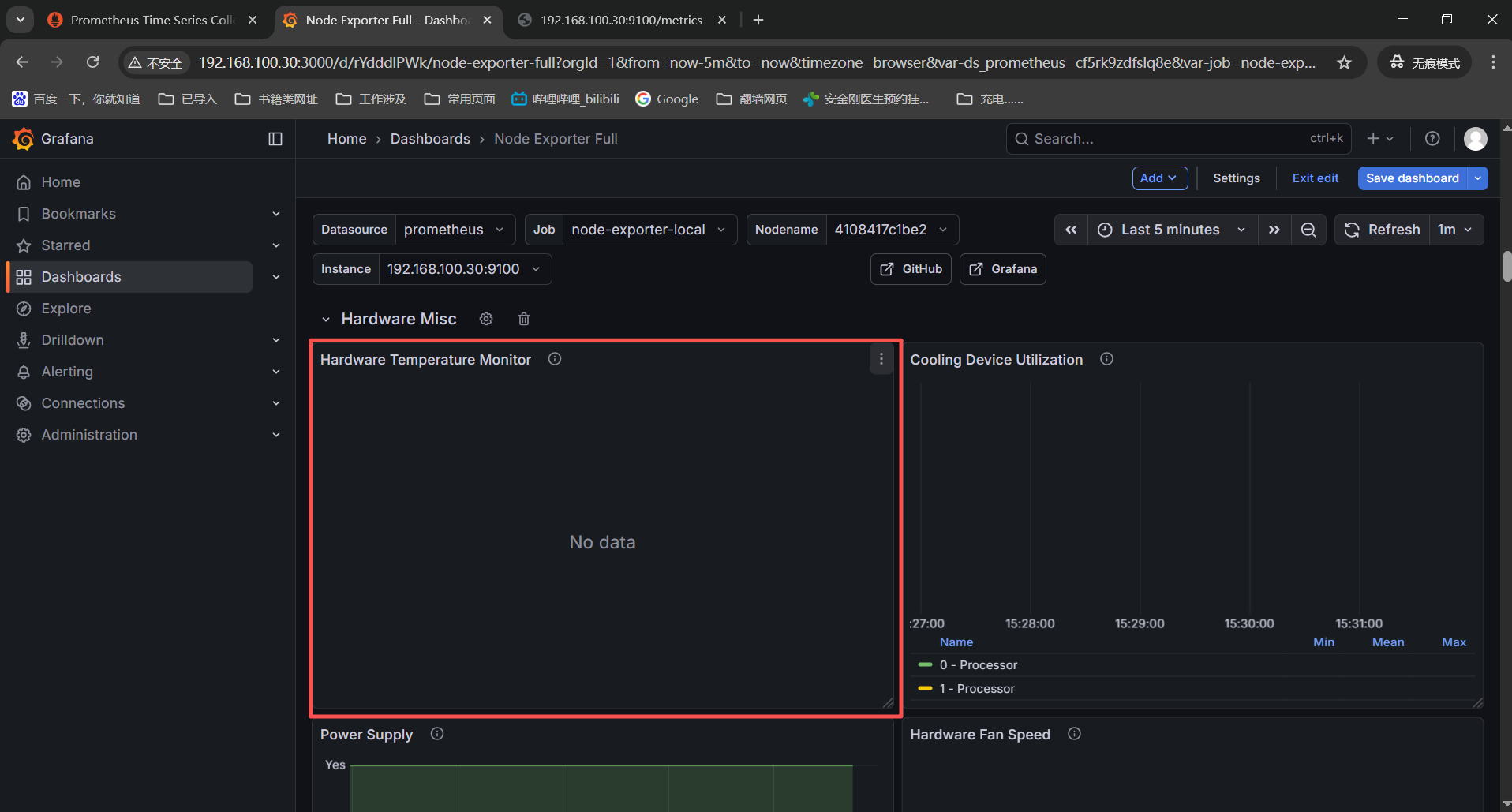
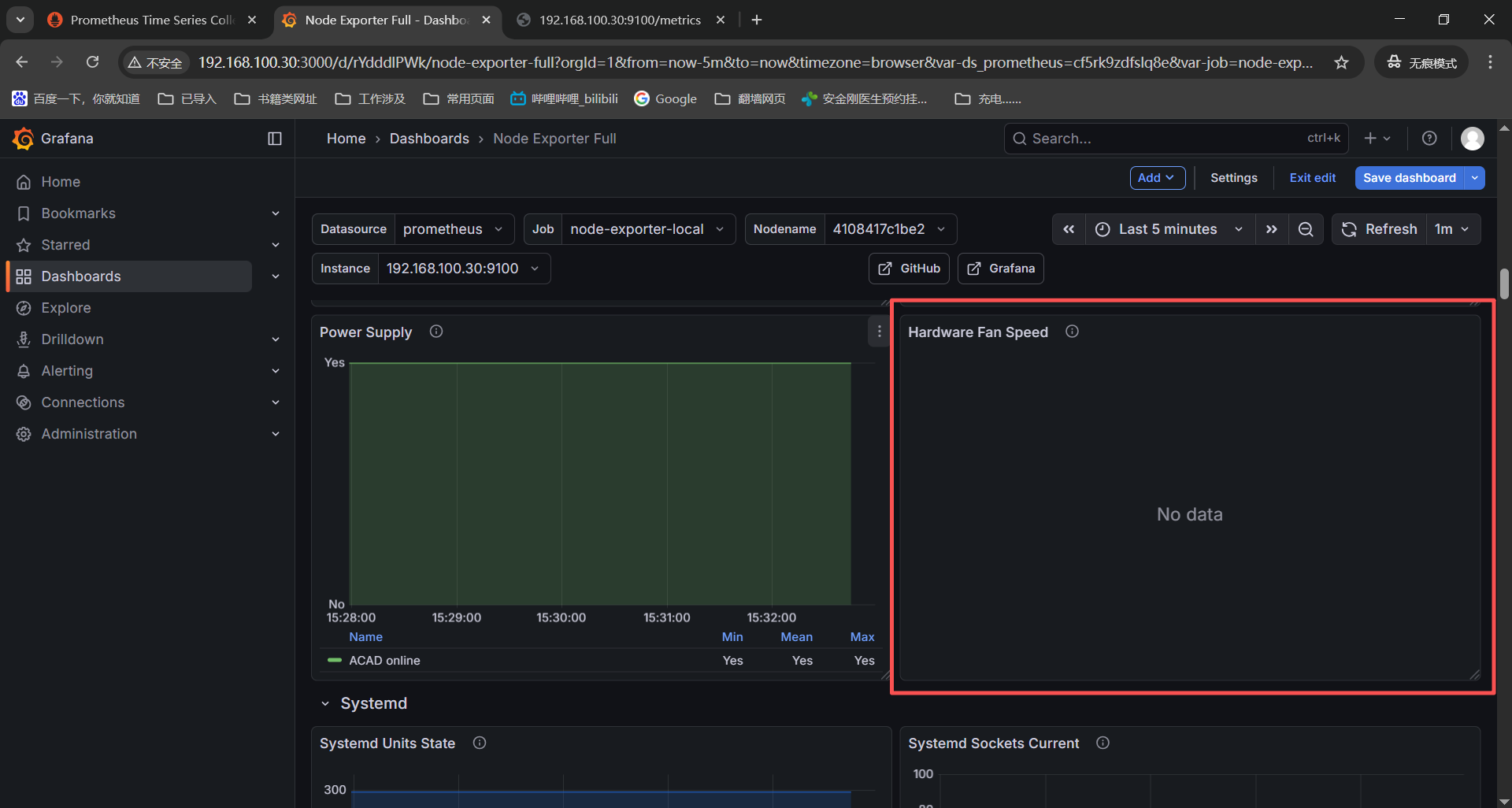
这个监控项在手动启动cpufreq收集器之后还是没有监控数据,那就是硬件不支持我使用的是vmware虚机不支持cpu频率缩放。
System Misc
------》CPU Frequency Scaling------》node_cpu_scaling_frequency_hertz{instance=" n o d e " , j o b = " node",job=" node",job="job"}
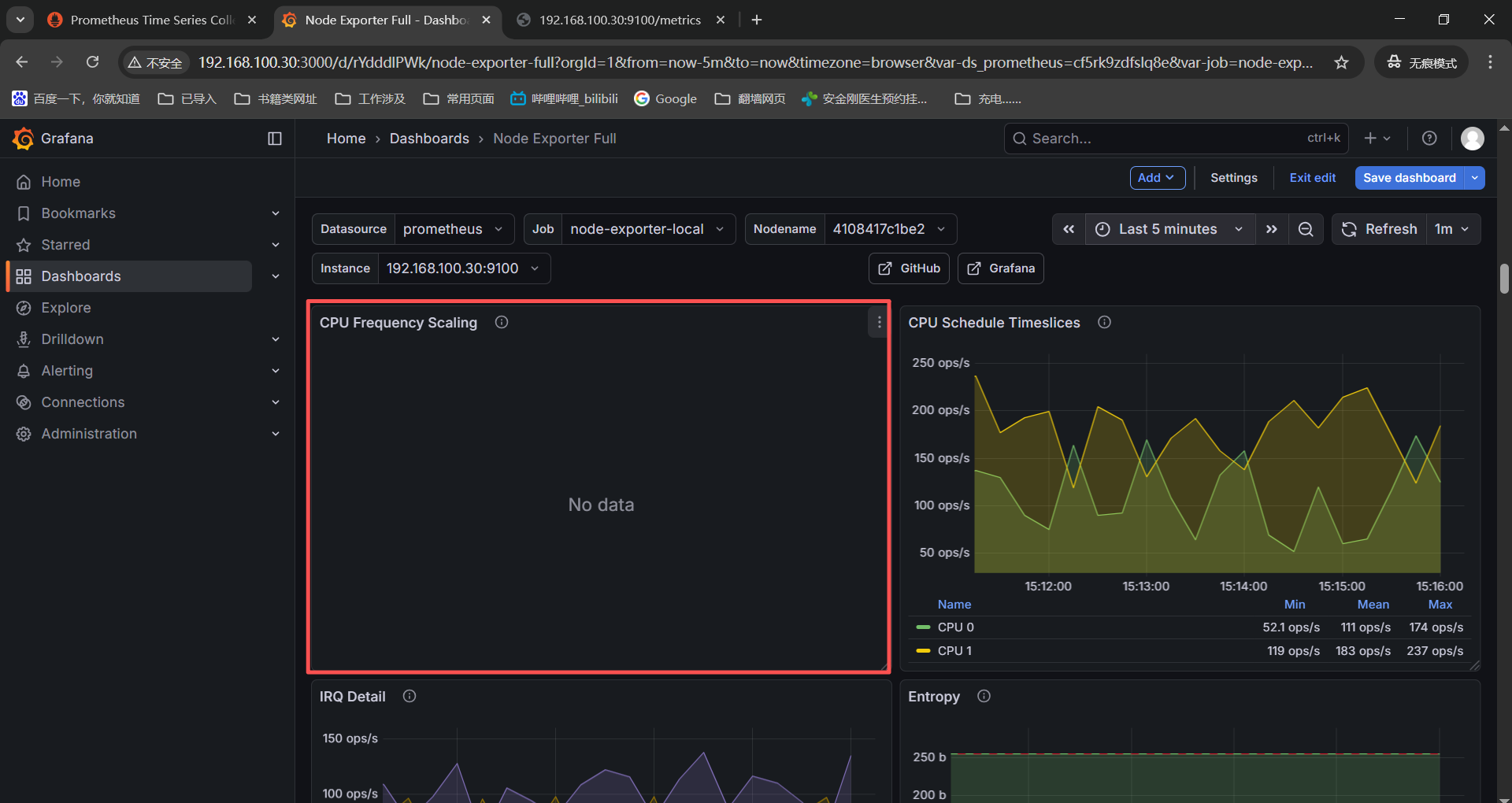
现在13个没有监控数据的表,有7个排查之后有监控数据,剩下6个没有监控数据或者是硬件或系统不达标没有监控数据也是正常的,为了grafana监控页面好看将没有监控数据的删除了。
进入导入的模版然后点击edit编辑,
找到没有监控数据的监控图表,点击右上角的三个点,选择最下面的remove就删除了。
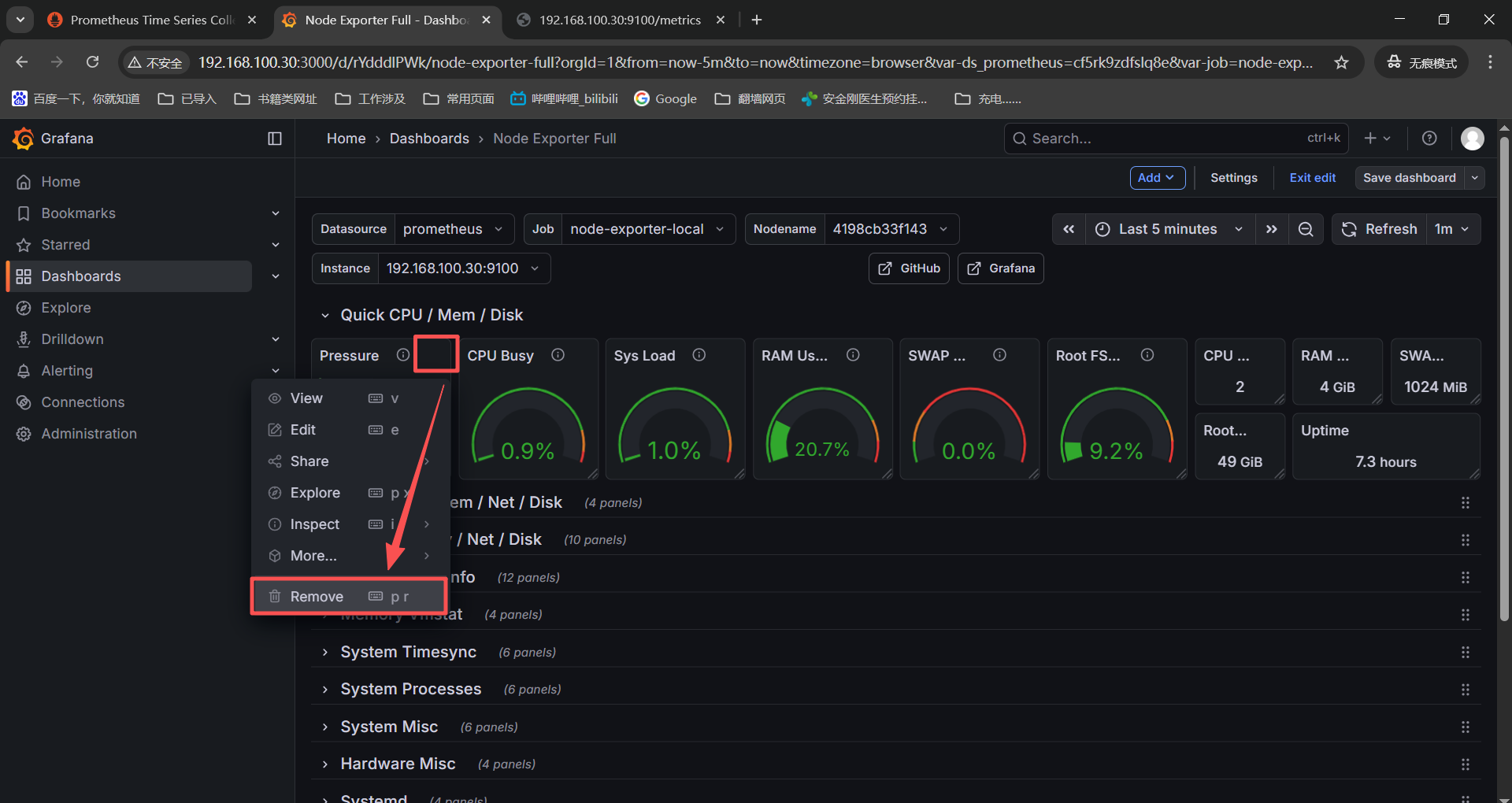
删除完成之后点击页面右上角的save dashboard保存就好了。
报错4:grafana加载了window的21697模版部分监控图表没有正常显示
PS:grafana导入的win监控模版有问题,他预制的监控项我本地没有所以没有监控数据,在豆包之后换了各种win监控模版导入之后还是没有,不挣扎了,就看已有的了。
检查没有监控数据的表和对应的监控项获取命令:
Memory Usage------》sum by (pod) (kube_pod_container_info{} * on(container_id) group_left avg by (container_id) (windows_container_memory_usage_private_working_set_bytes{instance="KaTeX parse error: Expected 'EOF', got '}' at position 8: server"}̲)) CPU Usage------》...server"}2m)) * 10)
system_threads------》windows_process_thread_count{instance=~"$server"}
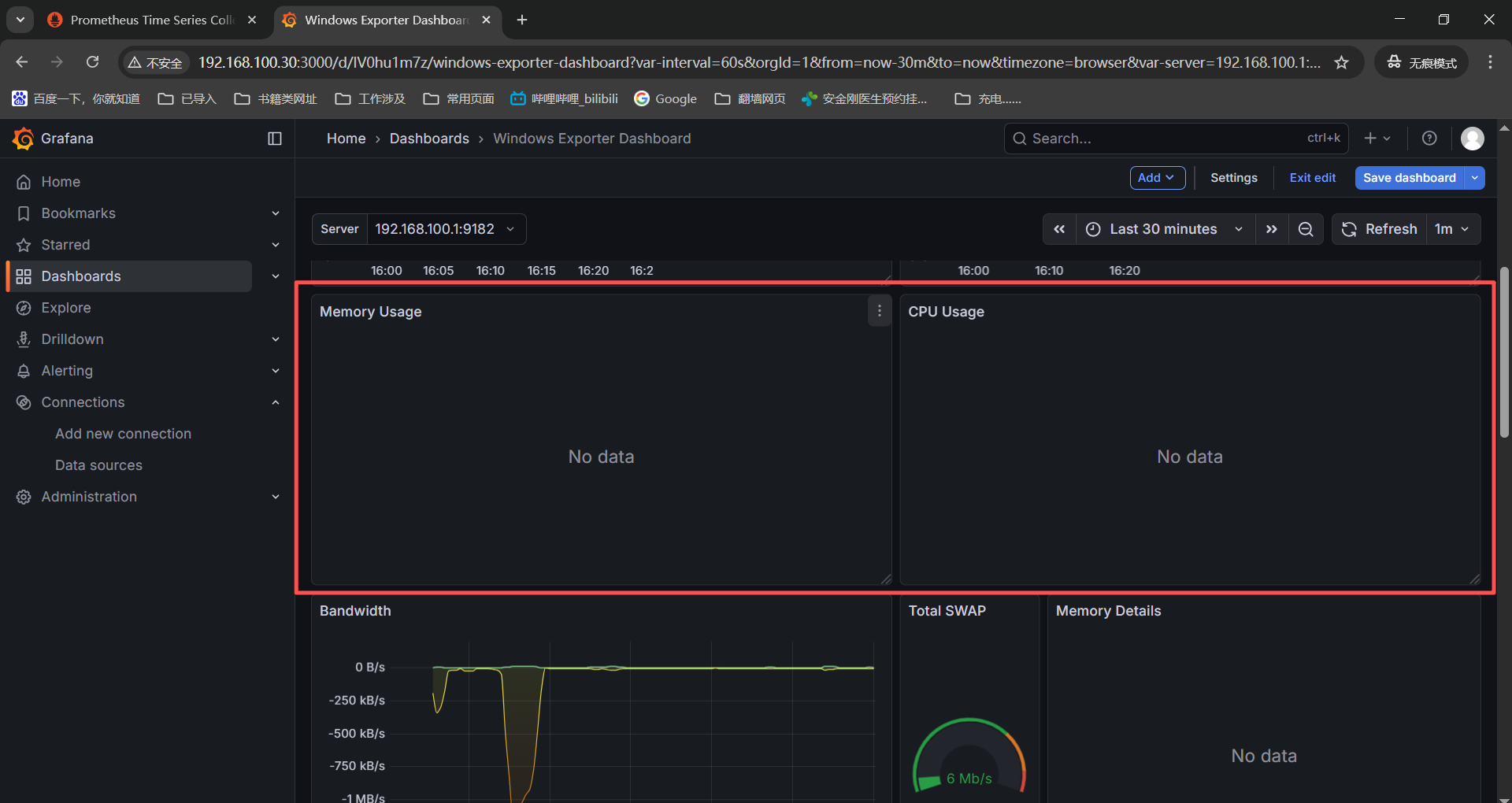
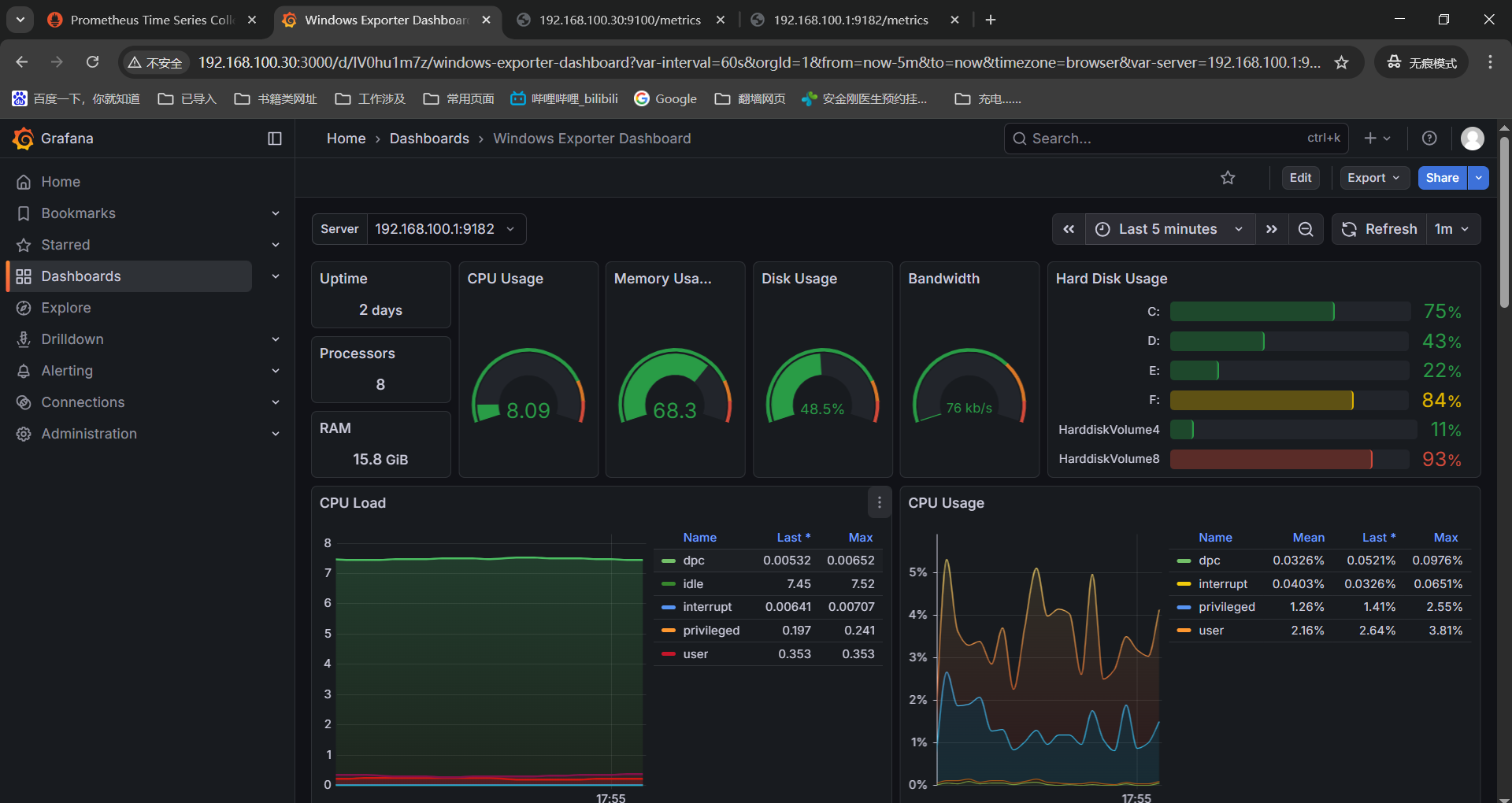
检查window机器的监控项是都没有采集的------》http://192.168.100.1:9182/metrics
------》windows_container_memory_usage_private_working_set_bytes
------》windows_container_cpu_usage_seconds_total
------》windows_process_thread_count



豆包了下windows_exporter的0.30.0版本之后对于监控项有比较重大的更新,我这笔记本是win10操作系统,比较老,换个0.29.0的windows_exporter看下部分监控数据上来了,比0.30.3好点。
五、命令总结
1、docker compose
bash
docker compose up -d #启动容器------》-d后台启动
docker compose down #停止并删除容器(数据卷保留,数据不丢失)
docker compose ls
docker compose stop #停止服务(不删除数据)
docker compose start #启动服务
docker compose restart #重启服务
docker volume ls #查看数据卷(确认数据持久化目录)
docker compose logs -f #查看日志------》-f实时查看
docker compose logs -f prometheus #查看promethues日志
docker compose logs -f grafana #查看grafana日志2、grafana监控项查看
linux_exporter------》http://192.168.100.30:9100/metrics【collector-查看已启动的监控项】
windows_exporter------》http://192.168.100.1:9182/metrics【collector-查看已启动的监控项】
3、prometheus的核心架构和工作流程
prometheus的核心组件:
prometheus server,核心组件,负责数据采集、存储、查询和告警规则评估。
exporter,数据采集代理,将非prometheus格式数据转换为标准指标并暴露。
alertmanager,处理告警,支持分组、路由、静默和通知。
pushgateway,接收短期任务的推送数据,再由server拉取(解决短期任务无法被pull的问题)。
prometheus获取监控数据的方式:
pull(默认),server主动向目标实例的metrics端点发起http请求,拉取指标数据。
push,短期任务或者是无固定IP实例,通过pushgateway将数据推送到网关,server再从网关拉去。
prometheus监控数据传输流程:
数据采集传输,exporter通过http协议暴露metrics端点,server以http GET请求拉取监控数据(默认15秒一次)。
数据存储,拉取的数据以时序数据库(TSDB)格式存储在本地磁盘,按时间分片管理。
数据查询传输,用户通过PromQL查询时,grafana或者prometheus web UI向server发起http请求,server从TSDB中读取数据返回。
告警传输,server 触发告警规则后,通过http POST将告警信息发送给Alertmanager,altermanager处理后推送通知。