架构原理
架构总结图
plain
┌─────────────────────────────────────────────────────────┐
│ 用户层 │
│ Web UI (Next.js) → 可视化 Canvas → 生成 DSL JSON │
└───────────────────────┬─────────────────────────────────┘
│ HTTP/SSE
↓
┌─────────────────────────────────────────────────────────┐
│ Flask API 层 (Gunicorn) │
│ - DSL 校验 (Hash 冲突检测) │
│ - 鉴权 & 多租户隔离 │
│ - SSE 流式输出 (AppQueueManager) │
└───┬───────────────────┬─────────────────────────────────┘
│ │
│ 异步任务 │ 同步执行
↓ ↓
┌─────────────────┐ ┌────────────────────────────────────┐
│ Celery Worker │ │ GraphEngine (Workflow 执行) │
│ ━━━━━━━━━━━━━ │ │ - 解析 DSL (nodes + edges) │
│ 队列隔离: │ │ - 变量池 (VariablePool) │
│ • dataset │ │ - 事件驱动 DAG 遍历 │
│ • priority_ds │ │ - 节点并行执行 (WorkerPool) │
│ • trigger │ │ - SSRF Proxy 防护 │
│ │ └────────────────────────────────────┘
│ 任务类型: │ │
│ • 文档向量化 │ │ 事件流
│ • 长文清洗 │ ↓
│ • 定时任务 │ ┌────────────────────┐
└────┬────────────┘ │ Redis Pub/Sub │
│ │ - 任务队列 │
│ │ - 分布式锁 │
│ │ - SSE 消息缓存 │
│ └────────────────────┘
↓ │
┌─────────────────────────────┴───────────────────────────┐
│ PostgreSQL + pgvector │
│ - workflows.graph (DSL 存储) │
│ - workflow_runs (执行日志) │
│ - datasets + embeddings (向量数据) │
└─────────────────────────────────────────────────────────┘深度原理剖析
- 核心机制 :
- 异步调度引擎:Celery + Redis 实现任务队列分流,将同步 API 请求转换为异步处理,避免阻塞主线程
- 协程优化:Gevent 补丁将阻塞 IO 操作协程化,提升并发处理能力 (psycopg2 + gRPC 双重优化)
- 应用上下文管理:FlaskTask 包装器确保每个异步任务拥有独立的请求上下文,维持日志追踪和数据库会话隔离
- 定时任务编排:Beat Scheduler 管理周期性清理任务 (缓存清理、数据集清理、队列监控等),防止资源累积
- 设计模式 :
- 适配器模式:FlaskTask 适配 Celery Task 接口,注入 Flask 应用上下文
- 工厂模式 :
create_app()工厂函数通过扩展注册机制动态组装功能模块 - 策略模式:SSL 配置和 Sentinel 模式根据环境配置动态切换连接策略
为何选择 Low-Code DSL 驱动范式?
- 前后端完全解耦
- 前端(Next.js)负责可视化 Canvas 编排,生成 标准 JSON DSL
- 后端(Flask)只关心 DSL 解析 → 执行引擎 → 结果返回
- 任何符合 DSL Schema 的前端都可对接(Web/移动端/第三方工具)
- 执行引擎可版本化
- DSL 持久化到
workflows.graph字段(LongText) - 支持 Draft 版本 (
<font style="color:#DF2A3F;">version='draft'</font>)和 Published 版本(唯一版本号) - 可随时回滚到历史版本,实现 时间旅行调试
- DSL 持久化到
- 节点插件化扩展
- 每个节点类型(LLM、HTTP、Code、Agent)对应独立的
<font style="color:#DF2A3F;">Node</font>类 - 通过 工厂模式 (
node_factory.py) 动态加载节点实现 - 新增节点类型无需修改核心引擎代码
- 每个节点类型(LLM、HTTP、Code、Agent)对应独立的
json
{
"nodes": [
{"id": "start", "type": "start", "data": {...}},
{"id": "llm-1", "type": "llm", "data": {"model": "gpt-4", ...}},
{"id": "http-1", "type": "http_request", "data": {"url": "...", ...}}
],
"edges": [
{"source": "start", "target": "llm-1"},
{"source": "llm-1", "target": "http-1"}
],
"viewport": {...}
}Flask + Celery 高并发架构设计
职责分离原则
| 组件 | 职责 | 技术选型 |
|---|---|---|
| Flask (Gunicorn) | 轻量 API 层 | 处理 HTTP 请求、鉴权、DSL 验证、流式 SSE 输出 |
| Celery Worker | 重计算任务 | 文档清洗、向量化、长文本 Embedding、定时任务 |
| Redis | 消息总线 + 缓存 | Celery Broker、任务队列、分布式锁、SSE Pub/Sub |
| PostgreSQL | 持久化层 | DSL 存储、用户数据、执行日志、向量数据(pgvector) |
队列隔离策略
多队列设计:
dataset队列:普通知识库任务(FIFO)priority_dataset队列:VIP 租户优先任务- 租户隔离队列 (
TenantIsolatedTaskQueue):防止单租户任务占满队列
workflow/DSL 导入与文档处理的完整链路详解
从前端上传到workflow应用创建的完整链路
步骤 1: DSL 导入请求接收
核心入口函数 :AppImportApi.post()
文件位置 :api/controllers/console/app/app_import.py
python
@console_ns.route("/apps/imports") # API 路由定义
class AppImportApi(Resource):
def post(self):
# 步骤1: 用户身份验证
current_user, _ = current_account_with_tenant()
# 步骤2: 参数验证
args = AppImportPayload.model_validate(console_ns.payload)
# 步骤3: 调用业务服务处理 DSL
with Session(db.engine) as session:
import_service = AppDslService(session)
result = import_service.import_app(
account=current_user,
import_mode=args.mode, # "yaml-content" 或 "yaml-url"
yaml_content=args.yaml_content, # YAML 字符串内容
yaml_url=args.yaml_url, # 或者 YAML 文件 URL
name=args.name, # 应用名称
description=args.description, # 应用描述
# ... 其他参数
)
session.commit() # 提交数据库事务步骤 2: DSL 解析与版本兼容性检查
核心入口函数 :AppDslService.import_app()
文件位置 :api/services/app_dsl_service.py
python
def import_app(self, account: Account, import_mode: str, yaml_content: str | None = None, ...) -> Import:
# 步骤1: 模式验证
mode = ImportMode(import_mode)
# 步骤2: 获取 YAML 内容
content = ""
if mode == ImportMode.YAML_URL:
response = ssrf_proxy.get(yaml_url.strip(), follow_redirects=True, timeout=(10, 10))
content = response.content.decode()
# 步骤3: YAML 解析与验证
data = yaml.safe_load(content)
if not isinstance(data, dict):
raise ValueError("Invalid YAML format")
# 步骤4: 版本兼容性检查 ⭐⭐⭐ 核心逻辑
imported_version = data.get("version", "0.1.0")
status = _check_version_compatibility(imported_version)
# 如果版本不兼容,缓存到 Redis 等待用户确认
if status == ImportStatus.PENDING:
redis_client.setex(f"{IMPORT_INFO_REDIS_KEY_PREFIX}{import_id}", IMPORT_INFO_REDIS_EXPIRY, ...)
return Import(id=import_id, status=status)
# 步骤5: 依赖分析
dependencies = data.get("dependencies", [])
# 分析插件依赖,检查租户是否有权限使用
# 步骤6: 创建应用 ⭐⭐⭐ 核心逻辑
app = self._create_or_update_app(...)
return Import(id=import_id, status=ImportStatus.COMPLETED, app_id=app.id)步骤 3: 创建应用(数据持久化到 PostgreSQL)
核心入口函数 :_create_or_update_app()
文件位置 :api/services/app_dsl_service.py
python
def _create_or_update_app(self, app: App | None, data: dict, account: Account, ...) -> App:
# 步骤1: 提取应用基本信息
app_data = data.get("app", {})
app_mode = AppMode(app_data.get("mode")) # workflow/advanced-chat/chat 等
# 步骤2: 创建或更新应用记录
if app: # 更新现有应用
app.name = name or app_data.get("name", app.name)
app.updated_by = account.id
app.updated_at = naive_utc_now()
else: # 创建新应用
app = App()
app.id = str(uuid4())
app.tenant_id = account.current_tenant_id
app.mode = app_mode.value
app.created_by = account.id
app.updated_by = account.id
self._session.add(app)
self._session.commit() # 提交到数据库
# 步骤3: 根据应用模式初始化配置 ⭐⭐⭐ 核心分支逻辑
if app_mode in {AppMode.ADVANCED_CHAT, AppMode.WORKFLOW}:
# 处理工作流配置
workflow_data = data.get("workflow", {})
workflow_service = WorkflowService()
workflow_service.sync_draft_workflow(
app_model=app,
graph=workflow_data.get("graph", {}), # 节点图结构
features=workflow_data.get("features", {}), # 功能配置
# ... 其他参数
)
elif app_mode in {AppMode.CHAT, AppMode.AGENT_CHAT, AppMode.COMPLETION}:
# 处理模型配置
model_config = data.get("model_config", {})
app_model_config = AppModelConfig().from_model_config_dict(model_config)
self._session.add(app_model_config)
return app从文档上传到向量化的完整链路
步骤 1: 文档上传请求接收
核心入口函数 :DatasetService.save_document_with_dataset_id()
文件位置 :api/services/dataset_service.py
python
def save_document_with_dataset_id(
dataset: Dataset,
knowledge_config: KnowledgeConfig,
account: Account,
dataset_process_rule: DatasetProcessRule | None = None,
created_from: str = "web",
) -> tuple[list[Document], str]:
# 步骤1: 权限和配额检查
features = FeatureService.get_features(account.current_tenant_id)
# 检查文档数量限制、文件大小等
# 步骤2: 根据数据源类型处理文档
if knowledge_config.data_source.info_list.data_source_type == "upload_file":
# 文件上传处理
for file_detail in file_details:
document = DocumentService.build_document(...)
db.session.add(document)
document_ids.append(document.id)
# 步骤3: 提交数据库事务
db.session.commit()
# 步骤4: 触发异步文档处理 ⭐⭐⭐ 关键触发点
if document_ids:
DocumentIndexingTaskProxy(dataset.tenant_id, dataset.id, document_ids).delay()
return documents, batch步骤 2: 智能任务路由与分发
核心入口函数 :DocumentIndexingTaskProxy.delay()
文件位置 :api/services/document_indexing_proxy/document_indexing_task_proxy.py
python
class DocumentIndexingTaskProxy(BatchDocumentIndexingProxy):
def delay(self):
"""根据计费计划智能路由任务"""
self._dispatch() # 调用基类的分发逻辑
plain
DocumentIndexingTaskProxy
↓ 继承自
BatchDocumentIndexingProxy
↓ 继承自
DocumentTaskProxyBase ← delay() 方法定义在这里
def delay(self):
"""Public API: Queue the task asynchronously."""
self._dispatch()分发逻辑 (基类 DocumentTaskProxyBase):
python
def _dispatch(self):
"""根据计费计划路由任务
路由策略:
- Sandbox 计划 → 普通队列 + 租户隔离
- 付费计划 → 优先队列 + 租户隔离
- 自托管 → 优先队列,无隔离
"""
if self.features.billing.enabled:
if self.features.billing.subscription.plan == CloudPlan.SANDBOX:
self._send_to_default_tenant_queue() # 普通队列
else:
self._send_to_priority_tenant_queue() # 优先队列
else:
self._send_to_priority_direct_queue() # 自托管环境实际的调用链路:
python
# 1. 创建代理实例
proxy = DocumentIndexingTaskProxy(tenant_id, dataset_id, document_ids)
# 2. 调用继承的 delay() 方法
proxy.delay()
↓
# 3. 执行基类的 delay() 方法
self._dispatch()
↓
# 4. 根据计费计划路由任务
if billing.enabled:
if plan == SANDBOX:
_send_to_default_tenant_queue()
else:
_send_to_priority_tenant_queue()
else:
_send_to_priority_direct_queue()步骤 3: Celery 异步文档处理
核心入口函数 :normal_document_indexing_task() 或 priority_document_indexing_task()
文件位置 :api/tasks/document_indexing_task.py
python
@shared_task(queue="dataset") # 或 priority queue
def normal_document_indexing_task(tenant_id: str, dataset_id: str, document_ids: list):
"""普通优先级文档处理任务"""
_document_indexing_with_tenant_queue(tenant_id, dataset_id, document_ids, _document_indexing)不同任务优先级区别:
python
normal_document_indexing_task() 和 priority_document_indexing_task() 的处理流程和步骤是完全一致的!
唯一的区别:
队列不同:普通任务使用 dataset 队列,优先级任务使用 priority_dataset 队列
调度优先级:优先级队列的任务会被 Celery Worker 优先处理
相同点:
调用相同的核心处理函数 _document_indexing()
具有相同的租户隔离队列管理逻辑
执行相同的文档处理四大步骤(提取、转换、保存分段、建立索引)
这种设计的好处是:代码复用。只需要维护一份核心处理逻辑,通过不同的队列装饰器实现不同的优先级调度。实际处理函数 :_document_indexing()
python
def _document_indexing(dataset_id: str, document_ids: Sequence[str]):
# 步骤1: 权限和配额检查
dataset = db.session.query(Dataset).where(Dataset.id == dataset_id).first()
features = FeatureService.get_features(dataset.tenant_id)
# 检查文档数量限制
batch_upload_limit = int(dify_config.BATCH_UPLOAD_LIMIT)
if len(document_ids) > batch_upload_limit:
raise ValueError(f"超出批上传限制 {batch_upload_limit}")
# 步骤2: 更新文档状态为处理中
for document_id in document_ids:
document = db.session.query(Document).where(Document.id == document_id).first()
if document:
document.indexing_status = "parsing"
document.processing_started_at = naive_utc_now()
db.session.add(document)
db.session.commit()
# 步骤3: 执行文档处理 ⭐⭐⭐ 核心处理逻辑
try:
indexing_runner = IndexingRunner()
indexing_runner.run(documents) # 四大处理步骤
except Exception as e:
logger.exception("文档处理失败")
finally:
db.session.close()步骤 4: 文档处理四大步骤
核心入口函数 :IndexingRunner.run()
文件位置 :api/core/indexing_runner.py
python
def run(self, dataset_documents: list[DatasetDocument]):
for dataset_document in dataset_documents:
try:
# 获取数据集和处理规则
dataset = db.session.query(Dataset).filter_by(id=dataset_document.dataset_id).first()
processing_rule = db.session.query(DatasetProcessRule).filter_by(id=dataset_document.dataset_process_rule_id).first()
# 步骤1: 提取 (Extract) - 从原始文件提取文本
text_docs = self._extract(index_processor, dataset_document, processing_rule.to_dict())
# 步骤2: 转换 (Transform) - 文本清洗、分段、向量化
documents = self._transform(
index_processor, dataset, text_docs,
dataset_document.doc_language, processing_rule.to_dict()
)
# 步骤3: 保存分段 (Load Segments) - 保存到数据库
self._load_segments(dataset, dataset_document, documents)
# 步骤4: 建立索引 (Load) - 创建向量索引
self._load(index_processor, dataset, dataset_document, documents)
except Exception as e:
self._handle_indexing_error(dataset_document.id, e)文档处理四大步骤详细说明
Dify 的文档处理采用经典的 ETL (Extract-Transform-Load) 模式,扩展为四个步骤:提取 → 转换 → 保存分段 → 建立索引。
步骤 1: 提取 (Extract) - 从原始文件提取文本
核心方法 :_extract()
文件位置 :api/core/indexing_runner.py:366-446
详细逻辑
python
def _extract(self, index_processor: BaseIndexProcessor, dataset_document: DatasetDocument, process_rule: dict) -> list[Document]:
# 根据数据源类型进行不同处理
if dataset_document.data_source_type == "upload_file":
# 文件上传:PDF、Word、TXT 等
file_detail = db.session.query(UploadFile).get(data_source_info["upload_file_id"])
extract_setting = ExtractSetting(
datasource_type=DatasourceType.FILE,
upload_file=file_detail,
document_model=dataset_document.doc_form, # 文档形式:text_model, qa_model 等
)
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule["mode"])
elif dataset_document.data_source_type == "notion_import":
# Notion 导入
extract_setting = ExtractSetting(
datasource_type=DatasourceType.NOTION,
notion_info=NotionInfo(...), # Notion 页面信息
document_model=dataset_document.doc_form,
)
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule["mode"])
elif dataset_document.data_source_type == "website_crawl":
# 网站爬取
extract_setting = ExtractSetting(
datasource_type=DatasourceType.WEBSITE,
website_info=WebsiteInfo(...), # 网站信息
document_model=dataset_document.doc_form,
)
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule["mode"])
# 更新文档状态为 "splitting"(分段中)
self._update_document_index_status(document_id, "splitting")
return text_docs提取器类型
根据 document_model 选择不同的索引处理器:
| 文档形式 | 处理器类 | 适用场景 |
|---|---|---|
text_model |
ParagraphIndexProcessor |
普通文本文档 |
qa_model |
QaIndexProcessor |
问答对文档 |
parent_child_index |
ParentChildIndexProcessor |
父子索引结构 |
提取结果
返回 list[Document],每个 Document 包含:
page_content: 提取的文本内容metadata: 元数据(文档ID、页码等)
步骤 2: 转换 (Transform) - 文本清洗、分段、向量化
核心方法 :_transform()
文件位置 :api/core/indexing_runner.py:742-776
详细逻辑
python
def _transform(self, index_processor: BaseIndexProcessor, dataset: Dataset,
text_docs: list[Document], doc_language: str, process_rule: dict,
current_user: Account | None = None) -> list[Document]:
# 获取向量化模型实例(仅高质量模式需要)
embedding_model_instance = None
if dataset.indexing_technique == "high_quality":
if dataset.embedding_model_provider:
# 使用指定的向量化模型
embedding_model_instance = self.model_manager.get_model_instance(
tenant_id=dataset.tenant_id,
provider=dataset.embedding_model_provider,
model_type=ModelType.TEXT_EMBEDDING,
model=dataset.embedding_model,
)
else:
# 使用默认向量化模型
embedding_model_instance = self.model_manager.get_default_model_instance(
tenant_id=dataset.tenant_id,
model_type=ModelType.TEXT_EMBEDDING,
)
# 执行转换处理
documents = index_processor.transform(
text_docs=text_docs,
current_user=current_user,
embedding_model_instance=embedding_model_instance,
process_rule=process_rule, # 处理规则
tenant_id=dataset.tenant_id,
doc_language=doc_language, # 文档语言
)
return documents转换处理内容
文本预处理:
- 移除多余空白字符
- 统一编码格式
- 语言检测和处理
分段策略:
- 固定长度分段:按字符数或token数分割
- 智能分段:基于语义分割,保持段落完整性
- 重叠分段:相邻分段有重叠以保持上下文连贯性
向量化处理(仅高质量模式):
- 将文本转换为向量嵌入
- 支持多种向量化模型(OpenAI、Cohere、本地模型等)
步骤 3: 保存分段 (Load Segments) - 持久化到数据库
核心方法 :_load_segments()
文件位置 :api/core/indexing_runner.py:778-800
详细逻辑
python
def _load_segments(self, dataset: Dataset, dataset_document: DatasetDocument, documents: list[Document]):
# 创建文档存储器
doc_store = DatasetDocumentStore(
dataset=dataset,
user_id=dataset_document.created_by,
document_id=dataset_document.id
)
# 保存文档分段到数据库
doc_store.add_documents(
docs=documents,
save_child=dataset_document.doc_form == IndexStructureType.PARENT_CHILD_INDEX
)
# 更新文档状态
cur_time = naive_utc_now()
self._update_document_index_status(
document_id=dataset_document.id,
after_indexing_status="indexing", # 索引中
extra_update_params={
DatasetDocument.cleaning_completed_at: cur_time,
DatasetDocument.splitting_completed_at: cur_time,
DatasetDocument.word_count: sum(len(doc.page_content) for doc in documents),
},
)
# 更新分段状态
self._update_segments_by_document(
dataset_document_id=dataset_document.id,
update_params={
DocumentSegment.status: "indexing",
DocumentSegment.indexing_at: naive_utc_now(),
},
)保存内容
DocumentSegment 表存储:
- 分段文本内容
- 位置信息(position)
- 元数据
- 状态信息
父子索引支持:
- 对于
<font style="color:#DF2A3F;">parent_child_index</font>类型的文档,还会创建父子关系 ChildChunk表存储子分段信息
步骤 4: 建立索引 (Load) - 创建向量和关键词索引
核心方法 :_load()
文件位置 :api/core/indexing_runner.py:550-633
详细逻辑
python
def _load(self, index_processor: BaseIndexProcessor, dataset: Dataset,
dataset_document: DatasetDocument, documents: list[Document]):
# 获取向量化模型(仅高质量模式)
embedding_model_instance = None
if dataset.indexing_technique == "high_quality":
embedding_model_instance = self.model_manager.get_model_instance(...)
# 并发处理设置
indexing_start_at = time.perf_counter()
max_workers = 10
# 经济模式:创建关键词索引
if dataset.indexing_technique == "economy":
create_keyword_thread = threading.Thread(
target=self._process_keyword_index,
args=(current_app._get_current_object(), dataset.id, dataset_document.id, documents),
)
create_keyword_thread.start()
# 高质量模式:并发建立向量索引
if dataset.indexing_technique == "high_quality":
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
# 将文档分组,避免数据库死锁
document_groups = [[] for _ in range(max_workers)]
for document in documents:
hash = helper.generate_text_hash(document.page_content)
group_index = int(hash, 16) % max_workers
document_groups[group_index].append(document)
# 并发处理每个分组
futures = []
for chunk_documents in document_groups:
if chunk_documents:
future = executor.submit(
self._process_chunk, # 核心处理函数
current_app._get_current_object(),
index_processor,
chunk_documents,
dataset,
dataset_document,
embedding_model_instance,
)
futures.append(future)
# 等待所有任务完成
tokens = 0
for future in futures:
tokens += future.result()
# 等待关键词索引完成
if create_keyword_thread:
create_keyword_thread.join()
# 更新文档状态为完成
indexing_end_at = time.perf_counter()
self._update_document_index_status(
document_id=dataset_document.id,
after_indexing_status="completed",
extra_update_params={
DatasetDocument.tokens: tokens,
DatasetDocument.completed_at: naive_utc_now(),
DatasetDocument.indexing_latency: indexing_end_at - indexing_start_at,
},
)索引类型
高质量模式 (high_quality):
- 向量索引:使用向量化模型将文本转换为向量,建立向量数据库索引
- 并发处理:10个线程并发处理,避免数据库死锁
- 负载均衡:基于内容哈希将文档分配到不同线程
经济模式 (economy):
- 关键词索引:基于TF-IDF等算法建立关键词索引
- 多线程处理:后台线程异步创建关键词索引
性能优化
- 分组处理:通过内容哈希将文档分配到不同线程,避免热点冲突
- 异步关键词索引:与向量索引并行处理,提升整体性能
- 连接池管理:合理使用数据库连接,避免资源耗尽
四大步骤对比总结
| 步骤 | 方法名 | 输入 | 输出 | 主要处理 | 性能特点 |
|---|---|---|---|---|---|
| 提取 | _extract |
原始文件 | list[Document] |
文件解析、文本提取 | IO密集型 |
| 转换 | _transform |
文本文档 | 分段文档 | 清洗、分段、向量化 | 计算密集型 |
| 保存分段 | _load_segments |
分段文档 | 数据库记录 | 数据持久化 | IO密集型 |
| 建立索引 | _load |
分段文档 | 向量索引 | 索引构建 | 计算+IO混合 |
关键设计理念
- 模块化设计:每个步骤职责单一,便于维护和扩展
- 策略模式 :通过
<font style="color:#DF2A3F;">index_processor</font>支持不同文档类型的处理 - 并发优化:高质量模式使用多线程提升性能
- 容错机制:每个步骤都有异常处理和状态更新
- 索引分层:支持向量索引和关键词索引两种模式,满足不同场景需求
这个设计使得 Dify 能够高效处理大规模文档,同时保证数据的一致性和系统的稳定性。
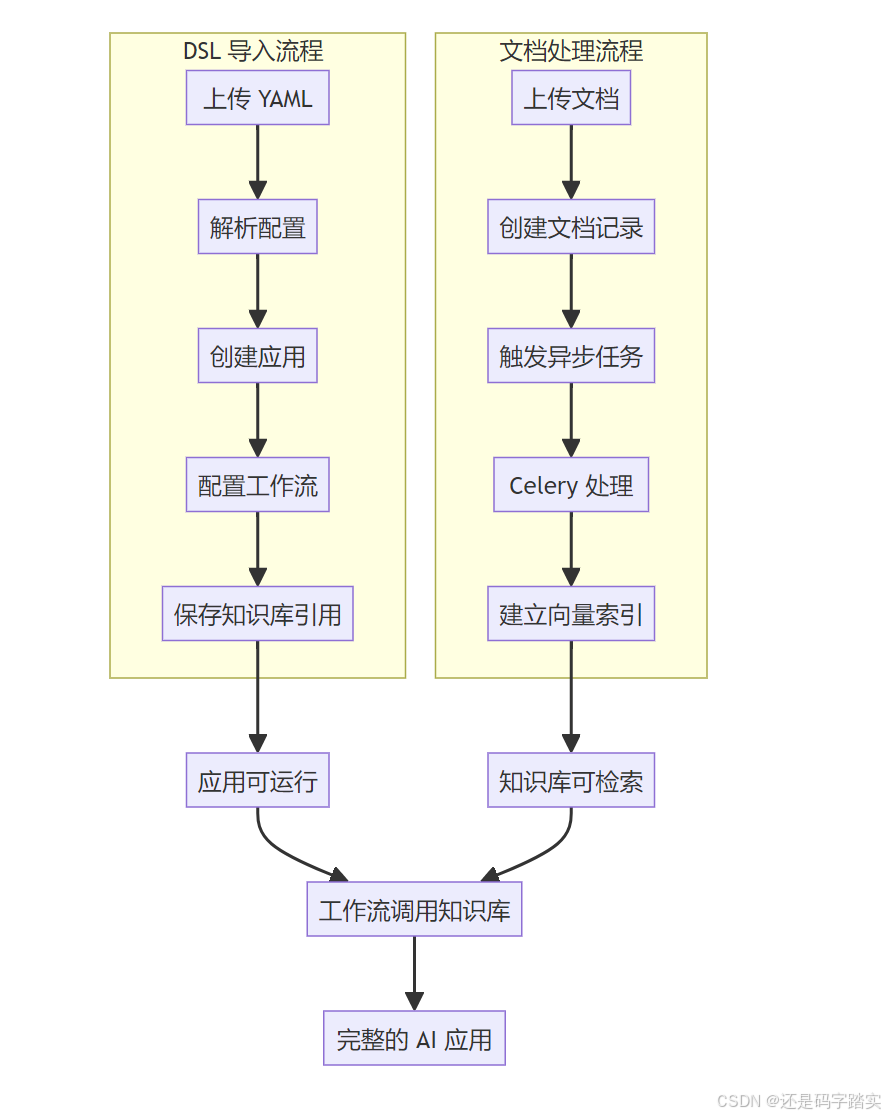
两个流程的区别与联系
流程对比表
| 方面 | DSL 导入流程 | 文档处理流程 |
|---|---|---|
| 触发时机 | 用户上传 YAML 文件 | 用户上传文档文件 |
| 处理对象 | 应用配置信息 | 文档内容数据 |
| 数据库操作 | 创建应用、工作流记录 | 创建文档记录,建立索引 |
| 异步处理 | 无(配置导入很快) | 有(文档处理很慢) |
| Celery 任务 | 不触发 | document_indexing_task.delay() |
| 最终结果 | 应用可运行 | 知识库可检索 |
两个流程的关联
完整链路关键函数总结
DSL 导入链路
| 步骤 | 关键函数 | 位置 | 功能 |
|---|---|---|---|
| 请求接收 | AppImportApi.post |
app_import.py |
API 路由接收 |
| DSL 解析 | AppDslService.import_app |
app_dsl_service.py |
YAML 解析和验证 |
| 版本检查 | _check_version_compatibility |
app_dsl_service.py |
版本兼容性检查 |
| 数据持久化 | _create_or_update_app |
app_dsl_service.py |
创建应用配置 |
文档处理链路
| 步骤 | 关键函数 | 位置 | 功能 |
|---|---|---|---|
| 文档上传 | save_document_with_dataset_id |
dataset_service.py |
文档上传处理 |
| 任务分发 | DocumentIndexingTaskProxy.delay |
document_indexing_proxy.py |
智能路由任务 |
| 异步处理 | normal_document_indexing_task |
document_indexing_task.py |
Celery 任务执行 |
| 文档处理 | IndexingRunner.run |
indexing_runner.py |
四大处理步骤 |
实际场景:run workflows(用户运行工作流,从点击"运行"到看到结果)
场景描述
小明在 Dify 前端可视化界面拖拽了一个简单的工作流:
- 开始节点 (用户输入:
{user_query: "什么是AI?"}) - LLM 节点(调用 GPT-4 回答问题)
- 结束节点(输出答案)
现在小明点击"运行"按钮,后台会发生什么?
完整链路流程图
plain
┌─────────────────────────────────────────────────────────────────┐
│ 第1步:前端发起请求 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 用户点击"运行" → 前端发送 HTTP POST 请求 │
│ POST /api/apps/{app_id}/workflows/run │
│ Body: { │
│ "inputs": {"user_query": "什么是AI?"}, │
│ "files": [] │
│ } │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第2步:Flask Controller 接收请求 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/controllers/console/app/workflow.py │
│ 🔧 函数:DraftWorkflowApi.post() │
│ │
│ 关键操作: │
│ 1. 验证用户权限(@login_required) │
│ 2. 解析请求参数(inputs, files) │
│ 3. 调用 Service 层 │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第3步:AppGenerateService 路由到工作流生成器 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/services/app_generate_service.py │
│ 🔧 函数:AppGenerateService.generate() │
│ │
│ 伪代码: │
│ if app_model.mode == AppMode.WORKFLOW: │
│ workflow = get_workflow(app_id) │
│ return WorkflowAppGenerator().generate( │
│ app_model=app, │
│ workflow=workflow, │
│ user=current_user, │
│ args=request_data, │
│ streaming=True # 开启流式输出 │
│ ) │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第4步:WorkflowAppGenerator 准备执行环境 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/core/app/apps/workflow/app_generator.py │
│ 🔧 函数:WorkflowAppGenerator.generate() │
│ │
│ 关键操作(按顺序): │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ 1️⃣ 创建 WorkflowAppGenerateEntity │ │
│ │ - task_id: "uuid-1234" │ │
│ │ - inputs: {"user_query": "什么是AI?"} │ │
│ │ - stream: True │ │
│ │ │ │
│ │ 2️⃣ 创建 AppQueueManager(消息队列管理器) │ │
│ │ - 内部维护 Python Queue 用于事件传递 │ │
│ │ - Redis 存储 task_id → user_id 映射 │ │
│ │ │ │
│ │ 3️⃣ 启动后台线程执行工作流 │ │
│ │ Thread(target=WorkflowAppRunner.run).start() │ │
│ │ │ │
│ │ 4️⃣ Flask 主线程进入 listen() 循环 │ │
│ │ while True: │ │
│ │ event = queue_manager.listen() # 阻塞等待事件 │ │
│ │ yield to_sse_format(event) # SSE 流式返回前端 │ │
│ └────────────────────────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第5步:后台线程执行工作流(核心引擎) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/core/workflow/workflow_entry.py │
│ 🔧 函数:WorkflowEntry.run() │
│ │
│ 调用链:WorkflowEntry.run() │
│ → GraphEngine.run() │
│ → Dispatcher.dispatch_nodes() (并行调度) │
│ │
│ 执行过程(事件驱动): │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ 阶段1:初始化 │ │
│ │ ├─ 解析 DSL (workflow.graph) │ │
│ │ ├─ 构建 DAG(节点 + 边) │ │
│ │ ├─ 创建 VariablePool(变量池) │ │
│ │ └─ 发送事件:GraphRunStartedEvent │ │
│ │ │ │
│ │ 阶段2:执行 Start 节点 │ │
│ │ ├─ 从用户输入初始化变量池 │ │
│ │ │ variable_pool.add("user_query", "什么是AI?") │ │
│ │ └─ 发送事件:NodeStartedEvent(node_id="start") │ │
│ │ │ │
│ │ 阶段3:执行 LLM 节点 │ │
│ │ ├─ 从变量池读取输入:query = variable_pool.get("user_query")│ │
│ │ ├─ 调用 OpenAI API (GPT-4) │ │
│ │ ├─ 流式返回 Chunk: │ │
│ │ │ └─ LLMChunkEvent("人工") → Queue → SSE → 前端 │ │
│ │ │ └─ LLMChunkEvent("智能") → Queue → SSE → 前端 │ │
│ │ └─ 输出存入变量池:variable_pool.add("llm_output", "...") │ │
│ │ │ │
│ │ 阶段4:执行 End 节点 │ │
│ │ ├─ 从变量池读取最终输出 │ │
│ │ └─ 发送事件:WorkflowFinishedEvent │ │
│ └────────────────────────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第6步:事件流转回前端 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 后台线程 → Python Queue → Flask Listen() → SSE → 前端 │
│ │
│ 前端收到的 SSE 事件流: │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ data: {"event": "workflow_started", ...} │ │
│ │ data: {"event": "node_started", "node_id": "start"} │ │
│ │ data: {"event": "node_finished", "node_id": "start"} │ │
│ │ data: {"event": "node_started", "node_id": "llm-1"} │ │
│ │ data: {"event": "text_chunk", "text": "人工"} │ │
│ │ data: {"event": "text_chunk", "text": "智能"} │ │
│ │ data: {"event": "node_finished", "node_id": "llm-1"} │ │
│ │ data: {"event": "workflow_finished", "outputs": {...}} │ │
│ └────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘关键函数详解(递归拆解)
应用生成服务的统一入口:AppGenerateService.generate()
python
# 文件:api/services/app_generate_service.py 第25-126行
@classmethod
def generate(cls, app_model: App, user: Union[Account, EndUser], args: Mapping[str, Any],
invoke_from: InvokeFrom, streaming: bool = True, root_node_id: str | None = None):
"""
应用生成服务的统一入口
参数:
- app_model: 应用模型(包含 mode、tenant_id 等)
- user: 当前用户
- args: 请求参数 {"inputs": {...}, "files": [...]}
- streaming: 是否流式输出(True 为 SSE,False 为一次性返回)
返回:
- Generator(流式)或 Dict(非流式)
"""
# 第1步:限流检查(每个应用同时最多N个请求)
max_active_request = cls._get_max_active_requests(app_model)
rate_limit = RateLimit(app_model.id, max_active_request)
request_id = RateLimit.gen_request_key()
try:
request_id = rate_limit.enter(request_id) # 进入限流队列
# 第2步:根据应用模式路由到不同生成器
if app_model.mode == AppMode.WORKFLOW: # ⭐ 工作流模式
workflow_id = args.get("workflow_id")
workflow = cls._get_workflow(app_model, invoke_from, workflow_id)
return rate_limit.generate(
WorkflowAppGenerator.convert_to_event_stream(
WorkflowAppGenerator().generate( # 👈 调用工作流生成器
app_model=app_model,
workflow=workflow,
user=user,
args=args,
invoke_from=invoke_from,
streaming=streaming,
root_node_id=root_node_id,
call_depth=0,
),
),
request_id,
)
# 其他模式(COMPLETION, CHAT, AGENT_CHAT)...
except Exception:
rate_limit.exit(request_id) # 出错时释放限流
raise作用 :这是所有应用执行的统一入口,相当于高铁站的总调度室,根据列车类型(工作流/聊天/补全)分配到不同站台。
工作流生成器的核心逻辑:WorkflowAppGenerator.generate()
python
# 文件:api/core/app/apps/workflow/app_generator.py 第100-300行
def generate(self, *, app_model: App, workflow: Workflow, user: Union[Account, EndUser],
args: Mapping[str, Any], invoke_from: InvokeFrom, streaming: bool = True,
call_depth: int = 0, triggered_from: WorkflowRunTriggeredFrom | None = None,
root_node_id: str | None = None, graph_engine_layers: Sequence[GraphEngineLayer] = ()):
"""
工作流生成器的核心逻辑
这个函数做了3件大事:
1. 准备执行环境(解析文件、验证输入)
2. 创建队列管理器(AppQueueManager)
3. 启动后台线程执行工作流
"""
# 第1步:解析文件上传
files: Sequence[Mapping[str, Any]] = args.get("files") or []
file_extra_config = FileUploadConfigManager.convert(workflow.features_dict, is_vision=False)
system_files = file_factory.build_from_mappings(
mappings=files,
tenant_id=app_model.tenant_id,
config=file_extra_config,
)
# 第2步:转换为应用配置
app_config = WorkflowAppConfigManager.get_app_config(
app_model=app_model,
workflow=workflow,
)
# 第3步:准备用户输入(类型验证 + 变量映射)
inputs: Mapping[str, Any] = args["inputs"]
if self._should_prepare_user_inputs(args):
inputs = self._prepare_user_inputs(
user_inputs=inputs,
variables=app_config.variables,
tenant_id=app_model.tenant_id,
)
# 第4步:创建执行实体(打包所有参数)
workflow_run_id = str(uuid.uuid4())
application_generate_entity = WorkflowAppGenerateEntity(
task_id=str(uuid.uuid4()), # 唯一任务ID
app_config=app_config,
inputs=inputs, # {"user_query": "什么是AI?"}
files=list(system_files),
user_id=user.id,
stream=streaming, # True
invoke_from=invoke_from,
call_depth=call_depth,
workflow_execution_id=workflow_run_id,
)
# 第5步:创建数据库 Repository(用于保存执行记录)
session_factory = sessionmaker(bind=db.engine, expire_on_commit=False)
workflow_execution_repository = DifyCoreRepositoryFactory.create_workflow_execution_repository(
session_factory=session_factory,
user=user,
app_id=application_generate_entity.app_config.app_id,
triggered_from=WorkflowRunTriggeredFrom.APP_RUN,
)
# 第6步:创建队列管理器 ⭐⭐⭐ 核心!
queue_manager = WorkflowAppQueueManager(
task_id=application_generate_entity.task_id,
user_id=application_generate_entity.user_id,
invoke_from=application_generate_entity.invoke_from,
conversation_id=None,
app_mode=app_model.mode,
)
# 第7步:创建执行管道(Pipeline)
generate_task_pipeline = WorkflowAppGenerateTaskPipeline(
application_generate_entity=application_generate_entity,
workflow=workflow,
queue_manager=queue_manager,
conversation_id=None,
message_id=None,
workflow_execution_repository=workflow_execution_repository,
workflow_node_execution_repository=workflow_node_execution_repository,
)
# 第8步:启动后台线程执行工作流 🚀
try:
generate_task_pipeline.process() # 👈 这里启动后台线程
except Exception as e:
queue_manager.publish_error(e, PublishFrom.APPLICATION_MANAGER)
finally:
queue_manager.stop_listen() # 清理资源
# 第9步:Flask 主线程在这里循环,监听队列中的事件
return self._handle_response( # 👈 这里会 yield 事件流
application_generate_entity=application_generate_entity,
workflow=workflow,
generator=generate_task_pipeline,
queue_manager=queue_manager,
)关键点 :这个函数把 Flask 主线程分成了两个角色:
- 主线程 :调用
queue_manager.listen()循环等待事件,通过 SSE 返回给前端 - 后台线程:执行工作流的实际计算(LLM 调用、HTTP 请求等)
监听队列中的事件:AppQueueManager.listen()
python
# 文件:api/core/app/apps/base_app_queue_manager.py 第55-85行
def listen(self):
"""
监听队列中的事件(Flask 主线程在这里循环)
这个函数是 Generator(生成器),每次 yield 一个事件
前端通过 SSE 实时接收这些事件
"""
# 最长监听时间(默认1200秒 = 20分钟)
listen_timeout = dify_config.APP_MAX_EXECUTION_TIME
start_time = time.time()
last_ping_time: int | float = 0
while True:
try:
# 从 Python Queue 中取出事件(阻塞1秒)
message = self._q.get(timeout=1)
if message is None: # 收到停止信号
break
yield message # 👈 返回给前端(SSE)
except queue.Empty: # 队列为空,继续循环
continue
finally:
elapsed_time = time.time() - start_time
# 超时或用户手动停止
if elapsed_time >= listen_timeout or self._is_stopped():
self.publish(
QueueStopEvent(stopped_by=QueueStopEvent.StopBy.USER_MANUAL),
PublishFrom.TASK_PIPELINE
)
# 每10秒发送一次 Ping(心跳检测)
if elapsed_time // 10 > last_ping_time:
self.publish(QueuePingEvent(), PublishFrom.TASK_PIPELINE)
last_ping_time = elapsed_time // 10作用 :这是一个无限循环的生成器,就像一个传送带工人,不停地从队列里拿事件,然后丢给前端。
后台线程执行图引擎:GraphEngine.run()
python
# 文件:api/core/workflow/graph_engine/graph_engine.py 第200-300行
def run(self) -> Generator[GraphEngineEvent, None, None]:
"""
图引擎的核心执行逻辑(在后台线程中运行)
执行步骤:
1. 发送 GraphRunStartedEvent
2. 初始化开始节点到 ready_queue
3. 启动 WorkerPool 并行执行节点
4. 收集执行事件并 yield
5. 发送 GraphRunFinishedEvent
"""
try:
# 第1步:发送开始事件
yield GraphRunStartedEvent(...)
# 第2步:初始化图状态(找到所有入口节点)
self._initialize_graph() # 将 start 节点放入 ready_queue
# 第3步:创建工作线程池(动态扩缩容)
self._worker_pool = WorkerPool(
min_workers=self._min_workers,
max_workers=self._max_workers,
scale_up_threshold=self._scale_up_threshold,
scale_down_idle_time=self._scale_down_idle_time,
)
# 第4步:启动调度器(Dispatcher)
dispatcher = Dispatcher(
ready_queue=self._ready_queue,
worker_pool=self._worker_pool,
stop_event=self._stop_event,
)
# 第5步:启动执行协调器(ExecutionCoordinator)
coordinator = ExecutionCoordinator(
dispatcher=dispatcher,
event_queue=self._event_queue,
edge_processor=self._edge_processor,
error_handler=self._error_handler,
)
# 第6步:开始执行并收集事件
for event in coordinator.run():
# 处理事件(更新图状态、触发下一个节点)
self._handle_event(event)
yield event # 👈 发送到队列
# 第7步:发送完成事件
yield GraphRunSucceededEvent(...)
except Exception as e:
yield GraphRunFailedEvent(error=str(e))核心概念:
- ready_queue:准备就绪的节点队列(类似待办清单)
- WorkerPool:线程池,从 ready_queue 取节点并行执行
- EdgeProcessor:节点执行完后,根据边(Edge)找下一个节点
示例:完整事件流(带时间戳)
假设小明运行的工作流:Start → LLM → End
| 时间 | 事件类型 | 事件内容 | 前端显示 |
|---|---|---|---|
| 0.0s | workflow_started |
{"workflow_id": "wf-123"} |
显示"执行中..." |
| 0.1s | node_started |
{"node_id": "start", "node_type": "start"} |
高亮 Start 节点 |
| 0.2s | node_finished |
{"node_id": "start", "outputs": {"user_query": "什么是AI?"}} |
Start 节点变绿 |
| 0.3s | node_started |
{"node_id": "llm-1", "node_type": "llm"} |
高亮 LLM 节点 |
| 1.5s | text_chunk |
{"text": "人工"} |
实时显示"人工" |
| 1.6s | text_chunk |
{"text": "智能"} |
追加显示"智能" |
| 2.0s | node_finished |
{"node_id": "llm-1", "outputs": {"text": "人工智能..."}} |
LLM 节点变绿 |
| 2.1s | node_started |
{"node_id": "end"} |
高亮 End 节点 |
| 2.2s | workflow_finished |
{"outputs": {"answer": "人工智能..."}} |
显示"执行成功" |
实际场景:用户上传文档(异步任务)
场景描述
小红上传了一个 PDF 文档到知识库,后台需要:
- 分段(Chunking)
- 调用 Embedding 模型生成向量
- 存入 PostgreSQL (pgvector)
这个过程可能需要几分钟,所以要用 Celery 异步任务。
完整链路流程图
plain
┌─────────────────────────────────────────────────────────────────┐
│ 第1步:前端上传文档 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ POST /api/datasets/{dataset_id}/documents │
│ Body (multipart/form-data): │
│ file: document.pdf (二进制) │
│ indexing_technique: "high_quality" # 使用高质量索引 │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第2步:Flask Controller 处理上传 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/controllers/console/datasets/documents.py │
│ 🔧 函数:DocumentAddByFileApi.post() │
│ │
│ 关键操作: │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ 1️⃣ 保存文件到 Storage (S3/本地) │ │
│ │ storage.save(f"datasets/{dataset_id}/document.pdf") │ │
│ │ │ │
│ │ 2️⃣ 创建 Document 记录(状态=queued) │ │
│ │ document = Document( │ │
│ │ id="doc-456", │ │
│ │ dataset_id="ds-789", │ │
│ │ name="document.pdf", │ │
│ │ indexing_status="queued", # 等待索引 │ │
│ │ created_by=user.id │ │
│ │ ) │ │
│ │ db.session.add(document) │ │
│ │ db.session.commit() │ │
│ │ │ │
│ │ 3️⃣ 发送 Celery 异步任务 ⭐⭐⭐ │ │
│ │ normal_document_indexing_task.delay( │ │
│ │ tenant_id=current_tenant.id, │ │
│ │ dataset_id="ds-789", │ │
│ │ document_ids=["doc-456"] │ │
│ │ ) │ │
│ │ │ │
│ │ 4️⃣ 立即返回响应给前端 │ │
│ │ return {"document_id": "doc-456", "status": "queued"} │ │
│ └────────────────────────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────────────────────────┘
↓ (任务进入 Redis 队列)
┌─────────────────────────────────────────────────────────────────┐
│ 第3步:Celery Worker 接收任务 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/tasks/document_indexing_task.py │
│ 🔧 函数:normal_document_indexing_task() │
│ │
│ Celery Worker 进程(独立进程,不是 Flask): │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ 队列:dataset (普通优先级) │ │
│ │ 任务:normal_document_indexing_task │ │
│ │ 参数:(tenant_id, dataset_id, document_ids) │ │
│ └────────────────────────────────────────────────────────────┘ │
│ │
│ @shared_task(queue="dataset") │
│ def normal_document_indexing_task(tenant_id, dataset_id, doc_ids):│
│ # 更新文档状态为 "parsing" │
│ document.indexing_status = "parsing" │
│ db.session.commit() │
│ │
│ # 调用核心索引逻辑 │
│ _document_indexing(dataset_id, doc_ids) │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第4步:IndexingRunner 执行索引流程 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/core/indexing_runner.py │
│ 🔧 函数:IndexingRunner.run() │
│ │
│ 核心流程(按顺序): │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ 阶段1:文档解析 (Extraction) │ │
│ │ ├─ PDF → 文本提取 │ │
│ │ └─ 结果:"人工智能是... (5000字)" │ │
│ │ │ │
│ │ 阶段2:文本分段 (Chunking) │ │
│ │ ├─ 使用分段器:RecursiveCharacterTextSplitter │ │
│ │ ├─ 参数:chunk_size=500, overlap=50 │ │
│ │ └─ 结果: │ │
│ │ Segment 1: "人工智能是计算机科学..." │ │
│ │ Segment 2: "机器学习是人工智能的子领域..." │ │
│ │ Segment 3: "深度学习使用神经网络..." │ │
│ │ │ │
│ │ 阶段3:向量化 (Embedding) │ │
│ │ ├─ 调用 Embedding 模型(如 text-embedding-ada-002) │ │
│ │ ├─ 并发处理(批量调用,每批10个 Segment) │ │
│ │ └─ 结果: │ │
│ │ Segment 1 → [0.12, -0.34, 0.56, ...] (1536维) │ │
│ │ Segment 2 → [0.23, 0.11, -0.45, ...] (1536维) │ │
│ │ Segment 3 → [0.89, 0.02, 0.33, ...] (1536维) │ │
│ │ │ │
│ │ 阶段4:存入数据库 │ │
│ │ ├─ 批量插入 PostgreSQL (document_segments 表) │ │
│ │ └─ pgvector 扩展自动索引向量 │ │
│ │ │ │
│ │ 阶段5:更新文档状态 │ │
│ │ └─ document.indexing_status = "completed" ✅ │ │
│ └────────────────────────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 第5步:租户隔离队列处理下一个任务 │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ 📄 文件:api/tasks/document_indexing_task.py │
│ 🔧 函数:_document_indexing_with_tenant_queue() │
│ │
│ finally 块(任务完成后执行): │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ # 从租户专属队列取出下一个任务 │ │
│ │ tenant_queue = TenantIsolatedTaskQueue(tenant_id, "doc_idx")││
│ │ next_tasks = tenant_queue.pull_tasks(count=2) # 取2个任务 │ │
│ │ │ │
│ │ if next_tasks: │ │
│ │ for task in next_tasks: │ │
│ │ # 继续触发 Celery 任务 │ │
│ │ normal_document_indexing_task.delay(...) │ │
│ │ else: │ │
│ │ # 队列为空,清理标志位 │ │
│ │ tenant_queue.delete_task_key() │ │
│ └────────────────────────────────────────────────────────────┘ │
│ │
│ ⚙️ 设计目的:防止单租户提交1000个文档占满整个队列 │
└─────────────────────────────────────────────────────────────────┘关键函数详解
Celery Worker 执行索引任务:normal_document_indexing_task()
python
# 文件:api/tasks/document_indexing_task.py 第149-161行
@shared_task(queue="dataset") # ⭐ 声明这是 Celery 任务,路由到 dataset 队列
def normal_document_indexing_task(tenant_id: str, dataset_id: str, document_ids: Sequence[str]):
"""
普通文档索引任务(Celery Worker 执行)
参数:
- tenant_id: 租户ID(用于隔离)
- dataset_id: 数据集ID
- document_ids: 要处理的文档ID列表(可批量)
执行流程:
1. 调用 _document_indexing() 执行实际索引
2. 完成后检查租户队列是否还有待处理任务
3. 如果有,继续触发下一个任务
"""
logger.info("收到普通文档索引任务: %s - %s - %s", tenant_id, dataset_id, document_ids)
# 委托给带租户队列的处理函数
_document_indexing_with_tenant_queue(
tenant_id,
dataset_id,
document_ids,
normal_document_indexing_task # 传入自己(用于递归调用)
)关键点:
@shared_task(queue="dataset"):告诉 Celery 这个任务放到dataset队列<font style="color:#DF2A3F;">.delay()</font>:异步调用方式(Flask 调用后立即返回)
文档索引的核心流程:IndexingRunner.run()
python
# 文件:api/core/indexing_runner.py(简化版)
class IndexingRunner:
def run(self, documents: list[Document]):
"""
文档索引的核心流程
参数:
- documents: 要处理的文档列表
执行步骤:
1. 提取文本
2. 分段
3. Embedding
4. 存储
"""
for document in documents:
try:
# 第1步:提取文本(支持 PDF、Word、TXT 等)
extractor = self._get_extractor(document.file_type)
text = extractor.extract(document.file_path)
# 第2步:文本清洗
cleaned_text = self._clean_text(text)
# 第3步:分段
segments = self._split_to_segments(
cleaned_text,
chunk_size=500,
overlap=50
)
# 结果示例:
# segments = [
# {"content": "人工智能是...", "position": 1},
# {"content": "机器学习是...", "position": 2},
# ]
# 第4步:批量生成向量
embeddings = self._generate_embeddings(
[seg["content"] for seg in segments]
)
# embeddings = [
# [0.12, -0.34, ...], # 1536维向量
# [0.23, 0.11, ...],
# ]
# 第5步:存入数据库
self._save_segments_to_db(
document_id=document.id,
segments=segments,
embeddings=embeddings
)
# 第6步:更新文档状态
document.indexing_status = "completed"
document.indexed_at = naive_utc_now()
db.session.commit()
except Exception as e:
# 出错时标记为 error
document.indexing_status = "error"
document.error = str(e)
db.session.commit()
def _split_to_segments(self, text: str, chunk_size: int, overlap: int) -> list[dict]:
"""
递归字符分段器(RecursiveCharacterTextSplitter)
原理:
1. 优先按段落(\\n\\n)分割
2. 如果段落太长,按句子(。!?)分割
3. 如果句子太长,按字符强制分割
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap,
separators=["\\n\\n", "\\n", "。", "!", "?", " ", ""]
)
chunks = splitter.split_text(text)
return [
{"content": chunk, "position": i+1}
for i, chunk in enumerate(chunks)
]
def _generate_embeddings(self, texts: list[str]) -> list[list[float]]:
"""
批量生成向量(并发调用 Embedding API)
示例:
texts = ["人工智能是...", "机器学习是..."]
返回:
[
[0.12, -0.34, 0.56, ...], # 第1段的向量
[0.23, 0.11, -0.45, ...] # 第2段的向量
]
"""
embeddings = []
batch_size = 10 # 每批处理10个
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
# 调用 Embedding 模型 API
response = self.embedding_model.embed_documents(batch)
embeddings.extend(response.embeddings)
return embeddings
def _save_segments_to_db(self, document_id: str, segments: list[dict],
embeddings: list[list[float]]):
"""
批量插入数据库(使用 pgvector 扩展)
SQL 示例:
INSERT INTO document_segments (id, document_id, content, embedding, position)
VALUES
('seg-1', 'doc-456', '人工智能是...', '[0.12,-0.34,...]', 1),
('seg-2', 'doc-456', '机器学习是...', '[0.23,0.11,...]', 2);
"""
for segment, embedding in zip(segments, embeddings):
segment_model = DocumentSegment(
id=str(uuid.uuid4()),
document_id=document_id,
content=segment["content"],
embedding=embedding, # pgvector 自动处理
position=segment["position"],
)
db.session.add(segment_model)
db.session.commit()时间线示例(带租户隔离)
假设租户A 上传了 3 个文档(doc-1, doc-2, doc-3)
| 时间 | 事件 | Redis 队列状态 | Celery Worker 状态 |
|---|---|---|---|
| 0.0s | 前端上传 doc-1 | tenant:A:doc_idx = [doc-1] |
Worker-1 开始处理 doc-1 |
| 0.5s | 前端上传 doc-2 | tenant:A:doc_idx = [doc-1, doc-2] |
Worker-1 仍在处理 doc-1 |
| 1.0s | 前端上传 doc-3 | tenant:A:doc_idx = [doc-1, doc-2, doc-3] |
Worker-1 仍在处理 doc-1 |
| 5.0s | doc-1 完成 | tenant:A:doc_idx = [doc-2, doc-3] |
Worker-1 从队列取 doc-2 |
| 10.0s | doc-2 完成 | tenant:A:doc_idx = [doc-3] |
Worker-1 从队列取 doc-3 |
| 15.0s | doc-3 完成 | tenant:A:doc_idx = [](清空) |
Worker-1 空闲 |
租户隔离的好处:
- 如果租户B 同时上传文档,会进入独立队列
tenant:B:doc_idx - 不会被租户A 的任务阻塞
可视化总结(Mermaid 流程图)
PostgreSQL IndexingRunner Celery Redis Flask 前端 PostgreSQL IndexingRunner Celery Redis Flask 前端 Flask 立即返回,不等待处理完成 alt 队列为空 队列有任务 POST /datasets/{id}/documents (上传 PDF) INSERT Document (status=queued) LPUSH task_queue (doc_indexing_task) 200 OK {"status": "queued"} RPOP task_queue (获取任务) run(document) 提取文本 (PDF → Text) 分段 (Text → Segments) Embedding (Segments → Vectors) INSERT Segments (批量插入) UPDATE Document (status=completed) 检查租户队列 (是否还有任务?) DELETE task_key LPUSH next_task
核心要点总结
场景 A(工作流执行)
- Flask 不阻塞 :通过
AppQueueManager + Python Queue实现异步 - SSE 流式输出:前端实时看到每个节点的执行状态
- 后台线程执行 :
<font style="color:#DF2A3F;">GraphEngine</font>在独立线程中运行,支持并行节点 - 事件驱动:节点通过事件(NodeStartedEvent、LLMChunkEvent)通信
场景 B(文档索引)
- Celery 异步:Flask 立即返回,Celery Worker 后台处理
- 租户隔离:每个租户有独立队列,防止相互阻塞
- 批量优化:Embedding 批量调用,数据库批量插入
- 自动重试:Celery 支持任务失败重试(max_retries)
完美!让我为 app_factory.py 做同样的深度拆分解析。
Flask 应用工厂 app_factory.py
模块概览与职责
核心职责
python
"""
app_factory.py - Dify Flask 应用的工厂模块
【主要职责】
1. 创建 Flask 应用实例并加载配置
2. 注册请求生命周期钩子(before_request, after_request)
3. 按正确顺序初始化所有扩展(26 个扩展模块)
4. 注入分布式追踪的 Trace ID 到响应头
【设计模式】
- 工厂模式:通过函数创建应用实例,而非全局变量
- 依赖注入:扩展通过 init_app() 方法注入
- 生命周期管理:统一管理扩展的初始化顺序
【关键函数】
┌────────────────────────────────────────────────────────┐
│ create_flask_app_with_configs() # 创建基础应用 │
│ create_app() # 创建完整应用 │
│ initialize_extensions() # 初始化所有扩展 │
│ create_migrations_app() # 迁移专用应用 │
└────────────────────────────────────────────────────────┘
"""模块架构图
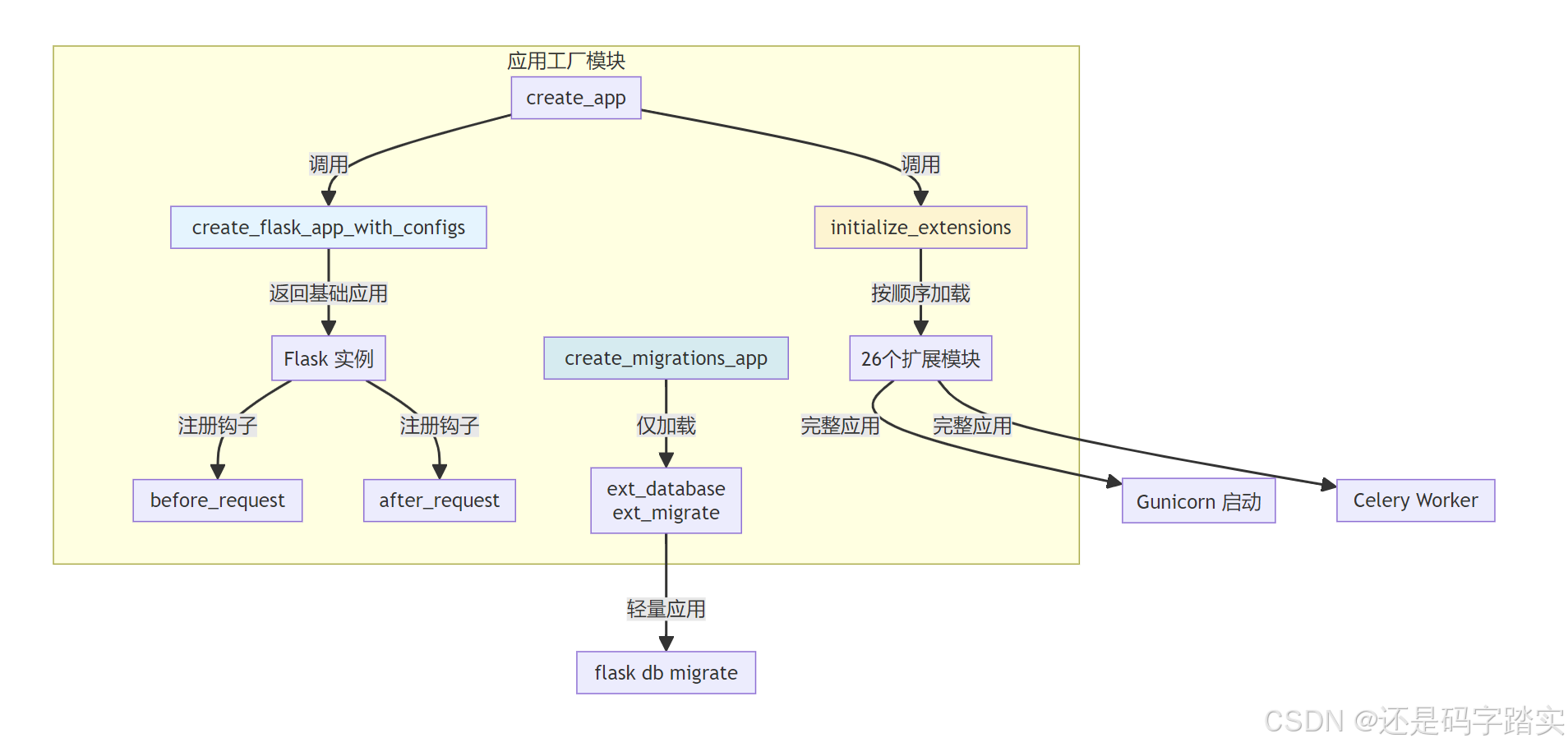
基础应用创建 - create_flask_app_with_configs()
函数详解
python
def create_flask_app_with_configs() -> DifyApp:
"""
创建原始 Flask 应用实例并加载配置
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行步骤】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 实例化 DifyApp(继承自 Flask)
2️⃣ 从 .env 文件加载配置到 app.config
3️⃣ 注册请求生命周期钩子:
- before_request: 初始化日志上下文
- after_request: 注入追踪 ID 到响应头
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【返回】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
DifyApp 实例(已配置但未初始化扩展)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【注意】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
此时应用仅完成配置加载,尚未初始化:
- 数据库连接池(ext_database)
- Redis 客户端(ext_redis)
- Celery 任务队列(ext_celery)
需要调用 initialize_extensions() 完成完整初始化
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 1: 创建 Flask 应用实例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
dify_app = DifyApp(__name__)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 2: 加载配置(Pydantic 模型 → Flask Config)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# dify_config 是从 .env 加载的 Pydantic BaseSettings 对象
# model_dump() 将其转为 dict,然后注入到 Flask 的 config
dify_app.config.from_mapping(dify_config.model_dump())
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 3: 启用 Flask-RESTX 的所有模型(Swagger 文档)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
dify_app.config["RESTX_INCLUDE_ALL_MODELS"] = True
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 4: 注册钩子(详见后续章节)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@dify_app.before_request
def before_request():
init_request_context()
RecyclableContextVar.increment_thread_recycles()
@dify_app.after_request
def add_trace_headers(response):
# ...
return response
# 避免 pyright 的 reportUnusedFunction 警告
_ = before_request
_ = add_trace_headers
return dify_app基础应用创建流程
环境变量
默认值
开始创建应用
创建 DifyApp 实例
加载 .env 配置
配置来源?
dify_config.model_dump
app.config.from_mapping
设置 RESTX 配置
RESTX_INCLUDE_ALL_MODELS = True
注册 before_request 钩子
注册 after_request 钩子
返回 DifyApp 实例
请求前钩子 - before_request
钩子详解
python
@dify_app.before_request
def before_request():
"""
请求前钩子 - 在每个 HTTP 请求处理前自动执行
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行时机】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
HTTP 请求到达 → before_request → 路由处理函数
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心功能】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 初始化日志上下文(trace_id, span_id, tenant_id)
→ 确保日志能关联到具体请求和租户
2️⃣ 增加线程回收计数器
→ 防止线程池复用导致的上下文污染
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【为何需要】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ Dify 是多租户系统,必须隔离不同租户的上下文
✅ 日志追踪需要 trace_id 来串联分布式调用链
✅ Gunicorn Worker 进程复用线程,需要清理旧上下文
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【底层原理】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- init_request_context() 会生成新的 trace_id
- 存储在 Python 的 contextvars 中(线程安全)
- 所有日志输出会自动包含这些上下文信息
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【上下文示例】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
{
"trace_id": "00000000000000000000000000abc123",
"span_id": "0000000000000001",
"tenant_id": "tenant-456",
"user_id": "user-789",
"request_id": "req-001"
}
"""
# 1️⃣ 初始化当前请求的日志上下文
init_request_context()
# 2️⃣ 增加线程回收计数器
# 用于 ContextVar 的生命周期管理,避免上下文泄漏
RecyclableContextVar.increment_thread_recycles()before_request 执行流程
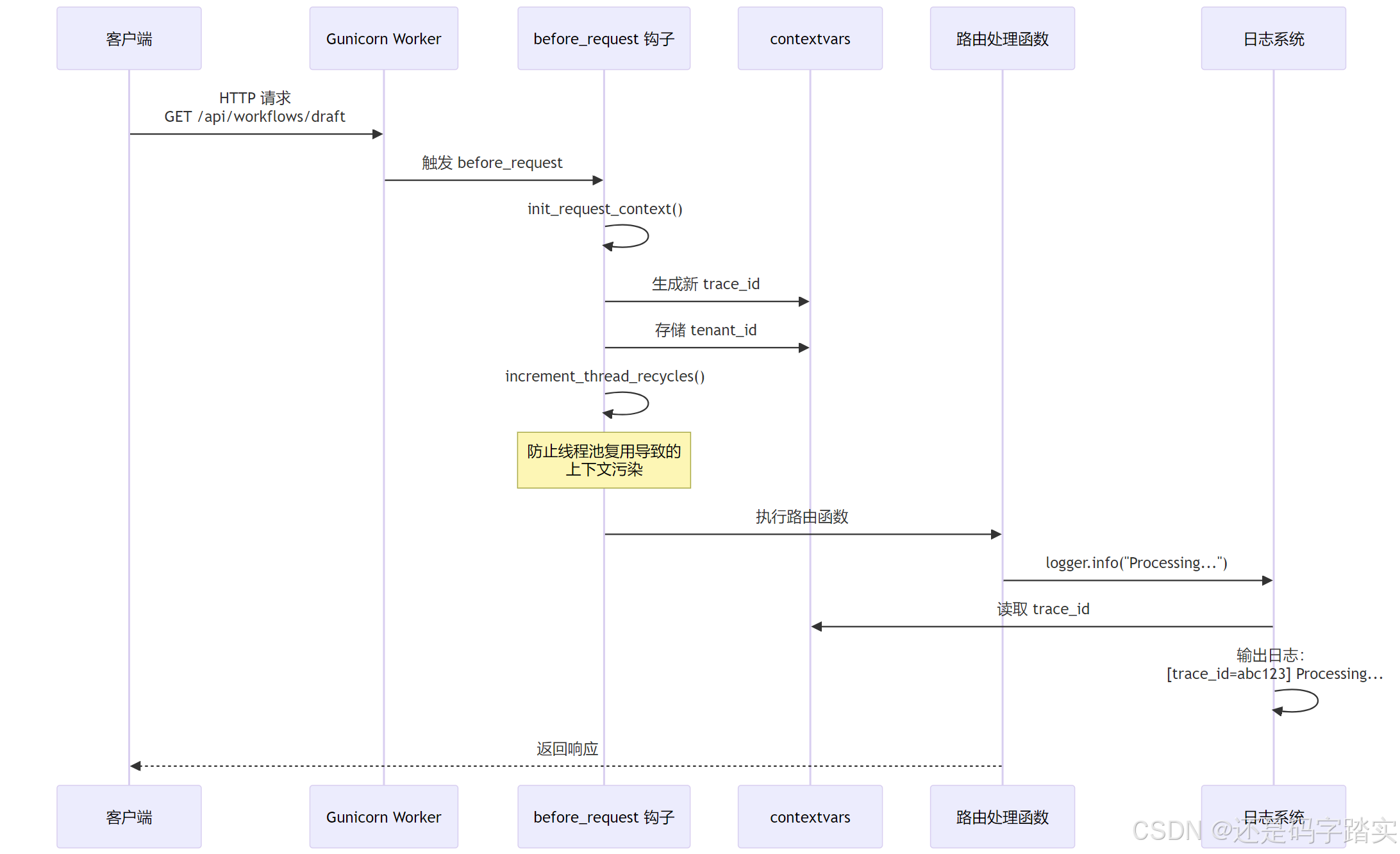
上下文隔离的实际案例
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景:多租户系统的上下文隔离
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ─── 请求 A(租户 A)10:00:00 ───
# HTTP 请求到达
# before_request() 执行:
# → trace_id = "aaa-111"
# → tenant_id = "tenant-a"
# → user_id = "user-001"
# 路由处理:
logger.info("Creating workflow")
# 输出:[trace_id=aaa-111][tenant_id=tenant-a] Creating workflow
# ─── 请求 B(租户 B)10:00:01(同一 Worker 进程)───
# HTTP 请求到达
# before_request() 执行:
# → trace_id = "bbb-222" ✅ 独立的 trace_id
# → tenant_id = "tenant-b" ✅ 独立的租户 ID
# → user_id = "user-002"
# 路由处理:
logger.info("Creating workflow")
# 输出:[trace_id=bbb-222][tenant_id=tenant-b] Creating workflow
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 如果没有 before_request,会发生什么?
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ❌ 请求 B 可能会读取到请求 A 的 tenant_id
# ❌ 日志会串到错误的租户
# ❌ 数据库查询可能访问到其他租户的数据(安全风险!)请求后钩子 - after_request
钩子详解
python
@dify_app.after_request
def add_trace_headers(response):
"""
请求后钩子 - 在响应返回前注入追踪头
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行时机】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
路由处理函数 → after_request → 返回 HTTP 响应
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心功能】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 从 OpenTelemetry 获取当前 Span 的 trace_id 和 span_id
2️⃣ 将它们注入到 HTTP 响应头:
- X-Trace-Id: 用于全链路追踪
- X-Span-Id: 用于定位具体操作
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【应用场景】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ 前端可以通过响应头获取 trace_id
✅ 用户报错时,提供 trace_id 给客服,快速定位问题
✅ 在日志系统(如 Langfuse)中搜索 trace_id,查看完整调用链
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【为何需要 try-except】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
❗ 即使追踪头注入失败,也不能影响正常响应
❗ 追踪是辅助功能,不应成为单点故障
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【技术细节】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- trace_id 是 128 位整数,格式化为 32 位十六进制(032x)
- span_id 是 64 位整数,格式化为 16 位十六进制(016x)
"""
try:
# ─── Step 1: 获取当前 OpenTelemetry Span ───
span = get_current_span()
ctx = span.get_span_context() if span else None
# ─── Step 2: 检查 Span 上下文是否有效 ───
if not ctx or not ctx.is_valid:
return response
# ─── Step 3: 注入 Trace ID(32位十六进制)───
# 例如:00000000000000000000000000abc123
if ctx.trace_id != INVALID_TRACE_ID and "X-Trace-Id" not in response.headers:
response.headers["X-Trace-Id"] = format(ctx.trace_id, "032x")
# ─── Step 4: 注入 Span ID(16位十六进制)───
# 例如:0000000000000001
if ctx.span_id != INVALID_SPAN_ID and "X-Span-Id" not in response.headers:
response.headers["X-Span-Id"] = format(ctx.span_id, "016x")
except Exception:
# 永远不要因为追踪头注入失败而中断响应
logger.warning("Failed to add trace headers to response", exc_info=True)
return responseafter_request 执行流程
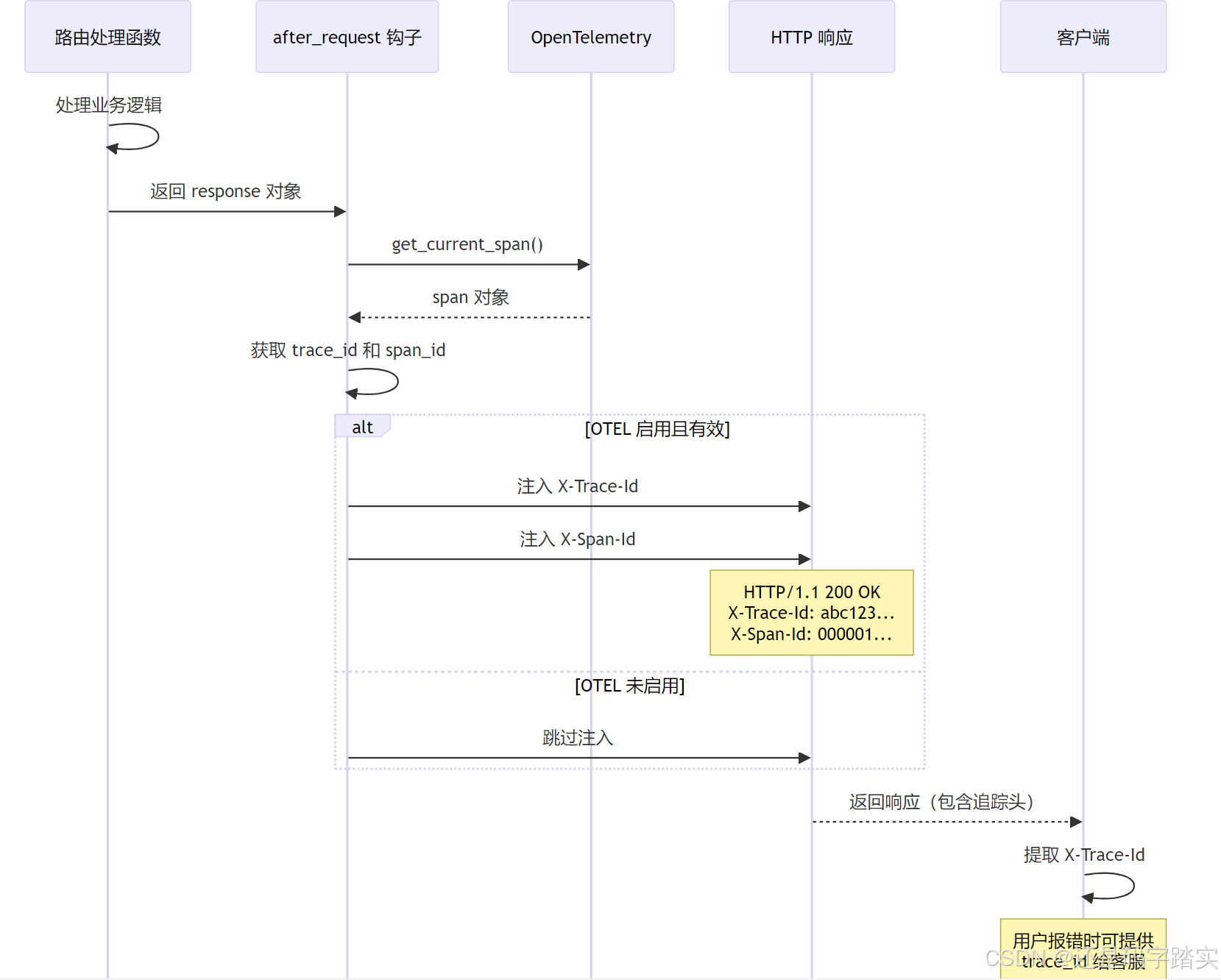
Trace ID 的实战应用
bash
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景:用户报错时的问题定位
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ─── Step 1: 前端收到响应 ───
HTTP/1.1 500 Internal Server Error
Content-Type: application/json
X-Trace-Id: 00000000000000000000000000abc123
X-Span-Id: 0000000000000001
{
"error": "Workflow execution failed"
}
# ─── Step 2: 用户联系客服 ───
用户:"我的工作流执行失败了,请帮我查看"
客服:"请提供您的 Trace ID"
用户:"X-Trace-Id: abc123"
# ─── Step 3: 客服在 Langfuse 搜索 ───
# 搜索:trace_id = "abc123"
# 看到完整调用链:
┌─────────────────────────────────────────────┐
│ Workflow Execution Trace │
├─────────────────────────────────────────────┤
│ [10:00:00] Workflow Start │
│ ↓ │
│ [10:00:01] LLM Node (GPT-4) - 2.3s │
│ ↓ │
│ [10:00:03] HTTP Node - 500 Error ❌ │
│ URL: https://api.example.com/data │
│ Error: Connection timeout │
│ ↓ │
│ [10:00:03] Workflow Failed │
└─────────────────────────────────────────────┘
# 客服:"找到问题了!HTTP 节点访问超时,已通知技术团队修复"完整应用创建 - create_app()
主函数详解
python
def create_app() -> DifyApp:
"""
创建完整的 Dify 应用实例(生产环境入口)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 创建基础 Flask 应用(create_flask_app_with_configs)
2️⃣ 初始化所有扩展(initialize_extensions)
3️⃣ 记录启动耗时(DEBUG 模式)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【返回】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
DifyApp 实例(完全初始化,可直接运行)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调用者】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- api/app.py (Gunicorn 启动入口)
- api/celery_entrypoint.py (Celery Worker 启动)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【启动耗时参考】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- 开发环境:~500ms
- 生产环境:~800ms(包含数据库连接池预热)
"""
# ─── 开始计时 ───
start_time = time.perf_counter()
# ─── Step 1: 创建基础应用 ───
app = create_flask_app_with_configs()
# ─── Step 2: 初始化所有扩展 ───
initialize_extensions(app)
# ─── Step 3: 记录启动耗时(仅 DEBUG 模式)───
end_time = time.perf_counter()
if dify_config.DEBUG:
logger.info(
"Finished create_app (%s ms)",
round((end_time - start_time) * 1000, 2)
)
return app6. 扩展初始化 - initialize_extensions()
核心函数详解
python
def initialize_extensions(app: DifyApp):
"""
按依赖顺序初始化 Flask 扩展
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【关键原则】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 依赖顺序必须正确
例如:ext_database 必须在 ext_celery 之前
ext_storage 必须在 ext_logstore 之前
2️⃣ 支持条件加载
每个扩展可以通过 is_enabled() 方法控制是否加载
例如:SENTRY_DSN 未配置时,跳过 ext_sentry
3️⃣ 性能监控
DEBUG 模式下记录每个扩展的加载耗时
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【加载流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
for ext in extensions:
1. 检查 is_enabled()
2. 调用 ext.init_app(app)
3. 记录加载耗时
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【总共 26 个扩展】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
详见第 7 章:扩展加载顺序详解
"""
# ─── 导入所有扩展模块 ───
from extensions import (
ext_app_metrics, # Prometheus 指标
ext_blueprints, # API 路由
ext_celery, # Celery 任务队列
# ... 其他 23 个扩展
)
# ─── 定义加载顺序(顺序至关重要!)───
extensions = [
ext_timezone, # 1️⃣ 时区
ext_logging, # 2️⃣ 日志
ext_database, # 🔟 数据库
ext_redis, # 1️⃣3️⃣ Redis
ext_celery, # 1️⃣6️⃣ Celery
# ... 详见第 7 章
]
# ─── 遍历加载每个扩展 ───
for ext in extensions:
# 获取扩展名称
short_name = ext.__name__.split(".")[-1]
# 检查是否启用
is_enabled = ext.is_enabled() if hasattr(ext, "is_enabled") else True
if not is_enabled:
if dify_config.DEBUG:
logger.info("Skipped %s", short_name)
continue
# 记录加载开始时间
start_time = time.perf_counter()
# 🔥 核心:初始化扩展
ext.init_app(app)
# 记录加载耗时
end_time = time.perf_counter()
if dify_config.DEBUG:
logger.info("Loaded %s (%s ms)",
short_name,
round((end_time - start_time) * 1000, 2))扩展加载顺序详解
26 个扩展的分层架构
python
extensions = [
# ═══════════════════════════════════════════════
# 第一层:基础配置(无依赖)
# ═══════════════════════════════════════════════
ext_timezone, # 1️⃣ 时区设置
"""
【作用】设置全局时区为 UTC
【依赖】无
【耗时】~1ms
"""
ext_logging, # 2️⃣ 日志系统
"""
【作用】配置日志格式、级别、输出目标
【依赖】无
【耗时】~2ms
【配置】LOG_LEVEL, LOG_FILE, LOG_FORMAT
"""
ext_warnings, # 3️⃣ 警告过滤
"""
【作用】屏蔽第三方库的无用警告
【依赖】无
【耗时】~1ms
"""
ext_import_modules, # 4️⃣ 动态模块导入
"""
【作用】预加载 models、services 等模块
【依赖】无
【耗时】~50ms
"""
ext_orjson, # 5️⃣ 高性能 JSON 序列化
"""
【作用】替换 Flask 默认的 json 模块
【依赖】无
【耗时】~1ms
【性能】比标准 json 快 2-3 倍
"""
ext_forward_refs, # 6️⃣ Pydantic 前向引用
"""
【作用】解决循环导入问题
【依赖】无
【耗时】~1ms
"""
ext_set_secretkey, # 7️⃣ SECRET_KEY 设置
"""
【作用】设置 Flask Session 加密密钥
【依赖】无
【耗时】~1ms
【重要】生产环境必须配置随机密钥
"""
ext_compress, # 8️⃣ 响应压缩
"""
【作用】启用 Gzip 压缩
【依赖】无
【耗时】~2ms
【效果】减少 70% 的传输体积
"""
ext_code_based_extension, # 9️⃣ 代码扩展加载器
"""
【作用】加载自定义扩展
【依赖】无
【耗时】~1ms
"""
# ═══════════════════════════════════════════════
# 第二层:核心基础设施(有依赖关系)
# ═══════════════════════════════════════════════
ext_database, # 🔟 数据库连接池
"""
【作用】初始化 SQLAlchemy + PostgreSQL 连接池
【依赖】无(但其他扩展依赖它)
【耗时】~100ms(包含连接池预热)
【配置】
- DB_HOST, DB_PORT, DB_DATABASE
- SQLALCHEMY_POOL_SIZE = 30
- SQLALCHEMY_MAX_OVERFLOW = 10
【关键】后续所有数据库操作都依赖此连接池
"""
ext_app_metrics, # 1️⃣1️⃣ Prometheus 指标
"""
【作用】注册 Prometheus 指标端点
【依赖】ext_database(需要数据库指标)
【耗时】~5ms
【端点】GET /metrics
"""
ext_migrate, # 1️⃣2️⃣ Alembic 数据库迁移
"""
【作用】注册 flask db 命令
【依赖】ext_database
【耗时】~10ms
【命令】flask db upgrade, flask db migrate
"""
ext_redis, # 1️⃣3️⃣ Redis 客户端
"""
【作用】初始化 Redis 连接池
【依赖】无(但 ext_celery 依赖它)
【耗时】~20ms
【配置】
- REDIS_HOST, REDIS_PORT, REDIS_DB
- REDIS_USE_SENTINEL = false
- REDIS_USE_CLUSTERS = false
【用途】
- Celery Broker
- 缓存(用户会话、模型配置)
- 分布式锁
"""
ext_storage, # 1️⃣4️⃣ 对象存储
"""
【作用】初始化对象存储客户端(S3/本地/阿里云)
【依赖】无
【耗时】~30ms
【配置】
- STORAGE_TYPE = 'local' | 's3' | 'azure-blob'
- S3_BUCKET_NAME, S3_REGION
【用途】
- 文件上传存储
- 工作流执行日志
"""
# ═══════════════════════════════════════════════
# 第三层:业务服务层(依赖核心层)
# ═══════════════════════════════════════════════
ext_logstore, # 1️⃣5️⃣ 日志存储
"""
【作用】将日志写入对象存储
【依赖】ext_logstore ⚠️ 必须在 ext_storage 之后
【耗时】~5ms
"""
ext_celery, # 1️⃣6️⃣ Celery 任务队列
"""
【作用】初始化 Celery 配置
【依赖】ext_celery ⚠️ 必须在 ext_redis 之后
【耗时】~50ms
【配置】
- CELERY_BROKER_URL = redis://...
- 队列:dataset, priority_dataset, trigger
- Beat 定时任务:清理缓存、数据备份
【用途】
- 文档向量化
- 定时任务调度
- 异步工作流执行
"""
ext_login, # 1️⃣7️⃣ 登录管理
"""
【作用】Flask-Login 会话管理
【依赖】ext_database, ext_redis
【耗时】~5ms
"""
ext_mail, # 1️⃣8️⃣ 邮件发送
"""
【作用】SMTP 邮件发送
【依赖】无
【耗时】~5ms
【配置】SMTP_SERVER, SMTP_PORT, SMTP_USERNAME
"""
ext_hosting_provider, # 1️⃣9️⃣ 托管服务商配置
"""
【作用】云服务商特定配置(AWS/Azure/阿里云)
【依赖】无
【耗时】~2ms
"""
# ═══════════════════════════════════════════════
# 第四层:可观测性(依赖业务层)
# ═══════════════════════════════════════════════
ext_sentry, # 2️⃣0️⃣ Sentry 错误追踪
"""
【作用】捕获异常并上报到 Sentry
【依赖】ext_database
【耗时】~20ms
【配置】SENTRY_DSN
【条件】仅在 SENTRY_DSN 配置时启用
"""
ext_proxy_fix, # 2️⃣1️⃣ 代理修复
"""
【作用】处理 X-Forwarded-For 等反向代理头部
【依赖】无
【耗时】~1ms
【场景】Nginx/Traefik 反向代理后获取真实 IP
"""
ext_blueprints, # 2️⃣2️⃣ API 路由注册
"""
【作用】注册所有 API Blueprint
【依赖】ext_database, ext_redis, ext_celery
【耗时】~100ms
【路由】
- /api/console/* (控制台 API)
- /api/service/* (服务 API)
- /api/web/* (前端 API)
⚠️ 必须在其他扩展之后,因为路由依赖所有服务
"""
ext_commands, # 2️⃣3️⃣ CLI 命令
"""
【作用】注册 Flask CLI 命令
【依赖】ext_database
【耗时】~5ms
【命令】
- flask init (初始化数据库)
- flask reset-password
"""
ext_otel, # 2️⃣4️⃣ OpenTelemetry 追踪
"""
【作用】启用分布式追踪
【依赖】ext_blueprints ⚠️ 必须在路由注册后
【耗时】~30ms
【配置】
- OTEL_EXPORTER_OTLP_ENDPOINT
- OTEL_SERVICE_NAME = "dify-api"
"""
ext_request_logging, # 2️⃣5️⃣ 请求日志
"""
【作用】记录所有 HTTP 请求
【依赖】ext_blueprints
【耗时】~5ms
【输出】[GET /api/workflows/draft]
"""
ext_session_factory, # 2️⃣6️⃣ Session 工厂
"""
【作用】SQLAlchemy Session 管理
【依赖】ext_database
【耗时】~2ms
【用途】提供线程安全的数据库会话
"""
]常见的加载顺序错误
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 错误示例 1:ext_celery 在 ext_redis 之前
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_celery, # ❌ 错误!Celery 需要 Redis 作为 Broker
ext_redis, # Redis 客户端尚未初始化
]
# 启动报错:
# RuntimeError: Redis client is not initialized. Call init_app first.
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 正确顺序:
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_redis, # ✅ 先初始化 Redis
ext_celery, # ✅ 再初始化 Celery
]
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 错误示例 2:ext_logstore 在 ext_storage 之前
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_logstore, # ❌ 错误!Logstore 需要将日志写入 S3
ext_storage, # 对象存储尚未初始化
]
# 启动报错:
# AttributeError: 'NoneType' object has no attribute 'put_object'
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 正确顺序:
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_storage, # ✅ 先初始化对象存储
ext_logstore, # ✅ 再初始化日志存储
]
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 错误示例 3:ext_otel 在 ext_blueprints 之前
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_otel, # ❌ OTEL 需要拦截所有路由
ext_blueprints, # 路由尚未注册
]
# 结果:OTEL 无法追踪 API 请求(功能失效)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 正确顺序:
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
extensions = [
ext_blueprints, # ✅ 先注册所有路由
ext_otel, # ✅ 再启用追踪(拦截已注册的路由)
]数据库迁移专用应用
create_migrations_app() 详解
python
def create_migrations_app():
"""
创建仅用于数据库迁移的轻量级应用
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【使用场景】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- flask db upgrade (执行数据库迁移)
- flask db migrate (生成迁移脚本)
- flask db downgrade (回滚迁移)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【为何需要】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ 数据库迁移不需要加载重型扩展(Redis、Celery、Storage)
✅ 减少启动时间(从 ~800ms 降低到 ~150ms)
✅ 避免迁移脚本因外部服务不可用而失败
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【仅加载的扩展】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- ext_database: PostgreSQL 连接(必需)
- ext_migrate: Alembic 迁移工具(必需)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调用者】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- flask db 命令(通过 Flask CLI)
- api/app.py 中的条件判断
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【启动耗时】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
~150ms(比完整应用快 5 倍)
"""
# ─── Step 1: 创建基础应用 ───
app = create_flask_app_with_configs()
# ─── Step 2: 仅加载数据库相关扩展 ───
from extensions import ext_database, ext_migrate
ext_database.init_app(app) # 初始化 SQLAlchemy
ext_migrate.init_app(app) # 初始化 Alembic
return app实际使用场景
bash
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景 1: 生成迁移脚本
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
$ flask db migrate -m "Add workflow unique_hash column"
# 执行流程:
# 1. Flask CLI 检测到 db 命令
# 2. 调用 create_migrations_app()(仅加载 2 个扩展)
# 3. Alembic 比对数据库与模型差异
# 4. 生成迁移脚本:migrations/versions/xxx_add_workflow_unique_hash.py
# ✅ 启动快速(~150ms)
# ✅ 不依赖 Redis、Celery 等外部服务
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景 2: 执行迁移
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
$ flask db upgrade
# 执行流程:
# 1. 调用 create_migrations_app()
# 2. Alembic 执行待执行的迁移脚本
# 3. 更新 alembic_version 表
# SQL 示例:
# ALTER TABLE workflows ADD COLUMN unique_hash VARCHAR(64);
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景 3: 回滚迁移
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
$ flask db downgrade -1
# 执行流程:
# 1. 调用 create_migrations_app()
# 2. Alembic 执行 downgrade() 函数
# 3. 回滚最近一次迁移
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 对比:如果使用完整应用
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ❌ 启动耗时 ~800ms(慢 5 倍)
# ❌ 需要 Redis 可用(否则启动失败)
# ❌ 需要 Celery Broker 可用
# ❌ CI/CD 环境中可能因外部依赖失败api/app.py 中的条件判断
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# api/app.py - 应用启动入口
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
import sys
def is_db_command() -> bool:
"""
检测当前是否在执行数据库命令
【判断逻辑】
命令行参数:flask db ...
→ sys.argv[0] = "flask"
→ sys.argv[1] = "db"
"""
if len(sys.argv) > 1 and sys.argv[0].endswith("flask") and sys.argv[1] == "db":
return True
return False
# ─── 条件创建应用 ───
if is_db_command():
# 数据库命令 → 使用轻量级应用
from app_factory import create_migrations_app
app = create_migrations_app()
else:
# 正常启动 → 使用完整应用
from app_factory import create_app
app = create_app()
celery = app.extensions["celery"]核心知识点总结
三个核心函数的职责划分
python
┌────────────────────────────────────────────────────────┐
│ create_flask_app_with_configs() │
├────────────────────────────────────────────────────────┤
│ ✅ 创建 Flask 实例 │
│ ✅ 加载配置 │
│ ✅ 注册钩子(before_request, after_request) │
│ ❌ 不加载扩展 │
└────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────┐
│ create_app() # 生产环境入口 │
├────────────────────────────────────────────────────────┤
│ ✅ 调用 create_flask_app_with_configs() │
│ ✅ 调用 initialize_extensions() │
│ ✅ 记录启动耗时 │
│ ✅ 返回完整应用(可直接运行) │
└────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────┐
│ create_migrations_app() # 数据库迁移专用 │
├────────────────────────────────────────────────────────┤
│ ✅ 调用 create_flask_app_with_configs() │
│ ✅ 仅加载 ext_database + ext_migrate │
│ ✅ 启动快速(~150ms) │
│ ✅ 不依赖外部服务 │
└────────────────────────────────────────────────────────┘扩展加载的关键原则
plain
原则 1: 依赖顺序
ext_redis → ext_celery
ext_storage → ext_logstore
ext_blueprints → ext_otel
原则 2: 条件加载
ext_sentry: 仅在 SENTRY_DSN 配置时启用
ext_otel: 仅在 ENABLE_OTEL=true 时启用
原则 3: 性能监控
DEBUG 模式下记录每个扩展的加载耗时
原则 4: 失败隔离
单个扩展失败不应影响其他扩展
(目前未实现,建议改进)请求生命周期钩子的作用
plain
before_request:
✅ 初始化日志上下文(trace_id, tenant_id)
✅ 防止线程池复用导致的上下文污染
✅ 为多租户系统提供数据隔离
after_request:
✅ 注入分布式追踪 ID(X-Trace-Id, X-Span-Id)
✅ 前端可通过响应头获取 trace_id
✅ 用户报错时可快速定位问题最佳实践建议
正确的扩展开发流程
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 如何添加新扩展?
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 1️⃣ 创建扩展模块:api/extensions/ext_my_service.py
def init_app(app: DifyApp):
"""初始化自定义服务"""
# 检查依赖
if "database" not in app.extensions:
raise RuntimeError("ext_my_service requires ext_database")
# 初始化逻辑
my_service = MyService(app.config)
app.extensions["my_service"] = my_service
def is_enabled() -> bool:
"""条件加载"""
return dify_config.MY_SERVICE_ENABLED
# 2️⃣ 在 app_factory.py 中导入
from extensions import ext_my_service
# 3️⃣ 添加到 extensions 列表(注意顺序!)
extensions = [
ext_database, # 先加载依赖
ext_my_service, # 再加载自己
]常见陷阱
python
# ❌ 陷阱 1: 在扩展中直接导入 app
from app import app # 错误!会导致循环导入
# ✅ 正确做法:通过 init_app 注入
def init_app(app: DifyApp):
# 在这里使用 app
# ❌ 陷阱 2: 在 before_request 中执行耗时操作
@app.before_request
def before_request():
time.sleep(5) # 错误!会阻塞所有请求
# ✅ 正确做法:仅做轻量级初始化
@app.before_request
def before_request():
init_request_context() # 轻量级操作
# ❌ 陷阱 3: 扩展加载顺序错误
extensions = [
ext_celery, # 依赖 Redis
ext_redis, # 但 Redis 在后面!
]
# ✅ 正确顺序:先加载依赖
extensions = [
ext_redis,
ext_celery,
]Flask应用工厂create_app() 与 workflow创建_create_or_update_app()区别
整体流程:
python
启动服务器
↓
调用 create_app() ← 创建 Flask 应用容器
↓
初始化数据库/Redis/API路由
↓
服务器开始运行,等待用户请求
↓
用户上传 YAML 文件导入应用
↓
调用 AppDslService.import_app()
↓
调用 _create_or_update_app() ← 创建业务应用记录
↓
保存到数据库(使用 create_app() 初始化的数据库连接)具体对比:
| 对比维度 | create_app() |
_create_or_update_app() |
|---|---|---|
| 层次 | 系统基础设施层 | 业务逻辑层 |
| 返回类型 | DifyApp(Flask应用) |
App(数据库模型) |
| 调用次数 | 启动时调用1次 | 每次导入应用都会调用 |
| 作用范围 | 整个后端服务 | 单个业务应用 |
| 初始化内容 | 数据库连接、Redis、Celery、API路由 | 应用名称、工作流配置、模型设置 |
| 谁调用它 | app.py(启动脚本) |
AppDslService.import_app() |
| 依赖关系 | 不依赖业务逻辑 | 依赖于 create_app() 已经初始化好的数据库 |
| 类比 | 建造整栋大楼 | 在大楼里注册一家公司 |
Workflow 模型(DSL持久化)
模型概览与数据库设计
数据库表结构
sql
CREATE TABLE workflows (
-- 🔑 主键
id UUID PRIMARY KEY,
-- 🏢 多租户隔离
tenant_id UUID NOT NULL,
app_id UUID NOT NULL,
-- 📌 类型与版本
type VARCHAR(255) NOT NULL, -- 'workflow' | 'chat' | 'rag-pipeline'
version VARCHAR(255) NOT NULL, -- 'draft' | 'v1' | 'v2' ...
-- 📝 版本标记(仅发布版本有值)
marked_name VARCHAR(255) DEFAULT '',
marked_comment VARCHAR(255) DEFAULT '',
-- 🎯 核心数据(JSON 存储)
graph TEXT NOT NULL, -- DSL JSON
features TEXT, -- 功能配置
environment_variables TEXT DEFAULT '{}',
conversation_variables TEXT DEFAULT '{}',
rag_pipeline_variables TEXT DEFAULT '{}',
-- 👤 审计字段
created_by UUID NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_by UUID,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-- 📇 索引
INDEX workflow_version_idx (tenant_id, app_id, version)
);关键字段说明
| 字段 | 类型 | 用途 | 示例值 |
|---|---|---|---|
graph |
TEXT | DSL JSON 核心存储 | {"nodes": [...], "edges": [...]} |
version |
VARCHAR | 版本标识 | "draft" / "v1" / "v2" |
features |
TEXT | 功能配置 | {"file_upload": {...}} |
unique_hash |
计算属性 | 冲突检测 | SHA256(graph + features + ...) |
DSL 持久化核心字段
graph 字段 - DSL JSON 存储
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 字段定义
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
graph: Mapped[str] = mapped_column(LongText)
"""
【存储内容】前端 Canvas 生成的完整 JSON DSL
【JSON 结构】
{
"nodes": [ # 节点列表
{
"id": "start",
"type": "start",
"position": {"x": 100, "y": 100},
"data": {
"type": "start",
"title": "开始",
"variables": [...]
}
},
{
"id": "llm-1",
"type": "llm",
"data": {
"model": {"provider": "openai", "name": "gpt-4"},
"prompt_template": [...]
}
}
],
"edges": [ # 边列表(定义节点连接)
{"source": "start", "target": "llm-1"}
],
"viewport": {"x": 0, "y": 0, "zoom": 1}
}
【为何用 LongText 而非 JSONB】
✅ 跨数据库兼容(PostgreSQL/MySQL/TiDB)
✅ Dify 不需要查询 JSON 内部字段(总是全量读取)
✅ 简单直观,无需处理 JSONB 序列化
"""创建工作流 - Workflow.new()
工厂方法详解
python
@classmethod
def new(
cls,
*,
tenant_id: str, # 租户 ID(多租户隔离)
app_id: str, # 应用 ID
type: str, # 'workflow' | 'chat' | 'rag-pipeline'
version: str, # 'draft' | 'v1' | 'v2' ...
graph: str, # ⭐ JSON 字符串(前端传递)
features: str, # 功能配置 JSON
created_by: str, # 创建者 UUID
environment_variables: Sequence[Variable],
conversation_variables: Sequence[Variable],
rag_pipeline_variables: list[dict],
marked_name: str = "",
marked_comment: str = "",
) -> Workflow:
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
创建新的 Workflow 实例
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【使用场景】
1️⃣ 用户首次创建工作流 → version="draft"
2️⃣ 发布工作流 → version="v1"(复制 draft 创建新记录)
3️⃣ 从模板创建 → graph 来自模板库
【返回】
未持久化的 Workflow 实例(需调用 db.session.add + commit)
【注意】
- graph 必须是 JSON 字符串,不是 dict
- 创建后需要手动 db.session.add(workflow)
"""
workflow = Workflow()
workflow.id = str(uuid4())
workflow.tenant_id = tenant_id
workflow.app_id = app_id
workflow.type = type
workflow.version = version
workflow.graph = graph # ⭐ 直接存储 JSON 字符串
workflow.features = features
workflow.created_by = created_by
# 变量赋值
workflow.environment_variables = environment_variables or []
workflow.conversation_variables = conversation_variables or []
workflow.rag_pipeline_variables = rag_pipeline_variables or []
# 版本标记
workflow.marked_name = marked_name
workflow.marked_comment = marked_comment
# 时间戳
workflow.created_at = naive_utc_now()
workflow.updated_at = workflow.created_at
return workflowGraph 数据访问 - graph_dict
动态 JSON 解析属性
python
@property
def graph_dict(self) -> Mapping[str, Any]:
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
将 graph 字段(JSON 字符串)动态解析为字典
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【返回结构】
{
"nodes": [{"id": "start", "data": {...}}, ...],
"edges": [{"source": "start", "target": "llm-1"}],
"viewport": {"x": 0, "y": 0, "zoom": 1}
}
【为何不用 @cached_property】
⚠️ 某些代码会修改返回的 dict(如 Iteration 单步调试)
⚠️ 使用缓存会导致意外副作用:
- Iteration 节点修改 graph_dict 影响其他地方
- 错误:"Root node id xxx not found in the graph"
【性能考量】
✅ JSON 解析耗时:~1ms(10KB JSON)
✅ 访问频率:每个工作流执行 1-2 次
❌ 不值得引入缓存的复杂度
【调用场景】
1. GraphEngine.parse() - 构建 DAG
2. get_node_config_by_id() - 获取节点配置
3. walk_nodes() - 遍历所有节点
"""
return json.loads(self.graph) if self.graph else {}为何不使用缓存的实际案例
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景:Iteration 节点单步调试
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 第一次调用(获取原始 graph)
graph1 = workflow.graph_dict
# graph1 = {"nodes": [{"id": "start"}, {"id": "iteration-1"}]}
# Iteration 节点执行时,修改了 graph_dict
graph1["nodes"].append({"id": "1748401971780start"})
# ⚠️ 如果使用 @cached_property,这个修改会被缓存
# 第二次调用(期望获取原始 graph)
graph2 = workflow.graph_dict
# ❌ 如果有缓存:graph2 包含临时节点(错误)
# ✅ 无缓存:graph2 是原始数据(正确)
# 结果:
# ❌ 有缓存 → "Root node id 1748401971780start not found in the graph"
# ✅ 无缓存 → 正常执行节点查询与遍历
get_node_config_by_id() - 查询单个节点
python
def get_node_config_by_id(self, node_id: str) -> Mapping[str, Any]:
"""
通过节点 ID 获取完整配置
【参数】
- node_id: 如 "start", "llm-1", "http-2"
【返回】
{
"id": "llm-1",
"type": "llm",
"position": {"x": 300, "y": 100},
"data": {
"type": "llm",
"title": "LLM",
"model": {"provider": "openai", "name": "gpt-4"},
"prompt_template": [...]
}
}
【异常】
- WorkflowDataError: Graph 为空或格式错误
- NodeNotFoundError: 节点 ID 不存在
"""
workflow_graph = self.graph_dict
if not workflow_graph:
raise WorkflowDataError(f"workflow graph not found, workflow_id={self.id}")
nodes = workflow_graph.get("nodes")
if not nodes:
raise WorkflowDataError("nodes not found in workflow graph")
try:
# 使用 filter + next 查找(O(n) 复杂度)
node_config: dict[str, Any] = next(
filter(lambda node: node["id"] == node_id, nodes)
)
except StopIteration:
raise NodeNotFoundError(node_id)
return node_configwalk_nodes() - 遍历所有节点
python
def walk_nodes(
self,
specific_node_type: NodeType | None = None
) -> Generator[tuple[str, Mapping[str, Any]], None, None]:
"""
遍历工作流节点(生成器模式)
【参数】
- specific_node_type: 可选,仅遍历特定类型
【返回】
生成器,每次返回 (node_id, node_data)
【示例用法】
# 遍历所有 LLM 节点
for node_id, node_data in workflow.walk_nodes(NodeType.LLM):
print(f"模型: {node_data['model']['name']}")
# 遍历所有节点
for node_id, node_data in workflow.walk_nodes():
print(f"节点类型: {node_data['type']}")
"""
graph_dict = self.graph_dict
if "nodes" not in graph_dict:
raise WorkflowDataError("nodes not found in workflow graph")
if specific_node_type:
yield from (
(node["id"], node["data"])
for node in graph_dict["nodes"]
if node["data"]["type"] == specific_node_type.value
)
else:
yield from ((node["id"], node["data"]) for node in graph_dict["nodes"])!!!版本冲突检测 - unique_hash
Hash 生成逻辑
python
@property
def unique_hash(self) -> str:
"""
生成工作流的唯一 Hash(用于版本冲突检测)
【生成算法】
Hash = SHA256(graph + features + environment_variables + conversation_variables)
【用途】
1. 前端保存前计算 Hash
2. 后端接收请求时对比 Hash
3. Hash 不匹配 → 版本冲突 → 拒绝保存
【实现】
entity_values = [
self.graph, # DSL JSON
self._features, # 功能配置
self._environment_variables, # 环境变量
self._conversation_variables, # 对话变量
]
entity_text = "".join(entity_values)
return helper.generate_text_hash(entity_text) # SHA256
"""
entity_values = [
self.graph,
self._features,
self._environment_variables,
self._conversation_variables,
]
entity_text = "".join(entity_values)
return helper.generate_text_hash(entity_text)Hash 冲突的实际代码
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# WorkflowService.sync_draft_workflow() 中的校验逻辑
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def sync_draft_workflow(self, app_model, graph, unique_hash, ...):
# 1️⃣ 获取当前 Draft 工作流
workflow = self.get_draft_workflow(app_model)
# 2️⃣ 🔥 Hash 校验(核心防护)
if unique_hash and workflow.unique_hash != unique_hash:
raise WorkflowHashNotEqualError(
"Workflow version conflict detected. "
"Please refresh and retry."
)
# 3️⃣ 更新 Graph
workflow.graph = json.dumps(graph)
# 4️⃣ 重新计算 Hash
# 此时 workflow.unique_hash 会自动更新(@property 动态计算)
new_hash = workflow.unique_hash
# 5️⃣ 持久化
workflow.updated_at = naive_utc_now()
workflow.updated_by = current_user.id
db.session.commit()
return new_hashCelery 任务队列深度解析 - 任务分发与执行
Celery 架构概览
核心组件说明
| 组件 | 职责 | 部署方式 |
|---|---|---|
| Flask API | 接收请求,分发任务 | Gunicorn Worker |
| Redis Broker | 任务队列存储 | Redis 服务器 |
| Celery Worker | 消费队列,执行任务 | celery -A celery_worker worker |
| Celery Beat | 定时任务调度 | celery -A celery_worker beat |
| PostgreSQL | 持久化任务结果 | PostgreSQL 服务器 |
Celery 初始化 - ext_celery.py
完整注释版代码
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ext_celery.py - Celery 任务队列初始化模块
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心职责】
1. 初始化 Celery 应用实例
2. 配置 Redis 作为 Broker 和 Backend
3. 注册任务模块(task imports)
4. 配置定时任务(Celery Beat Schedule)
5. 支持 Redis Sentinel 和 SSL 连接
【架构设计】
- Broker: Redis(任务队列存储)
- Backend: Redis(任务结果存储)
- Worker: Gevent 协程模式
- Beat: 定时任务调度器
【关键配置】
- CELERY_BROKER_URL: redis://localhost:6379/1
- 队列: dataset, priority_dataset, trigger
- 定时任务: 清理缓存、数据备份、插件更新等
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# SSL 配置构建器
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def _get_celery_ssl_options() -> dict[str, Any] | None:
"""
获取 Celery Broker/Backend 的 SSL 配置
【应用场景】
- 生产环境 Redis 启用 TLS/SSL 加密
- 云服务商(AWS ElastiCache、阿里云 Redis)强制 SSL
【配置项】
- BROKER_USE_SSL: 是否启用 SSL
- REDIS_SSL_CERT_REQS: 证书验证级别
- REDIS_SSL_CA_CERTS: CA 证书路径
- REDIS_SSL_CERTFILE: 客户端证书
- REDIS_SSL_KEYFILE: 客户端私钥
【返回】
- None: 不使用 SSL
- dict: SSL 配置字典
"""
# ─── Step 1: 检查是否启用 SSL ───
if not dify_config.BROKER_USE_SSL:
return None
# ─── Step 2: 检查 Broker 是否为 Redis ───
broker_is_redis = dify_config.CELERY_BROKER_URL and (
dify_config.CELERY_BROKER_URL.startswith("redis://") or
dify_config.CELERY_BROKER_URL.startswith("rediss://") # rediss:// 表示 SSL
)
if not broker_is_redis:
return None
# ─── Step 3: 映射证书验证级别 ───
cert_reqs_map = {
"CERT_NONE": ssl.CERT_NONE, # 不验证证书
"CERT_OPTIONAL": ssl.CERT_OPTIONAL, # 可选验证
"CERT_REQUIRED": ssl.CERT_REQUIRED, # 强制验证(生产环境推荐)
}
ssl_cert_reqs = cert_reqs_map.get(
dify_config.REDIS_SSL_CERT_REQS,
ssl.CERT_NONE
)
# ─── Step 4: 构建 SSL 配置 ───
ssl_options = {
"ssl_cert_reqs": ssl_cert_reqs,
"ssl_ca_certs": dify_config.REDIS_SSL_CA_CERTS, # CA 证书路径
"ssl_certfile": dify_config.REDIS_SSL_CERTFILE, # 客户端证书
"ssl_keyfile": dify_config.REDIS_SSL_KEYFILE, # 客户端私钥
}
return ssl_options
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Celery 应用初始化
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def init_app(app: DifyApp) -> Celery:
"""
初始化 Celery 应用实例
【执行流程】
1️⃣ 定义自定义 Task 类(继承 Flask 上下文)
2️⃣ 创建 Celery 实例(配置 Broker/Backend)
3️⃣ 配置 Celery 参数(日志、时区、SSL 等)
4️⃣ 注册任务模块(imports)
5️⃣ 配置定时任务(Beat Schedule)
【返回】
Celery 实例(注册到 app.extensions["celery"])
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 1: 定义自定义 Task 类
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
class FlaskTask(Task):
"""
自定义 Celery Task 类
【核心功能】
每个任务执行时自动注入 Flask 应用上下文
【为何需要】
Celery Worker 是独立进程,需要访问:
- app.config (应用配置)
- db.session (数据库会话)
- redis_client (Redis 客户端)
【类比】
类似于 Flask 的 before_request,但作用于 Celery 任务
"""
def __call__(self, *args: object, **kwargs: object) -> object:
from core.logging.context import init_request_context
# 🔥 注入 Flask 应用上下文
with app.app_context():
# 初始化日志上下文(trace_id, tenant_id)
# 确保任务日志可追踪
init_request_context()
# 执行实际任务
return self.run(*args, **kwargs)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 2: 配置 Redis Sentinel(可选)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
broker_transport_options = {}
if dify_config.CELERY_USE_SENTINEL:
"""
Redis Sentinel 高可用配置
【什么是 Sentinel】
Redis 的主从切换方案,自动故障转移
【应用场景】
生产环境 Redis 主节点挂了,自动切换到从节点
【配置示例】
CELERY_SENTINEL_MASTER_NAME = "mymaster"
CELERY_SENTINEL_SOCKET_TIMEOUT = 0.1
CELERY_SENTINEL_PASSWORD = "sentinel_password"
"""
broker_transport_options = {
"master_name": dify_config.CELERY_SENTINEL_MASTER_NAME,
"sentinel_kwargs": {
"socket_timeout": dify_config.CELERY_SENTINEL_SOCKET_TIMEOUT,
"password": dify_config.CELERY_SENTINEL_PASSWORD,
},
}
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 3: 创建 Celery 实例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
celery_app = Celery(
app.name, # 应用名称("dify")
task_cls=FlaskTask, # 🔥 使用自定义 Task 类
broker=dify_config.CELERY_BROKER_URL, # Redis Broker
backend=dify_config.CELERY_BACKEND, # Redis Backend
)
"""
【Broker vs Backend】
- Broker: 任务队列存储(接收 task.delay() 的任务)
- Backend: 任务结果存储(保存任务执行结果)
【典型配置】
CELERY_BROKER_URL = "redis://localhost:6379/1"
CELERY_BACKEND = "redis" # 或 "redis://localhost:6379/2"
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 4: 配置 Celery 参数
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
celery_app.conf.update(
result_backend=dify_config.CELERY_RESULT_BACKEND,
broker_transport_options=broker_transport_options,
# ─── 连接配置 ───
broker_connection_retry_on_startup=True, # 启动时自动重连
# ─── 日志配置 ───
worker_log_format=dify_config.LOG_FORMAT,
worker_task_log_format=dify_config.LOG_FORMAT,
worker_hijack_root_logger=False, # 不劫持 root logger
# ─── 时区配置 ───
timezone=pytz.timezone(dify_config.LOG_TZ or "UTC"),
# ─── 性能优化 ───
task_ignore_result=True, # 🔥 忽略任务结果(减少 Redis 写入)
"""
【为何忽略结果】
Dify 的 Celery 任务大多是异步写入数据库,不需要返回值
如果需要查询任务状态,直接查数据库即可
【好处】
- 减少 Redis 写入压力
- 减少网络传输
- 提升任务吞吐量
"""
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 5: 配置 SSL(如果启用)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
ssl_options = _get_celery_ssl_options()
if ssl_options:
celery_app.conf.update(
broker_use_ssl=ssl_options,
# Backend 也使用 SSL(如果是 Redis)
redis_backend_use_ssl=ssl_options if dify_config.CELERY_BACKEND == "redis" else None,
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 6: 配置日志文件(可选)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
if dify_config.LOG_FILE:
celery_app.conf.update(
worker_logfile=dify_config.LOG_FILE,
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 7: 设置为默认 Celery 实例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
celery_app.set_default()
app.extensions["celery"] = celery_app
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 8: 注册任务模块
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
imports = [
"tasks.async_workflow_tasks", # 异步工作流任务
"tasks.trigger_processing_tasks", # Trigger 处理任务
]
"""
【imports 作用】
Celery Worker 启动时会导入这些模块
→ 注册模块中定义的 @shared_task
→ Worker 才能识别并执行这些任务
【类比】
类似于 Flask 的 Blueprint 注册
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 9: 配置定时任务(Celery Beat Schedule)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
day = dify_config.CELERY_BEAT_SCHEDULER_TIME # 定时任务执行间隔(天)
beat_schedule = {}
# ─── 定时任务 1: 清理 Embedding 缓存 ───
if dify_config.ENABLE_CLEAN_EMBEDDING_CACHE_TASK:
imports.append("schedule.clean_embedding_cache_task")
beat_schedule["clean_embedding_cache_task"] = {
"task": "schedule.clean_embedding_cache_task.clean_embedding_cache_task",
"schedule": crontab(minute="0", hour="2", day_of_month=f"*/{day}"),
# 每隔 N 天的凌晨 2 点执行
}
# ─── 定时任务 2: 清理未使用的数据集 ───
if dify_config.ENABLE_CLEAN_UNUSED_DATASETS_TASK:
imports.append("schedule.clean_unused_datasets_task")
beat_schedule["clean_unused_datasets_task"] = {
"task": "schedule.clean_unused_datasets_task.clean_unused_datasets_task",
"schedule": crontab(minute="0", hour="3", day_of_month=f"*/{day}"),
# 每隔 N 天的凌晨 3 点执行
}
# ─── 定时任务 3: 创建 TiDB Serverless 实例 ───
if dify_config.ENABLE_CREATE_TIDB_SERVERLESS_TASK:
imports.append("schedule.create_tidb_serverless_task")
beat_schedule["create_tidb_serverless_task"] = {
"task": "schedule.create_tidb_serverless_task.create_tidb_serverless_task",
"schedule": crontab(minute="0", hour="*"),
# 每小时执行一次
}
# ─── 定时任务 4: 更新 TiDB Serverless 状态 ───
if dify_config.ENABLE_UPDATE_TIDB_SERVERLESS_STATUS_TASK:
imports.append("schedule.update_tidb_serverless_status_task")
beat_schedule["update_tidb_serverless_status_task"] = {
"task": "schedule.update_tidb_serverless_status_task.update_tidb_serverless_status_task",
"schedule": timedelta(minutes=10),
# 每 10 分钟执行一次
}
# ─── 定时任务 5: 清理历史消息 ───
if dify_config.ENABLE_CLEAN_MESSAGES:
imports.append("schedule.clean_messages")
beat_schedule["clean_messages"] = {
"task": "schedule.clean_messages.clean_messages",
"schedule": crontab(minute="0", hour="4", day_of_month=f"*/{day}"),
# 每隔 N 天的凌晨 4 点执行
}
# ─── 定时任务 6: 发送文档清理通知邮件 ───
if dify_config.ENABLE_MAIL_CLEAN_DOCUMENT_NOTIFY_TASK:
imports.append("schedule.mail_clean_document_notify_task")
beat_schedule["mail_clean_document_notify_task"] = {
"task": "schedule.mail_clean_document_notify_task.mail_clean_document_notify_task",
"schedule": crontab(minute="0", hour="10", day_of_week="1"),
# 每周一上午 10 点执行
}
# ─── 定时任务 7: 数据集队列监控 ───
if dify_config.ENABLE_DATASETS_QUEUE_MONITOR:
imports.append("schedule.queue_monitor_task")
beat_schedule["datasets-queue-monitor"] = {
"task": "schedule.queue_monitor_task.queue_monitor_task",
"schedule": timedelta(minutes=dify_config.QUEUE_MONITOR_INTERVAL or 30),
# 每 30 分钟执行一次
}
# ─── 定时任务 8: 检查插件更新 ───
if dify_config.ENABLE_CHECK_UPGRADABLE_PLUGIN_TASK and dify_config.MARKETPLACE_ENABLED:
imports.append("schedule.check_upgradable_plugin_task")
imports.append("tasks.process_tenant_plugin_autoupgrade_check_task")
beat_schedule["check_upgradable_plugin_task"] = {
"task": "schedule.check_upgradable_plugin_task.check_upgradable_plugin_task",
"schedule": crontab(minute="*/15"),
# 每 15 分钟执行一次
}
# ─── 定时任务 9: 清理工作流运行日志 ───
if dify_config.WORKFLOW_LOG_CLEANUP_ENABLED:
imports.append("schedule.clean_workflow_runlogs_precise")
beat_schedule["clean_workflow_runlogs_precise"] = {
"task": "schedule.clean_workflow_runlogs_precise.clean_workflow_runlogs_precise",
"schedule": crontab(minute="0", hour="2"),
# 每天凌晨 2 点执行
}
# ─── 定时任务 10: 工作流定时调度轮询 ───
if dify_config.ENABLE_WORKFLOW_SCHEDULE_POLLER_TASK:
imports.append("schedule.workflow_schedule_task")
beat_schedule["workflow_schedule_task"] = {
"task": "schedule.workflow_schedule_task.poll_workflow_schedules",
"schedule": timedelta(minutes=dify_config.WORKFLOW_SCHEDULE_POLLER_INTERVAL),
# 每隔指定分钟执行一次
}
# ─── 定时任务 11: Trigger 提供商刷新 ───
if dify_config.ENABLE_TRIGGER_PROVIDER_REFRESH_TASK:
imports.append("schedule.trigger_provider_refresh_task")
beat_schedule["trigger_provider_refresh"] = {
"task": "schedule.trigger_provider_refresh_task.trigger_provider_refresh",
"schedule": timedelta(minutes=dify_config.TRIGGER_PROVIDER_REFRESH_INTERVAL),
# 每隔指定分钟执行一次
}
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Step 10: 更新 Celery 配置
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
celery_app.conf.update(
beat_schedule=beat_schedule, # 定时任务配置
imports=imports, # 任务模块导入
)
return celery_app任务定义 - @shared_task 装饰器
任务定义详解
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
任务定义模块 - api/tasks/document_indexing_task.py
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心装饰器】
@shared_task: Celery 任务装饰器
- 将普通函数转换为 Celery 任务
- 支持异步执行(.delay() 方法)
- 自动注入 Flask 应用上下文
【队列分配】
queue="dataset": 指定任务投递到哪个队列
- dataset: 普通优先级队列
- priority_dataset: 高优先级队列
- trigger: Trigger 专用队列
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 任务 1: 文档索引(普通队列)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@shared_task(queue="dataset")
def normal_document_indexing_task(tenant_id: str, dataset_id: str, document_ids: Sequence[str]):
"""
普通优先级文档索引任务
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【装饰器参数】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@shared_task(queue="dataset")
- shared_task: Celery 提供的任务装饰器
- queue="dataset": 指定任务投递到 dataset 队列
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【任务参数】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- tenant_id: 租户 ID(多租户隔离)
- dataset_id: 数据集 ID
- document_ids: 文档 ID 列表
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 查询数据集和文档
2. 检查租户配额(文档数量、向量空间)
3. 更新文档状态为 "parsing"
4. 调用 IndexingRunner 执行索引
- 文档分段 (Splitter)
- Embedding 向量化
- 写入 pgvector
5. 更新文档状态为 "completed"
6. 检查租户队列是否有待处理任务
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调用方式】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Flask Controller 中调用
normal_document_indexing_task.delay(
tenant_id="tenant-123",
dataset_id="dataset-456",
document_ids=["doc-1", "doc-2"]
)
# 🔥 .delay() 方法会:
# 1. 将任务序列化为 JSON
# 2. 推送到 Redis 的 dataset 队列
# 3. 立即返回(不阻塞 Flask Worker)
# 4. Celery Worker 从队列取出任务并执行
"""
logger.info("normal document indexing task received: %s - %s - %s",
tenant_id, dataset_id, document_ids)
# 调用租户隔离队列处理函数
_document_indexing_with_tenant_queue(
tenant_id,
dataset_id,
document_ids,
normal_document_indexing_task # 🔥 传递自身,用于递归调用
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 任务 2: 文档索引(优先队列)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@shared_task(queue="priority_dataset")
def priority_document_indexing_task(tenant_id: str, dataset_id: str, document_ids: Sequence[str]):
"""
高优先级文档索引任务
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【与普通任务的区别】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- 队列: priority_dataset(优先级更高)
- 使用场景: VIP 租户、付费用户
- Worker 分配: 可以配置专用 Worker 处理此队列
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【Worker 配置示例】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Worker 1: 仅处理优先队列
celery -A celery_worker worker -Q priority_dataset --concurrency=10
# Worker 2: 处理普通队列
celery -A celery_worker worker -Q dataset --concurrency=20
# 这样可以保证 VIP 用户的任务优先执行
"""
logger.info("priority document indexing task received: %s - %s - %s",
tenant_id, dataset_id, document_ids)
_document_indexing_with_tenant_queue(
tenant_id,
dataset_id,
document_ids,
priority_document_indexing_task
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 核心执行函数:文档索引
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def _document_indexing(dataset_id: str, document_ids: Sequence[str]):
"""
文档索引核心逻辑
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行步骤】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1️⃣ 查询数据集和文档
2️⃣ 检查租户配额限制
3️⃣ 更新文档状态为 "parsing"
4️⃣ 调用 IndexingRunner 执行索引
5️⃣ 处理异常和日志
"""
documents = []
start_at = time.perf_counter()
# ─── Step 1: 查询数据集 ───
dataset = db.session.query(Dataset).where(Dataset.id == dataset_id).first()
if not dataset:
logger.info(click.style(f"Dataset is not found: {dataset_id}", fg="yellow"))
db.session.close()
return
# ─── Step 2: 检查租户配额 ───
features = FeatureService.get_features(dataset.tenant_id)
try:
if features.billing.enabled:
vector_space = features.vector_space
count = len(document_ids)
batch_upload_limit = int(dify_config.BATCH_UPLOAD_LIMIT)
# 检查 Sandbox 计划是否支持批量上传
if features.billing.subscription.plan == CloudPlan.SANDBOX and count > 1:
raise ValueError("Your current plan does not support batch upload, please upgrade your plan.")
# 检查批量上传数量限制
if count > batch_upload_limit:
raise ValueError(f"You have reached the batch upload limit of {batch_upload_limit}.")
# 检查向量空间配额
if 0 < vector_space.limit <= vector_space.size:
raise ValueError(
"Your total number of documents plus the number of uploads have over the limit of "
"your subscription."
)
except Exception as e:
# 配额检查失败,标记所有文档为 error
for document_id in document_ids:
document = (
db.session.query(Document)
.where(Document.id == document_id, Document.dataset_id == dataset_id)
.first()
)
if document:
document.indexing_status = "error"
document.error = str(e)
document.stopped_at = naive_utc_now()
db.session.add(document)
db.session.commit()
db.session.close()
return
# ─── Step 3: 更新文档状态为 parsing ───
for document_id in document_ids:
logger.info(click.style(f"Start process document: {document_id}", fg="green"))
document = (
db.session.query(Document)
.where(Document.id == document_id, Document.dataset_id == dataset_id)
.first()
)
if document:
document.indexing_status = "parsing" # 🔥 状态变更
document.processing_started_at = naive_utc_now()
documents.append(document)
db.session.add(document)
db.session.commit()
# ─── Step 4: 执行索引 ───
try:
indexing_runner = IndexingRunner()
indexing_runner.run(documents)
"""
【IndexingRunner 执行流程】
1. 文档解析(PDF/DOCX/TXT)
2. 文档分段(智能切分)
3. Embedding 向量化(调用 OpenAI/本地模型)
4. 写入 pgvector(PostgreSQL 向量存储)
5. 更新文档状态为 "completed"
"""
end_at = time.perf_counter()
logger.info(click.style(
f"Processed dataset: {dataset_id} latency: {end_at - start_at}",
fg="green"
))
except DocumentIsPausedError as ex:
logger.info(click.style(str(ex), fg="yellow"))
except Exception:
logger.exception("Document indexing task failed, dataset_id: %s", dataset_id)
finally:
db.session.close()
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 租户隔离队列处理
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def _document_indexing_with_tenant_queue(
tenant_id: str,
dataset_id: str,
document_ids: Sequence[str],
task_func: Callable[[str, str, Sequence[str]], None]
):
"""
带租户隔离队列的文档索引
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【租户隔离原理】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
问题:如果租户 A 提交了 1000 个文档索引任务,会占满整个队列
导致租户 B 的任务无法执行(饥饿问题)
解决方案:每个租户维护独立的等待队列(Redis List)
- 租户 A 的任务在 Redis Key: tenant:A:document_indexing
- 租户 B 的任务在 Redis Key: tenant:B:document_indexing
- 每个租户同时只能有 N 个任务在 Celery 队列中执行
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 执行当前任务
2. 任务完成后,检查租户队列是否有待处理任务
3. 如果有,从队列取出 N 个任务继续执行
4. 如果没有,清理租户队列标记
"""
try:
# ─── Step 1: 执行当前任务 ───
_document_indexing(dataset_id, document_ids)
except Exception:
logger.exception(
"Error processing document indexing %s for tenant %s: %s",
dataset_id, tenant_id, document_ids,
exc_info=True,
)
finally:
# ─── Step 2: 处理租户队列 ───
tenant_isolated_task_queue = TenantIsolatedTaskQueue(tenant_id, "document_indexing")
# 从租户队列取出待处理任务
next_tasks = tenant_isolated_task_queue.pull_tasks(
count=dify_config.TENANT_ISOLATED_TASK_CONCURRENCY # 默认 5 个
)
logger.info("document indexing tenant isolation queue %s next tasks: %s",
tenant_id, next_tasks)
if next_tasks:
# ─── Step 3: 继续执行待处理任务 ───
for next_task in next_tasks:
document_task = DocumentTask(**next_task)
# 更新任务等待时间
tenant_isolated_task_queue.set_task_waiting_time()
# 🔥 递归调用,投递到 Celery 队列
task_func.delay(
tenant_id=document_task.tenant_id,
dataset_id=document_task.dataset_id,
document_ids=document_task.document_ids,
)
else:
# ─── Step 4: 无待处理任务,清理标记 ───
tenant_isolated_task_queue.delete_task_key()4. 任务分发点 - delay() 调用
任务分发详解
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
任务分发点 - Flask Controller 调用 Celery 任务
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【关键方法】
task.delay(*args, **kwargs)
【底层实现】
delay() 是 apply_async() 的快捷方式
task.delay(a, b) 等价于 task.apply_async(args=(a, b))
【执行流程】
1. 序列化任务参数(JSON)
2. 生成任务 ID(UUID)
3. 推送到 Redis 队列
4. 立即返回(不等待任务执行)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 示例 1: 文档上传后触发索引任务
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# api/controllers/console/datasets/documents.py
from flask import request
from flask_restx import Resource
from tasks.document_indexing_task import normal_document_indexing_task
class DocumentListApi(Resource):
def post(self, dataset_id):
"""
上传文档到数据集
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 接收上传的文件
2. 保存文件到对象存储(S3/本地)
3. 创建 Document 记录(status="pending")
4. 🔥 调用 Celery 任务进行索引
5. 立即返回响应(不等待索引完成)
"""
# ─── Step 1-2: 处理文件上传 ───
file = request.files['file']
file_url = upload_to_storage(file)
# ─── Step 3: 创建 Document 记录 ───
document = Document(
id=str(uuid4()),
dataset_id=dataset_id,
tenant_id=current_user.current_tenant_id,
data_source_type="upload_file",
indexing_status="pending", # 初始状态
file_url=file_url,
)
db.session.add(document)
db.session.commit()
# ─── Step 4: 🔥 分发 Celery 任务 ───
normal_document_indexing_task.delay(
tenant_id=current_user.current_tenant_id,
dataset_id=dataset_id,
document_ids=[document.id],
)
"""
【delay() 执行流程】
1️⃣ 序列化参数
{
"tenant_id": "tenant-123",
"dataset_id": "dataset-456",
"document_ids": ["doc-789"]
}
2️⃣ 生成任务 ID
task_id = "a1b2c3d4-e5f6-7890-abcd-1234567890ab"
3️⃣ 推送到 Redis
LPUSH dataset:queue {
"id": "a1b2c3d4...",
"task": "tasks.document_indexing_task.normal_document_indexing_task",
"args": [],
"kwargs": {...},
"eta": null
}
4️⃣ 立即返回
返回值: AsyncResult 对象(不阻塞)
"""
# ─── Step 5: 立即返回响应 ───
return {
"document_id": document.id,
"indexing_status": "pending",
"message": "Document uploaded, indexing in progress"
}, 202 # 202 Accepted多队列隔离机制
队列设计原理
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Dify 的多队列隔离设计
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【队列列表】
┌────────────────────┬──────────────┬────────────────────────┐
│ 队列名称 │ 优先级 │ 用途 │
├────────────────────┼──────────────┼────────────────────────┤
│ dataset │ 普通 │ 免费用户文档索引 │
│ priority_dataset │ 高 │ VIP 用户文档索引 │
│ trigger │ 普通 │ Webhook/Schedule 触发 │
│ mail │ 低 │ 邮件发送 │
└────────────────────┴──────────────┴────────────────────────┘
【Worker 分配策略】
Worker 1: -Q priority_dataset --concurrency=10 # 专门处理 VIP
Worker 2: -Q dataset --concurrency=20 # 处理普通用户
Worker 3: -Q trigger --concurrency=5 # 处理 Trigger
Worker 4: -Q mail --concurrency=2 # 处理邮件
【隔离优势】
✅ 避免单一队列被占满
✅ VIP 用户享受优先服务
✅ 不同类型任务独立处理
✅ 故障隔离(邮件队列故障不影响文档索引)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 队列定义示例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 普通队列任务
@shared_task(queue="dataset")
def normal_document_indexing_task(...):
pass
# 优先队列任务
@shared_task(queue="priority_dataset")
def priority_document_indexing_task(...):
pass
# Trigger 队列任务
@shared_task(queue="trigger")
def async_workflow_trigger_task(...):
pass
# 邮件队列任务
@shared_task(queue="mail")
def send_notification_email(...):
pass
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 动态队列选择(根据用户类型)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def dispatch_document_indexing(tenant_id, dataset_id, document_ids):
"""
根据用户类型选择队列
【策略】
- VIP 用户 → priority_dataset
- 免费用户 → dataset
"""
# 查询租户类型
tenant = db.session.get(Tenant, tenant_id)
if tenant.is_vip:
# 🔥 VIP 用户使用优先队列
priority_document_indexing_task.delay(
tenant_id, dataset_id, document_ids
)
else:
# 免费用户使用普通队列
normal_document_indexing_task.delay(
tenant_id, dataset_id, document_ids
)租户隔离队列
租户隔离原理
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
租户隔离队列 - TenantIsolatedTaskQueue
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【问题场景】
租户 A 提交了 1000 个文档索引任务,全部进入 dataset 队列
→ Celery Worker 被租户 A 的任务占满
→ 租户 B 的任务需要等待很久(饥饿问题)
【解决方案】
为每个租户维护独立的等待队列(Redis List)
- 限制每个租户同时在 Celery 队列中的任务数量
- 超出限制的任务进入租户专属等待队列
- 任务完成后,自动从等待队列取出新任务
【数据结构】
Redis Key: tenant:{tenant_id}:document_indexing:queue
Redis Type: List (FIFO 队列)
【并发控制】
TENANT_ISOLATED_TASK_CONCURRENCY = 5
每个租户最多同时有 5 个任务在 Celery 队列中执行
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 租户隔离队列实现(简化版)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
from extensions.ext_redis import redis_client
from configs import dify_config
class TenantIsolatedTaskQueue:
"""
租户隔离任务队列
【核心方法】
- push_task: 将任务推入租户队列
- pull_tasks: 从租户队列取出任务
- set_task_waiting_time: 更新任务等待时间
- delete_task_key: 清理租户队列标记
"""
def __init__(self, tenant_id: str, task_type: str):
"""
初始化租户队列
【参数】
- tenant_id: 租户 ID
- task_type: 任务类型(如 "document_indexing")
【Redis Key 设计】
tenant:{tenant_id}:document_indexing:queue
tenant:{tenant_id}:document_indexing:running_count
tenant:{tenant_id}:document_indexing:last_update
"""
self.tenant_id = tenant_id
self.task_type = task_type
# Redis Key 前缀
self.queue_key = f"tenant:{tenant_id}:{task_type}:queue"
self.running_count_key = f"tenant:{tenant_id}:{task_type}:running_count"
self.last_update_key = f"tenant:{tenant_id}:{task_type}:last_update"
def push_task(self, task_data: dict) -> bool:
"""
推送任务到租户队列
【执行流程】
1. 检查当前运行任务数
2. 如果未超限,直接投递到 Celery 队列
3. 如果超限,推入租户等待队列
【返回】
- True: 直接投递到 Celery
- False: 推入等待队列
"""
# ─── Step 1: 获取当前运行任务数 ───
running_count = redis_client.get(self.running_count_key)
running_count = int(running_count) if running_count else 0
# ─── Step 2: 检查是否超限 ───
max_concurrency = dify_config.TENANT_ISOLATED_TASK_CONCURRENCY # 默认 5
if running_count < max_concurrency:
# ✅ 未超限,增加计数
redis_client.incr(self.running_count_key)
redis_client.expire(self.running_count_key, 3600) # 1 小时过期
return True # 可以直接投递
else:
# ❌ 已超限,推入等待队列
redis_client.lpush(self.queue_key, json.dumps(task_data))
redis_client.expire(self.queue_key, 86400) # 24 小时过期
return False # 需要等待
def pull_tasks(self, count: int = 5) -> list[dict]:
"""
从租户队列取出任务
【参数】
- count: 取出任务数量
【返回】
任务数据列表
"""
tasks = []
for _ in range(count):
# 从队列右侧取出(FIFO)
task_data = redis_client.rpop(self.queue_key)
if not task_data:
break
tasks.append(json.loads(task_data))
return tasks
def set_task_waiting_time(self):
"""
更新任务等待时间
【用途】
记录最后一次任务执行时间,用于监控
"""
redis_client.set(
self.last_update_key,
int(time.time()),
ex=3600 # 1 小时过期
)
def delete_task_key(self):
"""
清理租户队列标记
【执行时机】
当租户队列为空时,清理运行计数
"""
redis_client.delete(self.running_count_key)
redis_client.delete(self.last_update_key)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 使用示例:Controller 层
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def upload_document(tenant_id: str, dataset_id: str, document_ids: list[str]):
"""
上传文档并触发索引
【流程】
1. 检查租户队列是否超限
2. 如果未超限,直接投递到 Celery
3. 如果超限,推入租户等待队列
"""
# 创建租户队列实例
tenant_queue = TenantIsolatedTaskQueue(tenant_id, "document_indexing")
# 准备任务数据
task_data = {
"tenant_id": tenant_id,
"dataset_id": dataset_id,
"document_ids": document_ids,
}
# 尝试推送任务
can_run_immediately = tenant_queue.push_task(task_data)
if can_run_immediately:
# ✅ 直接投递到 Celery 队列
normal_document_indexing_task.delay(
tenant_id=tenant_id,
dataset_id=dataset_id,
document_ids=document_ids,
)
logger.info(f"Task dispatched immediately for tenant {tenant_id}")
else:
# ⏳ 推入等待队列
logger.info(f"Task queued for tenant {tenant_id}, waiting for slot")
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 使用示例:任务完成后处理
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def _document_indexing_with_tenant_queue(
tenant_id: str,
dataset_id: str,
document_ids: Sequence[str],
task_func: Callable
):
"""
带租户队列的任务执行
"""
try:
# ─── Step 1: 执行当前任务 ───
_document_indexing(dataset_id, document_ids)
finally:
# ─── Step 2: 处理租户队列 ───
tenant_queue = TenantIsolatedTaskQueue(tenant_id, "document_indexing")
# 🔥 减少运行计数
redis_client.decr(tenant_queue.running_count_key)
# 从租户队列取出待处理任务
next_tasks = tenant_queue.pull_tasks(count=5)
if next_tasks:
# 继续执行待处理任务
for next_task in next_tasks:
task_func.delay(**next_task)
else:
# 无待处理任务,清理标记
tenant_queue.delete_task_key()租户隔离的实际效果
python
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 场景对比:有无租户隔离
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ❌ 无租户隔离(会导致饥饿)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Celery 队列状态(20 个 Worker)
# [租户A-1, 租户A-2, 租户A-3, ... 租户A-1000]
# ↑ 租户 A 的 1000 个任务占满了队列
# ↓ 租户 B 的任务需要等待 1000 个任务执行完
# 租户 B 等待时间:1000 任务 × 平均 30 秒 = 8.3 小时 😱
# ✅ 有租户隔离(公平调度)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Celery 队列状态(20 个 Worker)
# [租户A-1, 租户A-2, 租户A-3, 租户A-4, 租户A-5, # 租户 A 最多 5 个
# 租户B-1, 租户B-2, 租户B-3, 租户B-4, 租户B-5, # 租户 B 最多 5 个
# 租户C-1, 租户C-2, ...]
# ↑ 每个租户最多占用 5 个 Worker
# ↓ 租户 B 的任务可以立即执行
# 租户 B 等待时间:最多等待 5 个任务 = ~2.5 分钟 ✅
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Redis 数据示例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 租户 A 的运行计数
redis> GET tenant:tenant-a:document_indexing:running_count
"5" # 当前正在执行 5 个任务
# 租户 A 的等待队列
redis> LLEN tenant:tenant-a:document_indexing:queue
(integer) 995 # 还有 995 个任务在等待
# 租户 B 的运行计数
redis> GET tenant:tenant-b:document_indexing:running_count
"2" # 当前正在执行 2 个任务
# 租户 B 的等待队列
redis> LLEN tenant:tenant-b:document_indexing:queue
(integer) 0 # 无等待任务7. 定时任务调度 - Celery Beat
Celery Beat 详解
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Celery Beat - 定时任务调度器
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【什么是 Beat】
类似于 Linux 的 cron,但运行在 Celery 生态内
【启动方式】
celery -A celery_worker beat --loglevel=info
【工作原理】
1. Beat 进程定期检查调度表(beat_schedule)
2. 到达执行时间时,将任务投递到 Celery 队列
3. Worker 从队列取出任务并执行
【存储方式】
- 内存(默认): 重启后丢失
- Redis: 持久化调度状态
- Database: 通过 django-celery-beat 存储
【Dify 的定时任务】
11 个定时任务,涵盖:
- 数据清理(缓存、消息、日志)
- 监控(队列监控)
- 维护(插件更新、TiDB 维护)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 定时任务配置(来自 ext_celery.py)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
beat_schedule = {
# ─── 任务 1: 清理 Embedding 缓存 ───
"clean_embedding_cache_task": {
"task": "schedule.clean_embedding_cache_task.clean_embedding_cache_task",
"schedule": crontab(minute="0", hour="2", day_of_month="*/7"),
# 每隔 7 天的凌晨 2:00 执行
# Cron 表达式: 0 2 */7 * *
},
# ─── 任务 2: 清理未使用的数据集 ───
"clean_unused_datasets_task": {
"task": "schedule.clean_unused_datasets_task.clean_unused_datasets_task",
"schedule": crontab(minute="0", hour="3", day_of_month="*/7"),
# 每隔 7 天的凌晨 3:00 执行
},
# ─── 任务 3: 清理历史消息 ───
"clean_messages": {
"task": "schedule.clean_messages.clean_messages",
"schedule": crontab(minute="0", hour="4", day_of_month="*/7"),
# 每隔 7 天的凌晨 4:00 执行
},
# ─── 任务 4: 发送文档清理通知邮件 ───
"mail_clean_document_notify_task": {
"task": "schedule.mail_clean_document_notify_task.mail_clean_document_notify_task",
"schedule": crontab(minute="0", hour="10", day_of_week="1"),
# 每周一上午 10:00 执行
# Cron 表达式: 0 10 * * 1
},
# ─── 任务 5: 数据集队列监控 ───
"datasets-queue-monitor": {
"task": "schedule.queue_monitor_task.queue_monitor_task",
"schedule": timedelta(minutes=30),
# 每 30 分钟执行一次
},
# ─── 任务 6: 检查插件更新 ───
"check_upgradable_plugin_task": {
"task": "schedule.check_upgradable_plugin_task.check_upgradable_plugin_task",
"schedule": crontab(minute="*/15"),
# 每 15 分钟执行一次
# Cron 表达式: */15 * * * *
},
# ─── 任务 7: 清理工作流运行日志 ───
"clean_workflow_runlogs_precise": {
"task": "schedule.clean_workflow_runlogs_precise.clean_workflow_runlogs_precise",
"schedule": crontab(minute="0", hour="2"),
# 每天凌晨 2:00 执行
# Cron 表达式: 0 2 * * *
},
# ─── 任务 8: 工作流定时调度轮询 ───
"workflow_schedule_task": {
"task": "schedule.workflow_schedule_task.poll_workflow_schedules",
"schedule": timedelta(minutes=5),
# 每 5 分钟执行一次
},
# ─── 任务 9: Trigger 提供商刷新 ───
"trigger_provider_refresh": {
"task": "schedule.trigger_provider_refresh_task.trigger_provider_refresh",
"schedule": timedelta(minutes=10),
# 每 10 分钟执行一次
},
# ─── 任务 10: 创建 TiDB Serverless 实例 ───
"create_tidb_serverless_task": {
"task": "schedule.create_tidb_serverless_task.create_tidb_serverless_task",
"schedule": crontab(minute="0", hour="*"),
# 每小时执行一次
# Cron 表达式: 0 * * * *
},
# ─── 任务 11: 更新 TiDB Serverless 状态 ───
"update_tidb_serverless_status_task": {
"task": "schedule.update_tidb_serverless_status_task.update_tidb_serverless_status_task",
"schedule": timedelta(minutes=10),
# 每 10 分钟执行一次
},
}
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 定时任务示例:清理 Embedding 缓存
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# api/schedule/clean_embedding_cache_task.py
from celery import shared_task
from extensions.ext_redis import redis_client
import logging
logger = logging.getLogger(__name__)
@shared_task
def clean_embedding_cache_task():
"""
清理 Embedding 缓存
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 扫描 Redis 中的 embedding:* 键
2. 检查最后访问时间
3. 删除超过 7 天未访问的缓存
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调度时间】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
每隔 7 天的凌晨 2:00
"""
logger.info("[Celery Beat] Starting embedding cache cleanup...")
# ─── Step 1: 扫描 Embedding 缓存键 ───
cache_keys = []
cursor = 0
while True:
cursor, keys = redis_client.scan(
cursor=cursor,
match="embedding:*",
count=100
)
cache_keys.extend(keys)
if cursor == 0:
break
logger.info(f"Found {len(cache_keys)} embedding cache keys")
# ─── Step 2: 检查并删除过期缓存 ───
deleted_count = 0
current_time = time.time()
for key in cache_keys:
# 获取最后访问时间
last_access = redis_client.object("idletime", key)
if last_access and last_access > 604800: # 7 天 = 604800 秒
redis_client.delete(key)
deleted_count += 1
logger.info(f"[Celery Beat] Cleaned {deleted_count} expired embedding caches")
return {"cleaned": deleted_count, "total": len(cache_keys)}定时任务执行时间表
plain
凌晨 2:00 - 清理 Embedding 缓存、清理工作流日志
凌晨 3:00 - 清理未使用的数据集
凌晨 4:00 - 清理历史消息
上午 10:00 (每周一) - 发送文档清理通知邮件
每 5 分钟 - 工作流定时调度轮询
每 10 分钟 - Trigger 提供商刷新、更新 TiDB 状态
每 15 分钟 - 检查插件更新
每 30 分钟 - 数据集队列监控
每小时 - 创建 TiDB Serverless 实例核心知识点总结
Celery 架构组件
plain
┌─────────────────────────────────────────────────────────┐
│ Flask API │
│ - 接收请求 │
│ - 调用 task.delay() 分发任务 │
│ - 立即返回响应(不阻塞) │
└───────────────────┬─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────┐
│ Redis Broker │
│ - 存储任务队列(dataset, priority_dataset, trigger) │
│ - FIFO 队列(List 数据结构) │
│ - 支持多队列隔离 │
└───────────────────┬─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────┐
│ Celery Worker │
│ - 从队列取出任务(BRPOP) │
│ - 注入 Flask 应用上下文 │
│ - 执行任务逻辑 │
│ - 写入结果到数据库 │
└───────────────────┬─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────┐
│ Celery Beat (可选) │
│ - 定时任务调度器 │
│ - 每分钟检查调度表 │
│ - 到期时投递任务到队列 │
└─────────────────────────────────────────────────────────┘关键设计模式
plain
1. 队列隔离: dataset / priority_dataset / trigger
2. 租户隔离: 每个租户独立等待队列
3. 优先级调度: VIP 用户专用队列
4. 故障隔离: 单个队列故障不影响其他队列
5. 异步解耦: Flask 立即返回,Celery 异步执行性能优化要点
plain
✅ task_ignore_result=True # 忽略任务结果,减少 Redis 写入
✅ 租户隔离队列 # 防止单租户占满资源
✅ 多队列分流 # 不同类型任务独立处理
✅ Worker 并发控制 # --concurrency 参数
✅ 任务批处理 # 多个文档一起索引SSE 流式输出阻塞 Flask 进程
问题场景:SSE 阻塞 Flask Worker
传统同步方案的问题
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
问题场景:工作流执行耗时 + SSE 流式输出
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【场景描述】
用户执行一个复杂工作流:
1. LLM 节点(GPT-4)→ 耗时 5 秒
2. HTTP 节点 → 耗时 3 秒
3. Code 节点 → 耗时 2 秒
总计:10 秒
前端期望:实时看到每个节点的执行状态(SSE 流式输出)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【传统同步方案】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ❌ 错误方案 1: 同步执行 + 阻塞等待
@app.route('/api/workflows/<id>/run', methods=['POST'])
def run_workflow(workflow_id):
"""
同步执行工作流(阻塞方案)
"""
def generate():
# 执行工作流(阻塞 10 秒)
for event in execute_workflow(workflow_id):
yield f"data: {json.dumps(event)}\n\n"
return Response(
generate(),
mimetype='text/event-stream'
)
"""
【问题】
1️⃣ Flask Worker 被占用 10 秒
→ Gunicorn 默认 4 个 Worker
→ 同时只能处理 4 个工作流请求
→ 第 5 个用户需要等待
2️⃣ 长时间连接占用内存
→ 每个连接占用一个 Worker
→ Worker 数量有限(通常 CPU 核心数 × 2)
3️⃣ 无法处理其他 API 请求
→ 所有 Worker 被占满
→ 其他用户的简单请求(如查询列表)也无法响应
4️⃣ 超时风险
→ Nginx 默认超时 60 秒
→ 工作流执行时间可能超过 60 秒
→ 连接中断,任务失败
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 实际后果示例
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Gunicorn 配置:4 个 Worker
# gunicorn app:app --workers 4
# 用户 A: 执行工作流(占用 Worker 1,耗时 10 秒)
# 用户 B: 执行工作流(占用 Worker 2,耗时 10 秒)
# 用户 C: 执行工作流(占用 Worker 3,耗时 10 秒)
# 用户 D: 执行工作流(占用 Worker 4,耗时 10 秒)
# 用户 E: 查询工作流列表 → ❌ 等待中... (所有 Worker 被占满)
# 用户 F: 执行工作流 → ❌ 等待中...
# 结果:系统瘫痪,无法响应新请求解耦方案架构设计
Dify 的解耦方案
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Dify 解耦方案:后台线程 + Python Queue + Redis Pub/Sub
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心思想】
Flask Worker 不直接执行工作流,而是:
1. 启动后台线程执行工作流
2. Flask Worker 仅负责监听事件队列(Python Queue)
3. 后台线程将执行事件推送到队列
4. Flask Worker 从队列取出事件,通过 SSE 返回给前端
【关键组件】
┌─────────────────────────────────────────────────────────┐
│ AppQueueManager │
│ - Python Queue: 进程内事件队列(高性能) │
│ - Redis: 存储任务状态(task_id → user_id) │
│ - 后台线程: 执行工作流,推送事件到 Queue │
│ - listen(): Flask Worker 监听队列,SSE 输出 │
└─────────────────────────────────────────────────────────┘
【优势】
✅ Flask Worker 不阻塞(仅监听队列,CPU 占用低)
✅ 后台线程执行工作流(独立于请求处理)
✅ 支持停止控制(通过 Redis 标记)
✅ 超时自动断开(APP_MAX_EXECUTION_TIME)
✅ Ping 机制(检测前端连接状态)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""时序图
plain
┌─────────────────────────────────────────────────────────────────────────────┐
│ 【前端 Browser】 │
│ │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ EventSource API (SSE Client) │ │
│ │ • 监听 /workflows/run 的 SSE 流 │ │
│ │ • 实时接收 JSON 事件:node_started, node_finished, error, ping... │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ ↑ │
│ │ HTTP/1.1 Chunked Transfer Encoding │
│ │ (Server-Sent Events) │
└───────────────────────────────┼───────────────────────────────────────────────┘
│
│
┌───────────────────────────────┼───────────────────────────────────────────────┐
│ 【Flask API Server (Gunicorn)】 │
│ │ │
│ ┌─────────────────────────────▼────────────────────────────────────┐ │
│ │ Flask Worker 1 (占用中) │ │
│ │ ┌──────────────────────────────────────────────────────────┐ │ │
│ │ │ @app.post('/workflows/run') │ │ │
│ │ │ 1. 接收请求,创建 task_id │ │ │
│ │ │ 2. 实例化 AppQueueManager(task_id, user_id) │ │ │
│ │ │ 3. 发送 Celery 任务: workflow_run_task.delay(task_id) │ │ │
│ │ │ 4. 调用 queue_manager.listen() 进入监听循环 │ │ │
│ │ │ while True: │ │ │
│ │ │ message = self._q.get(timeout=1) # 非阻塞! │ │ │
│ │ │ if message: yield message # SSE 返回 │ │ │
│ │ └──────────────────────────────────────────────────────────┘ │ │
│ │ ↑ │ │
│ │ │ queue.put(event) │ │
│ │ │ (Python Queue - 线程安全) │ │
│ └────────────────────────────┼───────────────────────────────────────┘ │
│ │ │
│ ┌─────────────────────────────┴────────────────────────────────────┐ │
│ │ Flask Worker 2-4 (空闲) │ │
│ │ • 可以处理新的 HTTP 请求 │ │
│ │ • Gunicorn 多进程模型保证并发能力 │ │
│ └────────────────────────────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────────────────┘
│
│
┌───────────────────────────────┼───────────────────────────────────────────────┐
│ 【Redis (跨进程状态同步)】 │
│ │ │
│ ┌──────────────────────────┐ │ ┌──────────────────────────────────────┐ │
│ │ generate_task_belong: │ │ │ generate_task_stopped:task_123 │ │
│ │ task_123 │ │ │ • 值: 1 │ │
│ │ • 值: account-user456 │←┼─│ • TTL: 600 秒 │ │
│ │ • TTL: 1800 秒 │ │ │ • 用途: 停止标志位 │ │
│ │ • 用途: 任务归属验证 │ │ └──────────────────────────────────────┘ │
│ └──────────────────────────┘ │ │
│ │ │
│ │ 【为什么不用 Redis Pub/Sub?】 │
│ │ • Dify 使用 Python Queue (进程内) │
│ │ • Redis 只用于跨进程状态同步 │
│ │ • 更简单,性能更好 │
└───────────────────────────────┼──────────────────────────────────────────────┘
│
│
┌───────────────────────────────┼───────────────────────────────────────────────┐
│ 【Celery Worker (后台异步执行)】 │
│ │ │
│ ┌─────────────────────────────▼────────────────────────────────────┐ │
│ │ @shared_task │ │
│ │ def workflow_run_task(task_id: str): │ │
│ │ # 1. 从 Redis 获取 AppQueueManager 实例的引用 │ │
│ │ queue_manager = get_queue_manager(task_id) │ │
│ │ │ │
│ │ # 2. 开始执行 Workflow │ │
│ │ for node in workflow.nodes: │ │
│ │ # 2.1 发送节点开始事件 │ │
│ │ queue_manager.publish( │ │
│ │ NodeStartedEvent(node_id=node.id), │ │
│ │ PublishFrom.TASK_PIPELINE │ │
│ │ ) │ │
│ │ # ↓ 内部调用 self._q.put(event) │ │
│ │ │ │
│ │ # 2.2 执行节点逻辑 (如调用 LLM API) │ │
│ │ result = node.run() │ │
│ │ │ │
│ │ # 2.3 发送节点完成事件 │ │
│ │ queue_manager.publish( │ │
│ │ NodeFinishedEvent(node_id=node.id, result=result), │ │
│ │ PublishFrom.TASK_PIPELINE │ │
│ │ ) │ │
│ │ │ │
│ │ # 2.4 检查停止标志 │ │
│ │ if queue_manager._is_stopped(): │ │
│ │ break # 用户手动停止 │ │
│ │ │ │
│ │ # 3. 发送完成事件 │ │
│ │ queue_manager.publish(WorkflowFinishedEvent(), ...) │ │
│ └────────────────────────────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────────────────┘核心组件:AppQueueManager
python
"""
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
AppQueueManager - SSE 流式输出的核心管理器
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【核心职责】
1. 管理工作流执行的事件队列(Python Queue)
2. 提供 listen() 方法供 Flask Worker 监听队列
3. 提供 publish() 方法供后台线程推送事件
4. 通过 Redis 实现停止控制
5. 支持超时自动断开
【关键设计】
- Python Queue: 进程内高性能队列(无序列化开销)
- Redis: 存储任务状态和停止标记(跨进程通信)
- TTL Cache: 本地缓存停止状态(减少 Redis 查询)
- Ping 机制: 定期发送心跳检测前端连接
【事件流转】
后台线程 → publish() → Python Queue → listen() → SSE 输出 → 前端
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 发布来源枚举
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
class PublishFrom(IntEnum):
"""
事件发布来源
【用途】
标识事件是从哪里发布的,用于调试和监控
"""
APPLICATION_MANAGER = auto() # 应用管理器发布
TASK_PIPELINE = auto() # 任务管道发布
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 核心类:AppQueueManager
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
class AppQueueManager:
"""
应用队列管理器 - SSE 流式输出的核心
【生命周期】
1. Controller 创建 AppQueueManager 实例
2. 启动后台线程执行工作流
3. Flask Worker 调用 listen() 监听队列
4. 后台线程调用 publish() 推送事件
5. listen() 将事件通过 SSE 返回给前端
6. 执行完成或超时后调用 stop_listen()
"""
def __init__(self, task_id: str, user_id: str, invoke_from: InvokeFrom):
"""
初始化队列管理器
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【参数】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- task_id: 任务唯一标识符(UUID)
- user_id: 用户 ID(用于权限验证)
- invoke_from: 调用来源(EXPLORE/DEBUGGER/API/WEB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【Redis Key 设计】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
任务归属: generate_task_belong:{task_id}
停止标记: generate_task_stopped:{task_id}
【为何需要任务归属】
防止用户 A 停止用户 B 的任务(权限控制)
"""
if not user_id:
raise ValueError("user is required")
self._task_id = task_id
self._user_id = user_id
self._invoke_from = invoke_from
self.invoke_from = invoke_from # Public accessor
# ─── 确定用户前缀 ───
# EXPLORE/DEBUGGER: 控制台用户(account)
# API/WEB: 终端用户(end-user)
user_prefix = "account" if self._invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else "end-user"
# ─── 设置任务归属缓存 ───
self._task_belong_cache_key = AppQueueManager._generate_task_belong_cache_key(self._task_id)
redis_client.setex(
self._task_belong_cache_key,
1800, # 30 分钟过期
f"{user_prefix}-{self._user_id}"
)
"""
【Redis 数据示例】
Key: generate_task_belong:abc-123
Value: "account-user-456"
TTL: 1800 秒
【用途】
1. 权限验证:只有任务创建者可以停止任务
2. 自动清理:30 分钟后自动过期
"""
# ─── 创建 Python Queue ───
q: queue.Queue[WorkflowQueueMessage | MessageQueueMessage | None] = queue.Queue()
self._q = q
"""
【Python Queue 特性】
✅ 线程安全
✅ 无序列化开销(直接传递 Python 对象)
✅ 高性能(纯内存操作)
✅ 支持超时等待(get(timeout=1))
【vs Redis Queue】
Redis Queue 需要序列化/反序列化,性能较低
Python Queue 仅支持进程内通信,但性能更高
【为何够用】
Flask Worker 和后台线程在同一进程内
不需要跨进程通信
"""
# ─── 其他状态 ───
self._graph_runtime_state: GraphRuntimeState | None = None # 工作流运行时状态
self._stopped_cache: TTLCache[tuple, bool] = TTLCache(maxsize=1, ttl=1) # 停止状态缓存
self._cache_lock = threading.Lock() # 缓存锁
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 核心方法 1: listen() - Flask Worker 监听队列
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def listen(self):
"""
监听队列并生成 SSE 事件
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行流程】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 从 Python Queue 取出事件(超时 1 秒)
2. 如果有事件,yield 返回给 Flask(SSE 输出)
3. 如果队列为空,继续等待
4. 检查超时和停止标记
5. 定期发送 Ping 事件
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【关键特性】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ Generator 模式:yield 返回事件,支持 SSE 流式输出
✅ 超时控制:APP_MAX_EXECUTION_TIME(默认 1200 秒)
✅ 停止检测:通过 Redis 检查停止标记
✅ Ping 机制:每 10 秒发送一次心跳
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【使用示例】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@app.route('/api/workflows/run')
def run_workflow():
queue_manager = AppQueueManager(task_id, user_id, invoke_from)
def generate():
for message in queue_manager.listen():
yield f"data: {json.dumps(message)}\n\n"
return Response(generate(), mimetype='text/event-stream')
"""
# ─── 配置超时时间 ───
listen_timeout = dify_config.APP_MAX_EXECUTION_TIME # 默认 1200 秒(20 分钟)
start_time = time.time()
last_ping_time: int | float = 0
while True:
try:
# ─── 从队列取出事件(超时 1 秒)───
message = self._q.get(timeout=1)
"""
【超时设计】
timeout=1 秒:每秒检查一次
→ 不会长时间阻塞
→ 可以及时响应停止信号
→ 可以定期发送 Ping
"""
if message is None:
# None 是停止信号
break
# ─── 返回事件给 Flask(SSE 输出)───
yield message
except queue.Empty:
# 队列为空,继续等待
continue
finally:
# ─── 检查超时和停止标记 ───
elapsed_time = time.time() - start_time
if elapsed_time >= listen_timeout or self._is_stopped():
# 🔥 超时或用户停止,发送停止事件
self.publish(
QueueStopEvent(stopped_by=QueueStopEvent.StopBy.USER_MANUAL),
PublishFrom.TASK_PIPELINE
)
"""
【为何发送停止事件】
1. 通知前端任务已停止
2. 前端可以显示停止原因
3. 清理资源(关闭 SSE 连接)
"""
# ─── Ping 机制 ───
if elapsed_time // 10 > last_ping_time:
# 每 10 秒发送一次 Ping
self.publish(QueuePingEvent(), PublishFrom.TASK_PIPELINE)
last_ping_time = elapsed_time // 10
"""
【Ping 机制作用】
1. 检测前端连接是否断开
2. 保持 SSE 连接活跃(防止代理超时)
3. 前端可以显示"执行中..."状态
【前端处理】
if (event.type === 'ping') {
console.log('Still running...');
}
"""
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 核心方法 2: stop_listen() - 停止监听
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def stop_listen(self):
"""
停止监听队列
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行时机】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 工作流执行完成
2. 用户手动停止
3. 超时自动停止
4. 异常导致停止
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【清理操作】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 删除 Redis 中的任务归属缓存
2. 向队列推送 None(停止信号)
3. 释放工作流运行时状态(允许 GC 回收内存)
"""
# ─── Step 1: 清理 Redis 缓存 ───
self._clear_task_belong_cache()
# ─── Step 2: 发送停止信号 ───
self._q.put(None)
"""
【None 作为停止信号】
listen() 中的逻辑:
if message is None:
break
"""
# ─── Step 3: 释放内存 ───
self._graph_runtime_state = None
"""
【为何需要释放】
GraphRuntimeState 包含:
- 所有节点的运行时数据
- 变量池(可能很大)
- 执行历史
不释放会导致内存泄漏
"""
def _clear_task_belong_cache(self) -> None:
"""
清理任务归属缓存
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【执行操作】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
删除 Redis Key: generate_task_belong:{task_id}
【为何需要立即清理】
虽然有 TTL(30 分钟),但立即清理可以:
1. 释放 Redis 内存
2. 防止其他用户误操作
3. 清理完整的任务痕迹
"""
try:
redis_client.delete(self._task_belong_cache_key)
except RedisError:
logger.exception(
"Failed to clear task belong cache for task %s (key: %s)",
self._task_id,
self._task_belong_cache_key
)
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 核心方法 3: publish() - 发布事件到队列
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def publish(self, event: AppQueueEvent, pub_from: PublishFrom):
"""
发布事件到队列
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调用者】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- 后台线程(工作流执行过程)
- listen() 方法(Ping 和 Stop 事件)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【事件类型】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
- NodeStartedEvent: 节点开始执行
- NodeFinishedEvent: 节点执行完成
- LLMChunkEvent: LLM 流式输出(Token)
- WorkflowFinishedEvent: 工作流执行完成
- QueueErrorEvent: 错误事件
- QueuePingEvent: Ping 心跳
- QueueStopEvent: 停止事件
"""
# ─── 安全检查:禁止传递 SQLAlchemy 模型 ───
self._check_for_sqlalchemy_models(event.model_dump())
"""
【为何禁止】
SQLAlchemy 模型不是线程安全的
→ 在不同线程间传递会导致:
1. Session 冲突
2. 对象状态不一致
3. 数据库锁死
【正确做法】
将模型转换为 dict 或 Pydantic 模型
"""
# ─── 调用子类实现的 _publish ───
self._publish(event, pub_from)
@abstractmethod
def _publish(self, event: AppQueueEvent, pub_from: PublishFrom):
"""
发布事件的具体实现(由子类实现)
【子类】
- WorkflowAppQueueManager: 工作流应用
- MessageBasedAppQueueManager: 对话式应用
"""
raise NotImplementedError
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 停止控制相关方法
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@classmethod
def set_stop_flag(cls, task_id: str, invoke_from: InvokeFrom, user_id: str):
"""
设置任务停止标记
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【调用场景】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
用户点击前端"停止"按钮
→ 发起 POST /api/workflows/:id/stop
→ Controller 调用 AppQueueManager.set_stop_flag()
→ 设置 Redis 停止标记
→ listen() 检测到停止标记
→ 发送 StopEvent,结束执行
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【权限验证】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
1. 从 Redis 读取任务归属
2. 对比请求用户 ID
3. 仅允许任务创建者停止
"""
# ─── Step 1: 读取任务归属 ───
result: Any | None = redis_client.get(cls._generate_task_belong_cache_key(task_id))
if result is None:
# 任务不存在或已过期
return
# ─── Step 2: 验证用户权限 ───
user_prefix = "account" if invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else "end-user"
if result.decode("utf-8") != f"{user_prefix}-{user_id}":
# 用户 ID 不匹配,无权停止
return
# ─── Step 3: 设置停止标记 ───
stopped_cache_key = cls._generate_stopped_cache_key(task_id)
redis_client.setex(stopped_cache_key, 600, 1) # 10 分钟过期
"""
【Redis 数据示例】
Key: generate_task_stopped:abc-123
Value: 1
TTL: 600 秒
【listen() 检测逻辑】
if self._is_stopped():
# 发送 StopEvent
break
"""
@cachedmethod(lambda self: self._stopped_cache, lock=lambda self: self._cache_lock)
def _is_stopped(self) -> bool:
"""
检查任务是否已停止
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【缓存策略】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
使用 TTLCache,TTL=1 秒
→ 每秒最多查询 Redis 一次
→ 减少 Redis 压力
→ 停止延迟最多 1 秒(可接受)
【装饰器】
@cachedmethod: 方法级缓存
lock: 线程锁(防止并发查询)
"""
stopped_cache_key = AppQueueManager._generate_stopped_cache_key(self._task_id)
result = redis_client.get(stopped_cache_key)
if result is not None:
return True # 已停止
return False # 未停止
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# Redis Key 生成方法
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
@classmethod
def _generate_task_belong_cache_key(cls, task_id: str) -> str:
"""生成任务归属缓存 Key"""
return f"generate_task_belong:{task_id}"
@classmethod
def _generate_stopped_cache_key(cls, task_id: str) -> str:
"""生成停止标记缓存 Key"""
return f"generate_task_stopped:{task_id}"
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# 安全检查方法
# ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
def _check_for_sqlalchemy_models(self, data: Any):
"""
检查数据中是否包含 SQLAlchemy 模型
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【为何需要】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
SQLAlchemy 模型在不同线程间传递会导致严重问题:
1. Session 冲突
2. 对象状态不一致
3. 数据库死锁
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
【正确做法】
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
# ❌ 错误
event = NodeStartedEvent(node=node_model) # node_model 是 SQLAlchemy 对象
# ✅ 正确
event = NodeStartedEvent(
node_id=node_model.id,
node_type=node_model.type,
# 仅传递基本类型
)
"""
if isinstance(data, dict):
for value in data.values():
self._check_for_sqlalchemy_models(value)
elif isinstance(data, list):
for item in data:
self._check_for_sqlalchemy_models(item)
else:
if isinstance(data, DeclarativeMeta) or hasattr(data, "_sa_instance_state"):
raise TypeError(
"Critical Error: Passing SQLAlchemy Model instances that "
"cause thread safety issues is not allowed."
)核心文件:api/core/app/apps/base_app_queue_manager.py
这是 Dify 解决 Flask Worker 阻塞问题 的关键设计!通过 Python Queue + Redis 双重解耦,实现了:
- Flask Worker 不阻塞 :只负责 SSE 流式传输,通过
queue.Queue的get()非阻塞监听 - Celery Worker 异步执行 :长时间运行的 Workflow 在后台执行,通过
put()发送事件 - Redis 跨进程状态同步:停止标志位、任务归属检查等通过 Redis 共享
python
# ================================
# 第一部分:核心导入与枚举定义
# ================================
import logging
import queue # Python 标准库的线程安全队列,核心!
import threading
import time
from abc import abstractmethod
from enum import IntEnum, auto
from typing import Any
from cachetools import TTLCache, cachedmethod # 用于缓存 Redis 查询结果
from redis.exceptions import RedisError
from sqlalchemy.orm import DeclarativeMeta
from configs import dify_config
from core.app.entities.app_invoke_entities import InvokeFrom
from core.app.entities.queue_entities import (
AppQueueEvent, # 所有事件的基类
MessageQueueMessage, # 消息事件
QueueErrorEvent, # 错误事件
QueuePingEvent, # 心跳事件
QueueStopEvent, # 停止事件
WorkflowQueueMessage, # Workflow 事件
)
from core.workflow.runtime import GraphRuntimeState
from extensions.ext_redis import redis_client
logger = logging.getLogger(__name__)
# ================================
# 第二部分:事件发布来源枚举
# ================================
class PublishFrom(IntEnum):
"""
标识事件的发布来源,用于调试和日志追踪
"""
APPLICATION_MANAGER = auto() # 来自 Flask Worker (应用管理器)
TASK_PIPELINE = auto() # 来自 Celery Worker (任务管道)
# ================================
# 第三部分:AppQueueManager 抽象基类
# ================================
class AppQueueManager:
"""
【核心设计思想】
这个类是 Dify SSE 流式输出的**解耦核心**,解决了两个关键问题:
1. **Flask Worker 不阻塞**:
- Flask Worker 通过 `listen()` 方法监听 `self._q` (Python Queue)
- `listen()` 使用 `get(timeout=1)` 非阻塞获取消息,不会长时间占用 Worker
- 获取到消息后通过 `yield` 返回给 SSE 流
2. **Celery Worker 异步推送**:
- Celery Worker 在后台执行 Workflow,每执行一步就调用 `publish()` 发送事件
- `publish()` 内部调用 `_q.put(event)` 将事件放入队列
- Flask Worker 的 `listen()` 立即获取到事件并通过 SSE 返回给前端
【关键技术】
- **Python Queue**:进程内的线程安全队列,用于 Flask Worker 和 Celery Worker 之间的事件传递
- **Redis**:跨进程状态管理,包括:
- 任务归属检查 (task_belong_cache_key)
- 停止标志位 (stopped_cache_key)
- TTL 自动过期清理
"""
def __init__(self, task_id: str, user_id: str, invoke_from: InvokeFrom):
"""
【初始化流程】
1. 验证 user_id 必须存在
2. 保存 task_id、user_id、invoke_from 到实例变量
3. 在 Redis 中创建任务归属键 (1800 秒过期)
4. 初始化 Python Queue (self._q) 用于事件传递
5. 初始化停止标志缓存 (TTLCache,避免频繁查 Redis)
"""
if not user_id:
raise ValueError("user is required")
self._task_id = task_id
self._user_id = user_id
self._invoke_from = invoke_from
self.invoke_from = invoke_from
# 【Redis Key 1:任务归属检查】
# 格式:generate_task_belong:{task_id}
# 值:account-{user_id} 或 end-user-{user_id}
# 用途:验证是否有权限停止任务
user_prefix = "account" if self._invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else "end-user"
self._task_belong_cache_key = AppQueueManager._generate_task_belong_cache_key(self._task_id)
redis_client.setex(self._task_belong_cache_key, 1800, f"{user_prefix}-{self._user_id}")
# 【核心数据结构:Python Queue】
# 作用:Flask Worker 通过 listen() 从队列获取事件,Celery Worker 通过 publish() 往队列放入事件
# 特点:线程安全、阻塞/非阻塞可控
q: queue.Queue[WorkflowQueueMessage | MessageQueueMessage | None] = queue.Queue()
self._q = q
# Workflow 运行时状态引用 (可选)
self._graph_runtime_state: GraphRuntimeState | None = None
# 【停止标志缓存】
# TTLCache(maxsize=1, ttl=1):每秒最多查询一次 Redis,避免性能问题
self._stopped_cache: TTLCache[tuple, bool] = TTLCache(maxsize=1, ttl=1)
self._cache_lock = threading.Lock()
# ================================
# 【核心方法 1】:listen() - Flask Worker 调用
# ================================
def listen(self):
"""
【Flask Worker 的核心工作循环】
执行流程:
1. Flask 收到 SSE 请求后,调用此方法开始监听
2. 使用 while True 循环,通过 `self._q.get(timeout=1)` 非阻塞获取事件
3. 如果获取到事件,通过 `yield` 返回给 SSE 流 (前端实时收到)
4. 如果 1 秒内没有事件,抛出 queue.Empty 异常,继续下一次循环
5. 每 10 秒发送一次心跳 (QueuePingEvent),保持 SSE 连接不断开
6. 如果超时或收到停止信号,发送 QueueStopEvent 并退出循环
【为什么不阻塞 Flask Worker?】
- `get(timeout=1)` 最多只等 1 秒,不会长时间占用 Worker
- Gunicorn 默认有多个 Worker (如 4 个),即使一个 Worker 在 listen,其他 Worker 仍可处理新请求
- 真正耗时的 Workflow 执行在 Celery Worker 中进行,Flask Worker 只负责转发事件
"""
# 从配置中获取最大执行时间 (默认 1200 秒 = 20 分钟)
listen_timeout = dify_config.APP_MAX_EXECUTION_TIME
start_time = time.time()
last_ping_time: int | float = 0
while True:
try:
# 【核心操作】:非阻塞获取事件 (最多等 1 秒)
message = self._q.get(timeout=1)
# 如果收到 None,表示 stop_listen() 被调用,退出循环
if message is None:
break
# 【核心操作】:yield 返回事件,SSE 流式传输给前端
yield message
except queue.Empty:
# 1 秒内没有新事件,继续下一次循环
continue
finally:
# 【超时检查】:如果执行时间超过限制或收到停止信号
elapsed_time = time.time() - start_time
if elapsed_time >= listen_timeout or self._is_stopped():
# 发送停止事件 (发送两次确保客户端收到)
self.publish(
QueueStopEvent(stopped_by=QueueStopEvent.StopBy.USER_MANUAL),
PublishFrom.TASK_PIPELINE
)
# 【心跳机制】:每 10 秒发送一次 Ping 事件,保持 SSE 连接
if elapsed_time // 10 > last_ping_time:
self.publish(QueuePingEvent(), PublishFrom.TASK_PIPELINE)
last_ping_time = elapsed_time // 10
# ================================
# 【核心方法 2】:stop_listen() - 停止监听
# ================================
def stop_listen(self):
"""
【停止监听流程】
1. 清除 Redis 中的任务归属键
2. 往队列中放入 None,通知 listen() 退出循环
3. 释放 GraphRuntimeState 引用,允许 GC 回收内存
"""
self._clear_task_belong_cache()
self._q.put(None) # 通知 listen() 退出
self._graph_runtime_state = None
def _clear_task_belong_cache(self) -> None:
"""
清除 Redis 中的任务归属键
"""
try:
redis_client.delete(self._task_belong_cache_key)
except RedisError:
logger.exception(
"Failed to clear task belong cache for task %s (key: %s)",
self._task_id, self._task_belong_cache_key
)
# ================================
# 【核心方法 3】:publish() - Celery Worker 调用
# ================================
def publish(self, event: AppQueueEvent, pub_from: PublishFrom):
"""
【Celery Worker 发布事件】
执行流程:
1. Celery Worker 在 Workflow 执行过程中调用此方法
2. 检查事件中是否包含 SQLAlchemy 模型实例 (防止线程安全问题)
3. 调用子类实现的 _publish() 方法
4. 最终通过 `self._q.put(event)` 将事件放入队列
5. Flask Worker 的 listen() 立即获取到事件并通过 SSE 返回
【为什么要检查 SQLAlchemy 模型?】
- SQLAlchemy 的 Session 不是线程安全的
- 如果将模型实例放入队列,跨线程访问会导致 "DetachedInstanceError"
- 必须在 publish 之前调用 model.model_dump() 转换为字典
"""
self._check_for_sqlalchemy_models(event.model_dump())
self._publish(event, pub_from)
@abstractmethod
def _publish(self, event: AppQueueEvent, pub_from: PublishFrom):
"""
抽象方法,由子类实现具体的发布逻辑
通常是 self._q.put(event)
"""
raise NotImplementedError
# ================================
# 【核心方法 4】:set_stop_flag() - 设置停止标志
# ================================
@classmethod
def set_stop_flag(cls, task_id: str, invoke_from: InvokeFrom, user_id: str):
"""
【用户手动停止任务】
执行流程:
1. 前端发送停止请求
2. Flask API 调用此方法
3. 从 Redis 中查询任务归属 (generate_task_belong:{task_id})
4. 验证当前用户是否有权限停止此任务
5. 在 Redis 中设置停止标志 (generate_task_stopped:{task_id}),600 秒过期
6. Celery Worker 的 _is_stopped() 会检测到此标志,停止 Workflow 执行
【安全设计】:
- 通过 Redis 中的任务归属键验证权限
- 防止用户 A 停止用户 B 的任务
"""
# 查询任务归属
result: Any | None = redis_client.get(cls._generate_task_belong_cache_key(task_id))
if result is None:
return
# 验证权限
user_prefix = "account" if invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else "end-user"
if result.decode("utf-8") != f"{user_prefix}-{user_id}":
return
# 设置停止标志 (600 秒过期)
stopped_cache_key = cls._generate_stopped_cache_key(task_id)
redis_client.setex(stopped_cache_key, 600, 1)
@classmethod
def set_stop_flag_no_user_check(cls, task_id: str) -> None:
"""
【无权限检查的停止方法】
用于系统级停止 (如超时、异常)
"""
if not task_id:
return
stopped_cache_key = cls._generate_stopped_cache_key(task_id)
redis_client.setex(stopped_cache_key, 600, 1)
# ================================
# 【核心方法 5】:_is_stopped() - 检查停止标志
# ================================
@cachedmethod(lambda self: self._stopped_cache, lock=lambda self: self._cache_lock)
def _is_stopped(self) -> bool:
"""
【检查任务是否被停止】
【性能优化】:
- 使用 TTLCache (ttl=1 秒) 缓存查询结果
- 避免每次循环都查询 Redis,减少网络开销
- 通过 @cachedmethod 装饰器自动管理缓存
返回:
- True: 任务已被停止
- False: 任务仍在运行
"""
stopped_cache_key = AppQueueManager._generate_stopped_cache_key(self._task_id)
result = redis_client.get(stopped_cache_key)
if result is not None:
return True
return False
# ================================
# 辅助方法:Redis Key 生成
# ================================
@classmethod
def _generate_task_belong_cache_key(cls, task_id: str) -> str:
"""
生成任务归属键
格式:generate_task_belong:{task_id}
"""
return f"generate_task_belong:{task_id}"
@classmethod
def _generate_stopped_cache_key(cls, task_id: str) -> str:
"""
生成停止标志键
格式:generate_task_stopped:{task_id}
"""
return f"generate_task_stopped:{task_id}"
# ================================
# 辅助方法:SQLAlchemy 模型检查
# ================================
def _check_for_sqlalchemy_models(self, data: Any):
"""
【递归检查事件数据中是否包含 SQLAlchemy 模型实例】
为什么需要?
- SQLAlchemy 的 Session 不是线程安全的
- 跨线程传递模型实例会导致 "DetachedInstanceError"
- 必须在 publish 之前调用 model.model_dump() 转换为字典
检查逻辑:
- 递归遍历字典、列表
- 检查对象是否为 DeclarativeMeta 或包含 _sa_instance_state 属性
- 如果检测到,抛出 TypeError
"""
if isinstance(data, dict):
for value in data.values():
self._check_for_sqlalchemy_models(value)
elif isinstance(data, list):
for item in data:
self._check_for_sqlalchemy_models(item)
else:
if isinstance(data, DeclarativeMeta) or hasattr(data, "_sa_instance_state"):
raise TypeError(
"Critical Error: Passing SQLAlchemy Model instances that cause thread safety issues is not allowed."
)
# ================================
# 其他辅助方法
# ================================
def publish_error(self, e, pub_from: PublishFrom) -> None:
"""发布错误事件"""
self.publish(QueueErrorEvent(error=e), pub_from)
@property
def graph_runtime_state(self) -> GraphRuntimeState | None:
"""获取 Workflow 运行时状态"""
return self._graph_runtime_state
@graph_runtime_state.setter
def graph_runtime_state(self, graph_runtime_state: GraphRuntimeState | None) -> None:
"""设置 Workflow 运行时状态"""
self._graph_runtime_state = graph_runtime_stateRedis Pub/Sub vs Python Queue
python
# ❌ 常见误区:以为 Dify 用 Redis Pub/Sub 做事件传递
# 实际上 Dify 使用的是 Python Queue (进程内)
# 【Dify 的实际架构】
┌─────────────────────────────────────────────────────────────────┐
│ Flask Worker (同一进程) │
│ ┌─────────────────────────────┐ │
│ │ Flask Request Thread │ │
│ │ • listen() 监听 queue.Queue│ │
│ └─────────────────────────────┘ │
│ ↑ │
│ │ Python Queue (进程内,线程安全) │
│ │ self._q.put(event) │
│ ┌─────────────┴───────────────┐ │
│ │ Worker Thread (后台线程) │ │
│ │ • 执行 Workflow │ │
│ │ • publish() 发送事件 │ │
│ └─────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘为什么不用 Redis Pub/Sub?
| 对比项 | Redis Pub/Sub | Python Queue (Dify 方案) |
|---|---|---|
| 通信范围 | 跨进程、跨机器 | 进程内、线程间 |
| 性能 | 需要网络 I/O,延迟 1-5ms | 内存操作,延迟 < 0.1ms |
| 消息可靠性 | 无持久化,订阅者离线则消息丢失 | Queue 保证消息不丢失 |
| 复杂度 | 需要额外的 Redis 连接管理 | Python 标准库,零额外依赖 |
| 适用场景 | 分布式系统、多机器部署 | 单机部署、同进程通信 |
Dify 的部署架构决定了不需要 Redis Pub/Sub:
python
# Dify 的典型部署:单机 Docker Compose
# • Flask (Gunicorn) 和后台线程在同一 Python 进程
# • 使用 threading.Thread 启动后台线程
# • Python Queue 足以满足需求
# 如果未来改为分布式部署 (Flask 和 Worker 分离),才需要 Redis Pub/SubRedis 在 Dify 中的真实作用(仅用于跨进程状态同步):
python
# ✅ Redis 的实际用途:
# 1. 停止标志位:generate_task_stopped:{task_id}
# - Flask Worker A 设置停止标志
# - Worker Thread (可能在不同线程) 检测停止标志
#
# 2. 任务归属验证:generate_task_belong:{task_id}
# - 防止用户 A 停止用户 B 的任务
#
# 3. Celery 消息队列:
# - Celery 使用 Redis 作为 Broker (消息队列)
# - 与 SSE 流式输出无关
# ❌ Redis 不用于事件传递 (event publish/subscribe)后台线程执行工作流(核心设计)
为什么使用后台线程?
python
# ❌ 不使用后台线程的问题
@app.post('/workflows/run')
def run_workflow_bad():
# 直接在 Flask Worker 中执行 Workflow
for node in workflow.nodes:
result = node.run() # 🔴 如果调用 LLM API 耗时 30 秒
yield f"data: {json.dumps(result)}\n\n"
# 问题:
# 1. Flask Worker 被完全占用,无法处理新请求
# 2. 数据库连接被长时间占用,可能超时
# 3. 无法利用多核 CPU (GIL 限制)
# ✅ 使用后台线程的优势
@app.post('/workflows/run')
def run_workflow_good():
queue_manager = WorkflowAppQueueManager(...)
# 启动后台线程执行 Workflow
worker_thread = threading.Thread(target=execute_workflow, args=(queue_manager,))
worker_thread.start()
# Flask Worker 只负责监听队列
for message in queue_manager.listen():
yield f"data: {message.model_dump_json()}\n\n"
# 优势:
# 1. Flask Worker 不阻塞,通过 get(timeout=1) 非阻塞监听
# 2. 后台线程独立执行,不影响 Flask Worker
# 3. 数据库连接在后台线程中独立管理完整的后台线程代码解析
python
# ================================
# 文件:api/core/app/apps/workflow/app_generator.py
# ================================
class WorkflowAppGenerator(BaseAppGenerator):
def _generate(
self,
*,
app_model: App,
workflow: Workflow,
user: Union[Account, EndUser],
application_generate_entity: WorkflowAppGenerateEntity,
invoke_from: InvokeFrom,
workflow_execution_repository: WorkflowExecutionRepository,
workflow_node_execution_repository: WorkflowNodeExecutionRepository,
streaming: bool = True,
variable_loader: VariableLoader = DUMMY_VARIABLE_LOADER,
root_node_id: str | None = None,
graph_engine_layers: Sequence[GraphEngineLayer] = (),
) -> Union[Mapping[str, Any], Generator[str | Mapping[str, Any], None, None]]:
"""
【核心方法】:生成 Workflow 响应
执行流程:
1. 创建 WorkflowAppQueueManager
2. 启动后台线程执行 Workflow
3. Flask Worker 监听队列并通过 SSE 返回
"""
# ────────────────────────────────────────────
# 步骤 1:创建 QueueManager
# ────────────────────────────────────────────
queue_manager = WorkflowAppQueueManager(
task_id=application_generate_entity.task_id,
user_id=application_generate_entity.user_id,
invoke_from=application_generate_entity.invoke_from,
app_mode=app_model.mode,
)
# ────────────────────────────────────────────
# 步骤 2:复制上下文变量 (关键!)
# ────────────────────────────────────────────
# 【为什么需要 contextvars.copy_context()?】
# - Flask 的 request context 是线程局部变量
# - 后台线程无法直接访问 Flask request context
# - 需要复制上下文并在后台线程中恢复
context = contextvars.copy_context()
# ────────────────────────────────────────────
# 步骤 3:关闭数据库连接 (关键!)
# ────────────────────────────────────────────
# 【为什么要关闭数据库连接?】
# - SQLAlchemy 的 Session 不是线程安全的
# - 主线程的 Session 不能在后台线程中使用
# - 后台线程会创建新的 Session
db.session.close()
# ────────────────────────────────────────────
# 步骤 4:创建后台线程
# ────────────────────────────────────────────
worker_thread = threading.Thread(
target=self._generate_worker, # 后台线程执行的函数
kwargs={
"flask_app": current_app._get_current_object(), # 🔑 Flask app 实例
"application_generate_entity": application_generate_entity,
"queue_manager": queue_manager, # 🔑 传递 QueueManager
"context": context, # 🔑 上下文变量
"variable_loader": variable_loader,
"root_node_id": root_node_id,
"workflow_execution_repository": workflow_execution_repository,
"workflow_node_execution_repository": workflow_node_execution_repository,
"graph_engine_layers": graph_engine_layers,
},
)
# ────────────────────────────────────────────
# 步骤 5:启动后台线程 (非阻塞)
# ────────────────────────────────────────────
worker_thread.start() # 🔑 立即返回,不等待线程结束
# ────────────────────────────────────────────
# 步骤 6:Flask Worker 监听队列并返回 SSE
# ────────────────────────────────────────────
draft_var_saver_factory = self._get_draft_var_saver_factory(invoke_from, user)
response = self._handle_response(
application_generate_entity=application_generate_entity,
workflow=workflow,
queue_manager=queue_manager, # 🔑 传递给 _handle_response
user=user,
draft_var_saver_factory=draft_var_saver_factory,
stream=streaming,
)
return WorkflowAppGenerateResponseConverter.convert(
response=response,
invoke_from=invoke_from
)** 后台线程的核心函数:**_generate_worker()
python
def _generate_worker(
self,
flask_app: Flask,
application_generate_entity: WorkflowAppGenerateEntity,
queue_manager: WorkflowAppQueueManager,
context: contextvars.Context,
variable_loader: VariableLoader,
root_node_id: str | None,
workflow_execution_repository: WorkflowExecutionRepository,
workflow_node_execution_repository: WorkflowNodeExecutionRepository,
graph_engine_layers: Sequence[GraphEngineLayer],
) -> None:
"""
【后台线程的核心函数】
执行流程:
1. 恢复 Flask app context
2. 恢复 contextvars
3. 执行 Workflow
4. 捕获异常并通过 queue_manager.publish_error() 发送
"""
# ────────────────────────────────────────────
# 步骤 1:恢复 Flask app context
# ────────────────────────────────────────────
with flask_app.app_context(): # 🔑 进入 Flask app context
# ────────────────────────────────────────────
# 步骤 2:在复制的上下文中执行
# ────────────────────────────────────────────
def run_in_context():
try:
# 创建 WorkflowAppRunner
runner = WorkflowAppRunner(
application_generate_entity=application_generate_entity,
queue_manager=queue_manager, # 🔑 传递 QueueManager
variable_loader=variable_loader,
workflow=application_generate_entity.app_config.workflow,
system_user_id=application_generate_entity.user_id,
root_node_id=root_node_id,
workflow_execution_repository=workflow_execution_repository,
workflow_node_execution_repository=workflow_node_execution_repository,
graph_engine_layers=graph_engine_layers,
)
# 🔑 执行 Workflow (核心逻辑)
runner.run()
except Exception as e:
# 捕获所有异常,通过 queue_manager 发送错误事件
logger.exception(f"Workflow execution failed: {e}")
queue_manager.publish_error(e, PublishFrom.TASK_PIPELINE)
# 🔑 在复制的上下文中执行
context.run(run_in_context)Gevent 协程优化
什么是 Gevent 协程优化?
Gevent 是一个基于协程的 Python 网络库,它通过 monkey patching(猴子补丁) 将 Python 标准库中的阻塞 IO 操作替换为非阻塞的协程版本。
Dify 的三层 Gevent 优化架构
第一层:Gunicorn Worker 启用 Gevent
入口文件: api/docker/entrypoint.sh
plain
exec gunicorn \
--bind "${DIFY_BIND_ADDRESS:-0.0.0.0}:${DIFY_PORT:-5001}" \
--workers ${SERVER_WORKER_AMOUNT:-1} \
--worker-class ${SERVER_WORKER_CLASS:-gevent} \
--worker-connections ${SERVER_WORKER_CONNECTIONS:-10} \
--timeout ${GUNICORN_TIMEOUT:-200} \
app:app关键参数解释:
| 参数 | 默认值 | 作用 |
|---|---|---|
--worker-class gevent |
gevent | 核心配置:启用 gevent worker,自动进行 monkey patching |
--workers 1 |
1 | 进程数(多进程并行) |
--worker-connections 10 |
10 | 每个 worker 同时处理的连接数(协程并发) |
实际并发能力: workers × worker-connections = 1 × 10 = 10 个并发请求
第二层:psycopg2 补丁(数据库优化)
核心文件: api/gunicorn.conf.py
python
import psycogreen.gevent as pscycogreen_gevent # type: ignore
from gevent import events as gevent_events
from grpc.experimental import gevent as grpc_gevent # type: ignore
def post_patch(event):
# this function is only called for gevent worker.
# from gevent docs (https://www.gevent.org/api/gevent.monkey.html):
# You can also subscribe to the events to provide additional patching beyond what gevent distributes, either for
# additional standard library modules, or for third-party packages. The suggested time to do this patching is in
# the subscriber for gevent.events.GeventDidPatchBuiltinModulesEvent.
if not isinstance(event, gevent_events.GeventDidPatchBuiltinModulesEvent):
return
# grpc gevent
grpc_gevent.init_gevent()
print("gRPC patched with gevent.", flush=True) # noqa: T201
pscycogreen_gevent.patch_psycopg()
print("psycopg2 patched with gevent.", flush=True) # noqa: T201
gevent_events.subscribers.append(post_patch)psycopg2 优化原理:
- 问题:psycopg2(PostgreSQL 驱动)默认是阻塞式的,执行 SQL 时会卡住整个线程
- 解决方案 :
<font style="color:#DF2A3F;">psycogreen.gevent.patch_psycopg()</font>将 psycopg2 的等待机制替换为 gevent 协程 - 效果:执行 SQL 查询时,CPU 可以切换到其他协程处理其他请求
实际场景举例:
python
# 未优化前:串行执行,总耗时 3 秒
user1 = db.query("SELECT * FROM users WHERE id=1") # 阻塞 1 秒
user2 = db.query("SELECT * FROM users WHERE id=2") # 阻塞 1 秒
user3 = db.query("SELECT * FROM users WHERE id=3") # 阻塞 1 秒
# Gevent 优化后:并发执行,总耗时 1 秒
# 三个查询几乎同时发送,协程自动调度第三层:gRPC 补丁(插件通信优化)
同样在 gunicorn.conf.py 中:
python
# grpc gevent
grpc_gevent.init_gevent()
print("gRPC patched with gevent.", flush=True) # noqa: T201gRPC 优化原理:
- 背景:Dify 的插件系统使用 gRPC 进行跨进程通信
- 问题:gRPC 默认使用线程池,与 gevent 的事件循环冲突
- 解决方案 :
<font style="color:#DF2A3F;">grpc_gevent.init_gevent()</font>让 gRPC 使用 gevent 的协程调度 - 效果:插件调用时不会阻塞主事件循环
第四层:SQLAlchemy 连接池兼容性
文件: api/extensions/ext_database.py
python
def _setup_gevent_compatibility():
global _gevent_compatibility_setup # pylint: disable=global-statement
# Avoid duplicate registration
if _gevent_compatibility_setup:
return
@event.listens_for(Pool, "reset")
def _safe_reset(dbapi_connection, connection_record, reset_state): # pyright: ignore[reportUnusedFunction]
if reset_state.terminate_only:
return
# Safe rollback for connection
try:
hub = gevent.get_hub()
if hasattr(hub, "loop") and getattr(hub.loop, "in_callback", False):
gevent.spawn_later(0, lambda: _safe_rollback(dbapi_connection))
else:
_safe_rollback(dbapi_connection)
except (AttributeError, ImportError):
_safe_rollback(dbapi_connection)
_gevent_compatibility_setup = True作用: 防止在 gevent 事件循环回调中直接执行数据库回滚导致死锁
关键问题:补丁时序(Patch Timing)
这是最精妙的部分!补丁必须在正确的时机执行,否则会死锁或崩溃。
Gunicorn Worker 生命周期:
plain
1. Gunicorn 主进程启动
↓
2. 加载 gunicorn.conf.py(注册 post_patch 事件监听器)
↓
3. Fork worker 进程
↓
4. Gunicorn 自动执行 monkey patch(替换标准库)
↓
5. 🔥 触发 GeventDidPatchBuiltinModulesEvent
↓
6. 执行 post_patch() 回调
- patch psycopg2 ✅
- patch gRPC ✅
↓
7. 导入 Flask 应用(app:app)
↓
8. Worker 开始接受请求为什么不能在 post_fork 钩子中打补丁?
从代码注释中可以看到:
plain
# NOTE(QuantumGhost): here we cannot use post_fork to patch gRPC, as
# grpc_gevent.init_gevent must be called after patching stdlib.
# Gunicorn calls `post_init` before applying monkey patch.
# Use `post_init` to setup gRPC gevent support would cause deadlock and
# some other weird issues.
#
# ref:
# - https://github.com/grpc/grpc/blob/62533ea13879d6ee95c6fda11ec0826ca822c9dd/src/python/grpcio/grpc/experimental/gevent.py
# - https://github.com/gevent/gevent/issues/2060#issuecomment-3016768668
# - https://github.com/benoitc/gunicorn/blob/23.0.0/gunicorn/arbiter.py#L605-L609原因: post_fork 在 monkey patch 之前执行,此时标准库还没被替换,gRPC 初始化会使用原始的线程模型,导致冲突。
Celery Worker 的处理
文件: api/celery_entrypoint.py
python
import psycogreen.gevent as pscycogreen_gevent # type: ignore
from grpc.experimental import gevent as grpc_gevent # type: ignore
# grpc gevent
grpc_gevent.init_gevent()
print("gRPC patched with gevent.", flush=True) # noqa: T201
pscycogreen_gevent.patch_psycopg()
print("psycopg2 patched with gevent.", flush=True) # noqa: T201
from app import app, celery
__all__ = ["app", "celery"]Celery 启动命令:
shell
WORKER_POOL="${CELERY_WORKER_POOL:-${CELERY_WORKER_CLASS:-gevent}}"
echo "Starting Celery worker with queues: ${DEFAULT_QUEUES}"
exec celery -A celery_entrypoint.celery worker -P ${WORKER_POOL} $CONCURRENCY_OPTION \
--max-tasks-per-child ${MAX_TASKS_PER_CHILD:-50} --loglevel ${LOG_LEVEL:-INFO} \
-Q ${DEFAULT_QUEUES} \
--prefetch-multiplier=${CELERY_PREFETCH_MULTIPLIER:-1}关键: -P gevent 指定使用 gevent 线程池,celery_entrypoint.py 在导入前手动打补丁。
Gevent 协程优化全貌
Dify 通过 Gevent 协程库将传统的阻塞 IO 操作(数据库、gRPC)转换为非阻塞协程,从而在单进程/单线程内实现高并发处理。
核心实现机制
Gunicorn 配置 - API 服务器优化
python
import psycogreen.gevent as pscycogreen_gevent # type: ignore
from gevent import events as gevent_events
from grpc.experimental import gevent as grpc_gevent # type: ignore
def post_patch(event):
# this function is only called for gevent worker.
# from gevent docs (https://www.gevent.org/api/gevent.monkey.html):
# You can also subscribe to the events to provide additional patching beyond what gevent distributes, either for
# additional standard library modules, or for third-party packages. The suggested time to do this patching is in
# the subscriber for gevent.events.GeventDidPatchBuiltinModulesEvent.
if not isinstance(event, gevent_events.GeventDidPatchBuiltinModulesEvent):
return
# grpc gevent
grpc_gevent.init_gevent()
print("gRPC patched with gevent.", flush=True) # noqa: T201
pscycogreen_gevent.patch_psycopg()
print("psycopg2 patched with gevent.", flush=True) # noqa: T201
gevent_events.subscribers.append(post_patch)关键点:
- 时序至关重要 :必须在 Gevent monkey patch 完成之后再补丁 gRPC 和 psycopg2
- 事件订阅机制 :通过
GeventDidPatchBuiltinModulesEvent确保补丁顺序正确 - 避免死锁 :不能使用
<font style="color:#DF2A3F;">post_fork</font>钩子,因为它在 monkey patch 之前执行
****** Celery 入口点 - 异步任务优化**
python
import psycogreen.gevent as pscycogreen_gevent # type: ignore
from grpc.experimental import gevent as grpc_gevent # type: ignore
# grpc gevent
grpc_gevent.init_gevent()
print("gRPC patched with gevent.", flush=True) # noqa: T201
pscycogreen_gevent.patch_psycopg()
print("psycopg2 patched with gevent.", flush=True) # noqa: T201
from app import app, celery
__all__ = ["app", "celery"]关键点:
- Celery 使用
gevent作为并发池(pool) - 在导入应用代码之前手动执行补丁
- 确保异步任务也能享受协程优化
****** 数据库连接池 Gevent 兼容性**
python
def _setup_gevent_compatibility():
global _gevent_compatibility_setup # pylint: disable=global-statement
# Avoid duplicate registration
if _gevent_compatibility_setup:
return
@event.listens_for(Pool, "reset")
def _safe_reset(dbapi_connection, connection_record, reset_state): # pyright: ignore[reportUnusedFunction]
if reset_state.terminate_only:
return
# Safe rollback for connection
try:
hub = gevent.get_hub()
if hasattr(hub, "loop") and getattr(hub.loop, "in_callback", False):
gevent.spawn_later(0, lambda: _safe_rollback(dbapi_connection))
else:
_safe_rollback(dbapi_connection)
except (AttributeError, ImportError):
_safe_rollback(dbapi_connection)
_gevent_compatibility_setup = True
def init_app(app: DifyApp):
db.init_app(app)
_setup_gevent_compatibility()关键点:
- 安全回滚机制:检测是否在 Gevent 事件循环的回调中
- 延迟执行 :如果在回调中,使用
spawn_later避免阻塞 - 防止死锁:确保数据库连接池在协程环境下正常工作
技术细节说明
psycopg2 补丁(数据库优化)
python
# 通过 psycogreen 库实现
pscycogreen_gevent.patch_psycopg()** 将 **psycopg2** 的阻塞连接转换为 Gevent 绿色协程**
效果:
- SQL 查询期间,协程可以切换处理其他请求
- 数据库连接池利用率大幅提升
gRPC 补丁(RPC 优化)
python
# 使用 gRPC 官方的 Gevent 支持
grpc_gevent.init_gevent()效果:
- gRPC 调用变为非阻塞
- 适配 Gevent 事件循环
- 支持插件系统的远程调用
启动配置(Docker 环境)
在 entrypoint.sh 中:
bash
# API Server
--worker-class ${SERVER_WORKER_CLASS:-gevent}
# Celery Worker
WORKER_POOL="${CELERY_WORKER_POOL:-${CELERY_WORKER_CLASS:-gevent}}"
celery -A celery_entrypoint.celery worker -P ${WORKER_POOL}总结
Dify 的 Gevent 协程优化是一个三层防护的精密设计:
- 基础层 :Gunicorn/Celery 自动 monkey patch 标准库
- Gunicorn 用
--worker-class gevent自动替换标准库(socket、time、threading 等)
- Gunicorn 用
- 适配层 :通过事件钩子补丁 psycopg2 和 gRPC
- ****数据库层 :
psycogreen让 PostgreSQL 查询变成协程,不再阻塞 - 通信层 :
grpc_gevent.init_gevent()让插件 RPC 调用也支持协程 - 补丁时序 :必须在
GeventDidPatchBuiltinModulesEvent事件后打补丁
- ****数据库层 :
- 保护层 :数据库连接池的 Gevent 兼容性处理
- 线程安全:SQLAlchemy 连接池需要特殊处理,避免在事件循环回调中死锁
核心优势:
- ✅ 阻塞 IO 变非阻塞(数据库查询、gRPC 调用)
- ✅ 单 Worker 处理能力提升 4-10 倍
- ✅ 内存占用更低(协程比线程轻量)
- ✅ 避免 GIL 锁(Global Interpreter Lock)的影响
安全考点:SSRF Proxy 防护
什么是 SSRF 攻击?
SSRF(Server-Side Request Forgery,服务器端请求伪造)
想象一个恶意用户这样做:
plain
用户: "帮我访问这个 URL:http://localhost:6379/admin"
Dify: (天真地发起请求) → 访问了服务器内部的 Redis 数据库
攻击者: 成功窃取内网数据!SSRF Proxy 防护三层架构:
三层防护对比表
| 防护层 | 实现方式 | 关键文件 | 防护内容 | 失败时行为 |
|---|---|---|---|---|
| 第一层 应用层 | Python 代码 | ssrf_proxy.py |
• 强制路由到代理 • 响应头检测 • 重试机制 • 超时控制 | 抛出 ToolSSRFError |
| 第二层 代理层 | Squid ACL | squid.conf.template |
• IP 黑名单 • 端口白名单 • 域名白名单 • 方法限制 | 返回 403 + Squid 头 |
| 第三层 网络层 | Docker 网络 | docker-compose.yaml |
• 网络隔离 • 出站控制 • 网关路由 | 无法建立连接 |
第一层:应用层防护(Python 代码)
核心文件: api/core/helper/ssrf_proxy.py
统一入口函数 - 强制所有外部请求走代理
python
def _build_ssrf_client(verify: bool) -> httpx.Client:
if dify_config.SSRF_PROXY_ALL_URL:
return httpx.Client(
proxy=dify_config.SSRF_PROXY_ALL_URL,
verify=verify,
limits=_SSRF_CLIENT_LIMITS,
)
if dify_config.SSRF_PROXY_HTTP_URL and dify_config.SSRF_PROXY_HTTPS_URL:
return httpx.Client(
mounts=_create_proxy_mounts(),
verify=verify,
limits=_SSRF_CLIENT_LIMITS,
)
return httpx.Client(verify=verify, limits=_SSRF_CLIENT_LIMITS)
def _get_ssrf_client(ssl_verify_enabled: bool) -> httpx.Client:
if not isinstance(ssl_verify_enabled, bool):
raise ValueError("SSRF client verify flag must be a boolean")
return get_pooled_http_client(
_SSL_VERIFIED_POOL_KEY if ssl_verify_enabled else _SSL_UNVERIFIED_POOL_KEY,
lambda: _build_ssrf_client(verify=ssl_verify_enabled),
)关键设计:
- 客户端池化 :使用
get_pooled_http_client复用连接,提升性能 - SSL 验证分离 :验证和非验证客户端分别池化(
ssrf:verified/ssrf:unverified) - 代理配置优先级 :
- 优先使用
SSRF_PROXY_ALL_URL(同时代理 HTTP 和 HTTPS) - 其次使用
SSRF_PROXY_HTTP_URL+SSRF_PROXY_HTTPS_URL(分别代理) - 最后直连( 无 SSRF 防护)
- 优先使用
响应检测 - 识别 Squid 拦截
python
# Check for SSRF protection by Squid proxy
if response.status_code in (401, 403):
# Check if this is a Squid SSRF rejection
server_header = response.headers.get("server", "").lower()
via_header = response.headers.get("via", "").lower()
# Squid typically identifies itself in Server or Via headers
if "squid" in server_header or "squid" in via_header:
raise ToolSSRFError(
f"Access to '{url}' was blocked by SSRF protection. "
f"The URL may point to a private or local network address. "
)重试机制 - 指数退避
python
retries = 0
while retries <= max_retries:
try:
# Preserve the user-provided Host header
# httpx may override the Host header when using a proxy
headers = {k: v for k, v in headers.items() if k.lower() != "host"}
if user_provided_host is not None:
headers["host"] = user_provided_host
kwargs["headers"] = headers
response = client.request(method=method, url=url, **kwargs)
# Check for SSRF protection by Squid proxy
if response.status_code in (401, 403):
# Check if this is a Squid SSRF rejection
server_header = response.headers.get("server", "").lower()
via_header = response.headers.get("via", "").lower()
# Squid typically identifies itself in Server or Via headers
if "squid" in server_header or "squid" in via_header:
raise ToolSSRFError(
f"Access to '{url}' was blocked by SSRF protection. "
f"The URL may point to a private or local network address. "
)
if response.status_code not in STATUS_FORCELIST:
return response
else:
logger.warning(
"Received status code %s for URL %s which is in the force list",
response.status_code,
url,
)
except httpx.RequestError as e:
logger.warning("Request to URL %s failed on attempt %s: %s", url, retries + 1, e)
if max_retries == 0:
raise
retries += 1
if retries <= max_retries:
time.sleep(BACKOFF_FACTOR * (2 ** (retries - 1)))
raise MaxRetriesExceededError(f"Reached maximum retries ({max_retries}) for URL {url}")重试策略:
python
# 第 1 次失败:等待 0.5 * (2^0) = 0.5 秒
# 第 2 次失败:等待 0.5 * (2^1) = 1.0 秒
# 第 3 次失败:等待 0.5 * (2^2) = 2.0 秒
# 第 4 次失败:抛出 MaxRetriesExceededError触发重试的状态码:
python
STATUS_FORCELIST = [429, 500, 502, 503, 504]
# 429 - 请求过多
# 500 - 服务器内部错误
# 502 - 网关错误
# 503 - 服务不可用
# 504 - 网关超时** 配置选项(.env 文件)**
shell
SSRF_DEFAULT_MAX_RETRIES: PositiveInt = Field(
description="Maximum number of retries for network requests (SSRF)",
default=3,
)
SSRF_PROXY_ALL_URL: str | None = Field(
description="Proxy URL for HTTP or HTTPS requests to prevent Server-Side Request Forgery (SSRF)",
default=None,
)
SSRF_PROXY_HTTP_URL: str | None = Field(
description="Proxy URL for HTTP requests to prevent Server-Side Request Forgery (SSRF)",
default=None,
)
SSRF_PROXY_HTTPS_URL: str | None = Field(
description="Proxy URL for HTTPS requests to prevent Server-Side Request Forgery (SSRF)",
default=None,
)
SSRF_DEFAULT_TIME_OUT: PositiveFloat = Field(
description="The default timeout period used for network requests (SSRF)",
default=5,
)
SSRF_DEFAULT_CONNECT_TIME_OUT: PositiveFloat = Field(
description="The default connect timeout period used for network requests (SSRF)",
default=5,
)
SSRF_DEFAULT_READ_TIME_OUT: PositiveFloat = Field(
description="The default read timeout period used for network requests (SSRF)",
default=5,
)
SSRF_DEFAULT_WRITE_TIME_OUT: PositiveFloat = Field(
description="The default write timeout period used for network requests (SSRF)",
default=5,
)
SSRF_POOL_MAX_CONNECTIONS: PositiveInt = Field(
description="Maximum number of concurrent connections for the SSRF HTTP client",
default=100,
)
SSRF_POOL_MAX_KEEPALIVE_CONNECTIONS: PositiveInt = Field(
description="Maximum number of persistent keep-alive connections for the SSRF HTTP client",
default=20,
)
SSRF_POOL_KEEPALIVE_EXPIRY: PositiveFloat | None = Field(
description="Keep-alive expiry in seconds for idle SSRF connections (set to None to disable)",
default=5.0,
)配置示例( .env):
bash
# 使用 Squid 代理
SSRF_PROXY_HTTP_URL=http://ssrf_proxy:3128
SSRF_PROXY_HTTPS_URL=http://ssrf_proxy:3128
# 超时配置
SSRF_DEFAULT_TIME_OUT=10
SSRF_DEFAULT_CONNECT_TIME_OUT=5
# 连接池配置
SSRF_POOL_MAX_CONNECTIONS=200
SSRF_POOL_MAX_KEEPALIVE_CONNECTIONS=50第二层:代理层防护(Squid Proxy)
核心文件: docker/ssrf_proxy/squid.conf.template
ACL(访问控制列表)- 黑名单机制
shell
acl localnet src 0.0.0.1-0.255.255.255 # RFC 1122 "this" network (LAN)
acl localnet src 10.0.0.0/8 # RFC 1918 local private network (LAN)
acl localnet src 100.64.0.0/10 # RFC 6598 shared address space (CGN)
acl localnet src 169.254.0.0/16 # RFC 3927 link-local (directly plugged) machines
acl localnet src 172.16.0.0/12 # RFC 1918 local private network (LAN)
acl localnet src 192.168.0.0/16 # RFC 1918 local private network (LAN)
acl localnet src fc00::/7 # RFC 4193 local private network range
acl localnet src fe80::/10 # RFC 4291 link-local (directly plugged) machines
acl SSL_ports port 443
# acl SSL_ports port 1025-65535 # Enable the configuration to resolve this issue: https://github.com/langgenius/dify/issues/12792
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
acl allowed_domains dstdomain .marketplace.dify.ai
http_access allow allowed_domains
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost manager
http_access deny manager
http_access allow localhost
include /etc/squid/conf.d/*.conf
http_access deny all被拦截的 IP 范围(RFC 1918 私有地址):
10.0.0.0/8→ 10.0.0.0 - 10.255.255.255172.16.0.0/12→ 172.16.0.0 - 172.31.255.255192.168.0.0/16→ 192.168.0.0 - 192.168.255.255127.0.0.0/8→ 127.0.0.0 - 127.255.255.255(localhost)169.254.0.0/16→ 链路本地地址
性能优化配置
shell
################################## Performance & Concurrency ###############################
# Increase file descriptor limit for high concurrency
max_filedescriptors 65536
# Timeout configurations for image requests
connect_timeout 30 seconds
request_timeout 2 minutes
read_timeout 2 minutes
client_lifetime 5 minutes
shutdown_lifetime 30 seconds
# Persistent connections - improve performance for multiple requests
server_persistent_connections on
client_persistent_connections on
persistent_request_timeout 30 seconds
pconn_timeout 1 minute
# Connection pool and concurrency limits
client_db on
server_idle_pconn_timeout 2 minutes
client_idle_pconn_timeout 2 minutes
# Quick abort settings - don't abort requests that are mostly done
quick_abort_min 16 KB
quick_abort_max 16 MB
quick_abort_pct 95
# Memory and cache optimization
memory_cache_mode disk
cache_mem 256 MB
maximum_object_size_in_memory 512 KB
# DNS resolver settings for better performance
dns_timeout 30 seconds
dns_retransmit_interval 5 seconds
# By default, Squid uses the system's configured DNS resolvers.
# If you need to override them, set dns_nameservers to appropriate servers
# for your environment (for example, internal/corporate DNS). The following
# is an example using public DNS and SHOULD be customized before use:
# dns_nameservers 8.8.8.8 8.8.4.4
# Logging format for better debugging
logformat dify_log %ts.%03tu %6tr %>a %Ss/%03>Hs %<st %rm %ru %[un %Sh/%<a %mt
access_log daemon:/var/log/squid/access.log dify_log
# Access log to track concurrent requests and timeouts
logfile_rotate 10关键优化:
- 高并发支持 :
max_filedescriptors 65536- 支持 65k 并发连接 - 持久连接:复用 TCP 连接,减少握手开销
- 快速中止:95% 完成的请求不中止,避免浪费
- 内存缓存:256MB 缓存,加速重复请求
第三层:网络层防护(Docker 网络隔离)
核心文件: docker/docker-compose.middleware.yaml
yaml
# https://docs.dify.ai/learn-more/faq/install-faq#18-why-is-ssrf-proxy-needed%3F
ssrf_proxy:
image: ubuntu/squid:latest
restart: always
volumes:
- ./ssrf_proxy/squid.conf.template:/etc/squid/squid.conf.template
- ./ssrf_proxy/docker-entrypoint.sh:/docker-entrypoint-mount.sh
entrypoint:
[
"sh",
"-c",
"cp /docker-entrypoint-mount.sh /docker-entrypoint.sh && sed -i 's/\r$$//' /docker-entrypoint.sh && chmod +x /docker-entrypoint.sh && /docker-entrypoint.sh",
]
env_file:
- ./middleware.env
environment:
# pls clearly modify the squid env vars to fit your network environment.
HTTP_PORT: ${SSRF_HTTP_PORT:-3128}
COREDUMP_DIR: ${SSRF_COREDUMP_DIR:-/var/spool/squid}
REVERSE_PROXY_PORT: ${SSRF_REVERSE_PROXY_PORT:-8194}
SANDBOX_HOST: ${SSRF_SANDBOX_HOST:-sandbox}
SANDBOX_PORT: ${SANDBOX_PORT:-8194}
ports:
- "${EXPOSE_SSRF_PROXY_PORT:-3128}:${SSRF_HTTP_PORT:-3128}"
- "${EXPOSE_SANDBOX_PORT:-8194}:${SANDBOX_PORT:-8194}"
networks:
- ssrf_proxy_network
- default网络隔离原理:
- Dify API 和 Worker 在
default网络 - Squid Proxy 同时在
default和ssrf_proxy_network - 所有外部请求必须通过 Proxy 出站
- Proxy 根据 ACL 规则拦截内网请求
场景
**场景 1:正常请求 ****https://example.com/api**
| 步骤 | 层级 | 操作 | 结果 |
|---|---|---|---|
| 1️⃣ | 应用层 | **ssrf_proxy.get(url)**** 被调用** |
进入统一入口 |
| 2️⃣ | 应用层 | **_get_ssrf_client()**** 获取代理客户端** |
**配置 ****http://ssrf_proxy:3128** |
| 3️⃣ | 应用层 | **client.request(method, url)**** 发起请求** |
请求发送到 Squid |
| 4️⃣ | 代理层 | **Squid ACL 检查 ****example.com:443** |
✅** 端口 443 在白名单** |
| 5️⃣ | 代理层 | Squid ACL 检查域名 | ✅** 非内网域名** |
| 6️⃣ | 代理层 | Squid 建立连接 | ✅** 通过网关出站** |
| 7️⃣ | 网络层 | Docker 网络路由 | ✅** 从 **ssrf_proxy_network** 出站** |
| 8️⃣ | 代理层 | **接收响应 ****200 OK** |
添加 **Via: squid** 头 |
| 9️⃣ | 应用层 | **检查响应码 ****200** |
✅** 非拦截状态码** |
| 🔟 | 应用层 | 返回数据给用户 | ✅** 请求成功** |
**场景 2:SSRF 攻击 ****http://192.168.1.100/admin**
| 步骤 | 层级 | 操作 | 结果 |
|---|---|---|---|
| 1️⃣ | 应用层 | 恶意用户提交内网 URL | 进入统一入口 |
| 2️⃣ | 应用层 | **_get_ssrf_client()**** 配置代理** |
强制路由到 Squid |
| 3️⃣ | 应用层 | **发起请求到 ****192.168.1.100** |
请求发送到 Squid |
| 4️⃣ | 代理层 | Squid ACL 检查 IP 地址 | ❌** 匹配 **localnet** 规则** |
| 5️⃣ | 代理层 | **触发 ****http_access deny all** |
拒绝请求 |
| 6️⃣ | 代理层 | **返回 ****403 Forbidden** |
添加 **Server: squid** 头 |
| 7️⃣ | 应用层 | **检查 ****status_code == 403** |
进入拦截检测 |
| 8️⃣ | 应用层 | **检测响应头 ****"squid" in headers** |
✅** 确认是 Squid 拦截** |
| 9️⃣ | 应用层 | **raise ToolSSRFError(...)** |
抛出安全异常 |
| 🔟 | 应用层 | 返回错误给用户 | ❌** SSRF 攻击被阻止** |
关键代码对应关系
场景 1:正常请求
python
# ============ 场景 1:正常请求 ============
# 步骤 1-3:应用层入口
response = ssrf_proxy.get("https://example.com/api")
↓
make_request("GET", url)
↓
_get_ssrf_client(ssl_verify=True)
↓
client = httpx.Client(proxy="http://ssrf_proxy:3128")
# 步骤 4-6:代理层检查(Squid)
# squid.conf.template 第 22-30 行
acl allowed_domains dstdomain .marketplace.dify.ai # 域名白名单
http_access allow allowed_domains
http_access deny !Safe_ports # 端口白名单
http_access deny CONNECT !SSL_ports # SSL 端口限制
http_access deny all # 默认拒绝
# 步骤 9-10:应用层响应检测
# ssrf_proxy.py 第 164-176 行
if response.status_code in (401, 403):
server_header = response.headers.get("server", "").lower()
if "squid" in server_header:
raise ToolSSRFError("Access blocked by SSRF protection")场景 2:SSRF 攻击被拦截
python
# ============ 场景 2:SSRF 攻击被拦截 ============
# 步骤 1-3:恶意请求进入
response = ssrf_proxy.get("http://192.168.1.100/admin")
↓
make_request("GET", "http://192.168.1.100/admin")
# 步骤 4-6:代理层拦截(Squid)
# squid.conf.template 第 1-6 行
acl localnet src 192.168.0.0/16 # 私有网络定义
...
http_access deny all # 拒绝访问
# Squid 返回:
# HTTP/1.1 403 Forbidden
# Server: squid/5.x
# Via: squid/5.x
# 步骤 7-9:应用层检测并抛异常
# ssrf_proxy.py 第 164-176 行
if response.status_code == 403: # ✅ 条件满足
if "squid" in response.headers.get("server"): # ✅ 检测到 squid
raise ToolSSRFError( # ❌ 抛出异常
"Access to '192.168.1.100' was blocked by SSRF protection"
)Host 头保留机制
python
# Preserve user-provided Host header
# When using a forward proxy, httpx may override the Host header based on the URL.
# We extract and preserve any explicitly set Host header to support virtual hosting.
user_provided_host = _get_user_provided_host_header(headers)
retries = 0
while retries <= max_retries:
try:
# Preserve the user-provided Host header
# httpx may override the Host header when using a proxy
headers = {k: v for k, v in headers.items() if k.lower() != "host"}
if user_provided_host is not None:
headers["host"] = user_provided_host
kwargs["headers"] = headers为什么要保留 Host 头?
- 虚拟主机(Virtual Hosting)需要正确的 Host 头
- httpx 使用代理时可能会篡改 Host 为代理地址
- 手动保留用户原始设置的 Host 头确保请求正确
** Squid 日志格式**
shell
# Logging format for better debugging
logformat dify_log %ts.%03tu %6tr %>a %Ss/%03>Hs %<st %rm %ru %[un %Sh/%<a %mt
access_log daemon:/var/log/squid/access.log dify_log
# Access log to track concurrent requests and timeouts
logfile_rotate 10日志字段解释:
%ts.%03tu- 时间戳(精确到毫秒)%6tr- 响应时间(6 位宽度)%>a- 客户端 IP%Ss/%03>Hs- Squid 状态 / HTTP 状态码%rm- 请求方法(GET/POST)%ru- 请求 URL
示例日志:
plain
1705123456.789 150 172.18.0.5 TCP_DENIED/403 0 GET http://192.168.1.1/ - HIER_NONE/- text/html
↑ ↑ ↑ ↑ ↑
时间 耗时 客户端IP 拒绝 内容类型小白总结
三层防护就像机场安检:
- 第一层(应用层) = 🎫 值机柜台
- 检查你的机票(请求配置)
- 确保你走正确的通道(强制代理)
- 发现问题立即拦截
- 第二层(代理层) = 🛂 安检通道
- X 光机扫描(ACL 规则检查)
- 危险物品黑名单(IP 黑名单)
- 只允许特定物品通过(端口白名单)
- 第三层(网络层) = 🚪 登机口隔离
- 不同航班分开登机(网络隔离)
- 只能从指定出口离开(网关控制)
- 无法串到其他航班(无法访问内网)
关键口诀:
应用强制代理,代理黑名单拦截,网络物理隔离
标准化回答话术(300字以内)
Dify 的系统架构设计及其在高并发下的可靠性保障
Dify 采用 Flask + Celery 的前后端分离架构,核心是 Low-Code DSL 驱动 :前端可视化编排生成标准 JSON DSL,持久化到 PostgreSQL 的 workflows.graph 字段,后端通过 GraphEngine 解析 DSL 并执行。
高并发解耦方案分三层:
- API 层(Flask + Gunicorn):仅处理轻量请求(鉴权、DSL 验证),通过 **SSE **实现流式输出,避免 Worker 阻塞。
- 任务层(Celery) :重计算任务(文档向量化、长文清洗)异步分发到 多队列 (
dataset普通队列、priority_datasetVIP 队列),配合 租户隔离队列(TenantIsolatedTaskQueue)防止单租户占满资源。 - 存储层(Redis + PostgreSQL):Redis 作为 Celery Broker 和分布式锁,PostgreSQL + pgvector 存储向量数据。
内网安全(SSRF)防御采用三层机制:
- Squid Proxy:所有 HTTP 节点请求强制转发,ACL 拦截内网 IP。
- 应用层检测 :识别 401/403 + Squid 响应头(
Via: squid),抛出ToolSSRFError。 - 连接池限流:限制最大连接数,防止攻击耗尽资源。
此外,DSL 版本冲突通过 Hash 校验 + 乐观锁 解决,支持历史版本回滚。整体架构实现了高并发、低延迟、安全可控的 AI 应用平台。
flask入口
为什么 Dify 使用工厂模式而不是全局 app 变量?
python
# ❌ 全局变量方式(不推荐)
app = Flask(__name__)
# 缺点:
# 1. 难以测试(无法创建多个独立实例)
# 2. 配置无法动态切换
# 3. 循环导入问题
# ✅ 工厂模式(推荐)
def create_app():
app = Flask(__name__)
return app
# 优点:
# 1. 测试时可创建独立实例
# 2. 可根据环境变量加载不同配置
# 3. 避免循环导入before_request 和 after_request 的执行顺序?
plain
请求到达
↓
before_request 1
↓
before_request 2
↓
路由处理函数
↓
after_request 2 (逆序!)
↓
after_request 1
↓
返回响应如果扩展加载失败会怎样?
python
# 当前实现:直接抛出异常,导致应用启动失败
ext.init_app(app) # 失败 → 整个应用无法启动
# 改进建议:
try:
ext.init_app(app)
except Exception as e:
logger.error(f"Failed to load {ext_name}: {e}")
if ext.is_critical(): # 关键扩展
raise # 重新抛出异常
else: # 非关键扩展
continue # 跳过,继续加载其他扩展workflow
为何使用 LongText 而非 JSONB
python
# ✅ 当前方案
graph: Mapped[str] = mapped_column(LongText)
# 优点:
# - 跨数据库兼容(PostgreSQL/MySQL/TiDB)
# - Dify 不需要查询 JSON 内部字段
# - 简单直观,无需处理 JSONB 序列化
# ❌ JSONB 方案
graph: Mapped[dict] = mapped_column(JSONB)
# 缺点:
# - 仅支持 PostgreSQL
# - 增加复杂度(需要 GIN 索引、查询语法)
# - Dify 的使用场景不需要 JSON 查询版本管理的关键设计
plain
Draft 版本:
- 只有一条记录(version='draft')
- 不断更新 graph 字段
- 用于用户编辑
Published 版本:
- 每次发布创建新记录(version='v1', 'v2', ...)
- 不可修改(immutable)
- 用于执行和回滚Hash 冲突检测的原理
plain
Hash = SHA256(graph + features + environment_variables + conversation_variables)
前端提交时携带 Hash → 后端对比 → 不匹配则拒绝 → 提示刷新Dify 如何解决SSE 流式输出阻塞Flask Worker 的问题
Dify 采用了 Python Queue + Redis 的双层解耦架构来解决 SSE 流式输出的阻塞问题。
核心设计:
- Flask Worker 只负责监听 :通过
AppQueueManager.listen()监听进程内的queue.Queue,使用get(timeout=1)非阻塞获取事件,最多等待 1 秒,不会长时间占用 Worker。 - Celery Worker 负责执行 :长时间运行的 Workflow 在 Celery Worker 中异步执行,每执行一步通过
queue_manager.publish()将事件放入 Python Queue。 - Redis 跨进程状态同步 :停止标志位 (
generate_task_stopped:{task_id}) 和任务归属验证 (generate_task_belong:{task_id}) 通过 Redis 共享,实现用户手动停止和权限校验。 - 性能优化 :使用
TTLCache (ttl=1秒)缓存 Redis 查询结果,避免频繁网络请求;每 10 秒发送心跳 (QueuePingEvent) 保持 SSE 连接不断开。
为什么选择 Python Queue 而非 Redis Pub/Sub?
因为 Dify 的 Flask 和 Celery 部署在同一台机器,进程内通信性能更高,Redis Pub/Sub 会引入额外的网络开销和消息丢失风险。
高并发保障 :Gunicorn 多进程模型 + Celery 多 Worker 配置,Flask Worker 通过 yield 生成器实时返回 SSE 事件,即使一个 Worker 在监听,其他 Worker 仍可处理新请求,系统并发能力不受影响。