介绍
Elasticsearch(简称 ES) 是一个开源的、分布式的、高度可扩展的搜索和分析引擎。
ES 经常与 Logstash(数据收集和处理管道)和 Kibana(数据可视化)一起使用,组成著名的 ELK Stack(现在官方称为 Elastic Stack),能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
核心区别:
- 结构化数据(固定的数据模型和格式),例子:关系型数据库(MySQL, Oracle)表中的数据
- 半结构化数据(具有某种结构,但格式不固定),例子:NoSQL数据库、文件系统
- 非结构化数据(没有预定义的数据模型或格式),例子:文本文档、图片、音频、视频、PDF
安装
ES的官方地址:https://www.elastic.co/cn/
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
7.8版本下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
目录结构:
- bin 可执行脚本目录
- config 配置目录
- jdk 内置 JDK 目录(可替换)
- lib 类库
- logs 日志目录
- modules 模块目录
- plugins 插件目录
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
注意:9300 端口为 ES集群间组件的通信端口, 9200 端口为浏览器访问的 http协议 RESTful 端口。
打开浏览器,输入地址: http://localhost:9200,有一串json代表安装成功。
yml
如果安装失败,可能空间不足,修改 config/jvm.options 配置文件:
# 设置 JVM 初始内存为 1G。此值可以设置与-Xmx 相同,以避免每次垃圾回收完成后 JVM 重新分配内存
# Xms represents the initial size of total heap space
# 设置 JVM 最大可用内存为 1G
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g数据格式
ES是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 ES里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。
ES 里的 Index 可以看做一个库,而 Types 相当于表(7版本后已经删除),Documents 则相当于表的行。
- 正排索引(文档 -> 包含哪些词),通过文档ID快速获取文档内容
- 倒排索引(词 -> 出现在哪些文档?),通过关键词快速查找包含它的所有文档
HTTP 基本操作
索引操作
对比关系型数据库,创建索引就等同于创建数据库。
创建索引
http
# 创建索引 shopping是索引名,注意:PUT请求具有幂等性
PUT http://localhost:9200/shopping
Content-Type:application/json
# 返回响应:
{
"acknowledged": true, //响应结果
"shards_acknowledged": true, //分片结果
"index": "shopping" //索引名称
}查询索引
http
# 查询索引 shopping是索引名
GET http://localhost:9200/shopping删除索引
http
# 删除索引 shopping是索引名
DELETE http://localhost:9200/shopping查看所有索引
http
# _cat 表示查看的意思, indices 表示索引,相当于Mysql的show tables
GET http://localhost:9200/_cat/indices?v
# 返回响应:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shopping J0WlEhh4R7aDrfIc3AkwWQ 1 1 0 0 208b 208b
-----解释-----
health 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status 索引打开、关闭状态
index 索引名
uuid 索引统一编号
pri 主分片数量
rep 副本数量
docs.count 可用文档数量
docs.deleted 文档删除状态(逻辑删除)
store.size 主分片和副分片整体占空间大小
pri.store.size 主分片占空间大小文档操作
这里的文档可以类比为关系型数,据库中的表数据,添加的数据格式为 JSON 格式。
文档创建
http
# 创建文档, shopping是索引名, 在该索引创建文档 (返回的_id,会随机生成)
POST http://localhost:9200/shopping/_doc
Content-Type:application/json
{
"title": "小米",
"value": "content",
"price": 3999
}
# 返回响应:
{
"_index": "shopping", //索引
"_type": "_doc", //类型-文档
"_id": "ANQqsHgBaKNfVnMbhZYU", //唯一标识,可以类比为 MySQL中的主键,随机生成
"_version": 1, //版本
"result": "created", //结果,这里的 create 表示创建成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
# 如果想要自定义唯一性标识, 101就是唯一标识
POST http://localhost:9200/shopping/_doc/101
Content-Type:application/json
{
"title": "小米2",
"value": "content",
"price": 3999
}主键查询 & 全查询
http
# 根据主键查询
GET http://localhost:9200/shopping/_doc/101
# 查询该索引下,全部文档
GET http://localhost:9200/shopping/_search全量修改 & 局部修改 & 删除
http
# 全量修改,将原有的数据内容进行覆盖,101就是唯一标识
PUT http://localhost:9200/shopping/_doc/101
Content-Type:application/json
{
"title": "小米2-修改",
"value": "content-修改",
"price": 3999
}
# 局部修改,只修改某一给条数据的局部信息,101就是唯一标识
POST http://localhost:9200/shopping/_update/101
Content-Type:application/json
{
"doc": {
"title": "修改华为"
}
}
# 删除某一个文档,101就是唯一标识,注意:删除一个文档不会立即从磁盘上移除
DELETE http://localhost:9200/shopping/_doc/101
# 再查看是否删除成功
GET http://localhost:9200/shopping/_doc/101
# 返回响应:foun=false,代表成功
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"found": false
}
# 条件删除文档
POST http://localhost:9200/shopping/_delete_by_query
Content-Type:application/json
{
"query": {
"match": {
"price":3999
}
}
}条件查询
http
# 条件查询:方式1:查询title=小米
GET http://localhost:9200/shopping/_search?q=title:小米
# 条件查询:方式2:查询title=小米
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query": {
"match": {
"title": "小米"
}
}
}
# 字段匹配查询,在多个字段中查询
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"multi_match": {
"query": "小米",
"fields": ["title","value"]
}
}
}
# 全查询
#GET http://localhost:9200/shopping/_search
#Content-Type:application/json
{
"query":{
"match_all":{}
}
}
# 查询指定字段
#GET http://localhost:9200/shopping/_search
#Content-Type:application/json
{
"query":{
"match_all":{}
},
"_source":["title","price"] // 只展示title,其他字段不展示
}分页查询 & 查询排序
http
# 分页查询
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"match_all":{}
},
"from":0, //当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * size
"size":2 //每页显示多少条
}
# 查询排序
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"match_all":{}
},
"sort":{
"price":{ // 排序字段
"order":"desc" // desc 降序,asc 升序
},
"title":{ // 排序字段
"order":"desc" // desc 降序,asc 升序
}
}
}多条件查询 & 范围查询
http
# bool组合查询通过:must(必须)、must_not(必须不)、should(应该)进行组合
# 多条件查询,查询小米,价格为3999元的。(must相当于数据库的&&)
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"bool":{
"must":[{ // 并且
"match": {"title":"小米"}
},{
"match": {"price":3999}
}]
}
}
}
# 多条件查询,查询小米和华为。(should相当于数据库的||)
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"bool":{
"should":[{ // 或者
"match":{"title":"小米"}
},{
"match":{"title":"华为"}
}]
},
"filter":{ // 范围查询:价格大于2000元的
"range":{
"price":{"gt":2000 }
}
}
}
}
# 范围查询:range 查询允许以下字符
gt 大于>
gte 大于等于>=
lt 小于<
lte 小于等于<=全文检索 & 完全匹配 & 高亮查询
http
# 全文检索
# 如搜索引擎那样,输入"小华",返回结果带回品牌有小米和华为的数据
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"match":{
"title" : "小华"
}
}
}
# 完全匹配
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"match_phrase":{
"title" : "为"
}
}
}
# 高亮查询,highlight 高亮显示
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"query":{
"match_phrase":{
"title" : "为"
}
},
"highlight":{
"fields":{
"title":{} //<----高亮这字段
}
}
// "highlight": {
// "pre_tags": "<font color='red'>", //前置标签
// "post_tags": "</font>", //后置标签
// "fields": { //需要高亮的字段
// "name": {}
// }
// }
}聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等。
http
# 聚合操作 terms 分组
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"aggs":{ //聚合操作
"price_group":{ //名称,可以随意起名
"terms":{ //分组
"field":"price" //聚合字段
}
}
},
"size":0 // 不显示全量数据,hits里不再返回数据
}
# 聚合操作 avg 平均值
GET http://localhost:9200/shopping/_search
Content-Type:application/json
{
"aggs":{ //聚合操作
"price_avg":{ //名称,随意起名
"avg":{ //求平均值
"field":"price" //聚合字段
}
}
},
"size":0
}映射关系
类似于数据库(database)中的表结构(table),创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
http
# 创建映射,还可以通过GET进行查询
PUT http://localhost:9200/user/_mapping
Content-Type:application/json
{
"properties": {
"name":{
"type": "text", //可分词
"index": true //是否索引,默认为 true,可以用来搜索
},
"sex":{
"type": "keyword", //不可分词,数据会作为完整字段进行匹配
"index": true
},
"tel":{
"type": "keyword",
"index": false //字段不会被索引,不能用来搜索
}
}
}
# 其他映射数据说明
store:是否将数据进行独立存储,默认为 false
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器JavaAPI-环境准备
可在我的码云ES项目,有JAVA项目连接ES,进行基本API操作。
Elasticsearch环境
集群 Cluster
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就是"elasticsearch"。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
节点 Node
集群中包含很多服务器, 一个节点就是其中的一个服务器。 作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
例子:节点1存入数据a、数据b;节点2存入数据c、数据d;查询数据c,需要访问节点2。
Windows集群部署
步骤1:部署集群
创建 elasticsearch-cluster 文件夹,分别在该目录下创建node1、node2、node3文件夹,分别安装ES服务;
步骤2:修改配置文件
每个节点的 config/elasticsearch.yml 配置文件
node1节点配置
yml
# 节点1-配置信息:
# 集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
# 节点名称,集群内要唯一
node.name: node-1
node.master: true
node.data: true
# ip 地址
network.host: localhost
# http 端口
http.port: 1001
# tcp 监听端口
transport.tcp.port: 9301
# 跨域配置
# action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"node2节点配置
yml
# 节点2-配置信息:
# 集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
# 节点名称,集群内要唯一
node.name: node-2
node.master: true
node.data: true
# ip 地址
network.host: localhost
# http 端口
http.port: 1002
# tcp 监听端口
transport.tcp.port: 9302
# 节点发现其他节点,查询node1节点
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# 跨域配置
# action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"node3节点配置
yml
# 节点3-配置信息:
# 集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
# 节点名称,集群内要唯一
node.name: node-3
node.master: true
node.data: true
network.host: localhost
http.port: 1003
transport.tcp.port: 9303
# 候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 跨域配置
# action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"步驟3:启动服务
分别启动每个服务,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
注意:启动前删除每个节点中的 data 目录中所有内容、和logs目录里日志文件。
步骤4:测试集群
访问机器节点状态:
GET http://127.0.0.1:1001/_cluster/healthGET http://127.0.0.1:1002/_cluster/healthGET http://127.0.0.1:1003/_cluster/health
json
# 访问:http://localhost:1001/_cluster/health
# 响应结果:
{
"cluster_name": "my-application",
"status": "green", // green 所有的主分片和副本分片都正常运行。
// yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
// red:有主分片没能正常运行。
"timed_out": false,
"number_of_nodes": 3, // 集群中有3个节点
"number_of_data_nodes": 3, // 集群中有3个数据节点
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}Linux集群部署
Elasticsearch 7.8.0下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
待补充:
Elasticsearch进阶
核心概念
- 索引(Index):一个索引就是一个拥有几分相似特征的文档的集合,为了提高搜索的性能
- 类型(Type):默认不再支持自定义索引类型(默认类型为: _doc)
- 文档(Document):是一条数据,以 JSON格式标识
- 字段(Field):相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
- 映射(Mapping):某个字段的数据类型、默认值、分析器、是否被索引等
- 分片(Shards):一个索引可以存储超出单个节点硬件限制的大量数据,相当于Mysql中的分表
- 副本(Replicas):避免数据丢失,将数据进行多个备份
- 分配(Allocation):将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
系统架构
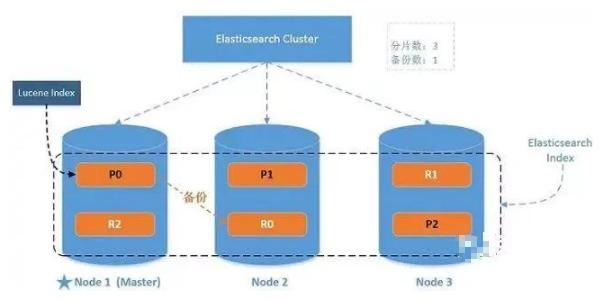
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 任何节点都可以成为主节点。
如图:有3个Node节点,Node1是主节点,P0的备份数据在Node2上,P1的备份数据在Node3上,P2的备份数据在Node1上,每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。