这一篇我将讲解C++中 仿函数 和 模板的进阶内容。
目录
[1.1利用仿函数完善上一篇 优先级队列 的代码](#1.1利用仿函数完善上一篇 优先级队列 的代码)
[1.2.1仿函数控制比较 指针指向的内容](#1.2.1仿函数控制比较 指针指向的内容)
[1.2.2仿函数 的 细节问题](#1.2.2仿函数 的 细节问题)
[1.2.3 算法中的仿函数](#1.2.3 算法中的仿函数)
[2.1 容器 array C++提供的静态数组](#2.1 容器 array C++提供的静态数组)
[2.2 array 与 a 10 的比较](#2.2 array 与 a [10] 的比较)
[2.2.3 两者都可以用sort函数排序](#2.2.3 两者都可以用sort函数排序)
[2.3.1.0 传递指针使用堆时模板传参的问题分析与办法](#2.3.1.0 传递指针使用堆时模板传参的问题分析与办法)
[2.3.3 vector](#2.3.3 vector)
[2.4 偏特化 / 半特化 (之前都是全特化)](#2.4 偏特化 / 半特化 (之前都是全特化))
[2.4.1 偏特化:限制是指针 / 引用,也可以和普通类型混用。](#2.4.1 偏特化:限制是指针 / 引用,也可以和普通类型混用。)
[2.5 模板的分离编译(.h和.cpp声明定义分离)](#2.5 模板的分离编译(.h和.cpp声明定义分离))
[2.5.1 编译链接,从根本理解为什么模板不能分离编译](#2.5.1 编译链接,从根本理解为什么模板不能分离编译)
1.仿函数
上一篇博主讲解了priority_queue的底层代码,其设计到了 仿函数,库里通过仿函数less和greater即可轻易调整 大堆、小堆之间的变化。如果不使用仿函数,我们最简单的方法就是去手动修改向上调整 和 向下调整 的比较逻辑,这很简单,也很麻烦。当然也可以使用函数指针进行操作。但是函数指针的定义很恶心,不好使用,C++为了避免函数指针就搞出了 仿函数 。
函数指针的定义:
仿函数就是一个类,类重载了一个运算符**()**,重载了这个运算符的类都可以叫仿函数。这使得这个类可以像函数一样使用:
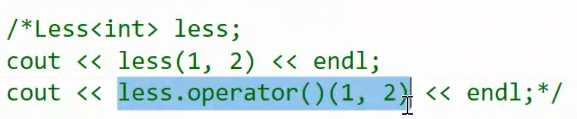
1.1利用仿函数完善上一篇 优先级队列 的代码
回到priority_queue 的底层,我们可以进一步完善它,我们像库里定义的那样,给它增加一个仿函数,使它可以转大堆为小堆:
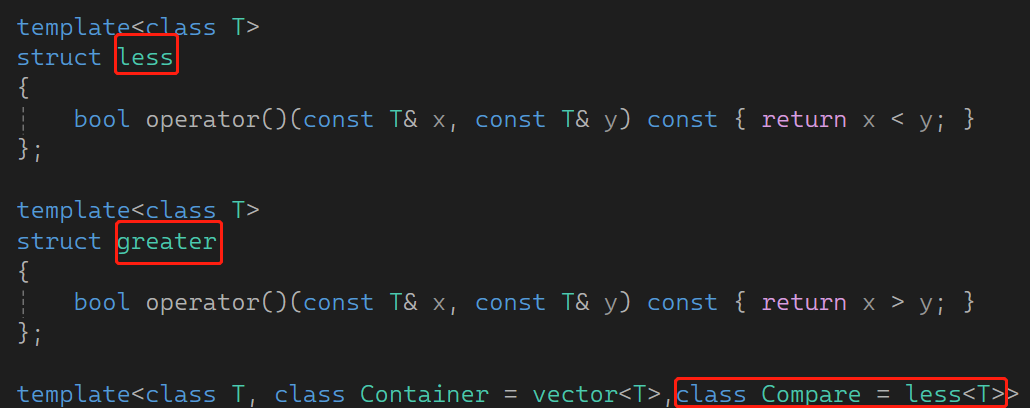
库里的less 和 greater 由于一些原因,导致大堆默认是less,小堆传greater ,很反直觉 。没办法我们将错就错也这样。然后,把向上,向下调整的比较逻辑都修改成仿函数:
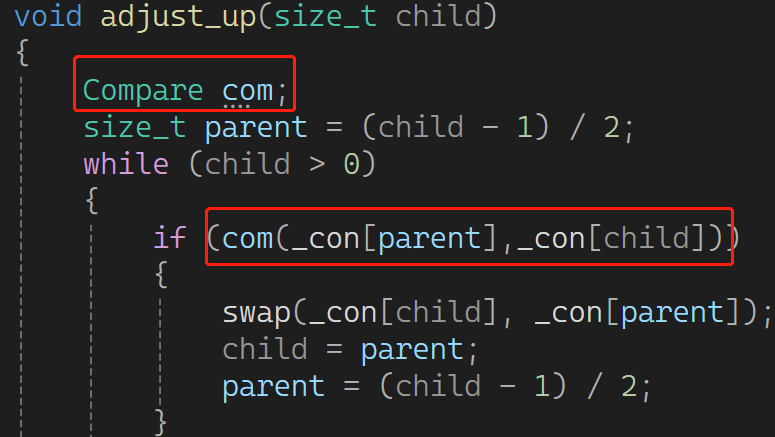
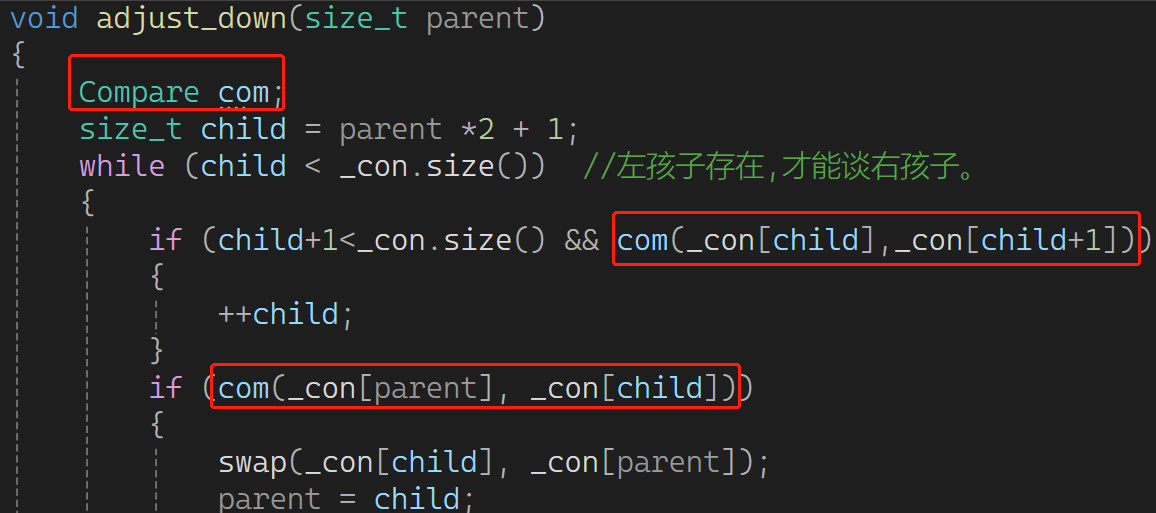
使用方面,改成小堆,只需要把缺省值less改成greater就行,十分简单:
其实compare参数作为第二个更好,不然每次都得把vector<T>这个参数补全。这也是设计不太完善的地方。

1.2仿函数的更多用途
1.2.1仿函数控制比较 指针指向的内容
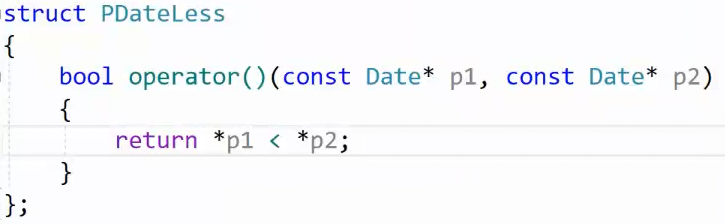
仿函数不只可以控制上面的简单数字比较逻辑,也可以封装、控制更复杂的逻辑,以下举例。现在假设我们实现了日期类,现在需要比较日期的大小。但是是通过传递指针 Date*:

比较结果错误:
并且结果不固定。 原因是我们比较的是指针的地址,new出来的地址存在很大的随机性,地址一会大一会小不固定,导致结果也一样。
那我们咋比较指针的指向内容? 通过仿函数,控制我们比较大小的逻辑 :
这时候比较结果就正确。


1.2.2仿函数 的 细节问题
|-----------|---------|----------|
| 函数 | 语言 | 参数区别 |
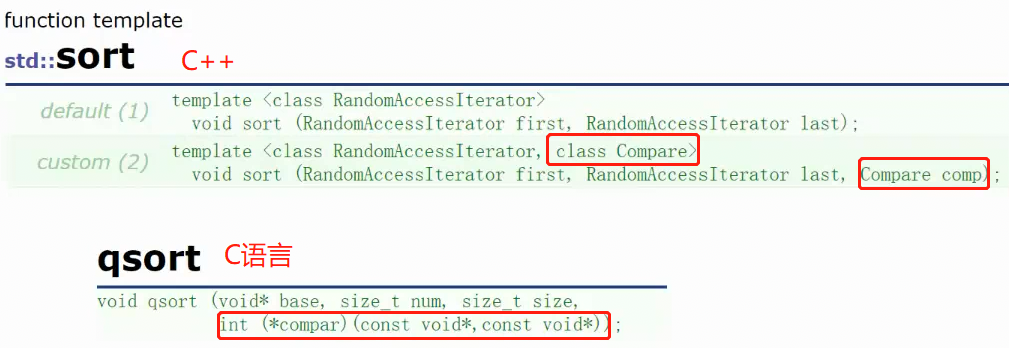
| sort | C++ | 仿函数 |
| qsort | C语言 | 函数指针 |
qsort的参数很长,函数指针形式,很复杂。小白哪怕老登都容易搞混写错。所以C++避免使用函数指


上图两个,参数都有仿函数。但这参数有什么区别? 用一个例子告诉你:
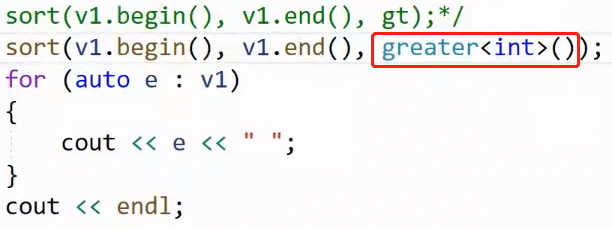
sort默认是升序,我们用 仿函数 greater 让它变成降序:没有问题吧?看起来很合理。那如果这样:
这是啥?为啥要加括号 ? 为啥我们写优先级队列(下图参数)又不需要加了?
其实问题很基础,也很关键:一个是传的对象,匿名对象 ,一个传的是类模板参数 的 实例化类型 。一个是对象,一个是类型。


1.2.3 算法中的仿函数
erase 是删除某个位置的值,remove是删除一个值。而 remove_if:
remove_if 其实是一个仿函数。 Predicate 是 以...为依据 的意思
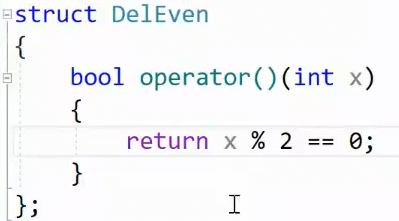
那这个Predicate pred 其实就是仿函数。让我们封装,控制一个判断条件,然后让remove_if 执行.假设我们要删除所有的偶数。

这大概就是remove_if 的实现,根据条件执行删除。 而它的仿函数也很简单。
find_if 也是用了仿函数
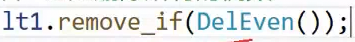

2.模板(进阶)
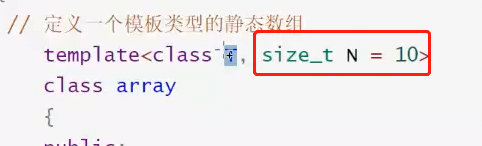
模板之前我们讲过,现在博主讲进阶的内容: 第一个,非类型模板参数。

通过这个,我们可以用整型定义常量作为模板参数:
有什么作用? 看接下来。如果我们是用宏定义定义一个N:
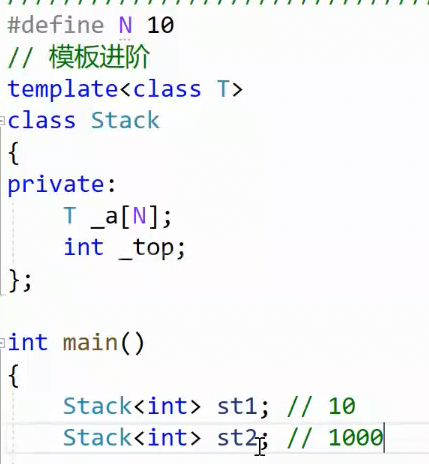
那就回到了一个宏定义经典问题:不能适配多种情况,比如我又需要空间1000,修改N就会导致st1浪费过多空间。
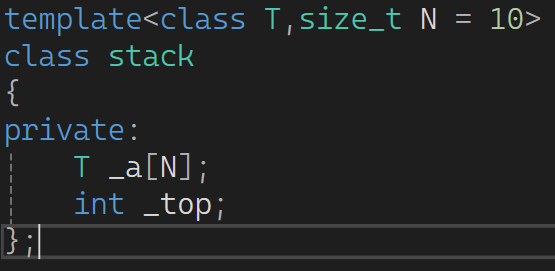
这就很好的解决的宏定义的问题。 同时注意,
C++20标准前,这个 非类型模板参数 N 都只支持 整型,指针,引用 。C++20添加了double 。目前不支持string等自定义类型。
2.1 容器 array C++提供的静态数组

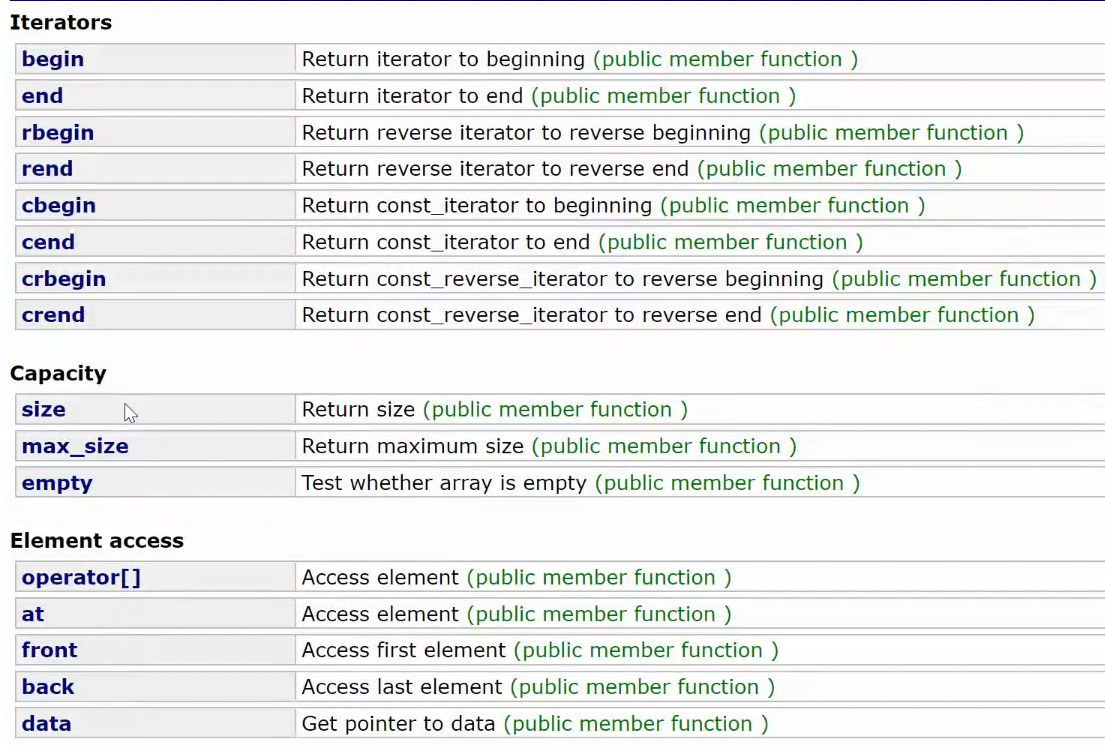
它是类模板,注意它的模板参数是 非类型模板参数 支持迭代器, 访问 以及各种常用接口。没有尾插尾删等,因为知道大小可以直接通过 随机访问。 **头文件是array,**设计的初衷是代替普通静态数组。
使用起来很简单,注意默认类型默认不会初始化,所以没写的值都是随机值
不过普通静态数组也支持,为什么大费周章封装一个array?接下来我会通过例子解释原因
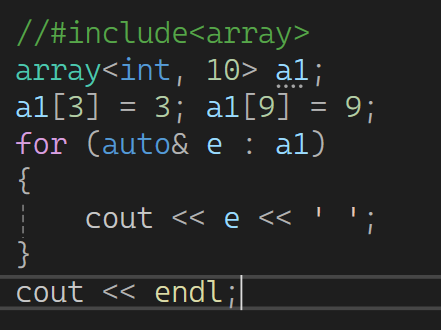

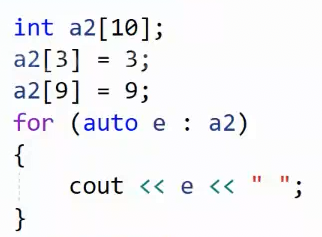
2.2 array<int , 10> 与 a 10 的比较
2.2.1容器适配容器
如果我想利用 list链表 设计一个动态二维数组,但是第二维不想用动态数组,想用静态数组,毕竟动态开辟难免有损耗:
 利用array可以这样操作,而普通的数组不好搞。总结就是 容器可以适配容器。这也是STL的核心优势之一。
利用array可以这样操作,而普通的数组不好搞。总结就是 容器可以适配容器。这也是STL的核心优势之一。
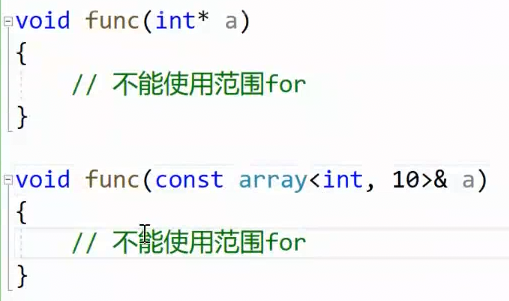
2.2.2函数传参,数组退化为指针
数组退化为指针,导致不能使用范围for了,但是array不会退化,是容器封装好了的,本质传的是容器而不是数组。
2.2.3 两者都可以用sort函数排序
指向数组的指针是天然的迭代器,C++标准明确:原生指针可以被当作 "随机访问迭代器" 使用
2.2.4数组越界检查不完全
数组会检查越界写,而且是抽查末尾附近,远了检查不出来。越界读根本不检查
根本原因:原生数组的编译后代码转化为指令,因为没存 N,不知道具体大小信息,很难检查。
array内部都会严格检查。因为他是运算符重载调用( 访问,肯定封装了检查),内存严格检查(有非类型模板参数,明确知道array空间大小。基于这个确定的N,array检查完美无暇。)
2.3模板的特化
特化,那就是特殊化处理。 什么是特殊化处理?举个刚刚讲过的例子:

对于这个熟悉的例子,我们不希望比较指针,而是比较指针指向的内容,那可以对这种情况特殊化处理:
特化的特点:实例化一个类模板。它的类型更匹配,编译就会使用这个模板。
比较一下通用的模板:
特化版本 <>是空的,并且函数名添加了<具体类型>,参数也标注了具体类型。
如图,我用红笔标注了.
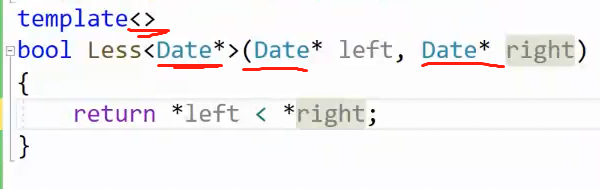

这只是小case,在这基础之上接下来举一个更容易混淆的例子
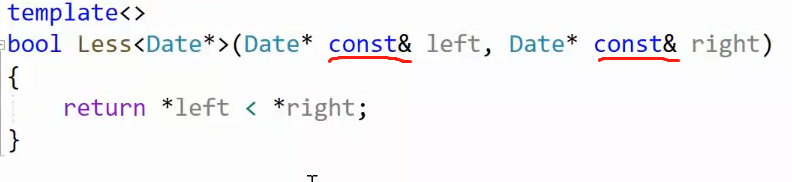
2.3.1指针作为模板特化的参数
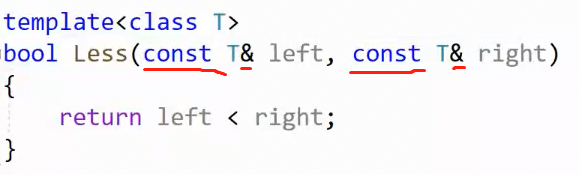
不需要改变的参数都要用const修饰保证数据安全,并且需要 引用 来提升传参效率。
基于此,如果我们需要特化的是指针的模板:
看似没问题,实则编译不通过:
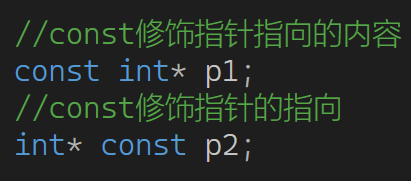
为什么会这样? 其实问题就出在 const。你期望const修饰引用,保护源数据的安全,但是因为指针有两种const修饰形式:1,修饰指针指向的内容,2,修饰指针本身不可改变指向。所以const Date*& 修饰了指针指向的内容,没修饰到引用对象。并且,此时你特化的是Date*,但是参数却是 const Date*
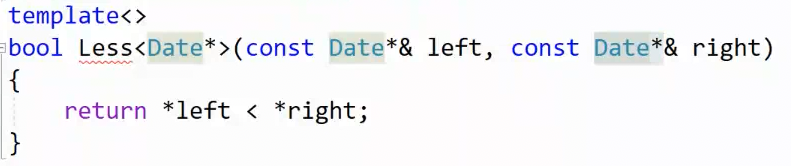
修改: Date* const & ,此时类型是 Date* ,const修饰引用对象,符合目的
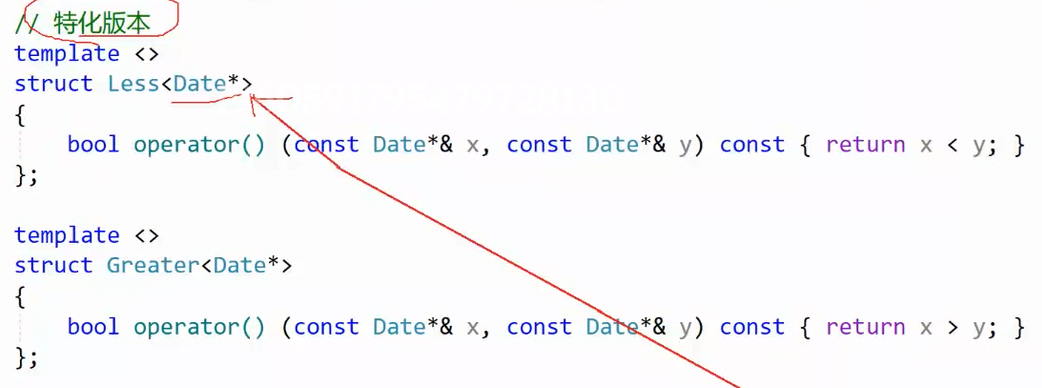
最终解答:
原const T& left,const修饰的是引用& 对象left,类型是T,const修饰引用对象。
const Date*& left,const Date*成为新类型,与Date*不一致,const不再修饰引用对象left,而是指针的内容,模板参数都不一样了,不能识别为特化模板,导致错误。
Date* const & left,const修饰引用对象left,而Date*作为类型和特化模板类型匹配,这才是正解。
也有其他解决办法。那就是直接写一个参数完全匹配的函数:这不是模板,也不是特化模板,模板和函数是可以同时存在的。编译器优先选择现成的函数,这某种程度上就解决了特化模板的问题。这个函数性质类似于特化版本。


2.3.1.0 传递指针使用堆时模板传参的问题分析与办法
用堆时,传Date* 过去会调用这个特化版本,但是会出现报错,问题出在堆内:
vecter<Date*> ,所以这两个是Date*类型,但是传参过去,特化版本是const Date*,这倒也是小问题,Date*可以权限缩小类型转换变成const Date*。 但是又有新问题了:
类型转换会产生临时变量(临时对象),而临时变量具有常性,所以特化版本需要常引用才能
兼容它。 那么办法就是改成常引用:
也可以简单点,直接去掉引用,这样会变成拷贝,效率低一点点。




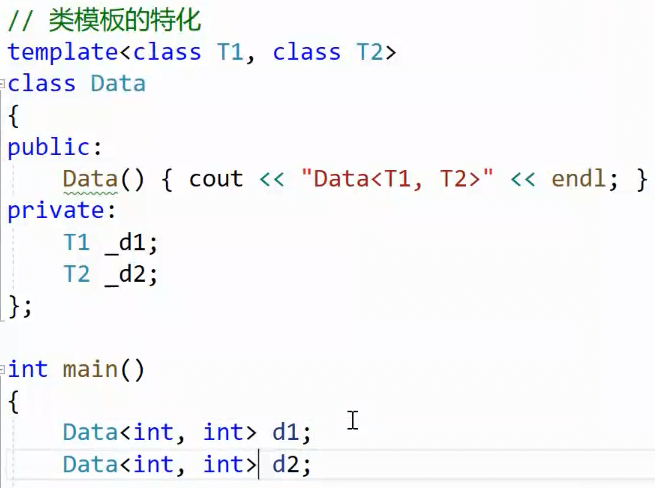
2.3.2类模板的特化
这里写了一个通用的类模板,
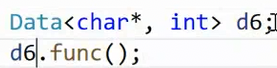
,d1,d2只能匹配这个模板。现在写一个它的特化版本:
上面的函数模板,特化类型写在函数名后,那类的特化类型,写在类名后。
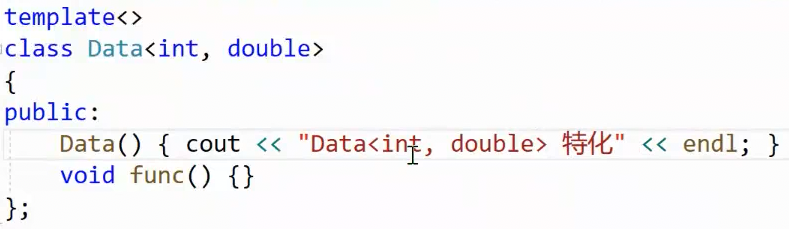
注意到私有成员删了,并且多了一个func函数。这引出一个概念:
类模板的特化,对内部成员不作要求。原模板定义的,特化模板可以不定义,甚至可以增加新的定义。
原本d2也可以匹配原模板,但是现在匹配特化版本去了,因为特化的int,double更符合参数。
特化版本可以认为是接近成品的东西了。
2.3.3 vector<bool>
之前vector没讲这个,vector<bool>就是vector通用模板的一个特化版本 。当vector存bool类型,就会调用特化版本,底层会用特殊方式处理,优化空间。为什么特化此版本?因为bool值是4字节,但是用4字节表示真与假,前辈们觉得用bool数组标记真假太浪费空间了。他们特化了此版本,为了优化空间,用 位 来标记真假。

如图,特化版本的成员可以完全不同。比如vector<bool> 新增了两个函数。
其实vector<bool> 用的是 偏特化/半特化去,下面我们来讲讲偏特化/半特化

2.4 偏特化 / 半特化 (之前都是全特化)
偏特化,有些地方也叫 半特化 ,就是不完全的特化,比如2个参数只特化了1个。
只要第一个是任意,第二个是char,就会匹配它。除非有更匹配的全特化:
这种情况下,如果是<double,double> ,图中的 全特化 没 偏特化 匹配。
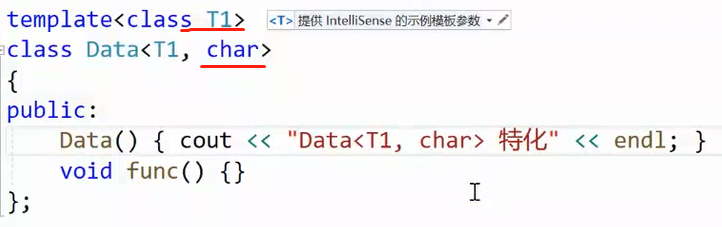

2.4.1 偏特化:限制是指针 / 引用,也可以和普通类型混用。
这样特化:也可以 限制了是指针。任意类型指针都可以
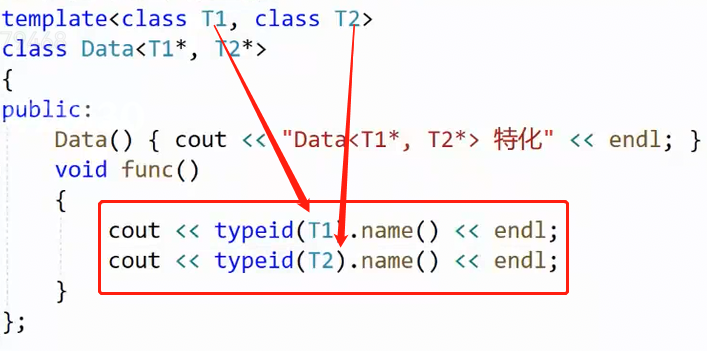
通过红框内的两个函数,可以查出类型名
可以观察T1,T2是不是指针:
意思就是,T1,T2是指针的时候才会匹配这个特化模板。传原类型不会匹配,传指针就会。
把T1*,T2*改成T1&,T2&,也有对应的效果:
这个限制也可以混杂在一起:
(只打印了参数一)



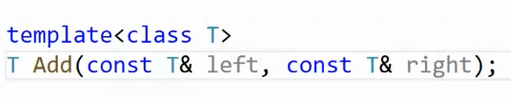
2.5 模板的分离编译(.h和.cpp声明定义分离)
我们之前讲模板初阶,提到过模板不能分离编译。那为什么呢?这次仔细解析
上面是模板,声明和定义分离在两个文件。
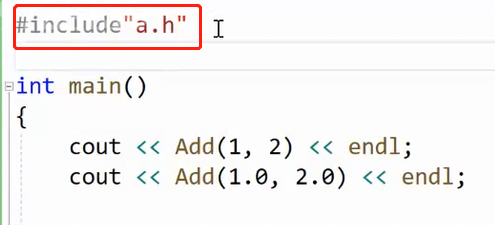
我们在第三个文件包模板的头文件,尝试使用该模板。就会报错:
这是 链接 错误。编译器找不到定义的时候,就会链接错误。
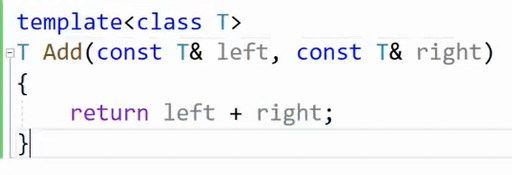
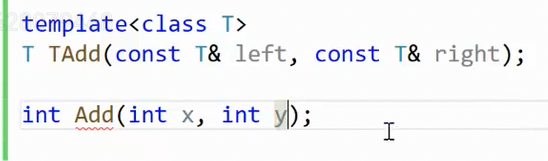
如果,我们定义一个真实存在但是分离编译的Add函数,和模板的TAdd区分开:
普通Add可以编译通过,但是TAdd依旧不可以:
所以为什么会这样?明明都有定义,偏要说找不到模板定义,链接错误?
这时候要从 编译链接 的过程开始讲。



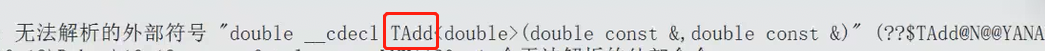
2.5.1 编译链接,从根本理解为什么模板不能分离编译
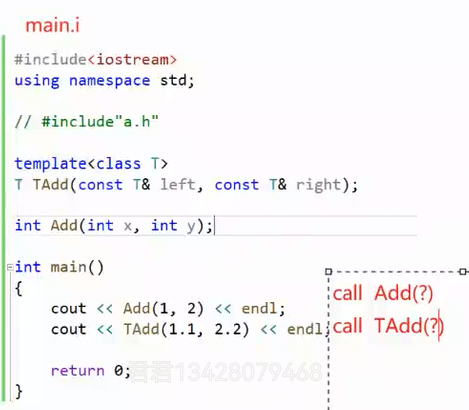
编译链接:我们一开始有 a.h,a.cpp,main.cpp 三个文件,第一步预处理:
a.h会展开,此时剩下两个文件,a.i 和 main.i
生成汇编代码,结合我们对反汇编的理解
函数调用会转化为 call 指令:
main.i 中没有函数的定义(分离了),找不到Add,TAdd函数的地址(地址:函数被编译为指令,这一串指令中的第一句指令的地址),定义在a.i文件中,这个阶段编译器不会去找别的文件(统一在链接时去找)。但是因为上面有函数声明,所以目前先确定可以编译通过,因为声明就是承诺会定义一个这个函数,后面可以找到地址。(这就像是承诺借你10万,但是钱还没给你呢,链接的时候再给你)
.o就是 .obj 文件,目标文件
到这,那链接错误的意思就是找不到这个函数的地址。
每个目标文件都会有一个叫符号表的东西,它会把函数的地址放在符号表内:
找到了就把地址放进来。这时候Add能找到,为啥TAdd找不到?
原因就是:
TAdd没有实例化成具体的函数,因为不知道实例化成什么。声明知道实例化成什么,但只有声明,不会实例化。有定义的地方,知道怎么实例化,但不知道实例化成什么。
解决办法:
让声明和定义同时出现。那解决分离编译的问题核心在于:显式实例化:
注意这里template不加尖括号,以及类型必须明确给出
看起来确实能解决问题,但是缺陷巨大 :麻烦,换一个类型又得重新实例化,这代表每个类型都得手敲一遍实例化,那就违背了模板初衷:泛用性!
如果直接定义在 a.h 不分离编译,不会链接错误。因为定义在 a.h 不需要链接了。a.h直接在main.cpp文件展开生成main.i文件,此时声明定义都有,直接实例化,生成地址了。就不需要链接查找函数了




下一篇讲解 C++继承 相关知识,感谢支持,一起加油