上一篇文章讨论了pandas的基本用法,本文会用另一个经典例子,泰坦尼克号生存预测来继续进行数据预处理。
泰坦尼克数据集描述
python
import seaborn as sns
import pandas as pd
# 直接加载titanic数据集
df = sns.load_dataset('titanic')
print(df.head())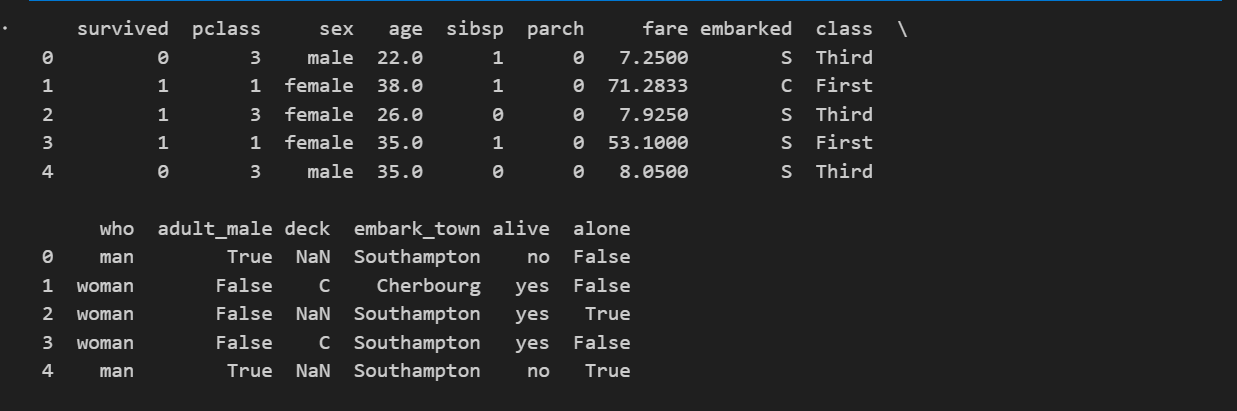
该数据集源于 1912 年泰坦尼克号沉船事件的真实乘客记录,标准训练集包含 891 名乘客 的记录,共 15 个特征,核心任务是基于乘客的个人信息、舱位等特征,预测该乘客是否在沉船事故中存活,是一个典型的二分类。
不同的特征(标签)含义如下
| 特征名 | 含义与取值说明 |
|---|---|
survived |
生存标签(目标变量):0= 遇难,1= 存活 |
pclass |
客舱等级:1= 一等舱,2= 二等舱,3= 三等舱(数字越小,舱位等级越高) |
sex |
性别:male= 男性,female= 女性 |
age |
年龄 |
sibsp |
同乘的兄弟姐妹 / 配偶数量 |
parch |
同乘的父母 / 子女数量 |
fare |
船票价格(反映舱位与服务等级) |
embarked |
登船港口缩写:S= 南安普顿,C= 瑟堡,Q= 皇后镇 |
class |
客舱等级的字符串形式:First/Second/Third(与pclass完全对应) |
who |
乘客类型:man= 成年男性,woman= 成年女性,child= 儿童 |
adult_male |
是否为成年男性:True/False |
deck |
舱位甲板号 |
embark_town |
登船港口完整名称:Southampton/Cherbourg/Queenstown(与embarked完全对应) |
alive |
生存情况的字符串形式:yes= 存活,no= 遇难(与survived完全对应) |
alone |
是否独自旅行:True= 无亲属陪同,False= 有亲属陪同 |
这个数据集相较于鸢尾花就复杂了很多,而且,很明显可以看出,有些特征与其最终是否幸存不一定有关系,有些特征可能冗余,不过这是特征工程需要做的事情,本文仅对数据集进行预处理。
查看数据集缺失情况
df.isnull()
该函数可以用来判断缺失值,但其有几个比较重要的属性,再这里一并介绍
python
# 缺失值处理
print("\n缺失值统计:")
print(df.isnull()) # 显示每个元素是否为缺失值
print(df.isnull().any()) # 显示每列是否存在缺失值
print(df.isnull().sum()) # 显示每列缺失值的数量如果直接调用isnull(),输出如下
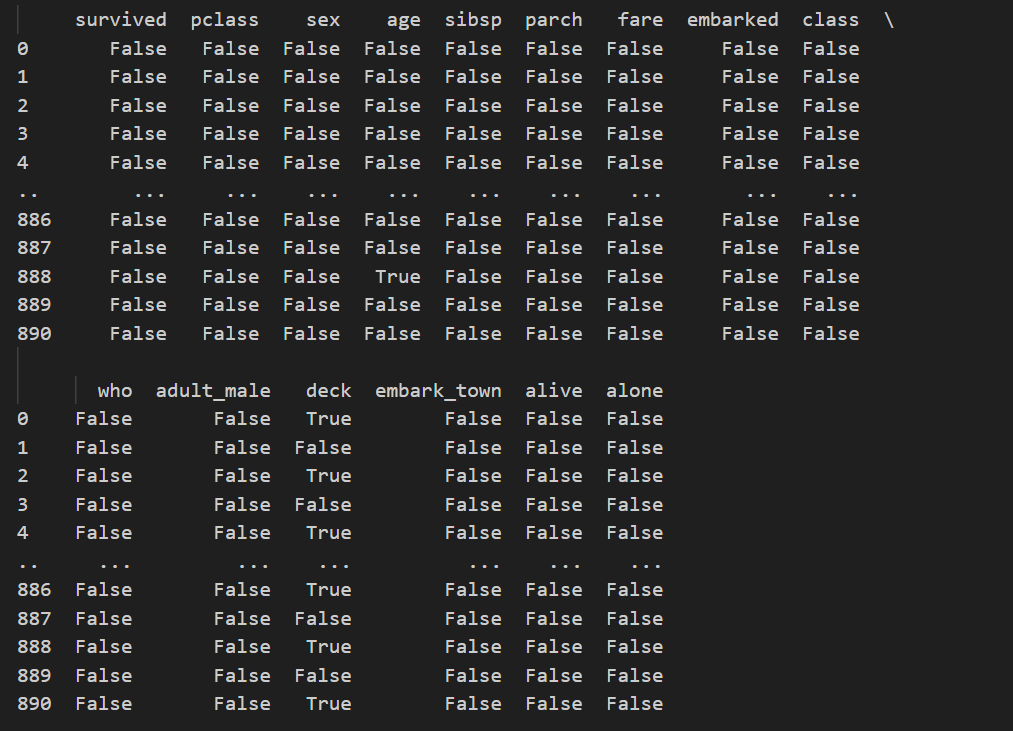
它会直接给出每个值是否缺失,但这样显然不够直观,我们尝试用isnull().any()
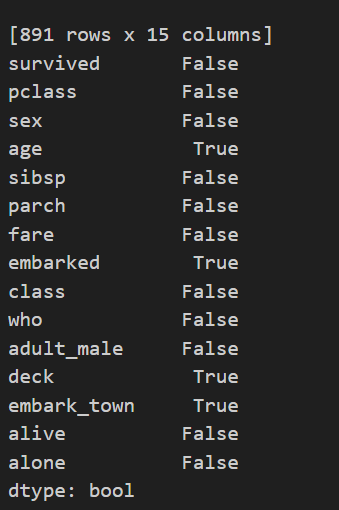
它会直接给出每个列是否缺失,但是我们并不知道每个列具体缺少了多少,下面尝试isnull().sum()
isnull().sum()
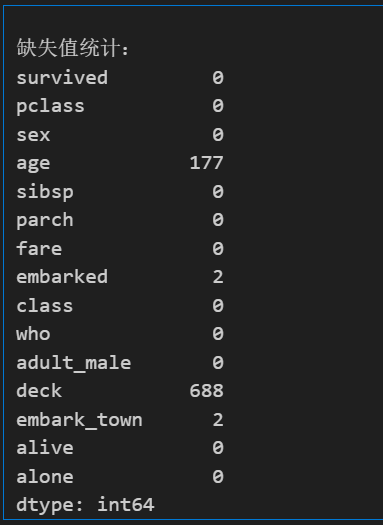
这个函数是最好用的,可以直观看到每个列的情况,我们发现相较于总量的891,age有部分缺失,deck有大量缺失,embarked和embark_town各有2个缺失,下面对缺失值进行处理。
fillna()
fillna() 是 pandas 中用于填充 DataFrame/Series 缺失值(NaN/None)的核心方法。
python
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)- value: 标量、字典、序列或 DataFrame。用于填充缺失值的值。
- method: {'backfill', 'bfill', 'pad', 'ffill', None}。填充方法。
- axis: {0 or 'index', 1 or 'columns'}。沿着哪个轴填充。
- inplace: bool,默认为 False。如果为 True,则在原地修改数据。
- limit: int,默认为 None。如果方法是 pad 或 ffill,则这是连续的填充的最大数量;如果方法是 backfill 或 bfill,则这是连续的填充的最大数量。
- downcast: dict,默认为 None。自动向下转换数据类型如果填充后数据类型可以优化(如 float 转 int),自动转换。
python
# 处理age
df['age'] = df['age'].fillna(df['age'].mean()) # 用平均值填充age的缺失值
# 处理embarked
df['embarked'] = df['embarked'].fillna(df['embarked'].mode()[0]) # 用众数填充embarked的缺失值
#处理deck
df = df.drop(columns=['deck']) # 删除deck列
#处理embark_town
df['embark_town'] = df['embark_town'].fillna(df['embark_town'].mode()[0]) # 用众数填充embark_town的缺失值
print("\n处理后缺失值统计:")
print(df.isnull().sum()) # 显示每列缺失值的数量这里用平均数填充age,embarked和embark_town由于缺失不多,用众数来填充,deck缺失太多了,因此直接df.drop()删除整列抛弃。
这些方法的写法基本是固定的,更多的处理方法见数据预处理(上)
(另外多说一句,我今天突然发现inplace=True这个参数直接用似乎会有警告,为了避免出问题还是用赋值的写法吧)
处理完成后再次调用isnull().sum()
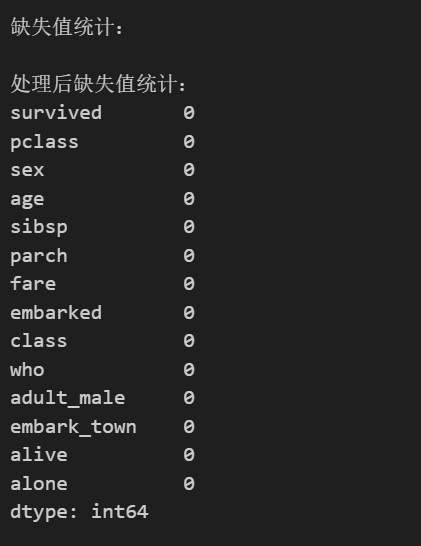
可以看到所有的缺失值都处理完了,当然也可以有不同的处理方法,这些都会影响到最终模型输出的效果,不过这就需要具体问题具体分析了。
特征编码
这里也会有同样的问题,编码的方式有很多种,也都会影响到最终模型输出的效果
首先展示一下独热编码
python
# 独热编码
df_one_hot = pd.get_dummies(df, columns=['sex', 'embarked', 'class', 'who', 'adult_male', 'embark_town', 'alive'], drop_first=True)
print("\n编码后数据集预览:")
print(df_one_hot.head())结果如下
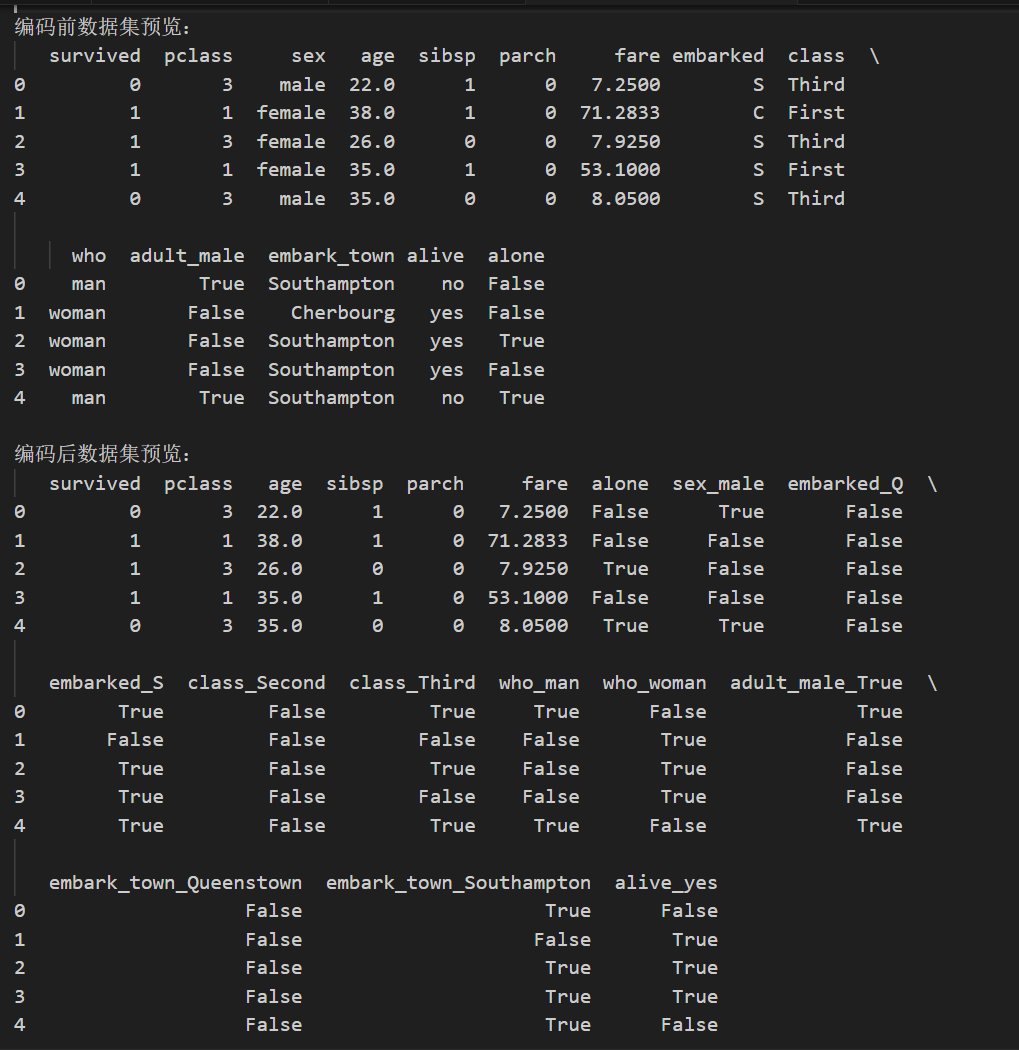
通过编码前后的对比,我们发现独热编码多出来很多列,这与独热编码的特性有关,比如embarked就分为了两列(原因是embarked有Q、S、C三个取值,用bool需要两列才能完全表示)
结合具体情况
这种编码简单易实现,但显然不利于模型输入,所有我们应当结合每个特征的情况来分析
python
# 类别特征编码
print("\n编码前数据集预览:")
print(df.head())
# 特殊处理几个特征
# 删除class列,因为它和pclass高度相关
df = df.drop(columns=['class'])
# who列包含child、man、woman三种类别,可以考虑删除,也可以映射
# 这里我们选择映射为0、1、2
who_mapping = {'child': 0, 'man': 1, 'woman': 2}
df['who'] = df['who'].map(who_mapping)
# embark_town列和embarked列高度相关,可以删除embark_town
df = df.drop(columns=['embark_town'])
# 独热编码其余类别特征
df = pd.get_dummies(df, columns=['sex', 'embarked', 'who', 'adult_male', 'alive'], drop_first=True)
print("\n编码后数据集预览:")
print(df.head())输出如下
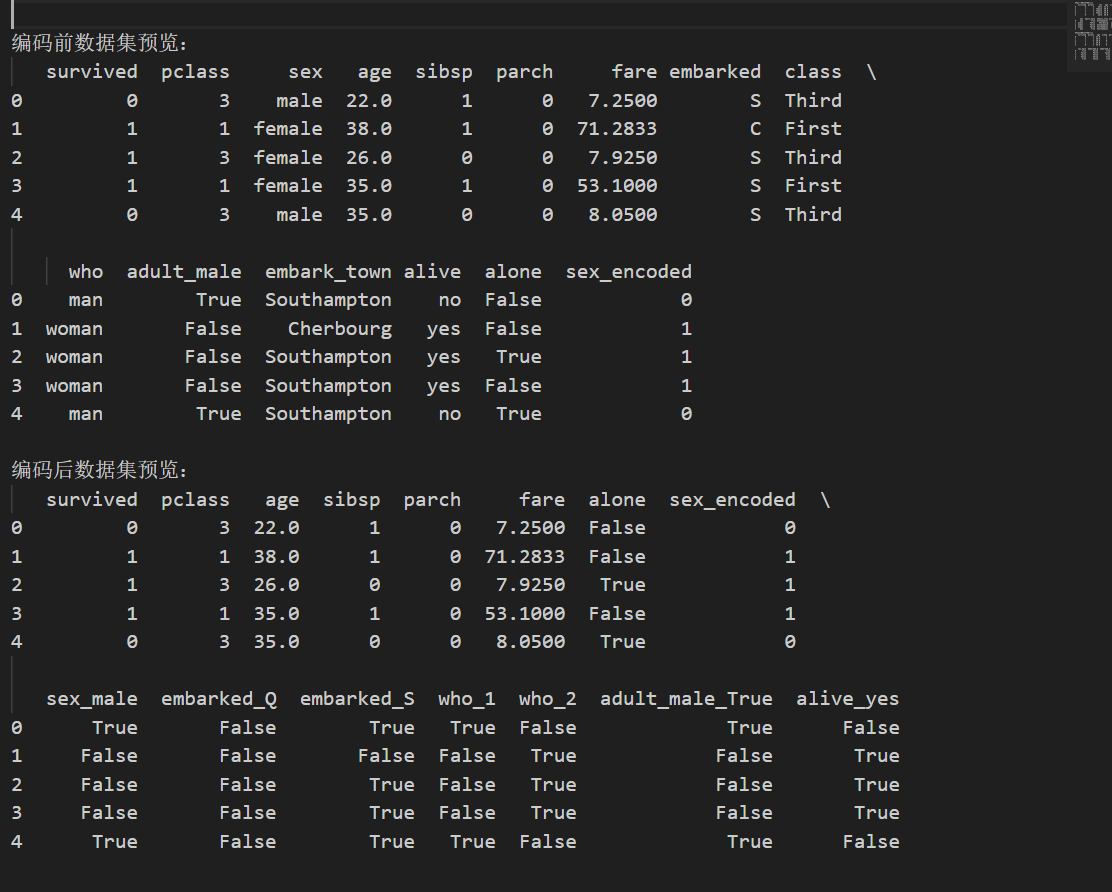
由此我们便完成了简单预处理的所有部分。当然之后还可以做更多的内容来提高预处理效果,下文会用一个文本数据集来进行介绍。