欢迎关注 【AIGC论文精读】原创作品
【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1
【DeepSeek论文精读】13. DeepSeek-Coder-V2: 突破闭源模型在代码智能领域的障碍
【DeepSeek论文精读】16. mHC:流形约束超连接
【DeepSeek论文精读】17. mHC:流形约束超连接
-
- [0. 论文简介](#0. 论文简介)
-
- [0.1 论文背景](#0.1 论文背景)
- [0.2 总结速览](#0.2 总结速览)
- [0.3 摘要](#0.3 摘要)
- [1. 引言](#1. 引言)
- [2. 架构](#2. 架构)
-
- [2.1 概述](#2.1 概述)
- [2.2 基于哈希N元语法的稀疏检索](#2.2 基于哈希N元语法的稀疏检索)
- [2.3 上下文感知门控](#2.3 上下文感知门控)
- [2.4 与多分支架构的集成](#2.4 与多分支架构的集成)
- [2.5 系统效率:解耦计算与内存](#2.5 系统效率:解耦计算与内存)
- [3. 缩放定律与稀疏分配](#3. 缩放定律与稀疏分配)
-
- [3.1. MoE与Engram之间的最优分配比例](#3.1. MoE与Engram之间的最优分配比例)
- [3.2 无限内存状态下的Engram](#3.2 无限内存状态下的Engram)
- [4. 大规模预训练](#4. 大规模预训练)
-
- [4.1 实验设置](#4.1 实验设置)
- [4.2 实验结果](#4.2 实验结果)
- [5. 长上下文训练](#5. 长上下文训练)
-
- [5.1 实验设置](#5.1 实验设置)
- [5.2 实验结果](#5.2 实验结果)
- [6. 分析](#6. 分析)
-
- [6.1. Engram 在功能上等同于增加了模型的深度吗?](#6.1. Engram 在功能上等同于增加了模型的深度吗?)
- [6.2 结构消融与层敏感性](#6.2 结构消融与层敏感性)
- [6.3 敏感性分析](#6.3 敏感性分析)
- [6.4 系统效率](#6.4 系统效率)
- [6.5 案例研究:门控可视化](#6.5 案例研究:门控可视化)
- [7. 相关工作](#7. 相关工作)
- [8. 结论](#8. 结论)
- [9. 代码介绍](#9. 代码介绍)
- [10. 参考文献](#10. 参考文献)
0. 论文简介
0.1 论文背景
2026年1月12日,DeepSeek 公布了一篇新论文 "通过可扩展查找的条件记忆:大语言模型稀疏化的新维度(Conditional Memory via Scalable Lookup_A New Axis of Sparsity for Large Language Models)"。
本文提出了一种名为 Engram 的条件记忆模块,旨在解决当前大语言模型中因缺乏原生知识检索机制而导致的效率问题,并通过引入"条件记忆"这一新的稀疏化维度,提升模型在知识检索、推理和长上下文理解等方面的性能。

【论文下载】: github
0.2 总结速览
-
要解决的问题
- 知识检索的低效率问题
- MoE 的局限性
- 模型深度与计算资源的浪费
-
提出的方法:Engram 条件记忆模块
Engram 是一个基于经典 N-gram 嵌入 的现代条件记忆模块,通过 O(1) 查找 实现静态知识的快速检索,并与动态计算模块(如 MoE)协同工作。其核心设计包括:
-
- 稀疏检索机制
使用哈希 N-gram 将局部上下文映射到静态嵌入表中,实现高效查找。
引入分词器压缩,归一化语义等效的 token,减少嵌入表规模。
- 稀疏检索机制
-
- 上下文感知的门控机制
使用当前隐藏状态作为查询,检索到的嵌入作为键和值,通过注意力式门控动态调节记忆的融合,抑制噪声与上下文无关的检索结果。
- 上下文感知的门控机制
-
- 多分支架构集成
适配多分支 Transformer 架构(如 mHC),共享嵌入表与值投影,但使用分支特定的键投影,实现细粒度控制。
- 多分支架构集成
-
- 系统级优化
利用确定性查找模式,实现预取与计算重叠,支持将大规模嵌入表卸载到主机内存,显著降低 GPU 内存压力。
利用 Zipfian 分布设计多级缓存层次,提升高频访问效率。
- 系统级优化
-
-
核心贡献
- 稀疏分配:
明确了神经计算(MoE)与静态内存(Engram)之间的权衡关系,发现了指导容量最优分配的 U 型缩放定律。 - 实证验证:
在严格的同参数和同计算量约束下,Engram-27B 模型在知识、推理、代码及数学领域均展现出优于 MoE 基准模型的稳定性能提升。 - 机制分析:
分析表明,Engram 减轻了早期网络层的静态模式重建负担,从而可能为复杂推理任务保留了有效的模型深度。 - 系统效率:
该模块采用确定性寻址机制,支持将大规模嵌入表卸载至主机内存,且推理开销极小。
- 稀疏分配:

0.3 摘要
虽然混合专家模型(MoE)通过条件计算扩展了模型容量,但Transformer模型缺乏原生的知识查找机制,被迫通过计算来低效地模拟检索过程。为应对这一问题,我们引入了条件记忆作为一项互补的稀疏化维度,并通过Engram模块具体实现。该模块对经典的N-元语法嵌入进行了现代化改造,以实现O(1) 查找。
通过构建稀疏分配问题,我们发现了一条U形缩放定律,该定律优化了神经计算(MoE)与静态记忆(Engram)之间的权衡。在此定律的指导下,我们将Engram扩展到270亿参数,在性能上超越了严格同参数、同计算量的MoE基线模型。
尤为重要的是,虽然记忆模块预期有助于知识检索任务(例如MMLU提升3.4分;CMMLU提升4.0分),但我们观察到其在通用推理(例如BBH提升5.0分;ARC-Challenge提升3.7分)以及代码/数学领域(例如HumanEval提升3.0分;MATH提升2.4分)的提升甚至更大。
机制分析表明,Engram使得模型主干免于在早期层中进行静态模式重构,从而有效地加深了网络以处理复杂推理。此外,通过将局部依赖关系委托给查找操作,它释放了注意力机制处理全局上下文的能力,显著提升了长上下文的检索性能(例如,Multi-Query NIAH:84.2 → 97.0)。
最后,Engram建立了面向基础设施的效率考量:其确定性的寻址方式使得能够在运行时从主机内存预取数据,而开销几乎可以忽略。我们展望条件记忆将成为下一代稀疏模型中不可或缺的建模原语。
代码已公开于:https://github.com/deepseek-ai/Engram
1. 引言
稀疏性是智能系统设计中一个反复出现的原则,从生物神经回路到现代大语言模型皆然。目前,这一原则主要通过混合专家模型(MoE) 得以实现,它通过条件计算来扩展模型容量。由于MoE能够大幅增加模型规模而无需成比例地增加计算量,它已成为前沿模型事实上的标准。
尽管这种条件计算范式取得了成功,但语言信号固有的异质性表明,在结构优化方面仍有显著空间。具体而言,语言建模包含两种性质不同的子任务:组合式推理和知识检索。前者需要深层、动态的计算,而文本中相当大的一部分------例如命名实体和固定表达模式------是局部、静态且高度刻板的。经典的N-元语法模型在捕捉此类局部依赖关系方面的有效性意味着,这些规律性可以自然地表示为计算成本低廉的查找操作。由于标准Transformer模型缺乏原生的知识查找机制,当前的大语言模型被迫通过计算来模拟检索。例如,解析一个常见的多词元实体需要消耗多个早期层的注意力和前馈网络资源。这个过程本质上相当于对静态查找表进行一次昂贵的运行时重建,将宝贵的序列深度浪费在琐碎的操作上,而这些资源本可以分配给更高层次的推理。
为了使模型架构与这种语言二元性对齐,我们主张采用一个互补的稀疏化维度:条件记忆。条件计算通过稀疏激活参数来处理动态逻辑,而条件记忆则依靠稀疏查找操作来检索固定知识的静态嵌入。作为对此范式的初步探索,我们重新审视N-元语法嵌入,将其作为一种典型实现:局部上下文作为键,通过恒定时间O(1)查找来索引庞大的嵌入表。我们的研究表明,或许令人惊讶的是,这种静态检索机制可以作为现代MoE架构的理想补充------但前提是它被正确设计。在本文中,我们提出了Engram,这是一个基于经典N-元语法结构但配备了现代化适配模块的条件记忆模块,这些适配包括分词器压缩、多头哈希、上下文感知门控和多分支集成(详见第2节)。
为了量化这两种机制之间的协同效应,我们构建了稀疏分配问题:在给定的总参数预算下,应如何在MoE专家和Engram记忆之间分配容量?我们的实验揭示了一个独特的U形缩放定律,表明即使是简单的查找机制,只要被视为一等建模原语,也能成为神经计算的重要补充。在此分配定律的指导下,我们将Engram扩展到具有270亿参数的模型。与严格的同参数、同计算量MoE基线相比,Engram-27B在不同领域均实现了更优的效率。关键的是,性能提升并不仅限于知识密集型任务(例如,MMLU: +3.4; CMMLU: +4.0; MMLU-Pro: +1.8),在这些任务中记忆容量直观上有益;我们在通用推理(例如,BBH: +5.0; ARC-Challenge: +3.7; DROP: +3.3)以及代码/数学领域(例如,HumanEval: +3.0; MATH: +2.4; GSM8K: +2.2)观察到了更为显著的改进。
通过LogitLens和CKA进行的机制分析揭示了这些改进的来源:Engram解除了模型主干在早期层中重建静态知识的负担,从而增加了可用于复杂推理的有效深度。此外,通过将局部依赖关系委托给查找操作,Engram释放了注意力机制处理全局上下文的能力,使其在长上下文场景中表现出色------在LongPPL和RULER评测上大幅超越基线模型(例如,Multi-Query NIAH: 97.0 对比 84.2; Variable Tracking: 89.0 对比 77.0)。
最后,我们将面向基础设施的效率确立为一等设计原则。与MoE的动态路由不同,Engram采用确定性ID来实现运行时预取,使得通信与计算重叠。实证结果表明,将1000亿参数的表格卸载到主机内存所带来的开销可以忽略不计(❤️%)。这证明Engram能有效绕过GPU内存限制,促进激进的参数扩展。
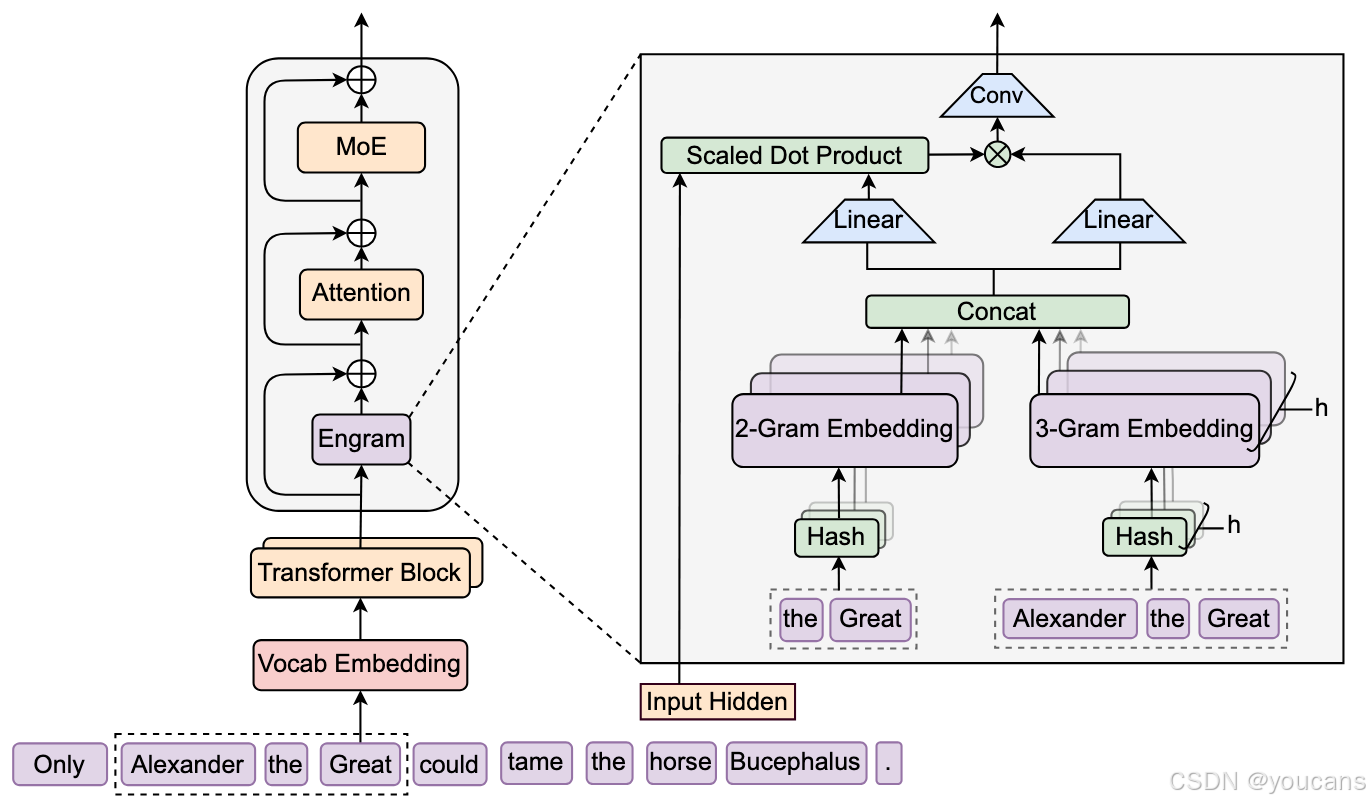
图 1 | Engram 架构。该模块通过检索静态 N 元语法记忆,并借助上下文感知门控机制将其与动态隐藏状态融合,以此增强骨干网络性能。此模块仅应用于特定层,实现内存与计算的解耦,同时保持标准的输入嵌入和输出解嵌入模块不受影响。
2. 架构
2.1 概述
如图1所示,Engram是一个条件记忆模块,旨在通过结构上分离静态模式存储与动态计算来增强Transformer主干。形式上,给定输入序列 X = ( x 1 , . . . , x T ) X = (x_1, ..., x_T) X=(x1,...,xT)和第 ℓ \ell ℓ层的隐藏状态 H ( ℓ ) ∈ R T × d \mathbf{H}^{(\ell)} \in \mathbb{R}^{T \times d} H(ℓ)∈RT×d,该模块在每个位置 t t t按两个功能阶段进行处理:检索和融合。首先,如第2.2节详述,我们提取并压缩后缀N元语法,通过哈希确定性地检索静态嵌入向量。随后,在第2.3节,这些检索到的嵌入由当前隐藏状态动态调制,并通过轻量级卷积进行精炼。最后,我们在第2.4节讨论与多分支架构的集成,并在第2.5节讨论系统级设计。
2.2 基于哈希N元语法的稀疏检索
第一阶段将局部上下文映射到静态内存条目,涉及分词器压缩和通过确定性哈希检索嵌入。
分词器压缩
虽然N元语法模型通常直接对分词器输出进行操作,但标准的子词分词器优先考虑无损重建,经常为语义等效的词分配不同的ID(例如,Apple 与 uapple)。为了最大化语义密度,我们实现了一个词汇表投影层。具体来说,我们预计算一个满射函数 P : V → V ′ \mathcal{P}: V \to V' P:V→V′,该函数基于规范化的文本等价性(使用NFKC、小写化等)将原始词符ID折叠为规范标识符。实践中,此过程对于一个128k词符的分词器实现了有效词汇表大小减少23%(参见附录C)。形式上,对于位置 t t t的一个词符,我们将其原始ID x t x_t xt映射到规范ID x ′ t = P ( x t ) x't = \mathcal{P}(x_t) x′t=P(xt),以形成后缀N元语法 g t , n = ( x t − n + 1 ′ , . . . , x t ′ ) g{t,n} = (x'_{t-n+1}, ..., x'_t) gt,n=(xt−n+1′,...,xt′)。
多头哈希
直接参数化所有可能N元语法的组合空间是不可行的。遵循Tito Svenstrup等人的方法,我们采用基于哈希的方法。为了减少冲突,我们为每个N元语法阶数 n n n采用 K K K个不同的哈希头。每个头 k k k通过一个确定性函数 φ n , k \varphi_{n,k} φn,k将压缩后的上下文映射到嵌入表 E n , k \mathbf{E}{n,k} En,k内的一个索引(其大小为素数 M n , k M{n,k} Mn,k):
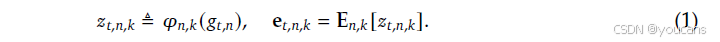
在实践中, φ n , k \varphi_{n,k} φn,k实现为一个轻量级的乘法-XOR哈希。我们通过连接所有检索到的嵌入来构建最终的记忆向量 e t ∈ R d mem \mathbf{e}t \in \mathbb{R}^{d{\text{mem}}} et∈Rdmem:

2.3 上下文感知门控
检索到的嵌入 e t \mathbf{e}_t et作为与上下文无关的先验。然而,由于是静态的,它们本质上缺乏上下文适应性,并且可能因哈希冲突或多义性而产生噪声。为了增强表达能力并解决这种歧义性,我们采用了一种受注意力机制启发的上下文感知门控机制。具体来说,我们利用当前的隐藏状态 h t \mathbf{h}_t ht------它已经通过先前的注意力层聚合了全局上下文------作为动态查询,而检索到的记忆 e t \mathbf{e}_t et则作为键和值投影的来源:
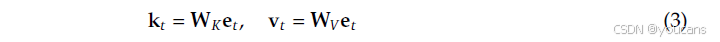
其中 W K \mathbf{W}_K WK、 W V \mathbf{W}_V WV是可学习的投影矩阵。为了确保梯度稳定性,在计算标量门 α t ∈ ( 0 , 1 ) \alpha_t \in (0,1) αt∈(0,1)之前,我们对查询和键应用RMSNorm:
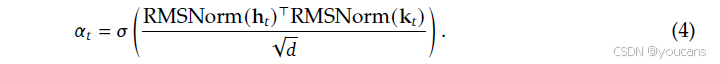
门控输出定义为 v ~ t = α t ⋅ v t \tilde{\mathbf{v}}_t = \alpha_t \cdot \mathbf{v}_t v~t=αt⋅vt。此设计强制执行语义对齐:如果检索到的记忆 e t \mathbf{e}_t et与当前上下文 h t \mathbf{h}_t ht相矛盾,门 α t \alpha_t αt倾向于趋近于零,从而有效地抑制噪声。
最后,为了扩展感受野并增强模型的非线性,我们引入了一个短的、深度因果卷积。令 V ~ ∈ R T × d \tilde{\mathbf{V}} \in \mathbb{R}^{T \times d} V~∈RT×d表示门控值序列。使用核大小 w w w(设为4),膨胀率 δ \delta δ(设为最大N元语法阶数)和SiLU激活函数,最终输出 Y \mathbf{Y} Y计算如下:
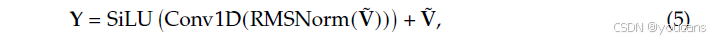
Engram模块通过残差连接集成到主干中: H ( ℓ ) ← H ( ℓ ) + Y \mathbf{H}^{(\ell)} \leftarrow \mathbf{H}^{(\ell)} + \mathbf{Y} H(ℓ)←H(ℓ)+Y,之后是标准的注意力和MoE层。至关重要的是,Engram并非应用于每一层;其具体放置由第2.5节详述的系统级延迟约束控制。
2.4 与多分支架构的集成
在这项工作中,我们采用先进的多分支架构作为默认主干,而不是标准的单流连接,因其具有卓越的建模能力。该架构的一个定义性特征是将残差流扩展为 M M M个并行分支,其中信息流由可学习的连接权重调制。
尽管Engram模块本质上与拓扑无关,但要将其适配到此多分支框架,需要进行结构优化以平衡效率和表达能力。具体来说,我们实现了一个参数共享策略:跨所有 M M M个分支共享一个稀疏嵌入表和一个值投影矩阵 W V \mathbf{W}_V WV,而使用 M M M个不同的键投影矩阵 W ( m ) K m = 1 M {\mathbf{W}^{(m)}K}{m=1}^{M} W(m)Km=1M以实现分支特定的门控行为。对于具有隐藏状态 h t ( m ) \mathbf{h}^{(m)}_t ht(m)的第 m m m个分支,分支特定的门控信号计算如下:
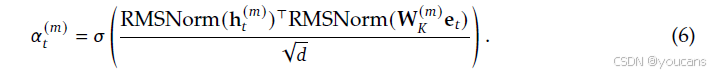
检索到的记忆随后由这些应用于共享值向量的独立门进行调制: u t ( m ) = α t ( m ) ⋅ ( W V e t ) \mathbf{u}^{(m)}_t = \alpha^{(m)}_t \cdot (\mathbf{W}_V \mathbf{e}_t) ut(m)=αt(m)⋅(WVet)。此设计允许线性投影(一个 W V \mathbf{W}_V WV和 M M M个不同的 W K ( m ) \mathbf{W}^{(m)}_K WK(m))融合到单个密集的FPS矩阵乘法中,从而最大化现代GPU的计算利用率。除非另有说明,所有实验均采用这种与流形约束超连接的集成方式。
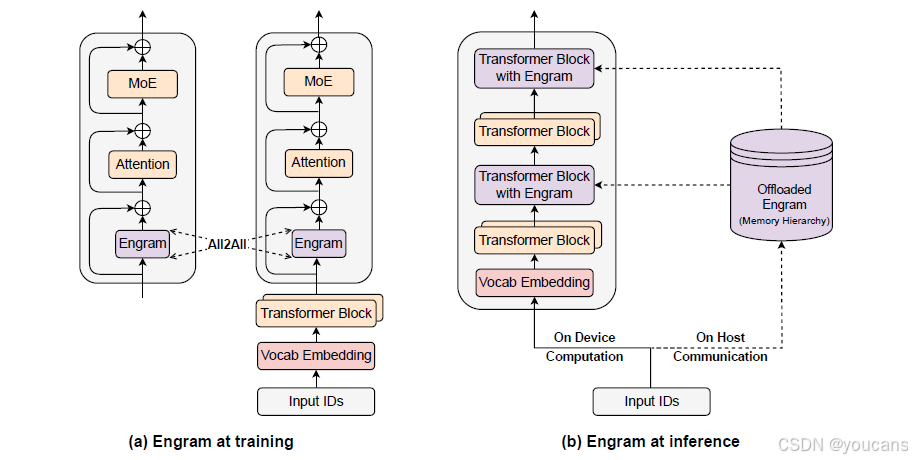
图2 | Engram 的系统实现
(a) 训练阶段:将庞大的嵌入表切分并分布到所有可用 GPU 上,通过 All-to-All 通信原语在各设备间拉取当前活跃的嵌入行。
(b) 推理阶段:Engram 表被卸载到主机内存。利用确定的检索逻辑,主机异步预取并把嵌入传输到设备,同时与前序 Transformer 块的在设备计算重叠进行,实现通信与计算的并行。
2.5 系统效率:解耦计算与内存
扩展记忆增强模型通常受到GPU高带宽内存(HBM)有限容量的约束。然而,Engram的确定性检索机制天然支持将参数存储与计算资源解耦。与MoE依赖于运行时隐藏状态进行动态路由不同,Engram的检索索引仅依赖于输入词符序列。这种可预测性有利于训练和推理的专用优化策略,如图2所示。
在训练期间,为了容纳大规模嵌入表,我们采用标准模型并行方法,将表分片到可用的GPU上。使用All-to-All通信原语在前向传播中收集活跃行,在反向传播中分发梯度,使得总内存容量能够随加速器数量线性扩展。
在推理期间,这种确定性特性支持预取和重叠策略。由于内存索引在前向传播之前已知,系统可以通过PCIe从充裕的主机内存异步检索嵌入。为了有效掩盖通信延迟,Engram模块被放置在主干内的特定层中,利用先前层的计算作为缓冲区以防止GPU停滞。这需要一种硬件-算法协同设计策略:虽然将Engram放置得更深可以延长用于隐藏延迟的计算窗口,但我们在第6.2节的消融研究表明,建模性能倾向于早期干预以卸载局部模式重建。因此,最优放置必须同时满足建模和系统延迟约束。
此外,自然语言N元语法天然遵循Zipfian分布,其中一小部分模式占内存访问的绝大部分。这种统计特性启发了多级缓存层次结构:频繁访问的嵌入可以缓存在更快的存储层中(例如GPU HBM或主机DRAM),而罕见模式的长尾则驻留在速度较慢、容量较大的介质中(例如NVMe SSD)。这种分层允许Engram扩展到巨大的内存容量,同时对有效延迟的影响最小。
3. 缩放定律与稀疏分配
Engram作为条件记忆的具体实例,在结构上与MoE专家提供的条件计算形成互补。本节研究这种二元性的缩放特性,以及如何最优地分配稀疏容量。具体而言,两个关键问题驱动着我们的研究:
-
有限约束下的分配。
当总参数和训练计算量固定(等参数量和等计算量)时,我们应如何在MoE专家和Engram嵌入之间分配稀疏容量?
-
无限内存状态。
考虑到Engram O ( 1 ) O(1) O(1)的非缩放性开销,如果放宽内存预算或进行激进的扩展,Engram本身会展现出何种缩放行为?
3.1. MoE与Engram之间的最优分配比例
计算匹配公式。
我们使用三个参数指标来分析这种权衡:
-
P tot P_{\text{tot}} Ptot:总可训练参数数量,不包括词汇嵌入层和语言模型头部。
-
P act P_{\text{act}} Pact:每个词符激活的参数数量。这个量决定了训练成本(计算量)。
-
P sparse ≜ P tot − P act P_{\text{sparse}} \triangleq P_{\text{tot}} - P_{\text{act}} Psparse≜Ptot−Pact:非活跃参数,代表了在不增加计算成本的情况下可用于扩展模型规模的"免费"参数预算(例如,未选中的专家或未检索到的嵌入)。
在每个计算量预算下,我们保持 P tot P_{\text{tot}} Ptot和 P act P_{\text{act}} Pact固定,以确保模型具有相同数量的参数和相同的每个词符计算量。对于MoE, P act P_{\text{act}} Pact由前 k k k个选中的专家决定,而未选中专家的参数计入 P sparse P_{\text{sparse}} Psparse。对于Engram,每个词符只检索恒定数量的嵌入槽,因此增加嵌入槽的数量会增加 P tot P_{\text{tot}} Ptot而不会增加每个词符的计算量。
分配比例。
我们定义分配比例 ρ ∈ 0 , 1 \rho \in 0,1 ρ∈0,1为分配给MoE专家容量的非活跃参数预算的比例:
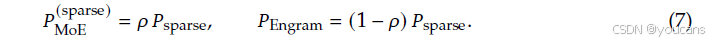
直观地说:
-
ρ = 1 \rho = 1 ρ=1对应于纯MoE模型(所有非活跃参数都分配给路由专家)。
-
ρ < 1 \rho < 1 ρ<1会减少路由专家的数量,并将释放出来的参数重新分配给Engram嵌入槽。
实验方案。
我们在两种计算状态下评估这种权衡,并在两种设置下保持恒定的稀疏比 P tot / P act ≈ 10 P_{\text{tot}}/P_{\text{act}} \approx 10 Ptot/Pact≈10:
C = 2 × 10 20 C = 2 \times 10^{20} C=2×1020 次浮点运算: P tot ≈ 5.7 B P_{\text{tot}} \approx 5.7\text{B} Ptot≈5.7B, P act = 568 M P_{\text{act}} = 568\text{M} Pact=568M。基线模型( ρ = 1 \rho = 1 ρ=1)总共有106个专家。
C = 6 × 10 20 C = 6 \times 10^{20} C=6×1020 次浮点运算: P tot ≈ 9.9 B P_{\text{tot}} \approx 9.9\text{B} Ptot≈9.9B, P act = 993 M P_{\text{act}} = 993\text{M} Pact=993M。基线模型( ρ = 1 \rho = 1 ρ=1)总共有99个专家。
对于不同的 ρ \rho ρ,我们仅通过调整路由专家的数量和Engram嵌入槽的数量来构建相应的模型。所有实验运行都使用相同的训练流水线和优化超参数。
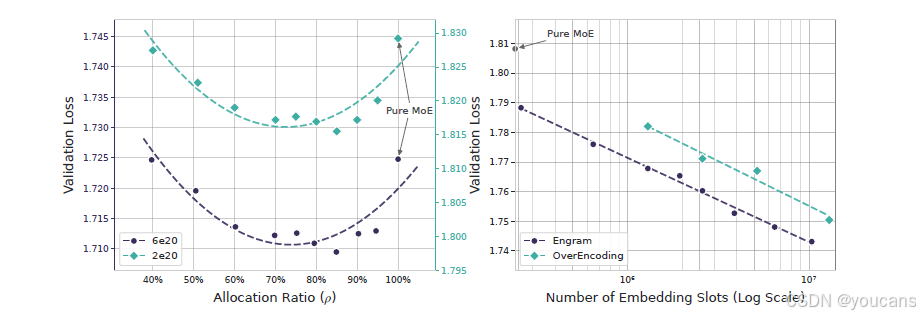
图3 | 稀疏分配与Engram扩展。
左图:不同分配比例𝜌下的验证损失。展示了两个计算预算(2e20和6e20次浮点运算)。两种状态均呈现U形曲线,混合分配方案超越了纯MoE模型。
右图:无限内存状态下的扩展行为。
验证损失相对于嵌入数量呈现对数线性趋势。
结果与分析。
图3(左)显示了验证损失与分配比例 ρ \rho ρ之间一致的U形关系。值得注意的是,即使MoE的分配比例降低到仅为 ρ ≈ 40 \rho \approx 40% ρ≈40(即,5.7B模型总共有46个专家,9.9B模型总共有43个专家),Engram模型仍能取得与纯MoE基线( ρ = 100 \rho = 100% ρ=100)相当的性能。此外,纯MoE基线被证明是次优的:将大约 20 20% 20- 25 25% 25的稀疏参数预算重新分配给Engram可以获得最佳性能。量化来看,在10B参数状态下( C = 6 × 10 20 C = 6 \times 10^{20} C=6×1020),验证损失从 ρ = 100 \rho=100% ρ=100时的1.7248改善到接近最优 ρ ≈ 80 \rho \approx 80% ρ≈80时的1.7109(差异 Δ = 0.0139 \Delta = 0.0139 Δ=0.0139)。关键的是,这个最优值的位置在不同状态间保持稳定( ρ ≈ 75 \rho \approx 75% ρ≈75- 80 80% 80),表明在考察的规模范围内(在固定稀疏度下)存在稳健的分配偏好。观察到的U形曲线证实了这两个模块之间的结构互补性:
-
MoE主导( ρ → 100 \rho \to 100% ρ→100): 模型缺乏用于静态模式的专用记忆,迫使它通过深度和计算来低效地重构它们。
-
Engram主导( ρ → 0 \rho \to 0% ρ→0): 模型失去条件计算能力,损害了需要动态、上下文相关推理的任务;在此状态下,内存无法替代计算。
3.2 无限内存状态下的Engram
在第3.1节中,我们在固定参数预算下优化了分配。我们现在探索互补的设置:激进的记忆扩展。这项研究的动机在于Engram在第2.5节详述的将存储与计算解耦的独特能力。
实验方案。
我们使用一个固定的MoE主干,其 P tot ≈ 3 B P_{\text{tot}} \approx 3\text{B} Ptot≈3B, P act = 568 M P_{\text{act}} = 568\text{M} Pact=568M,训练了1000亿个词符以确保收敛。在此主干之上,我们附加一个Engram表,并扫描嵌入槽数量 M M M从 2.58 × 10 5 2.58 \times 10^{5} 2.58×105到 1.0 × 10 7 1.0 \times 10^{7} 1.0×107(总计增加约130亿参数)。对于基线,我们与OverEncoding进行比较,后者通过将 N N N元语法嵌入与词汇嵌入进行平均来集成它们。我们注意到,虽然其他工作如SCONE也研究大规模嵌入,但它主要专注于推理,并且包含了额外的模块和额外的训练计算量,使其不符合本研究中严格的等计算量约束。
结果。
图3(右)表明,增加内存槽的数量会在验证损失上产生清晰且一致的改善。在整个探索范围内,曲线遵循严格的幂律(在对数空间中呈线性),表明Engram提供了一个可预测的扩展调节旋钮:更大的内存持续带来回报,而无需额外的计算。关键的是,关于扩展效率:虽然OverEncoding的直接平均方法得益于更大的内存表,但Engram从相同的内存预算中释放了更大的扩展潜力。这些结果与第3.1节的分配定律一起,验证了条件记忆作为一个独特的、可扩展的稀疏容量维度,补充了MoE的条件计算。
4. 大规模预训练
利用所提出的 Engram 架构和通过实验得出的分配定律,我们将 Engram 扩展到数十亿参数规模,以验证其在实际语言模型预训练中的有效性。具体来说,我们训练了四个模型:(1) Dense-4B(总参数量 4.1B),(2) MoE-27B(总参数量 26.7B),(3) Engram-27B(总参数量 26.7B),以及 (4) Engram-40B(总参数量 39.5B)。所有模型都使用相同的数据课程(相同的词符预算和顺序)进行训练,并且在激活参数量上严格匹配。
4.1 实验设置
训练数据与模型配置
所有模型都在一个包含 2620 亿个词符的语料库上进行预训练,我们使用 DeepSeek-v3 的词符化器,其词汇表大小为 128k。在建模方面,为了确保受控的对比,除非另有明确说明,我们所有模型都遵循一致的默认设置。我们使用一个包含 30 个模块的 Transformer,其隐藏层维度为 2560。每个模块集成了一个具有 32 个头的多头潜在注意力机制,并通过流形约束超连接(mHC)连接到前馈网络,其扩展率为 4。所有模型都使用 Muon 优化器进行优化;详细的超参数列在附录 A 中。我们实例化了四个不同的模型:
-
Dense-4B 作为基线模型。它采用了上述的主干架构,在每个模块中都集成了一个标准的密集前馈网络。
-
MoE-27B 用 DeepSeekMoE 模块替换了标准的密集前馈网络。配置为 72 个路由专家和 2 个共享专家(每个词符激活前 k k k = 6 个路由专家),该模型的总参数量扩展到 26.7B,同时保持与 Dense-4B 相同的激活参数量。
-
Engram-27B 严格基于 MoE-27B 架构衍生,以确保公平比较。我们将路由专家的数量从 72 个减少到 55 个,并将释放出的参数重新分配给一个 57 亿参数的嵌入模块( ρ = 74.3 \rho = 74.3% ρ=74.3),使模型总大小恒定保持在 26.7B。关于 Engram 的配置,我们在第 2 和第 15 层实例化该模块,并将最大 N N N 元语法大小设置为 3,头数设置为 8,维度设置为 1280。在优化方面,嵌入参数使用 Adam 更新,学习率缩放 5 倍且无权重衰减,而卷积参数初始化为零,以在训练开始时严格保持恒等映射。
-
Engram-40B 保留与 Engram-27B 相同的主干和计算预算,但将稀疏嵌入模块扩展到 185 亿参数(总计 395 亿参数)。该模型旨在研究 Engram 的扩展特性。
评估方案
我们在涵盖语言建模、知识、推理、阅读理解和代码/数学的多样化基准测试套件上评估模型。对于每个基准测试,我们遵循标准的提示协议和评估指标。
-
语言建模:我们报告了 The Pile 测试集上的损失以及从与训练数据相同分布抽取的验证集上的损失。
-
知识与推理:MMLU、MMLU-Redux、MMLU-Pro、CMMLU、C-Eval、AGIEval、ARC-Easy/Challenge、TriviaQA、TriviaQA-ZH(内部版)、PopQA、CCPM、BBH、HellaSwag、PIQA 和 WinoGrande。
-
阅读理解:DROP、RACE(Middle/High)和 C3。
-
代码与数学:HumanEval、MBPP、CruxEval、GSM8K、MGSM 和 MATH。
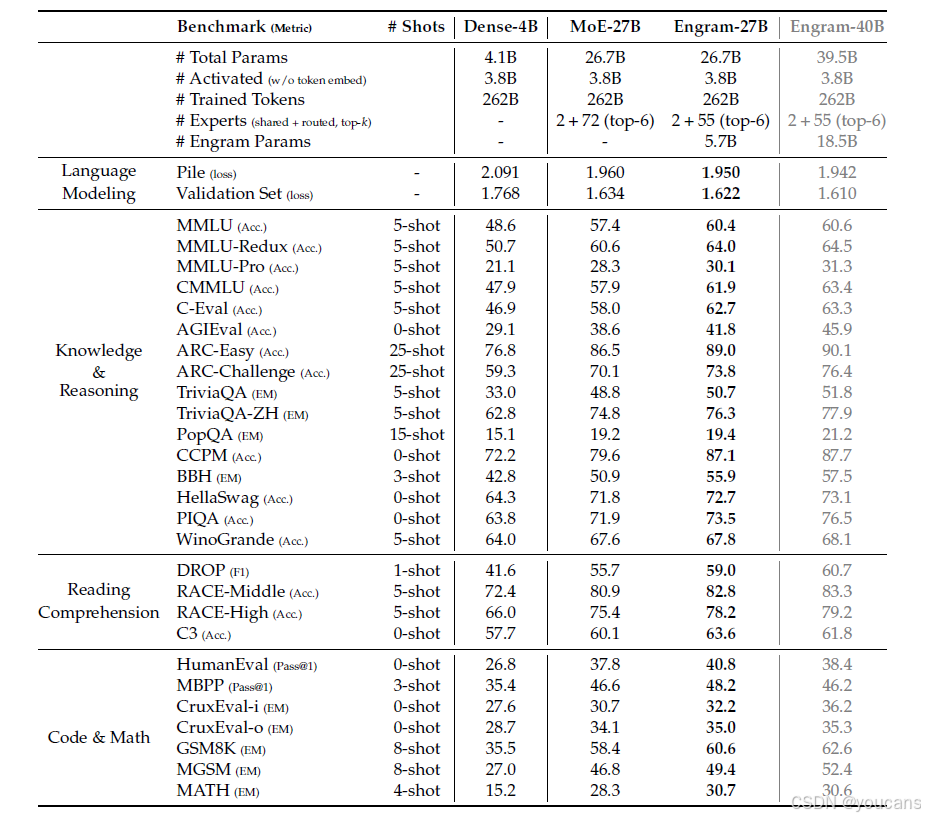
表1 | 稠密模型、MoE 模型与 Engram 模型的预训练性能对比。
所有模型均在 262B token 上训练,且激活参数量保持一致(3.8B)。Engram-27B 通过将路由专家参数从 72 减至 55,并把释放出的容量用于构建 5.7B 参数的 Engram 记忆,实现与 MoE-27B 的总参数量相等。Engram-40B 在保持激活参数预算不变的前提下,进一步将 Engram 记忆扩容至 18.5B 参数。完整的训练过程基准曲线见附录 B。
4.2 实验结果
表 1 总结了主要结果。
首先,与先前文献一致,在相同的训练计算预算下,与等计算量的 Dense-4B 基线相比,所有三种稀疏变体(MoE-27B、Engram-27B/40B)在所有基准测试上都显著优于 Dense-4B 基线。
更重要的是,Engram-27B 始终优于等参数量、等计算量的 MoE-27B 基线。有趣的是,这些增益不仅限于知识密集型任务(例如,MMLU: +3.0,MMLU-Pro: +1.8,CMMLU: +4.0),在这些任务中内存容量直观上是有益的。我们在通用推理领域(例如,BBH: +5.0,ARC-Challenge: +3.7,DROP: +3.3)以及代码和数学推理领域(例如,HumanEval: +3.0,MBPP: +1.6,GSM8K: +2.2,MATH: +2.4)观察到了更显著的改进。为了减少基准测试噪声的影响并可视化训练动态,我们在附录 B 中提供了预训练期间的完整基准测试轨迹。这些结果支持了我们的假设:引入专用的知识查找原语提高了表示效率,这种效率超出了将所有稀疏预算分配给条件计算所能达到的水平。
最后,扩展到 Engram-40B 进一步降低了预训练损失,并在大多数基准测试上提升了性能。虽然它尚未在所有任务上严格超越 Engram-27B,但这很可能是训练不足导致的。我们观察到,Engram-40B 与基线之间的训练损失差距在训练结束时继续扩大,这表明在当前词符预算内,扩展的内存容量尚未完全饱和。
5. 长上下文训练
通过将局部依赖建模卸载给静态查找,Engram架构保留了宝贵的注意力容量来管理全局上下文。在本节中,我们通过进行长上下文扩展训练来经验性地验证这一结构优势。通过一个严格的评估方案,该方案将架构贡献与基础模型能力分离开来,我们证明了Engram在长距离检索和推理任务中带来了显著的性能提升。
5.1 实验设置
训练细节。
为了启用长上下文能力,我们采用DeepSeek-V3中引入的上下文扩展策略。在预训练阶段之后,我们应用YaRN进行上下文窗口扩展,在一个32768个词符的上下文训练阶段进行5000步训练(使用300亿个高质量长上下文数据词符)。超参数设置为:尺度 s = 10 s=10 s=10, α = 1 \alpha=1 α=1, β = 32 \beta=32 β=32,缩放因子 f = 0.707 f=0.707 f=0.707。
模型配置。
我们比较了四种不同模型配置的上下文扩展。我们使用MoE-27B和Engram-27B的最终预训练检查点(50k步)。此外,为了严谨地评估架构效率,我们选择了Engram-27B在41k步和46k步的两个中间检查点。尽管初始化阶段不同,所有变体都经历了完全相同的上下文扩展训练方案。至关重要的是,选择Engram-27B(46k)是因为它表现出与完全训练的MoE-27B(50k)相同的预训练损失。这创建了一个受控的"等损失"设置,确保在上下文扩展期间任何性能差异可归因于架构而非模型的初始质量。
评估基准。
我们使用LongPPL和RULER评估长上下文性能。对于LongPPL,我们构建了涵盖四个类别的评估集:长书籍、研究论文、代码仓库和长思维链轨迹。对于RULER,我们评估了聚合为8个类别的14个子集:Single、Multi-keys、Multi-values 和 Multi-queries Needle-in-a-Haystack;多跳变量追踪、常见词提取、高频词提取和问答。
5.2 实验结果
评估结果总结在表2中。为了准确评估Engram架构的贡献,我们的分析分两步进行:首先,将基础模型能力的影响与架构设计解耦;其次,进行受控分析。
-
超越注意力机制的长上下文能力。 虽然注意力机制和位置编码为上下文处理提供了结构基础,但我们的结果表明,长上下文性能并非仅由架构先验决定。观察Engram从41k步到50k步的轨迹,我们发现即使控制模型架构相同且在上下文扩展阶段具有固定的计算预算,长上下文性能也会随着预训练的进展而单调提高。这表明长上下文性能与基础模型的通用建模能力内在相关。因此,严谨的架构比较必须通过对齐基础模型的损失,而不仅仅是训练步数,来控制这一混淆变量。
-
受控设置下的架构优越性。 遵循上述原则,我们将Engram与MoE基线进行基准测试。当控制基础能力相同时,Engram模块的效率增益变得明显:
-
等损失设置(46k vs 基线): 此设置严格隔离了架构效率。当比较Engram-27B(46k)与完全训练的MoE-27B(50k)------两者在预训练损失上对齐------时,Engram显示出显著的性能提升。具体来说,它在复杂的检索任务上超越了基线(例如,Multi-Query NIAH: 97.0 vs. 84.2;VT: 87.2 vs. 77.0)。
-
等计算量设置(50k vs 基线): 在标准的等计算预算下,Engram-27B(50k)进一步扩大了这一差距,在所有评估指标上确立了最高性能。
-
极限设置(约82%计算量): 即使是提前停止的Engram-27B(41k)与完全训练的MoE-27B(50k)相比仍然极具竞争力。它在LongPPL上与基线持平,并在RULER上超越基线,这突显了Engram架构固有的优越性。
-
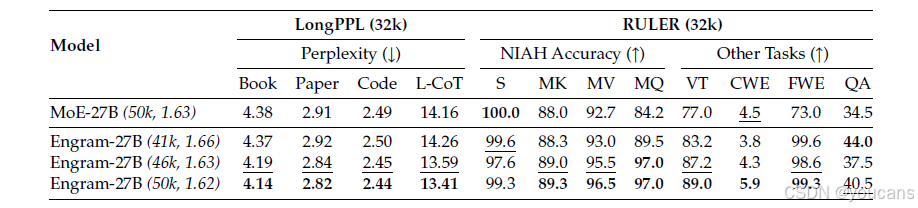
表2 | 长上下文性能对比。
括号内数值(如 (50k, 1.62))表示长上下文扩展前的预训练步数及对应损失。
两大关键发现:
(1) 仅使用 82% 的预训练算力(41k vs. 50k),Engram-27B 即达到基线的 LongPPL(Fang 等)性能,同时在 RULER(Hsieh 等)准确率上显著领先;
(2) 在"同等预训练损失"(46k)和"同等预训练算力"(50k)两种设定下,Engram-27B 在所有指标上均大幅超越基线。加粗为最优,下划为次优。
6. 分析
在本节中,我们研究了 Engram 的内部机制,包括其有效深度(第 6.1 节)、核心模块设计(第 6.2 节)和参数敏感性(第 6.3 节)。此外,我们评估了带有卸载功能的推理吞吐量(第 6.4 节),并以一个案例研究(第 6.5 节)作为结尾。
6.1. Engram 在功能上等同于增加了模型的深度吗?
当前的大语言模型缺乏专用的知识查找原语,它们依赖计算来模拟记忆回忆。如表 3 所示,为了识别实体"Diana, Princess of Wales",大语言模型必须消耗多个注意力层和前馈网络层来逐步组合特征,这个过程理论上可以通过一个知识查找操作来完成。
鉴于此,我们认为通过为模型配备显式的知识查找能力,Engram 有效地模拟了模型深度的增加,因为它解除了模型在早期阶段进行特征组合的负担。为了验证这个假设,我们使用了两种机制可解释性工具:LogitLens 和中心化核对齐分析。
表3 | 实体消歧示例,引自 Ghandeharioun 等(2024)。
该表展示了 LLM 如何逐层通过注意力与 FFN 整合上下文 token,逐步构建实体"威尔士王妃戴安娜"的内部表征
。"潜在状态翻译"列给出 PatchScope(Ghandeharioun 等,2024)为最后一个 token "Wales"自动生成的文本;"解释"列则为原作者提供的人工解读。

6.1.1 加速的预测收敛
我们首先使用 LogitLens 分析了预测在不同层级上的演变过程。通过将每个中间层的隐藏状态投影到最终的 LM 头部,我们计算了中间输出分布与模型最终输出分布之间的 KL 散度。这个指标量化了一个潜在表示距离"可以用于预测"的程度。
图 4 (a) 报告了逐层的 KL 散度。与 MoE 基线相比,两个 Engram 变体都表现出系统性的更小 KL 散度,最显著的差距出现在早期模块中。Engram 曲线中更陡峭的下降表明模型完成特征组合的速度要快得多。这一观察结果与我们的假设一致:通过显式地访问外部知识,Engram 减少了所需的计算步骤,从而在网络层级中更早地达到高置信度的有效预测。
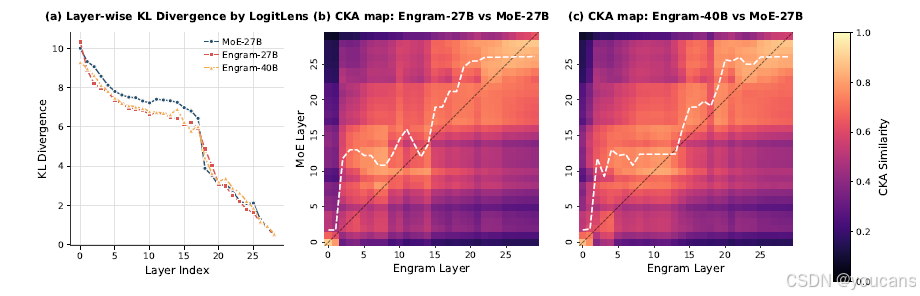
图4 | 表征对齐与收敛速度分析
(a) 通过 LogitLens(nostalgebraist,2020)计算逐层 KL 散度。早期层持续更低的散度表明 Engram 加快了预测收敛。
(b--c) 采用 CKA(Kornblith 等,2019)计算的相似度热力图。高相似度对角线的明显上移显示,Engram 的浅层在功能上等价于 MoE 模型的更深层,等效增加了模型深度。
6.1.2 表示对齐与有效深度
为了进一步研究 Engram 层是否在语义上对应基线的更深层,我们使用了中心化核对齐,这是一种广泛建立的用于比较表示结构的度量方法。给定两组表示 X X X 和 Y Y Y,CKA 定义为:
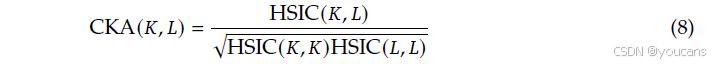
其中 K = X X ⊤ K=XX^{\top} K=XX⊤ 和 L = Y Y ⊤ L=YY^{\top} L=YY⊤ 表示格拉姆矩阵(使用线性核),HSIC 是希尔伯特-施密特独立性准则。我们使用一个带有 HSIC 无偏估计器的 minibatch 实现,并在 Few-NERD 数据集上评估,提取与命名实体最后一个词符对应的隐藏状态。
为了严格量化逐层的对应关系,我们首先计算成对的 CKA 相似度矩阵 S ∈ 0 , 1 L × L S \in 0,1^{L \times L} S∈0,1L×L,其中 L L L 是层数。然后,我们引入一个软对齐索引 a j a_j aj,定义为对于每个 Engram 层 j j j,与其最相似的前 k k k 个 MoE 层的加权质心:
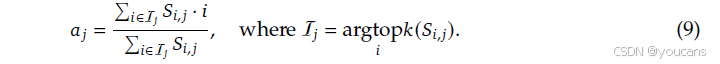
这里, S i , j S_{i,j} Si,j 表示 MoE 层 i i i 与 Engram 层 j j j 之间的相似度分数。索引 a j a_j aj 作为对应于 Engram 层 j j j 的"有效 MoE 深度"的稳健代理,利用前 k k k 个过滤( k = 5 k=5 k=5)来减轻低相似度的噪声。
图 4 (b)-© 可视化了带有软对齐曲线的相似度热图。我们观察到一个明显的向上偏移(偏离对角线),这意味着对于广泛的层来说, a j > j a_j > j aj>j。例如,Engram-27B 第 5 层形成的表示与 MoE 基线大约第 12 层的表示最为相似。
这种一致的偏离对角线偏移,与 LogitLens 的结果相吻合,证实了 Engram 在更早的层实现了更深层的表示。这验证了我们的核心假设:通过显式的查找操作绕过早期的特征组合阶段,Engram 在功能上等同于增加了模型的有效深度。
6.2 结构消融与层敏感性
在本节中,我们在受控设置下对 Engram 进行消融研究,以探究每个关键模块设计的有效性。除非另有说明,主干是一个 12 层 3B MoE 模型( 0.56 B 0.56\text{B} 0.56B 激活参数),训练了 100 B 100\text{B} 100B 个词符。图 5 报告了验证损失。橙色虚线表示 3B MoE 基线(验证损失 = 1.808 1.808 1.808)。
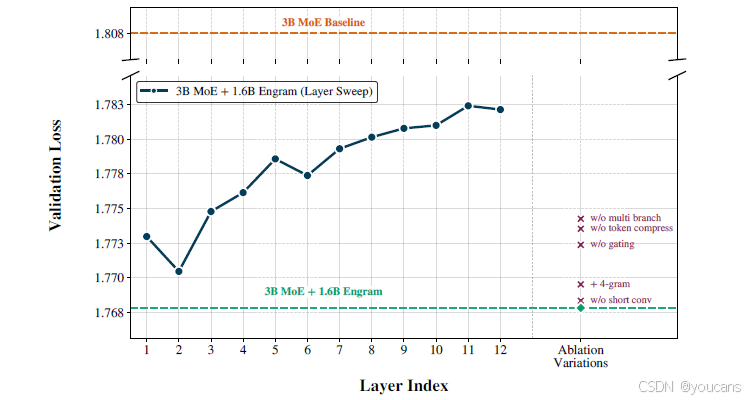
图5 | 架构消融实验结果。
我们将 3B MoE 基线与两种设定下的 Engram 变体进行对比:(1) 层敏感度(深蓝色曲线):单块 Engram 模块的插入深度扫描表明,早期注入(第 2 层)效果最佳,越深层功效越弱;(2) 组件消融(右侧标记):从参考配置中逐一移除子模块,验证了多分支融合、分词器压缩与上下文感知门控的关键作用。
参考配置。
我们用固定的 1.6 B 1.6\text{B} 1.6B 参数 Engram 记忆模块增强主干。我们的参考模型使用 2 , 3 {2,3} 2,3 元语法,并将 Engram 插入第 2 层和第 6 层,实现了验证损失 = 1.768 1.768 1.768,相较于 MoE 基线有显著改善( Δ = 0.04 \Delta = 0.04 Δ=0.04)。以下所有的结构消融都是相对于此参考配置定义的。
应该在何处注入记忆?
为了研究深度敏感性,我们保持 Engram 预算固定( 1.6 B 1.6\text{B} 1.6B),但将其合并为一个单独的 Engram 模块,并将其插入层从 1 扫描到 12。这个实验揭示了 Engram 放置位置固有的权衡。
一个放置权衡。
在早期注入 Engram 允许它在主干消耗计算深度之前卸载局部模式重构,这与主干自然的层次化处理方式相一致。然而,这会在门控精度上产生成本:早期的隐藏状态尚未通过注意力机制聚合足够的全局上下文,并且并行分支缺乏细粒度调制所需的表示差异。因此,最优的放置需要平衡 (i) 在早期卸载静态局部模式和 (ii) 利用更强的上下文查询进行后期门控。
扫描结果显示,第 2 层在单层注入设置下取得了最佳性能(验证损失 = 1.770 1.770 1.770),优于第 1 层,并且随着插入点变深而性能下降。这表明,一轮注意力已经足够为门控提供一个有意义的上下文化 h t \mathbf{h}_t ht,同时仍然足够早以替代主干的底层局部聚合。
虽然第 2 层在单次注入约束下是最优的,但我们发现,将相同的 1.6 B 1.6\text{B} 1.6B 内存拆分为两个较小的模块(通过减少嵌入维度 d mem d_{\text{mem}} dmem 实现),并将它们放置在第 2 层和第 6 层,性能甚至更好(验证损失 = 1.768 1.768 1.768)。这种分层设计结合了早期干预和丰富的后期上下文门控,调和了这一权衡。更重要的是,分层插入还提供了实际的系统优势,能够更好地利用第 2.5 节讨论的内存层次结构。
哪些组件重要?
从参考配置开始,我们逐一消融各个设计选择,同时保持 Engram 参数预算固定。结果由图 5 中的标记表示。我们发现三个组件产生了最显著的收益:(i) 多分支主干内的分支特定融合,(ii) 上下文感知门控,以及 (iii) 词符化器压缩。移除其中任何一个都会导致验证损失的最大回归。具体来说,对于"不带多分支"的消融,我们保留了 mHC 主干结构,但将分支特定的门控替换为单个 Engram 融合,该融合应用于预映射 H p r e \mathcal{H}^{pre} Hpre 之后的隐藏状态。
其他变化影响较小:
移除轻量级深度卷积只会轻微降低性能。在固定的 1.6 B 1.6\text{B} 1.6B 预算下,将容量分配给 4 元语法略次优------可能是因为它稀释了来自更频繁的 2/3 元语法模式的容量------尽管我们不排除在更大的内存规模下,更高阶的 N N N 元语法会变得有益。
6.3 敏感性分析
为了刻画 Engram 模块的功能性贡献,我们在推理过程中完全抑制稀疏嵌入输出,同时保持主干不变,以此来评估模型。至关重要的是,这种事后消融引入了训练-推理不一致性,可能在复杂的、混合能力的任务中引入噪声。因此,我们优先分析事实性知识和阅读理解------这是敏感性谱中的两个极端------在这项压力测试下它们表现出最高的信噪比。
如图 6 所示,结果揭示了一个显著的功能二分法。事实性知识基准测试遭受了灾难性的崩溃,仅保留了原始性能的 29-44%(例如,TriviaQA 为 29%),这证实了 Engram 模块是参数化知识的主要存储库。相反,阅读理解任务表现出显著的韧性,保留了 81-93%(例如,C3 为 93%),这表明基于上下文的任务主要依赖主干的注意力机制而非 Engram。
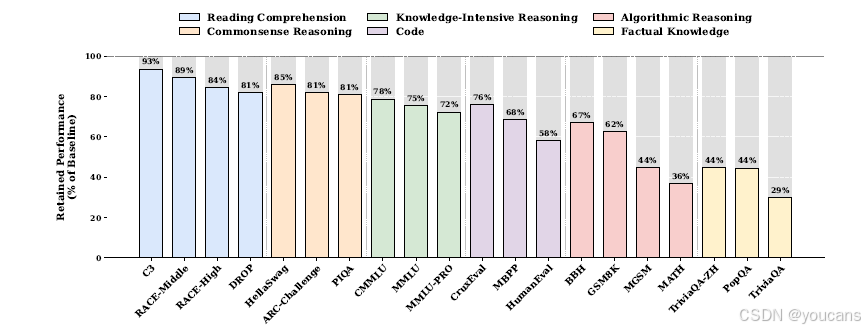
图6 | 移除 Engram 模块后的性能保留情况。事实知识高度依赖 Engram 模块,而阅读理解能力主要由主干网络保持。
6.4 系统效率
Engram 相对于基于路由的 MoE 的一个关键系统优势在于,其稀疏激活由显式的、静态的哈希 ID 寻址。这产生了一个严格确定性的内存访问模式:下一个 Engram 查找的索引在词符序列已知后即被确定,并且可以在相应层执行之前计算出来。
实验设置。
我们基于 nano-vLLM 实现了一个推理框架。为了获得一个干净的延迟基线,不受 MoE 中专家并行通信模式的影响,我们在两个密集主干(Dense-4B 和 Dense-8B)上进行基准测试。我们在第二个 Transformer 模块中插入了一个巨大的 100B 参数 Engram 层,整个嵌入表驻留在主机 DRAM 中。在推理过程中,系统异步预取 Engram 层的嵌入,将 PCIe 传输与第一个模块的计算重叠进行。
结果。
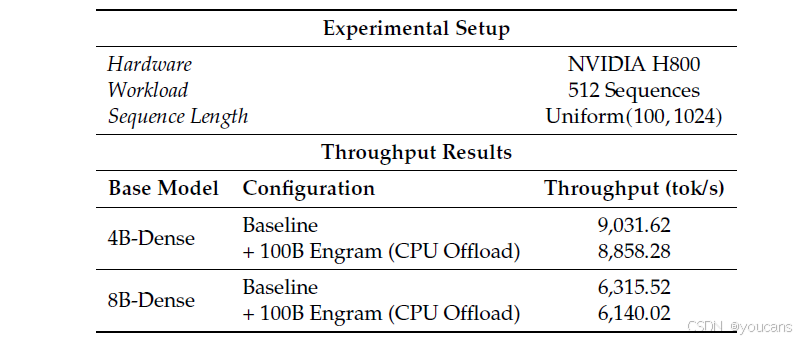
如表 4 详细所示,卸载一个 100B 参数的嵌入表带来的吞吐量损失可以忽略不计,在 8B 主干上峰值仅为 2.8%。这证实了早期密集模块的计算强度提供了足够的时间窗口来掩盖检索延迟。至关重要的是,每个步骤的有效通信量随激活的槽位数量而非总嵌入表大小而缩放。
至关重要的是,此实验作为一个保守的基线。虽然第 2.5 节中的层次化设计利用 Zipfian 局部性在 HBM 中缓存频繁访问的项目,但我们的实验设置强制所有检索都必须通过 PCIe 总线从主机内存获取。事实是,这种基线检索策略产生的开销极小,这强烈表明一个完全优化的、局部性感知的实现所带来的吞吐量损失将是微不足道的。
表4 | 端到端推理吞吐量。我们将一个 100B 参数的 Engram 层完全卸载到主机内存,并测量其推理吞吐量。
6.5 案例研究:门控可视化
在第 2.3 节中,我们介绍了上下文感知门控机制,旨在动态调制检索到的静态记忆与主干的集成。为了经验性地验证 Engram 是否按预期行为,我们在图 7 中可视化了 Engram-27B 在不同样本上的门控标量 α t \alpha_t αt。
结果表明了一种独特的选择性模式。该门控机制在完成局部的、静态的模式时始终激活(以红色显示)。在英语中,我们在多词元命名实体(例如,"Alexander the Great"、"the Milky Way")和公式化短语(例如,"By the way"、"Princess of Wales")上观察到强烈的激活。这种行为在不同语言中有效泛化。在中文示例中,Engram 识别并检索了独特的成语表达和历史实体,例如"四大发明"和"张仲景"。这些定性结果证实了 Engram 成功地识别并处理了刻板的语言依赖关系,有效地解除了 Transformer 主干记忆这些静态关联的负担。

图7 | Engram 门控机制可视化。
热力图强度对应门控标量 α_t ∈ 0, 1 的大小,深红色表示激活程度越高。由于 Engram 作用于后缀 N-gram(此处 N = 3),当某一 token x_t 出现高激活时,意味着以该 token 结尾的前序片段(即终止于 t 的短语)被识别为可从记忆中高效检索的静态模式。
7. 相关工作
N元语法建模与嵌入扩展。 起源于香农的框架, N N N元语法模型依赖局部历史来预测词符,传统上采用平滑技术来缓解数据稀疏性。尽管范式已转向神经架构以捕获长距离依赖,但 N N N元语法查找的计算效率在现代表示学习中得以保留,例如FastText等开创性工作。
最近,这一范式以嵌入扩展的形式复兴。虽然Per-Layer Embeddings和DeepEmbed等架构通过海量表来扩展容量,但一系列独特且与我们的方法最相关的前沿研究直接将组合式的 N N N元语法结构集成到表示空间中。SuperBPE和SCONE明确针对高频模式:前者通过将多词表达式合并为"超词"词符,后者则通过辅助编码模型。与此同时,OverEncoding和字节潜在变换器分别采用哈希 N N N元语法嵌入来捕获词符级和字节级的局部依赖性。这些研究共同证明了通过 N N N元语法表示扩展参数且计算开销最小的有效性。虽然这些方法在各自的应用场景中带来了显著提升,但我们的工作在两个关键维度上存在根本性差异。
- 首先,在建模和评估方案方面。先前的方法通常将 N N N元语法嵌入视为外部增强,而未在严格公平的对比方案下验证其效率。例如,SCONE专注于推理,并依赖额外模块,从而产生额外的训练计算量。类似地,即使在非等参数设置下,OverEncoding在稀疏MoE主干上也未能产生有意义的改进。相比之下,我们将条件记忆视为一个一等的建模原语,通过精心设计的Engram模块实例化。通过在我们的稀疏分配框架内严谨评估这一设计,我们证明了其相对于严格的等参数和等计算量MoE基线的明确优势。
- 其次,从系统角度来看,我们倡导算法-系统协同设计。现有方法将嵌入严格放置在输入层,这在本质上将内存访问与计算序列化。相反,Engram策略性地将记忆注入到更深层,以实现通信-计算重叠。此外,通过利用 N N N元语法固有的Zipfian分布,我们可以最大化硬件内存层次结构的效用。这种整体设计使得Engram能够扩展到海量参数,而推理开销几乎可以忽略。
-
混合专家模型。
MoE架构通过为每个词符有条件地激活稀疏的专家子集,将模型容量与计算成本解耦,这一范式由Shazeer等人引入。后续的创新,如GShard、BASE、Switch Transformer和GLaM实现了超线性的参数扩展,同时保持恒定的推理成本。最近,DeepSeek-MoE通过细粒度的专家划分和共享专家隔离,证明了其卓越的效率,显著优于具有等效活跃参数的密集模型。采用此架构,最先进的模型如DeepSeek-V3和Kimi-k2进一步将总参数量推至数千亿规模。
-
记忆网络。
记忆增强网络的研究旨在扩展模型容量而不成比例地增加计算成本,大致可分为参数化和非参数化方法。参数化记忆方法,如PKM、PEER、Selfmem、Memory+和UltraMem,将大规模的稀疏键值存储直接集成到模型层中,从而显著增加容量而对计算量影响甚微。相反,非参数化记忆方法如REALM、RETRO和PlugLM将知识存储与模型处理解耦,将外部内存视为可编辑和可扩展的键值存储,使模型能够适应不断变化的信息而无需重新训练。
-
知识存储机制。
与容量扩展并行,大量研究审查了控制Transformer编码和检索事实性知识的内部机制。前馈网络被广泛假设为具有键值记忆功能。在此框架下,第一层充当模式检测器,而第二层将特定信息投影到残差流中。通过识别负责存储不同事实的特定"知识神经元",证明了这种模块性。因果追踪方法提供了进一步的验证,该方法将事实回忆的信息流映射到特定的前馈网络层。这些见解使得精确的模型编辑算法成为可能,如ROME和MEMIT,它们允许直接更新事实关联而无需重新训练。此外,对内部表示的研究(例如Othello-GPT中的研究)表明,这些存储机制可能促进了结构化"世界模型"的出现,而不仅仅是统计记忆。
8. 结论
在本工作中,我们引入了条件记忆作为对主流条件计算范式(MoE)的一个互补稀疏化维度,旨在解决通过动态计算模拟知识检索的低效性问题。我们通过 Engram 模块将这一概念具体化,该模块对经典的 N N N 元语法嵌入进行了现代化改造,以实现针对静态模式的可扩展、恒定时间 O ( 1 ) O(1) O(1) 查找。
通过构建稀疏分配问题,我们发现了一条U形缩放定律,证明了在MoE专家与Engram记忆之间进行混合稀疏容量分配,严格优于纯MoE基线。在此定律的指导下,我们将Engram扩展到270亿参数,在多个领域实现了卓越的性能。值得注意的是,虽然记忆模块直观上有助于知识检索,但我们在通用推理、代码和数学领域观察到了更大的性能提升。
我们的机制分析表明,Engram通过解除早期层进行静态重建任务的负担,有效地"加深"了网络,从而释放了注意力容量以专注于全局上下文和复杂推理。这种架构转变转化为长上下文能力的实质性提升,正如在LongPPL和RULER上的性能增益所证明的那样。最后,Engram倡导将面向基础设施的效率作为一等设计原则。其确定性寻址允许存储与计算的解耦,使得能够将海量参数表卸载到主机内存中,而推理开销几乎可以忽略不计。我们展望条件记忆将成为下一代稀疏模型中不可或缺的建模原语。
9. 代码介绍
Deepseek 公开了 Engram 架构演示实现 代码:engram_demo_v1.py
- 快速开始
推荐使用 Python 3.8+ 和 PyTorch。
bash
pip install torch numpy transformers sympy提供了一个独立的实现来展示 Engram 模块的核心逻辑:
bash
python engram_demo_v1.py⚠️ 注意: 提供的代码是演示版本,旨在说明数据流。为专注于 Engram 模块,代码中模拟了标准组件(如 Attention、MoE、mHC)。
engram_demo_v1.py 代码如下。
python
## built-in
from typing import List
from dataclasses import dataclass, field
import math
## third-class
from sympy import isprime
import numpy as np
import torch
import torch.nn as nn
from transformers import AutoTokenizer
from tokenizers import normalizers, Regex
@dataclass
class EngramConfig:
tokenizer_name_or_path: str = "deepseek-ai/DeepSeek-V3"
engram_vocab_size: List[int] = field(default_factory=lambda: [129280*5, 129280*5])
max_ngram_size: int = 3
n_embed_per_ngram: int = 512
n_head_per_ngram: int = 8
layer_ids: List[int] = field(default_factory=lambda: [1, 15])
pad_id: int = 2
seed: int = 0
kernel_size: int = 4
@dataclass
class BackBoneConfig:
hidden_size: int = 1024
hc_mult: int = 4
vocab_size: int = 129280
num_layers: int = 30
engram_cfg = EngramConfig()
backbone_config = BackBoneConfig()
class CompressedTokenizer:
def __init__(
self,
tokenizer_name_or_path,
):
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path, trust_remote_code=True)
SENTINEL = "\uE000"
self.normalizer = normalizers.Sequence([
normalizers.NFKC(),
normalizers.NFD(),
normalizers.StripAccents(),
normalizers.Lowercase(),
normalizers.Replace(Regex(r"[ \t\r\n]+"), " "),
normalizers.Replace(Regex(r"^ $"), SENTINEL),
normalizers.Strip(),
normalizers.Replace(SENTINEL, " "),
])
self.lookup_table, self.num_new_token = self._build_lookup_table()
def __len__(self):
return self.num_new_token
def _build_lookup_table(self):
old2new = {}
key2new = {}
new_tokens = []
vocab_size = len(self.tokenizer)
for tid in range(vocab_size):
text = self.tokenizer.decode([tid], skip_special_tokens=False)
if "�" in text:
key = self.tokenizer.convert_ids_to_tokens(tid)
else:
norm = self.normalizer.normalize_str(text)
key = norm if norm else text
nid = key2new.get(key)
if nid is None:
nid = len(new_tokens)
key2new[key] = nid
new_tokens.append(key)
old2new[tid] = nid
lookup = np.empty(vocab_size, dtype=np.int64)
for tid in range(vocab_size):
lookup[tid] = old2new[tid]
return lookup, len(new_tokens)
def _compress(self, input_ids):
arr = np.asarray(input_ids, dtype=np.int64)
pos_mask = arr >= 0
out = arr.copy()
valid_ids = arr[pos_mask]
out[pos_mask] = self.lookup_table[valid_ids]
return out
def __call__(self, input_ids):
return self._compress(input_ids)
class ShortConv(nn.Module):
def __init__(
self,
hidden_size: int,
kernel_size: int = 4,
dilation: int = 1,
norm_eps: float = 1e-5,
hc_mult: int = 4,
activation: bool = True,
):
super().__init__()
self.hc_mult = hc_mult
self.activation = activation
total_channels = hidden_size * hc_mult
self.conv = nn.Conv1d(
in_channels=total_channels,
out_channels=total_channels,
kernel_size=kernel_size,
groups=total_channels,
bias=False,
padding=(kernel_size - 1) * dilation,
dilation=dilation,
)
self.norms = nn.ModuleList([
nn.RMSNorm(hidden_size, eps=norm_eps)
for _ in range(hc_mult)
])
if self.activation:
self.act_fn = nn.SiLU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Input: (B,L,HC_MULT,D)
Output: (B,L,HC_MULT,D)
"""
B, T, G, C = x.shape
assert G == self.hc_mult, f"Input groups {G} != hc_mult {self.hc_mult}"
normed_chunks = []
for i in range(G):
chunk = x[:, :, i, :]
normed_chunks.append(self.norms[i](chunk))
x_norm = torch.cat(normed_chunks, dim=-1)
x_bct = x_norm.transpose(1, 2)
y_bct = self.conv(x_bct)
y_bct = y_bct[..., :T]
if self.activation:
y_bct = self.act_fn(y_bct)
y = y_bct.transpose(1, 2).view(B, T, G, C).contiguous()
return y
def find_next_prime(start, seen_primes):
candidate = start + 1
while True:
if isprime(candidate) and candidate not in seen_primes:
return candidate
candidate += 1
class NgramHashMapping:
def __init__(
self,
engram_vocab_size,
max_ngram_size,
n_embed_per_ngram,
n_head_per_ngram,
layer_ids,
tokenizer_name_or_path,
pad_id,
seed,
):
self.vocab_size_per_ngram = engram_vocab_size
self.max_ngram_size = max_ngram_size
self.n_embed_per_ngram = n_embed_per_ngram
self.n_head_per_ngram = n_head_per_ngram
self.pad_id = pad_id
self.layer_ids = layer_ids
self.compressed_tokenizer = CompressedTokenizer(
tokenizer_name_or_path=tokenizer_name_or_path
)
self.tokenizer_vocab_size = len(self.compressed_tokenizer)
if self.pad_id is not None:
self.pad_id = int(self.compressed_tokenizer.lookup_table[self.pad_id])
max_long = np.iinfo(np.int64).max
M_max = int(max_long // self.tokenizer_vocab_size)
half_bound = max(1, M_max // 2)
PRIME_1 = 10007
self.layer_multipliers = {}
for layer_id in self.layer_ids:
base_seed = int(seed + PRIME_1 * int(layer_id))
g = np.random.default_rng(base_seed)
r = g.integers(
low=0,
high=half_bound,
size=(self.max_ngram_size,),
dtype=np.int64
)
multipliers = r * 2 + 1
self.layer_multipliers[layer_id] = multipliers
self.vocab_size_across_layers = self.calculate_vocab_size_across_layers()
def calculate_vocab_size_across_layers(self):
seen_primes = set()
vocab_size_across_layers = {}
for layer_id in self.layer_ids:
all_ngram_vocab_sizes = []
for ngram in range(2, self.max_ngram_size + 1):
current_ngram_heads_sizes = []
vocab_size = self.vocab_size_per_ngram[ngram - 2]
num_head = self.n_head_per_ngram
current_prime_search_start = vocab_size - 1
for _ in range(num_head):
found_prime = find_next_prime(
current_prime_search_start,
seen_primes
)
seen_primes.add(found_prime)
current_ngram_heads_sizes.append(found_prime)
current_prime_search_start = found_prime
all_ngram_vocab_sizes.append(current_ngram_heads_sizes)
vocab_size_across_layers[layer_id] = all_ngram_vocab_sizes
return vocab_size_across_layers
def _get_ngram_hashes(
self,
input_ids: np.ndarray,
layer_id: int,
) -> np.ndarray:
x = np.asarray(input_ids, dtype=np.int64)
B, T = x.shape
multipliers = self.layer_multipliers[layer_id]
def shift_k(k: int) -> np.ndarray:
if k == 0: return x
shifted = np.pad(x, ((0, 0), (k, 0)),
mode='constant', constant_values=self.pad_id)[:, :T]
return shifted
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)]
all_hashes = []
for n in range(2, self.max_ngram_size + 1):
n_gram_index = n - 2
tokens = base_shifts[:n]
mix = (tokens[0] * multipliers[0])
for k in range(1, n):
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
num_heads_for_this_ngram = self.n_head_per_ngram
head_vocab_sizes = self.vocab_size_across_layers[layer_id][n_gram_index]
for j in range(num_heads_for_this_ngram):
mod = int(head_vocab_sizes[j])
head_hash = mix % mod
all_hashes.append(head_hash.astype(np.int64, copy=False))
return np.stack(all_hashes, axis=2)
def hash(self, input_ids):
input_ids = self.compressed_tokenizer(input_ids)
hash_ids_for_all_layers = {}
for layer_id in self.layer_ids:
hash_ids_for_all_layers[layer_id] = self._get_ngram_hashes(input_ids, layer_id=layer_id)
return hash_ids_for_all_layers
class MultiHeadEmbedding(nn.Module):
def __init__(self, list_of_N: List[int], D: int):
super().__init__()
self.num_heads = len(list_of_N)
self.embedding_dim = D
offsets = [0]
for n in list_of_N[:-1]:
offsets.append(offsets[-1] + n)
self.register_buffer("offsets", torch.tensor(offsets, dtype=torch.long))
total_N = sum(list_of_N)
self.embedding = nn.Embedding(num_embeddings=total_N, embedding_dim=D)
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
shifted_input_ids = input_ids + self.offsets
output = self.embedding(shifted_input_ids)
return output
class Engram(nn.Module):
def __init__(self,layer_id):
super().__init__()
self.layer_id = layer_id
self.hash_mapping = NgramHashMapping(
engram_vocab_size=engram_cfg.engram_vocab_size,
max_ngram_size = engram_cfg.max_ngram_size,
n_embed_per_ngram = engram_cfg.n_embed_per_ngram,
n_head_per_ngram = engram_cfg.n_head_per_ngram,
layer_ids = engram_cfg.layer_ids,
tokenizer_name_or_path=engram_cfg.tokenizer_name_or_path,
pad_id = engram_cfg.pad_id,
seed = engram_cfg.seed,
)
self.multi_head_embedding = MultiHeadEmbedding(
list_of_N = [x for y in self.hash_mapping.vocab_size_across_layers[self.layer_id] for x in y],
D = engram_cfg.n_embed_per_ngram // engram_cfg.n_head_per_ngram,
)
self.short_conv = ShortConv(
hidden_size = backbone_config.hidden_size,
kernel_size = engram_cfg.kernel_size,
dilation = engram_cfg.max_ngram_size,
hc_mult = backbone_config.hc_mult,
)
engram_hidden_size = (engram_cfg.max_ngram_size-1) * engram_cfg.n_embed_per_ngram
self.value_proj = nn.Linear(engram_hidden_size,backbone_config.hidden_size)
self.key_projs = nn.ModuleList(
[nn.Linear(engram_hidden_size,backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)]
)
self.norm1 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)])
self.norm2 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)])
def forward(self,hidden_states,input_ids):
"""
hidden_states: [B, L, HC_MULT, D]
input_ids: [B, L]
"""
hash_input_ids = torch.from_numpy(self.hash_mapping.hash(input_ids)[self.layer_id])
embeddings = self.multi_head_embedding(hash_input_ids).flatten(start_dim=-2)
gates = []
for hc_idx in range(backbone_config.hc_mult):
key = self.key_projs[hc_idx](embeddings)
normed_key = self.norm1[hc_idx](key)
query = hidden_states[:,:,hc_idx,:]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(backbone_config.hidden_size)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign()
gate = gate.sigmoid().unsqueeze(-1)
gates.append(gate)
gates = torch.stack(gates,dim=2)
value = gates * self.value_proj(embeddings).unsqueeze(2)
output = value + self.short_conv(value)
return output
class TransformerBlock(nn.Module):
def __init__(self,layer_id):
super().__init__()
self.attn = lambda x:x
self.moe = lambda x:x
self.engram = None
if layer_id in engram_cfg.layer_ids:
self.engram = Engram(layer_id=layer_id)
def forward(self,input_ids,hidden_states):
if self.engram is not None:
hidden_states = self.engram(hidden_states=hidden_states,input_ids=input_ids) + hidden_states
hidden_states = self.attn(hidden_states) + hidden_states
hidden_states = self.moe(hidden_states) + hidden_states
return hidden_states
if __name__ == '__main__':
LLM = [
nn.Embedding(backbone_config.vocab_size,backbone_config.hidden_size),
*[TransformerBlock(layer_id=layer_id) for layer_id in range(backbone_config.num_layers)],
nn.Linear(backbone_config.hidden_size, backbone_config.vocab_size)
]
text = "Only Alexander the Great could tame the horse Bucephalus."
tokenizer = AutoTokenizer.from_pretrained(engram_cfg.tokenizer_name_or_path,trust_remote_code=True)
input_ids = tokenizer(text,return_tensors='pt').input_ids
B,L = input_ids.shape
for idx, layer in enumerate(LLM):
if idx == 0:
hidden_states = LLM[0](input_ids)
## mock hyper-connection
hidden_states = hidden_states.unsqueeze(2).expand(-1, -1, backbone_config.hc_mult, -1)
elif idx == len(LLM)-1:
## mock hyper-connection
hidden_states = hidden_states[:,:,0,:]
output = layer(hidden_states)
else:
hidden_states = layer(input_ids=input_ids,hidden_states=hidden_states)
print("✅ Forward Complete!")
print(f"{input_ids.shape=}\n{output.shape=}")
10. 参考文献
bash
1. LENNIE P. The cost of cortical computation[J]. Current biology, 2003, 13(6): 493-497.
2. OLSHAUSEN B A, FIELD D J. Sparse coding with an overcomplete basis set: A strategy employed by V1?[J]. Vision research, 1997, 37(23): 3311-3325.
3. DAI D et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models[EB/OL]. arXiv preprint arXiv:2401.06066, 2024.
4. SHAZEER N et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[EB/OL]. arXiv preprint arXiv:1701.06538, 2017.
5. COMANICI G et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities[EB/OL]. arXiv preprint arXiv:2507.06261, 2025.
6. GUO D et al. Deepseek-rl: Incentivizing reasoning capability in LLMs via reinforcement learning[EB/OL]. arXiv preprint arXiv:2501.12948, 2025.
7. TEAM K et al. Kimi linear: An expressive, efficient attention architecture[EB/OL]. arXiv preprint arXiv:2510.26692, 2025.
8. CONSTANT M et al. Survey: multiword expression processing: a survey[J]. Computational Linguistics, 2017, 43(4): 837-892.
9. ERMAN B. The idiom principle and the open choice principle[J]. Text-Interdisciplinary Journal for the Study of Discourse, 2000.
10. BRANTS T et al. Large language models in machine translation[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL). Prague, Czech Republic: Association for Computational Linguistics, 2007: 858-867.
11. LIU J et al. Infini-gram: Scaling unbounded n-gram language models to a trillion tokens[C]//First Conference on Language Modeling, 2024.
12. NGUYEN T. Understanding transformers via n-gram statistics[J]. Advances in neural information processing systems, 2024, 37: 98049-98082.
13. VASWANI A et al. Attention is all you need[C]//Advances in neural information processing systems, 2017: 5998-6008.
14. GHANDEHARIOUN A et al. Patchscopes: A unifying framework for inspecting hidden representations of language models[C]//International Conference on Machine Learning. PMLR, 2024: 15466-15490.
15. JIN M et al. Exploring concept depth: How large language models acquire knowledge and concept at different layers?[C]//Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE: Association for Computational Linguistics, 2025: 558-573.
16. BENGIO Y et al. Estimating or propagating gradients through stochastic neurons for conditional computation[EB/OL]. arXiv preprint arXiv:1308.3432, 2013.
17. BOJANOWSKI P et al. Enriching word vectors with subword information[J]. Transactions of the association for computational linguistics, 2017, 5: 135-146.
18. HUANG H et al. Over-tokenized transformer: Vocabulary is generally worth scaling[C]//Forty-second International Conference on Machine Learning. Vancouver, BC, Canada: OpenReview.net, 2025.
19. PAGNONI A et al. Byte latent transformer: Patches scale better than tokens[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025: 9238-9258.
20. TITO SVENSTRUP D et al. Hash embeddings for efficient word representations[C]//Advances in neural information processing systems, 2017.
21. YU D et al. Scaling embedding layers in language models[EB/OL]. arXiv preprint arXiv:2502.01637, 2025.
22. BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[C]//3rd International Conference on Learning Representations. San Diego, CA, USA, 2015.
23. DEHGHANI M et al. Scaling vision transformers to 22 billion parameters[C]//Proceedings of the 40th International Conference on Machine Learning. 2023: 7480-7512.
24. ZHANG B, SENNRICH R. Root mean square layer normalization[C]//Advances in neural information processing systems, 2019.
25. GU A, GOEL K, RE C. Efficiently modeling long sequences with structured state spaces[C]//The Tenth International Conference on Learning Representations. Virtual Event, 2022.
26. PENG B et al. RWKV: reinventing RNNs for the transformer era[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. Singapore: Association for Computational Linguistics, 2023: 14048-14077.
27. ELFWING S, UCHIBE E, DOYA K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning[J]. Neural networks, 2018, 107: 3-11.
28. HE K et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
29. LARSSON G, MAIRE M, SHAKHNAROVICH G. Fractalnet: Ultra-deep neural networks without residuals[C]//5th International Conference on Learning Representations. Toulon, France, 2017.
30. SZEGEDY C et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
31. XIE Z et al. Manifold-constrained hyper-connections[EB/OL]. arXiv preprint arXiv:2512.24880, 2025.
32. ZHU D et al. Hyper-connections[C]//The Thirteenth International Conference on Learning Representations. Singapore, 2025.
33. CHAO Y R, ZIPF G K. Human behavior and the principle of least effort: An introduction to human ecology[J]. Language, 1950, 26: 394.
34. PIANTADOSI S T. Zipfs word frequency law in natural language: A critical review and future directions[J]. Psychonomic bulletin & review, 2014, 21(5): 1112-1130.
35. HUANG Z et al. Ultra-sparse memory network[C]//The Thirteenth International Conference on Learning Representations. Singapore, 2025.
36. LIU A et al. Deepseek-v3 technical report[EB/OL]. arXiv preprint arXiv:2412.19437, 2024.
37. JORDAN K et al. Muon: an optimizer for hidden layers in neural networks[EB/OL]. arXiv preprint arXiv:2408.09634, 2024.
38. TEAM G. Gamma 3n[EB/OL]. 2025.
39. KINGMA D P. Adam: A method for stochastic optimization[EB/OL]. arXiv preprint arXiv:1412.6980, 2014.
40. GAO L et al. The pile: An 800gb dataset of diverse text for language modeling[EB/OL]. arXiv preprint arXiv:2101.00027, 2020.
41. HENDRYCKS D et al. Measuring massive multitask language understanding[C]//9th International Conference on Learning Representations. Virtual Event, Austria, 2021.
42. GEMA A P et al. Are we done with mmlu?[C]//Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025: 5069-5096.
43. WANG Y et al. Mmlu-pro: a more robust and challenging multi-task language understanding benchmark[J]. Advances in Neural Information Processing Systems, 2024, 37: 95266-95290.
44. LI H et al. Cmmlu: Measuring massive multitask language understanding in Chinese[C]//Findings of the Association for Computational Linguistics: ACL 2024. 2024: 11260-11285.
45. HUANG Y et al. C-eval: A multi-level multi-discipline Chinese evaluation suite for foundation models[J]. Advances in Neural Information Processing Systems, 2023, 36: 62991-63010.
46. ZHONG W et al. Agieval: a human-centric benchmark for evaluating foundation models[C]//Findings of the Association for Computational Linguistics: NAACL 2024. 2024: 2299-2314.
47. CLARK P et al. Think you have solved question answering? try arc, the AI2 reasoning challenge[EB/OL]. arXiv preprint arXiv:1803.05457, 2018.
48. JOSHI M et al. Triviaqa: a large scale distantly supervised challenge dataset for reading comprehension[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver, Canada: Association for Computational Linguistics, 2017: 1601-1611.
49. MALLEN A et al. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023: 9802-9822.
50. LI W et al. Ccpm: A Chinese classical poetry matching dataset[EB/OL]. arXiv preprint arXiv:2106.01979, 2021.
51. SUZGUN M et al. Challenging big-bench tasks and whether chain-of-thought can solve them[C]//Findings of the Association for Computational Linguistics: ACL 2023. 2023: 13003-13051.
52. ZELLERS R et al. Hellaswag: Can a machine really finish your sentence?[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019: 4791-4800.
53. BISK Y et al. Piqa: Reasoning about physical commonsense in natural language[C]//Proceedings of the AAAI conference on artificial intelligence, volume 34. 2020: 7432-7439.
54. SAKAGUCHI K et al. Winogrande: An adversarial winograd schema challenge at scale[J]. Communications of the ACM, 2021, 64(9): 99-106.
55. DUA D et al. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, MN, USA: Association for Computational Linguistics, 2019: 2368-2378.
56. LAI G et al. Race: Large-scale reading comprehension dataset from examinations[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 785-794.
57. SUN K et al. Investigating prior knowledge for challenging Chinese machine reading comprehension[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 141-155.
58. CHEN M et al. Evaluating large language models trained on code[EB/OL]. arXiv preprint arXiv:2107.03374, 2021.
59. AUSTIN J et al. Program synthesis with large language models[EB/OL]. arXiv preprint arXiv:2108.07732, 2021.
60. GU A et al. Cruveval: A benchmark for code reasoning, understanding and execution[C]//Forty-first International Conference on Machine Learning. Vienna, Austria: OpenReview.net, 2024.
61. COBBE K et al. Training verifiers to solve math word problems[EB/OL]. arXiv preprint arXiv:2110.14168, 2021.
62. SHI F et al. Language models are multilingual chain-of-thought reasoners[C]//The Eleventh International Conference on Learning Representations. Kigali, Rwanda, 2023.
63. HENDRYCKS D et al. Measuring mathematical problem solving with the MATH dataset[C]//Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1. 2021.
64. BORGEAUD S et al. Improving language models by retrieving from trillions of tokens[C]//International conference on machine learning. PMLR, 2022: 2206-2240.
65. HE X O. Mixture of a million experts[EB/OL]. arXiv preprint arXiv:2407.04153, 2024.
66. FANG L et al. What is wrong with perplexity for long-context language modeling?[C]//The Thirteenth International Conference on Learning Representations.
67. HSIEH C-P et al. Ruler: What\'s the real context size of your long-context language models?[C]//First Conference on Language Modeling.
68. GAO T et al. How to train long-context language models (effectively)[C]//Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025: 7376-7399.
69. PENG B et al. Yarn: Efficient context window extension of large language models[C]//The Twelfth International Conference on Learning Representations. Vienna, Austria, 2024.
70. PRESS O, SMITH N A, LEWIS M. Train short, test long: Attention with linear biases enables input length extrapolation[C]//The Tenth International Conference on Learning Representations. Virtual Event, 2022.
71. SU J et al. Roformer: Enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063.
72. XIAO G et al. Efficient streaming language models with attention sinks[C]//The Twelfth International Conference on Learning Representations. Vienna, Austria, 2024.
73. YANG S et al. Path attention: position encoding via accumulating householder transformations[EB/OL]. arXiv preprint arXiv:2505.16381, 2025.
74. BELROSE N et al. Eliciting latent predictions from transformers with the tuned lens[EB/OL]. arXiv preprint arXiv:2303.08112, 2023.
75. NOSTALGEBRAIST. Interpreting gpt: the logit lens[EB/OL]. LessWrong, 2020.
76. CSORDAS R, MANNING C D, POTTS C. Do language models use their depth efficiently?[EB/OL]. arXiv preprint arXiv:2505.13898, 2025.
77. DAVARI M et al. Reliability of CKA as a similarity measure in deep learning[C]//The Eleventh International Conference on Learning Representations. Kigali, Rwanda, 2023.
78. KORNBLITH S et al. Similarity of neural network representations revisited[C]//International conference on machine learning. 2019: 3519-3529.
79. KULLBACK S, LEIBLER R A. On information and sufficiency[J]. The annals of mathematical statistics, 1951, 22(1): 79-86.
80. DING N et al. Few-nerd: A few-shot named entity recognition dataset[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 3198-3213.
81. LI M, SUBRAMANI N. Echoes of bert: Do modern language models rediscover the classical nlp pipeline?[EB/OL]. arXiv preprint arXiv:2506.02132, 2025.
82. TENNEY I, DAS D, PAVLICK E. Bert rediscovers the classical nlp pipeline[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019.
83. KWON W et al. Efficient memory management for large language model serving with pagedattention[C]//Proceedings of the 29th symposium on operating systems principles. 2023: 611-626.
84. HABER J, POESIO M. Polysemy---Evidence from linguistics, behavioral science, and contextualized language models[J]. Computational Linguistics, 2024, 50(1): 351-417.
85. SHANNON C E. A mathematical theory of communication[J]. The Bell system technical journal, 1948, 27(3): 379-423.
86. KATZ S M. Estimation of probabilities from sparse data for the language model component of a speech recognizer[J]. IEEE Trans. Acoust. Speech Signal Process., 1987, 35(3): 400-401.
87. KNESER R, NEY H. Improved backing-off for M-gram language modeling[C]//International conference on acoustics, speech, and signal processing, volume 1. 1995: 181-184.
88. BENGIO Y, DUCHARME R, VINCENT P. A neural probabilistic language model[J]. J. Mach. Learn. Res., 2003, 3: 1137-1155.
89. LIU A et al. SuperBPE: Space travel for language models[C]//Second Conference on Language Modeling, 2025.
90. LAMPLE G et al. Large memory layers with product keys[C]//Advances in Neural Information Processing Systems, 2019.
91. CHENG X et al. Decouple knowledge from paramters for plug-and-play language modeling[C]//Findings of the Association for Computational Linguistics: ACL 2023. Toronto, Canada: Association for Computational Linguistics, 2023: 14288-14308.
92. BERGÈS V et al. Memory layers at scale[C]//Forty-second International Conference on Machine Learning. Vancouver, BC, Canada: OpenReview.net, 2025.
93. HUANG Z et al. Ultramenv2: Memory networks scaling to 120b parameters with superior long-context learning[EB/OL]. arXiv preprint arXiv:2508.18756, 2025.
94. GUU K et al. Retrieval augmented language model pre-training[C]//International conference on machine learning. PMLR, 2020: 3929-3938.
95. WANG B et al. Shall we pretrain autoregressive language models with retrieval? a comprehensive study[C]//Proceedings of the 2023 conference on empirical methods in natural language processing. 2023: 7763-7786.
96. CHENG X et al. Lift yourself up: Retrieval-augmented text generation with self-memory[J]. Advances in Neural Information Processing Systems, 2023, 36: 43780-43799.
97. GEVA M et al. Transformer feed-forward layers are key-value memories[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 5484-5495.
98. DAI D et al. Knowledge neurons in pretrained transformers[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 8493-8502.
99. MENG K et al. Locating and editing factual associations in GPT[C]//Advances in neural information processing systems, 2022, 35: 17359-17372.
100. MENG K et al. Mass-editing memory in a transformer[C]//The Eleventh International Conference on Learning Representations. Kigali, Rwanda, 2023.
101. LI K et al. Emergent world representations: Exploring a sequence model trained on a synthetic task[C]//The Eleventh International Conference on Learning Representations. Kigali, Rwanda, 2023.
102. DEEPSEEK-AI et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model[EB/OL]. arXiv preprint arXiv:2405.04434, 2024.
103. BI X et al. Deepseek llm: Scaling open-source language models with longterm[EB/OL]. arXiv preprint arXiv:2401.02954, 2024.
104. WANG L et al. Auxiliary-loss-free load balancing strategy for mixture-of-experts[EB/OL]. arXiv preprint arXiv:2408.15664, 2024.
105. GREETON A et al. Measuring statistical dependence with hilbert-schmidt norms[C]//International conference on algorithmic learning theory. Springer, 2005: 63-77.
106. KRIEGESKORTE N, MUR M, BANDETTINI P A. Representational similarity analysis-connecting the branches of systems neuroscience[J]. Frontiers in systems neuroscience, 2008, 2: 249.
107. KUDO T, RICHARDSON J. Sentencepiece: a simple and language independent subword tokenizer and detokenizer for neural text processing[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 66-71.
108. WHISTLER K. Unicode standard annex #15: Unicode normalization forms[S]. Unicode Standard Annex 15, The Unicode Consortium, July 2025.
109. TEAM R. Rwkv architecture history[EB/OL]. 2025. Section "RWKV-V8's DeepEmbed", accessed 2025-12-09.
110. FEDUS W, ZOPH B, SHAZEER N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. Journal of Machine Learning Research, 2022, 23(120): 1-39.
111. DU N et al. Glam: Efficient scaling of language models with mixture-of-experts[C]//International conference on machine learning. PMLR, 2022: 5547-5569.
112. LEPIKHIN D et al. Gshard: Scaling giant models with conditional computation and automatic sharding[EB/OL]. arXiv preprint arXiv:2006.16668, 2020.
113. LEWIS M et al. Base layers: Simplifying training of large, sparse models[C]//Proceedings of the 38th International Conference on Machine Learning. 2021: 6265-6274.版权声明:
本文由 youcans@xidian 对论文 "通过可扩展查找的条件记忆:大语言模型稀疏化的新维度(Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models)" 进行摘编和翻译,只供研究学习使用。
youcans@xidian 作品 ,转载必须标注原文链接:
【DeepSeek论文精读】17. 通过可扩展查找的条件记忆:大语言模型稀疏化的新维度
Copyright 2026 youcans@Xidian
Created:2026-01
