⭐ 深度学习入门体系(第 20 篇): 如何从 0 到 1 训练一个稳定、可复现的深度学习模型
------让训练变得"可控、可靠、可解释"
深度学习最让人头疼的问题是什么?
不是模型难,也不是数学难,而是:
一次训练好,一次训练崩;
换一台机器结果变了;
改一点配置,就训练乱飞。
许多初学者以为这是"运气",
但工程师都知道:
稳定训练是可以系统设计的。
这一篇,我会带你从零开始搭建一个 "可复现的深度学习训练全流程" 。
无论你训练的是猫狗分类还是大型 Transformer,这套流程都能直接用。
文章目录
- [⭐ 深度学习入门体系(第 20 篇): 如何从 0 到 1 训练一个稳定、可复现的深度学习模型](#⭐ 深度学习入门体系(第 20 篇): 如何从 0 到 1 训练一个稳定、可复现的深度学习模型)
- [🎯 一、训练深度学习模型的终极目标是什么?](#🎯 一、训练深度学习模型的终极目标是什么?)
- [📦 二、从 0 开始应该准备什么?](#📦 二、从 0 开始应该准备什么?)
-
- [① 准备一个干净的数据结构](#① 准备一个干净的数据结构)
- [② 明确任务是什么(非常关键)](#② 明确任务是什么(非常关键))
- [③ 选择最简单的 experiment base(起点配置)](#③ 选择最简单的 experiment base(起点配置))
- [🛠 三、训练流程第一阶段:准备数据](#🛠 三、训练流程第一阶段:准备数据)
- [🚀 四、训练流程第二阶段:确定超参数](#🚀 四、训练流程第二阶段:确定超参数)
-
- [(1)batch size](#(1)batch size)
- [(2)学习率(Learning Rate)](#(2)学习率(Learning Rate))
- (3)优化器
- (4)调度器(Scheduler)
- [🧱 五、训练流程第三阶段:编写训练循环(最重要)](#🧱 五、训练流程第三阶段:编写训练循环(最重要))
- [📊 六、训练流程第四阶段:监控与分析曲线](#📊 六、训练流程第四阶段:监控与分析曲线)
-
- [① train_loss](#① train_loss)
- [② val_loss](#② val_loss)
- [③ 学习率曲线](#③ 学习率曲线)
- [🧪 七、训练流程第五阶段:解决训练中的常见问题](#🧪 七、训练流程第五阶段:解决训练中的常见问题)
-
-
- [症状 1:loss 不下降](#症状 1:loss 不下降)
- [症状 2:acc 一直不上升](#症状 2:acc 一直不上升)
- [症状 3:训练集 95%,验证集 50%](#症状 3:训练集 95%,验证集 50%)
- [症状 4:不同机器训练结果不同](#症状 4:不同机器训练结果不同)
-
- [📦 八、训练流程第六阶段:保存、部署、推理](#📦 八、训练流程第六阶段:保存、部署、推理)
- [🧠 九、总结:深度学习训练不是玄学,而是流程科学](#🧠 九、总结:深度学习训练不是玄学,而是流程科学)
- [🔜 下一阶段:深入模型结构与工程进阶](#🔜 下一阶段:深入模型结构与工程进阶)
🎯 一、训练深度学习模型的终极目标是什么?
一句话总结:
让模型在看不见的新数据上表现稳定可靠。
也就是"泛化能力"。
训练过程的一切:
- 数据增强
- 学习率
- batch size
- 正则
- early stopping
- 验证集
- 训练曲线分析
都不是为了让模型在训练集上表现好,而是让它在真实使用中表现好。
这是你设计训练方案的唯一中心思想。
📦 二、从 0 开始应该准备什么?
我们按顺序来。
① 准备一个干净的数据结构
示例结构:
dataset/
train/
class1/
class2/
val/
class1/
class2/或者自定义 Dataset,但是建议第一步统一成干净结构。
数据结构乱,训练效率会直接降低。
② 明确任务是什么(非常关键)
你需要清楚地写出:
- 分类?
- 多分类?
- 回归?
- 多标签?
- 是否存在数据不平衡?
不同任务的损失函数、指标都不同。
③ 选择最简单的 experiment base(起点配置)
这是深度学习工程师的"黄金策略":
第一次训练绝对不要用复杂模型。
从小模型、小数据增强、小 batch 开始跑通流程。
比如:
- ResNet18
- batch 16
- LR = 1e-3
- Adam
- CrossEntropy
先保证流程是对的,再往上叠。
🛠 三、训练流程第一阶段:准备数据
本系列已经讲过数据增强,本篇给你一个工程师常用的最稳定增强组合:
python
train_transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.3),
A.ShiftScaleRotate(shift_limit=0.05, scale_limit=0.1, rotate_limit=20, p=0.5),
A.Normalize(),
ToTensorV2(),
])验证集不应该加随机增强:
python
val_transform = A.Compose([
A.Resize(224, 224),
A.Normalize(),
ToTensorV2(),
])为什么?
训练模型是教它变强,验证模型是检查它真实表现。
检查时不要加随机扰动。
🚀 四、训练流程第二阶段:确定超参数
这是工程中的"关键配置表"。
(1)batch size
- 显存小:8~32
- 显存大:64~256
- 大模型:512+(加累积)
(2)学习率(Learning Rate)
默认起点:
- AdamW:3e-4
- SGD:0.1(大 batch)
整个系列你已经知道:
学习率是训练成败的核心。
(3)优化器
推荐:
- AdamW(最稳)
- SGD(大 batch、高精度场景)
(4)调度器(Scheduler)
主流配置:
Warmup + Cosine Annealing
现代深度学习几乎都是这样配。
🧱 五、训练流程第三阶段:编写训练循环(最重要)
一个可靠的训练循环应具备:
- 前向传播
- 反向传播
- 学习率更新
- 准确率计算
- 日志记录
- 保存 best model 权重
- early stopping(可选)
工程模板:
python
for epoch in range(epochs):
model.train()
for x, y in train_loader:
y_pred = model(x)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.eval()
with torch.no_grad():
for x, y in val_loader:
y_pred = model(x)
val_loss += criterion(y_pred, y).item()训练循环不是写越花哨越好,而是越稳定、干净、易读越好。
📊 六、训练流程第四阶段:监控与分析曲线
训练过程不能盲跑。
你应该重点关注三条曲线:
① train_loss
反映模型是否在学习。
② val_loss
反映模型是否在泛化。
③ 学习率曲线
反映优化节奏是否合理。
如果你看到:
- train_loss ↓
- val_loss ↓
恭喜,模型正在变强。
如果你看到:
- train_loss ↓
- val_loss ↑
这是典型的过拟合,马上调整策略。
训练不是调参游戏,而是"诊断病情 + 对症下药"。
🧪 七、训练流程第五阶段:解决训练中的常见问题
下面是工程师常见"训练疑难杂症"以及对应解决方案。
症状 1:loss 不下降
可能原因:
- 学习率太大 → 调低
- 输入数据没归一化
- 标签处理错误
症状 2:acc 一直不上升
可能原因:
- 数据增强过强
- 优化器设置不对
- 学习率曲线不合理
症状 3:训练集 95%,验证集 50%
典型过拟合 → 用第 19 篇的武器库。
症状 4:不同机器训练结果不同
解决思路:
- 固定随机种子
- 固定数据加载顺序
- 使用 deterministic 模式
- 确保版本一致
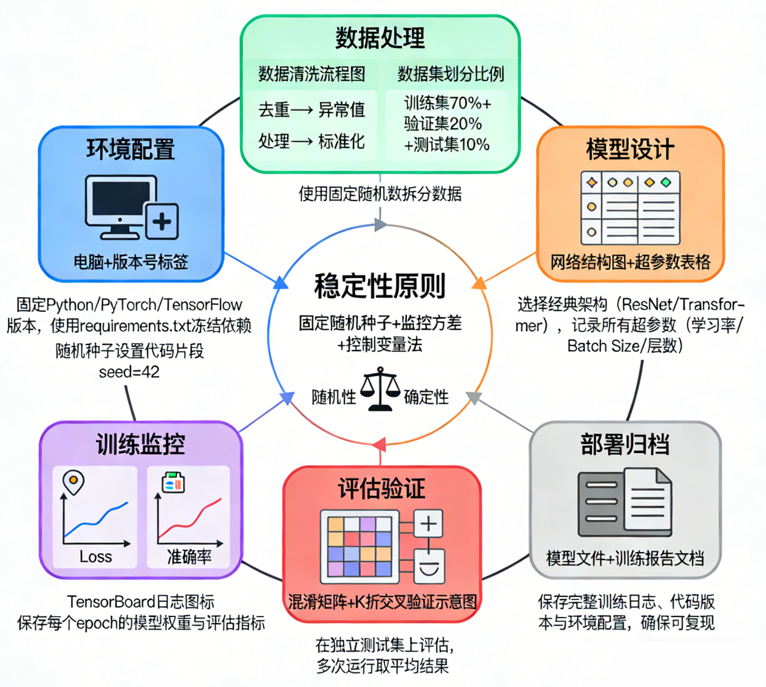
📦 八、训练流程第六阶段:保存、部署、推理
简单流程:
- 保存 best 权重
- 编写 predict.py
- 使用 TorchScript 或 ONNX 导出
- 在实际环境测试推理速度
- 根据需要量化、剪枝、压缩
你不需要一次把所有做好,但至少:
训练模型不难,部署模型才是真正的"工程能力"。
🧠 九、总结:深度学习训练不是玄学,而是流程科学
你现在应该完全理解:
- 为什么训练要从小模型开始
- 为什么学习率决定训练成败
- 为什么 batch size 会影响泛化
- 为什么数据增强是第一生产力
- 为什么要用 warmup + cosine
- 为什么要监控验证集曲线
- 为什么训练成功可以"被设计"
和大家最初的印象不同:
训练深度学习模型不是靠运气,而是靠系统化方法。
从数据 → 模型 → 优化 → 正则 → 曲线分析 → 保存部署
每一步都决定最终结果。
如果你掌握了这一篇内容,那么你已经具备了"独立训练任意模型"的基本能力。
🔜 下一阶段:深入模型结构与工程进阶
至此,《深度学习入门体系》第 1 阶段(20 篇)正式收尾。
下一阶段将进入大模型、训练技巧、Transformer 与 ViT 的深入讲解。