RGA:当检索增强生成迈向自主进化的下一代框架
从RAG到RGA:生成式AI的范式演进
在深入探讨RGA之前,让我们先回顾一下它演进而来的基础框架------RAG(检索增强生成)。
想象一位准备重要演讲的学者。传统大语言模型如同依赖固定记忆库 的专家,只能基于训练时学到的知识回答问题,无法获取最新信息或特定领域资料。而RAG则像是为这位专家配备了实时研究助手:当问题提出时,助手先检索相关文献,然后将这些资料与问题一同交给专家,生成更准确、更具时效性的回答。
这就是RAG的核心价值:将外部知识检索与大语言模型生成能力相结合,解决模型的"知识固化"和"幻觉"问题。
但RAG有其局限性:
-
检索与生成是单向流水线:检索→生成,过程不可逆
-
检索结果质量决定上限:若检索不到相关信息,生成质量必然受限
-
缺乏动态优化:无法根据生成效果调整检索策略
正是在这样的背景下,RGA(Retrieve, Generate, Augment,检索-生成-增强) 应运而生,形成了一个更加动态、迭代和自优化的框架。
RGA三重奏:检索、生成、增强的循环交响
第一阶段:智能检索(Retrieve)
与传统RAG的简单检索不同,RGA的检索阶段更加智能化和多维度:
-
多源异构检索:同时查询结构化数据库、非结构化文档、实时信息流甚至多模态数据
-
迭代式查询优化:根据初步检索结果,自动重写和优化查询语句
-
上下文感知检索:考虑对话历史、用户偏好等上下文信息进行个性化检索
python
# 简化的RGA检索过程示意
def rga_retrieve(query, context, iteration=0):
# 1. 根据迭代次数调整检索策略
if iteration > 0:
query = rewrite_query_based_on_feedback(query, previous_results)
# 2. 并行多源检索
vector_results = vector_db.search(query, top_k=10)
keyword_results = keyword_search(query, top_k=5)
realtime_results = fetch_realtime_data(query)
# 3. 智能结果融合与排序
combined_results = intelligent_reranking(
vector_results, keyword_results, realtime_results,
relevance_scores, diversity_weight=0.3
)
return combined_results[:8] # 返回最优的8个结果第二阶段:条件生成(Generate)
生成阶段不仅仅基于检索结果,还融入了质量评估和不确定性量化:
-
基于证据的生成:明确标注生成内容与检索证据的对应关系
-
多版本生成:针对同一检索集,生成多个不同风格或侧重点的答案
-
置信度标注:自动评估生成结果的可信度,高亮不确定部分
python
def rga_generate(retrieved_docs, query, generation_config):
# 1. 证据-声明对齐
claim_evidence_pairs = align_claims_with_evidence(retrieved_docs)
# 2. 多视角生成
versions = []
for perspective in ["concise", "detailed", "cautious", "creative"]:
version = llm_generate(
prompt=build_prompt(query, retrieved_docs, perspective),
temperature=generation_config[perspective]["temp"]
)
versions.append({
"text": version,
"perspective": perspective,
"confidence": calculate_confidence(version, retrieved_docs)
})
# 3. 综合评估与选择
best_version = select_best_version(versions, user_profile)
return best_version, versions # 返回最佳版本和所有备选第三阶段:知识增强(Augment)
这是RGA最具创新性的环节,实现了系统的自我进化:
-
闭环反馈学习:根据用户交互反馈,优化未来检索和生成策略
-
知识库动态更新:将高质量生成内容经过验证后,反哺到知识库中
-
检索器与生成器协同优化:通过强化学习让两个组件相互适应和提升
python
def rga_augment(query, generated_response, user_feedback, knowledge_base):
# 1. 反馈分析
feedback_analysis = analyze_feedback(user_feedback, generated_response)
# 2. 知识提炼与验证
if feedback_analysis["is_high_quality"]:
new_knowledge = extract_knowledge_snippets(generated_response)
validated_knowledge = human_in_the_loop_validation(new_knowledge)
# 3. 知识库增量更新
knowledge_base.add(
content=validated_knowledge,
metadata={
"source": "generated",
"query": query,
"confidence": feedback_analysis["confidence_score"],
"timestamp": current_time()
}
)
# 4. 模型参数微调
if feedback_analysis["requires_model_update"]:
fine_tune_retriever_weights(feedback_analysis)
adjust_generation_parameters(feedback_analysis)
return updated_knowledge_baseRGA的技术架构:一个自我进化的生态系统
核心创新:双向优化循环
传统RAG是单向的"检索→生成"流程,而RGA建立了双向优化循环:
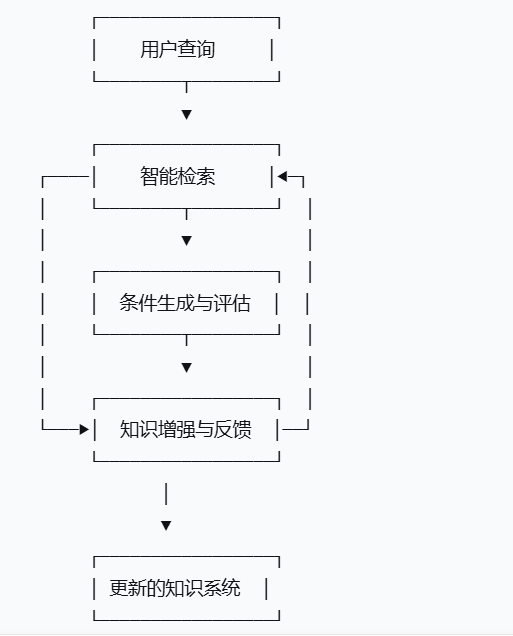
关键技术组件
-
自适应检索器:能够根据生成质量反馈调整检索策略的神经网络检索器
-
元学习生成器:具备"学习如何生成"能力的模型,快速适应新领域
-
知识蒸馏模块:将生成的高质量内容提炼为结构化知识
-
多目标优化器:平衡准确性、新颖性、多样性和安全性的优化框架
RGA的应用场景:从静态工具到智能伙伴
1. 研究助手2.0
传统研究助手只能检索已有文献,RGA系统能够:
-
发现跨学科的知识连接
-
基于现有文献生成研究假设
-
将新发现自动整合到知识库中
2. 动态知识管理系统
在企业环境中,RGA可以:
-
自动总结会议讨论并更新公司知识库
-
识别知识盲区并建议学习材料
-
随着业务发展自主扩展知识覆盖范围
3. 个性化教育导师
RGA驱动的教育系统:
-
根据学生反馈动态调整教学策略
-
从成功教学案例中提炼最佳实践
-
生成个性化的学习路径和练习题目
4. 创意协作伙伴
在创意领域,RGA能够:
-
检索相关艺术风格并生成新颖融合
-
从用户偏好中学习审美倾向
-
将成功的创意选择反哺到风格库中
RGA的挑战与未来方向
当前技术挑战
-
计算复杂度:三重循环迭代需要更多计算资源
-
错误传播风险:增强阶段的错误可能被固化到系统中
-
评估难题:如何准确评估系统整体进化效果而非单次输出质量
-
安全与伦理:自主知识更新可能引入偏见或错误信息
前沿研究方向
-
轻量化RGA架构:降低计算需求,实现边缘设备部署
-
可解释性增强:让系统的"思考过程"更加透明
-
跨模态统一框架:处理文本、图像、音频的通用RGA系统
-
联邦学习集成:在保护隐私的前提下实现多系统协同进化
结语:从工具到伙伴的范式转变
RGA代表了生成式AI发展的一个重要方向:从静态的工具到动态的伙伴。传统AI系统如同精密的仪器,功能固定,需要人工维护和更新。而RGA系统则更像一个不断成长的学习伙伴,能够从每次交互中学习,扩展自己的能力边界。
这种转变的技术意义在于,它开始解决大语言模型的核心局限------知识固化 和缺乏持续学习能力。通过检索、生成、增强的三重循环,RGA系统不仅回答问题,更在互动中构建和扩展自身的知识体系。
正如人类智慧不仅在于记忆已知,更在于从经验中学习和成长,RGA框架正将这一特质赋予人工智能系统。在这个框架下,每一次对话都不只是信息的交换,更是系统进化的一小步,指向一个更加智能、适应性和自主的未来。
当我们期待AI真正理解世界、创造新知时,RGA或许提供了那条从"拥有知识的系统"到"能够获得知识的系统"的关键路径。这条路刚刚开始,但方向已经明确:未来的AI不会只告诉我们已知的答案,而会与我们一同探索未知的领域。