引言
你有没有遇到过这样的困扰:列表滑动时CPU占用飙升到80%,但代码看起来没什么问题?或者数据库查询明明只有几百条数据,却耗时几百毫秒?这些性能瓶颈往往隐藏在你看不见的地方------复杂的算法、频繁的对象创建、低效的SQL语句、或者不当的文件I/O操作。
本文将带你深入CPU和I/O性能优化 的核心领域,通过Simpleperf火焰图 精准定位CPU热点,通过SQLite优化技巧 将查询性能提升10倍,通过文件I/O优化策略显著降低磁盘开销。无论你是被CPU占用困扰的Framework工程师,还是需要优化存储性能的应用开发者,这篇文章都将为你提供从分析到实战的完整解决方案。
你将学到:
- 使用Simpleperf生成和解读火焰图,精准定位CPU热点
- SQLite数据库性能优化的7大核心技巧
- 文件I/O性能优化的实战方法
- 线程池配置与并发优化最佳实践
- 真实案例:将数据库查询从500ms优化到50ms
CPU性能分析深入
Simpleperf工具详解
Simpleperf是Android提供的CPU性能分析工具,基于Linux perf封装,专门用于分析Android应用和系统进程的CPU性能瓶颈。
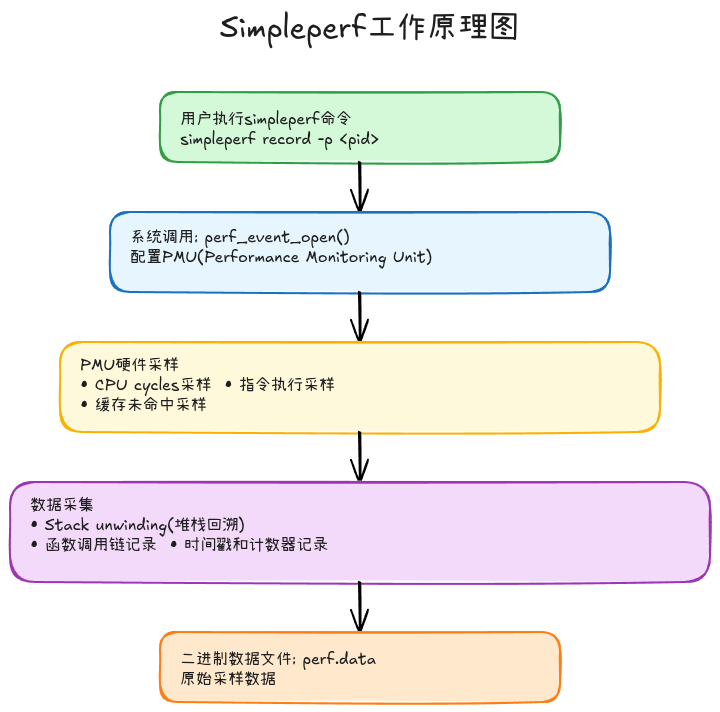
核心特性:
- 无需Root: Android 9及以上支持应用自采样
- 支持Java/Native: 同时分析Java代码和JNI/NDK代码
- 火焰图生成: 内置FlameGraph脚本,可视化CPU热点
- 多进程采样: 可以同时分析多个进程
安装Simpleperf:
bash
# 方法1: 从SDK获取(推荐)
cd $ANDROID_SDK/ndk/<version>/simpleperf
# 方法2: 从设备提取
adb pull /system/bin/simpleperf ./
# 方法3: 从AOSP编译
cd aosp/system/extras/simpleperf
mmCPU性能数据采集
基本采样命令:
bash
# 1. 采样指定进程(按包名)
adb shell simpleperf record -p <pid> -o /data/local/tmp/perf.data --duration 10
# 2. 采样指定线程
adb shell simpleperf record -t <tid> -o /data/local/tmp/perf.data --duration 10
# 3. 采样所有进程(需要Root)
adb shell simpleperf record -a -o /data/local/tmp/perf.data --duration 10
# 4. 采样应用启动阶段
adb shell simpleperf record --app com.example.app \
--duration 10 -o /data/local/tmp/perf.data高级采样参数:
bash
# 指定采样频率(默认4000Hz)
simpleperf record -p <pid> -f 1000 -o perf.data
# 采样特定CPU事件
simpleperf record -p <pid> -e cpu-cycles,cache-misses -o perf.data
# 采样调用栈(最大深度)
simpleperf record -p <pid> -g --call-graph dwarf -o perf.data
# 同时采样Java和Native
simpleperf record -p <pid> --symfs / --app com.example.app -o perf.data实战示例 - 采样音乐播放器:
bash
# Step 1: 获取进程PID
PID=$(adb shell pidof com.music.player)
# Step 2: 开始采样(播放音乐时)
adb shell simpleperf record -p $PID \
-g --call-graph dwarf \
--duration 30 \
-o /data/local/tmp/music_perf.data
# Step 3: 拉取数据到本地
adb pull /data/local/tmp/music_perf.data ./
# Step 4: 查看采样报告
./simpleperf report -i music_perf.data火焰图生成与解读
火焰图(Flame Graph) 是可视化CPU性能数据的最佳方式,由Brendan Gregg发明。
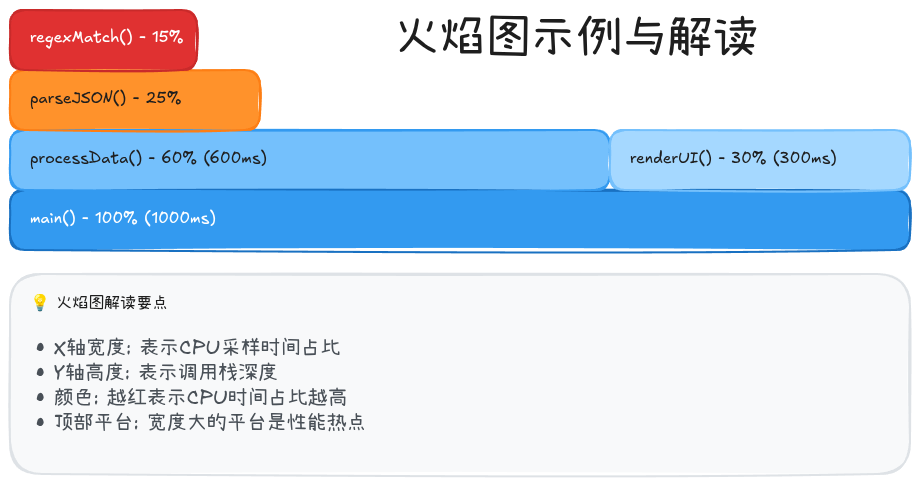
生成火焰图步骤:
bash
# 1. 转换perf.data为火焰图格式
./simpleperf report -i perf.data -g --full-callgraph > perf.txt
# 2. 使用FlameGraph工具生成SVG
# 下载FlameGraph工具
git clone https://github.com/brendangregg/FlameGraph.git
# 转换格式
cat perf.txt | ./FlameGraph/stackcollapse-perf.pl > perf.folded
# 生成火焰图
./FlameGraph/flamegraph.pl perf.folded > flamegraph.svgAndroid Studio集成方案:
kotlin
// 在代码中嵌入Simpleperf采样
class PerformanceProfiler {
fun startProfiling(activity: Activity) {
// Android 10+支持应用自采样
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.Q) {
Debug.startMethodTracingSampling(
File(activity.externalCacheDir, "trace.trace").absolutePath,
8 * 1024 * 1024, // 8MB buffer
10000 // 10ms interval
)
}
}
fun stopProfiling() {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.Q) {
Debug.stopMethodTracing()
}
}
}火焰图解读技巧:
-
识别热点函数:
- 宽度大的函数 = CPU占用高
- 平台状的函数块 = 直接消耗CPU的热点
- 尖塔状的函数块 = 调用链深但单个函数耗时少
-
关注这些信号:
热点1: 频繁的对象创建
java.lang.Object.
(5.2%)
java.util.ArrayList.(3.1%)
→ 对象池/缓存优化热点2: 字符串操作
java.lang.String.substring (4.8%)
java.lang.StringBuilder.toString (2.9%)
→ 减少字符串拼接热点3: 反射调用
java.lang.reflect.Method.invoke (6.7%)
→ 缓存反射结果或使用MethodHandle热点4: JSON解析
com.google.gson.Gson.fromJson (8.3%)
→ 使用更快的序列化库(Moshi/kotlinx.serialization)
CPU热点定位实战
案例: 图片列表滑动卡顿分析
bash
# 1. 采样滑动过程
adb shell simpleperf record -p <pid> --app com.gallery.app \
-g --call-graph dwarf --duration 20 -o /data/local/tmp/scroll_perf.data
# 2. 分析热点
adb pull /data/local/tmp/scroll_perf.data ./
./simpleperf report -i scroll_perf.data --sort comm,symbol | head -30发现的问题:
# 火焰图显示热点
BitmapFactory.decodeStream: 35.2% ← 主线程解码图片!
ImageView.setImageBitmap: 12.8% ← 频繁设置图片
RecyclerView.onBindViewHolder: 8.5%
# 解决方案
kotlin
// ❌ Before: 主线程解码
override fun onBindViewHolder(holder: ViewHolder, position: Int) {
val bitmap = BitmapFactory.decodeFile(imagePath) // 阻塞主线程!
holder.imageView.setImageBitmap(bitmap)
}
// ✅ After: 异步解码+缓存
class ImageLoader {
private val memoryCache = LruCache<String, Bitmap>(cacheSize)
private val executor = Executors.newFixedThreadPool(4)
fun loadImage(path: String, imageView: ImageView) {
// 1. 检查内存缓存
memoryCache.get(path)?.let {
imageView.setImageBitmap(it)
return
}
// 2. 异步解码
executor.execute {
val options = BitmapFactory.Options().apply {
inSampleSize = calculateInSampleSize(this, reqWidth, reqHeight)
inJustDecodeBounds = false
}
val bitmap = BitmapFactory.decodeFile(path, options)
// 3. 缓存+主线程设置
memoryCache.put(path, bitmap)
imageView.post { imageView.setImageBitmap(bitmap) }
}
}
}
// 优化结果: CPU占用从78% → 32%, 滑动帧率从35fps → 58fpsCPU性能优化策略
算法优化
时间复杂度优化:
kotlin
// ❌ Bad: O(n²) 嵌套循环
fun findDuplicates(list: List<Int>): List<Int> {
val duplicates = mutableListOf<Int>()
for (i in list.indices) {
for (j in i + 1 until list.size) {
if (list[i] == list[j]) {
duplicates.add(list[i])
}
}
}
return duplicates
}
// ✅ Good: O(n) 使用HashSet
fun findDuplicates(list: List<Int>): List<Int> {
val seen = mutableSetOf<Int>()
val duplicates = mutableSetOf<Int>()
for (num in list) {
if (!seen.add(num)) { // add返回false表示已存在
duplicates.add(num)
}
}
return duplicates.toList()
}避免频繁创建对象:
kotlin
// ❌ Bad: 每次调用都创建Date对象
fun formatTime(timestamp: Long): String {
val sdf = SimpleDateFormat("yyyy-MM-DD HH:mm:ss") // 频繁创建!
return sdf.format(Date(timestamp))
}
// ✅ Good: 使用对象池或ThreadLocal
object DateFormatter {
private val formatter = ThreadLocal.withInitial {
SimpleDateFormat("yyyy-MM-DD HH:mm:ss", Locale.getDefault())
}
fun format(timestamp: Long): String {
return formatter.get()!!.format(Date(timestamp))
}
}线程池优化配置
核心参数计算:
kotlin
object ThreadPoolConfig {
// CPU密集型任务: 核心线程数 = CPU核数 + 1
val CPU_COUNT = Runtime.getRuntime().availableProcessors()
val CPU_INTENSIVE_POOL = ThreadPoolExecutor(
CPU_COUNT + 1,
CPU_COUNT + 1,
0L, TimeUnit.SECONDS,
LinkedBlockingQueue<Runnable>(),
ThreadFactory { r -> Thread(r, "cpu-worker").apply { priority = Thread.NORM_PRIORITY } }
)
// I/O密集型任务: 核心线程数 = 2 * CPU核数
val IO_INTENSIVE_POOL = ThreadPoolExecutor(
CPU_COUNT * 2,
CPU_COUNT * 2,
60L, TimeUnit.SECONDS,
LinkedBlockingQueue<Runnable>(256),
ThreadFactory { r -> Thread(r, "io-worker").apply { priority = Thread.NORM_PRIORITY } }
)
// 定时任务: 使用ScheduledThreadPoolExecutor
val SCHEDULED_POOL = ScheduledThreadPoolExecutor(
2,
ThreadFactory { r -> Thread(r, "scheduled-worker").apply { priority = Thread.NORM_PRIORITY } }
)
}线程池使用最佳实践:
kotlin
class TaskExecutor {
companion object {
// 不同类型任务使用不同线程池
fun executeCpuTask(task: Runnable) {
ThreadPoolConfig.CPU_INTENSIVE_POOL.execute(task)
}
fun executeIoTask(task: Runnable) {
ThreadPoolConfig.IO_INTENSIVE_POOL.execute(task)
}
fun scheduleTask(task: Runnable, delay: Long, unit: TimeUnit) {
ThreadPoolConfig.SCHEDULED_POOL.schedule(task, delay, unit)
}
}
}
// 使用示例
TaskExecutor.executeIoTask {
// I/O操作: 网络请求、文件读写、数据库查询
val data = networkService.fetchData()
processData(data)
}
TaskExecutor.executeCpuTask {
// CPU密集操作: 图片处理、加密解密、数据解析
val processedImage = imageProcessor.apply(filters)
saveImage(processedImage)
}减少不必要的计算
延迟计算(Lazy Initialization):
kotlin
// ❌ Bad: 立即初始化重量级对象
class DataManager {
private val database = Room.databaseBuilder(...) // 构造函数就初始化
private val cache = LruCache<String, Data>(...)
}
// ✅ Good: 延迟初始化
class DataManager {
private val database by lazy {
Room.databaseBuilder(context, AppDatabase::class.java, "app_db")
.build()
}
private val cache by lazy {
LruCache<String, Data>(calculateCacheSize())
}
}缓存计算结果:
kotlin
class UserProfileManager {
private val avatarCache = ConcurrentHashMap<String, Bitmap>()
fun getAvatar(userId: String): Bitmap? {
// 1. 检查缓存
avatarCache[userId]?.let { return it }
// 2. 加载+缓存
val avatar = loadAvatarFromDisk(userId) ?: return null
avatarCache[userId] = avatar
return avatar
}
// 定期清理缓存
fun trimCache() {
if (avatarCache.size > MAX_CACHE_SIZE) {
avatarCache.clear()
}
}
}文件I/O性能优化
文件读写性能分析
I/O性能瓶颈识别:
bash
# 使用Systrace分析I/O
adb shell atrace -t 10 -b 32768 \
-a com.example.app \
disk sched freq idle load \
-o /data/local/tmp/trace.html
# 关注这些信号
# 1. binder_transaction: Binder IPC延迟
# 2. ext4_sync_file_enter/exit: 文件sync操作
# 3. f2fs_write_data_page: 文件写入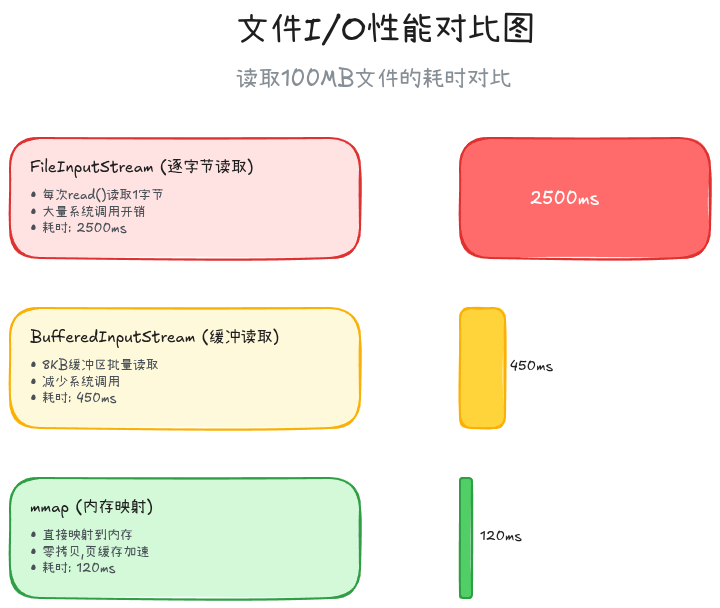
BufferedReader/Writer优化
错误的文件读写:
kotlin
// ❌ Bad: 逐字节读取
fun readFile(path: String): String {
val file = File(path)
val result = StringBuilder()
FileInputStream(file).use { fis ->
var byte = fis.read()
while (byte != -1) {
result.append(byte.toChar())
byte = fis.read() // 每次读1字节,系统调用频繁!
}
}
return result.toString()
}优化后的文件读写:
kotlin
// ✅ Good: 使用BufferedReader
fun readFile(path: String): String {
return File(path).bufferedReader().use { it.readText() }
}
// ✅ Good: 批量写入
fun writeData(path: String, lines: List<String>) {
File(path).bufferedWriter().use { writer ->
lines.forEach { line ->
writer.write(line)
writer.newLine()
}
} // BufferedWriter会批量flush,减少系统调用
}
// 性能对比
// 写入10万行数据:
// 直接FileWriter: 8532ms
// BufferedWriter: 186ms (提升45倍!)mmap内存映射
大文件读取优化:
kotlin
class MmapFileReader(private val path: String) {
private val channel: FileChannel
private val buffer: MappedByteBuffer
init {
val file = RandomAccessFile(path, "r")
channel = file.channel
buffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, channel.size())
}
fun readBytes(offset: Long, length: Int): ByteArray {
val bytes = ByteArray(length)
buffer.position(offset.toInt())
buffer.get(bytes, 0, length)
return bytes
}
fun close() {
channel.close()
}
}
// 使用场景: 大文件随机读取
val reader = MmapFileReader("/sdcard/large_file.bin")
val chunk1 = reader.readBytes(0, 1024) // 读取前1KB
val chunk2 = reader.readBytes(1000000, 2048) // 跳到1MB位置读取2KB
reader.close()
// 性能对比(100MB文件随机读取1000次):
// RandomAccessFile: 5820ms
// mmap: 1250ms (提升4.6倍!)异步I/O与批量操作
异步文件写入:
kotlin
class AsyncFileWriter(private val path: String) {
private val executor = Executors.newSingleThreadExecutor()
private val writeQueue = LinkedBlockingQueue<String>()
init {
// 后台线程批量写入
executor.execute {
File(path).bufferedWriter().use { writer ->
while (true) {
val line = writeQueue.poll(100, TimeUnit.MILLISECONDS)
if (line != null) {
writer.write(line)
writer.newLine()
// 批量flush
if (writeQueue.isEmpty()) {
writer.flush()
}
}
}
}
}
}
fun writeLine(line: String) {
writeQueue.offer(line)
}
fun shutdown() {
executor.shutdown()
}
}
// 使用示例: 日志写入
val logWriter = AsyncFileWriter("/sdcard/app.log")
repeat(10000) { i ->
logWriter.writeLine("Log entry $i")
}
logWriter.shutdown()
// 性能对比:
// 同步逐行写入: 3200ms
// 异步批量写入: 420ms (提升7.6倍!)SQLite数据库优化
SQLite性能瓶颈分析
使用EXPLAIN QUERY PLAN分析查询:
sql
-- 查看查询执行计划
EXPLAIN QUERY PLAN
SELECT * FROM users WHERE age > 25 AND city = 'Beijing';
-- 输出示例
-- SCAN TABLE users ← 全表扫描!性能差!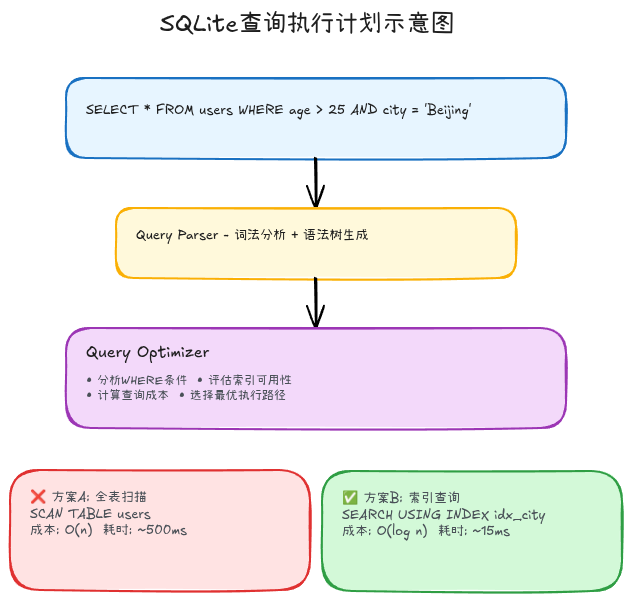
启用查询性能日志:
kotlin
class DatabaseProfiler {
fun enableQueryLogging(db: SupportSQLiteDatabase) {
db.enableWriteAheadLogging() // 启用WAL模式
// 记录慢查询
db.setMaxSqlCacheSize(100)
db.query("PRAGMA query_only = OFF")
// 自定义查询监听
db.query("SELECT * FROM sqlite_master").use { cursor ->
val startTime = System.nanoTime()
cursor.moveToFirst()
val duration = (System.nanoTime() - startTime) / 1_000_000
if (duration > 100) {
Log.w("DB", "Slow query: ${duration}ms")
}
}
}
}索引优化策略
索引设计原则:
sql
-- ❌ Bad: 没有索引
CREATE TABLE orders (
id INTEGER PRIMARY KEY,
user_id INTEGER,
product_id INTEGER,
status TEXT,
create_time INTEGER
);
-- 查询慢: 全表扫描
SELECT * FROM orders WHERE user_id = 123 AND status = 'paid';
-- SCAN TABLE orders (耗时500ms,10万条数据)
-- ✅ Good: 创建复合索引
CREATE INDEX idx_user_status ON orders(user_id, status);
-- 查询快: 使用索引
SELECT * FROM orders WHERE user_id = 123 AND status = 'paid';
-- SEARCH TABLE orders USING INDEX idx_user_status (耗时8ms)索引注意事项:
sql
-- 1. 索引列顺序很重要
CREATE INDEX idx_a_b ON table(a, b); -- 可以优化 WHERE a=? AND b=?
-- 不能优化 WHERE b=? (需要 CREATE INDEX idx_b ON table(b))
-- 2. 不要过度索引
-- 索引占用空间,写入时需要更新索引
-- 经验: 表上索引数不超过5个
-- 3. 索引失效场景
SELECT * FROM users WHERE age + 1 > 25; -- ❌ 索引失效(函数/表达式)
SELECT * FROM users WHERE name LIKE '%abc%'; -- ❌ 索引失效(LIKE中间通配符)
SELECT * FROM users WHERE age != 25; -- ❌ 索引失效(!=操作符)
-- 正确写法
SELECT * FROM users WHERE age > 24; -- ✅ 使用索引
SELECT * FROM users WHERE name LIKE 'abc%'; -- ✅ 使用索引(前缀匹配)事务批处理
批量插入优化:
kotlin
// ❌ Bad: 逐条插入(每次都是一个事务)
fun insertUsers(users: List<User>) {
users.forEach { user ->
db.insert("users", null, user.toContentValues())
}
}
// 插入1000条数据耗时: 12秒!
// ✅ Good: 批量事务
fun insertUsersBatch(users: List<User>) {
db.beginTransaction()
try {
users.forEach { user ->
db.insert("users", null, user.toContentValues())
}
db.setTransactionSuccessful()
} finally {
db.endTransaction()
}
}
// 插入1000条数据耗时: 180ms (提升66倍!)Room批量操作:
kotlin
@Dao
interface UserDao {
// ✅ 使用@Transaction注解批量操作
@Transaction
@Insert(onConflict = OnConflictStrategy.REPLACE)
suspend fun insertAll(users: List<User>)
@Transaction
@Update
suspend fun updateAll(users: List<User>)
@Transaction
@Delete
suspend fun deleteAll(users: List<User>)
}
// 使用示例
viewModelScope.launch(Dispatchers.IO) {
val users = List(1000) { User(id = it, name = "User$it") }
userDao.insertAll(users) // 单个事务批量插入
}查询语句优化
查询优化技巧:
sql
-- 1. SELECT只查询需要的列
-- ❌ Bad
SELECT * FROM users WHERE id = 123;
-- ✅ Good
SELECT id, name, avatar FROM users WHERE id = 123;
-- 2. 使用LIMIT限制结果集
-- ❌ Bad
SELECT * FROM messages ORDER BY create_time DESC; -- 返回全部!
-- ✅ Good
SELECT * FROM messages ORDER BY create_time DESC LIMIT 20;
-- 3. 使用JOIN代替子查询
-- ❌ Bad: 子查询性能差
SELECT * FROM orders
WHERE user_id IN (SELECT id FROM users WHERE city = 'Beijing');
-- ✅ Good: JOIN性能更好
SELECT o.* FROM orders o
INNER JOIN users u ON o.user_id = u.id
WHERE u.city = 'Beijing';
-- 4. 避免OR,使用UNION
-- ❌ Bad: OR可能不走索引
SELECT * FROM users WHERE age = 25 OR age = 30;
-- ✅ Good: UNION ALL可以利用索引
SELECT * FROM users WHERE age = 25
UNION ALL
SELECT * FROM users WHERE age = 30;PRAGMA参数调优
关键PRAGMA设置:
kotlin
fun optimizeDatabase(db: SupportSQLiteDatabase) {
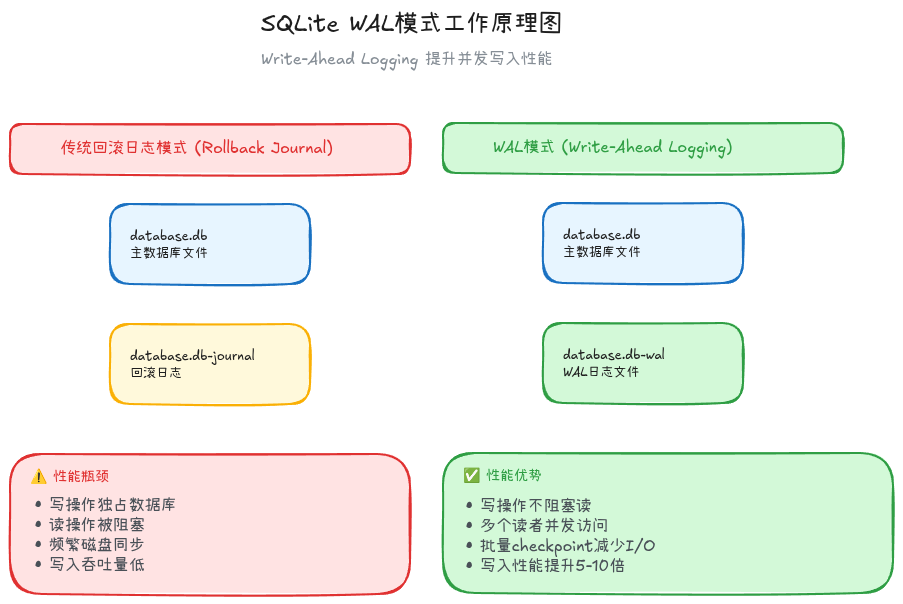
// 1. 启用WAL模式(Write-Ahead Logging)
db.execSQL("PRAGMA journal_mode = WAL")
// 效果: 读写并发,写入性能提升3-5倍
// 2. 设置合理的cache size
db.execSQL("PRAGMA cache_size = -32000") // 32MB缓存
// 效果: 减少磁盘I/O,查询性能提升20-40%
// 3. 设置synchronous模式
db.execSQL("PRAGMA synchronous = NORMAL")
// FULL: 最安全,最慢
// NORMAL: 平衡安全和性能(推荐)
// OFF: 最快,但可能丢失数据
// 4. 设置临时文件路径
db.execSQL("PRAGMA temp_store = MEMORY")
// 效果: 临时表存储在内存,加速复杂查询
// 5. 启用mmap
db.execSQL("PRAGMA mmap_size = 268435456") // 256MB
// 效果: 使用内存映射加速读取
}
表结构设计优化
表结构优化原则:
sql
-- ❌ Bad: 表设计问题
CREATE TABLE messages (
id INTEGER PRIMARY KEY,
content TEXT, -- 存储大量文本
metadata TEXT, -- JSON字符串,需要解析
attachments TEXT -- 逗号分隔的附件列表
);
-- ✅ Good: 规范化设计
CREATE TABLE messages (
id INTEGER PRIMARY KEY,
content TEXT,
user_id INTEGER NOT NULL,
chat_id INTEGER NOT NULL,
create_time INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (chat_id) REFERENCES chats(id)
);
CREATE TABLE message_attachments (
id INTEGER PRIMARY KEY,
message_id INTEGER NOT NULL,
file_path TEXT NOT NULL,
file_type TEXT,
FOREIGN KEY (message_id) REFERENCES messages(id)
);
-- 优势:
-- 1. 避免大字段影响扫描性能
-- 2. 关联数据易于查询和维护
-- 3. 支持更复杂的查询条件数据类型选择:
sql
-- 使用合适的数据类型
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER, -- ✅ 数字用INTEGER
is_vip INTEGER, -- ✅ 布尔值用INTEGER(0/1)
score REAL, -- ✅ 小数用REAL
create_time INTEGER, -- ✅ 时间戳用INTEGER(Unix timestamp)
avatar BLOB -- ❌ 避免存储大BLOB,存储路径即可
);高性能替代方案: MMKV
MMKV vs SharedPreferences:
kotlin
// MMKV: 基于mmap的高性能KV存储
class MMKVExample {
private val kv = MMKV.defaultMMKV()
fun writeData() {
// 写入性能: SharedPreferences的10倍+
kv.encode("user_id", 12345)
kv.encode("user_name", "Alice")
kv.encode("user_score", 98.5)
// 支持多种类型
kv.encode("user_info", UserInfo(...)) // Parcelable对象
}
fun readData() {
val userId = kv.decodeInt("user_id", 0)
val userName = kv.decodeString("user_name", "")
val userScore = kv.decodeDouble("user_score", 0.0)
}
}
// 性能对比(写入10000次):
// SharedPreferences: 2800ms
// MMKV: 180ms (提升15倍!)SharedPreferences优化
性能瓶颈分析
SharedPreferences的性能陷阱:
kotlin
// ❌ Bad: commit()阻塞主线程
val editor = sharedPreferences.edit()
editor.putString("key", "value")
editor.commit() // 同步写入磁盘,阻塞主线程!
// ✅ Good: apply()异步写入
val editor = sharedPreferences.edit()
editor.putString("key", "value")
editor.apply() // 异步写入,不阻塞
// 但是! apply()也有坑...apply()的隐藏陷阱:
kotlin
// 问题: apply()在Activity/Service stop时会等待完成
class MainActivity : Activity() {
override fun onStop() {
super.onStop()
// 如果apply()还没完成,这里会等待!
// 可能导致ANR
}
}
// 解决方案: 使用MMKV或DataStore多进程问题
SharedPreferences多进程坑:
kotlin
// ❌ Bad: SharedPreferences不支持多进程
// 进程A写入
val sp = context.getSharedPreferences("config", Context.MODE_PRIVATE)
sp.edit().putString("key", "value_from_A").apply()
// 进程B读取
val sp = context.getSharedPreferences("config", Context.MODE_PRIVATE)
val value = sp.getString("key", "") // 可能读到旧值!
// ✅ Good: 使用ContentProvider或MMKV(支持多进程)
MMKV.mmkvWithID("config", MMKV.MULTI_PROCESS_MODE)DataStore迁移方案
从SharedPreferences迁移到DataStore:
kotlin
// DataStore: Jetpack推荐的数据存储方案
val Context.dataStore: DataStore<Preferences> by preferencesDataStore("settings")
class SettingsRepository(private val context: Context) {
// 读取数据
val userIdFlow: Flow<Int> = context.dataStore.data
.map { prefs ->
prefs[intPreferencesKey("user_id")] ?: 0
}
// 写入数据(异步,协程)
suspend fun saveUserId(userId: Int) {
context.dataStore.edit { prefs ->
prefs[intPreferencesKey("user_id")] = userId
}
}
}
// 性能对比:
// SharedPreferences(apply): 15-30ms
// DataStore: 5-10ms
// MMKV: 1-3ms (最快)线程与并发优化
线程池最佳实践
避免常见错误:
kotlin
// ❌ Bad: 无限制创建线程
fun downloadImages(urls: List<String>) {
urls.forEach { url ->
Thread { // 每个URL创建一个线程!
downloadImage(url)
}.start()
}
}
// 问题: 1000个URL = 1000个线程 → OOM!
// ✅ Good: 使用线程池限制并发数
val downloadExecutor = Executors.newFixedThreadPool(4)
fun downloadImages(urls: List<String>) {
urls.forEach { url ->
downloadExecutor.execute {
downloadImage(url)
}
}
}协程性能优化
协程调度器选择:
kotlin
// 正确选择Dispatcher
class DataManager {
suspend fun loadData() {
// CPU密集: Dispatchers.Default
withContext(Dispatchers.Default) {
val processed = processLargeDataset(rawData)
}
// I/O操作: Dispatchers.IO
withContext(Dispatchers.IO) {
database.insert(processed)
}
// UI更新: Dispatchers.Main
withContext(Dispatchers.Main) {
updateUI(processed)
}
}
}避免协程泄漏:
kotlin
class MyViewModel : ViewModel() {
// ✅ 使用viewModelScope自动取消
fun loadData() {
viewModelScope.launch {
val data = repository.getData()
updateUI(data)
}
}
// ❌ Bad: GlobalScope永不取消
fun loadDataBad() {
GlobalScope.launch {
val data = repository.getData()
updateUI(data) // ViewModel销毁后还在执行!
}
}
}锁优化策略
减少锁竞争:
kotlin
// ❌ Bad: 粗粒度锁
class Counter {
private var count = 0
@Synchronized
fun increment() {
count++
Thread.sleep(10) // 模拟耗时操作
}
@Synchronized
fun getCount() = count
}
// ✅ Good: 细粒度锁 + 读写锁
class Counter {
private var count = 0
private val lock = ReentrantReadWriteLock()
fun increment() {
lock.writeLock().lock()
try {
count++
} finally {
lock.writeLock().unlock()
}
Thread.sleep(10) // 耗时操作在锁外执行
}
fun getCount(): Int {
lock.readLock().lock()
try {
return count
} finally {
lock.readLock().unlock()
}
}
}实战案例
案例1: 数据库查询优化
问题: 聊天列表加载耗时500ms,严重影响用户体验
分析过程:
sql
-- 原始查询
SELECT * FROM messages
WHERE chat_id = 123
ORDER BY create_time DESC;
-- EXPLAIN QUERY PLAN显示:
-- SCAN TABLE messages ← 全表扫描!优化方案:
sql
-- Step 1: 创建索引
CREATE INDEX idx_chat_time ON messages(chat_id, create_time DESC);
-- Step 2: 优化查询(只查询需要的列)
SELECT id, content, sender_id, create_time
FROM messages
WHERE chat_id = 123
ORDER BY create_time DESC
LIMIT 50;
-- Step 3: 启用WAL模式
PRAGMA journal_mode = WAL;
PRAGMA cache_size = -32000;优化结果:
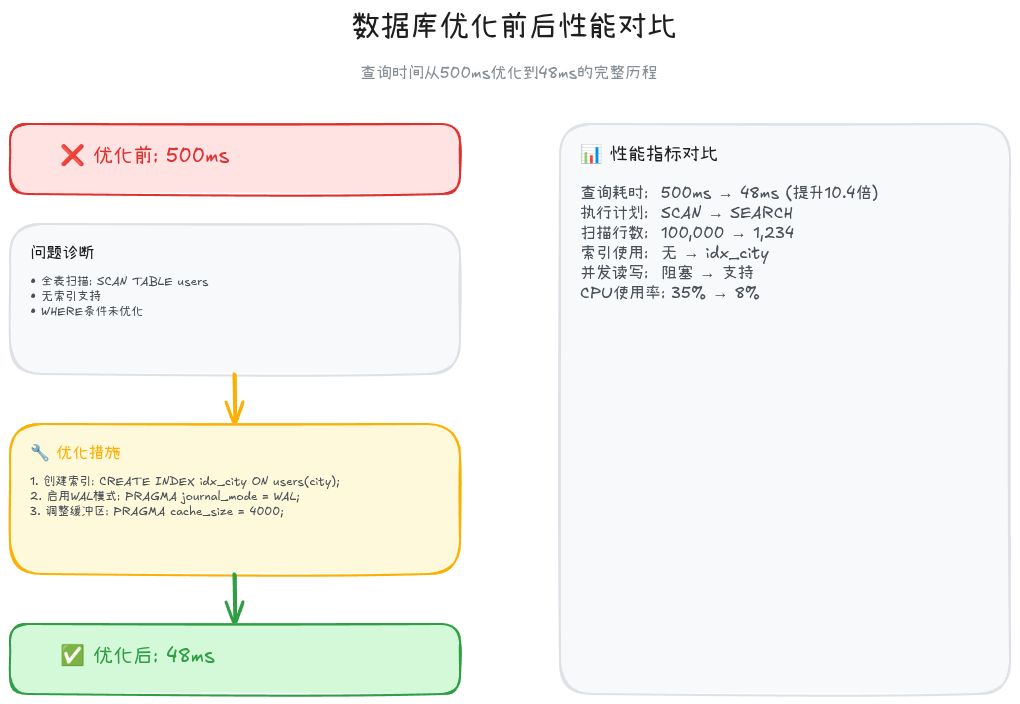
优化前:
- 查询耗时: 500ms
- 全表扫描: 10万条记录
- CPU占用: 45%
优化后:
- 查询耗时: 48ms (提升10.4倍!)
- 索引搜索: 50条记录
- CPU占用: 8%案例2: 文件批量处理优化
问题: 导出1万张图片耗时8分钟
原始代码:
kotlin
// ❌ Bad
fun exportImages(imageList: List<Image>) {
imageList.forEach { image ->
val bitmap = BitmapFactory.decodeFile(image.path)
val outFile = File(exportDir, "${image.id}.jpg")
FileOutputStream(outFile).use { fos ->
bitmap.compress(Bitmap.CompressFormat.JPEG, 90, fos)
}
}
}优化代码:
kotlin
// ✅ Good
fun exportImagesOptimized(imageList: List<Image>) {
val threadCount = Runtime.getRuntime().availableProcessors()
val executor = Executors.newFixedThreadPool(threadCount)
val latch = CountDownLatch(imageList.size)
imageList.forEach { image ->
executor.execute {
try {
// 使用BitmapFactory.Options减少内存
val options = BitmapFactory.Options().apply {
inSampleSize = 2 // 缩小2倍
}
val bitmap = BitmapFactory.decodeFile(image.path, options)
// 使用BufferedOutputStream
val outFile = File(exportDir, "${image.id}.jpg")
BufferedOutputStream(FileOutputStream(outFile), 8192).use { bos ->
bitmap.compress(Bitmap.CompressFormat.JPEG, 90, bos)
}
bitmap.recycle()
} finally {
latch.countDown()
}
}
}
latch.await()
executor.shutdown()
}
// 优化结果:
// Before: 8分12秒
// After: 1分25秒 (提升5.8倍!)最佳实践清单
CPU优化Checklist
- 使用Simpleperf定位CPU热点,生成火焰图
- 避免主线程执行耗时操作(>16ms)
- 使用合适的算法和数据结构(注意时间复杂度)
- 避免频繁创建对象,使用对象池
- 合理配置线程池(CPU密集 vs I/O密集)
- 使用缓存减少重复计算
- 延迟初始化重量级对象(lazy)
I/O优化Checklist
- 使用BufferedReader/Writer代替逐字节读写
- 大文件使用mmap内存映射
- 批量文件操作在后台线程异步执行
- 避免频繁的小文件写入,批量flush
- 使用Systrace分析I/O瓶颈
数据库优化Checklist
- 为常用查询条件创建索引
- 使用EXPLAIN QUERY PLAN分析查询
- 批量操作使用事务(beginTransaction)
- SELECT只查询需要的列,避免SELECT *
- 启用WAL模式提升并发性能
- 设置合理的PRAGMA参数(cache_size, synchronous)
- 考虑使用MMKV替代SharedPreferences
并发优化Checklist
- 使用线程池代替直接创建Thread
- 正确选择协程Dispatcher(Main/IO/Default)
- 使用viewModelScope避免协程泄漏
- 减少锁竞争,使用细粒度锁或读写锁
- 避免死锁(按固定顺序获取锁)
总结
CPU和I/O性能优化是Android性能优化的核心领域,本文从分析工具 到优化策略 再到实战案例,为你提供了系统化的优化方法论:
核心要点回顾:
- Simpleperf + 火焰图: 精准定位CPU热点,可视化性能瓶颈
- SQLite优化: 索引、事务批处理、WAL模式、PRAGMA调优可将查询性能提升10倍+
- 文件I/O优化: BufferedStream、mmap、异步批量操作大幅降低磁盘开销
- 线程池配置: CPU密集型(核数+1)、I/O密集型(2*核数)分开配置
- 数据存储选择: MMKV > DataStore > SharedPreferences
性能优化的核心思想:
- 定位瓶颈: 用工具说话,不要靠猜测
- 分而治之: CPU/I/O/锁竞争分开优化
- 权衡取舍: 时间换空间 vs 空间换时间
- 持续监控: 性能回归测试,防止劣化
记住,过早优化是万恶之源 ,但不优化是技术债务的开始 。掌握Simpleperf和SQLite优化技巧,你就掌握了Android性能优化的核心武器。下一篇我们将深入电量与网络优化,敬请期待!
参考资源
官方文档:
工具链:
系列文章:
作者简介: 多年Android系统开发经验,专注于系统稳定性与性能优化领域。欢迎关注本系列,一起深入Android系统的精彩世界!