一条SQL查询语句是如何执行的?
在思考这个问题之前,先了解 MySQL 的整体架构,MySQL可以分为 Server 层和存储引擎层。
1. Server 层
这是 MySQL 的核心层,涵盖了连接器、查询缓存、分析器、优化器和执行器等关键组件。所有的内置函数(如日期、时间、数学及加密函数)以及跨存储引擎的功能(如存储过程、触发器、视图)均在此层统一实现。
通俗理解: 如果把 MySQL 看作一家物流公司 ,Server 层就是管理调度中心 。它负责接待客户(连接器)、理解客户需求(分析器)、规划最优运输路线(优化器),并指挥底下的工人(执行器)去干活。它只管"做什么(What)",而不关心货物具体存放在哪个架子上。
2. 存储引擎层
专注于数据的物理存储与提取。该层采用插件式架构 (Pluggable Storage Engine Architecture) ,支持 InnoDB、MyISAM、Memory 等多种引擎,允许根据业务需求灵活切换。值得注意的是,InnoDB 凭借其优异的事务处理能力(ACID)和行级锁机制,自 MySQL 5.5.5 版本起已被确立为默认存储引擎。
通俗理解: 这一层相当于物流公司的仓库和搬运工 。它负责"怎么做(How)"------即真正地把货物(数据)存进货架或取出来。
- 所谓的"插件式":意味着你可以根据需求更换"仓库管理模式"。比如,有的仓库注重极致速度但不保证货物百分百安全(Memory 引擎),有的仓库则拥有最严密的安保和防丢失机制(InnoDB 引擎)。
- Server 层与存储引擎层的交互 :Server 层通过一套标准的 API 接口 与存储引擎通信。因此,Server 层根本不需要知道底层是 InnoDB 还是 MyISAM,就像调度中心只要下达"取货"指令,不需要知道搬运工是用叉车还是传送带一样。
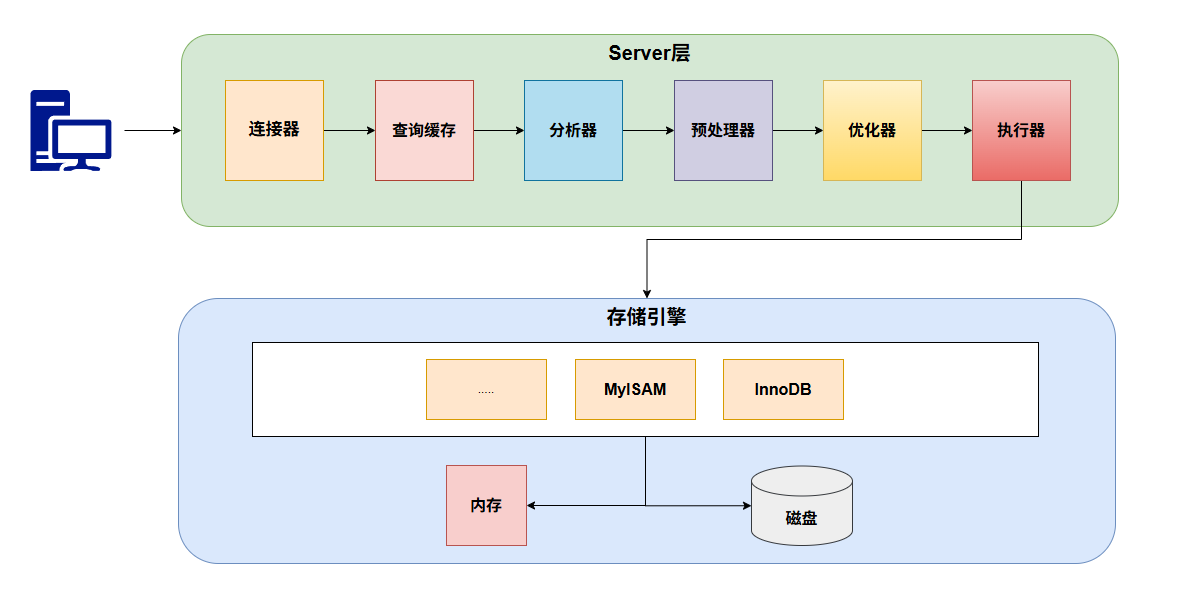
从图中可以看到,不同的存储引擎可以使用同一个 Server 层,大概了解这个框架,下面看每个组件的作用。
注意:MySQL 8.0版本直接将查询缓存的整块功能删掉了,也就是说8.0开始彻底没有这个功能了。
连接器
当客户端向 MySQL 发起请求时,第一步必须先建立与服务端的连接。连接器作为 MySQL Server 层的入口组件,主要负责连接建立、身份认证、权限获取以及连接维持与管理。
客户端通常通过 TCP 协议与服务端建立连接。以标准的 MySQL 客户端工具为例,连接命令如下:
sql
mysql -h$ip -P$port -u$user -p在执行完上述命令后,就需要输入密码。在生产环境中,强烈建议不要将密码直接显式地写在 -p 参数之后,以避免密码在命令行历史或进程列表中泄露。
连接建立的过程包含以下关键步骤:
- TCP 握手 :客户端与服务器首先完成
TCP三次握手。 - 身份认证 :
- 如果用户名或密码错误,服务端返回
Access denied for user错误,连接终止。 - 如果认证通过,连接器会查询权限表(
mysql.user 等),读取该用户的当前权限数据。
- 如果用户名或密码错误,服务端返回
- 权限快照 :
- 关键机制:用户在连接建立成功的瞬间,其权限即被锁定。这意味着,连接建立后对该用户权限的任何修改,不会影响已经存在的连接。只有新建的连接才会应用修改后的权限。
连接完成后,如果没有后续请求,连接将进入空闲状态。此时通过SHOW PROCESSLIST命令查看,该连接的Command列会显示为 "Sleep"。
- 超时断开 :MySQL 不会让空闲连接无限期存在。该行为由参数
wait_timeout控制,默认值为 8 小时(28800秒)。如果空闲时间超过该阈值,连接器会自动断开连接。 - 断连后果 :连接断开后,若客户端再次发送请求,会收到
Lost connection to MySQL server during query错误。此时客户端必须执行重连操作。
在实际应用开发中,对于连接的管理主要分为两种策略:
- 长连接:连接建立后,客户端持续通过该连接发送请求,直到客户端主动关闭或被服务端超时断开。
- 短连接:每次执行少量查询后即断开连接,下次查询时重新建立。
最佳实践与性能挑战: 由于建立连接的过程涉及 TCP 握手、身份认证及权限初始化,开销较大,因此在高性能场景下,建议优先使用长连接以减少 I/O 和 CPU 的无谓消耗。
长连接的内存风险(OOM) : 全面使用长连接可能导致 MySQL 内存占用飙升,甚至因 OOM(Out Of Memory)被系统 Kill。 原因 :MySQL 在执行查询过程中使用的临时内存是管理在连接对象中的。这些资源在连接存在期间通常不会释放,只有在连接断开时才会回收。
为了解决长连接导致的内存溢出风险,通常采用以下两种策略:
- 定期重连: 在应用层控制连接生命周期。例如,使用一段时间后,或在执行过占用大量内存的查询后,主动断开连接并重建。
- 连接重置(推荐 MySQL 5.7+) : 利用 mysql_reset_connection 接口。在执行完大操作后,调用此接口可将连接恢复到初始状态(释放累积的内存资源),而无需重新进行 TCP 握手和权限验证,从而在性能与资源之间取得平衡。
查询缓存
注 :该功能在 MySQL 8.0 版本中已被彻底移除 。在 MySQL 5.7 及之前版本中,通常也不建议开启。此处仅作原理性介绍,以帮助理解 MySQL 的历史演进。
当连接建立完成后,MySQL 会首先尝试检查查询缓存。 其工作机制基于内存中的 Key-Value 存储:
- Key:原始的 SQL 查询语句。
- Value:该语句对应的查询结果集。
如果当前查询语句在缓存中直接命中(Key 匹配),MySQL 将跳过后续的分析、优化和执行阶段,直接将 Value 返回给客户端,能够显著提升响应速度。若未命中,则继续执行后续流程,并将最终结果存入缓存。
为什么它弊大于利?
查询缓存的设计存在一个严重的失效机制缺陷 :只要对一个表进行任何数据更新(INSERT, UPDATE, DELETE),该表上所有关联的查询缓存都会被强制清空。
在写多读少或读写混合的常规业务场景中,这种机制会导致缓存频繁失效,形成"刚缓存--->即失效"的恶性循环,不仅无法提升性能,反而因为维护缓存带来了额外的系统开销。只有在极少数完全静态(如系统配置表)的场景下,通过将 query_cache_type 设置为 DEMAND 并配合 SQL_CACHE 显式指定,才具有一定价值。
鉴于上述局限性以及对数据库并发性能的掣肘,MySQL 8.0 版本已从代码层面移除了查询缓存模块。现代应用通常建议在应用层(如 Redis)或依赖 InnoDB 的 Buffer Pool 来处理缓存需求。
分析器
如果没有命中查询缓存,MySQL 就进入了真正的执行阶段。首先,服务器必须"读懂"你的请求。由于你发送给数据库的只是一串由字符、空格和符号组成的文本(String),MySQL 需要通过分析器将其转换为内部能识别的数据结构。
这个过程主要分为两个阶段:
第一步:词法分析
这是编译过程的第一步。MySQL 会扫描你输入的 SQL 语句字符串,将其拆解为一个个最小的语言单元(Token)。
- 识别关键词 :例如,它会识别出
select是一个查询关键字,from 是来源关键字。 - 识别标识符 :它会将字符串
t_user识别为"表名",将id识别为"列名"。
第二步:语法分析
在提取出 Token 之后,分析器会根据 MySQL 定义的语法规则,检查这些 Token 的组合是否合法,并生成解析树。
- 合规性检查 :比如,它会检查
select 后面是否跟着字段名,from 后面是否跟着表名。 - 错误处理:如果你的语句不符合语法规则(例如关键字拼写错误、标点符号遗漏),MySQL 会直接拦截并报错,不会进入后续步骤。
预处理器
经过分析器处理后,MySQL 得到了一棵语法正确的解析树,但这并不代表语句能被正确执行。预处理器随即介入,重点进行语义分析 ,解决"语句对不对"的问题:
- 对象校验 :它会核实 SQL 语句中提到的表和列在数据库中是否真实存在 。如果你把表名写错了,经典的
Table 'xxx' doesn't exist错误就是在这一步抛出的。 - 权限与歧义检查 :确认用户是否有权操作这些表,并检查多表关联时字段引用是否明确(例如避免
Column 'name' is ambiguous)。 - 展开通配符 :它会将
SELECT *这种模糊指令,依据数据字典扩展为具体的列名列表,为后续优化器计算成本提供精确依据。
优化器
经过分析器和预处理器的处理,MySQL 已经知道了你"想要做什么"。但在真正开始执行之前,它还需要解决"该怎么做" 的问题------这就是优化器的职责。
优化器的核心目的是找到执行效率最高的方案。面对复杂的 SQL 语句,往往存在多种执行路径,优化器需要权衡各种方案,生成一个最终的执行计划。
决策场景:以 Join 为例
最典型的例子就是多表关联查询。假设执行如下语句:
sql
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;针对这条 SQL,优化器至少有两种执行策略:
- 方案 A :先从表
t1 里面取出c=10 的记录,通过ID关联到表 t2,再判断t2 里面 d 的值是否等于 20。 - 方案 B :先从表
t2 里面取出 d=20 的记录,通过ID关联到表 t1,再判断t1里面c 的值是否等于 10。
这两种执行路径的逻辑结果完全一致,但根据 t1 和 t2 的数据量级、索引分布不同,执行效率可能天差地别。优化器的作用就是判断哪种方案更快。
核心指标:什么是"成本"?
MySQL 优化器是基于成本的优化器 (Cost-Based Optimizer, CBO)。在面试中,如果面试官问"优化器依据什么选择索引?",标准答案就是"成本"。
那么,这里的成本具体指什么?主要由以下两部分构成:
- I/O 成本:将数据从磁盘加载到内存的开销。MySQL 以"页"为单位读取数据,读取的页数越多,I/O 成本越高。
- CPU 成本:数据加载到内存后,CPU 对其进行检测(如验证是否满足 where 条件)、排序、分组等操作的开销。需要扫描和比对的行数越多,CPU 成本越高。
优化器会根据扫描行数、索引基数等统计信息,估算每个方案的 I/O 和 CPU 成本总和,最终选择总成本最低的那个方案。
执行器
通过分析器知道了"做什么",通过优化器知道了"该怎么做",现在 MySQL 终于进入了实操阶段------执行器。
执行器主要负责权限校验、调用存储引擎接口以及返回结果。
权限二次校验
虽然连接器在建立连接时已经获取了用户权限,但在真正读取数据表之前,执行器会进行更细致的表级或列级权限校验。
无权限: 如果校验失败,执行器会立即终止操作并报错:
sql
mysql> select * from t_user where id=10;
ERROR 1142 (42000): SELECT command denied to user 'q'@'localhost' for table 't_user'有权限: 校验通过后,执行器会根据该表的定义(frm 文件),打开表并开始调用对应的存储引擎接口。
执行流程(Server 层与引擎层的交互)
执行器并不关心数据具体是如何存储在 B+ 树上的,它只是通过标准的 Handler API 接口与存储引擎对话。
以一个没有索引的表 T 为例,执行语句 select * from t_user where id=10,其执行流程如下:
- 调用接口取第一行:执行器调用 InnoDB 引擎的"取全表第一行"接口。
- Server 层过滤 :InnoDB 把第一行数据返回给执行器。执行器拿到数据后,在 Server 层判断这行数据的
id 是否等于 10。- 如果不符合,跳过。
- 如果符合,将这行记录放入结果集缓存。
- 循环调用:执行器继续调用引擎的"取下一行"接口。重复上述判断逻辑,直到引擎返回"数据读完了"(EOF)。
- 返回结果:执行器将遍历过程中所有满足条件的行组成的结果集,统一返回给客户端。
对于有索引的表: 逻辑几乎一致,区别在于调用接口不同。执行器会调用"取满足条件的第一行"接口(定位索引根节点),然后循环调用"取满足条件的下一行"接口(利用 B+ 树的有序性),直到条件不满足为止。
关键指标:rows_examined
在数据库的慢查询日志(Slow Query Log)中,有一个关键字段 rows_examined,它表示语句执行过程中扫描了多少行。
这个值正是执行器每次调用引擎获取数据行时累加的。
注意:Server 层扫描行数 ≠ 引擎层扫描行数 在某些高级优化场景下(如索引下推 Index Condition Pushdown),引擎内部可能会过滤掉不符合条件的行,而不返回给执行器。因此,你可能会发现rows_examined的值有时会小于引擎实际扫描过的行数。
总结
至此,我们已经完整剖析了 MySQL 执行一条查询语句的全过程。我们可以将这个过程浓缩为以下关键步骤:
- 连接器:建立连接,确认身份,读取权限。
- 查询缓存(8.0 已删):如果有缓存且命中,直接返回;否则继续。
- 分析器 :词法分析与语法分析,确保语句"符合规则"。
- 预处理器 :语义分析,展开 * 号,检查表列是否存在,确保语句"符合事实"。
- 优化器 :计算成本(I/O 和 CPU),选择索引,确定 Join 顺序,解决"怎么做"的问题。
- 执行器 :校验权限,循环调用存储引擎接口,解决"去执行"的问题。
- 存储引擎:作为底层"苦力",负责具体数据的读取(InnoDB/MyISAM)。
技术在交流中精进。关于 MySQL 的查询执行流程,如果你有不同的见解或疑问,欢迎在评论区留言探讨。觉得有用的话,别忘了反手一个赞!