作者:Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun
机构:Microsoft Research
来源期刊: IEEE Conference on Computer Vision and Pattern Recognition(CVPR)
发表时间:2016年
一、研究目标、方法与创新点
1. 研究目标
本文重在解决深度神经网络中的"退化问题"(degradation problem):随着网络深度增加,训练误差和测试误差不降反升,这并非过拟合导致,而是由于优化困难。作者提出一种深度残差学习框架,使网络能够轻松训练极深模型(如152层),并在多个视觉任务上取得突破性性能。
2. 过去方法及其局限
传统深度网络(如VGG、GoogLeNet)通过堆叠卷积层提升性能,但超过一定深度后会出现梯度消失或者爆炸问题。
虽然批量归一化(Batch Normalization) 和合理的初始化缓解了梯度问题,但深度增加仍会导致训练误差上升,也就是文章提到的"退化现象"。
此前也有使用**快捷连接(shortcut connections)**的方法(如Highway Networks),但依赖带参数的门控机制,并未在极深网络中表现出明显优势。
3. 本文方法
提出残差学习框架,将堆叠的层拟合为残差函数:
F(x)=H(x)−x
则原始映射变为:
H(x)=F(x)+x
通过恒等快捷连接将输入直接加到输出上,使网络更容易学习微小扰动,而非完整的映射
快捷链接的优势:
1.拟合小的残差网络可以更好的优化权重。
2.可以在一定程度上避免梯度消失问题。
3.提升训练的稳定性。
4. 优势与创新点
1.解决退化问题:即使网络很深,也能通过残差块轻松训练。
2.无额外参数:恒等快捷连接不增加参数或计算量。
3.极深网络可行:成功训练152层网络,在ImageNet上取得当时最佳性能。
4.通用性强:在分类、检测、分割等多个任务上均取得显著提升。
5.提出瓶颈结构:使用1×1卷积降低维度,减少计算量,使千层网络训练成为可能。
二、算法主要思想与原理
1. 残差学习基本思想
假设我们希望网络学习一个映射 H(x)H(x),直接学习可能困难。我们改为学习残差:
F(x) = H(x)−x
则原始映射可表示为:
H(x) = F(x)+x
如果恒等映射是最优的,那么将残差推向零比直接拟合恒等映射更容易。
2. 残差块结构
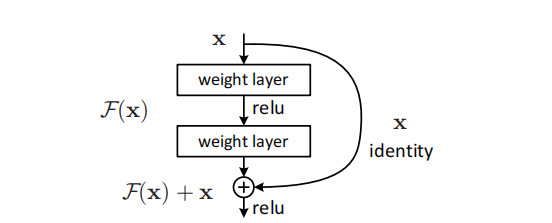 提出的残差块
提出的残差块
-
若输入输出维度相同,直接使用恒等连接。
-
若维度不同,使用1×1卷积进行投影。
3.文中专业术语
-
退化问题:网络加深后训练误差上升的现象。
-
恒等快捷连接:将输入直接传递到输出,不经过任何变换。
-
瓶颈结构:使用1×3×1卷积组合,先降维再升维,减少计算量。
-
批量归一化:对每层输入进行归一化,加速训练并缓解梯度问题。
三、实验结果
1. 数据集
ImageNet 2012:128万训练图像,5万验证图像,1000类。
CIFAR-10:5万训练图像,1万测试图像,10类。
PASCAL VOC & MS COCO:用于目标检测与分割任务。
2. 评价指标
分类任务:Top-1错误率、Top-5错误率。
Top-1 Error Rate:模型预测的第一位类别与真实标签不匹配的比例。换句话说,如果模型的第一个预测类别就是正确的类别,那么它就是正确预测;否则,它就是错误的。
Top-5 Error Rate:模型预测的前五个类别中没有正确类别的比例。也就是说,如果模型的前五个预测类别中有一个类别与真实标签匹配,那么该预测就被认为是正确的。如果前五个类别中都没有正确类别,那么就是错误的。
检测任务:mAP(mean Average Precision)。
COCO任务:mAP@0.5:0.95。
3. 定量实验
ImageNet分类结果
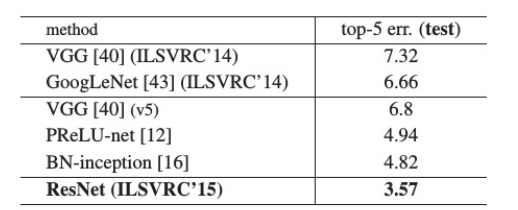
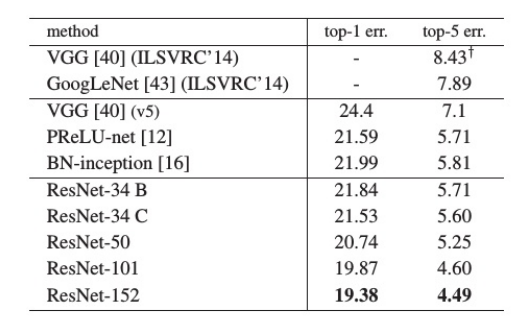
-
ResNet-152 取得 19.38% Top-1错误率,优于所有先前模型。
-
集成模型在测试集上达到 3.57% Top-5错误率,获ILSVRC 2015分类任务冠军。
CIFAR-10实验
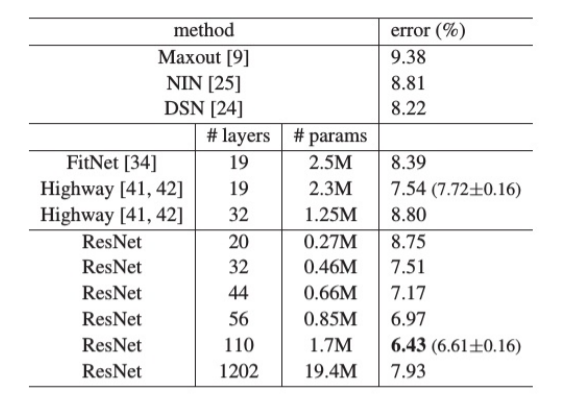
-
ResNet-110 取得 6.43% 错误率,优于同类深层模型。
-
训练1202层网络仍能收敛,证明优化无障碍。
目标检测结果
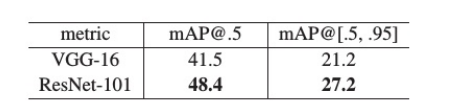
- 在COCO数据集上,ResNet-101比VGG-16提升 28% 相对性能。
4. 定性分析
-
训练曲线对比:深层残差网络训练误差始终低于普通网络。
-
响应分析:残差网络各层响应标准差较小,说明其学习的是小扰动。
-
深度效应:残差网络随深度增加性能持续提升,普通网络则出现退化。
四、结论
本文提出的深度残差学习框架成功解决了极深神经网络的训练难题,通过引入恒等快捷连接和残差映射,使网络能够轻松训练上百甚至上千层。该方法不仅显著提升了ImageNet分类性能,也在检测、分割等多个视觉任务上取得突破,成为后续深度网络设计的基础架构之一。残差学习的核心思想------学习残差而非完整映射------已被广泛证明是一种高效且通用的深度学习策略。