本期内容为自己总结归档,7天学会Redis。其中本人遇到过的面试问题会重点标记。
(若有任何疑问,可在评论区告诉我,看到就回复)
Day 3 - 持久化机制深度解析
3.1 RDB持久化机制
3.1.1 RDB概述:内存快照的哲学
RDB(Redis Database)是Redis默认的持久化方式,它通过创建内存数据的快照来实现持久化。RDB文件是一个紧凑的二进制文件,记录了某个时间点上的完整数据状态。
核心思想:在特定时间点,将内存中的所有数据以二进制格式保存到磁盘上。
3.1.2 ⭐fork写时复制原理
为什么需要fork?
Redis是单线程 处理命令的,如果在主线程中直接进行磁盘I/O操作,会导致服务阻塞。为了解决这个问题,Redis使用fork创建子进程来执行RDB持久化。
写时复制(Copy-On-Write)详解
COW核心思想:只有在真正需要修改数据时,才复制内存页。
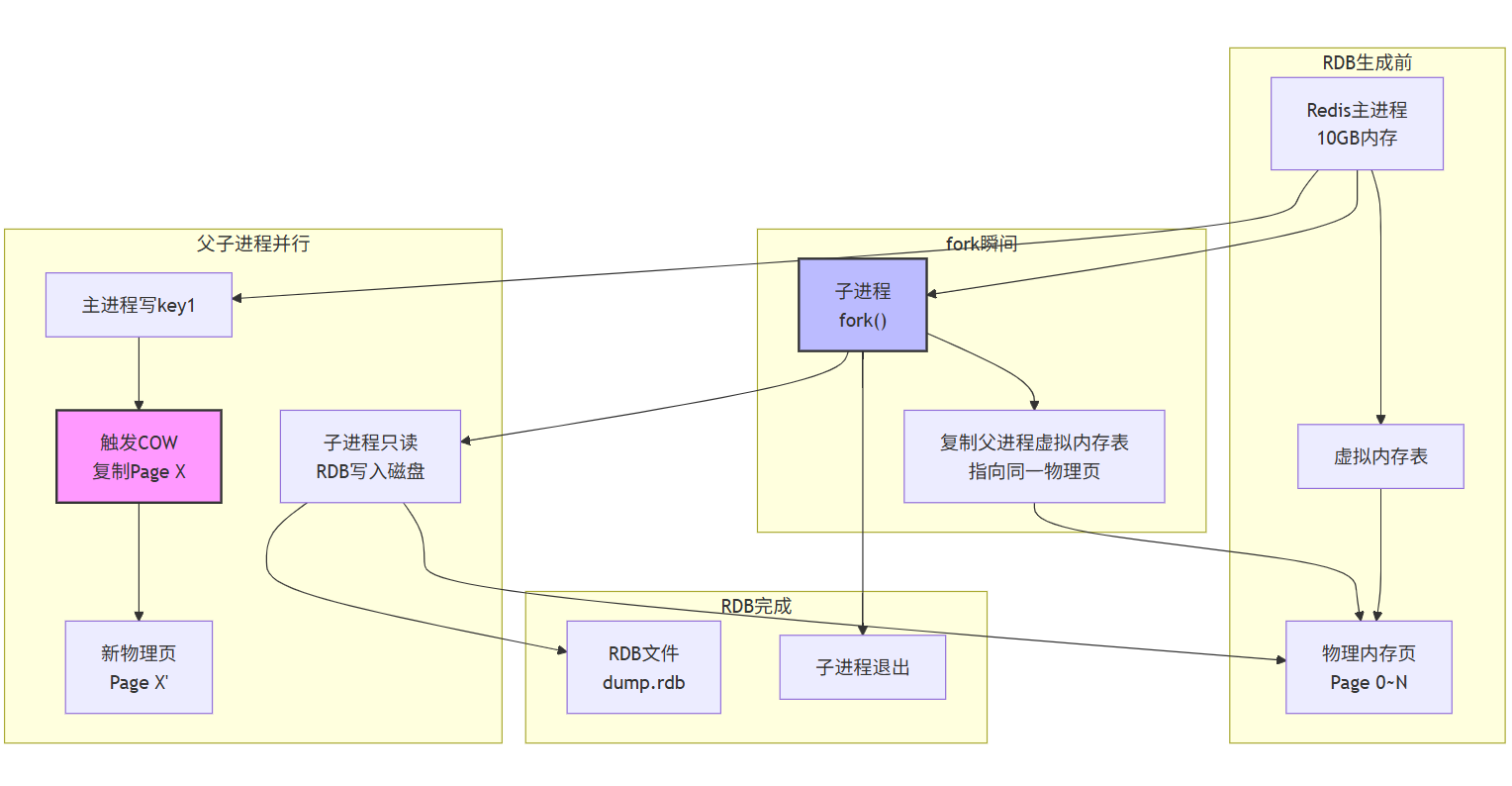
COW的优势与风险
优势:
-
快速创建子进程:只需复制页表,不复制实际内存数据
-
内存高效:只有在数据修改时才复制内存页
-
父进程无阻塞:主进程继续提供服务
风险:
-
内存翻倍风险:如果主进程大量写入,可能复制大量内存页
-
性能抖动:内存紧张时,复制大内存页可能引起性能下降
-
磁盘空间风险:RDB文件可能很大,需要足够磁盘空间
-
RDB期间:主线程每修改一个Key,对应内存页(4KB)被复制
-
若修改1000个Key,最糟糕情况触发1000次COW,额外内存=1000×4KB=4MB
-
但若修改同一页的多个Key,仅触发1次COW
-
3.1.3 快照触发的多维度考量
自动触发条件
Redis配置示例:
bash
# redis.conf中的RDB配置
save 900 1 # 900秒内至少有1个key变化
save 300 10 # 300秒内至少有10个key变化
save 60 10000 # 60秒内至少有10000个key变化
stop-writes-on-bgsave-error yes # 保存出错时停止写入
rdbcompression yes # 压缩RDB文件
rdbchecksum yes # 校验和
dbfilename dump.rdb # 文件名
dir ./ # 保存目录触发逻辑:
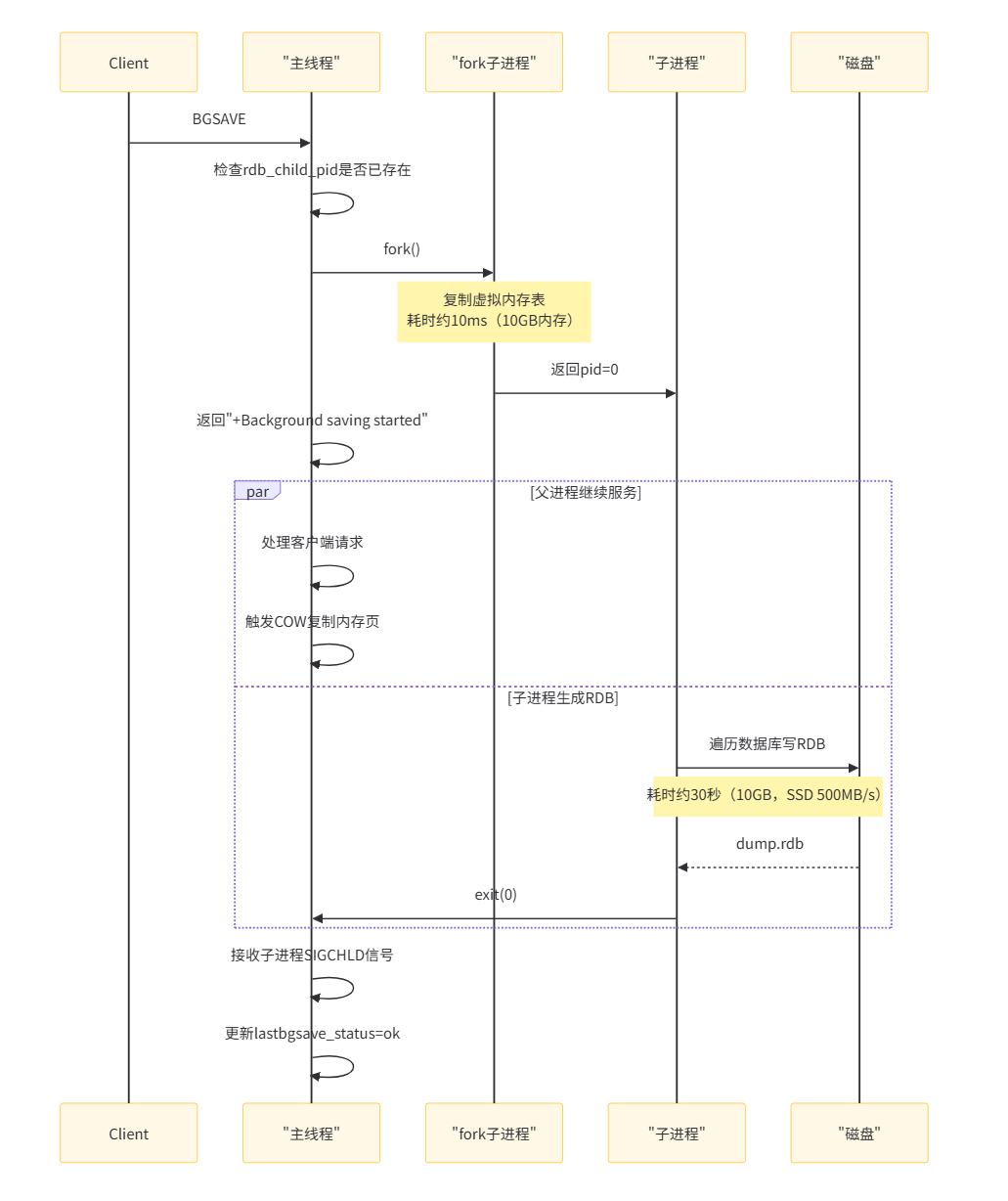
手动触发命令
bash
bash
# 1. 同步保存(阻塞所有客户端)
SAVE # 直接在主线程执行,会阻塞服务
# 2. 异步保存(后台执行)
BGSAVE # fork子进程执行,不阻塞服务
# 3. 查看保存状态
LASTSAVE # 返回上次成功保存的时间戳
INFO persistence # 查看持久化相关信息触发策略的选择依据
| 场景 | 推荐策略 | 理由 |
|---|---|---|
| 数据变更频繁 | 提高save频率(如save 60 1000) | 减少数据丢失风险 |
| 数据量大 | 降低save频率,增大变化阈值 | 避免频繁fork开销 |
| 内存紧张 | 谨慎设置,避免内存翻倍 | 防止OOM |
| 对数据安全性要求高 | 结合AOF使用混合持久化 | 提供更好的数据安全 |
3.1.4 RDB文件格式解析
RDB文件是紧凑的二进制格式,无文本解析开销,支持快速加载。
RDB文件结构
bash
+---------------------+
| REDIS (魔数) | # 9字节,"REDIS" + 版本号
+---------------------+
| RDB版本号 | # 4字节,如"0006"
+---------------------+
| 辅助字段 | # 可选,如redis-ver、redis-bits等
+---------------------+
| 数据库数据 |
| +---------------+ |
| | SELECTDB | | # 选择数据库
| +---------------+ |
| | key-value对 | | # 实际数据
| +---------------+ |
+---------------------+
| 结束符 | # 1字节,0xFF
+---------------------+
| 校验和 | # 8字节CRC64校验
+---------------------+
RDB的优缺点分析
优点:
-
紧凑的二进制格式:文件小,节省磁盘空间
-
快速恢复:直接加载到内存,恢复速度快
-
适合备份:单个文件便于备份和传输
-
最大化性能:fork子进程执行,主进程无阻塞
缺点:
-
可能丢失数据:两次保存之间的数据会丢失
-
fork可能阻塞:数据量大时,fork可能消耗较多时间和内存
-
版本兼容性:不同版本Redis的RDB格式可能不兼容
3.2 AOF持久化机制
3.2.1 AOF概述:命令追加的日志
AOF(Append Only File)通过记录所有写命令来持久化数据。每次执行写命令后,Redis会将命令以协议格式追加到AOF缓冲区,然后根据策略写入磁盘。
核心思想:记录数据的变化过程,而不是最终状态。
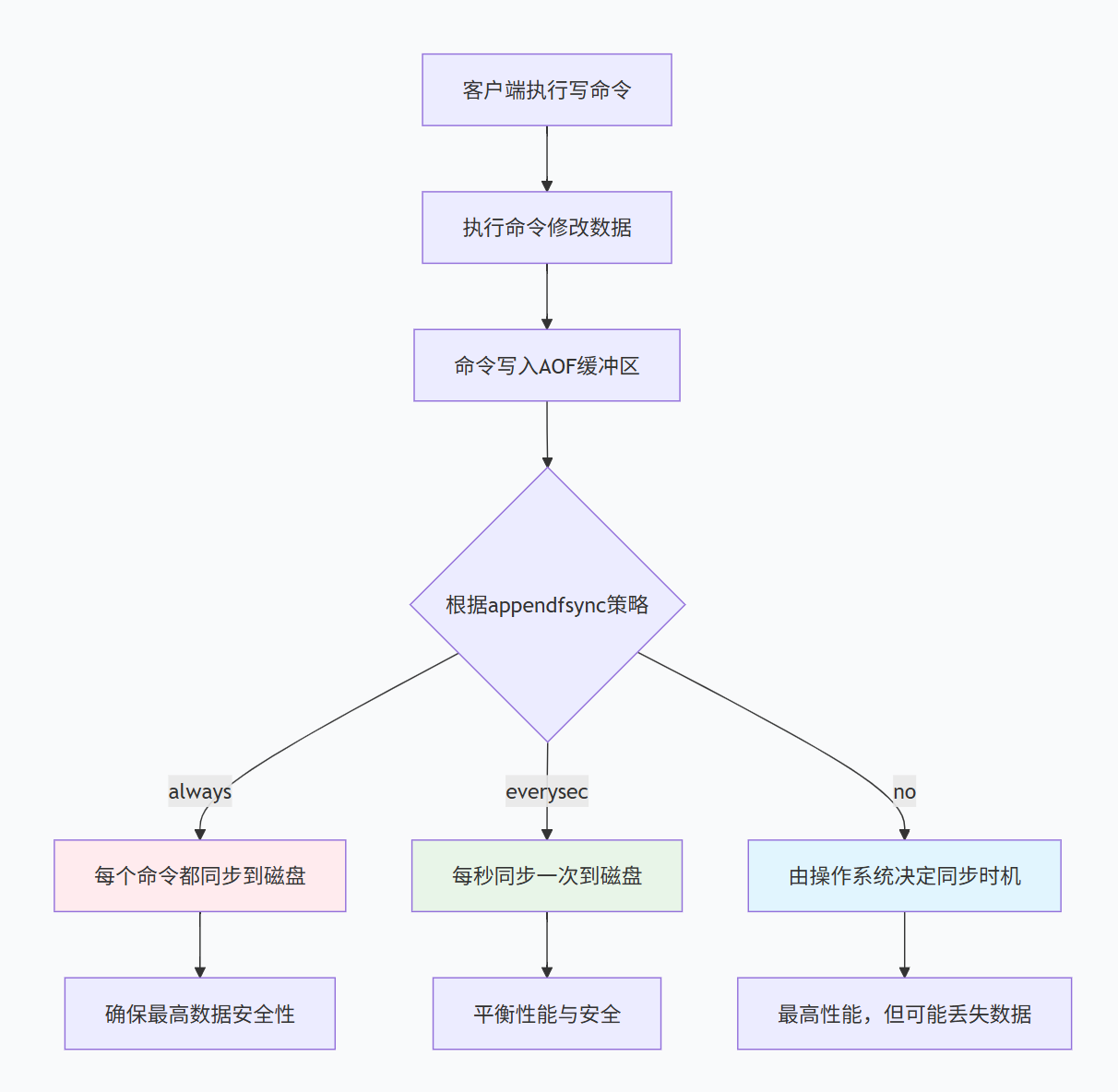
3.2.2 ⭐AOF写入流程
3.2.3 AOF重写与后台进程
为什么需要AOF重写?
随着时间推移,AOF文件会不断增大:
-
冗余命令:如对同一个key多次SET,只有最后一次有效
-
过期命令:已删除key的相关命令已无效
-
文件膨胀:大量命令导致文件过大,影响恢复速度
AOF重写原理
重写目标 :从当前数据库状态生成最小命令集。
重写流程:
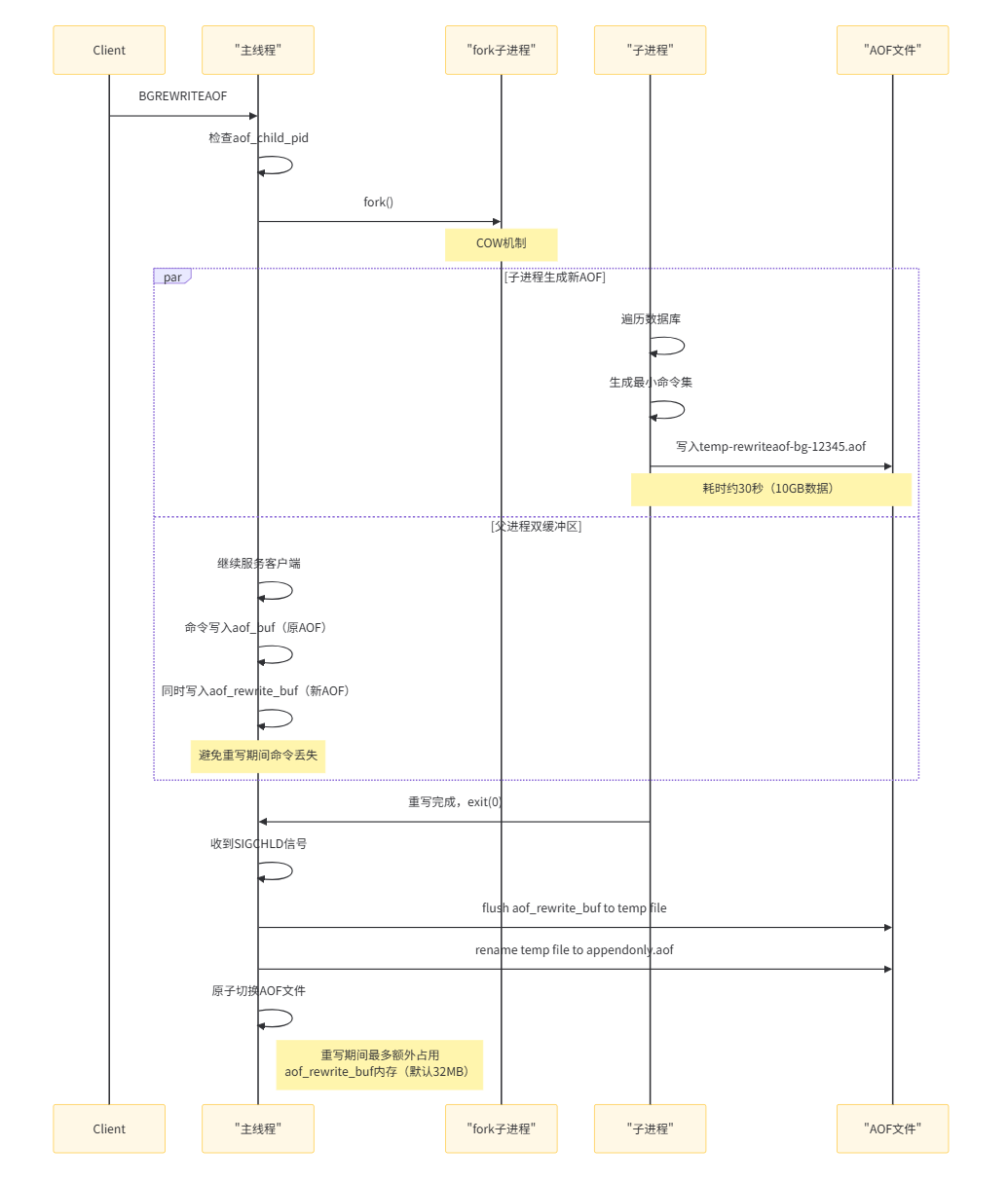
AOF重写触发条件
bash
# redis.conf配置
auto-aof-rewrite-percentage 100 # 当前AOF文件比上次重写后大小增长100%
auto-aof-rewrite-min-size 64mb # AOF文件至少64MB才重写
# 手动触发
BGREWRITEAOF # 后台重写AOF重写缓冲区的作用
重写期间,新的写命令需要同时:
-
写入现有的AOF文件(保证数据不丢失)
-
写入重写缓冲区(保证重写后的AOF文件包含最新数据)
当子进程完成重写后,主进程会将重写缓冲区的内容追加到新AOF文件中,然后原子性地替换旧AOF文件。
3.2.4 fsync策略与性能权衡
三种fsync策略对比
| 策略 | 执行时机 | 数据安全性 | 性能影响 | 适用场景 |
|---|---|---|---|---|
| always | 每个命令后 | 最高,最多丢失一个命令 | 最差,频繁磁盘写入 | 对数据安全要求极高 |
| everysec | 每秒一次 | 较好,最多丢失1秒数据 | 中等,平衡性能与安全 | 大多数生产环境 |
| no | 由操作系统决定 | 最低,可能丢失较多数据 | 最好,完全异步 | 可容忍数据丢失 |
性能测试数据参考
| 场景 | QPS(每秒查询数) | 数据丢失风险 | 备注 |
|---|---|---|---|
| 无持久化 | 100,000+ | 最高,重启即丢失 | 纯缓存场景 |
| RDB(默认配置) | 80,000-90,000 | 中等,丢失最近一次快照后的数据 | 通用场景 |
| AOF always | 1,000-5,000 | 极低,最多丢失一个命令 | 金融等敏感场景 |
| AOF everysec | 40,000-60,000 | 低,最多丢失1秒数据 | 推荐的生产配置 |
| RDB+AOF混合 | 30,000-50,000 | 很低,结合两者优势 | 数据安全要求高 |
3.3 混合持久化与数据恢复
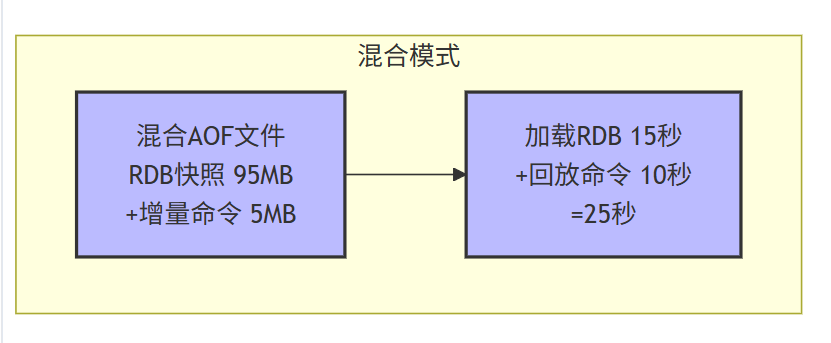
3.3.1 ⭐RDB+AOF混合模式
RDB/AOF痛点:AOF重写后仍是命令日志,恢复速度慢;RDB恢复快但数据丢失多。
解决方案 :重写AOF时,前半部分是RDB二进制快照,后半部分是增量AOF命令。
AOF文件结构(混合模式):
启用混合持久化
bash
bash
# redis.conf配置
aof-use-rdb-preamble yes # Redis 4.0+默认开启
# AOF重写时会生成混合格式
# 手动检查AOF文件
$ file appendonly.aof
appendonly.aof: Redis RDB or AOF format, RDB version 0009, checksum 7a9a97e4混合持久化优势
-
快速恢复:RDB部分提供快速加载
-
数据完整:AOF部分保证数据不丢失
-
文件较小:相比纯AOF,文件更紧凑
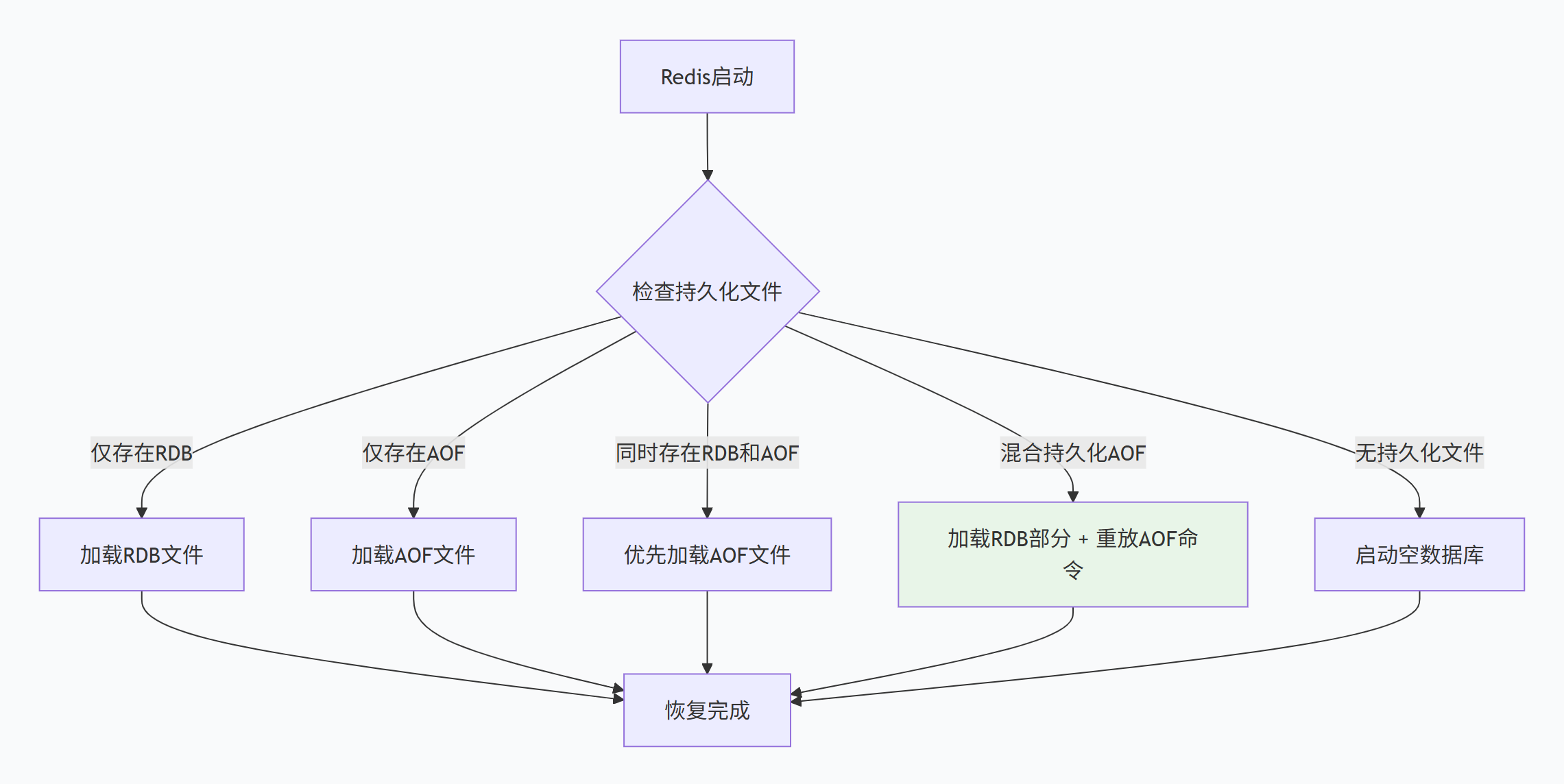
3.3.2 故障恢复流程
Redis启动时的数据恢复
AOF文件损坏修复
bash
# 1. 检查AOF文件完整性
redis-check-aof --fix appendonly.aof
# 2. 备份原文件后修复
cp appendonly.aof appendonly.aof.bak
redis-check-aof --fix appendonly.aof
# 3. 使用修复后的文件重启Redis修复原理:
-
扫描AOF文件,寻找有效的RESP协议格式
-
跳过损坏的命令,保留有效部分
-
生成修复后的AOF文件
3.3.3 数据一致性保证
持久化与性能的权衡
CAP理论在Redis持久化中的应用:
-
C(一致性):AOF always提供最强一致性
-
A(可用性):RDB和无持久化提供最高可用性
-
P(分区容错性):所有持久化方式都需要
实际生产中的选择:
| 业务类型 | 推荐配置 | 一致性级别 | 性能影响 |
|---|---|---|---|
| 缓存系统 | RDB(默认) | 最终一致性 | 低 |
| 会话存储 | RDB+定期备份 | 会话级一致性 | 中 |
| 业务数据库 | AOF everysec + RDB | 秒级一致性 | 中 |
| 金融交易 | AOF always + 同步复制 | 强一致性 | 高 |
写入安全保证
Redis持久化与Linux系统的交互:
-
文件系统缓存:write()写入页面缓存,fsync()刷到磁盘
-
磁盘缓存:有些磁盘有写缓存,需要禁用或使用电池备份
-
操作原子性:rename()操作是原子的,用于AOF重写切换
确保数据安全的额外措施:
bash
# 1. 禁用磁盘写缓存(确保数据真正落盘)
hdparm -W0 /dev/sda
# 2. 使用带电池备份的RAID卡
# 3. 定期验证持久化文件
crontab -e
# 每天检查AOF文件
0 2 * * * redis-check-aof /var/lib/redis/appendonly.aof3.4 面试高频考点
考点1:⭐RDB和AOF持久化的区别和优缺点?
面试回答:
RDB和AOF是Redis的两种持久化机制,各有特点:
RDB(快照持久化):
-
原理:定期将内存数据保存为二进制快照
-
优点:
-
文件紧凑,恢复速度快
-
fork子进程执行,不影响主进程
-
适合备份和灾难恢复
-
-
缺点:
-
可能丢失最后一次快照后的数据
-
数据量大时fork可能阻塞服务
-
不是实时持久化
-
AOF(追加日志):
-
原理:记录每个写命令,重启时重放命令
-
优点:
-
数据安全性高,最多丢失1秒数据(everysec策略)
-
可读性强,文件格式简单
-
支持重写压缩文件
-
-
缺点:
-
文件通常比RDB大
-
恢复速度较慢(需要重放命令)
-
对性能影响比RDB大
-
生产建议:通常结合使用,用RDB做定期备份,AOF保证数据安全。
考点2:fork写时复制(COW)在RDB持久化中如何工作?
面试回答:
fork写时复制是RDB持久化的关键技术:
-
fork创建子进程:
-
调用fork()系统调用创建子进程
-
子进程复制父进程的页表,共享相同的物理内存页
-
所有共享内存页被标记为只读
-
-
写时复制机制:
-
当父进程(Redis主进程)修改数据时,尝试写入只读页触发页错误
-
内核复制该内存页为新页,修改页表映射
-
父进程修改新页,子进程继续使用原页
-
-
子进程持久化:
-
子进程遍历内存中的原始数据页
-
将数据序列化为RDB格式写入磁盘
-
完成后退出,父进程收到信号清理资源
-
-
优势与风险:
-
优势:快速创建进程,内存高效,父进程无阻塞
-
风险:大量写入时可能复制大量内存页,导致内存使用翻倍
-
考点3:AOF重写的原理和过程?
面试回答:
AOF重写是为了解决AOF文件膨胀问题:
重写原理:从当前数据库状态生成最小命令集,消除冗余命令。
重写过程:
-
触发重写:主进程fork子进程
-
子进程重写:
-
遍历所有数据库和key
-
为每个key生成最简命令(如一个SET命令代替多个历史SET)
-
写入新的AOF文件
-
-
主进程处理新命令:
-
继续服务客户端请求
-
新命令写入现有AOF文件
-
同时写入AOF重写缓冲区
-
-
完成切换:
-
子进程完成重写后通知主进程
-
主进程将重写缓冲区命令追加到新AOF文件
-
原子性地用新文件替换旧文件
-
触发条件:
-
自动:AOF文件增长超过一定比例(默认100%)和最小大小(默认64MB)
-
手动:执行BGREWRITEAOF命令
考点4:Redis数据恢复的优先级和流程?
面试回答:
Redis启动时的数据恢复遵循特定优先级:
-
恢复优先级:
-
如果启用了AOF,优先加载AOF文件
-
如果AOF关闭,加载RDB文件
-
如果都没有,启动空数据库
-
-
恢复流程:
启动 → 检查持久化配置 → 寻找持久化文件 → 加载数据 → 开始服务 -
混合持久化恢复:
-
如果AOF文件包含RDB前缀(混合模式)
-
先加载RDB部分的基础数据
-
再重放后面的AOF命令
-
-
文件损坏处理:
-
使用redis-check-aof修复AOF文件
-
使用redis-check-rdb检查RDB文件
-
从备份恢复或使用从节点数据
-
-
重要原则:
-
AOF文件比RDB文件更新(通常)
-
混合持久化结合了两者优点
-
生产环境建议定期备份持久化文件
-
考点5:⭐如何保证Redis持久化的数据一致性?
面试回答:
保证Redis持久化数据一致性需要多层面策略:
-
配置层面:
-
根据业务需求选择持久化策略
-
AOF always:最强一致性,每个命令都fsync
-
AOF everysec:平衡选择,最多丢失1秒数据
-
RDB:定期持久化,可能丢失最后一次快照后的数据
-
-
混合持久化:
-
Redis 4.0+的混合模式(RDB+AOF)
-
结合RDB的快速恢复和AOF的数据安全
-
-
系统层面:
-
禁用磁盘写缓存:确保数据真正落盘
-
使用带电池备份的RAID卡
-
定期fsync确保数据同步
-
-
架构层面:
-
主从复制:从节点作为热备份
-
哨兵/集群:高可用保障
-
定期备份:远程备份持久化文件
-
-
监控与恢复:
-
监控持久化状态和延迟
-
定期验证持久化文件完整性
-
制定灾难恢复预案并定期演练
-
一致性等级选择:
-
强一致性:AOF always + 同步复制(性能最低)
-
最终一致性:RDB或AOF everysec(推荐大多数场景)
-
弱一致性:无持久化或异步复制(纯缓存场景)