一. string对象 和 字符数组 的区别
-
string对象结尾多了一个\0。
-
这个 \0 不属于有效字符,只是一个标识符。所以在计算字符串长度时不算 \0 ,但是申请空间时要为\0留一个位置。
二. 迭代器
下图中的迭代器两个两个为一组分别为 普通迭代器(包含const迭代器)、普通反向迭代器(包含const反向迭代器)、const迭代器、const反向迭代器。
因为前两组已经包含后两组,虽然后两组设计出来是为了更好区分普通迭代器和const迭代器,但是实际应用比较少。

使用的角度把迭代器就当做一个指针,比如begin就是指向字符串中的第一个元素的,带不带const影响的只是这个"指针"指向的元素我们是否有权限进行读写。
这几个迭代器的指向是确定的,我们可以用它来为一个迭代器类型的变量赋值(保存到变量中)在对这个变量进行移动,却不可以直接对他++或--。因为他们返回的是临时对象,具有常性不可修改。
不同的迭代器有不同的类型:iterator、const_iterator、reverse_iterator、const_reverse_iterator
这四种类型都属于string这个类,是在类中定义的,所以使用时不仅要指明命名空间域,还要指明类域。

1)begin

2)end

-
end() 也分普通版本和const版本。
-
它指向的不是最后一个字符的位置,而是最后一个字符的下一个位置 !(也就是\0)

3)rbegin
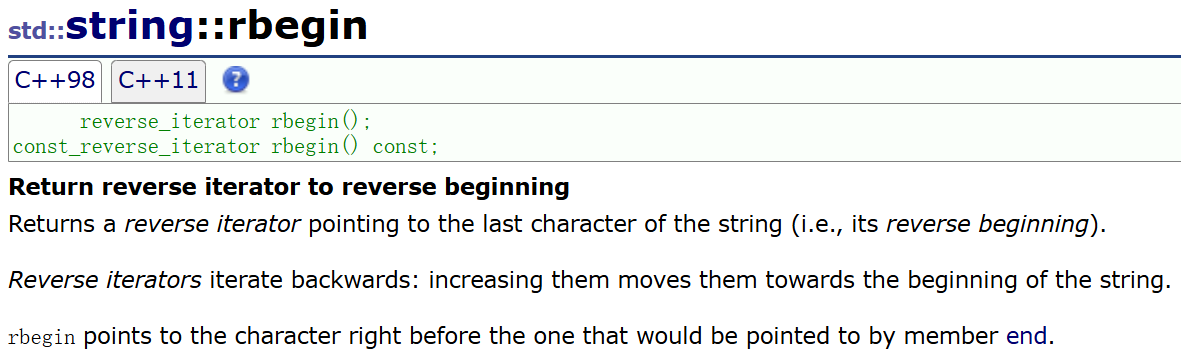
-
rbegin 指向的是字符串的最后一个有效元素 (\0的前一个位置),他是反向的开始。
-
我们在使用反向迭代器时,希望他向字符串开头移动,也就是往左移,但是注意:我们习惯上可能认为左移应该--,但是反向迭代器++就是左移(向字符串开头移动)。
4)rend

- 返回一个反向迭代器,指向字符串第一个元素的前一个位置 。
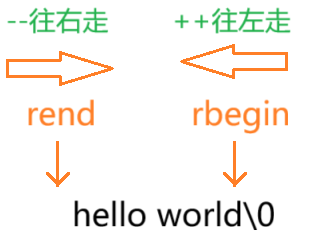
begin 和 end 组成了一个左闭右开的区间。
rbegin 和 rend 组成了一个左开右闭的区间。
他们都包含了所有元素。
begin 和 rbegin 向目标方向移动的方式都是++,只不过他们标记的正方向不同。
类似的end 和 rend 向目标方向移动的方式都是--,只不过目标方向相反。
5)cbegin、cend、crbegin、crend
-
是C++11标准引进的,以cbegin为例:
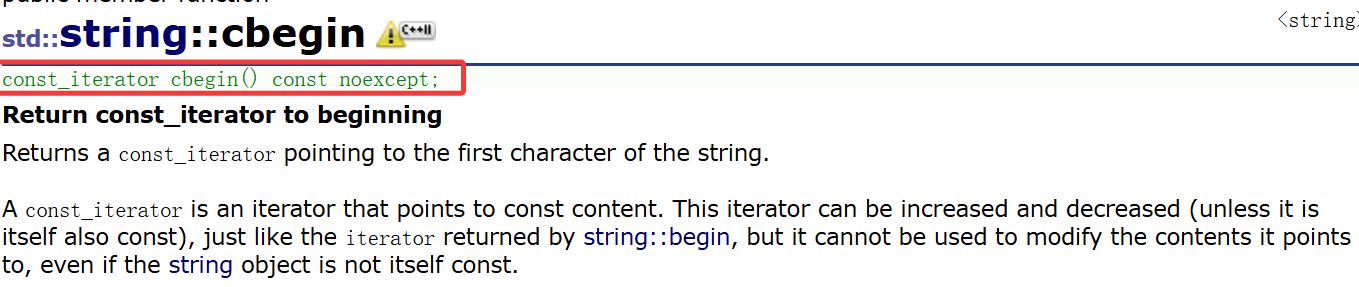
-
cbegin 的函数原型中有一个 noexcept,noexcept是 C++11 引入的关键字,表示这个成员函数承诺不会抛出任何异常。
6)迭代器使用示例
cpp
void Test01() // 迭代器
{
string s1 = "hello world";
// 不能对函数调用的返回值直接++
// 所以先获取迭代器,再自增
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit;
++rit; // 反向迭代器++向左遍历,不要以为往左走就用--
}
cout << endl;
}
成功实现反向遍历,但实际反向迭代器并不常用。比如上篇最后的第一道算法题(仅仅反转字母)的思想,用双指针就可以实现逆置,不必使用反向迭代器。
7)const迭代器 -- 权限问题
1. 普通迭代器和const迭代器的异同
① 两版本迭代器本身的指向都可以修改。
② 都可以通过指针读取元素。
③ 普通版本可以通过迭代器对指向元素做修改(可写);const版本迭代器指向的内容不可以修改。
2. 调用时的权限问题(权限可以缩小,不可以放大)
① 一个const成员函数,普通对象和const对象都能调;普通成员函数只有普通对象能调。const成员函数内部不能修改类的成员变量。
② 当普通函数和const对象同时存在时,对象调用的一定是更匹配的。
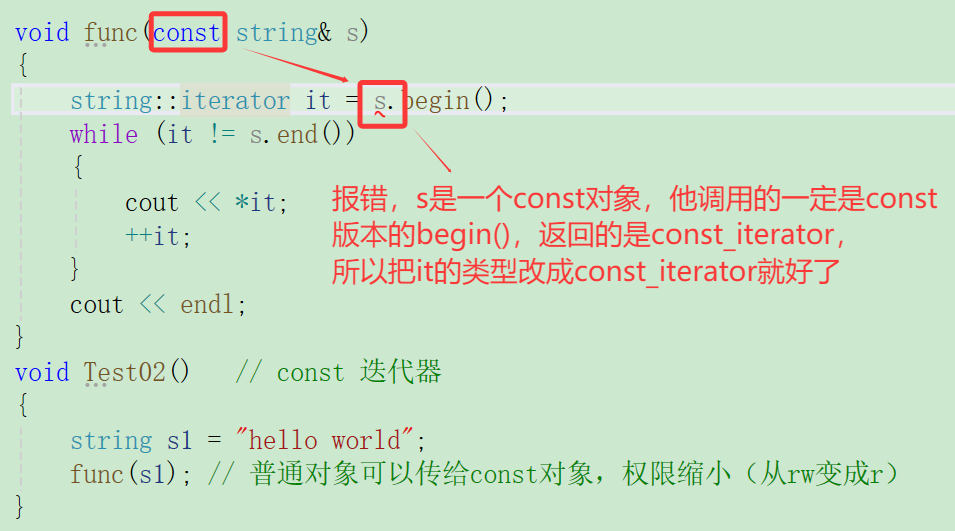

cpp
void func(const string& s)
{
string::const_iterator it = s.begin();
while (it != s.end())
{
cout << *it;
++it;
}
cout << endl;
}
void Test02() // const 迭代器
{
string s1 = "hello world";
func(s1); // 普通对象可以传给const对象,权限缩小(从rw变成r)
}
3. 区分 const_iterator 和 const iterator
① const_iterator:迭代器指向的内容不能修改。
② const iterator:迭代器自身的指向不能修改。
三. capacity组(容量相关)

1)size、length、max_size、capacity
-
size :有效字符个数。推荐使用,每个容器都有一个size()表示有多少个数据,更通用。

-
length:有效字符个数。和size功能相同,但是是string独有的,不具有通用性,所以用的比较少。

-
max_size:固定值,表示字符串理论上能达到的最大长度(只是个理论值,实际是达不到的)。没什么用。

-
capacity :字符串当前已分配的内存能够容纳的字符数量(不包括\0)。capacity >= size,capacity是能容纳的字符个数,size是实际有的字符个数,当capacity不够了,会自动发生扩容。

cpp
void Test03() // capacity组
{
string s1("hello world");
cout << s1.size() << endl;
cout << s1.length() << endl;
cout << s1.max_size() << endl;
cout << s1.capacity() << endl;
}
2)clear、empty
5. clear: 清空,只清理字符,不清理空间。即令size = 0, capacity不变。
6. empty: 判断字符串是否为空。为空返回真,不为空返回假。

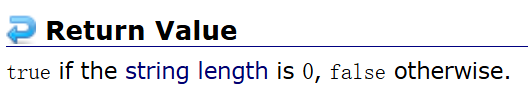
3)shrink_to_fit、reserve、resize、扩容机制
7. shrink_to_fit: 缩容。很少用,开销比较大。
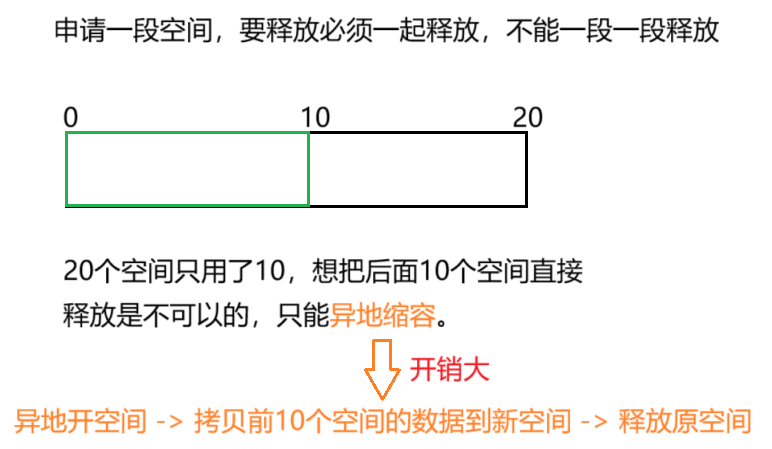
string的扩容机制
C++标准只规定了空间不足是要发生扩容,却没有具体规定要如何扩(一次扩二倍?1.5倍?并没有规定),所以不同编译器在设计时采取的具体的扩容机制是不同的。
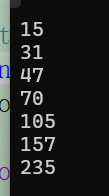
VS(msvc)中:第一次扩2倍,之后都扩1.5倍。
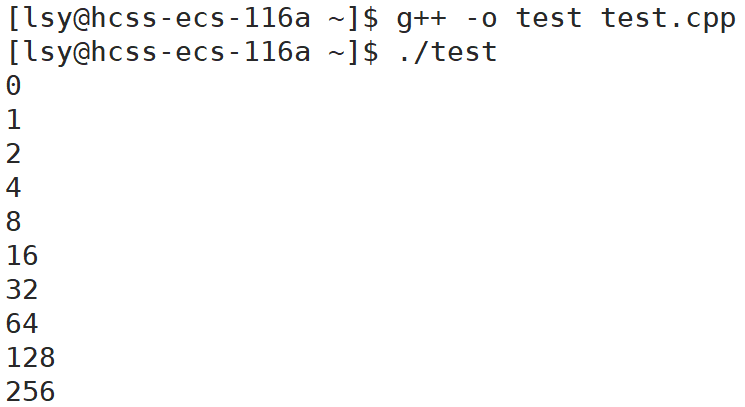
cppvoid Test04() // string扩容机制 { string s; int old_capacity = s.capacity(); cout << old_capacity << endl; for (size_t i = 0; i < 200; i++) { // push_back:向字符串尾部插入 s.push_back('y'); if (s.capacity() != old_capacity) { cout << s.capacity() << endl; old_capacity = s.capacity(); } } }
- Linux(g++)中:全部2倍扩容。
8. reserve:请求更改容量到n。
① 扩容:一定会扩。实际在使用reserve时我们只是用它的扩容功能。申请扩到n,他可能会扩到n或更大(可能因为内存对齐或者什么原因)。
② 扩容功能使用场景:确定大约会用多大空间,直接一把开够,减少扩容开销。
③ 缩容:缩容被视为非绑定请求,缩不缩都不一定,取决于平台。所以我们不能用这个功能,不然可能在这个平台缩了能用,换一个平台代码就跑不了了。如果实在需要缩容就用shrink_to_fit。
并且即使缩容了,也最多缩到size,不会影响数据。

cpp
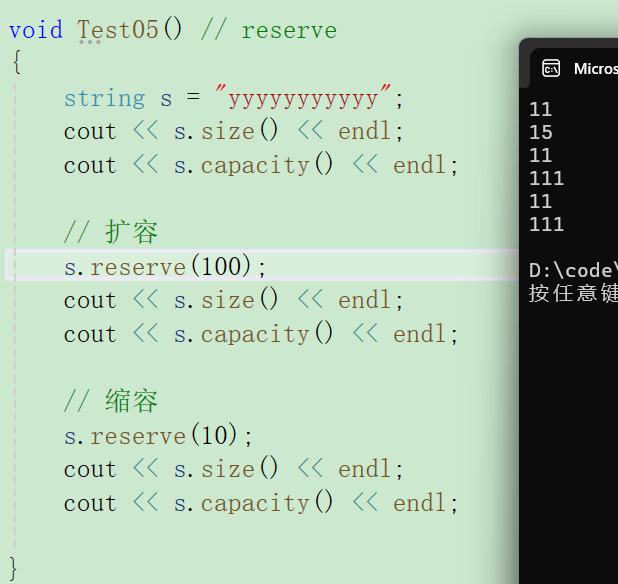
void Test05() // reserve
{
string s = "yyyyyyyyyyy";
cout << s.size() << endl;
cout << s.capacity() << endl;
// 扩容
s.reserve(100);
cout << s.size() << endl;
cout << s.capacity() << endl;
// 缩容
s.reserve(10);
cout << s.size() << endl;
cout << s.capacity() << endl;
}④ VS下只扩容,不缩容。并且我要开100,他实际开的可能更多。
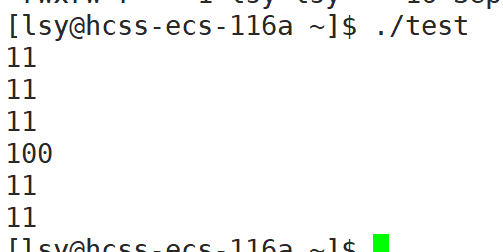
⑤ Linux下,使用g++编译的,缩容扩容都会做。并且我要缩到10,为了不影响数据,只缩到了11(也就是size的大小)。
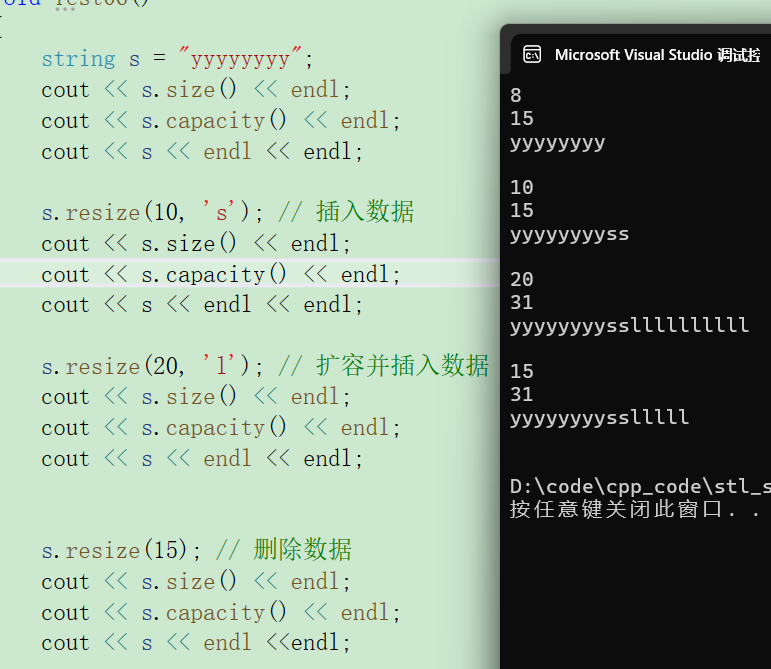
9. resize: 调整元素个数到 n(size大小)。

n的大小有三种情况:
① size < n < capacity :插入数据。
② n < size:删除数据。
③ n > capacity :扩容之后插入数据。
插入的数据如果指定了字符c,则插入c。如果没有指定则用'\0'。
四. 元素访问相关

1)\[\]下标访问:返回对字符串中pos位置的字符的引用

-
普通版本:可读可写。
-
const版本:只读。
2)at:返回对字符串中pos位置的字符的引用

-
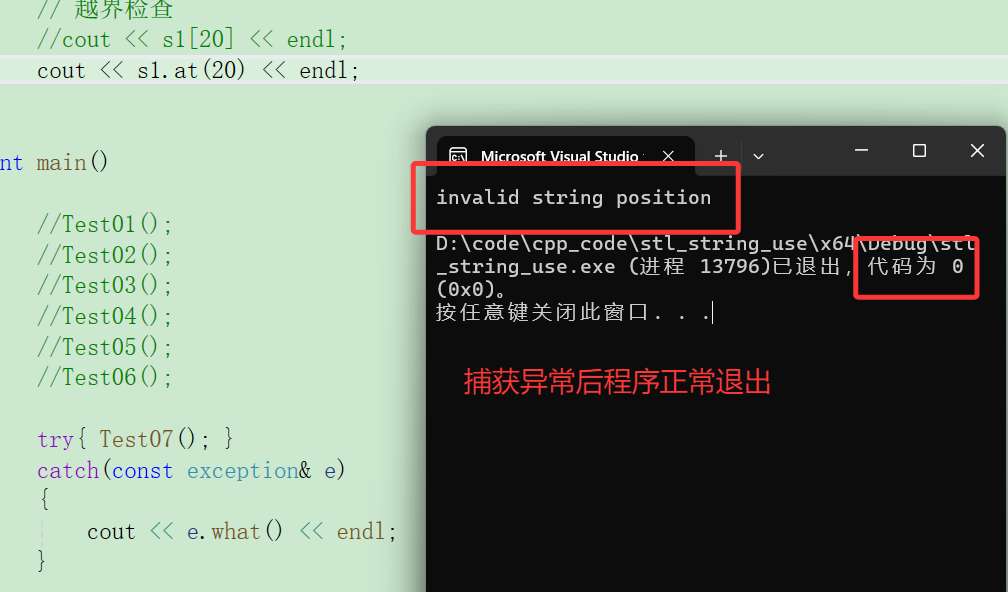
该函数自动检查pos是否为字符串中字符的有效位置(即pos是否小于字符串长度),如果不是,则抛出out_of_range异常。
-
它的功能和\[\]一样。

-
\[\]是运算符重载,at是函数。
-
他们的区别在越界错误检查的方式 不同:
① \[\]:断言报错,直接终止程序。但是断言只在debug模式下起作用。
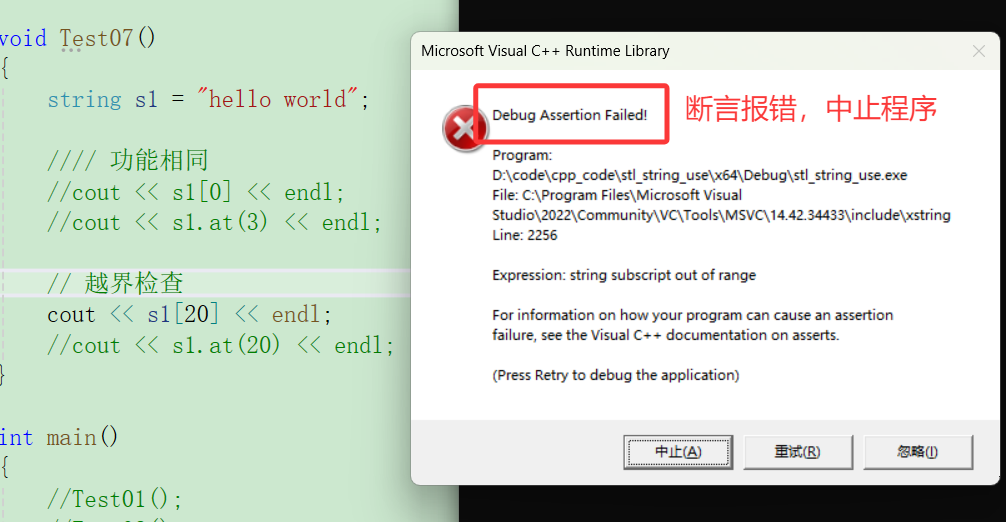
② at:抛异常,捕获后可继续运行。
3)back、front
-
back:访问最后一个字符。
-
front:访问第一个元素。
-
这两个一般不用:s.back() 可被 ss.size() - 1 代替;s.front() 可被 s0 代替。\[\] 是更常用的方法。
五. 修改相关
1)push_back、append、+=、pop_back
1. push_bach: 尾插,从字符串的尾部插入一个字符。
2. append: 追加,尾插一个串(一个字符也是一个串)。

3. += : 在尾部追加,综合了1,2最常用的功能,并且可读性很高,更好用。

4. pop_back: 尾删,删除字符串最尾部的一个元素,字符串长度减一。

- 使用演示
cpp
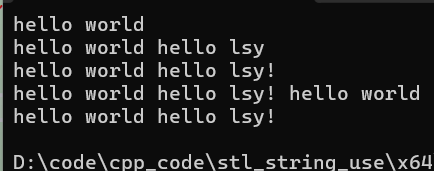
void Test08()
{
string s1 = "hello ";
string s2 = "world";
s1.append(s2);
cout << s1 << endl;
s1.append(" hello ls");
s1.append("y");
cout << s1 << endl;
s1.push_back('!');
cout << s1 << endl;
s1 += " hell";
s1 += 'o';
s1 += " ";
s1 += s2;
cout << s1 << endl;
for(size_t i = 11; i > 0; i--)
{
s1.pop_back();
}
cout << s1 << endl;
}
2)insert、erase
因为头插头删需要挪动数据,效率低,所以没有提供直接可使用的接口。不建议做头插或头删,但是我们如果有需求,也提供了间接的接口 -- insert、erase。
1. insert: 在指定位置插入字符或字符串。底层要先挪动数据,再插入,效率不高。

2. erase: 删除元素。很可能要挪动数据,从而覆盖删除,效率不高。
① 删除字符串中从pos位置开始的len个字符。如果使用缺省值作用类似clear,清除字符串中所有元素。
② 删除迭代器指向的一个字符。
③ 删除迭代区间( [first, last),左闭右开)内的所有字符。

cpp
void Test09()
{
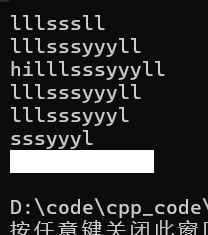
string s1 = "lllll";
string s2 = "sss";
s1.insert(3, s2);
cout << s1 << endl; // lllsssll
s1.insert(6, "yyy");
cout << s1 << endl; // lllsssyyyll
// 头插
s1.insert(0, 1, 'i');
s1.insert(s1.begin(), 'h');
cout << s1 << endl; // hilllsssyyyll
// 头删
s1.erase(0, 2);
cout << s1 << endl; // lllsssyyyll
s1.erase(s1.end() - 1);
cout << s1 << endl; // lllsssyyyl
s1.erase(s1.begin(), s1.begin() + 3);
cout << s1 << endl; // sssyyyl
s1.erase(); // 清空
cout << s1 << endl;
}
3)assign、replace
1. assign: 为字符串赋一个新值,替换其当前内容。很少用。

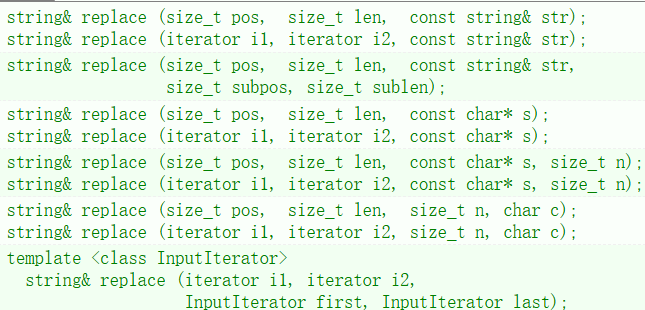
2. replace: 用新内容替换字符串中从字符pos开始并跨越len字符的部分(或字符串中位于[i1,i2)之间的部分)。
如果不是等比例替换,而是用长字符串替换短字符串,或者用短字符串替换长字符串,就要挪动数据,效率不高。
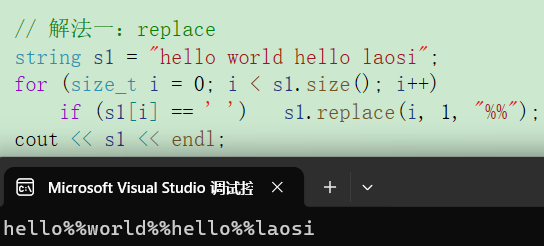
将字符串中所有空格变成%%
- 解法一:使用replace原地换
效率很低,不推荐
- 解法二:开一个新串
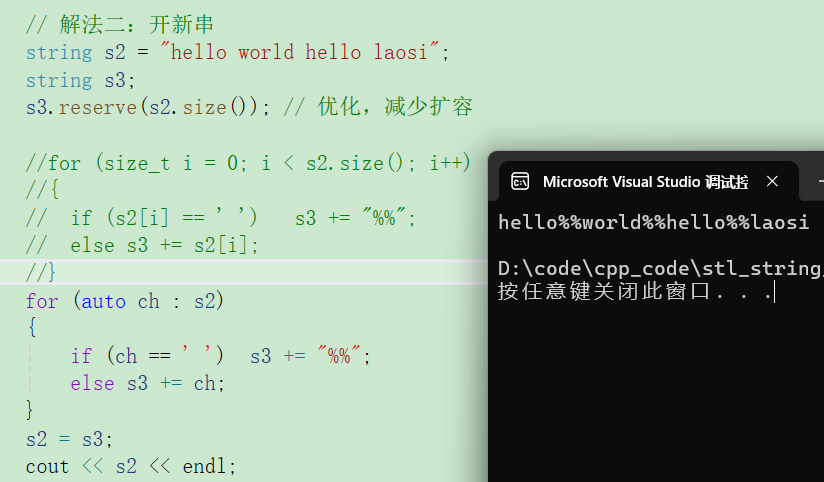
六. String operations组
1)c_str
返回C风格的字符数组,最后一个元素是'\0'。

cpp
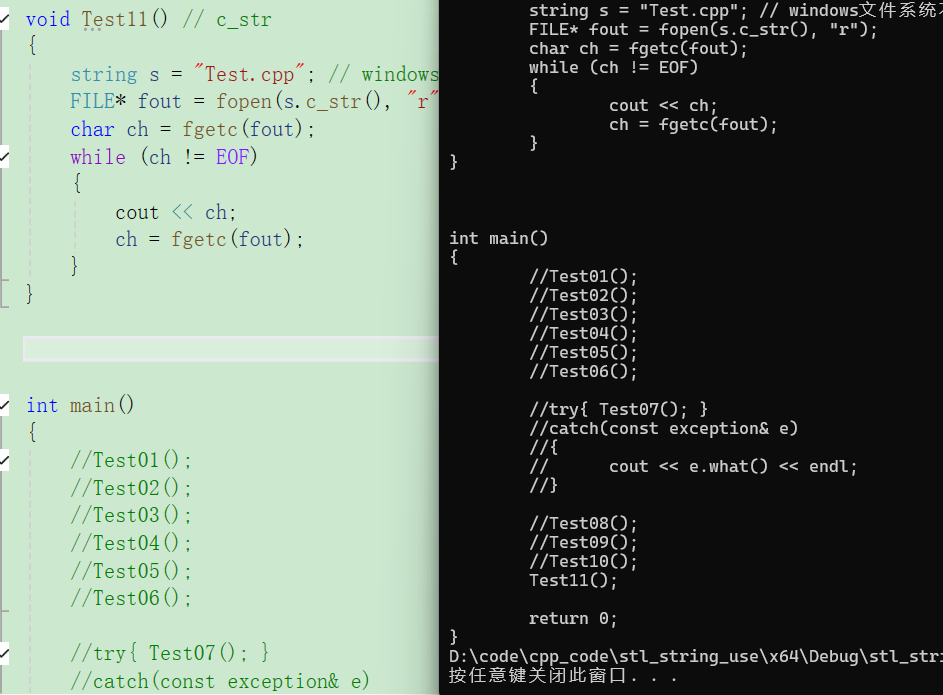
void Test11() // c_str
{
string s = "Test.cpp"; // windows文件系统不区分大小写
FILE* fout = fopen(s.c_str(), "r");
char ch = fgetc(fout);
while (ch != EOF)
{
cout << ch;
ch = fgetc(fout);
}
}
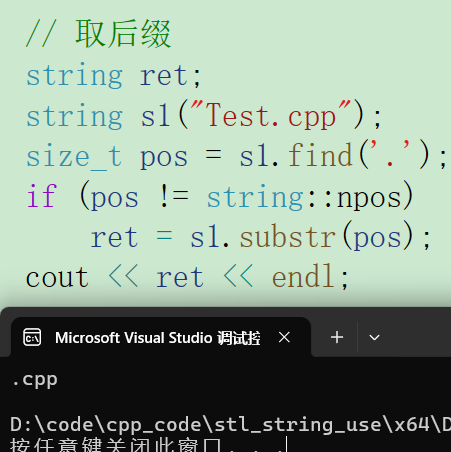
2)substr
取pos位置开始的len个字符并返回。不传参默认全取完。

3)find、rfind
- find
从pos位置开始查找完全匹配的字符。
返回第一个匹配的第一个字符的位置。如果没有找到匹配项,函数返回npos。

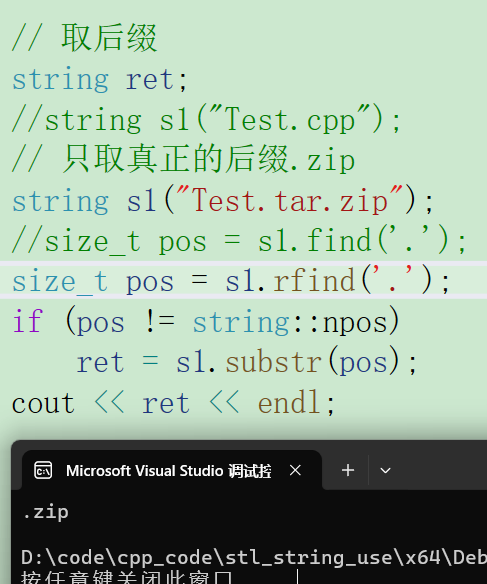
- rfind:从后往前找。
例1:1. find
2. rfind
例2:把一个网址的协议、域名、资源分别解析出来。
解析需要找两个位置,pos1和pos2,通过两个位置将网址分成三个子串sub1, sub2, sub3分别对应协议、域名、资源。
pos1比较好找,find第一个冒号即可。
pos2从前、从后都不太好找,但是find支持从指定位置开始找,所以从pos1 + 3开始的第一个 / 就是pos2。
cppstring s2 = "https://legacy.cplusplus.com/reference/string/string/find/"; size_t pos1 = s2.find(":"); if (pos1 != string::npos) { string sub1 = s2.substr(0, pos1); cout << sub1 << endl; } size_t pos2 = s2.find("/", pos1 + 3); if (pos2 != string::npos) { //string sub2 = s2.substr(pos1 + 3, pos2); // 注意第二个参数是子串长度,不是结束位置 string sub2 = s2.substr(pos1 + 3, pos2-(pos1+3)); string sub3 = s2.substr(pos2 + 1); cout << sub2 << endl << sub3 << endl; }

4)find_fist_of、find_last_of、find_first_not_of、find_last_not_of

- find_first_of
为了方便理解可以记为find_any_of,即从指定位置开始只要找到字符串里的任意字符就返回。返回值为匹配的第一个字符的位置。如果没有找到匹配项,则返回string::npos。

cpp
string str("Please, replace the \"abcd\" in this sentence by asterisks.");
cout << str << endl;
size_t found = str.find_first_of("abcd");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_of("abcd", found + 1); // 下一次从found+1位置开始找
}
// 至此已经将str中的所有abcd用*替换了
cout << str << endl;
- find_last_of
从后往前找。
cpp
string str("Please, replace the \"abcd\" in this sentence by asterisks.");
cout << str << endl;
size_t found = str.find_last_of("abcd");
str[found] = '*';
// find_last_of这里只找一个,验证确实是从后往前找
cout << str << endl;
- find_first_not_of
不是指定字符串里的字符就返回。
cpp
string str("Please, replace the \"abcd\" in this sentence by asterisks.");
cout << str << endl;
size_t found = str.find_first_not_of("abcd");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_not_of("abcd", found + 1); // 下一次从found+1位置开始找
}
// 至此已经将str中的所有不是abcd的字符用*替换了
cout << str << endl;
5)compare
将字符串对象或其子串的值与参数指定的字符序列按ASCII码进行比较。不常用,因为string重载了关系运算符。

七. Non-member function overloads非成员函数重载组

非成员函数是全局的,但是不一定要重载为类的友元,除非函数内要访问类的私有成员。
那么为什么这些函数不能重载为类的成员函数,而必须是全局的呢?
类似我们前面说的流插入和流提取的重载,因为类的成员函数的第一个参数类型是固定的--当前类类型的this指针。所以如果重载为类的成员函数,第一个参数必须是类类型。这不能满足我们左操作数可能不是当前类类型的需求,因此必须重载为全局的函数,参数类型可自定义。
1)relational operators关系运算符
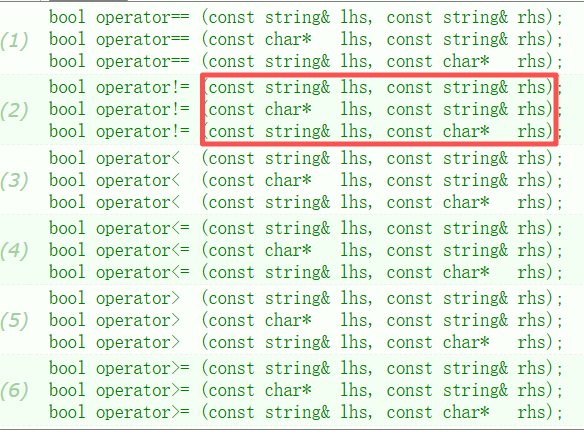
每个运算符都重载了三种参数,字符串与字符串、字符数组与字符串、字符串与字符数组。这样以下三种情况都支持了,但是是有一点冗余的,因为单参数构造支持隐式类型转换,后两种重载即使不给出,字符数组也会在传参时自动隐式类型转换为字符串类型。
cpp
const char* str = "lsy";
string s1("lll"), s2("sss");
// 以下三种情况都支持了
s1 == s2; // 字符串与字符串
str == s1; // 字符数组与字符串
s1 == str; // 字符串与字符数组2)operator+
字符串拼接(字符串也可与字符数组、字符拼接)

3)流提取operator>>、流插入operator<<
-
istream& operator>> (istream& is, string& str);
-
ostream& operator<< (ostream& os, const string& str);
4)getline

-
获取整行。
-
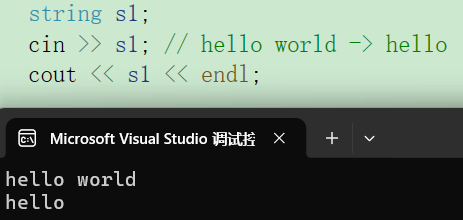
cin和scanf都认为空格和回车是值的分隔符,所以cin一个"hello world",实际变量只存储到"hello"。
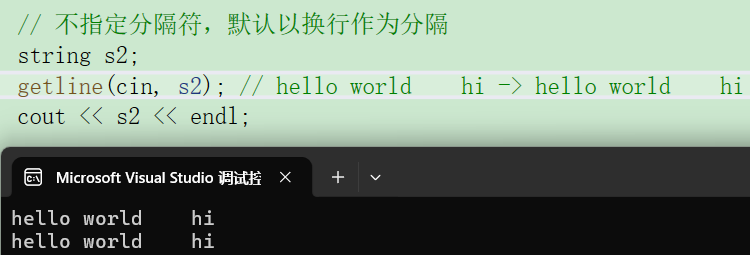
此时就需要getline:获取一行,默认以换行为分隔符。
那么希望字符串里有换行符呢?getline支持指定分隔符。
- 参数:一个istream对象,即cin。字符串目标存放位置。可选:分隔符。
cpp
// 指定分隔符
string s3;
getline(cin, s3, '$'); // hello world\nhi\n$ -> hello world\n hi\n
cout << s3 << endl;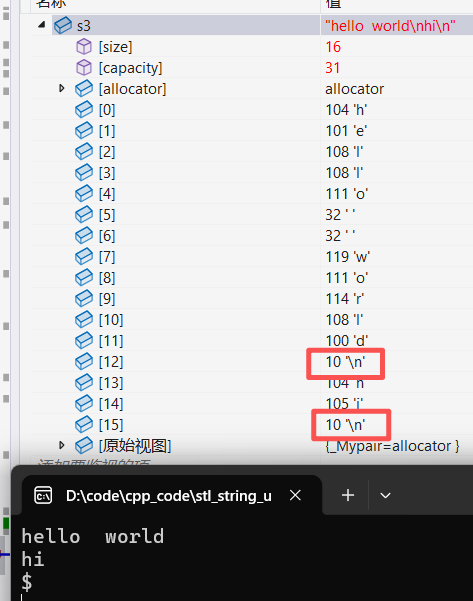
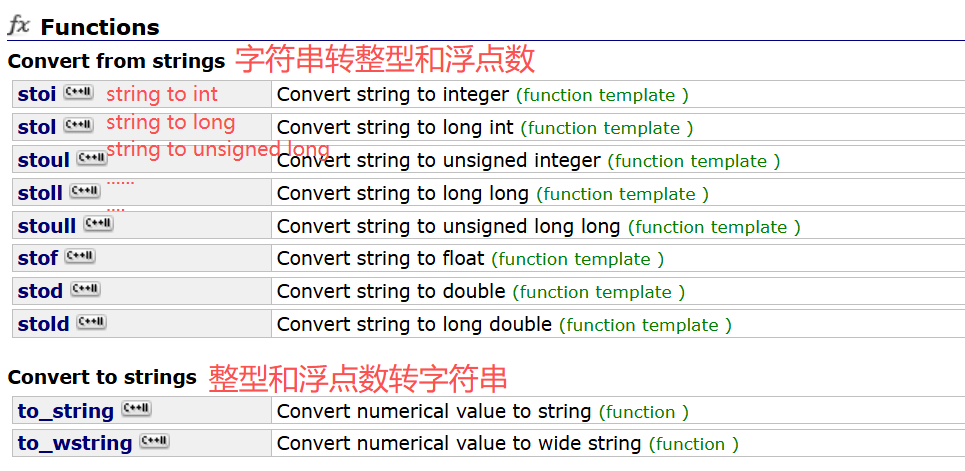
八. 转换函数
默认转十进制,可以设置参数,指定用什么进制。
九. 流的标志位
while(cin>>s1){} 和 while(getline(cin, s1)){} 可以实现循环多组输入,按Ctrl+z回车可以结束,为什么呢?
因为流都有四个标志流的状态的参数:


Ctrl+z可以将eofbit置为true,代表该流出现异常,不可用了。
标识完又是如何判断的呢?
自定义类型转内置类型要重载一个operator bool,将cin或getline返回的istream对象转换为bool值,在operator bool函数内部检查几个标志的设置情况。
十. 算法题
https://leetcode.cn/problems/add-strings/description/
1)415. 字符串相加
题目描述
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
示例 1:
输入:num1 = "11", num2 = "123" 输出:"134"示例 2:
输入:num1 = "456", num2 = "77" 输出:"533"示例 3:
输入:num1 = "0", num2 = "0" 输出:"0"提示:
- 1 <= num1.length, num2.length <= 104
- num1 和num2 都只包含数字 0-9
- num1 和num2 都不包含任何前导零
题解
cpp
class Solution
{
public:
string addStrings(string num1, string num2)
{
int end1 = num1.size()-1, end2 = num2.size()-1;
int next = 0; // 进位
// 提前开好足够的空间,减少扩容开销
string str;
str.reserve(max(num1.size(), num2.size()) + 1);
while(end1 >= 0 || end2 >= 0) // 两个串只要有一个还没遍历完,就继续
{
int n1 = end1 >= 0 ? num1[end1--] - '0' : 0;
int n2 = end2 >= 0 ? num2[end2--] - '0' : 0;
int ret = n1 + n2 + next;
// 更新当前位和进位值
next = ret / 10;
ret = ret % 10;
str += ret + '0';
}
// '9' + '1'的例子,最后的进位无法在循环中尾插到str中
if(next == 1) str += '1';
// reverse不是string的成员函数,不要写成str.reverse()
// 正确的结果应该头插(手算一下两数相加就知道),但是头插开销大
// 所以我们采用全部尾插,最后逆置
reverse(str.begin(), str.end());
return str;
}
};2)125. 验证回文串
题目描述
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串
s,如果它是 回文串 ,返回true;否则,返回false。示例 1:
输入: s = "A man, a plan, a canal: Panama" 输出:true 解释:"amanaplanacanalpanama" 是回文串。示例 2:
输入:s = "race a car" 输出:false 解释:"raceacar" 不是回文串。示例 3:
输入:s = " " 输出:true 解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。 由于空字符串正着反着读都一样,所以是回文串。提示:
1 <= s.length <= 2 * 105s仅由可打印的 ASCII 字符组成
题解
cpp
class Solution
{
public:
bool isPalindrome(string s)
{
for(auto& e : s)
{
// 小写转大写
if(e >= 'a' && e <= 'z')
e = e - 32; // 小写字母的ASCII码比大写字母大
}
int left = 0, right = s.size()-1;
while(left < right)
{
// 在保证left < right的情况下移动指针,直到找到第一个数字或字母
while(!isalnum(s[left]) && left < right) left++;
while(!isalnum(s[right]) && left < right) right--;
// 比较两字符并移动指针
if(s[left++] == s[right--]) continue;
else return false;
}
// 走到这说明遍历完没发现有不一样的
return true;
}
};3)牛客:HJ1 字符串最后一个单词的长度
题目描述:
对于给定的若干个单词组成的句子,每个单词均由大小写字母混合构成,单词间使用单个空格分隔。输出最后一个单词的长度。
输入描述:
在一行上输入若干个字符串,每个字符串代表一个单词,组成给定的句子。
除此之外,保证每个单词非空,由大小写字母混合构成,且总字符长度不超过 103103 。
输出描述:
在一行上输出一个整数,代表最后一个单词的长度。
示例1
输入:HelloNowcoder
输出:13
说明:在这个样例中,最后一个单词是 "HelloNowcoder" ,长度为 13 。
示例2
输入:A B C D
输出:1
题解
cpp
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
getline(cin, s); // 输入的字符串中可能有空格所以必须用getline,而不是cin
// 没有空格返回npos(-1),-1+1=0,即取整个串,也是正确的
int pos = s.rfind(' '); // 为找最后一个单词,所以从后往前找第一个空格
string sub = s.substr(pos + 1); // 取空格后面的内容,即为最后一个单词
cout << sub.size() << endl; // 输出最后一个单词的长度
return 0;
}