SQL(结构化查询语言)是操作关系型数据库的标准语言,核心可以分为几大类:数据查询 (DQL) 、数据操作 (DML) 、数据定义 (DDL) 、数据控制 (DCL),其中日常开发中最常用的是前两类。
一、基础查询语句(DQL - SELECT)
这是最核心、使用频率最高的语句,用于从数据库中查询数据。
1. 基础语法
sql
-- 查询指定列
SELECT 列名1, 列名2 FROM 表名;
-- 查询所有列(不推荐在生产环境使用*,效率低)
SELECT * FROM 表名;
-- 去重查询
SELECT DISTINCT 列名 FROM 表名;
-- 带条件查询(WHERE)
SELECT 列名 FROM 表名 WHERE 条件;
-- 排序(ORDER BY,ASC升序/ DESC降序,默认升序)
SELECT 列名 FROM 表名 ORDER BY 列名 DESC;
-- 限制结果行数(MySQL用LIMIT,Oracle用ROWNUM)
SELECT 列名 FROM 表名 LIMIT 10; -- 只查前10条2. 示例(以学生表student为例)
sql
-- 查所有学生的姓名和年龄
SELECT name, age FROM student;
-- 查年龄大于18的学生,按年龄降序排列,只取前5条
SELECT name, age FROM student WHERE age > 18 ORDER BY age DESC LIMIT 5;
-- 查所有不同的班级(去重)
SELECT DISTINCT class FROM student;二、数据操作语句(DML)
用于新增、修改、删除表中的数据。
1. 插入数据(INSERT)
sql
-- 插入指定列(列名和值要一一对应)
INSERT INTO 表名(列名1, 列名2) VALUES (值1, 值2);
-- 插入所有列(需按表的列顺序填写值)
INSERT INTO 表名 VALUES (值1, 值2, 值3);
-- 批量插入(推荐,比单条插入效率高)
INSERT INTO 表名(列名1, 列名2)
VALUES (值1, 值2), (值3, 值4), (值5, 值6);示例:
sql
-- 给学生表插入一条数据
INSERT INTO student(name, age, class) VALUES ('张三', 20, '计算机1班');
-- 批量插入3条
INSERT INTO student(name, age, class)
VALUES ('李四', 19, '数学2班'), ('王五', 21, '英语1班');2. 更新数据(UPDATE)
sql
-- 带条件更新(必须加WHERE,否则会更新全表!)
UPDATE 表名 SET 列名1=值1, 列名2=值2 WHERE 条件;示例:
sql
-- 将张三的年龄改为22
UPDATE student SET age=22 WHERE name='张三';3. 删除数据(DELETE)
sql
-- 带条件删除(必须加WHERE,否则会删除全表!)
DELETE FROM 表名 WHERE 条件;
-- 清空表(保留表结构,数据全部删除,不可恢复)
TRUNCATE TABLE 表名; -- 比DELETE效率高示例:
sql
-- 删除姓名为李四的学生
DELETE FROM student WHERE name='李四';三、数据定义语句(DDL)
用于创建、修改、删除数据库 / 表结构(日常开发中一般由 DBA 或架构师操作,新手谨慎使用)。
1. 创建表(CREATE TABLE)
sql
CREATE TABLE 表名 (
列名1 数据类型 约束,
列名2 数据类型 约束,
...
);示例:
sql
-- 创建学生表
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键,自增
name VARCHAR(50) NOT NULL, -- 姓名,非空
age INT, -- 年龄
class VARCHAR(50) -- 班级
);2. 修改表结构(ALTER TABLE)
sql
-- 添加列
ALTER TABLE 表名 ADD 列名 数据类型;
-- 修改列类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-- 删除列
ALTER TABLE 表名 DROP COLUMN 列名;3. 删除表(DROP TABLE)
sql
-- 删除表(表结构和数据全部删除,不可恢复)
DROP TABLE 表名;四、数据控制语言(DCL)
1、DCL 的核心应用场景
DCL 主要用于两类操作:
权限管理:授予(GRANT)或撤销(REVOKE)用户对数据库 / 表的操作权限(如查询、修改、删除)。
事务控制:管理事务的提交(COMMIT)、回滚(ROLLBACK)、保存点(SAVEPOINT),确保数据操作的原子性。
2、权限管理:GRANT & REVOKE
这是 DCL 最常用的部分,通常由数据库管理员(DBA)操作,普通开发人员很少直接使用,但了解其逻辑有助于理解数据库权限体系。
授予权限(GRANT)
核心语法:
sql
-- 给用户授予指定权限(针对表/数据库)
GRANT 权限类型 ON 数据库名.表名 TO '用户名'@'访问地址' [IDENTIFIED BY '密码'];
-- 授予多个权限
GRANT 权限1, 权限2 ON 数据库名.表名 TO '用户名'@'访问地址';
-- 授予所有权限(谨慎使用)
GRANT ALL PRIVILEGES ON 数据库名.* TO '用户名'@'访问地址';常用权限类型:
| 权限类型 | 作用 |
|---|---|
| SELECT | 允许查询表数据(DQL) |
| INSERT | 允许插入数据(DML) |
| UPDATE | 允许修改数据(DML) |
| DELETE | 允许删除数据(DML) |
| CREATE | 允许创建表 / 数据库(DDL) |
| DROP | 允许删除表 / 数据库(DDL) |
| ALTER | 允许修改表结构(DDL) |
| ALL PRIVILEGES | 所有权限 |
示例:
sql
-- 场景1:给用户test授予studentdb数据库中student表的查询和插入权限
GRANT SELECT, INSERT ON studentdb.student TO 'test'@'localhost' IDENTIFIED BY '123456';
-- 场景2:给用户admin授予studentdb数据库所有表的所有权限(仅本机访问)
GRANT ALL PRIVILEGES ON studentdb.* TO 'admin'@'localhost';
-- 场景3:允许用户test从任意地址访问(%代表所有地址,生产环境谨慎)
GRANT SELECT ON studentdb.student TO 'test'@'%';撤销权限(REVOKE)
核心语法:
sql
REVOKE 权限类型 ON 数据库名.表名 FROM '用户名'@'访问地址';示例:
sql
-- 撤销test用户对student表的插入权限
REVOKE INSERT ON studentdb.student FROM 'test'@'localhost';
-- 撤销admin用户的所有权限
REVOKE ALL PRIVILEGES ON studentdb.* FROM 'admin'@'localhost';注意点:
权限生效:部分数据库(如 MySQL)授予权限后需执行 FLUSH PRIVILEGES; 让权限立即生效;
访问地址:localhost 仅允许本机访问,% 允许任意地址(生产环境需限制为具体 IP);
最小权限原则:实际开发中应只授予用户 "够用" 的权限,避免过度授权(如普通查询用户只给 SELECT 权限)。
3、事务控制:COMMIT & ROLLBACK & SAVEPOINT
事务控制是 DCL 的另一核心,用于保证一组数据库操作要么全部成功,要么全部失败(原子性),常见于转账、订单创建等场景。
事务的基本概念
事务有 4 个特性(ACID):
原子性(Atomicity):操作要么全做,要么全不做;
一致性(Consistency):事务执行前后数据状态一致;
隔离性(Isolation):多个事务互不干扰;
持久性(Durability):事务提交后数据永久保存。
核心事务控制语句
(1)开启事务
不同数据库开启事务的语法略有差异:
sql
-- MySQL
START TRANSACTION; -- 或 BEGIN;
-- Oracle
SET TRANSACTION; -- 或直接执行DML语句自动开启(2)提交事务(COMMIT)
确认所有操作生效,数据永久保存:
sql
COMMIT;(3)回滚事务(ROLLBACK)
撤销当前事务的所有操作,恢复到事务开始前的状态:
sql
ROLLBACK;
-- 回滚到指定保存点(SAVEPOINT)
ROLLBACK TO 保存点名;(4)创建保存点(SAVEPOINT)
在事务中创建 "断点",可回滚到该断点(而非整个事务):
sql
SAVEPOINT 保存点名;示例:转账场景(经典事务控制)
假设有账户表account,数据如下:
| id | name | balance |
|---|---|---|
| 1 | 张三 | 1000 |
| 2 | 李四 | 1000 |
需求:张三给李四转 200 元,保证扣钱和加钱要么都成功,要么都失败。
sql
-- 1. 开启事务
START TRANSACTION;
-- 2. 执行操作
UPDATE account SET balance = balance - 200 WHERE name = '张三'; -- 张三扣200
UPDATE account SET balance = balance + 200 WHERE name = '李四'; -- 李四加200
-- 可选:创建保存点(如需部分回滚)
SAVEPOINT transfer_step;
-- 3. 验证操作(可选)
SELECT * FROM account;
-- 4. 确认生效(无异常则提交)
COMMIT;
-- 如果操作出错(如余额不足),回滚事务
-- ROLLBACK;
-- 或回滚到保存点:ROLLBACK TO transfer_step;注意点:
自动提交:MySQL 默认开启 "自动提交"(每条 DML 语句自动 COMMIT),开启事务后会暂时关闭自动提交;
回滚范围:只有 DML 语句(INSERT/UPDATE/DELETE)可回滚,DDL 语句(CREATE/DROP/ALTER)执行后会自动 COMMIT,无法回滚;
保存点:仅在当前事务内有效,事务提交 / 回滚后失效。
补:连接云服务器上的mysql的流程
首先连接到云服务器中,在云服务器上登录用户,使用 root 用户(或具有管理员权限的用户)登录 MySQL,执行命令:
bash
mysql -u root -p输入 MySQL root 密码后进入命令行界面。
下一步就是创建一个用户
创建用户 + 授权的基础语法:
sql
-- 1. 创建用户(指定用户名、访问地址、密码)
CREATE USER '用户名'@'访问地址' IDENTIFIED BY '密码';
-- 2. 授予权限(指定权限、数据库/表、用户)
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'访问地址';
-- 3. 刷新权限(使授权生效)
FLUSH PRIVILEGES;示例:
允许远程访问(本地 / 其他服务器连接)
适合本地开发、其他服务器连接云服务器 MySQL 的场景:
sql
-- 创建用户(允许任意地址访问,%代表所有IP)
CREATE USER 'sql_user'@'%' IDENTIFIED BY 'YourStrongPassword123!';
-- 仅授予查询+插入+修改权限(最小权限原则,避免删除风险)
GRANT SELECT, INSERT, UPDATE ON test_db.* TO 'sql_user'@'%';
-- 刷新权限
FLUSH PRIVILEGES;提示:生产环境不建议用%(任意 IP),应指定具体 IP,比如:
sql
CREATE USER 'sql_user'@'192.168.1.100' IDENTIFIED BY 'YourStrongPassword123!'; -- 仅允许192.168.1.100访问验证用户权限:
sql
-- 查看用户权限
SHOW GRANTS FOR 'sql_user'@'%';
-- 测试登录(服务器本机)
mysql -u sql_user -p
-- 远程测试(本地终端)
mysql -h 云服务器IP -u sql_user -p修改/删除用户
sql
-- 修改用户密码
ALTER USER 'sql_user'@'%' IDENTIFIED BY 'NewStrongPassword456!';
-- 撤销权限
REVOKE DELETE ON test_db.* FROM 'sql_user'@'%';
-- 删除用户
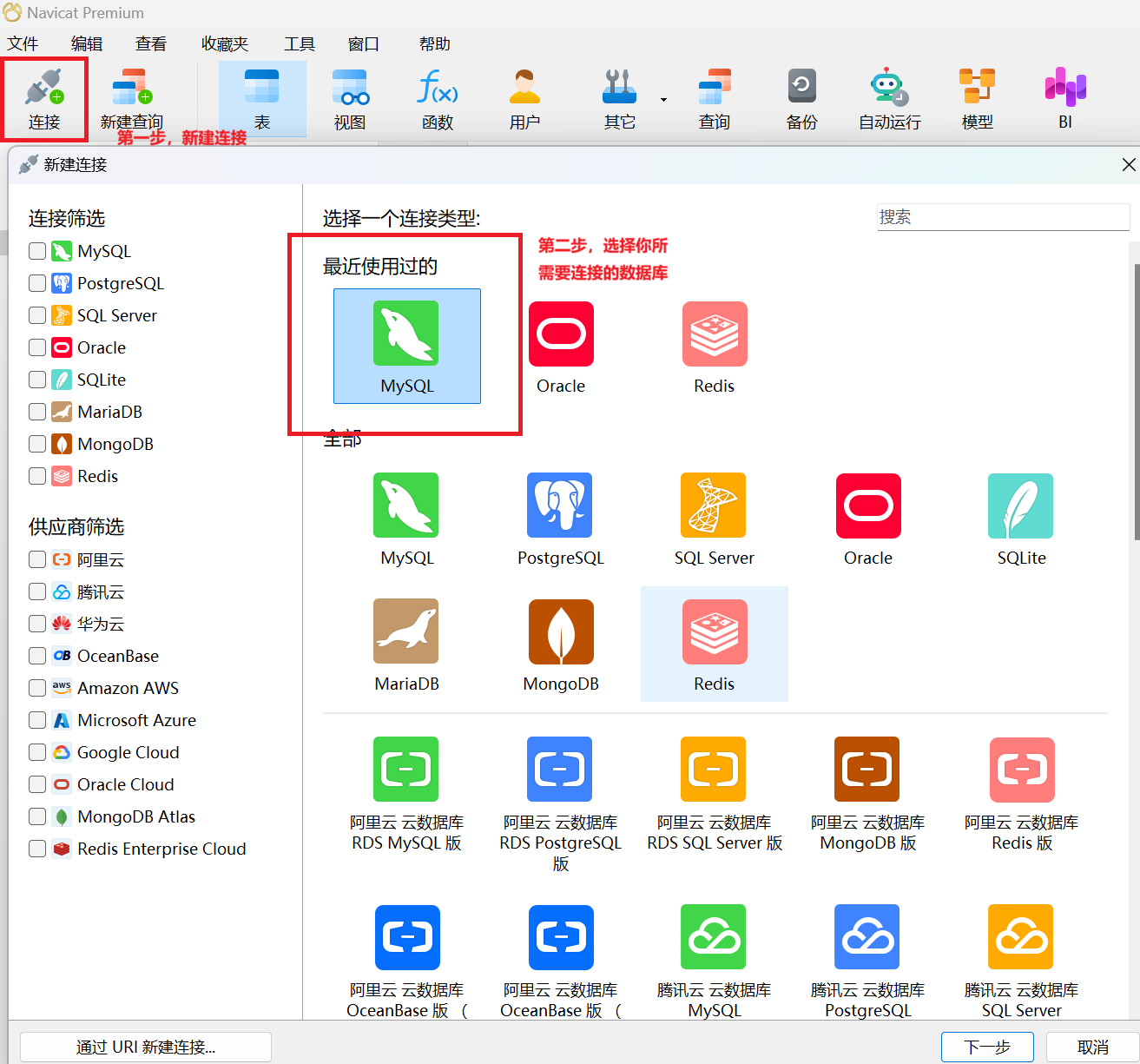
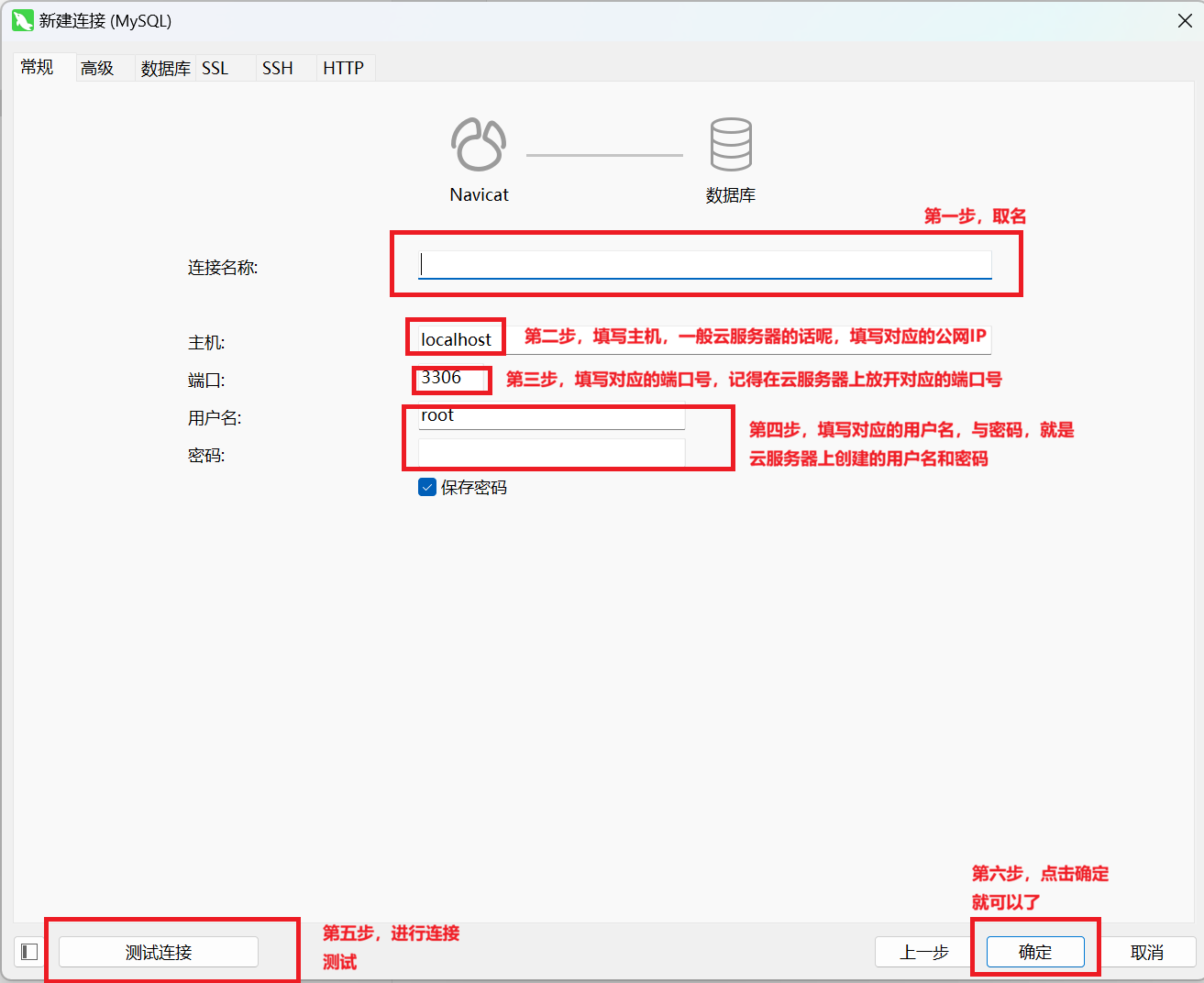
DROP USER 'sql_user'@'%';用户创建好了之后,在本地的客户端上运行mysql的客户端,新建连接,连接远程数据库,如下图所示
我使用的是Navicat Premium 17.0.8
五、常用进阶查询
1. 聚合函数
用于统计计算,常见的有COUNT()(计数)、SUM()(求和)、AVG()(平均值)、MAX()(最大值)、MIN()(最小值)。
sql
-- 统计学生总数
SELECT COUNT(*) FROM student;
-- 计算学生的平均年龄
SELECT AVG(age) FROM student;
-- 按班级分组,统计每个班级的学生数
SELECT class, COUNT(*) FROM student GROUP BY class;2. 多表关联查询(JOIN)
用于查询多个表中的关联数据,常见的有INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)。
sql
-- 内连接:只查两张表中匹配的数据
SELECT s.name, c.course_name
FROM student s
INNER JOIN score c ON s.id = c.student_id;
-- 左连接:查左表所有数据,右表匹配不上的显示NULL
SELECT s.name, c.course_name
FROM student s
LEFT JOIN score c ON s.id = c.student_id;3.去重
DISTINCT 是 SQL 内置的关键字(非函数),用于从查询结果中剔除重复的行 / 列值,是最基础也最常用的去重方式。
sql
-- 单列去重
SELECT DISTINCT 列名 FROM 表名;
-- 多列去重(多列值完全相同才会被判定为重复)
SELECT DISTINCT 列名1, 列名2 FROM 表名;
-- 结合WHERE条件去重
SELECT DISTINCT 列名 FROM 表名 WHERE 条件;4.分组
GROUP BY是 SQL 中用于数据分组聚合 的核心关键字,它的作用是将表中的数据按照指定列(或多个列)的相同值划分为多个 "组",然后对每个组单独使用聚合函数(如COUNT/SUM/AVG)进行统计计算,是实现分类统计的必备工具。
语法:
sql
SELECT 分组列1, 分组列2, 聚合函数(统计列)
FROM 表名
[WHERE 筛选条件] -- 分组前筛选数据
GROUP BY 分组列1, 分组列2 -- 分组列必须和SELECT中非聚合列一一对应
[HAVING 分组后筛选条件]; -- 分组后筛选组示例:
假设 student 表数据如下:
| id | name | age | class | score |
|---|---|---|---|---|
| 1 | 张三 | 20 | 计算机 1 班 | 85 |
| 2 | 李四 | 19 | 计算机 1 班 | 90 |
| 3 | 王五 | 21 | 数学 2 班 | 88 |
| 4 | 赵六 | 20 | 数学 2 班 | 92 |
| 5 | 钱七 | 22 | 计算机 1 班 | 80 |
sql
-- 场景1:按班级分组,统计每个班级的学生人数
SELECT class, COUNT(*) AS student_count
FROM student
GROUP BY class;
-- 输出结果:
-- class | student_count
-- 计算机1班 | 3
-- 数学2班 | 2
-- 场景2:按班级分组,计算每个班级的平均分
SELECT class, AVG(score) AS avg_score
FROM student
GROUP BY class;
-- 输出结果:
-- class | avg_score
-- 计算机1班 | 85
-- 数学2班 | 90总结
核心高频语句 :SELECT(查询)、INSERT(新增)、UPDATE(修改)、DELETE(删除)是日常开发中最常用的 4 个语句,其中UPDATE和DELETE必须加WHERE条件,避免误操作。
查询进阶 :WHERE(条件)、ORDER BY(排序)、GROUP BY(分组)、JOIN(多表关联)是实现复杂查询的核心,聚合函数(COUNT/SUM等)常用于数据统计。
DDL 语句谨慎用 :CREATE/ALTER/DROP涉及表结构修改,新手操作前务必备份数据,避免不可逆损失。