输入输出长度不匹配的模型输出
翻译任务(如 "我爱中国" 对应输出 "I love China",输入(4 个汉字)与输出(3 个英文单词)长度不同)。
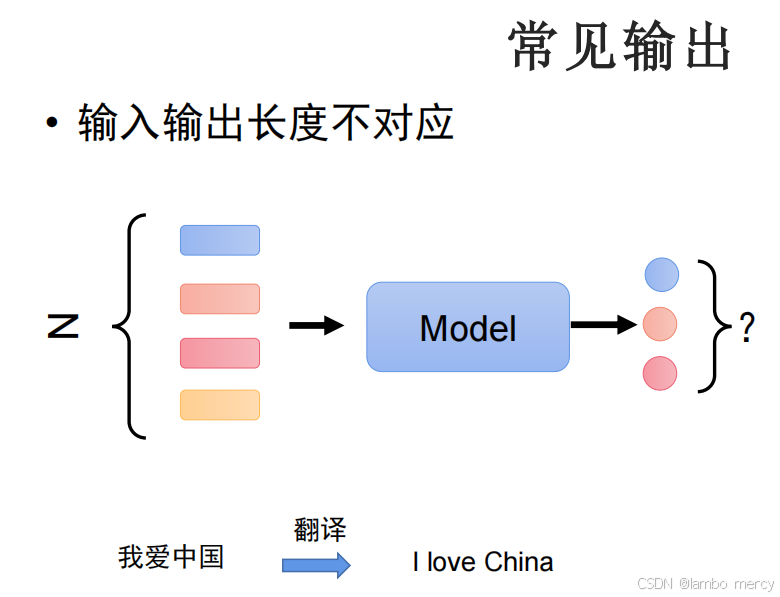
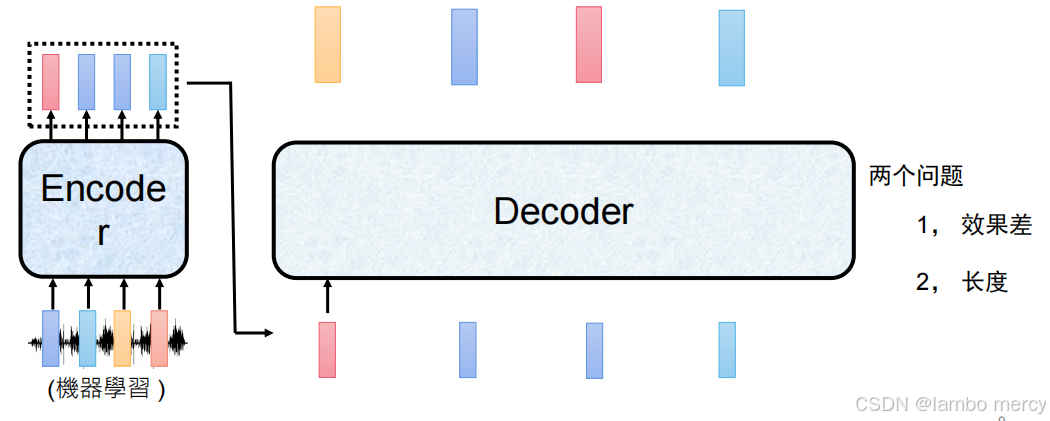
模型输出的三类典型场景
逐元素标签匹配
- 逻辑:输入的每个向量对应一个输出标签,输入、输出长度均为 N。
- 适用任务:序列标注类任务(如词性标注,每个单词对应一个词性标签)。
序列级单一标签
- 逻辑:整个输入序列对应一个输出标签,输入长度为 N,输出长度为 1。
- 适用任务:序列分类类任务(如文本情感判断,一段文本对应 "正面"/"负面" 等单一标签)。
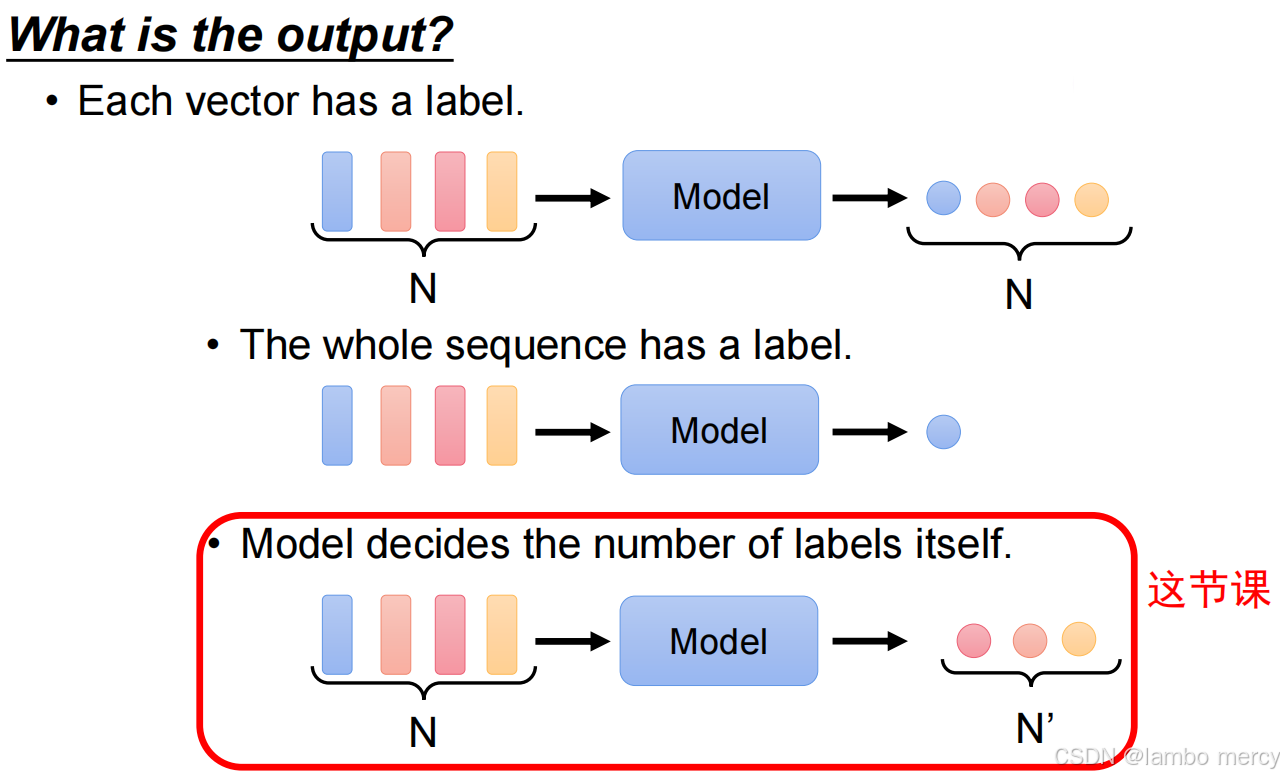
模型自主决定输出数量
- 逻辑:模型根据输入自主生成输出标签数量(记为 N'),N' 与输入长度 N 不相等。
- 适用任务:该课程聚焦的任务类型(如文本生成、摘要,输入长文本后输出长度自主决定的精简内容)。
序列到序列(Seq2seq)生成模型
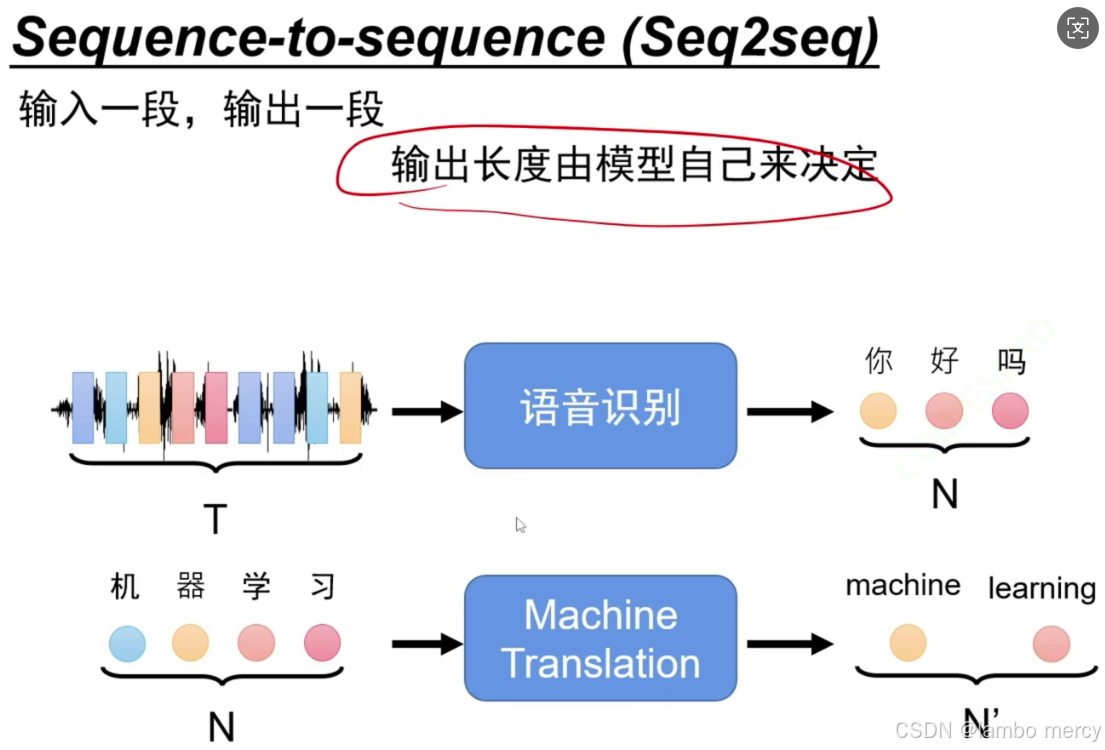
序列到序列(Seq2seq)是一种用于处理 "输入一段序列、输出一段序列" 任务的模型架构,核心特点是输出序列的长度由模型自主决定,而非与输入长度强绑定。
-
典型应用案例
- 语音识别:输入为长度为 T 的语音信号序列,模型自主生成长度为 N 的文本序列(如输入语音信号,输出 "你好吗"),T 与 N 长度不固定。
- 机器翻译:输入为长度为 N 的中文文本序列(如 "机器学习"),模型自主生成长度为 N' 的英文文本序列(如 "machine learning"),N 与 N' 长度不固定。
Seq2seq 广泛应用于文本摘要、对话生成等任务 ------ 这类任务均需要模型根据输入内容,自主控制输出序列的长度以匹配任务需求。
Transformer 架构解析
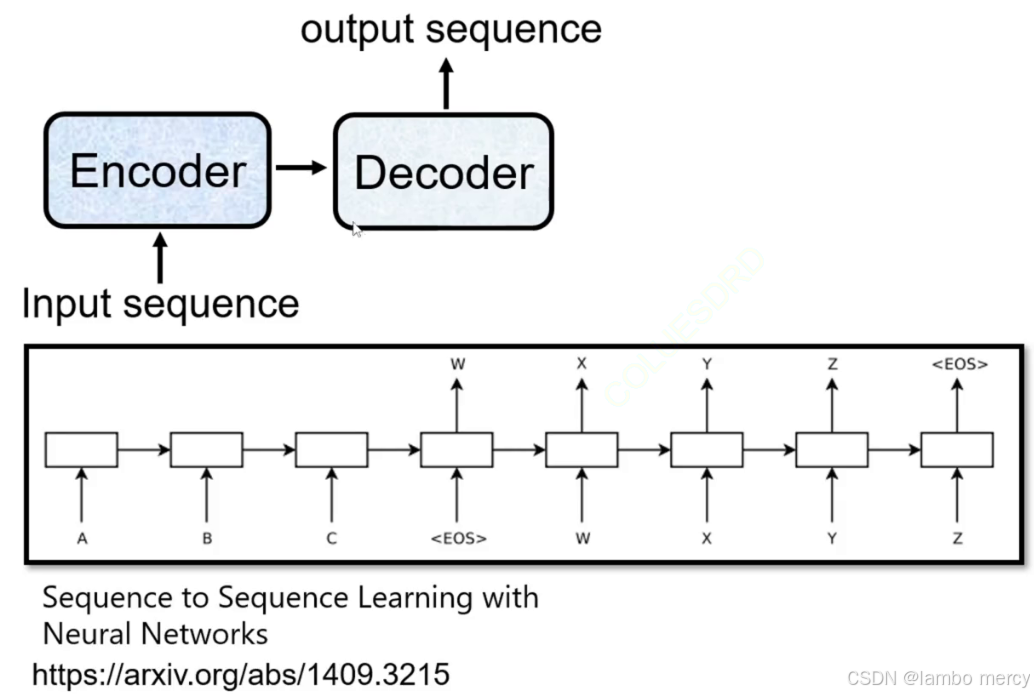
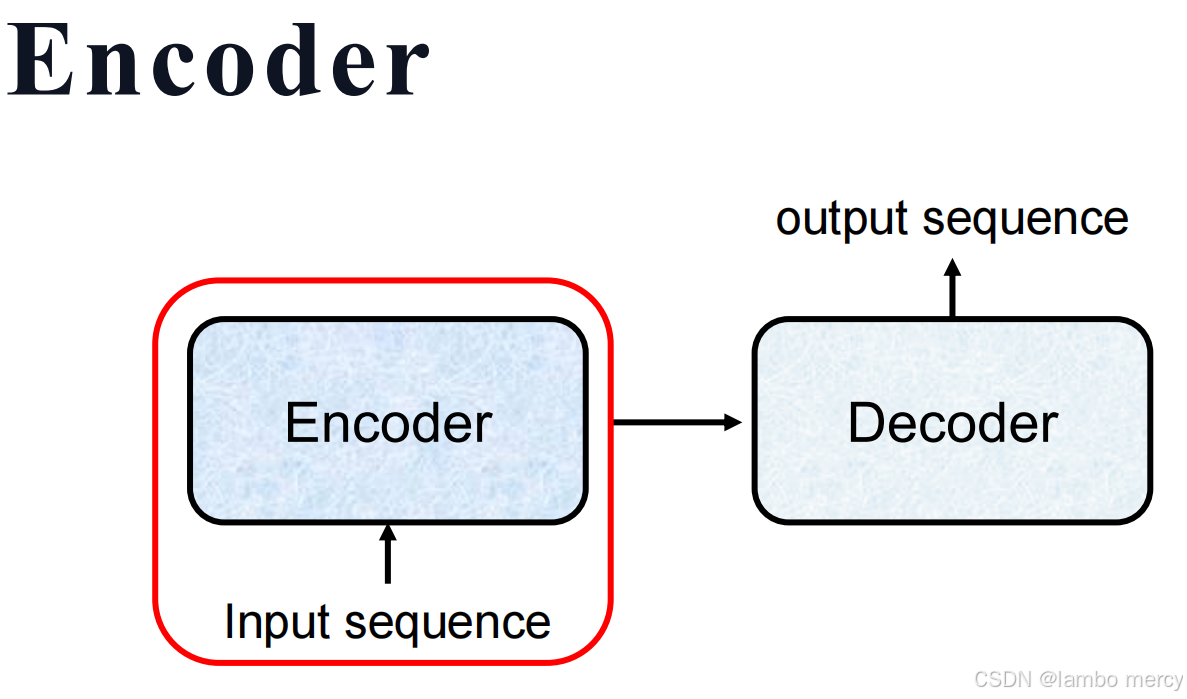
遵循 "编码器(Encoder)- 解码器(Decoder)" 范式:
- 输入序列(Input sequence)先传入 Encoder,由 Encoder 将其编码为特征表示;
- Encoder 的输出传递给 Decoder,最终由 Decoder 生成输出序列(output sequence)。
底层实现逻辑
-
该架构的 Encoder/Decoder 基于循环结构(图中链式模块,通常为 LSTM/GRU 等循环神经网络单元),特点是:
- 需按序列顺序逐元素处理输入(如输入序列的 A、B、C 需依次传入循环单元);
- 以
<EOS>(End of Sequence,序列结束标志)作为序列的边界: - 输入序列处理到
<EOS>时,Encoder 完成编码; - 输出序列生成到
<EOS>时,Decoder 结束生成(图中输出序列包含 W、X、Y、Z,最终以<EOS>收尾)。
-
架构特点与局限
- 适用场景:解决输入、输出长度不固定的序列转换任务(如翻译、文本生成);
- 局限:因循环结构的顺序性,存在长序列信息衰减、并行计算效率低的问题,后续被 Transformer 架构(基于注意力机制)优化。
Seq2seq 生成方式及现存问题
- 效果差:Encoder 需将输入序列压缩为特征表示,长序列的关键信息易丢失,导致 Decoder 生成的内容与输入语义的匹配度降低;
- 长度问题:Decoder 生成的输出序列长度难以稳定控制,无法精准适配不同任务对输出长度的需求。
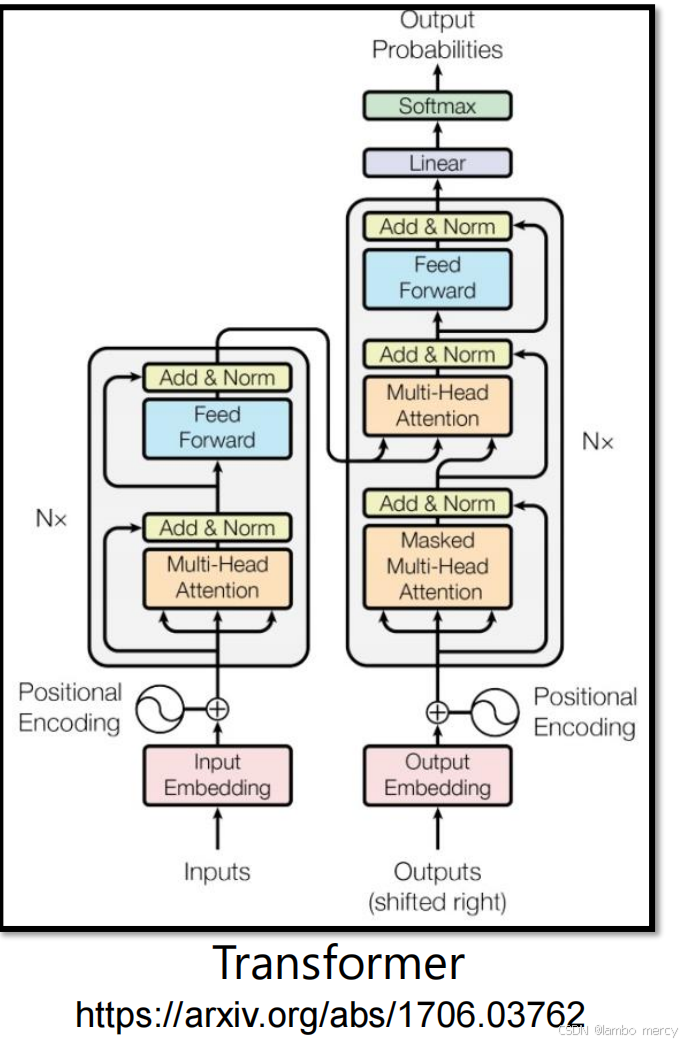
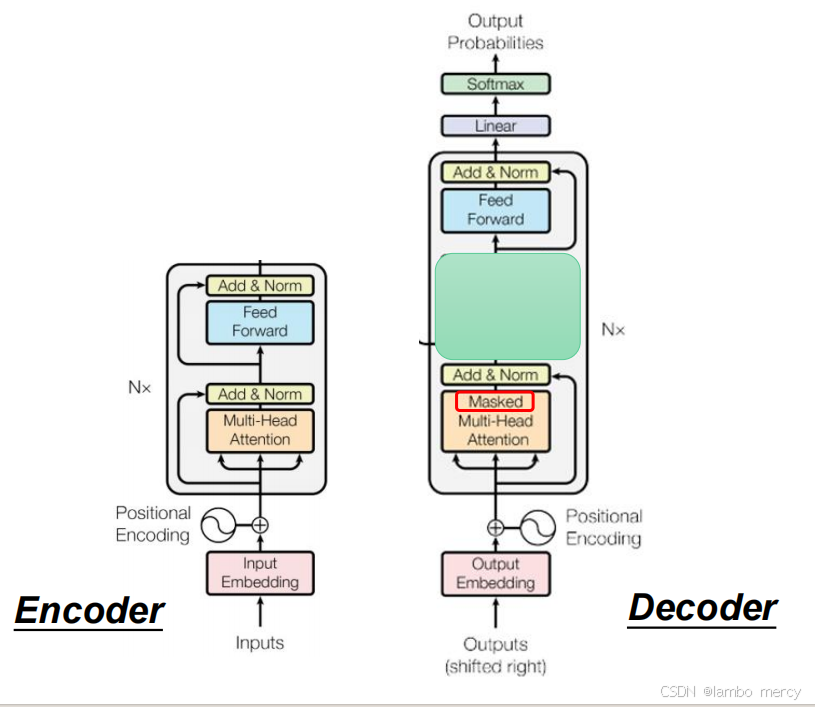
Transformer 是基于 "编码器(Encoder)- 解码器(Decoder)" 的序列到序列架构,核心以注意力机制替代循环结构,提升并行性与长序列建模能力,其结构可分为三部分:
- 输入
- 编码器输入 :
- Input Embedding:将输入序列的 token 转换为固定维度的向量;
- Positional Encoding:注入序列的位置信息(因 Transformer 无循环结构,需显式编码位置顺序),与 Embedding 结果相加作为编码器的输入。
- 解码器输入 :
- Output Embedding:将已生成的输出序列 token 转换为向量;
- Positional Encoding:同样注入位置信息,且输入需 "右移"(训练时避免解码阶段获取后续未生成的 token)。
- 编码器(Encoder):N 层子模块堆叠
每层子模块包含以下组件(均搭配残差连接 + 层归一化 "Add & Norm"):
- 多头注意力(Multi-Head Attention):同时关注输入序列的不同位置信息,捕捉全局依赖;
- 前馈网络(Feed Forward):对多头注意力的输出做独立的线性变换,增强特征表达能力。
- 解码器(Decoder):N 层子模块堆叠
每层子模块包含以下组件(均搭配残差连接 + 层归一化 "Add & Norm"):
- 掩码多头注意力(Masked Multi-Head Attention):防止解码时关注后续未生成的 token,保证生成的自回归性;
- 多头注意力:以编码器的输出为 "键 / 值"、解码器的中间输出为 "查询",实现对输入序列的针对性关注;
- 前馈网络:与编码器的前馈网络功能一致,增强特征表达。
- 输出层
- Linear 层:将解码器的输出映射到目标词汇表的维度;
- Softmax 层:将输出转换为各 token 的概率分布,得到最终的输出序列。
架构价值:Transformer 解决了传统循环式 Seq2seq 的 "长序列信息衰减""并行效率低" 等问题,是现代自然语言处理任务(如翻译、文本生成)及大语言模型(如 GPT、BERT)的核心基础架构。
编码器encoder
Transformer 编码器采用与 BERT 完全一致的网络架构,这是其实现上下文语义理解的基础。
- 输入:接收序列形式的输入(图中为
x¹-x⁴,代表序列中的不同 token); - 输出:为每个输入 token 生成对应的特征表示(图中为
h¹-h⁴),实现输入序列的语义编码。
编码器的单层组件(各模块后均搭配残差连接 + 层归一化 "Add & Norm"):
- 输入嵌入(Input Embedding):将输入 token 转换为向量表示;
- 位置编码(Positional Encoding):注入序列的位置信息,弥补 Transformer 无循环结构的顺序信息缺失;
- 多头注意力(Multi-Head Attention):捕捉输入序列的全局依赖关系;
- 前馈网络(Feed Forward):增强特征的非线性表达能力。
解码器Decoder
"将 Encoder 提取的特征直接当作 Decoder 输入" 的做法,会直接导致图中提到的 "效果差""长度失控" 两个核心问题,原因如下:
- 效果差:丢失生成序列的上下文逻辑
Encoder 的输出是输入序列的语义特征编码 (比如图中 "機器學習" 对应的语音,Encoder 输出的是该语音的语义特征序列),但 Decoder 的核心任务是生成连贯的目标序列:
- 若直接用 Encoder 特征当 Decoder 输入:Decoder 失去了 "已生成 token 的上下文依赖",只能基于输入的语义特征生成,无法保证序列的逻辑连贯性(比如生成的 "機、器、學、習" 可能语义脱节),最终效果大幅下降。
- 长度失控:生成长度与需求不匹配
Encoder 的输出长度是与输入序列长度绑定的(比如输入语音对应 4 个 token,Encoder 输出 4 个特征),但 Decoder 要生成的目标序列长度:
- 可能与输入长度不一致(比如翻译任务中,英文输入长度≠中文输出长度);
- 若直接用 Encoder 特征当输入:Decoder 的输入长度固定为 Encoder 的输出长度,只能生成与输入长度相同的序列,无法灵活匹配目标序列的实际长度需求,出现 "长度不符合预期" 的问题。
所以我们需要自回归生成:
自回归生成方式
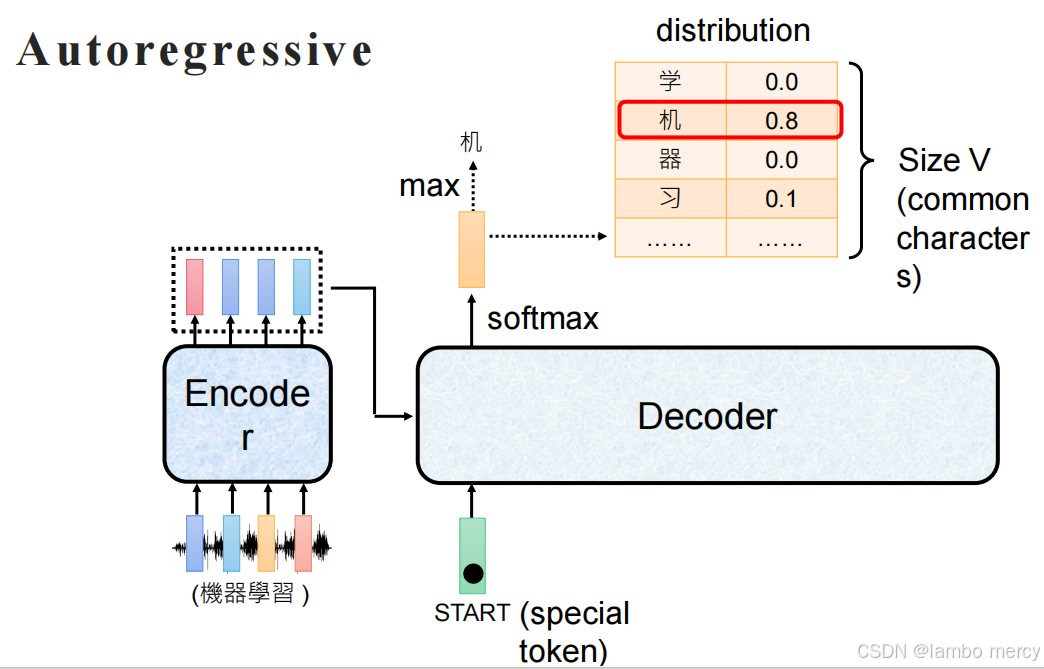
生成起点:Decoder 以特殊 token "START" 作为初始输入,启动序列生成过程。
核心机制:逐 token 自回归生成
- 概率分布输出:Decoder 每一步会输出对应词汇表(Size V,包含常用字符)的概率分布(如图中 "机" 的概率为 0.8);
- token 选取:通过 "max" 操作选取当前概率最大的 token(此处为 "机")作为当前生成结果;
- 循环生成:该生成的 token 会作为 Decoder 下一步的输入,重复 "输出概率分布 - 选 token" 的流程,直至生成结束 token,完成序列生成。
以 "前一步生成结果作为后一步输入" 的逻辑保证序列生成的顺序性,但因逐 token 生成的特性,存在生成效率较低(无法并行生成多个 token)的局限。
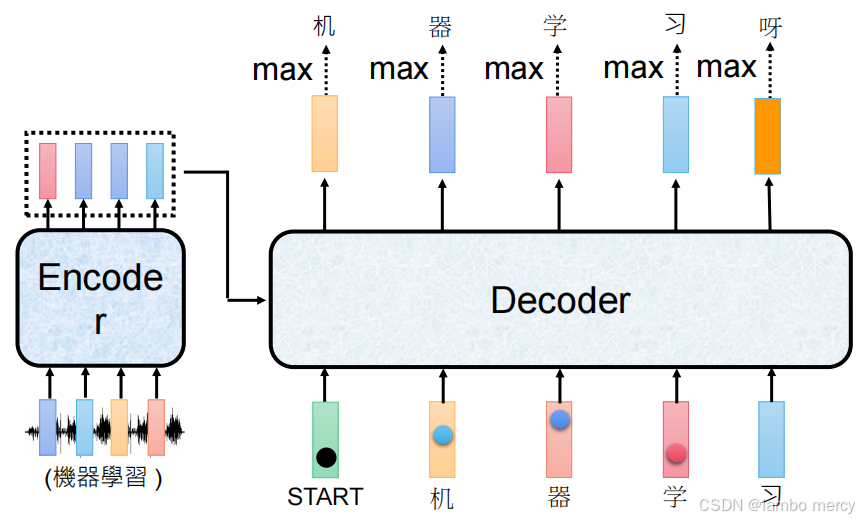
输入处理:Encoder 接收 "机器学习" 对应的语音信号序列,将其编码为特征表示后传递给 Decoder。
逐步自回归生成:
- 步骤 1:以特殊 token "START" 为初始输入,通过 "max" 操作从输出概率分布中选取 "机";
- 步骤 2:以 "机" 为输入,生成 "器";
- 步骤 3:以 "器" 为输入,生成 "学";
- 步骤 4:以 "学" 为输入,生成 "习";
- 步骤 5:以 "习" 为输入,生成 "呀"。(示例中出现的语义偏离情况)。
潜在局限:
- 采用 "贪心式"(选当前概率最大 token)的生成策略,易陷入局部最优,可能出现生成内容偏离原输入语义的情况(如图中最终生成的 "呀" 与目标内容 "机器学习" 不匹配)。
Decoder 的结构
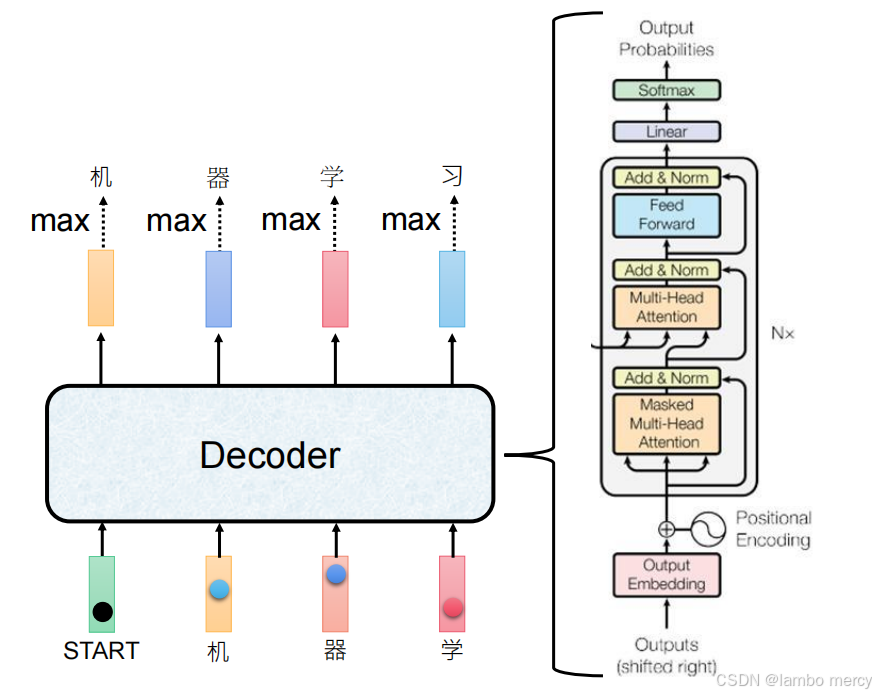
其结构通过多层模块支撑自回归生成的合理性与顺序性:
输入处理:
- Output Embedding:将已生成的 token 转换为向量表示;
- Positional Encoding:注入位置信息,弥补无循环结构的顺序信息缺失;
- 输入 "右移(shifted right)":训练阶段避免解码时获取后续未生成的 token,匹配自回归的生成逻辑。
多层子模块(N 层堆叠):
- Masked Multi-Head Attention:防止解码时关注后续 token,保障自回归生成的顺序性;
- Multi-Head Attention:结合 Encoder 的输出,捕捉输入序列与当前生成内容的语义关联;
- Feed Forward:增强特征的非线性表达能力;
- 各模块后搭配 "Add & Norm(残差连接 + 层归一化)":稳定训练过程,保留关键特征信息。
输出层:
- 通过 Linear 层映射到词汇表维度,经 Softmax 输出 token 的概率分布,为 "max" 操作(选取当前概率最高的 token)提供依据。
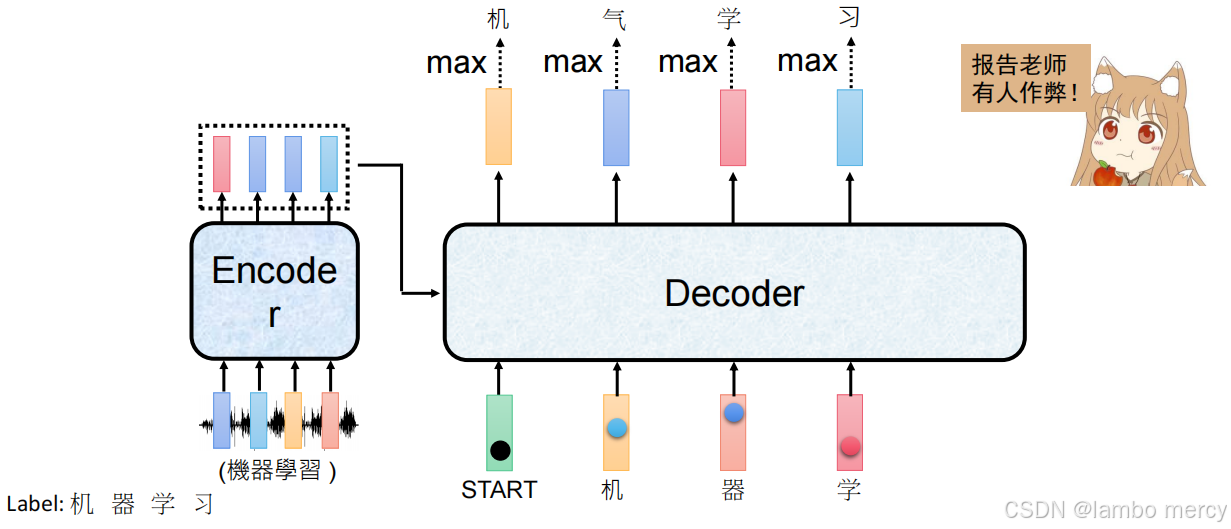
顺序链式依赖问题
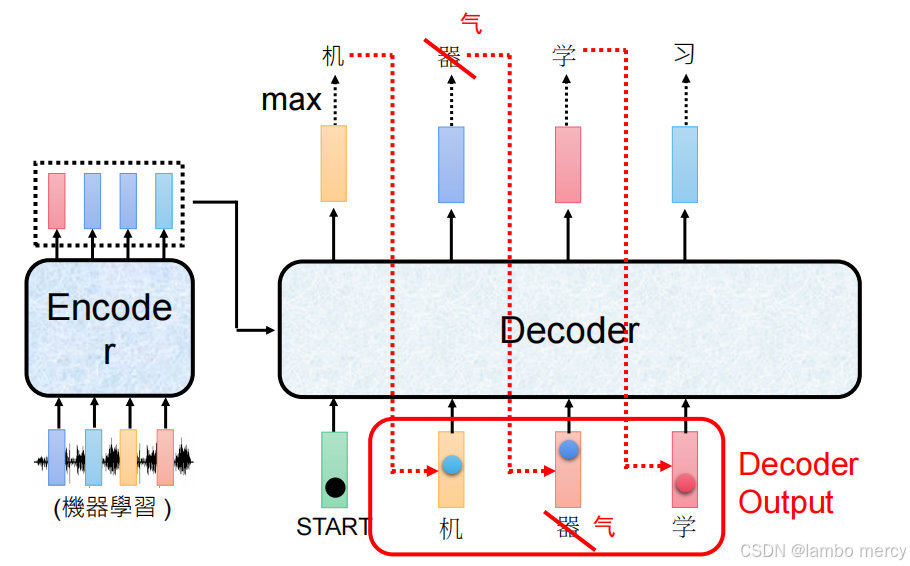
自回归生成的核心逻辑是 "前一步的输出作为后一步的输入",每一步的生成结果都严格依赖上一步的输出,形成顺序链式依赖关系。
错误传递过程
- 第一步:Decoder 基于 "START" 生成 "机"(与目标 Label 一致,正确);
- 第二步:本该基于 "机" 生成 "器",但错误生成 "气";
- 后续影响:由于自回归的依赖逻辑,第三步及之后的生成会以错误的 "气" 作为输入,而非正确的 "器",导致后续生成完全偏离目标序列(原本目标为 "机器学习")。
自回归的顺序链式依赖,使得某一步的错误会被传递到后续所有步骤,形成错误的累积放大,最终导致整个生成序列偏离预期目标。(一错全错)
Teacher Forcing(教师强制)
自回归(AR)模型的推理阶段必须逐 token 串行生成(前一步输出是后一步输入),但如果训练阶段也串行,效率会极低(比如生成 100 个 token 的序列,就要串行计算 100 次)。
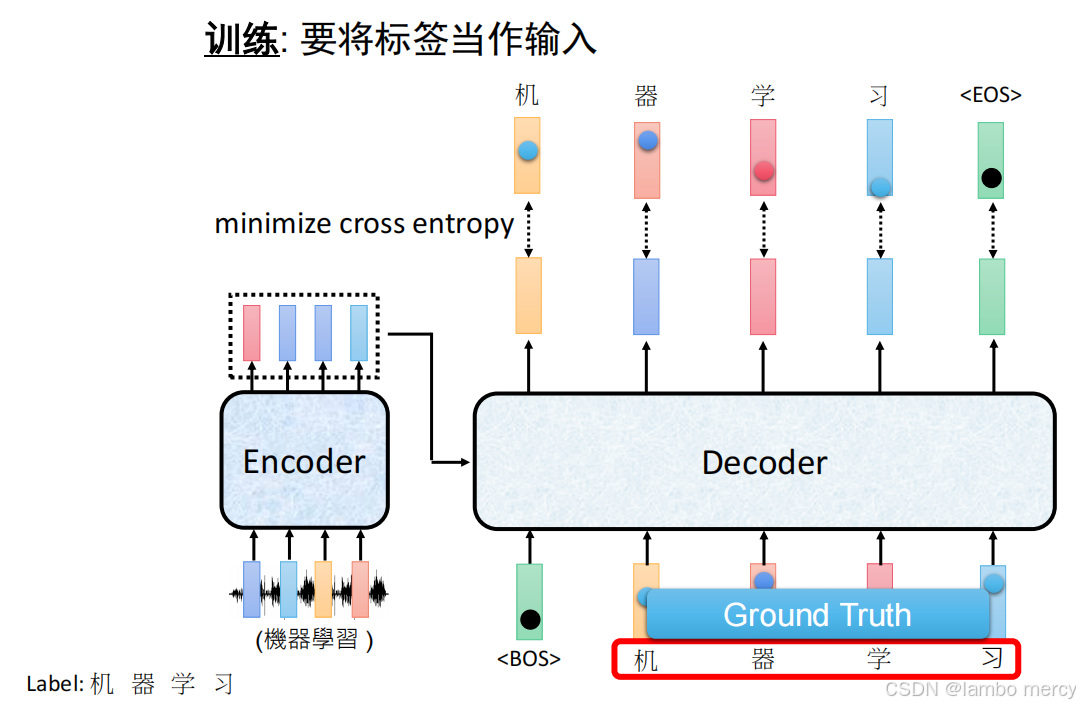
Teacher Forcing 的核心目标是:训练时用 "完整目标序列" 做输入,实现全序列并行计算(一次算完所有 token 的输出);
- Teacher Forcing(教师强制)
- 训练时,Decoder 的输入不是 "模型自己生成的 token",而是人工标注的完整目标序列(右移一位);
- 右移的目的:让 Decoder 的第
i步输入对应第i步的目标输出(比如生成 "机器学习",目标序列是[机, 器, 学, 习],Decoder 输入是[START, 机, 器, 学]);- 作用:避免训练阶段依赖模型自身生成的错误 token(推理阶段才会依赖),同时为 "并行计算" 提供完整的输入序列。
但是会出现一个问题,如果把人工标注的完整目标序列作为输入,模型会偷懒偷看答案,不推理,直接把下个词的输入作为输出。
怎么办呢?
"Masked"(掩码)
MASK 的位置
- 作用于 Transformer Decoder 的 "Masked Multi-Head Attention" 模块中。
核心功能
- 防止 Decoder 在生成当前 token 时,获取后续未生成的 token 信息 (即 "未来信息泄露"),保证序列生成的自回归顺序性(只能基于已生成的 token 生成下一个 token)。
具体机制
- 在注意力计算时,MASK 会对 "当前 token 之后的位置" 施加掩码(通常通过下三角矩阵实现:将后续位置的注意力权重设为极小值,如负无穷)。
- 经过 Softmax 层后,这些被掩码的位置权重会趋近于 0,使得模型仅能关注 "当前及之前已生成的 token",无法利用后续未生成的内容。
必要性
- Decoder 的任务是逐 token 自回归生成序列(如翻译、文本生成),若允许模型关注后续 token,会破坏生成的顺序逻辑(相当于 "提前知道了答案"),导致训练与实际生成的逻辑不一致,最终影响生成结果的合理性与准确性。
(对比:Encoder 的 Multi-Head Attention 无此 MASK,因为 Encoder 需完整关注输入序列的所有位置,无需限制注意力范围)
Teacher Forcing + Mask 的核心目标是:
- 训练时用 "完整目标序列" 做输入,实现全序列并行计算(一次算完所有 token 的输出);
- 同时通过 Mask 屏蔽 "未来信息",保证训练逻辑和自回归推理逻辑一致(模型只能看到当前及之前的 token)。
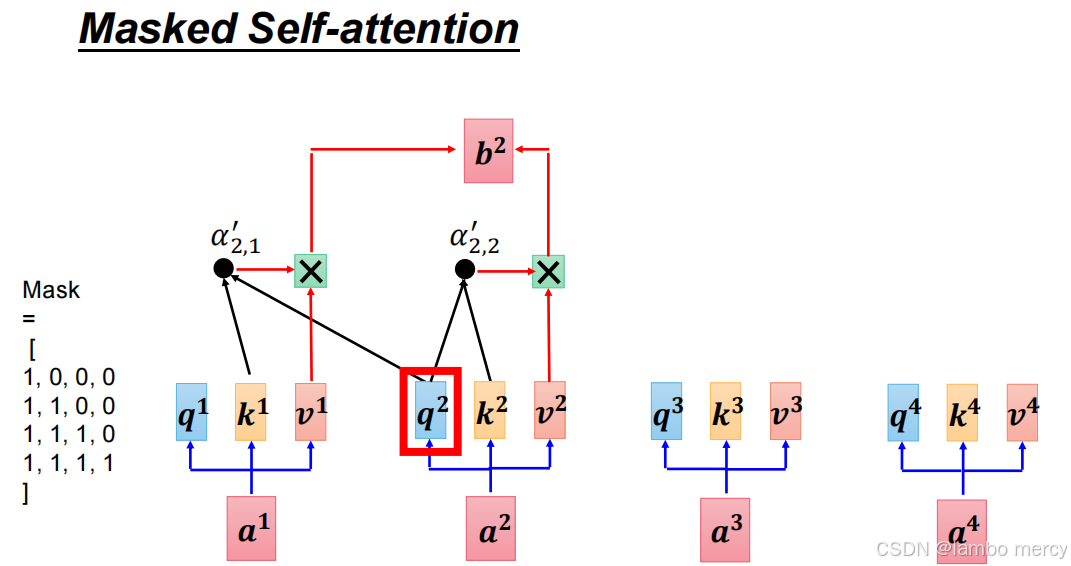
在 Self-attention 基础上增加掩码约束MASK:
- 核心修改:限制每个输入元素的注意力范围,仅允许关注 "当前及之前的元素"(如
a¹只能关注a¹,a²只能关注a¹、a²);- 实现方式:通过掩码矩阵屏蔽 "后续元素" 的注意力连接(图中原本的全连接会被截断);
- 作用:避免自回归生成场景下的 "未来信息泄露",保证序列生成的顺序性(比如文本生成时,生成当前 token 不能依赖后续未生成的 token)。
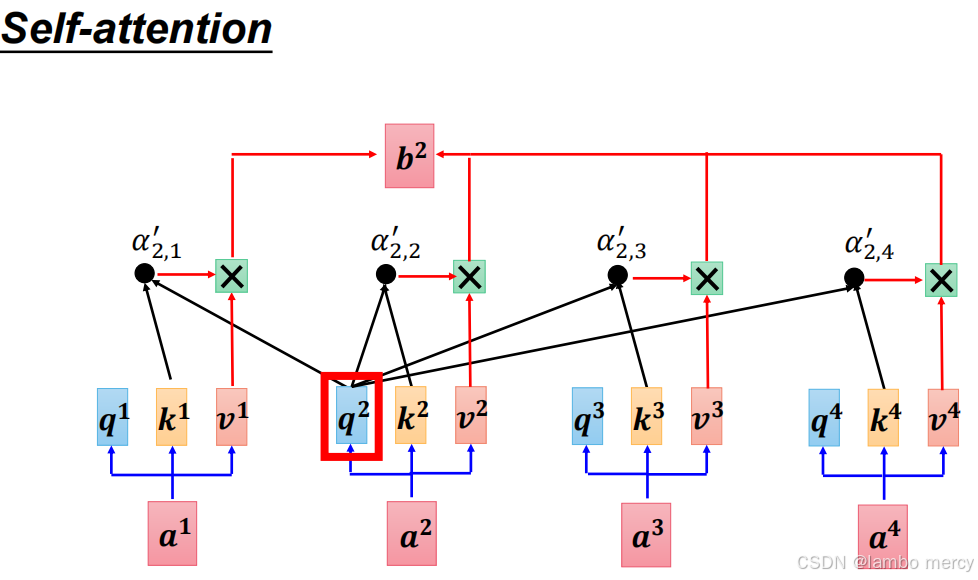
Self-attention: 计算第 2 个位置的输出
b²时,第 2 个位置的查询向量q²会与 ** 所有位置的键向量(k¹、k²、k³、k⁴) 计算注意力权重(α'₂,₁、α'₂,₂、α'₂,₃、α'₂,₄),最终b²是所有位置的值向量(v¹~v⁴)的加权组合。简言之:无范围限制,能关注整个序列的所有元素。
Masked Self-attention:
计算第 2 个位置的输出
b²时,通过掩码矩阵 限制了注意力范围:图左侧的掩码矩阵(第二行是[1,1,0,0])规定:第 2 个位置仅能关注前 2 个位置(a¹、a²) ,无法关注后续位置(a³、a⁴)。反映在图中:q²仅与k¹、k²计算有效注意力权重(α'₂,₁、α'₂,₂),k³、k⁴对应的权重被屏蔽(图中无连接),最终b²仅是v¹、v²的加权组合。
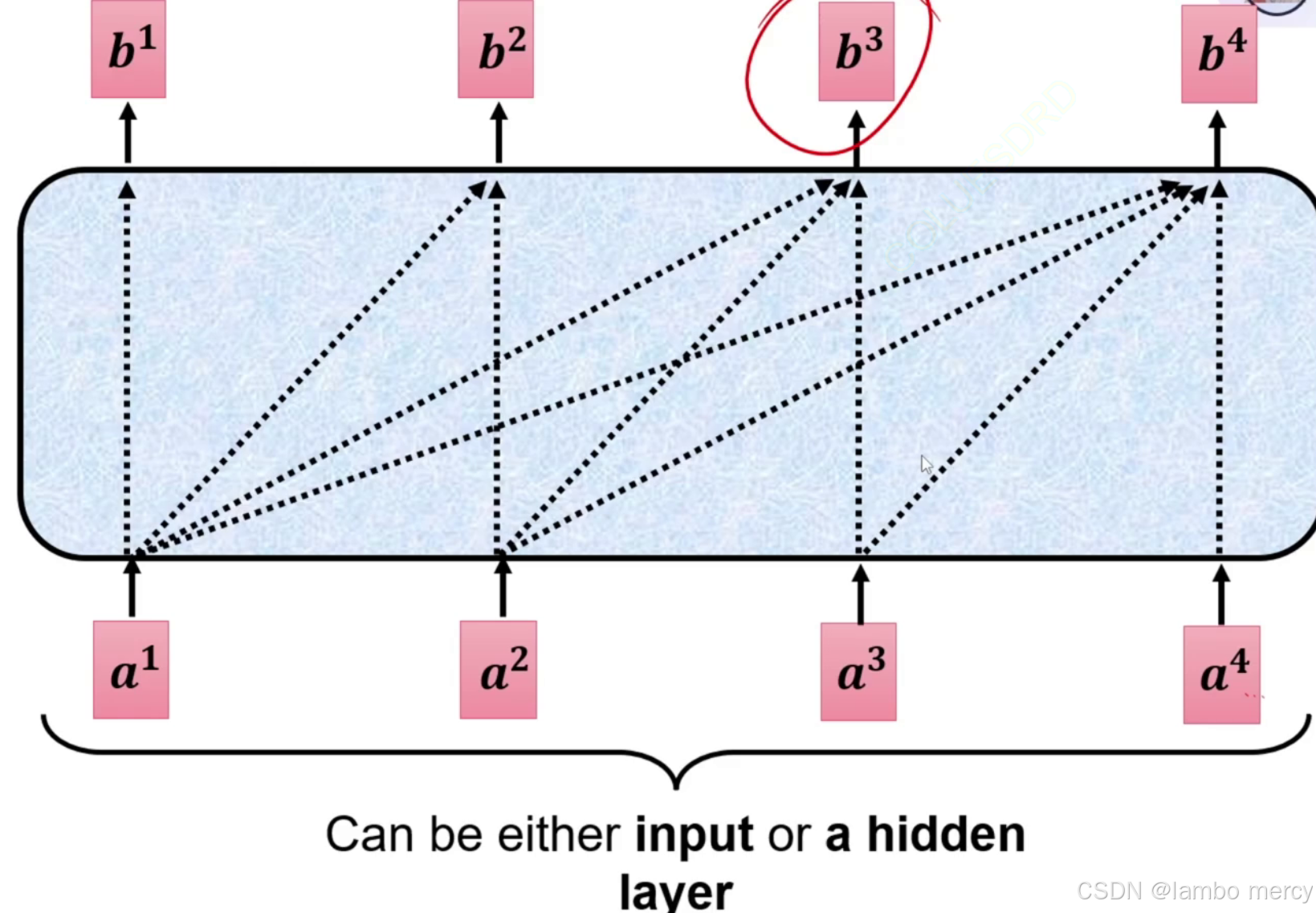
Self-attention :适用于需要全局上下文信息的场景(如 Transformer 的 Encoder),比如文本理解任务(需同时捕捉 "机器学习" 中 "机" 与 "习" 的关联),无顺序生成的约束。
Masked Self-attention :适用于自回归生成场景(如 Transformer 的 Decoder),比如文本生成任务(生成 "机" 后,不能提前依赖未生成的 "学、习"),通过掩码防止 "未来信息泄露",保证生成的顺序性。
"输出长度控制" 问题
自回归生成的核心痛点之一:无法自主控制输出长度
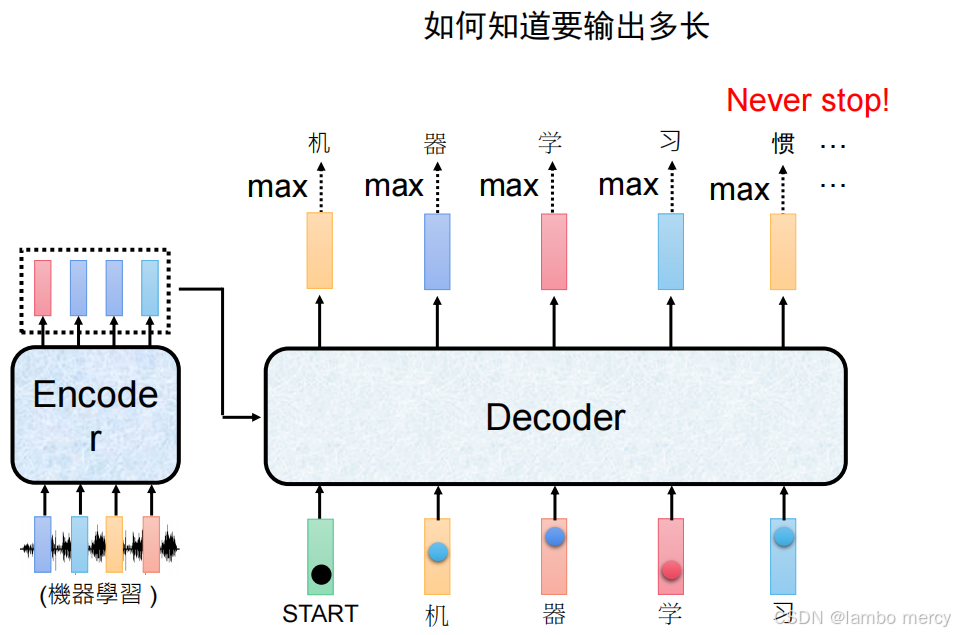
- 自回归生成的逻辑是 "前一步输出作为后一步输入",但模型本身没有 "停止生成" 的内置机制:
- 图中 Decoder 已生成目标序列 "机器学习",但仍继续生成无关 token(如 "惯"),出现 "Never stop!" 的无限生成风险;
- 核心疑问是 "如何知道要输出多长"------ 自回归生成默认无法自主判断 "目标序列已完成"。
- 问题的本质原因
自回归生成的逐 token 链式依赖逻辑,仅定义了 "如何生成下一个 token",但未定义 "何时停止生成",因此会持续生成 token,直到人为干预。
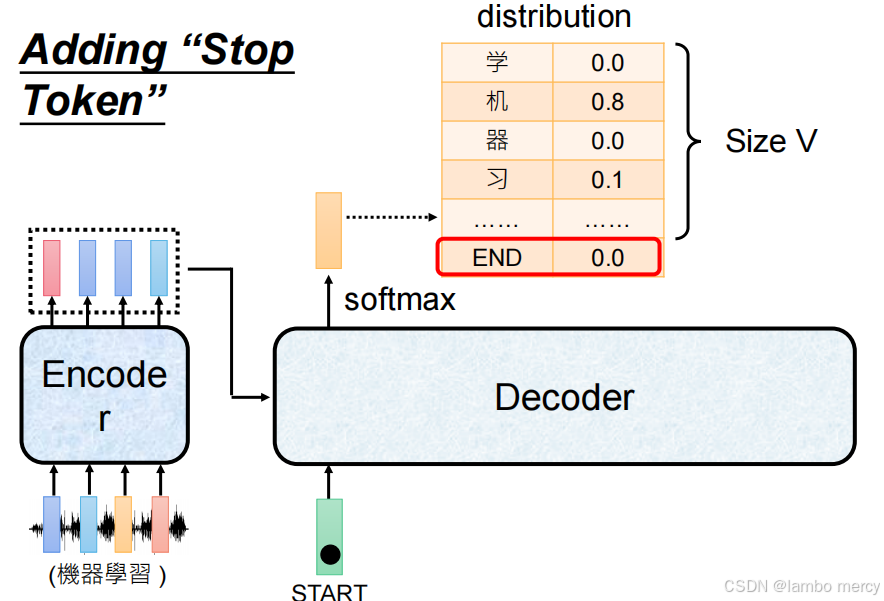
- 解决方法:引入 "终止 Token"(如 END/EOS)
通过在词汇表中加入特殊的 "终止 Token"(End of Sequence, EOS),实现长度控制:
- 训练阶段:将目标序列处理为 "目标内容 + 终止 Token"(如 "机器学习 + END"),让模型学习 "生成完目标内容后,输出终止 Token";
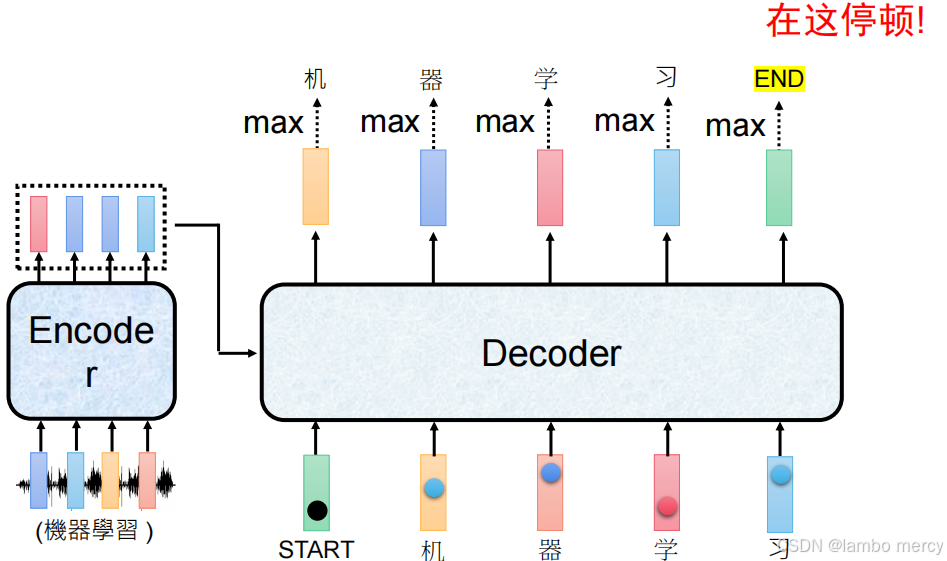
- 推理阶段:当 Decoder 生成 "终止 Token" 时,立即停止生成,从而控制输出长度,避免无限生成的情况。
交叉熵损失计算逻辑
自回归模型训练中的交叉熵损失计算逻辑
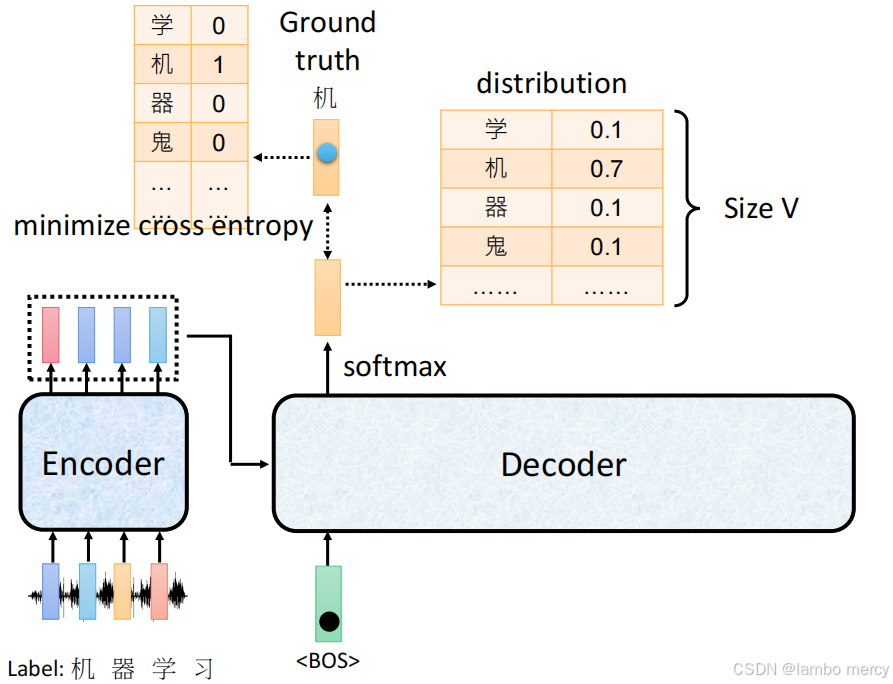
训练阶段通过最小化交叉熵损失让模型学习生成正确 token 的过程:
1. 输入与目标配置
- Encoder 输入:接收 "机器学习" 对应的语音信号序列,编码为特征表示后传递给 Decoder;
- Decoder 输入 :以特殊开始符
<BOS>(Begin of Sequence)为初始输入,启动序列生成; - 目标 Label :真实输出序列为 "机、器、学、习",当前训练步骤的目标 token 是 "机"(即
Ground truth)。
2. Decoder 的输出:概率分布
Decoder 处理后,输出整个词汇表(Size V)的概率分布:
- 每个 token 对应一个概率值(如图中 "机" 的概率是 0.7,"学""器""鬼" 的概率均为 0.1);
- 该分布代表模型对 "当前步骤应生成哪个 token" 的预测结果。
3. 损失计算:最小化交叉熵
交叉熵的作用是衡量 "模型预测的概率分布" 与 "真实标签分布" 的差异:
- 真实标签分布:以 one-hot 形式表示(仅目标 token "机" 对应值为 1,其余 token 对应值为 0,如图左侧表格所示);
- 交叉熵损失 :计算 "预测分布" 与 "真实分布" 的交叉熵,训练的核心目标是最小化这个损失------ 让模型预测的概率分布尽可能接近真实标签分布(即让 "机" 的概率尽可能高,其他 token 的概率尽可能低)。
通过持续最小化交叉熵损失,模型会逐步学习 "基于当前输入(如<BOS>)生成正确的目标 token(如 "机")",最终掌握整个序列的生成逻辑。
训练与测试的流程差异
平常任务 vs 生成任务:训练与测试的流程差异
1. 平常任务:训练与测试方式一致
- 核心逻辑:"训练时的方式,即为测试时的方式"。
- 示例(如图像分类):训练阶段是 "输入图片→提取特征→输出分类结果";测试阶段的流程完全相同,输入、处理逻辑、输出方式均无差异。
- 特点:训练与测试的流程、输入输出逻辑高度统一,无流程上的割裂。
2. 生成任务:训练与测试方式完全不同
生成任务(如文本生成)的训练和测试,在流程、计算方式上均存在明显差异:
(1)训练阶段:整体并行
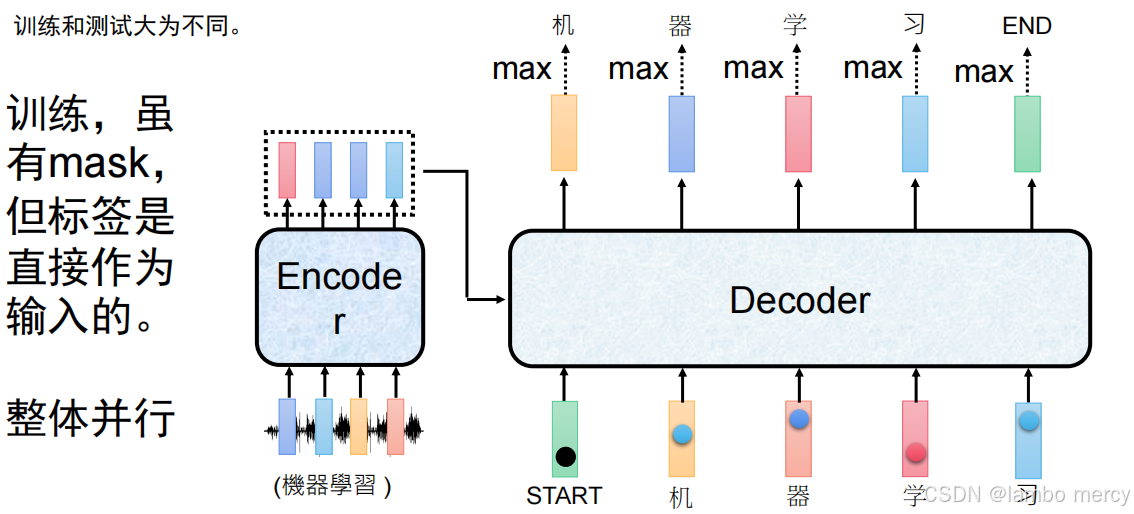
- 核心策略:采用
Teacher Forcing(将真实标签直接作为 Decoder 输入),结合Mask屏蔽未来信息。 - 流程:Decoder 输入是 "
START+完整真实标签"(如 "START + 机 + 器 + 学 + 习"),借助 Mask 保证仅关注当前及之前的 token,同时实现全序列并行计算(一次处理所有 token)。 - 特点:效率高,避免模型依赖自身生成的错误内容。
(2)测试阶段:整体串行
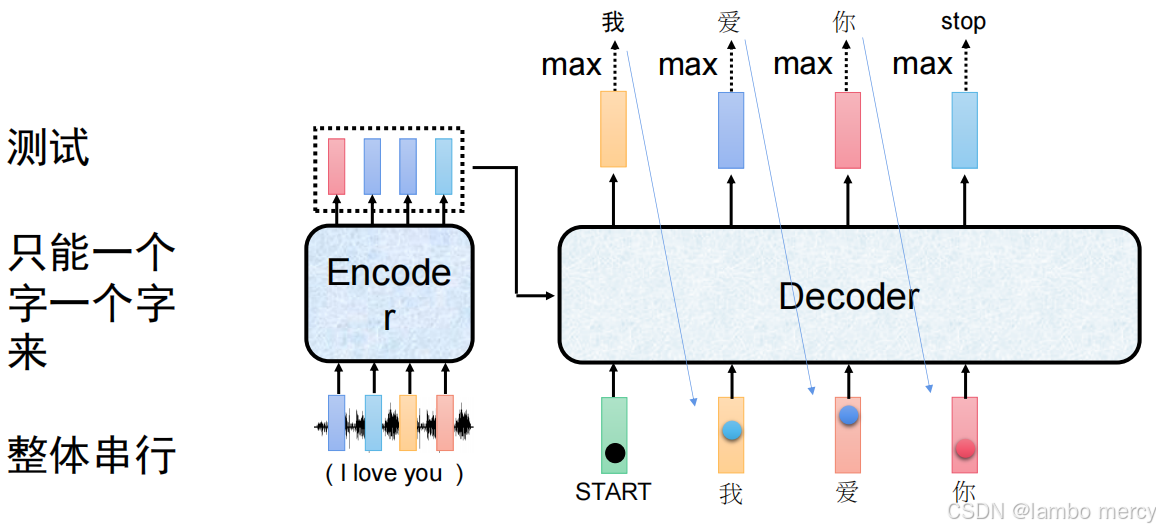
- 核心逻辑:自回归逐 token 生成。
- 流程:测试时无真实标签,只能以 "模型自己生成的前一个 token" 作为下一个 token 的输入(如从
START生成 "我",再用 "我" 生成 "爱",以此类推),逐 token 串行处理。 - 特点:流程与训练阶段完全割裂,只能依赖自身生成的内容,存在 "错误传递" 风险。
总结
- 平常任务:训练 = 测试,流程统一;
- 生成任务:训练(并行、依赖真实标签)≠ 测试(串行、依赖自生成内容),这是生成任务 "暴露偏差" 问题的核心来源。
Beam Search(束搜索)
解决自回归生成中 "贪婪策略的局部最优" 与 "全路径搜索的高计算量" 矛盾。
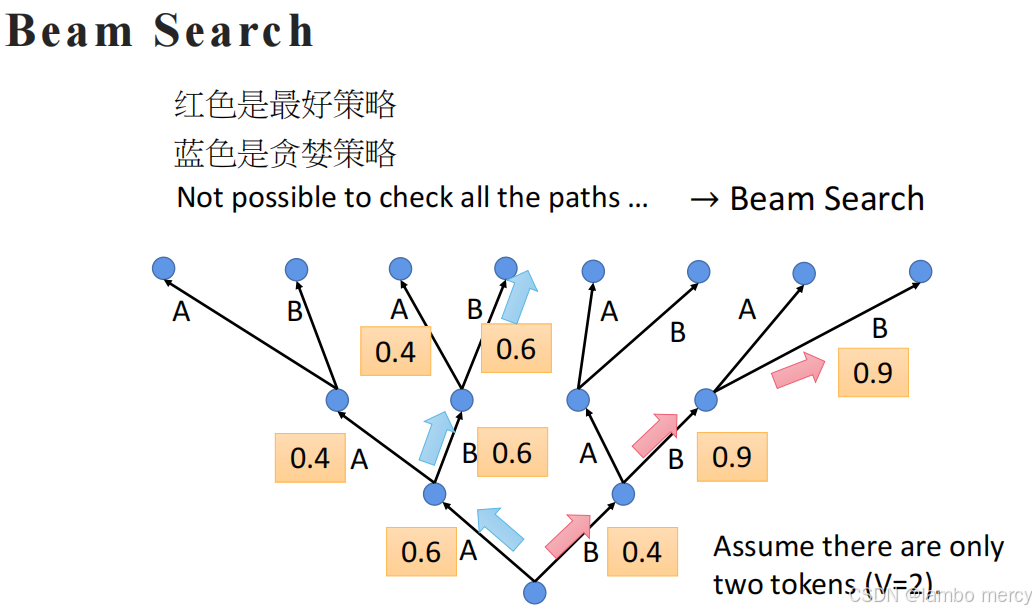
1. 背景:贪婪策略的局限与全路径搜索的不可行
- 贪婪策略(图中蓝色路径) :每一步仅选择当前概率最大的 token(如选 0.6 而非 0.4),但这种 "短视" 选择会陷入局部最优------ 某一步的高概率,可能导致后续序列的总概率更低。
- 全路径搜索 :遍历所有可能的 token 组合(图中 "所有 paths"),能找到总概率最高的 "最好策略"(图中红色路径),但当词汇表或序列长度较大时,路径数量呈指数增长,计算量完全不可行(即图中 "Not possible to check all the paths")。
2. Beam Search 的核心逻辑
Beam Search 通过保留 Top-K 个候选序列(K 为束宽),平衡计算量与结果质量:
- 初始阶段:从
START开始,生成所有可能的第一个 token,保留概率最高的 K 个序列; - 迭代扩展:每一步对当前保留的 K 个序列,分别扩展所有可能的下一个 token,计算每个新序列的总概率,再保留总概率最高的 K 个序列;
- 终止条件:当候选序列生成终止符(如
<EOS>)时,停止扩展,最终从所有候选中选总概率最高的序列。
3. 图中示例的直观体现
图中假设词汇表仅含 2 个 token(A、B):
- 贪婪策略(蓝色)仅保留当前最优的单个序列,错过后续总概率更高的路径;
- Beam Search 会同时保留多个候选(如束宽 K=2),既避免全路径的高计算量,又能捕捉到 "总概率更高的最好策略"(红色路径)。
总结
Beam Search 是自回归生成中常用的解码策略:以可控的计算量,避免贪婪策略的局部最优,同时比全路径搜索更高效,最终得到更接近全局最优的生成序列。
Cross Attention(交叉注意力)
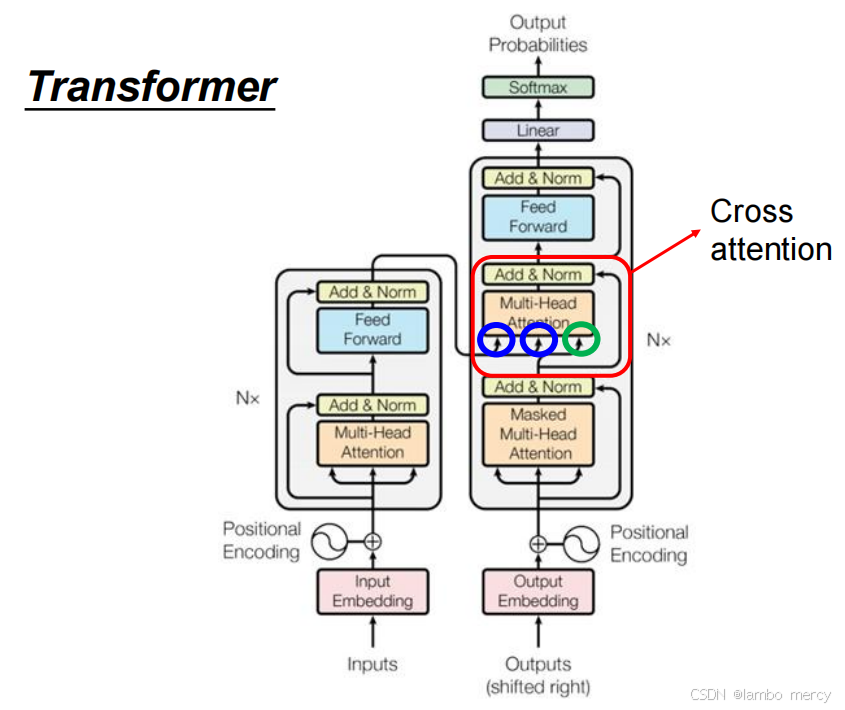
- Cross Attention 位于 Transformer 的Decoder 层内:
- 在 Decoder 的
Masked Multi-Head Attention(掩码自注意力)之后; - 在
Feed Forward(前馈网络)之前; - 每一层 Decoder 都会包含这一模块(图中 "N×" 代表多层堆叠)。
- Cross Attention 是Encoder 与 Decoder 之间的信息桥梁
- 以Decoder 中 Masked 自注意力的输出作为 "查询(Query)";
- 以Encoder 的最终输出作为 "键(Key)" 和 "值(Value)";
- 通过注意力计算,让 Decoder 在生成当前 token 时,能关注到输入序列(Encoder 编码的内容)的全局信息。
例如在翻译任务中:Decoder 生成目标语言的 "机" 时,Cross Attention 会让它关联到源语言中对应的 "machine"(Encoder 编码的内容),保证生成内容与输入语义一致。
- 与自注意力的区别
Cross Attention 和 Transformer 中的自注意力(如 Encoder 的 Multi-Head Attention、Decoder 的 Masked Multi-Head Attention)的核心差异是:
- 自注意力:是单一序列内部的注意力(如 Encoder 关注输入序列自身的上下文,Decoder 的 Masked 自注意力关注输出序列自身的已生成内容);
- Cross Attention:是两个不同序列之间的注意力(连接输入序列与输出序列),是 Encoder 向 Decoder 传递信息的唯一方式。
Cross Attention 是 Transformer 实现 "输入 - 输出语义对齐" 的关键模块,保证了生成内容与输入的关联性。
Cross Attention 的具体计算流程与信息传递逻辑
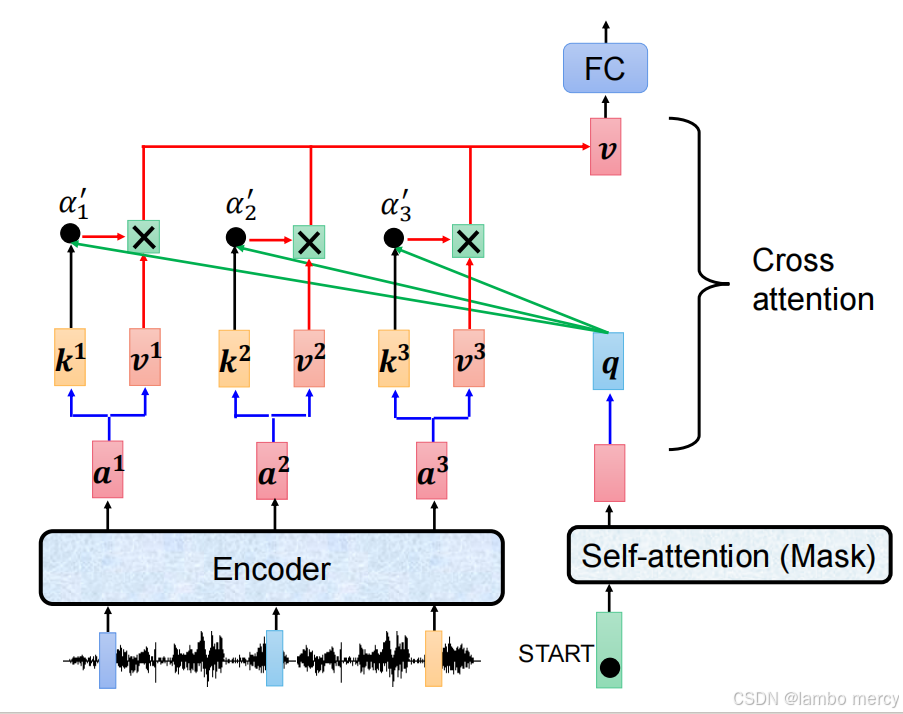
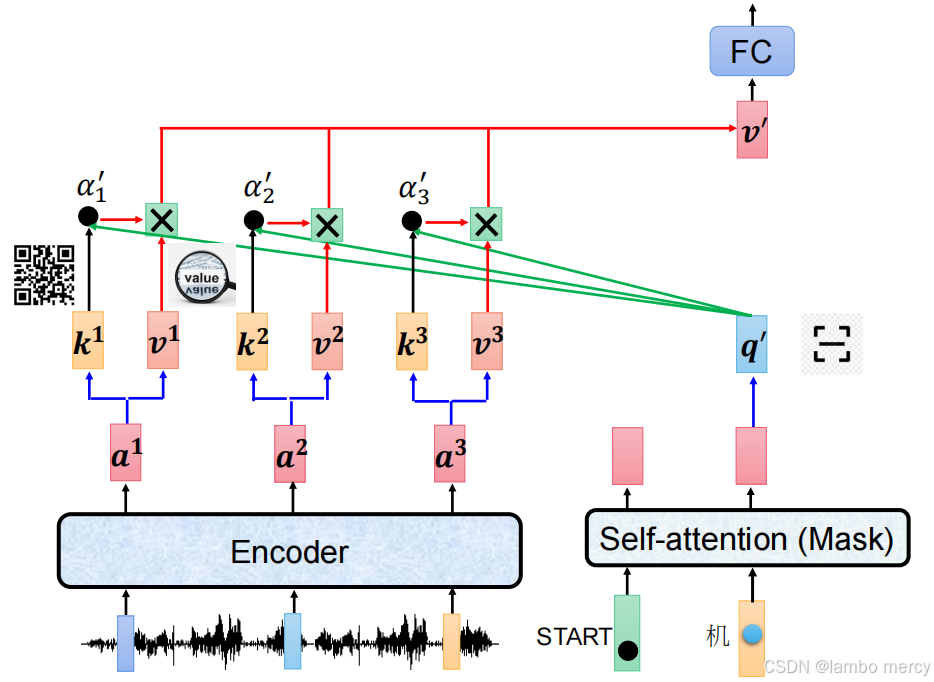
1. 输入来源:分别来自 Encoder 与 Decoder
-
Encoder 侧的 "信息池" :Encoder 处理输入(如图中的语音信号)后,输出序列特征
a¹、a²、a³;每个特征会被转换为对应的键(Key,k)和值(Value,v),这是 Cross Attention 可调用的 "输入语义信息"。 -
Decoder 侧的 "当前状态" :Decoder 以特殊符
START为起点,先经过Masked Self-attention ,得到当前生成步骤的查询(Query,q)------ 这是 Decoder "当前生成状态" 的特征表示。
2. Cross Attention 的计算步骤
"用 Decoder 的查询,匹配 Encoder 的键,加权 Encoder 的值":
- 计算注意力得分 :用 Decoder 的
q,分别与 Encoder 的k¹、k²、k³计算注意力得分(图中α'₁、α'₂、α'₃),得分越高代表q与对应k的语义关联越强; - 得分归一化(隐含步骤):对得分做 Softmax 处理,得到总和为 1 的注意力权重;
- 加权融合值向量 :用归一化后的权重,对 Encoder 的
v¹、v²、v³做加权求和,得到融合了输入语义的特征向量; - 全连接转换 :加权后的向量经过
FC(全连接层)处理,作为 Decoder 后续模块的输入。
3. 核心作用:保证生成内容与输入语义对齐
Cross Attention 是 Encoder 向 Decoder 传递信息的唯一通道:
- 它让 Decoder 在生成序列时,能精准关联 Encoder 输入中与当前状态相关的信息(比如生成 "机" 时,自动关注 Encoder 中对应 "machine" 的特征);
- 结合 Decoder 内的 Masked Self-attention(捕捉已生成内容的上下文),Cross Attention 让生成的内容既符合自身逻辑,又与输入语义保持一致。