文章目录
- 一、SenseVoice开源项目介绍
-
- [1 模型结构详解](#1 模型结构详解)
-
- [(1)先来看SenseVoice Small架构](#(1)先来看SenseVoice Small架构)
- [(2)再来看SenseVoice Large架构](#(2)再来看SenseVoice Large架构)
- [2 核心功能](#2 核心功能)
- [3 性能评测](#3 性能评测)
- 二、推理实战
-
- [1 使用funasr推理](#1 使用funasr推理)
- [2 直接推理](#2 直接推理)
- 三、微调实战
-
- [1 数据处理](#1 数据处理)
- [2 训练脚本](#2 训练脚本)
一、SenseVoice开源项目介绍
SenseVoice开源模型是多语言音频理解模型,具有包括语音识别、语种识别、语音情感识别、声学事件检测 能力。
github仓库:SenseVoice
1 模型结构详解
SenseVoice 多语言音频理解模型,支持语音识别,语种识别,情感识别,声学事件检测,逆文本正则化等能力,采用工业级数十万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于中文,粤语,英语,日语,韩语音频识别,并输出带有情感和事件的富文本转写结果。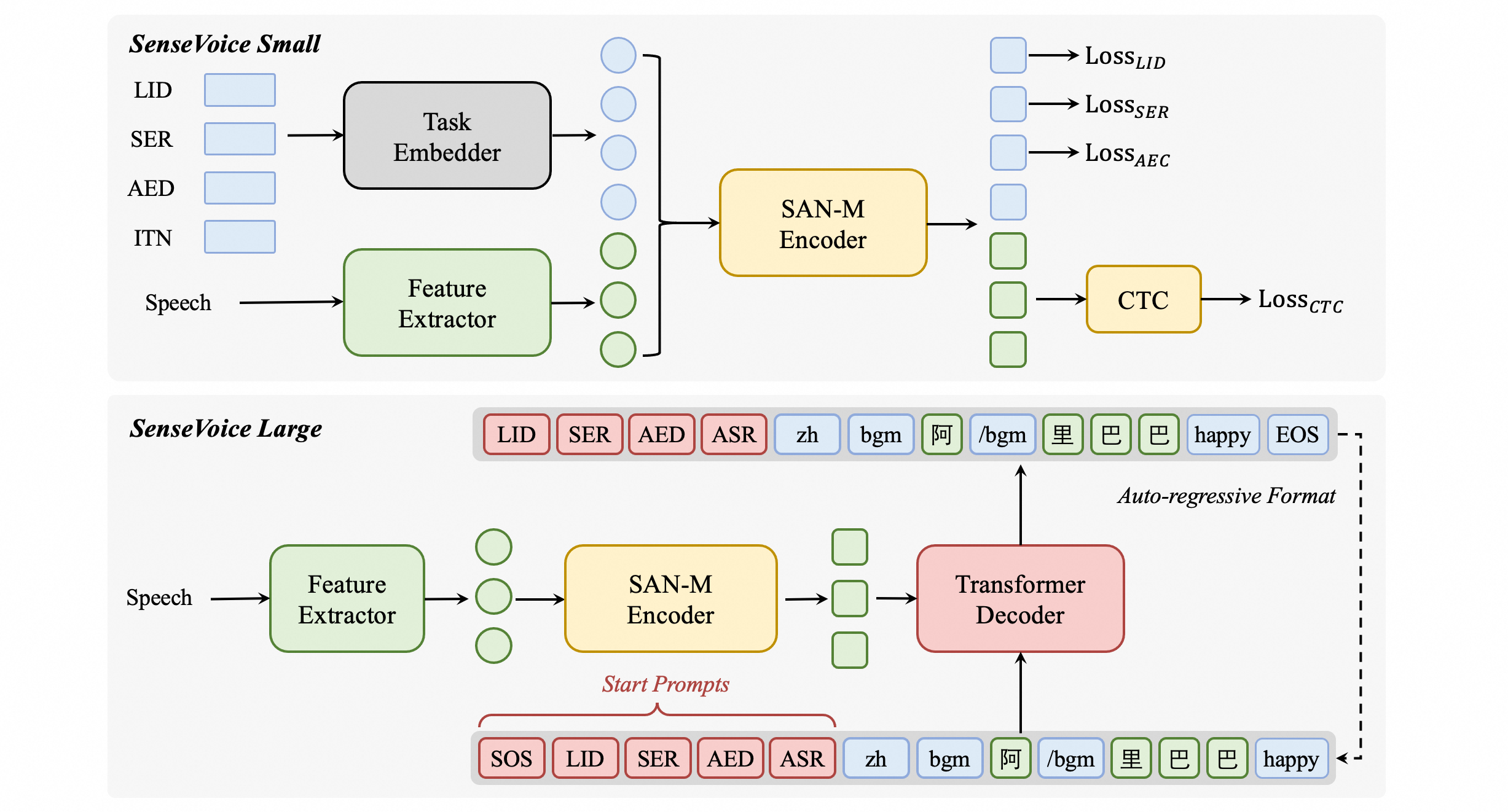
SenseVoice是一个统一的多任务语音处理模型,能同时处理多种语音相关任务:
- LID:语种识别 【en】
- SER:语音情感识别【happy】
- AED:音频事件检测(如笑声,咳嗽等)
- ITN:逆文本规范化(将语音转写的文本规范化)
- ASR:自动化语音识别(核心任务 语音转录)
- Speech:通用语音表示学习
(1)先来看SenseVoice Small架构
这是一个非自回归,多任务并行处理的轻量级模型。
text
输入音频 → Feature Extractor → Task Embedder → 并行输出多个任务结果关键组件:
- Feature Extractor:提取音频特征(如梅尔频谱图)
- Task Embedder:任务嵌入器,为不同任务生成特定的提示向量。
- 并行输出:同时输出LID,SER,AED等多个任务的结果。
优势:
- 高效快速:一次前向传播完成所有任务。
- 轻量级:适合资源受限场景。
- 任务解耦:各任务相互独立
(2)再来看SenseVoice Large架构
这是一个更强大的自回归,多任务统一生成式模型。
模型将所有任务都转换为统一的文本标记序列进行生成:
text
音频输入 → SAN-M Encoder → Transformer Decoder → 自回归生成序列:
SOS → LID → SER → AED → ASR → zh → bgm → 阿 → /bgm → 里 → 巴 → happy → EOS序列解码示例:
text
SOS # 开始标志
LID:zh # 语种:中文
SER:happy # 情绪:高兴
AED:bgm # 检测到背景音乐开始
ASR:阿 # 识别文字"阿"
AED:/bgm # 背景音乐结束
ASR:里 # 识别文字"里"
ASR:巴 # 识别文字"巴"
EOS # 结束关键创新:
- SAN-M Encoder:可能是专门设计的音频编码器
- 统一输出格式:将所有任务(LID,SER,AED,ASR)的输出统一编码为文本标记序列。
- 自回归生成:像语言模型一样逐个生成标记,但包含结构化信息。
2 核心功能
SenseVoice专注于高精度多语言语音识别,情感辨识和音频事件检测
- 多语言识别:采用超过40万小时数据训练,支持超过50中语言,识别效果优于Whisper模型。
- 富文本识别:
- 具备优秀的情感识别,能在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽等多种常见人机交互事件进行检测。
- 高效推理:SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms,15倍有余Whisper-Large。
- 微调定制:具备便携的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署:具有完整的服务部署链路,支持多並發请求,支持客户端语言有,Python、c++、HTML、Java与C#等。
3 性能评测
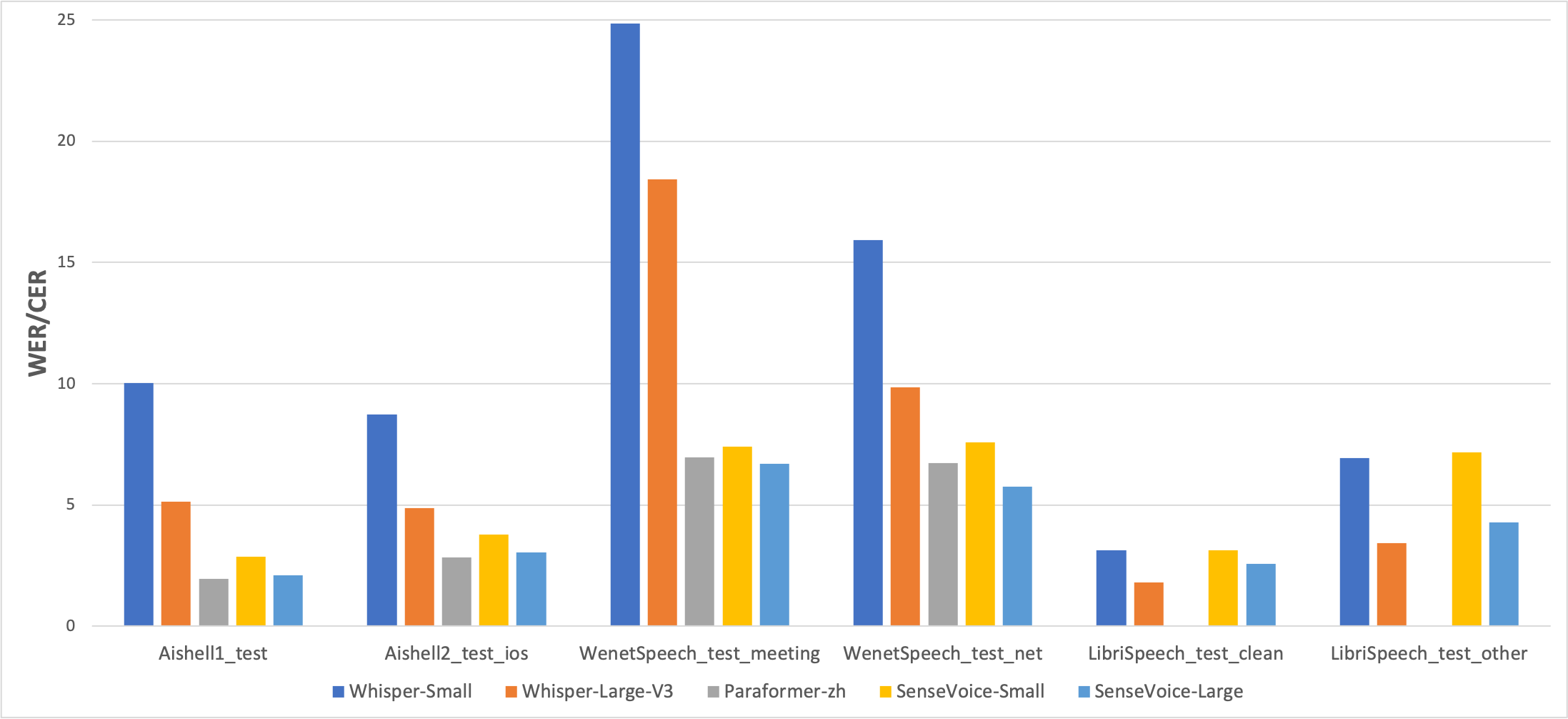
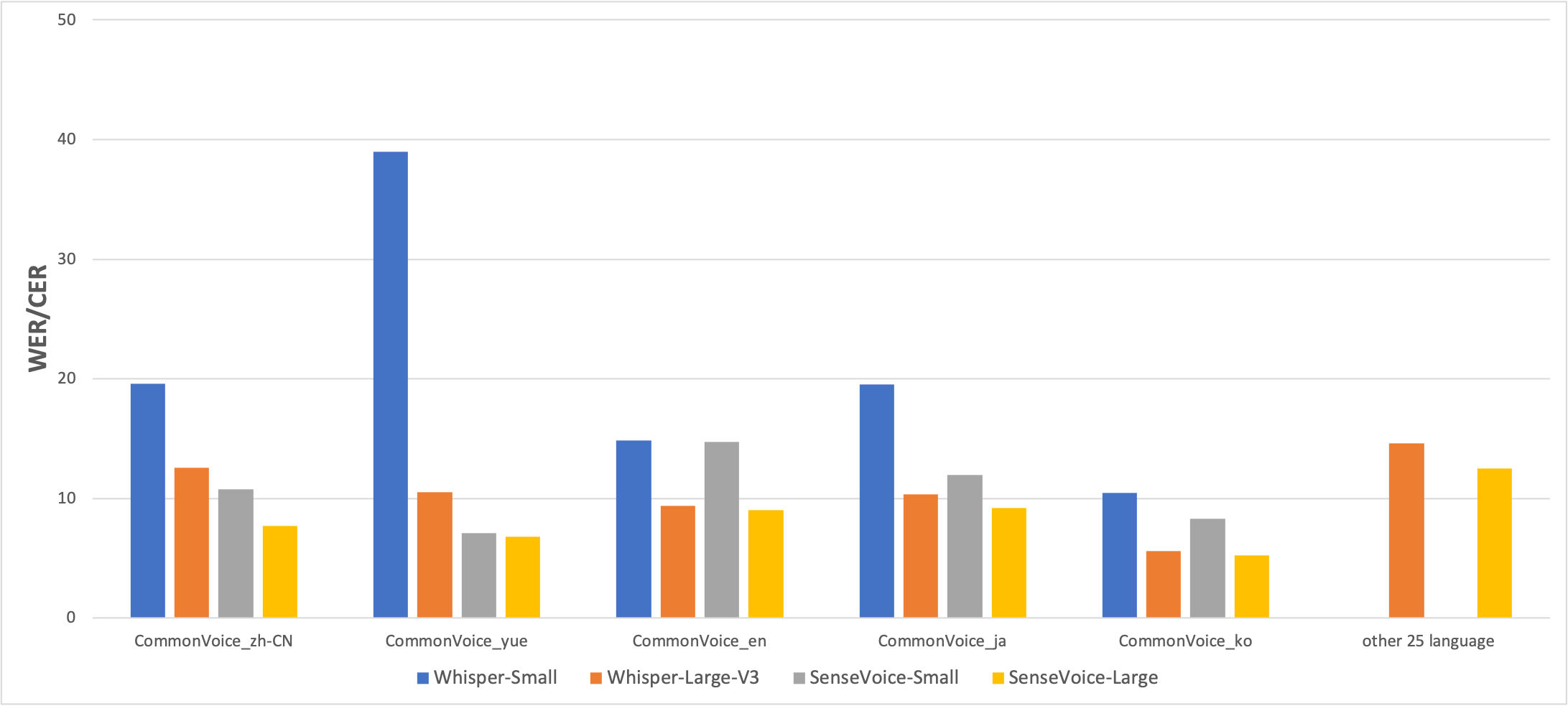
多语言语音识别
我们在开源基准数据集上比较了SenseVoice与Whisper的多语言语音识别性能和推理效率。在中文和粤语识别效果上,SenseVoice-Small模型具有明显的效果优势。
二、推理实战
1 使用funasr推理
支持任意格式音频输入,支持任意时长输入
python
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text) 参数说明(点击展开)
model_dir:模型名称,或本地磁盘中的模型路径。
trust_remote_code:
True 表示 model 代码实现从 remote_code 处加载,remote_code 指定 model 具体代码的位置(例如,当前目录下的 model.py),支持绝对路径与相对路径,以及网络 url。
False 表示,model 代码实现为 FunASR 内部集成版本,此时修改当前目录下的 model.py 不会生效,因为加载的是 funasr 内部版本,模型代码 点击查看。
vad_model:表示开启 VAD,VAD 的作用是将长音频切割成短音频,此时推理耗时包括了 VAD 与 SenseVoice 总耗时,为链路耗时,如果需要单独测试 SenseVoice 模型耗时,可以关闭 VAD 模型。
vad_kwargs:表示 VAD 模型配置,max_single_segment_time: 表示 vad_model 最大切割音频时长,单位是毫秒 ms。
use_itn:输出结果中是否包含标点与逆文本正则化。
batch_size_s 表示采用动态 batch,batch 中总音频时长,单位为秒 s。
merge_vad:是否将 vad 模型切割的短音频碎片合成,合并后长度为 merge_length_s,单位为秒 s。
ban_emo_unk:禁用 emo_unk 标签,禁用后所有的句子都会被赋与情感标签。默认 False如果输入均为短视频(小于30s),并且需要批量化推理,为了加快推理效率,可以移除vad模型,并设置batch_size
python
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size=64,
)2 直接推理
支持任意格式音频输入,输入音频时长限制在30s以下。
python
from model import SenseVoiceSmall
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device="cuda:0")
m.eval()
res = m.inference(
data_in=f"{kwargs ['model_path']}/example/en.mp3",
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
ban_emo_unk=False,
**kwargs,
)
text = rich_transcription_postprocess(res [0][0]["text"])
print(text)三、微调实战
1 数据处理
数据集-train.jsonl
json
{"key": "848dc09b", "source": "/data/H2413325/code_dir_V2/voice_datasets_process/Chinese_voice/train_voice/848dc09b/848dc09b.wav", "source_len": 1193, "target": "在大语言模型中,我们对储能设备、机台和机种进行了点检,并使用 v work 系统记录了检查结果。此外,工务部门还负责制具的互译工作,确保所有操作符合标准。", "target_len": 4}
{"key": "68f7f60b", "source": "/data/H2413325/code_dir_V2/voice_datasets_process/Chinese_voice/train_voice/68f7f60b/68f7f60b.wav", "source_len": 2970, "target": "实验的成本高,周期长,每个机种需要消耗主板超过1300批次,需要经过大约30轮的实体实验,且高度依赖工程师的工艺设计经验,并且方案一旦出现缺陷,难以进行分析分析和对症下药。那针对以上问题,我们引入了计算流体动力学仿真软件,结合PE的工程经验和ID的仿真技术,对点胶和毛细填充过程进行仿真计算和结果的可视化呈现。", "target_len": 155}数据集-val.jsonl
json
{"key": "7e29ed37", "source": "/data/H2413325/code_dir_V2/voice_datasets_process/Chinese_voice/train_voice/7e29ed37/7e29ed37.wav", "source_len": 1170, "target": "在处理异常时,各Site的程式需要与集控中心协调,确保发料和KT仓的国别、料号、工艺及时长等信息准确无误。", "target_len": 53}
{"key": "40a97f76", "source": "/data/H2413325/code_dir_V2/voice_datasets_process/Chinese_voice/train_voice/40a97f76/40a97f76.wav", "source_len": 1133, "target": "在点检以下 v work 系统的制具时,我们需要注意储能机台和不同机种的工务要求,并确保大语言互译的准确性。", "target_len": 4}2 训练脚本
直接执行:bash finetune.sh
bash
# Copyright FunASR (https://github.com/alibaba-damo-academy/FunASR). All Rights Reserved.
# MIT License (https://opensource.org/licenses/MIT)
# workspace=`pwd`
workspace="/data/code_dir_V2/FunASR-main/data/list"
# which gpu to train or finetune
export CUDA_VISIBLE_DEVICES="0"
gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}')
# model_name from model_hub, or model_dir in local path
## option 1, download model automatically
model_name_or_model_dir="SenseVoiceSmall_bak"
## option 2, download model by git
#local_path_root=${workspace}/modelscope_models
#mkdir -p ${local_path_root}/${model_name_or_model_dir}
#git clone https://www.modelscope.cn/${model_name_or_model_dir}.git ${local_path_root}/${model_name_or_model_dir}
#model_name_or_model_dir=${local_path_root}/${model_name_or_model_dir}
# data dir, which contains: train.json, val.json
# train_data=${workspace}/train.jsonl
# val_data=${workspace}/val.jsonl
train_data=/data/code_dir_V2/voice_datasets_process/Chinese_voice/train.jsonl
val_data=/data/code_dir_V2/voice_datasets_process/Chinese_voice/val.jsonl
# exp output dir
output_dir="./outputs"
log_file="${output_dir}/log.txt"
deepspeed_config=${workspace}/../../ds_stage1.json
mkdir -p ${output_dir}
echo "log_file: ${log_file}"
DISTRIBUTED_ARGS="
--nnodes ${WORLD_SIZE:-1} \
--nproc_per_node $gpu_num \
--node_rank ${RANK:-0} \
--master_addr ${MASTER_ADDR:-127.0.0.1} \
--master_port ${MASTER_PORT:-26669}
"
echo $DISTRIBUTED_ARGS
# funasr trainer path
train_tool=../../../funasr/bin/train_ds.py
torchrun $DISTRIBUTED_ARGS \
${train_tool} \
++model="${model_name_or_model_dir}" \
++train_data_set_list="${train_data}" \
++valid_data_set_list="${val_data}" \
++dataset_conf.data_split_num=1 \
++dataset_conf.batch_sampler="BatchSampler" \
++dataset_conf.batch_size=6000 \
++dataset_conf.sort_size=1024 \
++dataset_conf.batch_type="token" \
++dataset_conf.num_workers=4 \
++train_conf.max_epoch=50 \
++train_conf.log_interval=1 \
++train_conf.resume=true \
++train_conf.validate_interval=2000 \
++train_conf.save_checkpoint_interval=2000 \
++train_conf.keep_nbest_models=20 \
++train_conf.avg_nbest_model=10 \
++train_conf.use_deepspeed=false \
++train_conf.deepspeed_config=${deepspeed_config} \
++optim_conf.lr=0.0002 \
++output_dir="${output_dir}" &> ${log_file}