目录
[1.1 系统架构编辑](#1.1 系统架构编辑)
[1.2 高可用](#1.2 高可用)
[2.1 FIFO Scheduler【先进先出调度器】](#2.1 FIFO Scheduler【先进先出调度器】)
[2.2 Capacity Scheduler【容量调度器】](#2.2 Capacity Scheduler【容量调度器】)
[2.3 Fair Scheduler【公平调度器】](#2.3 Fair Scheduler【公平调度器】)
1.原理
Yarn是一个分布式的通用资源管理系统,它处在整个大数据架构的中间位置,不仅可以把MapReduce的作业调度到HDFS上运行,也可以把我们spark/flink等作业任务都调度到HDFS上运行。

1.1 系统架构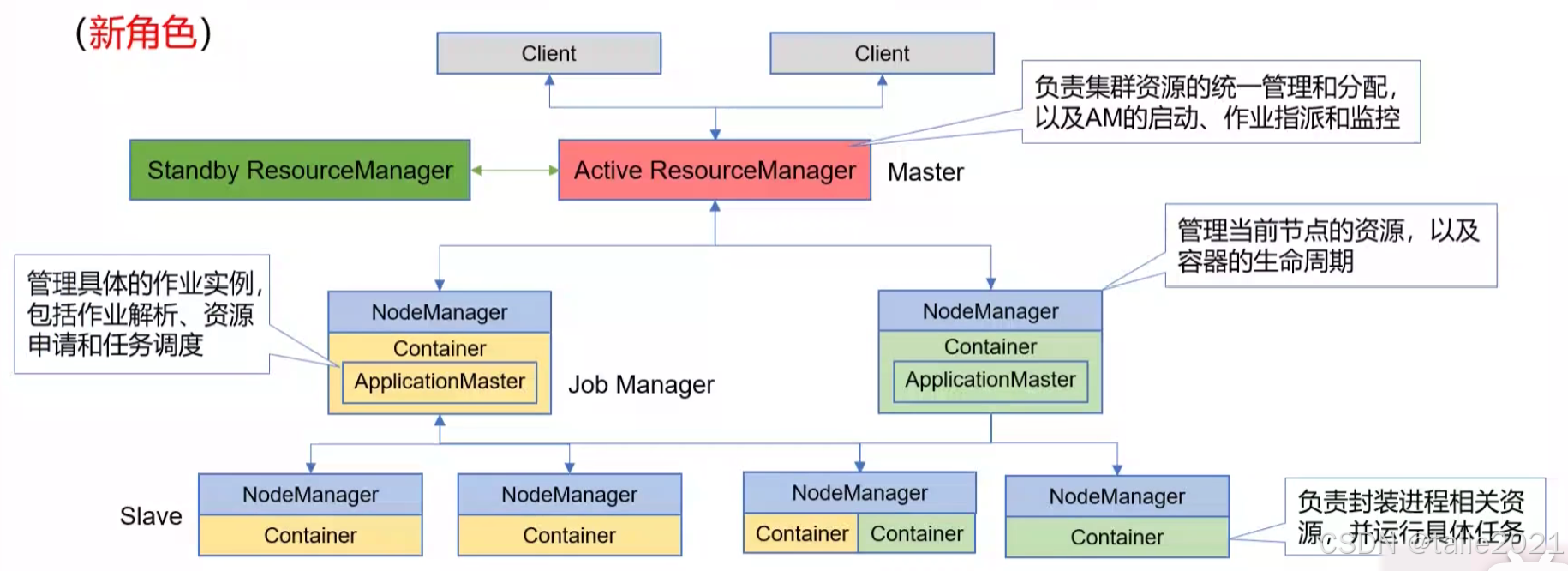
Yarn是很典型的主从架构,主节点是Resource Manager,从节点是Node Manager。一般会有热备节点解决单点架构问题。当前活跃的管理节点是active,热备节点是standby。
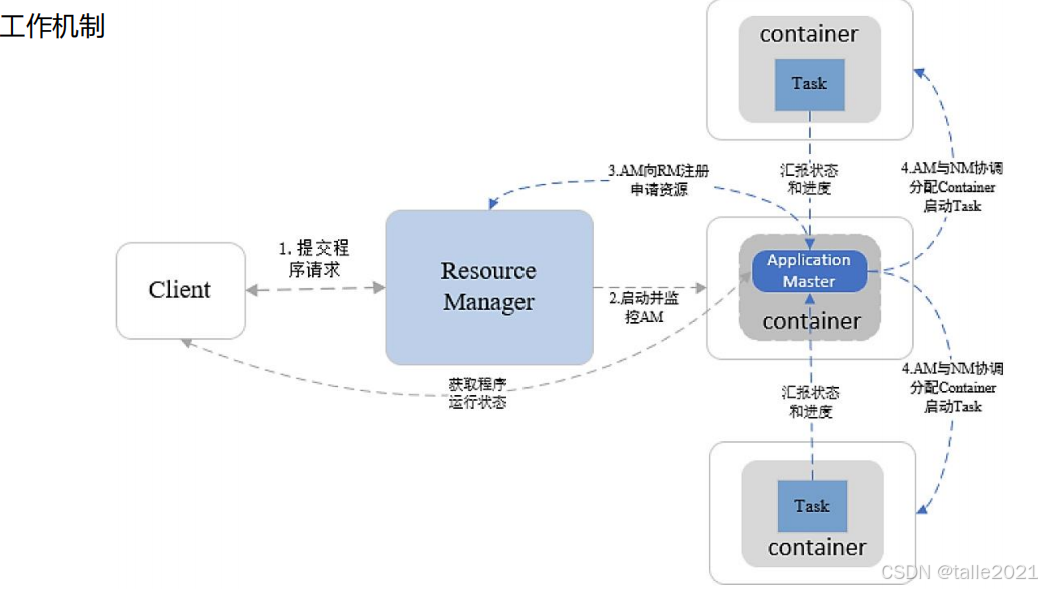
客户端向Resource Manager提交了一个作业上来, resource manager会在所有的Node Manager从节点里给提交上来的作业分配资源,分配到的资源包括所需要的CPU、内存、环境变量等都封装到container里,一般第一次提交上来的作业会分配一个container用来运行作业。第一个container分配出来之后,在第一个container里,作业先是把自己的作业管理进程ApplicationMaster运行起来,运行起来之后,才开始进行作业的具体解析。当解析后发现当前作业运行时需要额外的三个资源,于是ApplicationMaster再向Resource Manager申请资源,Resource Manager就会在所有Node Manager里面又找到三个资源分装成container并给到ApplicationMaster,ApplicationMaster拿到资源后,就把作业解析成多个task并分发到container里运行, 这些task在运行过程中实时向ApplicationMaster汇报,如果某个task挂掉了,ApplicationMaster会尝试着去重启。ApplicationMaster发现所有的task都运行完了再向Resource Manager申请释放资源,Resource Manager就把几个container释放掉。
Yarn处于中间层具有通用性,客户端既可以提交mapreduce作业,也可以提交spark作业。因为只要提交的任务实现了ApplicationMaster的接口,就可以在集群里边运行。
1.2 高可用
ResourceManager高可用指1个Active ResourceManager、多个Standby ResourceManager,宕机后自动实现主备切换。这些主节点之间的状态切换由ZooKeeper决定,ZooKeeper会从所有的主节点里面选取一个作为主节点,被选中的主节点状态就转换成Active,其他的就变成Standby。如果Active挂掉之后,由ZooKeeper把这个Active主节点的状态降成Standby,再从其他的Standby里选一个作为管理节点,把状态升为Active。 状态切换过来后,还要把元数据同步过来。在Yarn里,元数据直接放在ZooKeeper里, Standby可以从ZooKeeper里把元数据拿过来,同步元数据之后,再由ZooKeeper把状态切换成Active,就可以进行集群管理了。这里ZooKeeper充当了两个作用,第一负责状态切换,第二是存储元数据。
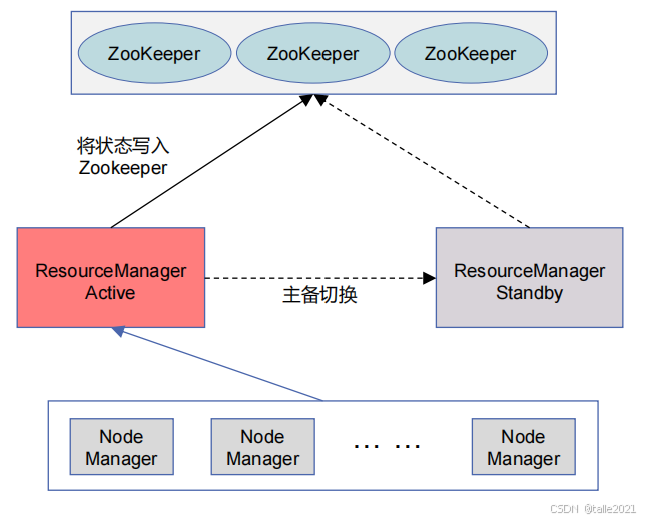
在主从切换的过程中,集群里运行的任务会阻塞,一直等到新的Active ResourceManager被选举出来才开始正常去继续执行。
2.资源调度策略
2.1 FIFO Scheduler【先进先出调度器】
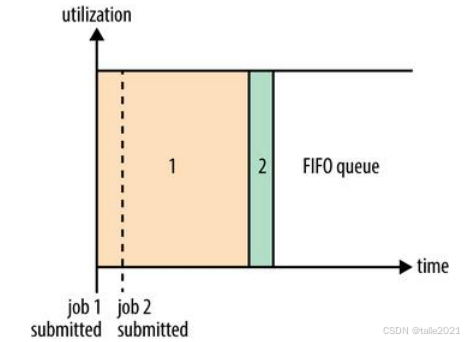
先进先出调度策略是将所有任务放入一个队列,先进的队列先获得资源,排在后面的任务只能等待前面的任务执行完。下面这张图可以看到,一开始先是提交了job1,job1就拿到整个集群的所有的资源。在虚线处job2也提交上来了,但它不能立马获取到资源,只能排在job1后面,等job1运行完成之后,job2才可以开始运行。这种先进先出的调度策略实现原理很简单,但它资源利用率低,无法交叉运行任务,对一些紧急的小任务非常不友好,紧急任务无法插队。
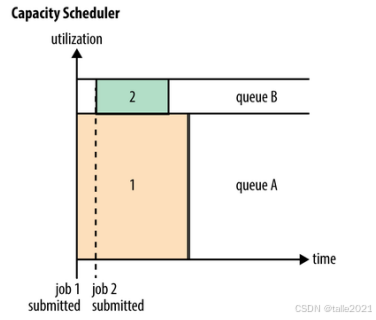
2.2 Capacity Scheduler【容量调度器】
容量调度策略的核心思想是集群资源由多个队列分享,每个队列都要预设资源分配的比例,空闲资源优先分配给"实际资源/预算资源"比值最低的队列,队列内部采用FIFO调度策略。下面这张图可以看到,集群里面划分了两个队列,队列A和队列B,除了划分多队列外还要预分固定的资源。假设队列A运行的都是一些大作业,占了集群80%的资源,队列B运行一些紧急的小作业,只需要20%的资源就够了。job1一提交就能拿到队列A的80%资源,运行过程中,在虚线处紧急的小任务job2上来, 拿到20%的资源,两个job互不干扰。实际上,在生产过程中,容量调度并不是完全严格分配队列资源队列A80%,队列B20%,会有一个最大的一个资源占比,默认情况下队列A是80%,队列B是20%。但是它可以设置队列B在某些情况下,最大可以获得整个集群百分之百的资源。比方说队列A运行的是一些大作业,一般大作业是晚上提交的,像白天队列A里面是空闲的,但白天队列B会有大量的任务提交,队列B在运行的时候发现队列A没有任务,有80%的空闲资源,队列B默认是拿20%,最多可以拿百分之百,于是队列B就把整个集群的资源全部拿到,然后进行作业的运算,这样就不会浪费资源。
2.3 Fair Scheduler【公平调度器】
公平调度策略的思想是多队列公平共享集群资源,通过平分的方式,动态分配资源,无需预先设定资源分配比例,队列内部可配置FIFO、Fair(默认)。
下图集群里分了两个队列,队列A和队列B,这两个队列之间并没有预先设定一个资源占比,他俩之间用公平的方式分配资源,见面分一半叫公平。比方在最开始时刻job1提交到队列A里面,提交进来之后发现整个集群的资源都是空闲的,于是job1把整个集群的资源都占用了,拿到集群百分之百的资源。在虚线处job2提交进来了,job2在提交到执行的过程中有一段空余时间,这段空余时间就给到job1让出一半资源来给到job2,job2拿到50%的资源就开始运行。默认情况下,队列和队列之间以公平的形式分配资源,何为公平,就是见面分一半。队列内部默认情况下也是公平去分配资源, job2运行的时候,job3提交到了同一个队列之后, job3在提交到执行的过程中有一段空余时间,这段空余时间就给到job2让出一半资源来给到job3,job3拿到队列内部50%的资源就开始运行了。
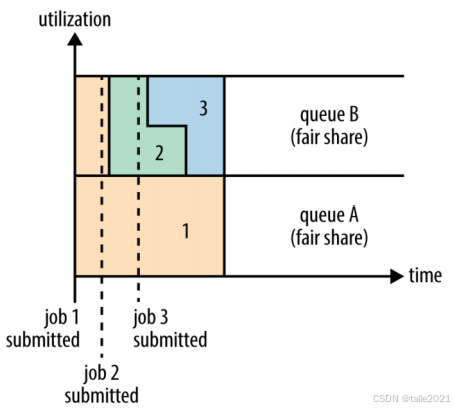
默认情况下每个队列的权重都是1,作业分资源按1比1去分。 如果某一个队列资源占用比较大,可以提升权重,比如说权重提升成2,这样可以拿2/3资源。