在这篇文章中,我们将讨论:什么时候你真的需要多智能体架构 ,目前实践中最常见的 四种核心模式,以及 LangChain 如何帮助你高效地构建多智能体系统。
许多 agentic 任务,其实用一个设计良好、工具齐全的单一智能体 就可以完成。
你应该始终从这里开始------单智能体更容易构建、理解,也更容易调试。
但当应用规模开始扩大,团队往往会遇到一个非常现实的问题:
他们已经拥有大量功能各异的 agent 能力,却希望把这些能力整合成一个统一、连贯的对外交互界面。
随着要整合的能力不断增加,两个核心约束开始变得无法忽视:
一、上下文管理(Context Management)
每个能力背后往往都有高度专业化的知识,这些内容并不适合一次性塞进一个 prompt 里。
如果上下文窗口是无限的、延迟为零,那当然可以一次性把所有相关信息都给模型。
但现实情况是,你必须设计机制,让信息在任务推进过程中被"按需浮现"。
二、分布式开发(Distributed Development)
不同团队独立开发、维护各自的能力模块,并且有清晰的边界与责任归属。
在这种情况下,一个巨大的、统一维护的 agent prompt 会迅速变得不可控,跨团队协作成本极高。
当你需要管理庞大的领域知识 、跨团队协作 ,或是处理真正复杂的任务 时,这些约束会迅速成为瓶颈。
这正是多智能体架构开始显现价值的时刻。
近期的一些研究已经证明:在上述场景下,多智能体系统的表现明显优于单智能体。
例如在 Anthropic 的多智能体研究系统中,
以 Claude Opus 4 作为主控智能体 、Claude Sonnet 4 作为子智能体 的多智能体架构,
在内部研究评测中,相比单一的 Claude Opus 4,性能提升达 90.2%。
关键原因在于:
多智能体架构允许每个智能体拥有独立的上下文窗口 ,从而实现真正的并行推理,这是单一智能体无法做到的。
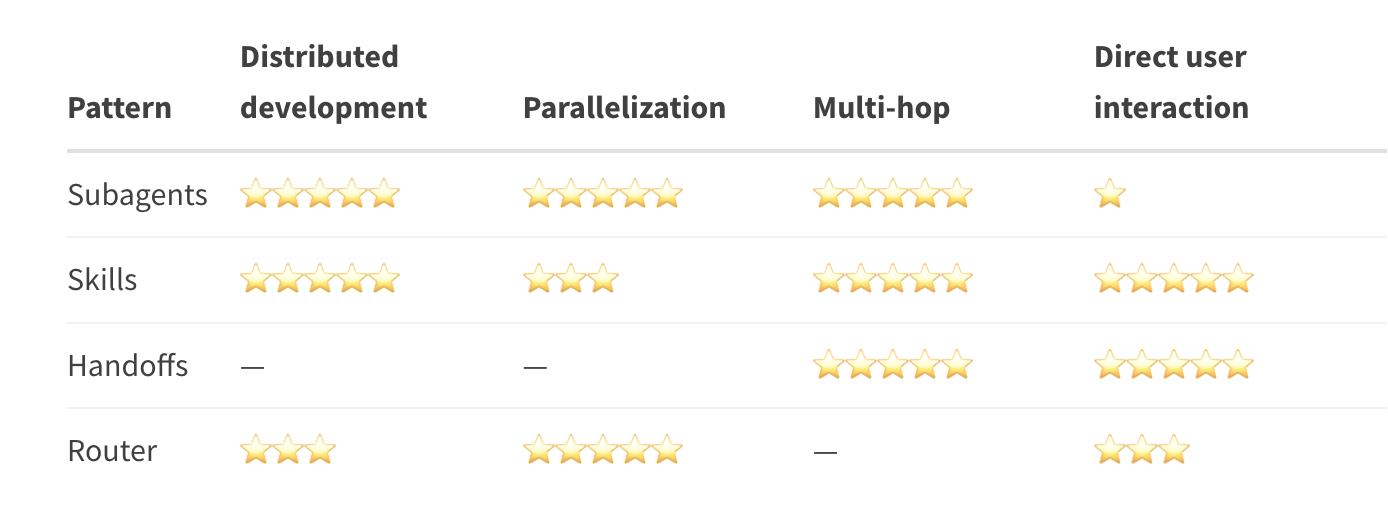
多智能体架构的四种核心模式
我们观察到,绝大多数多智能体应用都可以归结为四种架构模式:
子智能体(Subagents) 、技能(Skills) 、交接(Handoffs) 和 路由(Router)。
它们在任务协调方式、状态管理策略,以及能力解锁的顺序控制上各不相同。
下面我们将逐一介绍,并给出适用场景与关键权衡点。
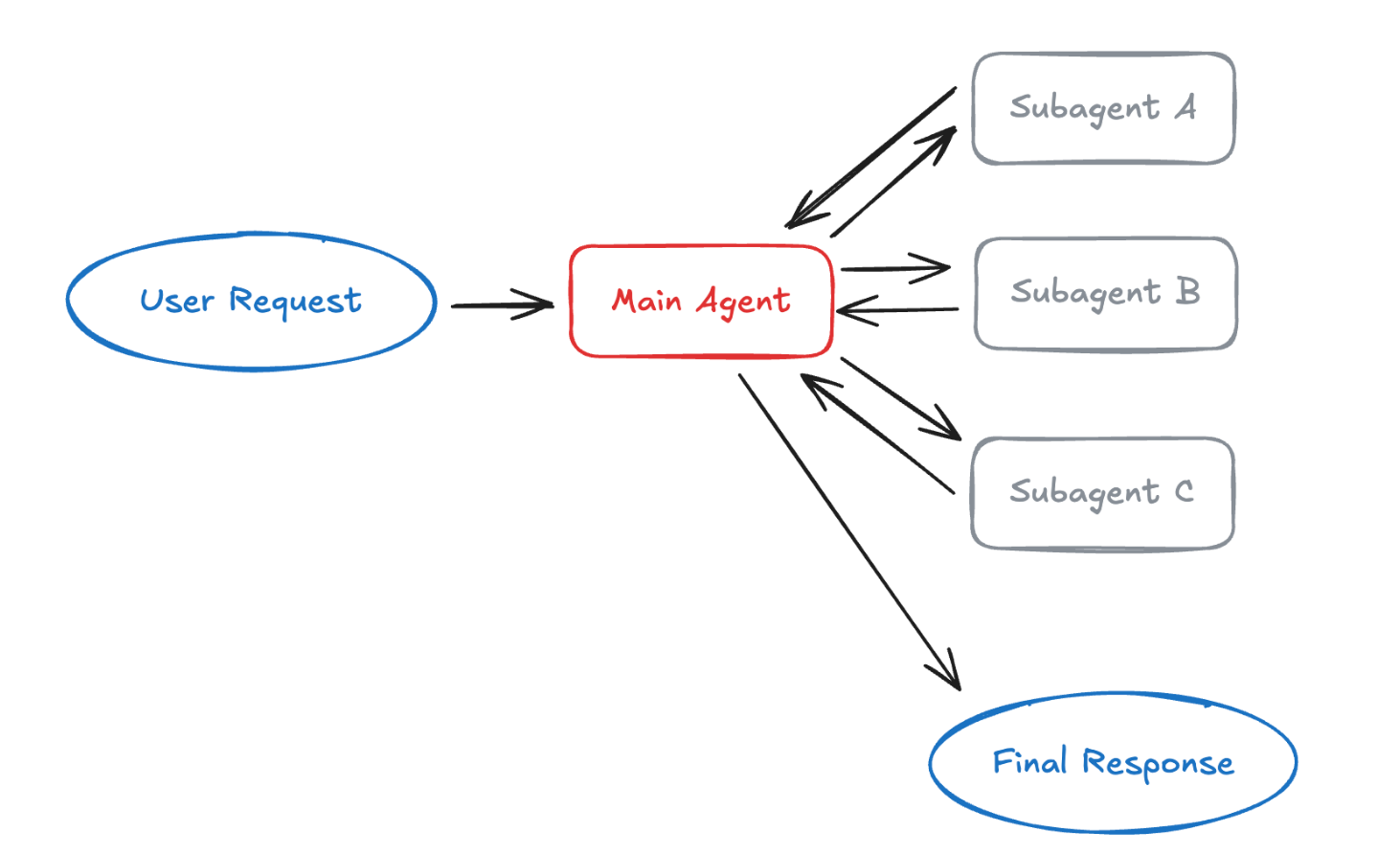
子智能体(Subagents):集中式调度
在子智能体模式中,一个主管智能体 负责统一调度多个专职子智能体,并通过工具调用的方式与它们交互。
工作方式
主智能体负责决定:
- 调用哪些子智能体
- 向它们传入什么输入
- 如何整合它们返回的结果
子智能体本身是无状态的 ,不会记住历史交互。
所有对话上下文都由主智能体统一维护,这带来了非常强的上下文隔离能力。
这种架构下,所有路由决策都集中在主智能体中,它也可以并行调用多个子智能体。
适用场景
- 存在多个彼此区隔的专业领域
- 需要一个统一的工作流控制中枢
- 子智能体不需要直接与用户对话
典型例子包括:
个人助理系统(协调日历、邮件、CRM)、
或研究系统(将任务分派给不同领域的专家)。
关键权衡
每一次交互都会多出一次模型调用,因为所有结果必须回到主智能体进行整合。
这会增加一定的延迟与 token 成本,但换来的,是集中式控制与高度可控的上下文隔离。
如果你希望快速上手这种模式,LangChain 的 Deep Agents 提供了开箱即用的实现,只需极少代码即可引入子智能体。
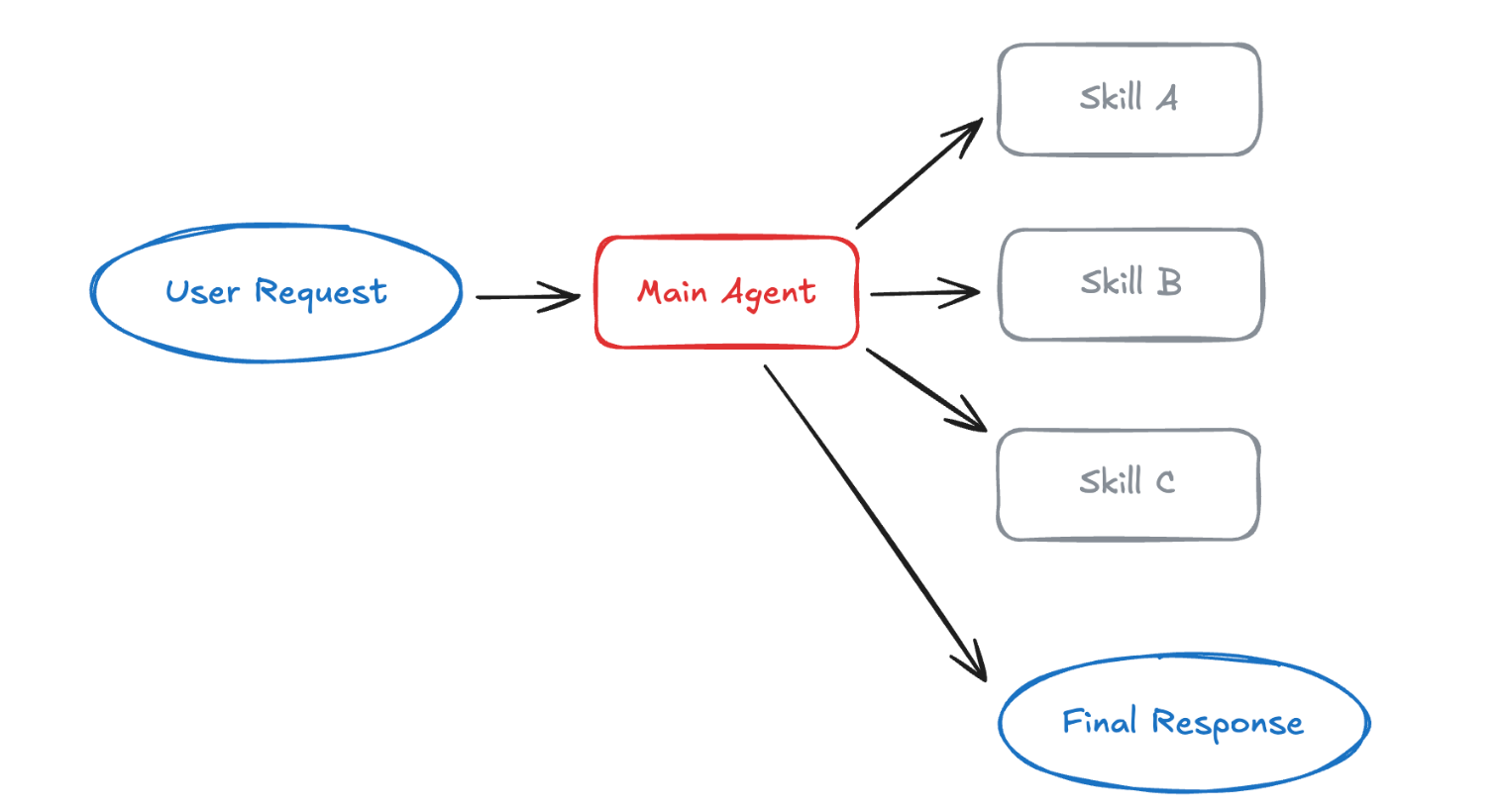
技能(Skills):渐进式能力展开
在技能模式中,智能体会在需要时,按需加载特定的 prompt 与知识模块 。
你可以把它理解为一种「能力的渐进式披露」。
严格来说,技能架构仍然是单智能体系统,但它通过动态切换"角色与能力配置" ,实现了类似多智能体的效果。
因此,我们将它视为一种准多智能体架构。
工作方式
技能通常以目录形式存在,包含:
- 指令说明
- 脚本
- 相关资源文件
在启动时,智能体只知道技能的名称与简介。
当某个技能被判定为相关时,才会加载其完整上下文。
技能内部还可以包含更细粒度的文件,只有在真正需要时才会被进一步发现和加载。
适用场景
- 一个智能体需要掌握大量潜在专长
- 不需要在能力之间强制隔离
- 不同团队分别维护不同技能模块
常见例子包括:编码助手、创意写作助手等。
关键权衡
随着技能被不断加载,上下文会在对话历史中持续累积,可能导致 token 使用膨胀。
但作为回报,这种模式结构简单,且智能体始终可以直接与用户交互。
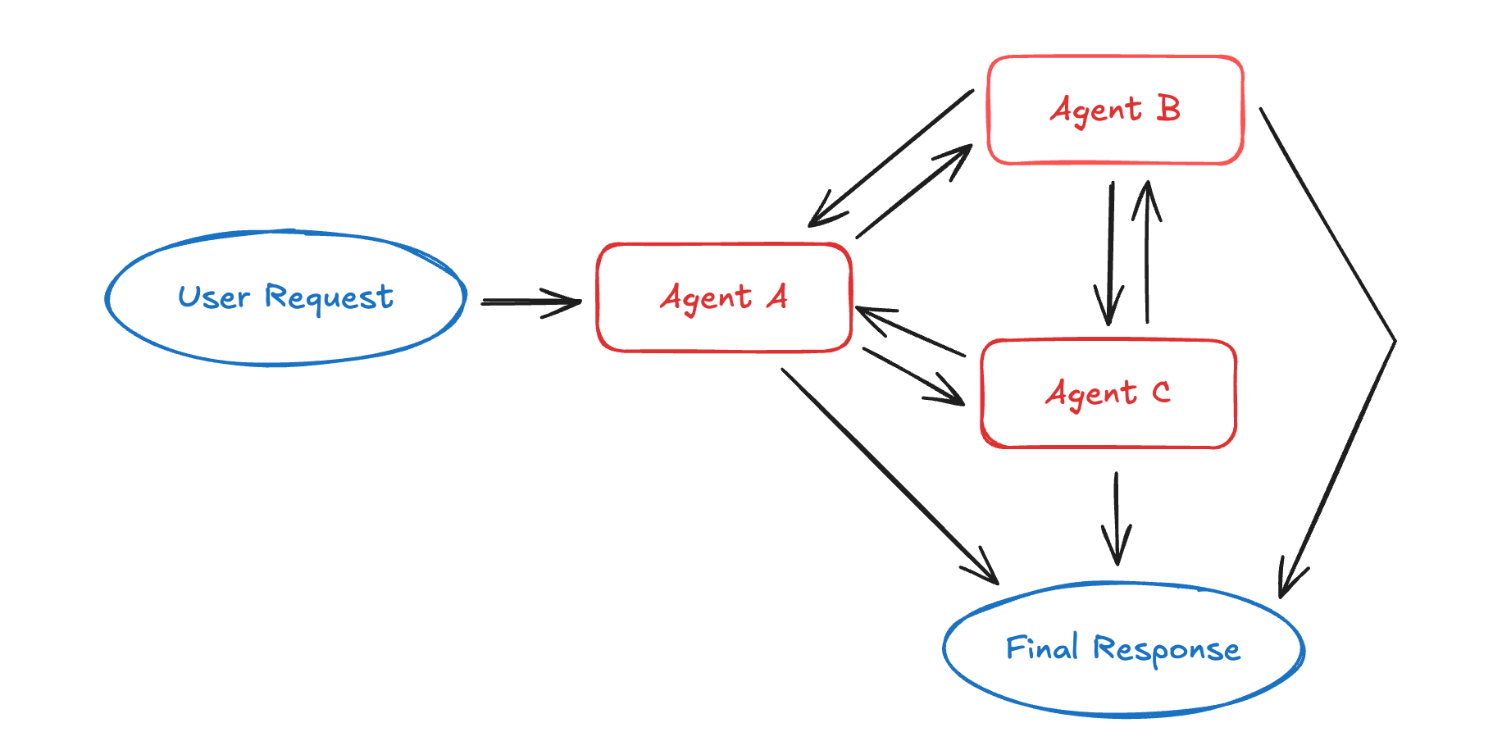
交接(Handoffs):状态驱动的智能体切换
在交接模式中,当前活跃的智能体会随着对话状态动态变化 。
每个智能体都可以通过工具调用,将控制权移交给其他智能体。
工作方式
当一个智能体触发交接工具时,会更新系统状态,决定下一个被激活的智能体。
这既可以是切换到另一个智能体,也可以是重写当前智能体的系统 prompt 与可用工具集合。
这种状态会在多轮对话中持续存在,从而支持顺序化的任务流程。
适用场景
- 客服流程(分阶段收集信息)
- 多阶段对话体验
- 需要满足前置条件后才能解锁能力的场景
关键权衡
相比其他模式,交接模式更依赖状态管理,设计复杂度更高。
但它可以带来非常自然的、多轮连续对话体验。
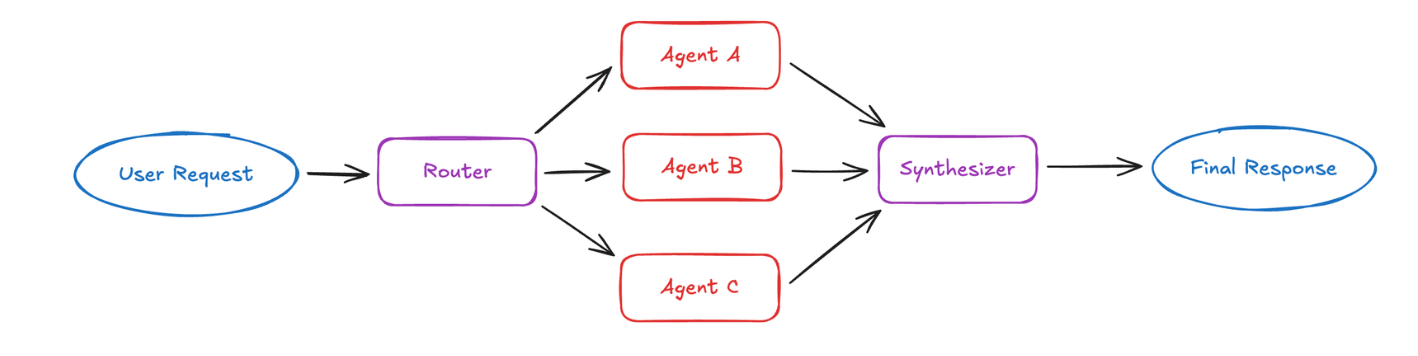
路由(Router):并行分发与结果综合
在路由模式中,一个路由步骤会先对用户输入进行分类,
然后将请求并行分发给一个或多个专用智能体,最后再综合结果。
工作方式
路由器负责:
- 拆解用户查询
- 并行调用相关智能体
- 将多个返回结果整合为统一输出
路由器通常是无状态的,每个请求都是独立处理。
适用场景
- 明确区分的垂直领域
- 需要并行查询多个数据源
- 需要综合多方结果的系统
例如:企业知识库、多领域客服助手。
关键权衡
无状态设计意味着单次请求性能稳定,但如果需要连续对话,就会重复付出路由成本。
这一问题可以通过将路由器作为工具,嵌入到一个有状态的对话智能体中来缓解。
将需求映射到架构模式
在真正实现多智能体系统之前,你可以先对照以下需求进行判断:
- 多个独立领域,需要并行执行 → 子智能体
- 单智能体,多种专长,轻量组合 → 技能
- 有明确顺序与状态切换 → 交接
- 多来源并行查询与综合 → 路由
性能与成本考量
架构选择会直接影响延迟、成本与用户体验 。
我们分析了三个典型场景,来对比不同模式在真实条件下的表现。
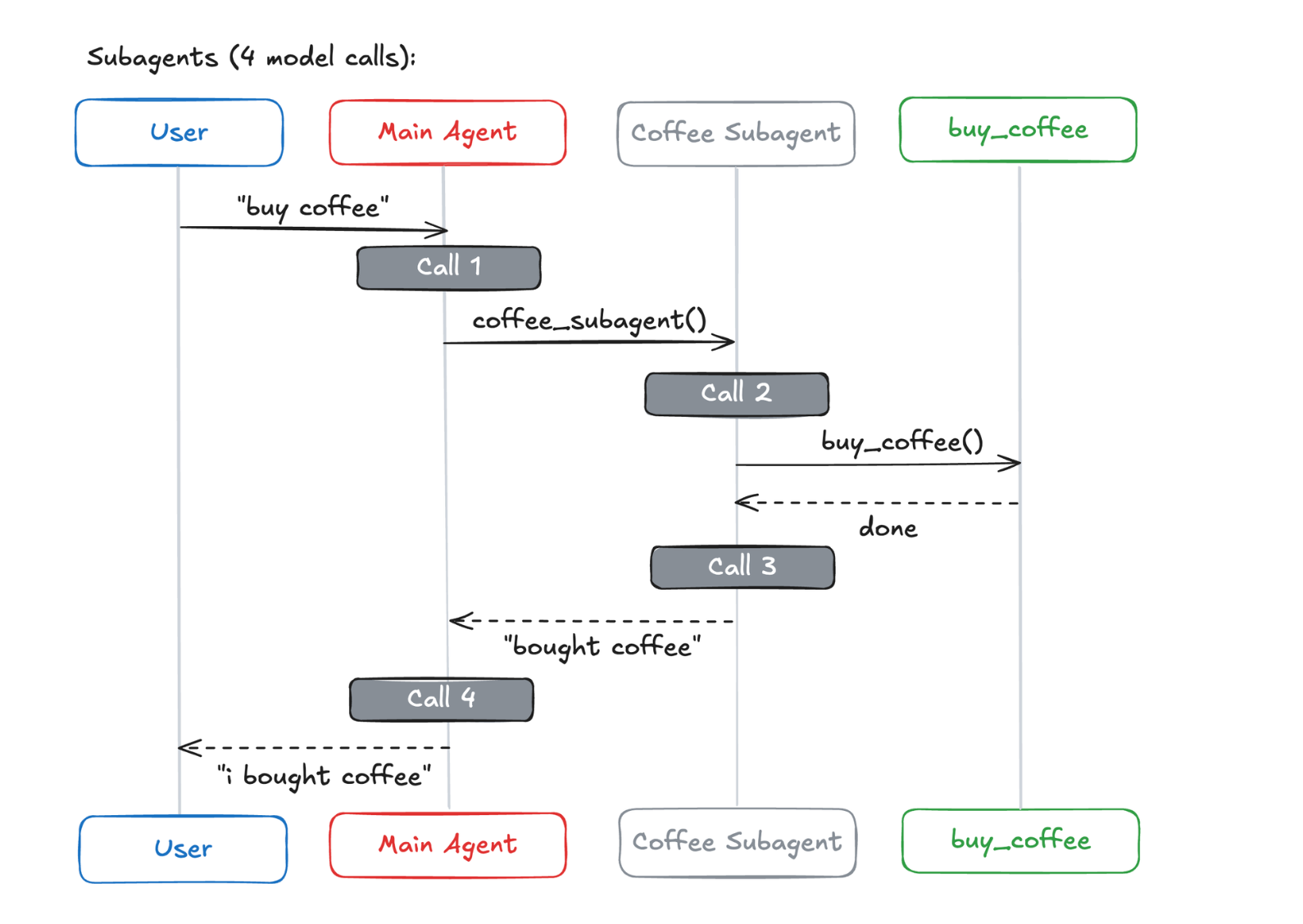
场景一:一次性请求
用户请求:"买咖啡"
结论:
技能、交接、路由在一次性任务中最省调用;
子智能体多一次调用,但换来了集中控制。

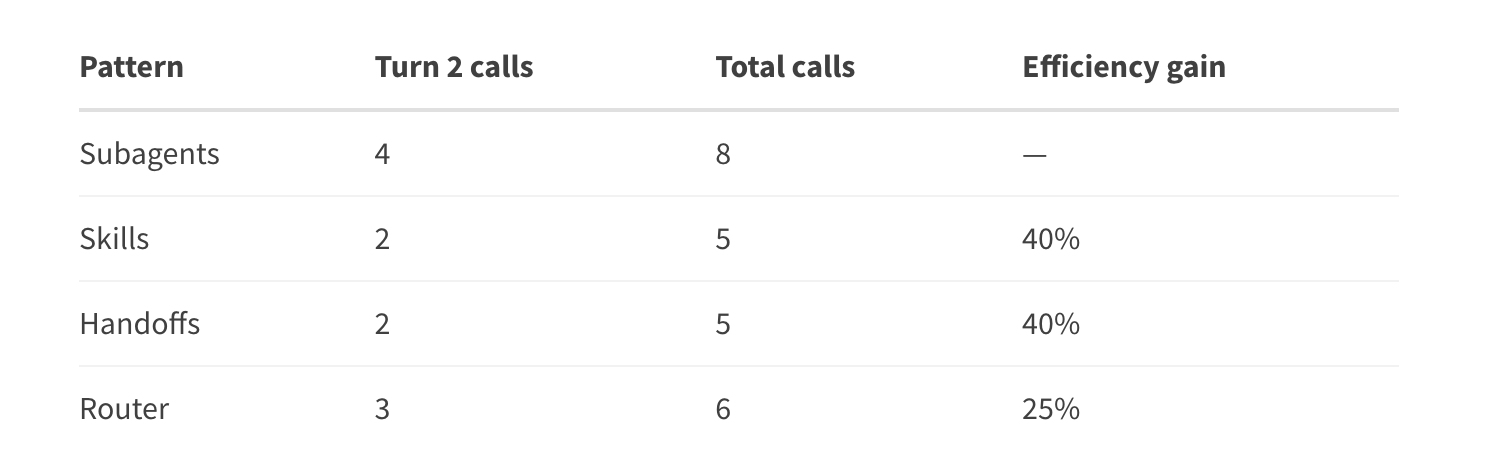
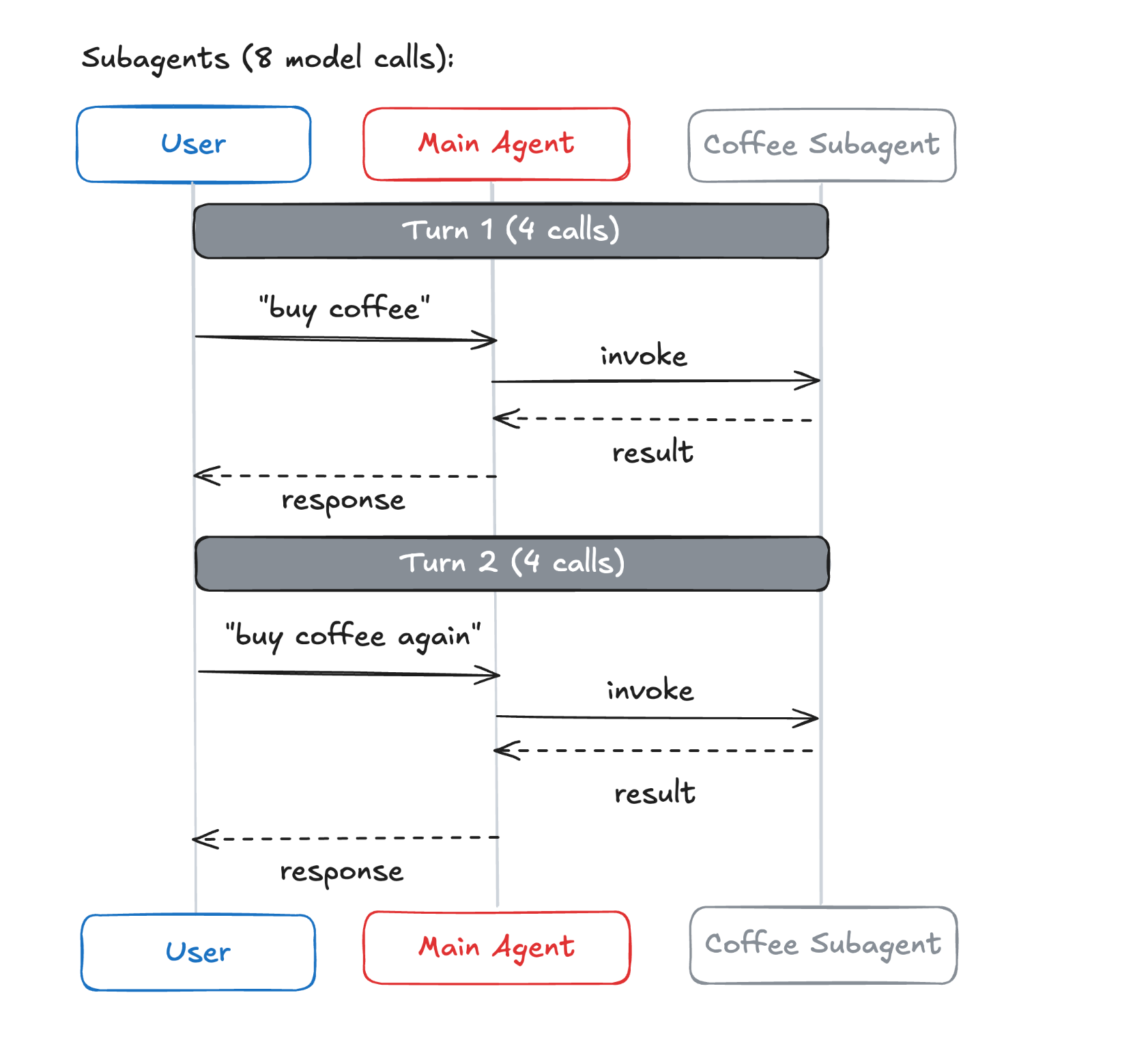
场景二:重复请求
有状态模式(技能、交接)能显著减少重复调用;
子智能体每次成本稳定,但不会因历史而优化。
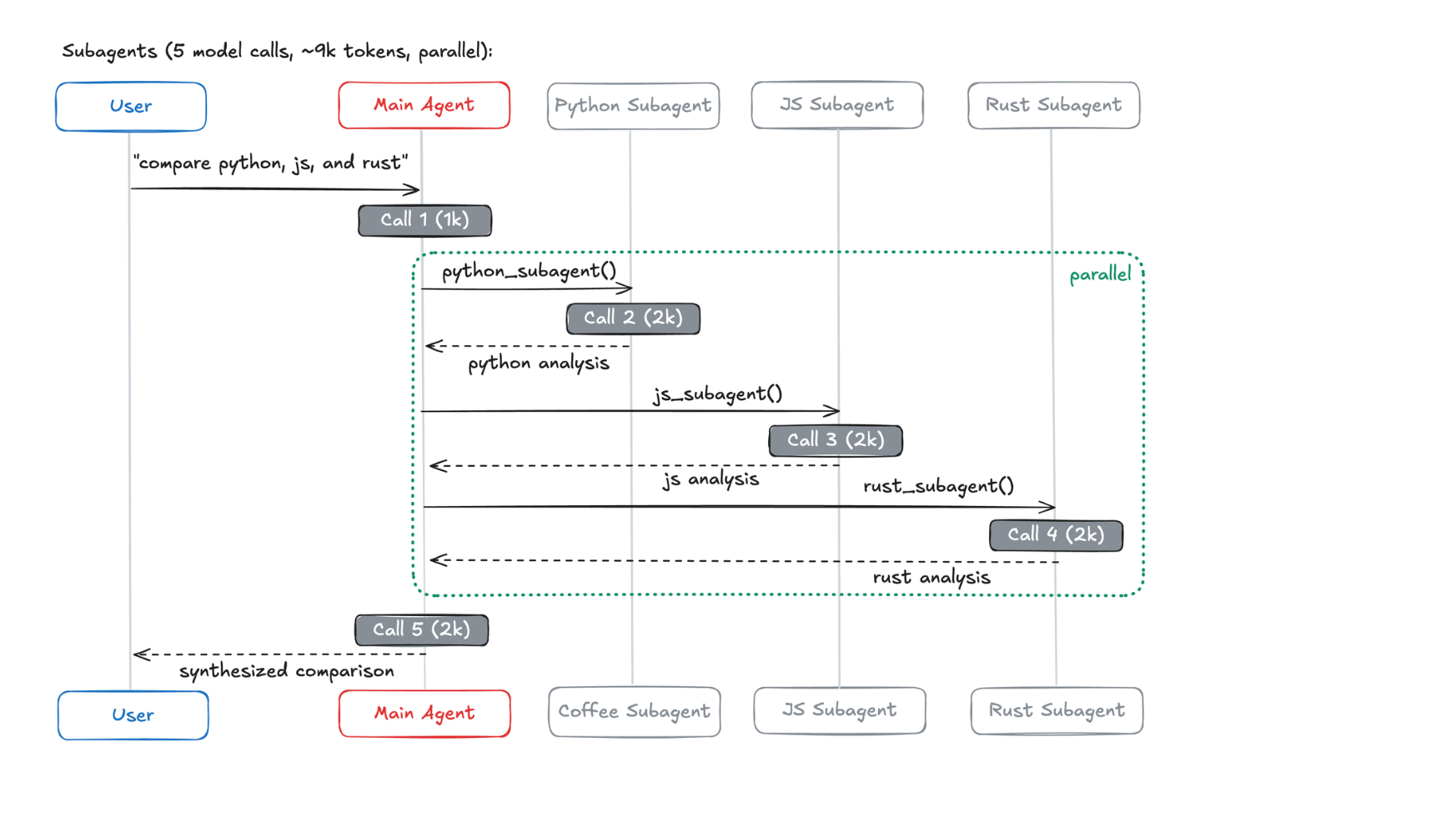
场景三:多领域查询
需要并行能力的场景下,子智能体与路由最优;
技能模式调用少,但 token 消耗高;
交接模式因顺序执行,效率最低。
在该场景中,子智能体相比技能模式,总体 token 使用量减少约 67% ,
原因正是上下文隔离避免了无关信息的持续累积。

总结与建议
多智能体系统的本质,是协调多个专用能力来解决复杂工作流 。
当你确实需要多智能体时,请务必让架构选择直接服务于你的核心约束。
但在绝大多数情况下:
先从单智能体开始 ,
先优化 prompt 与工具设计 ,
只有在明确撞到瓶颈时,才引入多智能体架构。
如果你希望快速起步,Deep Agents 提供了一种融合子智能体与技能的现成方案,适合复杂任务规划。